Customer 360 (C360) provides a complete and unified view of a customer’s interactions and behavior across all touchpoints and channels. This view is used to identify patterns and trends in customer behavior, which can inform data-driven decisions to improve business outcomes. For example, you can use C360 to segment and create marketing campaigns that are more likely to resonate with specific groups of customers.
In 2022, AWS commissioned a study conducted by the American Productivity and Quality Center (APQC) to quantify the Business Value of Customer 360. The following figure shows some of the metrics derived from the study. Organizations using C360 achieved 43.9% reduction in sales cycle duration, 22.8% increase in customer lifetime value, 25.3% faster time to market, and 19.1% improvement in net promoter score (NPS) rating.

Without C360, businesses face missed opportunities, inaccurate reports, and disjointed customer experiences, leading to customer churn. However, building a C360 solution can be complicated. A Gartner Marketing survey found only 14% of organizations have successfully implemented a C360 solution, due to lack of consensus on what a 360-degree view means, challenges with data quality, and lack of cross-functional governance structure for customer data.
In this post, we discuss how you can use purpose-built AWS services to create an end-to-end data strategy for C360 to unify and govern customer data that address these challenges. We structure it in five pillars that power C360: data collection, unification, analytics, activation, and data governance, along with a solution architecture that you can use for your implementation.
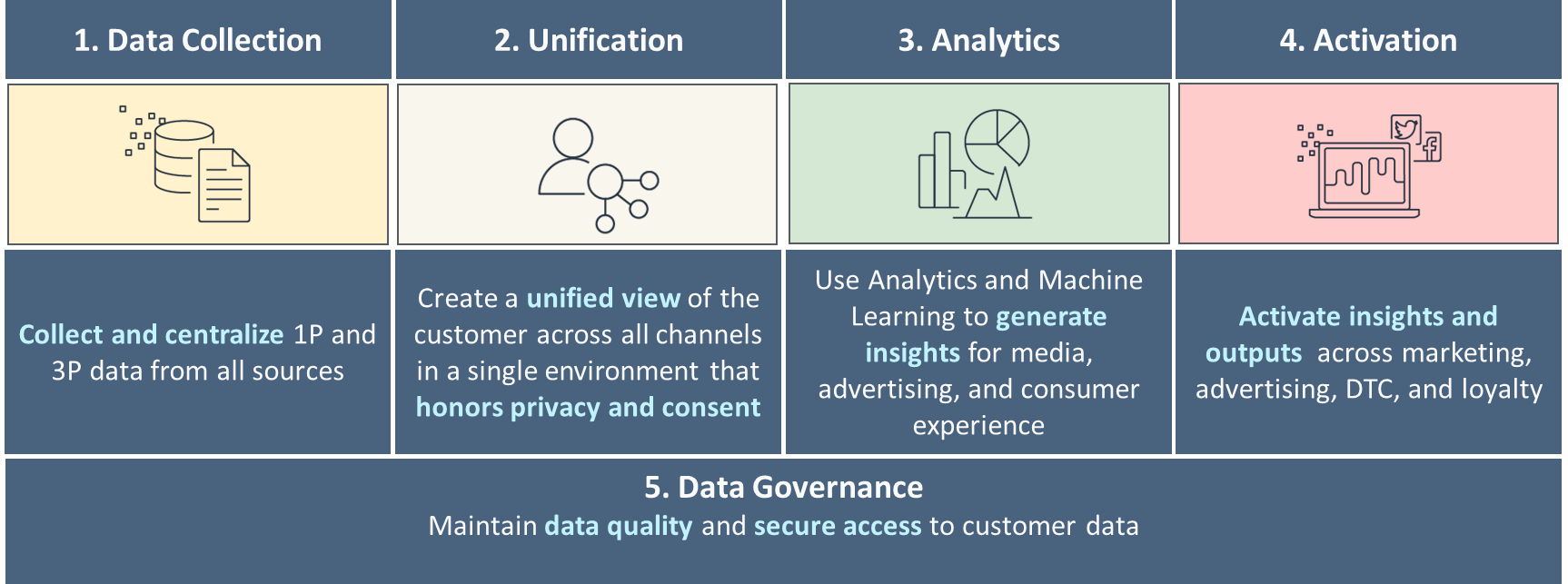
The five pillars of a mature C360
When you embark on creating a C360, you work with multiple use cases, types of customer data, and users and applications that require different tools. Building a C360 on the right datasets, adding new datasets over time while maintaining the quality of data, and keeping it secure needs an end-to-end data strategy for your customer data. You also need to provide tools that make it straightforward for your teams to build products that mature your C360.
