اعداد و شمار کے دور میں، تنظیمیں وسیع پیمانے پر منظم اور غیر ساختہ ڈیٹا کو ذخیرہ کرنے اور تجزیہ کرنے کے لیے ڈیٹا لیکس کا استعمال کر رہی ہیں۔ ڈیٹا لیکس مختلف ذرائع سے ڈیٹا کے لیے ایک مرکزی ذخیرہ فراہم کرتی ہیں، جس سے تنظیموں کو قابل قدر بصیرت کو غیر مقفل کرنے اور ڈیٹا پر مبنی فیصلہ سازی کو آگے بڑھانے میں مدد ملتی ہے۔ تاہم، جیسے جیسے ڈیٹا کا حجم بڑھتا جا رہا ہے، ڈیٹا لے آؤٹ اور تنظیم کو بہتر بنانا موثر استفسار اور تجزیہ کے لیے اہم ہو جاتا ہے۔
ڈیٹا لیکس میں اہم چیلنجوں میں سے ایک سست استفسار کی کارکردگی کا امکان ہے، خاص طور پر جب بڑے ڈیٹا سیٹس سے نمٹ رہے ہوں۔ اس کی وجہ ڈیٹا کی ناکارہ ترتیب جیسے عوامل سے منسوب کیا جا سکتا ہے، جس کے نتیجے میں ڈیٹا کی ضرورت سے زیادہ اسکیننگ اور کمپیوٹ وسائل کا غیر موثر استعمال ہوتا ہے۔ اس چیلنج سے نمٹنے کے لیے، تقسیم کاری اور بکٹنگ جیسے عام طرز عمل استفسار کی کارکردگی کو نمایاں طور پر بہتر بنا سکتے ہیں اور حسابی اخراجات کو کم کر سکتے ہیں۔
تقسیم کرنا ایک ایسی تکنیک ہے جو کسی بڑے ڈیٹاسیٹ کو مخصوص معیارات، جیسے تاریخ، علاقہ یا پروڈکٹ کے زمرے کی بنیاد پر چھوٹے، زیادہ قابل انتظام حصوں میں تقسیم کرتی ہے۔ ڈیٹا کو تقسیم کرنے سے، نیچے کی طرف سے تجزیاتی سوالات غیر متعلقہ پارٹیشنز کو چھوڑ سکتے ہیں، جس سے ڈیٹا کی مقدار کو کم کیا جا سکتا ہے جسے اسکین اور پروسیس کرنے کی ضرورت ہے۔ آپ سوالات میں WHERE شق میں پارٹیشن کالم استعمال کر سکتے ہیں صرف ان مخصوص پارٹیشنز کو اسکین کرنے کے لیے جن کی آپ کے استفسار کی ضرورت ہے۔ یہ تیز تر استفسار کے رن ٹائمز اور وسائل کے زیادہ موثر استعمال کا باعث بن سکتا ہے۔ یہ خاص طور پر اس وقت اچھا کام کرتا ہے جب کم کارڈینیلیٹی والے کالم کو کلید کے طور پر منتخب کیا جاتا ہے۔
کیا ہوگا اگر آپ کے پاس ایک اعلی کارڈینیلیٹی کالم ہے جسے آپ کو بعض اوقات VIP صارفین کے ذریعہ فلٹر کرنے کی ضرورت ہوتی ہے؟ ہر صارف کی شناخت عام طور پر ایک ID سے کی جاتی ہے، جو لاکھوں میں ہو سکتی ہے۔ پارٹیشننگ ایسے ہائی کارڈینیلیٹی کالمز کے لیے موزوں نہیں ہے کیونکہ آپ چھوٹی فائلوں، سست پارٹیشن فلٹرنگ، اور اعلی ایمیزون سادہ اسٹوریج سروس (ایمیزون S3) API لاگت (ایک S3 سابقہ تقسیم کالم کی قیمت کے مطابق بنایا گیا ہے)۔ اگرچہ آپ اپنے ڈیٹاسیٹ کو کچھ حد تک محدود کرنے کے لیے قدرتی کلید جیسے شہر یا ریاست کے ساتھ پارٹیشننگ کا استعمال کر سکتے ہیں، پھر بھی اگر آپ کا ڈیٹا ٹائم سیریز ہے تو تاریخ پر مبنی پارٹیشنز میں استفسار کرنا ضروری ہے۔
یہ کہاں ہے بالٹی کھیل میں آتا ہے. بکٹنگ اس بات کو یقینی بناتی ہے کہ ایک یا زیادہ کالموں کی ایک جیسی قدروں والی تمام قطاریں ایک ہی فائل میں ختم ہوں۔ ایک فائل فی ویلیو کے بجائے، پارٹیشننگ کی طرح، ایک ہیش فنکشن فائلوں کی ایک مقررہ تعداد میں قدروں کو یکساں طور پر تقسیم کرنے کے لیے استعمال کیا جاتا ہے۔ ڈیٹا کو اس طرح ترتیب دینے سے، آپ موثر فلٹرنگ انجام دے سکتے ہیں، کیونکہ صرف متعلقہ بالٹیوں کو ہی پروسیس کرنے کی ضرورت ہے، جس سے کمپیوٹیشنل اوور ہیڈ کو مزید کم کیا جا سکتا ہے۔
AWS پر بکٹنگ لاگو کرنے کے متعدد اختیارات ہیں۔ ایک طریقہ استعمال کرنا ہے۔ ایمیزون ایتینا SELECT (CTAS) اسٹیٹمنٹ کے طور پر ٹیبل بنائیں، جو آپ کو ایک سوال سے براہ راست بالٹیڈ ٹیبل بنانے کی اجازت دیتا ہے۔ متبادل طور پر، آپ استعمال کر سکتے ہیں AWS گلو اپاچی اسپارک کے لیے، جو ڈیٹا ٹرانسفارمیشن کے عمل کے دوران بکٹنگ کنفیگریشنز کے لیے بلٹ ان سپورٹ فراہم کرتا ہے۔ AWS Glue آپ کو بکٹنگ کے پیرامیٹرز کی وضاحت کرنے کی اجازت دیتا ہے، جیسے کہ بالٹیوں کی تعداد اور بالٹی آن کرنے کے لیے کالم، ایتھینا کے ساتھ موثر استفسار کے لیے ایک بہتر ڈیٹا لے آؤٹ فراہم کرتا ہے۔
اس پوسٹ میں، ہم AWS ڈیٹا لیکس پر بکٹنگ کو لاگو کرنے کے طریقہ پر تبادلہ خیال کرتے ہیں، بشمول Apache Spark کے لیے Athena CTAS سٹیٹمنٹ اور AWS Glue کا استعمال۔ ہم اپاچی آئس برگ ٹیبلز کے لیے بکٹنگ کا بھی احاطہ کرتے ہیں۔
مثال استعمال کیس
اس پوسٹ میں، آپ ایک عوامی ڈیٹاسیٹ استعمال کرتے ہیں۔ NOAA انٹیگریٹڈ سرفیس ڈیٹا بیس. ڈیٹا تجزیہ کار ایتھینا کے ذریعے پچھلے 5 سالوں کے دوران ڈیٹا کے لیے ایک بار کے سوالات چلاتے ہیں۔ زیادہ تر سوالات مخصوص رپورٹ کی اقسام کے ساتھ مخصوص اسٹیشنوں کے لیے ہیں۔ سوالات کو 10 سیکنڈ میں مکمل کرنے کی ضرورت ہے، اور لاگت کو احتیاط سے بہتر بنانے کی ضرورت ہے۔ اس منظر نامے میں، آپ ایک ڈیٹا انجینئر ہیں جو استفسار کی کارکردگی اور لاگت کو بہتر بنانے کے ذمہ دار ہیں۔
مثال کے طور پر، اگر کوئی تجزیہ کار کسی مخصوص اسٹیشن کے لیے ڈیٹا بازیافت کرنا چاہتا ہے (مثال کے طور پر، اسٹیشن ID 123456) ایک خاص قسم کی رپورٹ کے ساتھ (مثال کے طور پر، CRN01)، استفسار درج ذیل سوال کی طرح نظر آ سکتا ہے:
NOAA انٹیگریٹڈ سرفیس ڈیٹا بیس کے معاملے میں، station_id متعدد منفرد اسٹیشن شناخت کنندگان کے ساتھ، کالم میں ایک اعلی کارڈنلٹی ہونے کا امکان ہے۔ دوسری طرف، the report_type کالم میں نسبتاً کم کارڈنلٹی ہو سکتی ہے، رپورٹ کی اقسام کے محدود سیٹ کے ساتھ۔ اس منظر نامے کو دیکھتے ہوئے، ڈیٹا کو تقسیم کرنا ایک اچھا خیال ہوگا۔ report_type اور اس کی طرف سے بالٹی station_id.
