یہ بلاگ پوسٹ Veoneer کی کیرولین چنگ کے ساتھ مل کر لکھی گئی ہے۔
Veoneer ایک عالمی آٹو موٹیو الیکٹرانکس کمپنی ہے اور آٹوموٹیو الیکٹرانک سیفٹی سسٹمز میں عالمی رہنما ہے۔ وہ بہترین درجے کے ریسٹرینٹ کنٹرول سسٹم پیش کرتے ہیں اور عالمی سطح پر کار مینوفیکچررز کو 1 بلین سے زیادہ الیکٹرانک کنٹرول یونٹس اور کریش سینسرز فراہم کر چکے ہیں۔ کمپنی آٹوموٹو سیفٹی ڈویلپمنٹ کی 70 سالہ تاریخ پر کام جاری رکھے ہوئے ہے، جدید ترین ہارڈ ویئر اور سسٹمز میں مہارت رکھتی ہے جو ٹریفک کے واقعات کو روکتے ہیں اور حادثات کو کم کرتے ہیں۔
آٹوموٹیو ان کیبن سینسنگ (ICS) ایک ابھرتی ہوئی جگہ ہے جو سیفٹی کو بڑھانے اور سواری کے تجربے کو بہتر بنانے کے لیے کئی قسم کے سینسر جیسے کیمرے اور ریڈار، اور مصنوعی ذہانت (AI) اور مشین لرننگ (ML) پر مبنی الگورتھم کا استعمال کرتی ہے۔ اس طرح کے نظام کی تعمیر ایک پیچیدہ کام ہو سکتا ہے. ڈویلپرز کو تربیت اور جانچ کے مقاصد کے لیے بڑی مقدار میں تصاویر کو دستی طور پر تشریح کرنا پڑتا ہے۔ یہ بہت وقت طلب اور وسائل کی ضرورت ہے۔ اس طرح کے کام کے لیے تبدیلی کا وقت کئی ہفتے ہے۔ مزید برآں، کمپنیوں کو انسانی غلطیوں کی وجہ سے متضاد لیبل جیسے مسائل سے نمٹنا پڑتا ہے۔
AWS آپ کی ترقی کی رفتار بڑھانے اور ML جیسے جدید تجزیات کے ذریعے اس طرح کے سسٹمز بنانے کے لیے آپ کی لاگت کو کم کرنے میں مدد کرنے پر مرکوز ہے۔ ہمارا وژن ایم ایل کو خودکار تشریح کے لیے استعمال کرنا، حفاظتی ماڈلز کی دوبارہ تربیت کو فعال کرنا، اور کارکردگی کے مستقل اور قابل اعتماد میٹرکس کو یقینی بنانا ہے۔ اس پوسٹ میں، ہم Amazon کی ورلڈ وائیڈ اسپیشلسٹ آرگنائزیشن اور جنریٹو اے آئی انوویشن سینٹرہم نے ان کیبن امیج ہیڈ باؤنڈنگ بکس اور کلیدی پوائنٹس کی تشریح کے لیے ایک فعال لرننگ پائپ لائن تیار کی ہے۔ یہ حل لاگت کو 90% سے زیادہ کم کرتا ہے، ٹرناراؤنڈ ٹائم کے لحاظ سے تشریح کے عمل کو ہفتوں سے گھنٹوں تک تیز کرتا ہے، اور اسی طرح کے ML ڈیٹا لیبلنگ کے کاموں کے لیے دوبارہ استعمال کے قابل بناتا ہے۔
حل جائزہ
ایکٹیو لرننگ ایک ایم ایل اپروچ ہے جس میں ایک ماڈل کو تربیت دینے کے لیے انتہائی معلوماتی ڈیٹا کو منتخب کرنے اور ان کی تشریح کرنے کا ایک تکراری عمل شامل ہے۔ لیبل لگائے گئے ڈیٹا کے ایک چھوٹے سے سیٹ اور بغیر لیبل والے ڈیٹا کے ایک بڑے سیٹ کو دیکھتے ہوئے، فعال سیکھنے سے ماڈل کی کارکردگی بہتر ہوتی ہے، لیبل لگانے کی کوشش کم ہوتی ہے، اور مضبوط نتائج کے لیے انسانی مہارت کو مربوط کیا جاتا ہے۔ اس پوسٹ میں، ہم AWS سروسز کے ساتھ تصویری تشریحات کے لیے ایک فعال لرننگ پائپ لائن بناتے ہیں۔