We recommend building your data strategy around five pillars of C360, as shown in the following figure. This starts with basic data collection, unifying and linking data from various channels related to unique customers, and progresses towards basic to advanced analytics for decision-making, and personalized engagement through various channels. As you mature in each of these pillars, you progress towards responding to real-time customer signals.
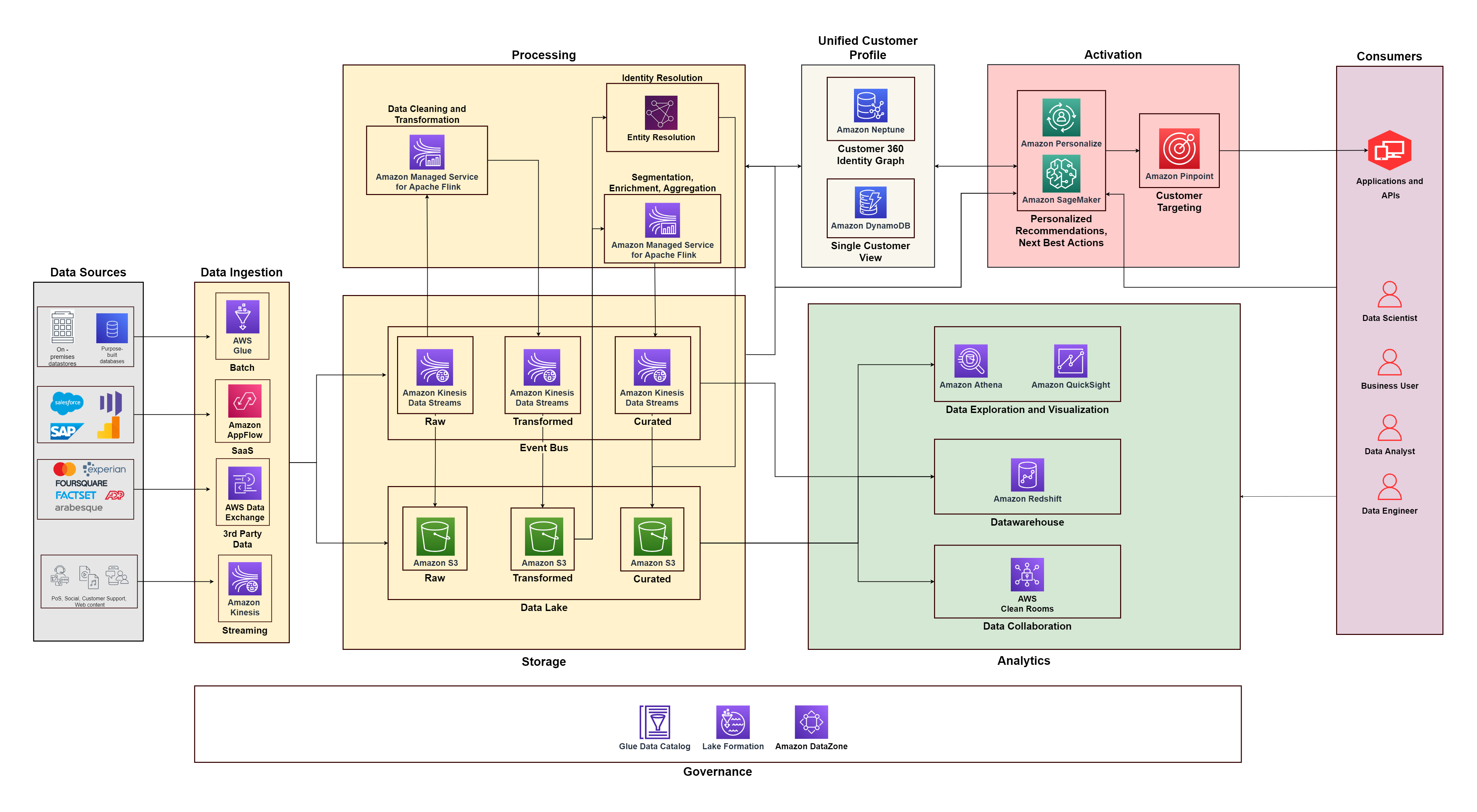
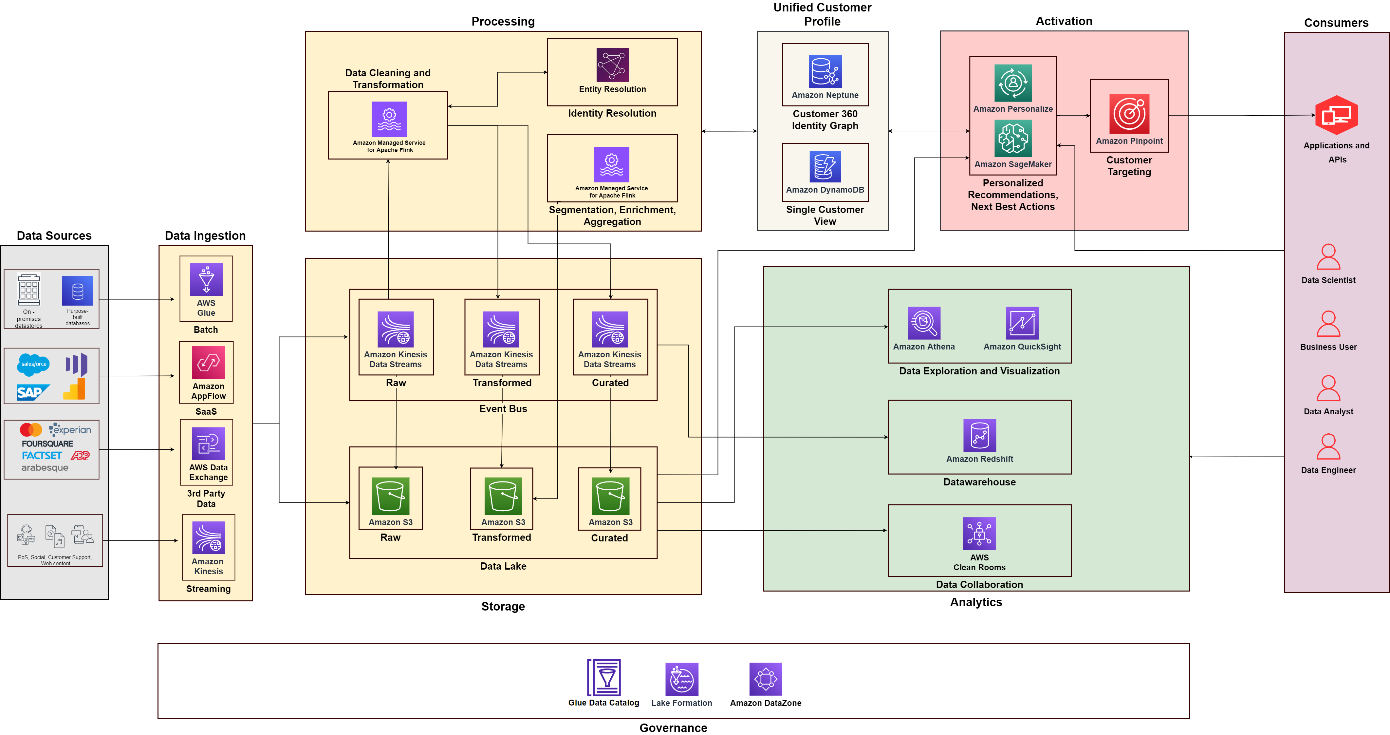