اس تقسیم اور بکٹنگ حکمت عملی کے ساتھ، ایتھینا پہلے غیر متعلقہ رپورٹ کی قسموں کے لیے پارٹیشنز کو ختم کر سکتی ہے، اور پھر متعلقہ پارٹیشن کے اندر صرف ان بالٹیوں کو سکین کر سکتی ہے جو مخصوص سٹیشن ID سے مماثل ہو، جس سے ڈیٹا پر عملدرآمد کی مقدار میں نمایاں کمی ہو اور استفسار کے رن ٹائمز کو تیز کیا جا سکے۔ یہ نقطہ نظر نہ صرف استفسار کی کارکردگی کی ضرورت کو پورا کرتا ہے، بلکہ ہر استفسار کے لیے اسکین کیے گئے اور بل کیے گئے ڈیٹا کی مقدار کو کم سے کم کرکے لاگت کو بہتر بنانے میں بھی مدد کرتا ہے۔
اس پوسٹ میں، ہم جائزہ لیتے ہیں کہ ڈیٹا لے آؤٹ، خاص طور پر، بکٹنگ سے کس طرح استفسار کی کارکردگی متاثر ہوتی ہے۔ ہم بکٹنگ حاصل کرنے کے تین مختلف طریقوں کا بھی موازنہ کرتے ہیں۔ مندرجہ ذیل جدول ٹیبل بنانے کے لیے حالات کی نمائندگی کرتا ہے۔
| . | noaa_remote_original | athena_non_bucketed | athena_bucketed | glue_bucketed | athena_bucketed_iceberg |
| فارمیٹ | CSV | چھڑی | چھڑی | چھڑی | چھڑی |
| سمپیڑن | N / A | پرسکون | پرسکون | پرسکون | پرسکون |
| کے ذریعے تخلیق کیا گیا۔ | N / A | ایتھینا سی ٹی اے ایس | ایتھینا سی ٹی اے ایس | گلو ای ٹی ایل | آئس برگ کے ساتھ ایتھینا سی ٹی اے ایس |
| انجن | N / A | ٹریل | ٹریل | اپاچی چمک | اپاچی آئس برگ |
| تقسیم کیا ہے؟ | ہاں لیکن مختلف طریقے سے | جی ہاں | جی ہاں | جی ہاں | جی ہاں |
| بالٹی ہے؟ | نہیں | نہیں | جی ہاں | جی ہاں | جی ہاں |
noaa_remote_original کے ذریعہ تقسیم کیا گیا ہے۔ year کالم، لیکن کی طرف سے نہیں report_type کالم یہ قطار اس بات کی نمائندگی کرتی ہے کہ آیا جدول کو اصل کالموں کے ذریعہ تقسیم کیا گیا ہے جو سوالات میں استعمال ہوتے ہیں۔
بیس لائن ٹیبل
اس پوسٹ کے لیے، آپ مختلف شرائط کے ساتھ کئی جدولیں بناتے ہیں: کچھ بکٹنگ کے بغیر اور کچھ بکٹنگ کے ساتھ، تاکہ بکٹنگ کی کارکردگی کی خصوصیات کو ظاہر کیا جا سکے۔ سب سے پہلے، آئیے NOAA ڈیٹا کا استعمال کرتے ہوئے ایک اصل ٹیبل بنائیں۔ بعد کے مراحل میں، آپ ٹیسٹ ٹیبل بنانے کے لیے اس ٹیبل سے ڈیٹا اکٹھا کرتے ہیں۔
ٹیبل کی تعریف کو متعین کرنے کے متعدد طریقے ہیں: DDL چلانا، AWS Glue کرالر، AWS Glue Data Catalog API، وغیرہ۔ اس مرحلے میں، آپ ایتھینا کنسول کے ذریعے ڈی ڈی ایل چلاتے ہیں۔
بنانے کے لیے درج ذیل مراحل کو مکمل کریں۔ "bucketing_blog"."noaa_remote_original" ڈیٹا کیٹلاگ میں ٹیبل:
- ایتھینا کنسول کھولیں۔
- استفسار ایڈیٹر میں، ایک نیا AWS Glue ڈیٹا بیس بنانے کے لیے درج ذیل DDL چلائیں:
- کے لئے ڈیٹا بیس کے تحت ڈیٹامنتخب کریں
bucketing_blogموجودہ ڈیٹا بیس کو ترتیب دینے کے لیے۔ - اصل ٹیبل بنانے کے لیے درج ذیل ڈی ڈی ایل کو چلائیں:
چونکہ ماخذ ڈیٹا نے فیلڈز کا حوالہ دیا ہے، ہم استعمال کرتے ہیں۔ OpenCSVSerde پہلے سے طے شدہ کے بجائے LazySimpleSerde.
ان CSV فائلوں میں ایک ہیڈر قطار ہے، جسے ہم ایتھینا سے کہتے ہیں کہ وہ شامل کر کے اسے چھوڑ دیں۔ skip.header.line.count اور قدر کو 1 پر سیٹ کریں۔
مزید تفصیلات کے لئے ملاحظہ کریں CSV پر کارروائی کے لیے OpenCSVSerDe.