درج ذیل خاکہ ہماری فعال سیکھنے کی پائپ لائن کے مجموعی فریم ورک کو ظاہر کرتا ہے۔ لیبلنگ پائپ لائن ایک سے تصاویر لیتی ہے۔ ایمیزون سادہ اسٹوریج سروس (Amazon S3) بالٹی اور آؤٹ پٹ ML ماڈلز اور انسانی مہارت کے تعاون سے تشریح شدہ تصاویر۔ ٹریننگ پائپ لائن ڈیٹا کو پری پروسیس کرتی ہے اور انہیں ایم ایل ماڈلز کو تربیت دینے کے لیے استعمال کرتی ہے۔ ابتدائی ماڈل کو دستی طور پر لیبل لگائے گئے ڈیٹا کے ایک چھوٹے سیٹ پر ترتیب دیا گیا ہے اور اسے تربیت دی گئی ہے، اور اسے لیبلنگ پائپ لائن میں استعمال کیا جائے گا۔ لیبلنگ پائپ لائن اور ٹریننگ پائپ لائن کو ماڈل کی کارکردگی کو بڑھانے کے لیے مزید لیبل والے ڈیٹا کے ساتھ آہستہ آہستہ دہرایا جا سکتا ہے۔
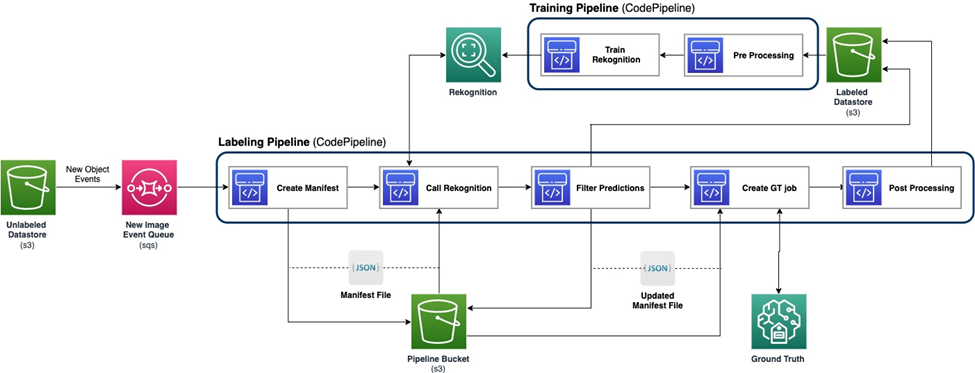
لیبلنگ پائپ لائن میں، ایک ایمیزون S3 ایونٹ کی اطلاع جب تصاویر کا ایک نیا بیچ بغیر لیبل والے ڈیٹا اسٹور S3 بالٹی میں آتا ہے، لیبلنگ پائپ لائن کو چالو کرتا ہے۔ ماڈل نئی امیجز پر قیاس کے نتائج تیار کرتا ہے۔ ایک حسب ضرورت فیصلے کا فنکشن ڈیٹا کے کچھ حصوں کا انتخاب کنفیڈینس سکور یا صارف کے طے کردہ دیگر افعال کی بنیاد پر کرتا ہے۔ یہ ڈیٹا، اس کے قیاس کے نتائج کے ساتھ، انسانی لیبلنگ کے کام کے لیے بھیجا جاتا ہے۔ ایمیزون سیج میکر گراؤنڈ ٹروتھ پائپ لائن کی طرف سے پیدا. انسانی لیبلنگ کے عمل سے ڈیٹا کی تشریح میں مدد ملتی ہے، اور ترمیم شدہ نتائج کو بقیہ خودکار تشریح شدہ ڈیٹا کے ساتھ ملایا جاتا ہے، جسے بعد میں ٹریننگ پائپ لائن کے ذریعے استعمال کیا جا سکتا ہے۔
ماڈل کی دوبارہ تربیت ٹریننگ پائپ لائن میں ہوتی ہے، جہاں ہم ماڈل کو دوبارہ تربیت دینے کے لیے انسانی لیبل والے ڈیٹا پر مشتمل ڈیٹاسیٹ کا استعمال کرتے ہیں۔ ایک مینی فیسٹ فائل یہ بیان کرنے کے لیے تیار کی جاتی ہے کہ فائلیں کہاں محفوظ ہیں، اور وہی ابتدائی ماڈل نئے ڈیٹا پر دوبارہ تربیت دی جاتی ہے۔ دوبارہ تربیت کے بعد، نیا ماڈل ابتدائی ماڈل کی جگہ لے لیتا ہے، اور فعال سیکھنے کی پائپ لائن کا اگلا تکرار شروع ہوتا ہے۔
ماڈل کی تعیناتی۔