The following diagram illustrates the functional architecture that combines the building blocks of a Customer Data Platform on AWS with additional components used to design an end-to-end C360 solution. This is aligned to the five pillars we discuss in this post.
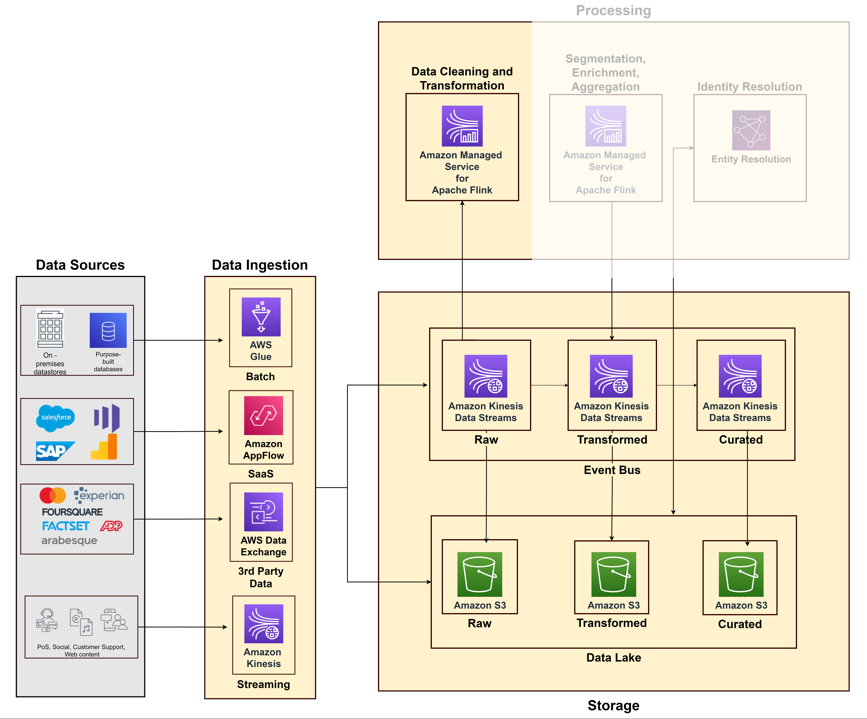
Pillar 1: Data collection
As you start building your customer data platform, you have to collect data from various systems and touchpoints, such as your sales systems, customer support, web and social media, and data marketplaces. Think of the data collection pillar as a combination of ingestion, storage, and processing capabilities.