- پارٹیشنز کو شامل کرنے کے لیے درج ذیل ڈی ڈی ایل کو چلائیں۔ ہم استعمال کیس کی ضرورت کی بنیاد پر 5 سالوں میں سے صرف 124 سالوں کے لیے پارٹیشنز جوڑتے ہیں:
- اس بات کی تصدیق کرنے کے لیے درج ذیل DML چلائیں کہ آیا آپ ڈیٹا سے کامیابی کے ساتھ استفسار کر سکتے ہیں:
اب آپ بیس لائن کی کارکردگی کو جانچنے کے لیے اصل جدول سے استفسار کرنے کے لیے تیار ہیں۔
- استفسار کی کارکردگی کو بیس لائن کے طور پر جانچنے کے لیے اصل ٹیبل کے خلاف ایک استفسار چلائیں۔ درج ذیل استفسار رپورٹ کی قسم کے ساتھ پانچ مخصوص اسٹیشنوں کے لیے ریکارڈ کا انتخاب کرتا ہے۔
CRN05: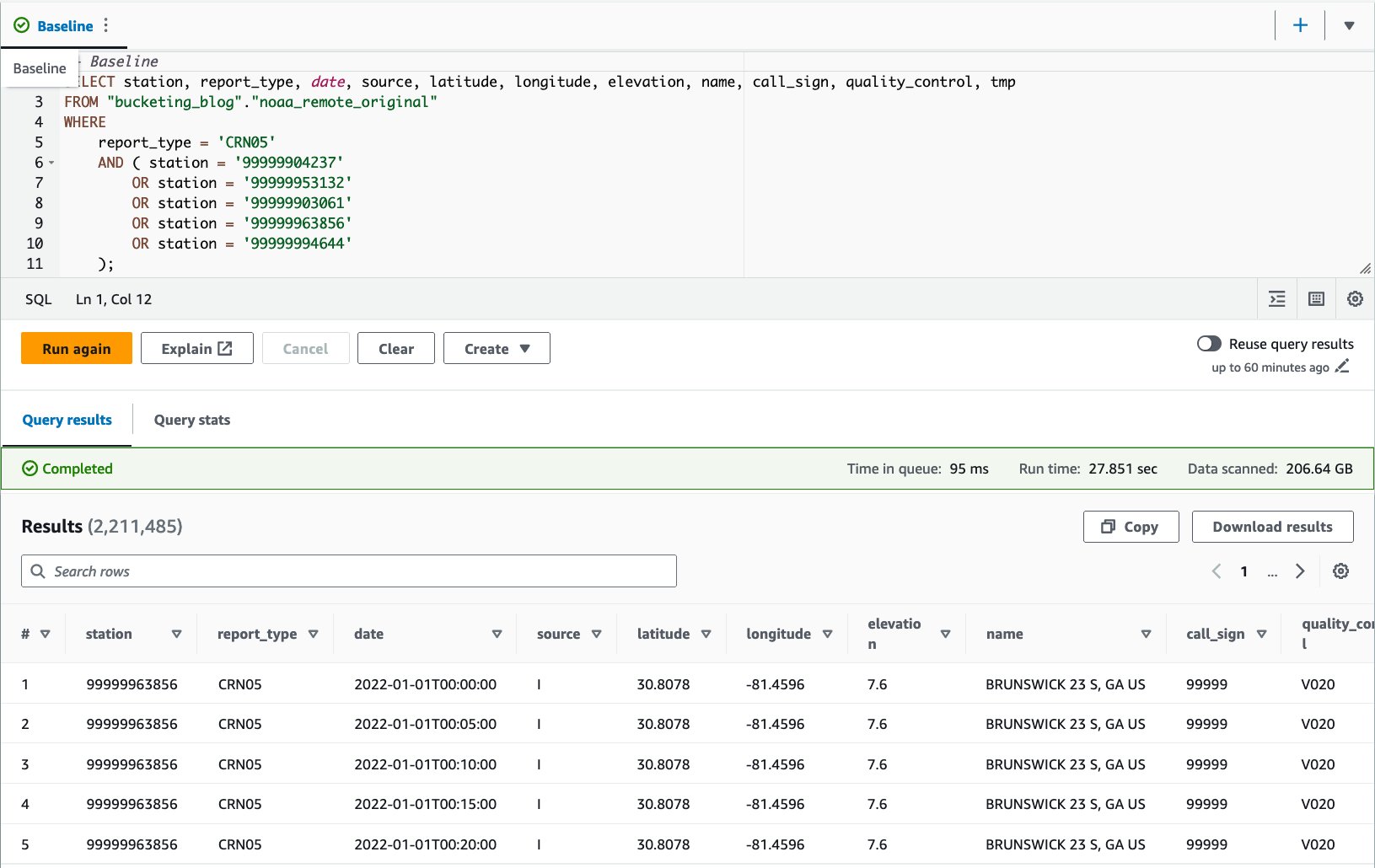
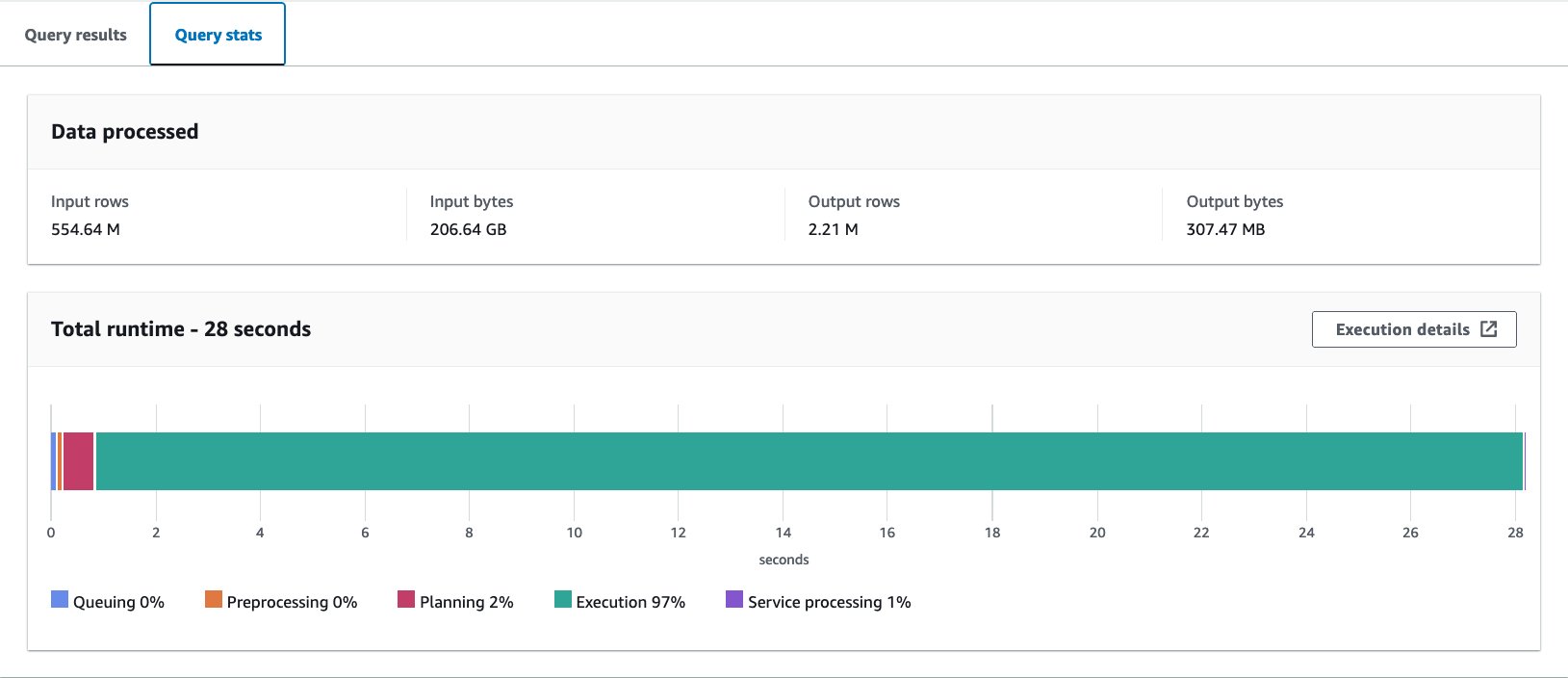
ہم نے اس سوال کو 10 بار چلایا۔ 10 سوالات کے لیے اوسط استفسار کا رن ٹائم 27.6 سیکنڈ ہے، جو کہ ہمارے ہدف 10 سیکنڈ سے کہیں زیادہ ہے، اور 155.75 ملین ریکارڈ واپس کرنے کے لیے 1.65 GB ڈیٹا اسکین کیا جاتا ہے۔ یہ اصل خام میز کی بنیادی کارکردگی ہے۔ اس بیس لائن سے ڈیٹا لے آؤٹ کو بہتر بنانا شروع کرنے کا وقت آگیا ہے۔
اس کے بعد، آپ اصل سے مختلف حالتوں کے ساتھ ٹیبل بناتے ہیں: ایک بغیر بالٹی کے اور ایک بکٹنگ کے ساتھ، اور ان کا موازنہ کریں۔
ایتھینا سی ٹی اے ایس کا استعمال کرتے ہوئے ڈیٹا لے آؤٹ کو بہتر بنائیں
اس سیکشن میں، ہم ڈیٹا لے آؤٹ اور اس کی شکل کو بہتر بنانے کے لیے Athena CTAS استفسار کا استعمال کرتے ہیں۔
سب سے پہلے، آئیے تقسیم کے ساتھ لیکن بالٹی کے بغیر ایک ٹیبل بنائیں۔ نئی جدول کو کالم کے حساب سے تقسیم کیا گیا ہے۔ report_type کیونکہ زیادہ تر متوقع سوالات اس کالم کو WHERE شق میں استعمال کرتے ہیں، اور اشیاء کو Snappy کمپریشن کے ساتھ Parquet کے طور پر محفوظ کیا جاتا ہے۔