لیبلنگ پائپ لائن اور ٹریننگ پائپ لائن دونوں پر تعینات ہیں۔ AWS کوڈ پائپ لائن. AWS کوڈ بلڈ۔ مثالوں کو لاگو کرنے کے لیے استعمال کیا جاتا ہے، جو کہ تھوڑی مقدار میں ڈیٹا کے لیے لچکدار اور تیز ہوتا ہے۔ جب رفتار کی ضرورت ہوتی ہے تو ہم استعمال کرتے ہیں۔ ایمیزون سیج میکر GPU مثال پر مبنی اختتامی نکات عمل کو سپورٹ اور تیز کرنے کے لیے مزید وسائل مختص کرنے کے لیے۔
جب نیا ڈیٹا سیٹ ہو یا جب ماڈل کی کارکردگی میں بہتری کی ضرورت ہو تو ماڈل ری ٹریننگ پائپ لائن کو استعمال کیا جا سکتا ہے۔ ری ٹریننگ پائپ لائن میں ایک اہم کام تربیتی ڈیٹا اور ماڈل دونوں کے لیے ورژن کنٹرول سسٹم کا ہونا ہے۔ اگرچہ AWS خدمات جیسے ایمیزون پہچان۔ انٹیگریٹڈ ورژن کنٹرول فیچر ہے، جو پائپ لائن کو لاگو کرنے کے لیے سیدھا بناتا ہے، اپنی مرضی کے مطابق ماڈلز کے لیے میٹا ڈیٹا لاگنگ یا اضافی ورژن کنٹرول ٹولز کی ضرورت ہوتی ہے۔
پورے ورک فلو کو استعمال کرتے ہوئے لاگو کیا جاتا ہے۔ AWS کلاؤڈ ڈویلپمنٹ کٹ (AWS CDK) ضروری AWS اجزاء بنانے کے لیے، بشمول درج ذیل:
- CodePipeline اور SageMaker ملازمتوں کے لیے دو کردار
- دو کوڈ پائپ لائن نوکریاں، جو ورک فلو کو منظم کرتی ہیں۔
- پائپ لائنوں کے کوڈ نمونے کے لیے دو S3 بالٹیاں
- جاب مینی فیسٹ، ڈیٹاسیٹس اور ماڈلز پر لیبل لگانے کے لیے ایک S3 بالٹی
- پری پروسیسنگ اور پوسٹ پروسیسنگ او ڈبلیو ایس لامبڈا۔ سیج میکر گراؤنڈ ٹروتھ لیبلنگ جابز کے لیے فنکشنز
AWS CDK سٹیکس انتہائی ماڈیولرائزڈ اور مختلف کاموں میں دوبارہ قابل استعمال ہیں۔ ٹریننگ، انفرنس کوڈ، اور سیج میکر گراؤنڈ ٹروتھ ٹیمپلیٹ کو کسی بھی اسی طرح کے فعال سیکھنے کے منظرناموں کے لیے تبدیل کیا جا سکتا ہے۔
ماڈل ٹریننگ
ماڈل ٹریننگ میں دو کام شامل ہیں: ہیڈ باؤنڈنگ باکس تشریح اور انسانی کلیدی نکات کی تشریح۔ ہم اس سیکشن میں ان دونوں کا تعارف کراتے ہیں۔
ہیڈ باؤنڈنگ باکس تشریح
ہیڈ باؤنڈنگ باکس تشریح ایک تصویر میں انسانی سر کے باؤنڈنگ باکس کے مقام کی پیش گوئی کرنے کا کام ہے۔ ہم ایک استعمال کرتے ہیں ایمیزون ریکگنیشن کسٹم لیبلز ہیڈ باؤنڈنگ باکس تشریحات کے لیے ماڈل۔ مندرجہ ذیل نمونہ نوٹ بک SageMaker کے ذریعے Recognition Custom Labels ماڈل کو کیسے تربیت دی جائے اس بارے میں مرحلہ وار ٹیوٹوریل فراہم کرتا ہے۔
ہمیں تربیت شروع کرنے کے لیے پہلے ڈیٹا تیار کرنے کی ضرورت ہے۔ ہم تربیت کے لیے ایک مینی فیسٹ فائل اور ٹیسٹ ڈیٹاسیٹ کے لیے ایک مینی فیسٹ فائل تیار کرتے ہیں۔ ایک مینی فیسٹ فائل میں متعدد آئٹمز ہوتے ہیں، جن میں سے ہر ایک تصویر کے لیے ہوتا ہے۔ مندرجہ ذیل مینی فیسٹ فائل کی ایک مثال ہے، جس میں تصویر کا راستہ، سائز، اور تشریح کی معلومات شامل ہیں:
مینی فیسٹ فائلوں کا استعمال کرتے ہوئے، ہم ڈیٹا سیٹس کو تربیت اور جانچ کے لیے Recognition Custom Labels ماڈل میں لوڈ کر سکتے ہیں۔ ہم نے مختلف مقدار میں تربیتی ڈیٹا کے ساتھ ماڈل کو دہرایا اور اسی 239 ان دیکھی تصاویر پر اس کا تجربہ کیا۔ اس ٹیسٹ میں، mAP_50 اسکور 0.33 تربیتی امیجز کے ساتھ 114 سے بڑھ کر 0.95 ٹریننگ امیجز کے ساتھ 957 ہو گیا۔ مندرجہ ذیل اسکرین شاٹ فائنل ریکوگنیشن کسٹم لیبلز ماڈل کی کارکردگی کے میٹرکس کو دکھاتا ہے، جو F1 سکور، درستگی، اور یاد کرنے کے لحاظ سے بہترین کارکردگی پیش کرتا ہے۔

ہم نے ماڈل کو روکے ہوئے ڈیٹاسیٹ پر مزید جانچا جس میں 1,128 تصاویر ہیں۔ یہ ماڈل مسلسل غیر دیکھے ہوئے ڈیٹا پر باؤنڈنگ باکس کی درست پیشین گوئیاں کرتا ہے، جس سے اعلیٰ حاصل ہوتا ہے۔ mAP_50 94.9 فیصد۔ مندرجہ ذیل مثال ہیڈ باؤنڈنگ باکس کے ساتھ ایک خودکار تشریح شدہ تصویر دکھاتی ہے۔

کلیدی نکات کی تشریح
کلیدی نکات کی تشریح کلیدی نکات کے مقامات پیدا کرتی ہے، بشمول آنکھیں، کان، ناک، منہ، گردن، کندھے، کہنیوں، کلائیاں، کولہے اور ٹخنے۔ مقام کی پیشین گوئی کے علاوہ، اس مخصوص کام میں پیشین گوئی کرنے کے لیے ہر نقطہ کی مرئیت کی ضرورت ہوتی ہے، جس کے لیے ہم ایک نیا طریقہ وضع کرتے ہیں۔
اہم نکات کی تشریح کے لیے، ہم استعمال کرتے ہیں a یولو 8 پوز ماڈل ابتدائی ماڈل کے طور پر سیج میکر پر۔ ہم سب سے پہلے تربیت کے لیے ڈیٹا تیار کرتے ہیں، بشمول لیبل فائلز اور کنفیگریشن .yaml فائل بنانے کے لیے یولو کی ضروریات کے مطابق۔ ڈیٹا تیار کرنے کے بعد، ہم ماڈل کو تربیت دیتے ہیں اور نمونے کو محفوظ کرتے ہیں، بشمول ماڈل وزن کی فائل۔ تربیت یافتہ ماڈل وزن کی فائل کے ساتھ، ہم نئی امیجز کی تشریح کر سکتے ہیں۔
تربیتی مرحلے میں، مقامات کے ساتھ لیبل لگائے گئے تمام پوائنٹس، بشمول مرئی پوائنٹس اور بند پوائنٹس، تربیت کے لیے استعمال کیے جاتے ہیں۔ لہذا، یہ ماڈل بطور ڈیفالٹ پیشین گوئی کا مقام اور اعتماد فراہم کرتا ہے۔ مندرجہ ذیل تصویر میں، 0.6 کے قریب ایک بڑی اعتماد کی حد (مین تھریشولڈ) ان پوائنٹس کو تقسیم کرنے کے قابل ہے جو کیمرے کے نقطہ نظر سے باہر نظر آتے ہیں یا بند ہیں۔ تاہم، پوشیدہ پوائنٹس اور مرئی پوائنٹس کو اعتماد سے الگ نہیں کیا جاتا ہے، جس کا مطلب ہے کہ پیش گوئی شدہ اعتماد مرئیت کی پیشین گوئی کے لیے مفید نہیں ہے۔