ڈیٹا ادخال
You have to build ingestion pipelines based on factors like types of data sources (on-premises data stores, files, SaaS applications, third-party data), and flow of data (unbounded streams or batch data). AWS provides different services for building data ingestion pipelines:
- AWS گلو is a serverless data integration service that ingests data in batches from on-premises databases and data stores in the cloud. It connects to more than 70 data sources and helps you build extract, transform, and load (ETL) pipelines without having to manage pipeline infrastructure. AWS گلو ڈیٹا کوالٹی checks for and alerts on poor data, making it straightforward to spot and fix issues before they harm your business.
- ایمیزون ایپ فلو ingests data from software as a service (SaaS) applications like Google Analytics, Salesforce, SAP, and Marketo, giving you the flexibility to ingest data from more than 50 SaaS applications.
- AWS ڈیٹا ایکسچینج makes it straightforward to find, subscribe to, and use third-party data for analytics. You can subscribe to data products that help enrich customer profiles, for example demographics data, advertising data, and financial markets data.
- ایمیزون کنیسیس ingests streaming events in real time from point-of-sales systems, clickstream data from mobile apps and websites, and social media data. You could also consider using ایمیزون نے اپاچی کافکا کے لیے سٹریمنگ کا انتظام کیا۔ (Amazon MSK) for streaming events in real time.
The following diagram illustrates the different pipelines to ingest data from various source systems using AWS services.
ڈیٹا اسٹوریج
Structured, semi-structured, or unstructured batch data is stored in an object storage because these are cost-efficient and durable. ایمیزون سادہ اسٹوریج سروس (Amazon S3) is a managed storage service with archiving features that can store petabytes of data with eleven 9’s of durability. Streaming data with low latency needs is stored in Amazon Kinesis ڈیٹا اسٹریمز for real-time consumption. This allows immediate analytics and actions for various downstream consumers—as seen with Riot Games’ central Riot Event Bus.
ڈیٹا پراسیسنگ
Raw data is often cluttered with duplicates and irregular formats. You need to process this to make it ready for analysis. If you are consuming batch data and streaming data, consider using a framework that can handle both. A pattern such as the Kappa architecture views everything as a stream, simplifying the processing pipelines. Consider using Apache Flink کے لیے Amazon کے زیر انتظام سروس to handle the processing work. With Managed Service for Apache Flink, you can clean and transform the streaming data and direct it to the appropriate destination based on latency requirements. You can also implement batch data processing using ایمیزون ای ایم آر on open source frameworks such as Apache Spark at 3.5 times better performance than the self-managed version. The architecture decision of using a batch or streaming processing system will depend on various factors; however, if you want to enable real-time analytics on your customer data, we recommend using a Kappa architecture pattern.
Pillar 2: Unification
To link the diverse data arriving from various touchpoints to a unique customer, you need to build an identity processing solution that identifies anonymous logins, stores useful customer information, links them to external data for better insights, and groups customers in domains of interest. Although the identity processing solution helps build the unified customer profile, we recommend considering this as part of your data processing capabilities. The following diagram illustrates the components of such a solution.