- ایتھینا استفسار ایڈیٹر کھولیں۔
- اپنا S3 بالٹی اور سابقہ فراہم کرتے ہوئے درج ذیل استفسار کو چلائیں:
آپ کا ڈیٹا درج ذیل اسکرین شاٹس کی طرح نظر آنا چاہیے۔
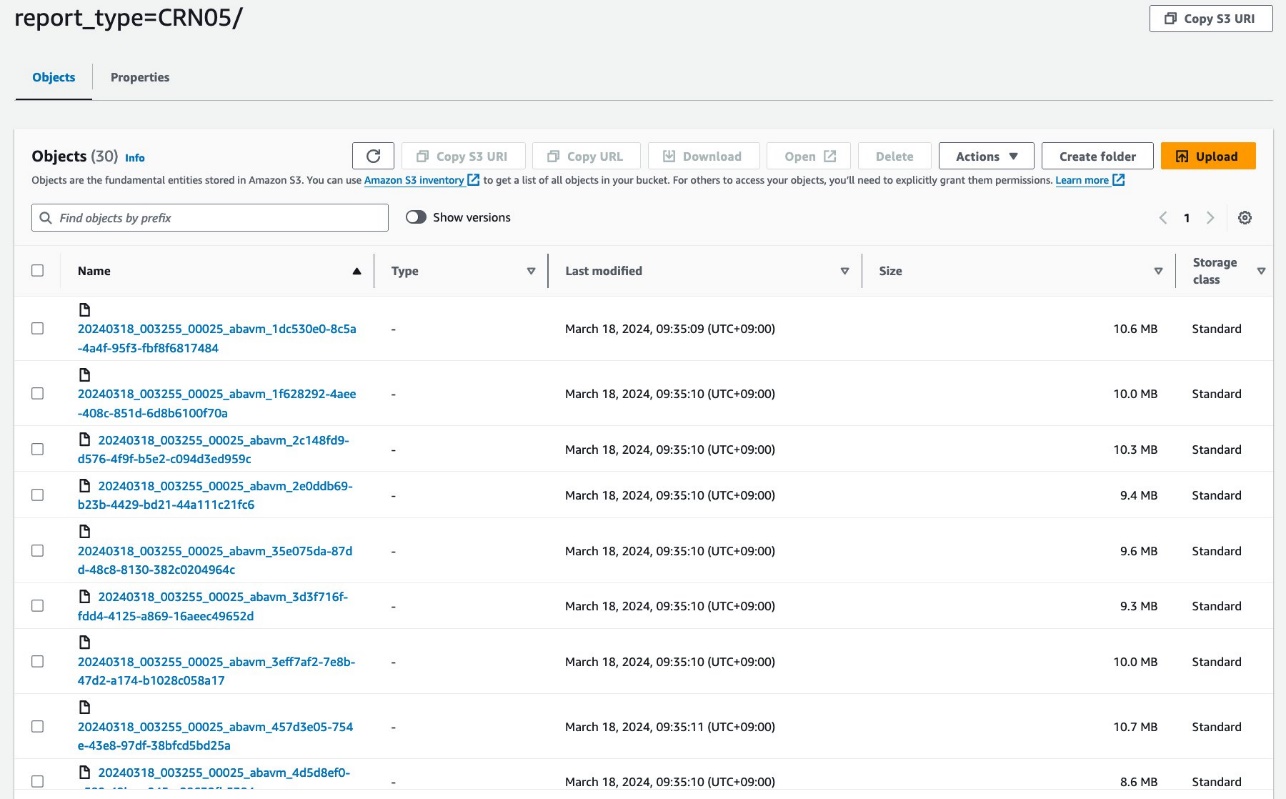
پارٹیشن کے نیچے 30 فائلیں ہیں۔
اگلا، آپ Hive سٹائل بکٹنگ کے ساتھ ایک ٹیبل بناتے ہیں۔ بالٹیوں کی تعداد کو آپ کے اپنے استعمال کے کیس کے لیے تجربات کے ذریعے احتیاط سے ترتیب دینے کی ضرورت ہے۔ عام طور پر، آپ کے پاس جتنی زیادہ بالٹیاں ہوں گی، گرانولریٹی اتنی ہی چھوٹی ہوگی، جس کا نتیجہ بہتر کارکردگی کا باعث بن سکتا ہے۔ دوسری طرف، بہت سی چھوٹی فائلیں استفسار کی منصوبہ بندی اور پروسیسنگ میں غیر موثریت کو متعارف کروا سکتی ہیں۔ اس کے علاوہ، بکٹنگ صرف اس صورت میں کام کرتی ہے جب آپ بکٹنگ کلید کی چند اقدار سے استفسار کر رہے ہوں۔ آپ اپنے استفسار میں جتنی زیادہ قدریں شامل کریں گے، اتنا ہی زیادہ امکان ہے کہ آپ تمام بالٹیاں پڑھ لیں گے۔
اصلاح کے لیے بنیادی سوال درج ذیل ہے:
اس مثال میں، میز کو 16 بالٹیوں میں ایک ہائی کارڈینیلیٹی کالم کے ذریعے بِکٹ کیا جائے گا (station)، جسے استفسار میں WHERE شق کے لیے استعمال کیا جانا ہے۔ باقی تمام شرائط وہی رہیں۔ اسٹیشن آئی ڈی میں بیس لائن استفسار کی پانچ اقدار ہیں، اور آپ توقع کرتے ہیں کہ سوالات زیادہ سے زیادہ اس نمبر کے قریب ہوں گے، جو کہ بالٹیوں کی تعداد سے کافی کم ہے، اس لیے 16 کو اچھی طرح کام کرنا چاہیے۔ بالٹیوں کی ایک بڑی تعداد کی وضاحت کرنا ممکن ہے، لیکن اگر پارٹیشنز کی کل تعداد 100 سے زیادہ ہو تو CTAS استعمال نہیں کیا جا سکتا۔