مرئیت کی پیشین گوئی حاصل کرنے کے لیے، ہم ڈیٹاسیٹ پر تربیت یافتہ ایک اضافی ماڈل متعارف کراتے ہیں جس میں صرف نظر آنے والے پوائنٹس پر مشتمل ہوتا ہے، جس میں مخدوش پوائنٹس اور کیمرے کے نقطہ نظر سے باہر دونوں کو چھوڑ کر۔ درج ذیل اعداد و شمار مختلف مرئیت کے ساتھ پوائنٹس کی تقسیم کو ظاہر کرتا ہے۔ اضافی ماڈل میں مرئی پوائنٹس اور دیگر پوائنٹس کو الگ کیا جا سکتا ہے۔ ہم مرئی پوائنٹس حاصل کرنے کے لیے 0.6 کے قریب ایک حد (اضافی حد) استعمال کر سکتے ہیں۔ ان دو ماڈلز کو ملا کر، ہم مقام اور مرئیت کا اندازہ لگانے کے لیے ایک طریقہ وضع کرتے ہیں۔

ایک اہم نکتہ کی پیشین گوئی پہلے مرکزی ماڈل کے ذریعہ محل وقوع اور اہم اعتماد کے ساتھ کی جاتی ہے، پھر ہمیں اضافی ماڈل سے اضافی اعتماد کی پیشین گوئی ملتی ہے۔ اس کے بعد اس کی مرئیت کی درجہ بندی اس طرح کی جاتی ہے:
- مرئی، اگر اس کا مرکزی اعتماد اس کی مرکزی حد سے زیادہ ہے، اور اس کا اضافی اعتماد اضافی حد سے زیادہ ہے
- روکا ہوا، اگر اس کا بنیادی اعتماد اس کی مرکزی حد سے زیادہ ہے، اور اس کا اضافی اعتماد اضافی حد سے کم یا اس کے برابر ہے
- کیمرے کے جائزے سے باہر، اگر دوسری صورت میں
کلیدی نکات کی تشریح کی ایک مثال مندرجہ ذیل تصویر میں دکھائی گئی ہے، جہاں ٹھوس نشانات نظر آنے والے پوائنٹس ہیں اور کھوکھلے نشانات مخفی پوائنٹس ہیں۔ کیمرے کے ریویو پوائنٹس کے باہر نہیں دکھائے گئے ہیں۔

معیار کی بنیاد پر۔ OKS MS-COCO ڈیٹاسیٹ پر تعریف، ہمارا طریقہ ان دیکھے ٹیسٹ ڈیٹاسیٹ پر 50% کا mAP_98.4 حاصل کرنے کے قابل ہے۔ مرئیت کے لحاظ سے، طریقہ ایک ہی ڈیٹا سیٹ پر 79.2% درجہ بندی کی درستگی حاصل کرتا ہے۔
انسانی لیبلنگ اور دوبارہ تربیت
اگرچہ ماڈلز ٹیسٹ ڈیٹا پر بہترین کارکردگی حاصل کرتے ہیں، پھر بھی نئے حقیقی دنیا کے ڈیٹا پر غلطیاں کرنے کے امکانات موجود ہیں۔ ہیومن لیبلنگ دوبارہ تربیت کا استعمال کرتے ہوئے ماڈل کی کارکردگی کو بڑھانے کے لیے ان غلطیوں کو درست کرنے کا عمل ہے۔ ہم نے ایک ججمنٹ فنکشن ڈیزائن کیا ہے جس میں اعتماد کی قدر کو ملایا گیا ہے جو تمام ہیڈ باؤنڈنگ باکس یا کلیدی پوائنٹس کے آؤٹ پٹ کے لیے ML ماڈلز سے نکلتی ہے۔ ہم ان غلطیوں اور اس کے نتیجے میں خراب لیبل والی تصاویر کی نشاندہی کرنے کے لیے حتمی اسکور کا استعمال کرتے ہیں، جنہیں انسانی لیبلنگ کے عمل میں بھیجنے کی ضرورت ہے۔