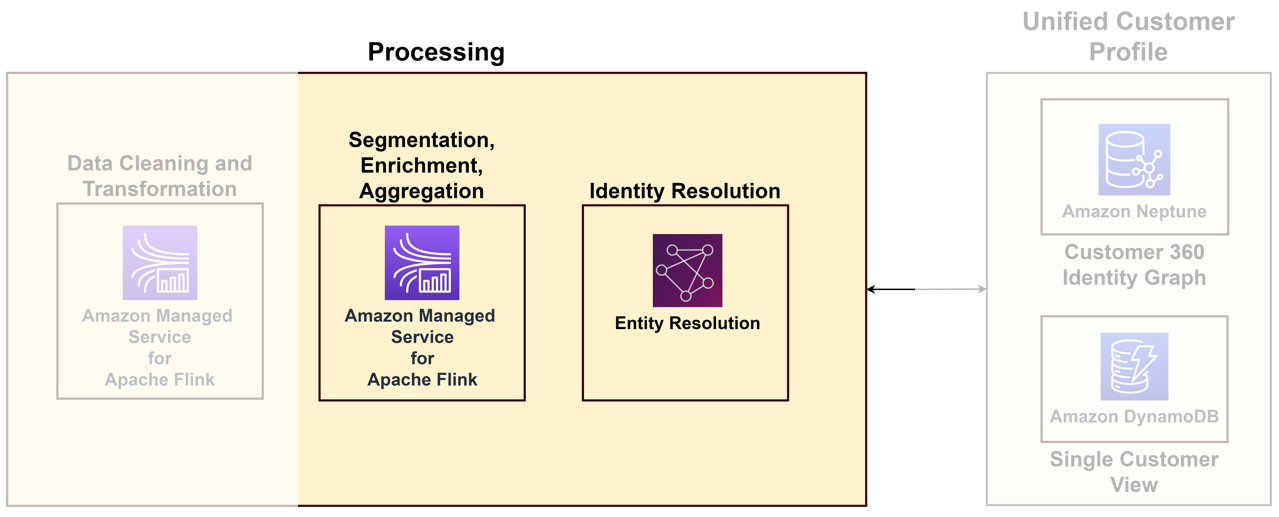
The key components are as follows:
- شناخت کا حل – Identity resolution is a deduplication solution, where records are matched to identify a unique customer and prospects by linking multiple identifiers such as cookies, device identifiers, IP addresses, email IDs, and internal enterprise IDs to a known person or anonymous profile using privacy-compliant methods. This can be achieved using AWS ہستی کی قرارداد, which enables using rules and machine learning (ML) techniques to match records and resolve identities. متبادل کے طور پر ، آپ کر سکتے ہیں build identity graphs کا استعمال کرتے ہوئے ایمیزون نیپچون for a single unified view of your customers.
- Profile aggregation – When you’ve uniquely identified a customer, you can build applications in Managed Service for Apache Flink to consolidate all their metadata, from name to interaction history. Then, you transform this data into a concise format. Instead of showing every transaction detail, you can offer an aggregated spend value and a link to their Customer Relationship Management (CRM) record. For customer service interactions, provide an average CSAT score and a link to the call center system for a deeper dive into their communication history.
- Profile enrichment – After you resolve a customer to a single identity, enhance their profile using various data sources. Enrichment typically involves adding demographic, behavioral, and geolocation data. You can use third-party data products from AWS Marketplace delivered through AWS Data Exchange to gain insights on income, consumption patterns, credit risk scores, and many more dimensions to further refine the customer experience.
- کسٹمر کی تقسیم – After uniquely identifying and enriching a customer’s profile, you can segment them based on demographics like age, spend, income, and location using applications in Managed Service for Apache Flink. As you advance, you can incorporate AI services for more precise targeting techniques.
After you have done the identity processing and segmentation, you need a storage capability to store the unique customer profile and provide search and query capabilities on top of it for downstream consumers to use the enriched customer data.
The following diagram illustrates the unification pillar for a unified customer profile and single view of the customer for downstream applications.
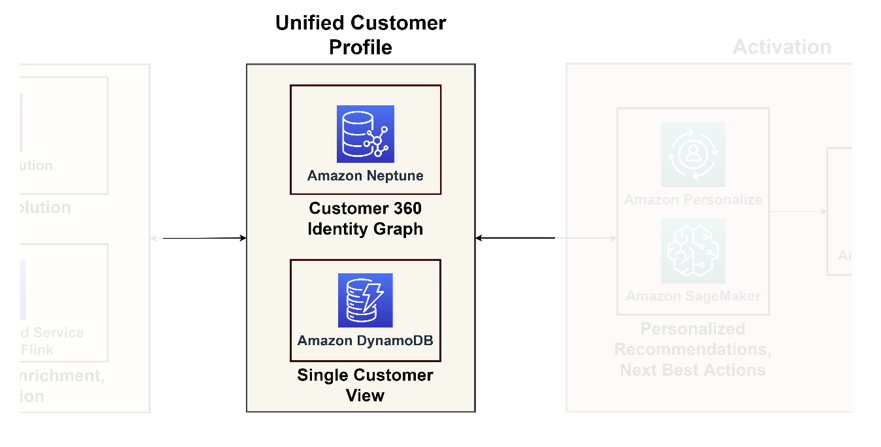
متحد کسٹمر پروفائل
Graph databases excel in modeling customer interactions and relationships, offering a comprehensive view of the customer journey. If you are dealing with billions of profiles and interactions, you can consider using Neptune, a managed graph database service on AWS. Organizations such as Zeta اور Activision have successfully used Neptune to store and query billions of unique identifiers per month and millions of queries per second at millisecond response time.