- درج ذیل استفسار کو چلائیں:
استفسار S3 آبجیکٹ کو ترتیب دیتا ہے جیسا کہ درج ذیل اسکرین شاٹس میں دکھایا گیا ہے۔
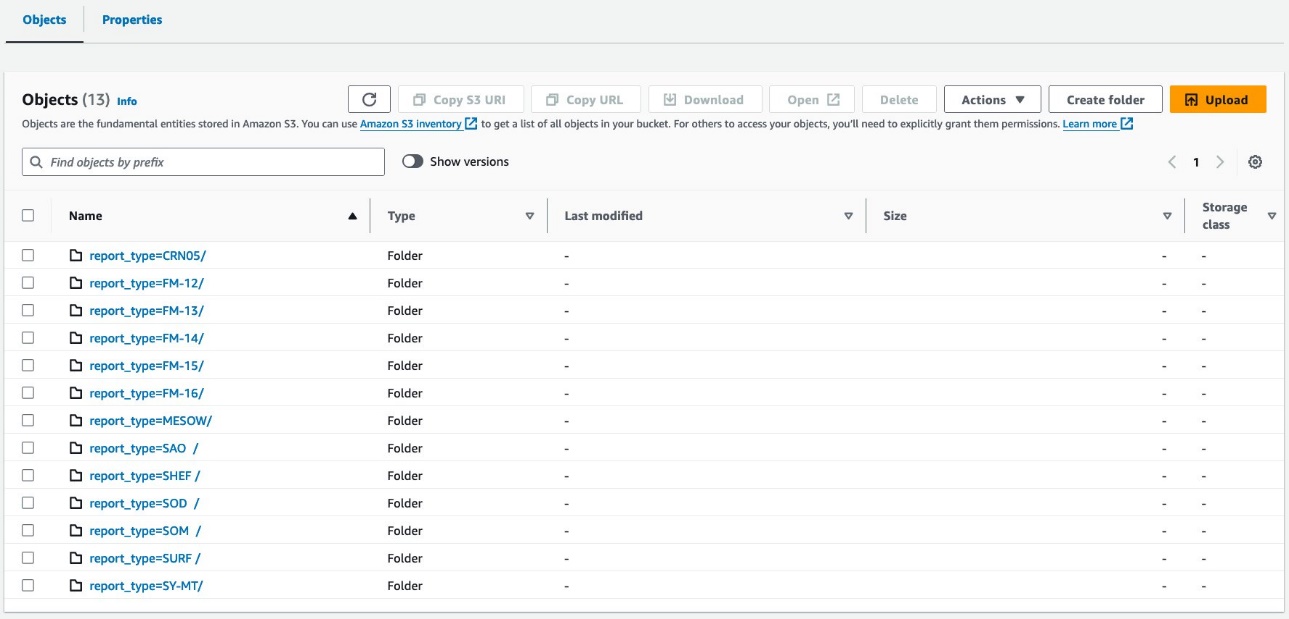

ٹیبل لیول کی ترتیب بالکل اسی کے درمیان نظر آتی ہے۔ athena_non_bucketed اور athena_bucketed: ہر ٹیبل میں 13 پارٹیشنز ہیں۔ فرق پارٹیشنز کے نیچے اشیاء کی تعداد ہے۔ ہر پارٹیشن میں 16 آبجیکٹ (بالٹیاں) ہیں، اس معاملے میں تقریباً 10-25 MB ہر ایک۔ ڈیٹا کی مقدار سے قطع نظر بالٹیوں کی تعداد مخصوص قیمت پر مستقل رہتی ہے، لیکن بالٹی کا سائز ڈیٹا کی مقدار پر منحصر ہوتا ہے۔
اب آپ استفسار کی کارکردگی کا جائزہ لینے کے لیے ہر ٹیبل کے خلاف استفسار کرنے کے لیے تیار ہیں۔ استفسار پانچ مخصوص اسٹیشنوں اور رپورٹ کی قسم کے ساتھ ریکارڈ کا انتخاب کرے گا۔ CRN05 گزشتہ 5 سالوں سے. اگرچہ آپ یہ نہیں دیکھ سکتے کہ کسی مخصوص اسٹیشن کا کون سا ڈیٹا کس بالٹی میں واقع ہے، لیکن ایتھینا نے اس کا حساب لگایا اور درست طریقے سے واقع کیا ہے۔
- درج ذیل بیان کے ساتھ غیر بالٹی والے ٹیبل سے استفسار کریں:

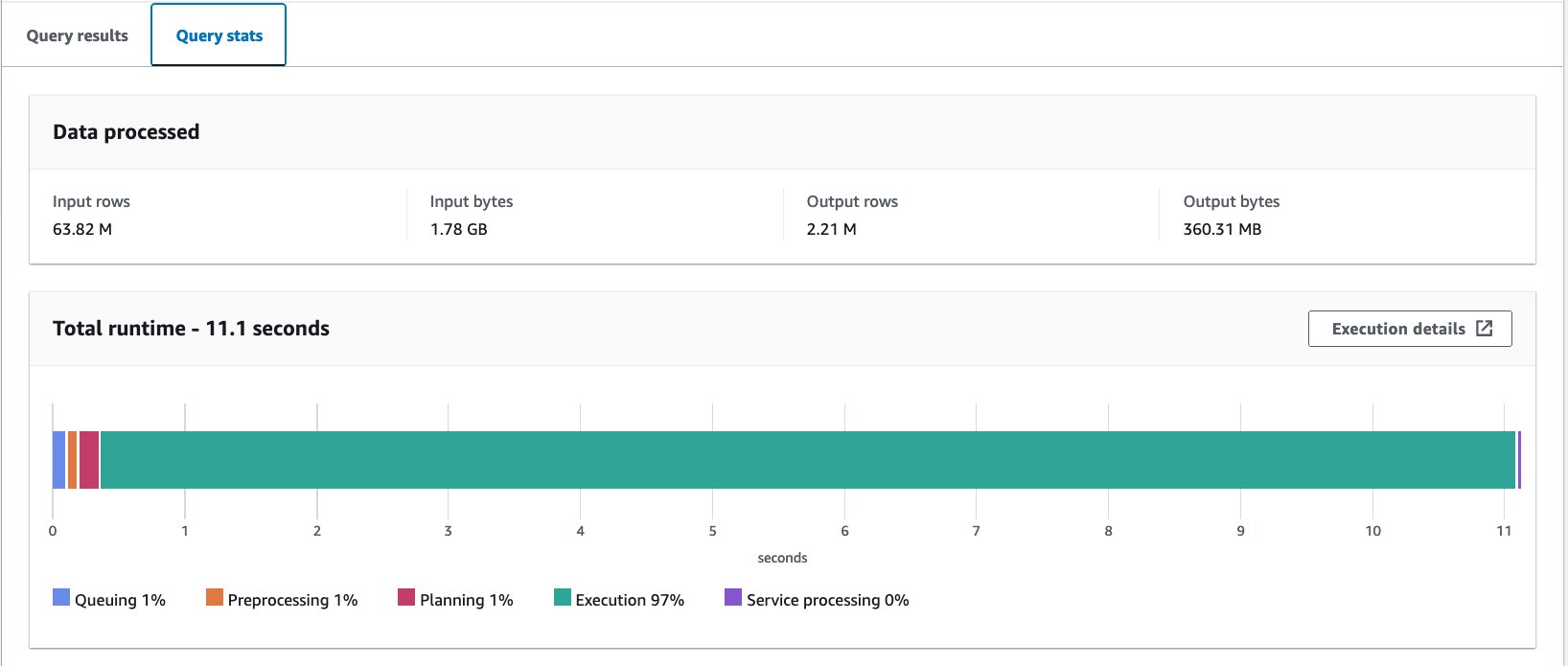
ہم نے اس سوال کو 10 بار چلایا۔ 10 سوالات کا اوسط رن ٹائم 10.95 سیکنڈ ہے، اور 358 ملین ریکارڈ واپس کرنے کے لیے 2.21 MB ڈیٹا اسکین کیا جاتا ہے۔ رن ٹائم اور اسکین سائز دونوں میں نمایاں کمی آئی ہے کیونکہ آپ نے ڈیٹا کو تقسیم کر دیا ہے، اور اب صرف ایک پارٹیشن پڑھ سکتے ہیں جہاں 12 میں سے 13 پارٹیشنز کو چھوڑ دیا گیا ہے۔ اس کے علاوہ اسکین کیے گئے ڈیٹا کی مقدار 206 جی بی سے کم ہو کر 360 ایم بی رہ گئی ہے جو کہ 99.8 فیصد کی کمی ہے۔ یہ صرف تقسیم کی وجہ سے نہیں ہے، بلکہ اس کے فارمیٹ کو Parquet میں تبدیل کرنے اور Snappy کے ساتھ کمپریشن کی وجہ سے بھی ہے۔