خراب لیبل والی تصاویر کے علاوہ، تصاویر کا ایک چھوٹا سا حصہ تصادفی طور پر انسانی لیبلنگ کے لیے منتخب کیا جاتا ہے۔ انسانی لیبل والی یہ تصاویر دوبارہ تربیت، ماڈل کی کارکردگی کو بڑھانے اور تشریح کی مجموعی درستگی کے لیے تربیتی سیٹ کے موجودہ ورژن میں شامل کی گئی ہیں۔
نفاذ میں، ہم سیج میکر گراؤنڈ ٹروتھ کا استعمال کرتے ہیں۔ انسانی لیبلنگ عمل سیج میکر گراؤنڈ ٹروتھ ڈیٹا لیبلنگ کے لیے صارف دوست اور بدیہی UI فراہم کرتا ہے۔ مندرجہ ذیل اسکرین شاٹ ہیڈ باؤنڈنگ باکس تشریح کے لیے سیج میکر گراؤنڈ ٹروتھ لیبلنگ جاب کو ظاہر کرتا ہے۔

مندرجہ ذیل اسکرین شاٹ کلیدی نکات کی تشریح کے لیے سیج میکر گراؤنڈ ٹروتھ لیبلنگ جاب کو ظاہر کرتا ہے۔

لاگت، رفتار، اور دوبارہ قابل استعمال
لاگت اور رفتار انسانی لیبلنگ کے مقابلے میں ہمارے حل کو استعمال کرنے کے اہم فوائد ہیں، جیسا کہ درج ذیل جدولوں میں دکھایا گیا ہے۔ ہم ان جدولوں کو لاگت کی بچت اور رفتار کی رفتار کو ظاہر کرنے کے لیے استعمال کرتے ہیں۔ تیز رفتار GPU SageMaker مثال کے طور پر ml.g4dn.xlarge کا استعمال کرتے ہوئے، 100,000 تصاویر پر پوری زندگی کی تربیت اور تخمینہ لاگت انسانی لیبلنگ کی لاگت سے 99% کم ہے، جبکہ رفتار انسانی لیبلنگ سے 10-10,000 گنا تیز ہے، اس پر منحصر ہے۔ کام
پہلا جدول لاگت کی کارکردگی کے میٹرکس کا خلاصہ کرتا ہے۔
| ماڈل | mAP_50 1,128 ٹیسٹ امیجز پر مبنی ہے۔ | 100,000 تصاویر پر مبنی تربیتی لاگت | 100,000 تصاویر پر مبنی تخمینہ لاگت | انسانی تشریح کے مقابلے لاگت میں کمی | 100,000 تصاویر پر مبنی انفرنس ٹائم | انسانی تشریح کے مقابلے میں وقت کی سرعت |
| شناخت ہیڈ باؤنڈنگ باکس | 0.949 | $4 | $22 | 99 فیصد کم | 5.5 H | دن |
| یولو کلیدی نکات | 0.984 | $27.20 | *$10 | 99.9 فیصد کم | منٹ | مہینے |
مندرجہ ذیل جدول کارکردگی کے میٹرکس کا خلاصہ کرتا ہے۔
| تشریح کا کام | mAP_50 (%) | تربیت کی لاگت ($) | تخمینہ لاگت ($) | انفرنس ٹائم |
| ہیڈ باؤنڈنگ باکس | 94.9 | 4 | 22 | 5.5 گھنٹے |
| اہم نکات | 98.4 | 27 | 10 | 5 منٹ |
مزید برآں، ہمارا حل اسی طرح کے کاموں کے لیے دوبارہ پریوست فراہم کرتا ہے۔ دوسرے سسٹمز جیسے ایڈوانس ڈرائیور اسسٹ سسٹم (ADAS) اور ان کیبن سسٹمز کے لیے کیمرہ پرسیپشن ڈیولپمنٹ بھی ہمارے حل کو اپنا سکتے ہیں۔
خلاصہ