واحد گاہک کا نظارہ
Although graph databases provide in-depth insights, yet they can be complex for regular applications. It is prudent to consolidate this data into a single customer view, serving as a primary reference for downstream applications, ranging from ecommerce platforms to CRM systems. This consolidated view acts as a liaison between the data platform and customer-centric applications. For such purposes, we recommend using ایمیزون ڈائنومو ڈی بی for its adaptability, scalability, and performance, resulting in an up-to-date and efficient customer database. This database will accept a lot of write queries back from the activation systems that learn new information about the customers and feed them back.
Pillar 3: Analytics
The analytics pillar defines capabilities that help you generate insights on top of your customer data. Your analytics strategy applies to the wider organizational needs, not just C360. You can use the same capabilities to serve financial reporting, measure operational performance, or even monetize data assets. Strategize based on how your teams explore data, run analyses, wrangle data for downstream requirements, and visualize data at different levels. Plan on how you can enable your teams to use ML to move from descriptive to prescriptive analytics.
۔ AWS جدید ڈیٹا فن تعمیر shows a way to build a purpose-built, secure, and scalable data platform in the cloud. Learn from this to build querying capabilities across your data lake and the data warehouse.
The following diagram breaks down the analytics capability into data exploration, visualization, data warehousing, and data collaboration. Let’s find out what role each of these components play in the context of C360.

ڈیٹا ایکسپلوریشن
Data exploration helps unearth inconsistencies, outliers, or errors. By spotting these early on, your teams can have cleaner data integration for C360, which in turn leads to more accurate analytics and predictions. Consider the personas exploring the data, their technical skills, and the time to insight. For instance, data analysts who know to write SQL can directly query the data residing in Amazon S3 using ایمیزون ایتینا. Users interested in visual exploration can do so using AWS گلو ڈیٹا بریو. Data scientists or engineers can use ایمیزون EMR اسٹوڈیو or ایمیزون سیج میکر اسٹوڈیو to explore data from the notebook, and for a low-code experience, you can use ایمیزون سیج میکر ڈیٹا رینگلر. Because these services directly query S3 buckets, you can explore the data as it lands in the data lake, reducing time to insight.
تصور
Turning complex datasets into intuitive visuals unravels hidden patterns in the data, and is crucial for C360 use cases. With this capability, you can design reports for different levels catering to varying needs: executive reports offering strategic overviews, management reports highlighting operational metrics, and detailed reports diving into the specifics. Such visual clarity helps your organization make informed decisions across all tiers, centralizing the customer’s perspective.
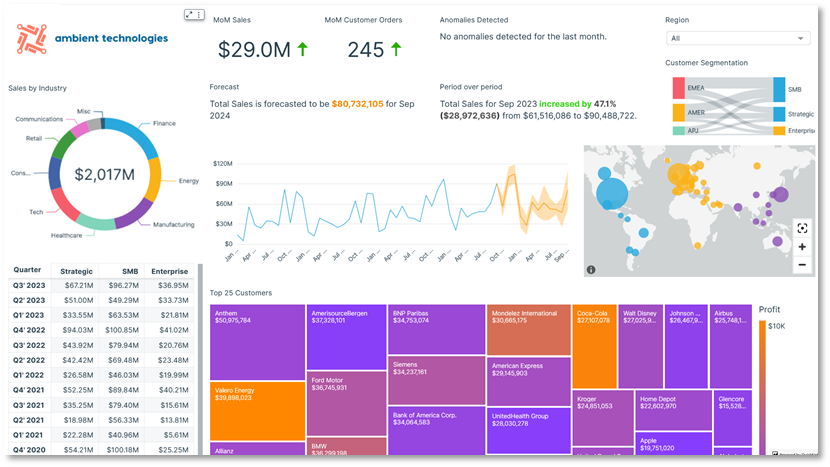
The following diagram shows a sample C360 dashboard built on ایمیزون کوئیک سائٹ. QuickSight offers scalable, serverless visualization capabilities. You can benefit from its ML integrations for automated insights like forecasting and anomaly detection or natural language querying with QuickSight میں Amazon Q, direct data connectivity from various sources, and pay-per-session pricing. With QuickSight, you can embed dashboards to external websites and applications، اور مسالا engine enables rapid, interactive data visualization at scale. The following screenshot shows an example C360 dashboard built on QuickSight.