- درج ذیل بیان کے ساتھ بالٹی والے ٹیبل سے استفسار کریں:
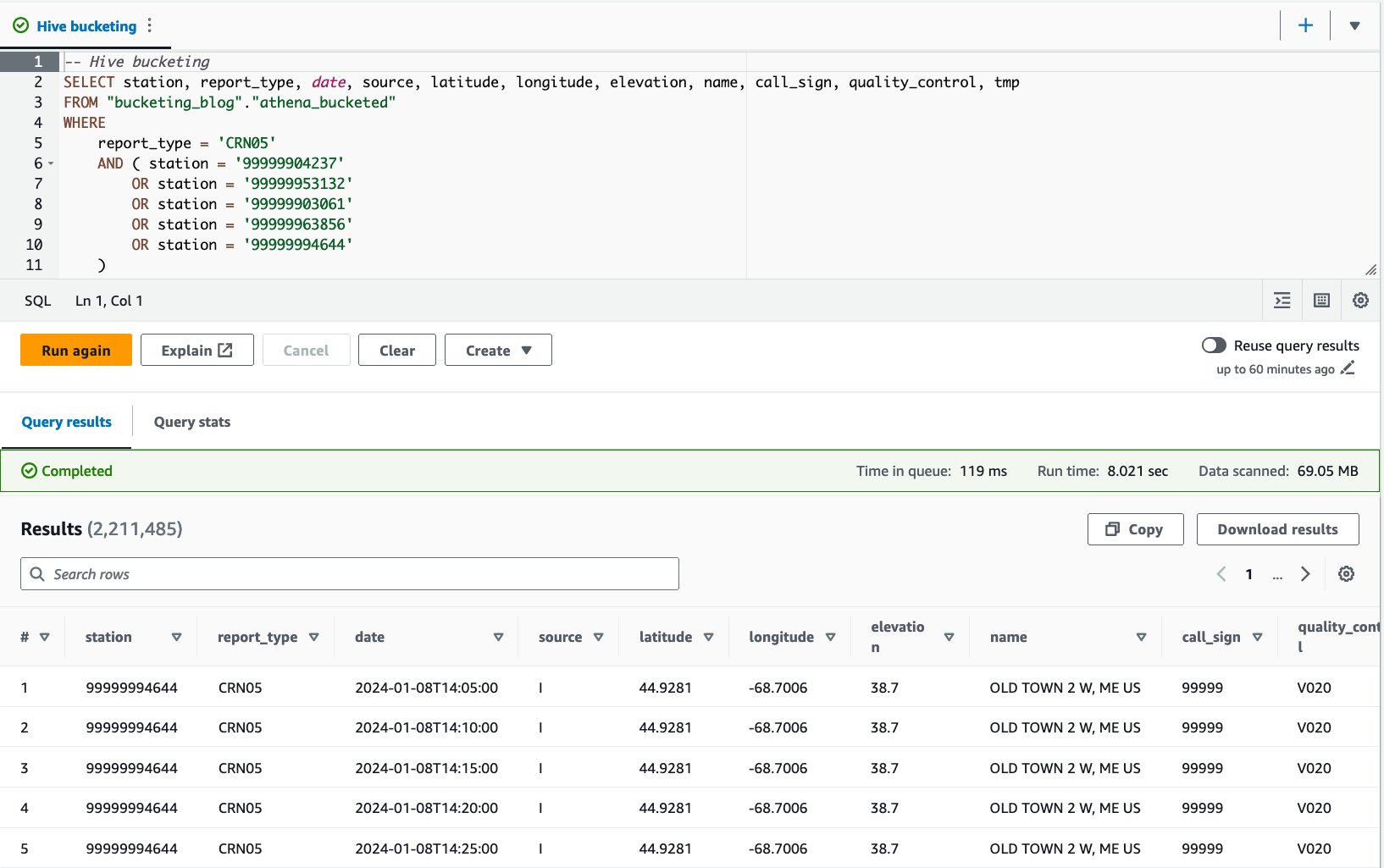
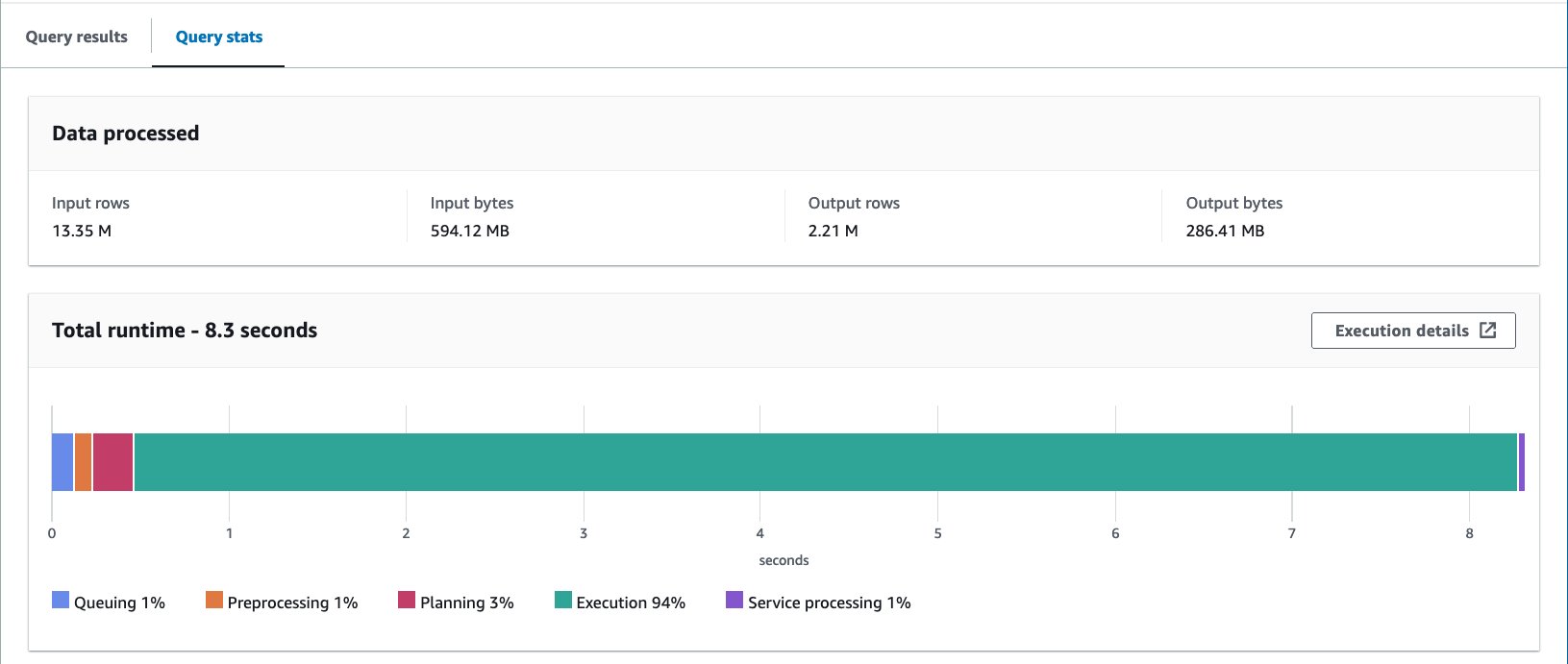
ہم نے اس سوال کو 10 بار چلایا۔ 10 سوالات کا اوسط رن ٹائم 7.82 سیکنڈ ہے، اور 69 ملین ریکارڈ واپس کرنے کے لیے 2.21 MB ڈیٹا اسکین کیا جاتا ہے۔ اس کا مطلب ہے اوسط رن ٹائم میں 10.95 سے 7.82 سیکنڈز (-29%) کی کمی، اور 358 MB سے 69 MB (-81%) تک اسکین کیے گئے ڈیٹا کی ڈرامائی کمی ہے تاکہ نان بکٹڈ ٹیبل کے مقابلے میں ریکارڈ کی اتنی ہی تعداد میں واپس آ سکے۔ . اس صورت میں، رن ٹائم اور اسکین کردہ ڈیٹا دونوں کو بکیٹنگ کے ذریعے بہتر بنایا گیا تھا۔ اس کا مطلب ہے کہ بالٹی لگانے سے نہ صرف کارکردگی بلکہ لاگت میں بھی کمی آئی۔
خیال
جیسا کہ پہلے بتایا گیا ہے، اپنے استفسار کی کارکردگی کو زیادہ سے زیادہ کرنے کے لیے اپنی بالٹی کو احتیاط سے سائز کریں۔ بکٹنگ صرف اس صورت میں کام کرتی ہے جب آپ بکٹنگ کلید کی چند اقدار کے بارے میں استفسار کر رہے ہوں۔ اصل استفسار میں متوقع قدروں کی تعداد سے زیادہ بالٹیاں بنانے پر غور کریں۔
مزید برآں، ایک Athena CTAS استفسار ایک وقت میں 100 پارٹیشنز بنانے تک محدود ہے۔ اگر آپ کو بڑی تعداد میں پارٹیشنز کی ضرورت ہو تو، آپ AWS Glue extract، transform and load (ETL) استعمال کرنا چاہیں گے، حالانکہ وہاں ایک ایک سے زیادہ ایس کیو ایل بیانات میں تقسیم کرنے کا حل.