اس پوسٹ میں، ہم نے AWS خدمات کا استعمال کرتے ہوئے ان کیبن امیجز کی خودکار تشریح کے لیے ایک فعال لرننگ پائپ لائن کیسے بنائی ہے۔ ہم ML کی طاقت کا مظاہرہ کرتے ہیں، جو آپ کو تشریح کے عمل کو خودکار اور تیز کرنے کے قابل بناتا ہے، اور اس فریم ورک کی لچک جو AWS سروسز کے ذریعے تعاون یافتہ یا SageMaker پر حسب ضرورت ماڈلز کا استعمال کرتا ہے۔ Amazon S3، SageMaker، Lambda، اور SageMaker Ground Truth کے ساتھ، آپ ڈیٹا اسٹوریج، تشریح، تربیت، اور تعیناتی کو ہموار کر سکتے ہیں، اور لاگت کو نمایاں طور پر کم کرتے ہوئے دوبارہ استعمال کی اہلیت حاصل کر سکتے ہیں۔ اس حل کو لاگو کرنے سے، آٹوموٹیو کمپنیاں ایم ایل پر مبنی اعلی درجے کے تجزیات جیسے کہ خودکار تصویری تشریح کا استعمال کر کے زیادہ چست اور سستی بن سکتی ہیں۔
آج ہی شروع کریں اور کی طاقت کو غیر مقفل کریں۔ AWS خدمات اور آپ کے آٹوموٹو ان کیبن سینسنگ کے استعمال کے کیسز کے لیے مشین لرننگ!
مصنفین کے بارے میں
 یانسیانگ یو ایمیزون جنریٹو اے آئی انوویشن سینٹر میں ایک اپلائیڈ سائنٹسٹ ہے۔ صنعتی ایپلی کیشنز کے لیے AI اور مشین لرننگ سلوشنز بنانے کے 9 سال سے زیادہ کے تجربے کے ساتھ، وہ جنریٹو AI، کمپیوٹر ویژن، اور ٹائم سیریز ماڈلنگ میں مہارت رکھتا ہے۔
یانسیانگ یو ایمیزون جنریٹو اے آئی انوویشن سینٹر میں ایک اپلائیڈ سائنٹسٹ ہے۔ صنعتی ایپلی کیشنز کے لیے AI اور مشین لرننگ سلوشنز بنانے کے 9 سال سے زیادہ کے تجربے کے ساتھ، وہ جنریٹو AI، کمپیوٹر ویژن، اور ٹائم سیریز ماڈلنگ میں مہارت رکھتا ہے۔
 تیانی ماؤ شکاگو کے علاقے میں مقیم AWS میں ایک اپلائیڈ سائنٹسٹ ہے۔ اس کے پاس مشین لرننگ اور ڈیپ لرننگ سلوشنز بنانے میں 5+ سال کا تجربہ ہے اور وہ انسانی فیڈ بیکس کے ساتھ کمپیوٹر ویژن اور کمک سیکھنے پر توجہ مرکوز کرتا ہے۔ وہ صارفین کے چیلنجوں کو سمجھنے اور AWS خدمات کا استعمال کرتے ہوئے اختراعی حل تیار کرکے ان کے حل کے لیے ان کے ساتھ کام کرنے سے لطف اندوز ہوتا ہے۔
تیانی ماؤ شکاگو کے علاقے میں مقیم AWS میں ایک اپلائیڈ سائنٹسٹ ہے۔ اس کے پاس مشین لرننگ اور ڈیپ لرننگ سلوشنز بنانے میں 5+ سال کا تجربہ ہے اور وہ انسانی فیڈ بیکس کے ساتھ کمپیوٹر ویژن اور کمک سیکھنے پر توجہ مرکوز کرتا ہے۔ وہ صارفین کے چیلنجوں کو سمجھنے اور AWS خدمات کا استعمال کرتے ہوئے اختراعی حل تیار کرکے ان کے حل کے لیے ان کے ساتھ کام کرنے سے لطف اندوز ہوتا ہے۔