ڈیٹا گودام
Data warehouses are efficient in consolidating structured data from multifarious sources and serving analytics queries from a large number of concurrent users. Data warehouses can provide a unified, consistent view of a vast amount of customer data for C360 use cases. ایمیزون ریڈ شفٹ addresses this need by adeptly handling large volumes of data and diverse workloads. It provides strong consistency across datasets, allowing organizations to derive reliable, comprehensive insights about their customers, which is essential for informed decision-making. Amazon Redshift offers real-time insights and predictive analytics capabilities for analyzing data from terabytes to petabytes. With ایمیزون ریڈ شفٹ ایم ایل, you can embed ML on top of the data stored in the data warehouse with minimum development overhead. ایمیزون ریڈ شفٹ سرور لیس simplifies application building and makes it straightforward for companies to embed rich data analytics capabilities.
ڈیٹا تعاون
You can securely collaborate and analyze collective datasets from your partners without sharing or copying one another’s underlying data using AWS صاف کمرے. You can bring together disparate data from across engagement channels and partner datasets to form a 360-degree view of your customers. AWS Clean Rooms can enhance C360 by enabling use cases like cross-channel marketing optimization, advanced customer segmentation, and privacy-compliant personalization. By safely merging datasets, it offers richer insights and robust data privacy, meeting business needs and regulatory standards.
Pillar 4: Activation
The value of data diminishes the older it gets, leading to higher opportunity costs over time. In a survey conducted by Intersystems, 75% of the organizations surveyed believe untimely data inhibited business opportunities. In another survey, 58٪ تنظیمیں (out of 560 respondents of HBR Advisory council and readers) stated they saw an increase in customer retention and loyalty using real-time customer analytics.
You can achieve a maturity in C360 when you build the ability to act on all the insights acquired from the previous pillars we discussed in real time. For example, at this maturity level, you can act on customer sentiment based on the context you automatically derived with an enriched customer profile and integrated channels. For this you need to implement prescriptive decision-making on how to address the customer’s sentiment. To do this at scale, you have to use AI/ML services for decision-making. The following diagram illustrates the architecture to activate insights using ML for prescriptive analytics and AI services for targeting and segmentation.
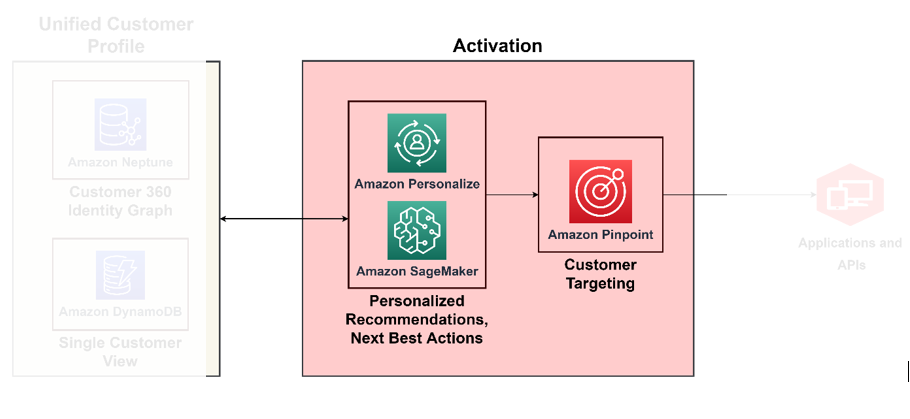
Use ML for the decision-making engine
With ML, you can improve the overall customer experience—you can create predictive customer behavior models, design hyper-personalized offers, and target the right customer with the right incentive. You can build them using ایمیزون سیج میکر, which features a suite of managed services mapped to the data science lifecycle, including data wrangling, model training, model hosting, model inference, model drift detection, and feature storage. SageMaker enables you to build and operationalize your ML models, infusing them back into your applications to produce the right insight to the right person at the right time.