AWS Glue ETL کا استعمال کرتے ہوئے ڈیٹا لے آؤٹ کو بہتر بنائیں
Apache Spark ایک کھلا ذریعہ تقسیم شدہ پروسیسنگ فریم ورک ہے جو PySpark، Scala، اور Spark SQL کے ساتھ لچکدار ETL کو قابل بناتا ہے۔ یہ آپ کو اپنی ضروریات کی بنیاد پر اپنے ڈیٹا کو تقسیم اور بالٹی کرنے کی اجازت دیتا ہے۔ اسپارک کے پاس ملازمتوں کو تیز کرنے کے لیے کئی ٹیوننگ آپشنز ہیں۔ آپ آسانی سے اسپارک جابز کو خودکار اور مانیٹر کر سکتے ہیں۔ اس سیکشن میں، ہم ڈیٹا لے آؤٹ کو بہتر بنانے کے لیے اسپارک کوڈ کو چلانے کے لیے AWS Glue ETL جابز کا استعمال کرتے ہیں۔
ایتھینا بکٹنگ کے برعکس، AWS Glue ETL اسپارک پر مبنی بکٹنگ کو بکٹنگ الگورتھم کے طور پر استعمال کرتا ہے۔ آپ کو صرف مندرجہ ذیل ٹیبل پراپرٹی کو ٹیبل پر شامل کرنے کی ضرورت ہے: bucketing_format = 'spark'. اس ٹیبل پراپرٹی کے بارے میں تفصیلات کے لیے دیکھیں ایتھینا میں تقسیم اور بالٹی بنانا.
AWS Glue ETL کے ذریعے بکٹنگ کے ساتھ ٹیبل بنانے کے لیے درج ذیل مراحل کو مکمل کریں:
- AWS Glue کنسول پر، منتخب کریں۔ ETL نوکریاں نیوی گیشن پین میں.
- میں سے انتخاب کریں نوکری پیدا کریں۔ اور منتخب کریں بصری ای ٹی ایل.
- کے تحت نوڈس شامل کریں۔منتخب کریں AWS گلو ڈیٹا کیٹلاگ لیے ذرائع.
- کے لئے ڈیٹا بیسمنتخب کریں
bucketing_blog. - کے لئے ٹیبلمنتخب کریں
noaa_remote_original. - کے تحت نوڈس شامل کریں۔منتخب کریں اسکیما کو تبدیل کریں۔ لیے تبدیلیاں.
- کے تحت نوڈس شامل کریں۔منتخب کریں کسٹم ٹرانسفارم لیے تبدیلیاں.
- کے لئے نام، داخل کریں
ToS3WithBucketing. - کے لئے نوڈ والدینمنتخب کریں اسکیما کو تبدیل کریں۔.
- کے لئے کوڈ بلاکدرج ذیل کوڈ کا ٹکڑا درج کریں:
مندرجہ ذیل اسکرین شاٹ میں AWS Glue Studio کا استعمال کرتے ہوئے ٹیبل اور ڈیٹا بنانے کے لیے بنائی گئی جاب کو دکھایا گیا ہے۔
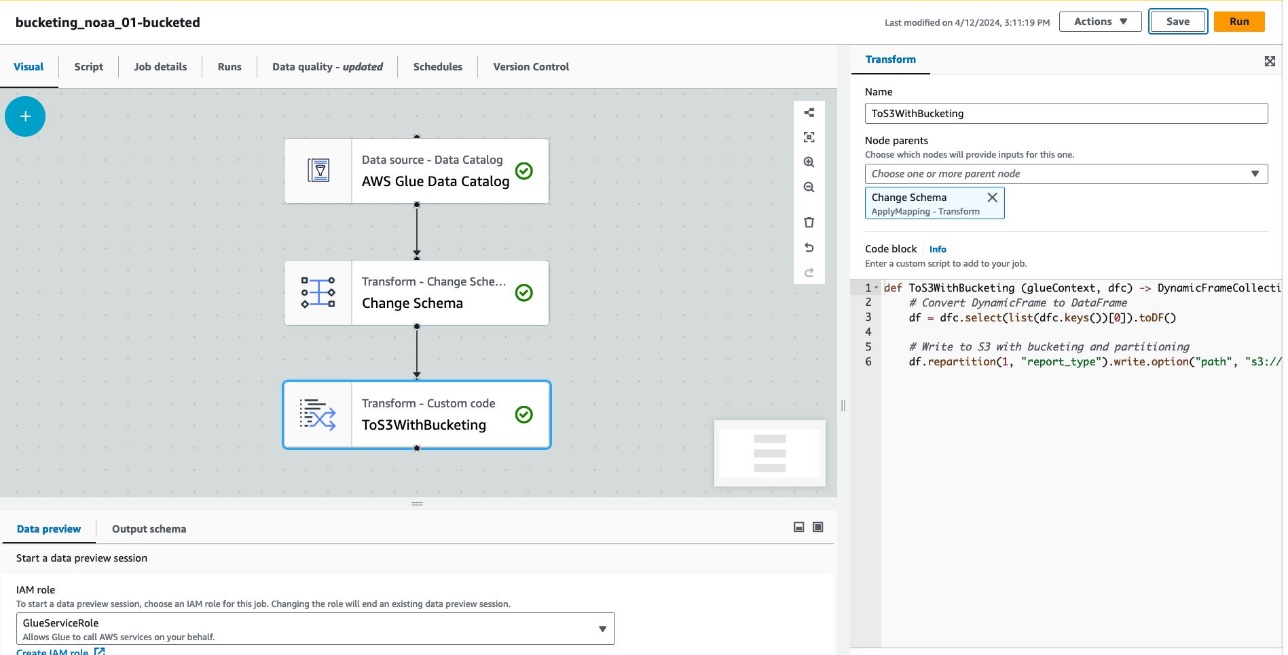
ہر نوڈ درج ذیل کی نمائندگی کرتا ہے:
- ۔ AWS گلو ڈیٹا کیٹلاگ نوڈ لوڈ کرتا ہے۔
noaa_remote_originalڈیٹا کیٹلاگ سے ٹیبل - ۔ اسکیما کو تبدیل کریں۔ نوڈ اس بات کو یقینی بناتا ہے کہ یہ ڈیٹا کیٹلاگ میں رجسٹرڈ کالموں کو لوڈ کرتا ہے۔
- ۔ ToS3WithBucketing نوڈ پارٹیشننگ اور اسپارک بیسڈ بکٹنگ دونوں کے ساتھ ایمیزون S3 کو ڈیٹا لکھتا ہے۔
یہ کام بصری ایڈیٹر میں کامیابی کے ساتھ لکھا گیا ہے۔
- کے تحت ملازمت کی تفصیلات، کے لئے آئی اے ایم کا کردار، اپنا چنو AWS شناخت اور رسائی کا انتظام اس کام کے لیے (IAM) کا کردار۔
- کے لئے ورکر کی قسممنتخب کریں G.8X.
- کے لئے کارکنوں کی تعداد طلب کی۔، 5 درج کریں۔
- میں سے انتخاب کریں محفوظ کریں، پھر منتخب کریں رن.
ان اقدامات کے بعد، میز glue_bucketed. بنا دیا گیا ہے.
- میں سے انتخاب کریں میزیں نیویگیشن پین میں، اور ٹیبل کا انتخاب کریں۔
glue_bucketed. - پر عوامل مینو، منتخب کریں ٹیبل میں ترمیم کریں۔ کے تحت انتظام کریں.
- میں ٹیبل کی خصوصیات سیکشن کا انتخاب کریں، شامل کریں.
- کلید کے ساتھ کلیدی جوڑا شامل کریں۔
bucketing_formatاور قدر کی چنگاری۔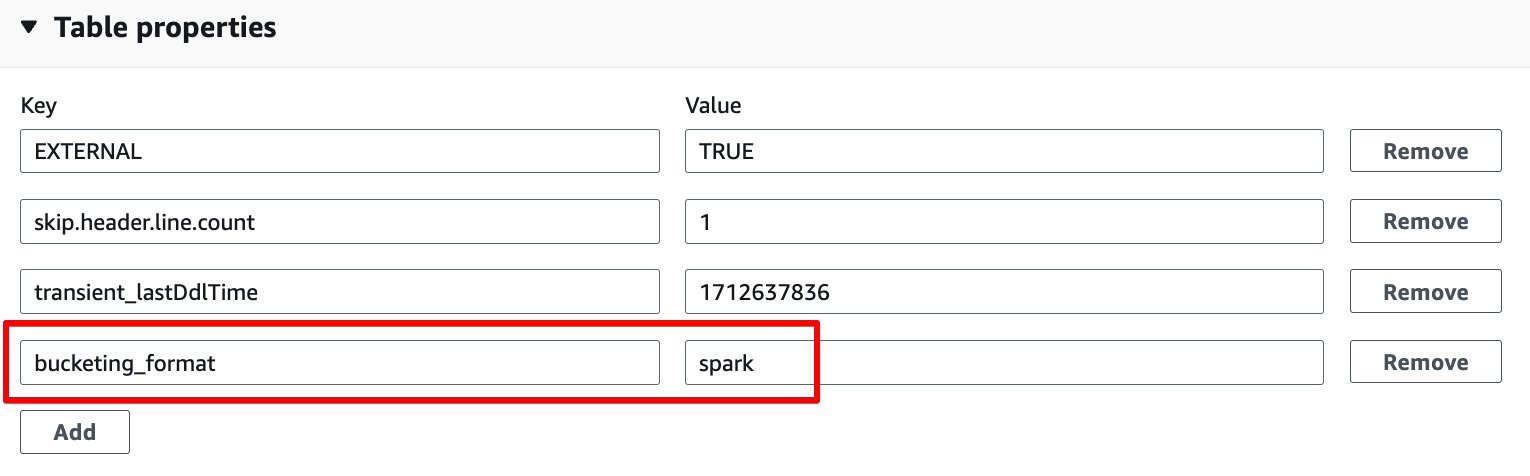
- میں سے انتخاب کریں محفوظ کریں.