 یانرو ژاؤ ایمیزون جنریٹو اے آئی انوویشن سینٹر میں ایک اپلائیڈ سائنٹسٹ ہے، جہاں وہ صارفین کے حقیقی دنیا کے کاروباری مسائل کے لیے AI/ML حل تیار کرتا ہے۔ انہوں نے مینوفیکچرنگ، توانائی اور زراعت سمیت کئی شعبوں میں کام کیا ہے۔ یانرو نے پی ایچ ڈی کی ڈگری حاصل کی۔ اولڈ ڈومینین یونیورسٹی سے کمپیوٹر سائنس میں۔
یانرو ژاؤ ایمیزون جنریٹو اے آئی انوویشن سینٹر میں ایک اپلائیڈ سائنٹسٹ ہے، جہاں وہ صارفین کے حقیقی دنیا کے کاروباری مسائل کے لیے AI/ML حل تیار کرتا ہے۔ انہوں نے مینوفیکچرنگ، توانائی اور زراعت سمیت کئی شعبوں میں کام کیا ہے۔ یانرو نے پی ایچ ڈی کی ڈگری حاصل کی۔ اولڈ ڈومینین یونیورسٹی سے کمپیوٹر سائنس میں۔
 پال جارج آٹوموٹیو ٹیکنالوجیز میں 15 سال سے زیادہ کا تجربہ رکھنے والا ایک قابل پروڈکٹ لیڈر ہے۔ وہ معروف پروڈکٹ مینجمنٹ، حکمت عملی، گو ٹو مارکیٹ اور سسٹم انجینئرنگ ٹیموں میں ماہر ہے۔ اس نے عالمی سطح پر کئی نئی سینسنگ اور پرسیپشن پروڈکٹس کو انکیوبیٹ اور لانچ کیا ہے۔ AWS میں، وہ خود مختار گاڑیوں کے کام کے بوجھ کے لیے حکمت عملی اور گو ٹو مارکیٹ کی قیادت کر رہا ہے۔
پال جارج آٹوموٹیو ٹیکنالوجیز میں 15 سال سے زیادہ کا تجربہ رکھنے والا ایک قابل پروڈکٹ لیڈر ہے۔ وہ معروف پروڈکٹ مینجمنٹ، حکمت عملی، گو ٹو مارکیٹ اور سسٹم انجینئرنگ ٹیموں میں ماہر ہے۔ اس نے عالمی سطح پر کئی نئی سینسنگ اور پرسیپشن پروڈکٹس کو انکیوبیٹ اور لانچ کیا ہے۔ AWS میں، وہ خود مختار گاڑیوں کے کام کے بوجھ کے لیے حکمت عملی اور گو ٹو مارکیٹ کی قیادت کر رہا ہے۔
 کیرولین چنگ Veoneer میں انجینئرنگ مینیجر ہے (Magna International کے ذریعے حاصل کیا گیا)، اس کے پاس سینسنگ اور پرسیپشن سسٹم تیار کرنے کا 14 سال سے زیادہ کا تجربہ ہے۔ وہ فی الحال میگنا انٹرنیشنل میں کمپیوٹ ویژن انجینئرز اور ڈیٹا سائنسدانوں کی ایک ٹیم کو منظم کرنے کے لیے انٹیریئر سینسنگ پری ڈیولپمنٹ پروگرامز کی قیادت کرتی ہیں۔
کیرولین چنگ Veoneer میں انجینئرنگ مینیجر ہے (Magna International کے ذریعے حاصل کیا گیا)، اس کے پاس سینسنگ اور پرسیپشن سسٹم تیار کرنے کا 14 سال سے زیادہ کا تجربہ ہے۔ وہ فی الحال میگنا انٹرنیشنل میں کمپیوٹ ویژن انجینئرز اور ڈیٹا سائنسدانوں کی ایک ٹیم کو منظم کرنے کے لیے انٹیریئر سینسنگ پری ڈیولپمنٹ پروگرامز کی قیادت کرتی ہیں۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/build-an-active-learning-pipeline-for-automatic-annotation-of-images-with-aws-services/