ایمیزون کو ذاتی بنائیں۔ supports contextual recommendations, through which you can improve the relevance of recommendations by generating them within a context—for instance, device type, location, or time of day. Your team can get started without any prior ML experience using APIs to build sophisticated personalization capabilities in a few clicks. For more information, see Amazon Personalize کے ساتھ کاروباری قواعد کا استعمال کرتے ہوئے مخصوص آئٹمز کو فروغ دے کر اپنی سفارشات کو حسب ضرورت بنائیں.
Activate channels across marketing, advertising, direct-to-consumer, and loyalty
Now that you know who your customers are and who to reach out to, you can build solutions to run targeting campaigns at scale. With ایمیزون پن پوائنٹ, you can personalize and segment communications to engage customers across multiple channels. For example, you can use Amazon Pinpoint to build engaging customer experiences through various communication channels like email, SMS, push notifications, and in-app notifications.
Pillar 5: Data governance
Establishing the right governance that balances control and access gives users trust and confidence in data. Imagine offering promotions on products that a customer doesn’t need, or bombarding the wrong customers with notifications. Poor data quality can lead to such situations, and ultimately results in customer churn. You have to build processes that validate data quality and take corrective actions. AWS گلو ڈیٹا کوالٹی can help you build solutions that validate the quality of data at rest and in transit, based on predefined rules.
To set up a cross-functional governance structure for customer data, you need a capability for governing and sharing data across your organization. With ایمیزون ڈیٹا زون, admins and data stewards can manage and govern access to data, and consumers such as data engineers, data scientists, product managers, analysts, and other business users can discover, use, and collaborate with that data to drive insights. It streamlines data access, letting you find and use customer data, promotes team collaboration with shared data assets, and provides personalized analytics either via a web app or API on a portal. AWS جھیل کی تشکیل makes sure data is accessed securely, guaranteeing the right people see the right data for the right reasons, which is crucial for effective cross-functional governance in any organization. Business metadata is stored and managed by Amazon DataZone, which is underpinned by technical metadata and schema information, which is registered in the AWS گلو ڈیٹا کیٹلاگ. This technical metadata is also used both by other governance services such as Lake Formation and Amazon DataZone, and analytics services such as Amazon Redshift, Athena, and AWS Glue.

یہ سب کو ایک دوسرے کے قریب لاتا
Using the following diagram as a reference, you can create projects and teams for building and operating different capabilities. For example, you can have a data integration team focus on the data collection pillar—you can then align functional roles, like data architects and data engineers. You can build your analytics and data science practices to focus on the analytics and activation pillars, respectively. Then you can create a specialized team for customer identity processing and for building the unified view of the customer. You can establish a data governance team with data stewards from different functions, security admins, and data governance policymakers to design and automate policies.
نتیجہ
Building a robust C360 capability is fundamental for your organization to gain insights into your customer base. AWS Databases, Analytics, and AI/ML services can help streamline this process, providing scalability and efficiency. Following the five pillars to guide your thinking, you can build an end-to-end data strategy that defines the C360 view across the organization, makes sure data is accurate, and establishes cross-functional governance for customer data. You can categorize and prioritize the products and features you have to build within each pillar, select the right tool for the job, and build the skills you need in your teams.
دورہ AWS for Data Customer Stories to learn how AWS is transforming customer journeys, from the world’s largest enterprises to growing startups.
مصنفین کے بارے میں
 Ismail Makhlouf is a Senior Specialist Solutions Architect for Data Analytics at AWS. Ismail focuses on architecting solutions for organizations across their end-to-end data analytics estate, including batch and real-time streaming, big data, data warehousing, and data lake workloads. He primarily works with organizations in retail, ecommerce, FinTech, HealthTech, and travel to achieve their business objectives with well architected data platforms.
Ismail Makhlouf is a Senior Specialist Solutions Architect for Data Analytics at AWS. Ismail focuses on architecting solutions for organizations across their end-to-end data analytics estate, including batch and real-time streaming, big data, data warehousing, and data lake workloads. He primarily works with organizations in retail, ecommerce, FinTech, HealthTech, and travel to achieve their business objectives with well architected data platforms.
 سندیپن بھومک (Sandi) is a Senior Analytics Specialist Solutions Architect at AWS. He helps customers modernize their data platforms in the cloud to perform analytics securely at scale, reduce operational overhead, and optimize usage for cost-effectiveness and sustainability.
سندیپن بھومک (Sandi) is a Senior Analytics Specialist Solutions Architect at AWS. He helps customers modernize their data platforms in the cloud to perform analytics securely at scale, reduce operational overhead, and optimize usage for cost-effectiveness and sustainability.
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/big-data/create-an-end-to-end-data-strategy-for-customer-360-on-aws/