اب میزوں سے استفسار کرنے کا وقت آگیا ہے۔
- درج ذیل بیان کے ساتھ بالٹی والے ٹیبل سے استفسار کریں:

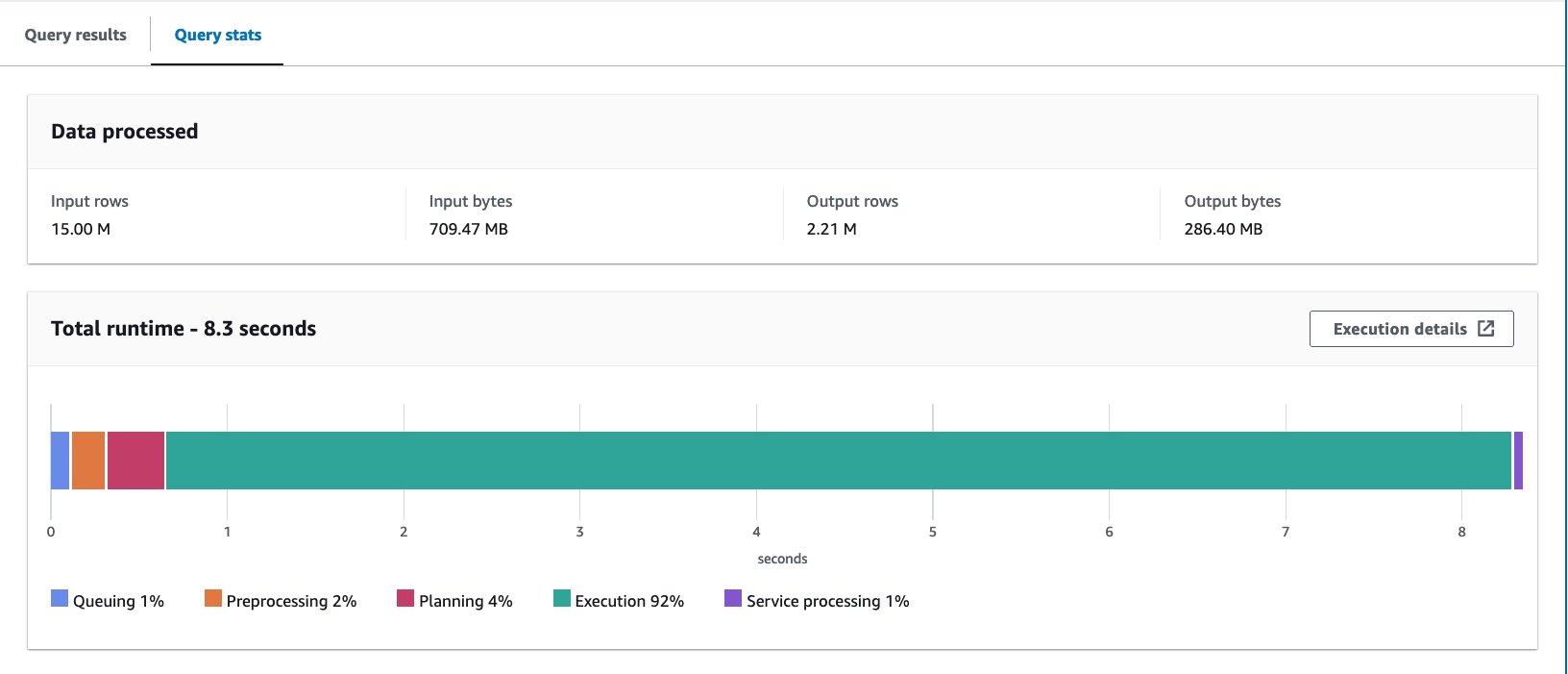
ہم نے 10 بار استفسار کیا۔ 10 سوالات کا اوسط رن ٹائم 7.09 سیکنڈ ہے، اور 88 ملین ریکارڈ واپس کرنے کے لیے 2.21 MB ڈیٹا اسکین کیا جاتا ہے۔ اس صورت میں، رن ٹائم اور اسکین کردہ ڈیٹا دونوں کو بکیٹنگ کے ذریعے بہتر بنایا گیا تھا۔ اس کا مطلب ہے کہ بالٹی لگانے سے نہ صرف کارکردگی بلکہ لاگت میں بھی کمی آئی۔
Athena CTAS مثال کے مقابلے میں اسکین کیے گئے بڑے بائٹس کی وجہ یہ ہے کہ اس ٹیبل میں اقدار کو مختلف طریقے سے تقسیم کیا گیا تھا۔ AWS Glue بالٹیڈ ٹیبل میں، اقدار کو پانچ فائلوں پر تقسیم کیا گیا تھا۔ Athena CTAS بالٹی ٹیبل میں، اقدار کو چار فائلوں پر تقسیم کیا گیا تھا۔ یاد رکھیں کہ قطاروں کو ہیش فنکشن کا استعمال کرتے ہوئے بالٹی میں تقسیم کیا جاتا ہے۔ اسپارک بکٹنگ الگورتھم Hive سے مختلف ہیش فنکشن کا استعمال کرتا ہے، اور اس صورت میں، اس کے نتیجے میں فائلوں میں مختلف تقسیم ہوتی ہے۔
خیال
گلو ڈائنامک فریم مقامی طور پر بکٹنگ کی حمایت نہیں کرتا ہے۔ آپ کو بالٹی ٹیبل کے لیے ڈائنامک فریم کے بجائے اسپارک ڈیٹا فریم استعمال کرنے کی ضرورت ہے۔
فائن ٹیوننگ AWS Glue ETL کی کارکردگی کے بارے میں معلومات کے لیے، رجوع کریں۔ Apache Spark جابز کے لیے AWS Glue کی کارکردگی کو بہتر بنانے کے بہترین طریقے.
پوشیدہ تقسیم کے ساتھ آئس برگ ڈیٹا لے آؤٹ کو بہتر بنائیں
Apache Iceberg بڑی تجزیاتی میزوں کے لیے ایک اعلیٰ کارکردگی والا اوپن ٹیبل فارمیٹ ہے، جو بڑے ڈیٹا میں SQL ٹیبلز کی وشوسنییتا اور سادگی کو لاتا ہے۔ حال ہی میں، ACID ٹرانزیکشن، ٹائم ٹریول کے سوال، اور بہت کچھ جیسی اعلیٰ صلاحیتوں کو حاصل کرنے کے لیے اپاچی آئس برگ ٹیبلز کو استعمال کرنے کی بہت زیادہ مانگ کی گئی ہے۔
آئس برگ میں، بکٹنگ Hive ٹیبل طریقہ سے مختلف طریقے سے کام کرتی ہے جو ہم نے اب تک دیکھا ہے۔ آئس برگ میں، بکٹنگ پارٹیشننگ کا ایک ذیلی سیٹ ہے، اور اسے بالٹی پارٹیشن ٹرانسفارم کا استعمال کرتے ہوئے لاگو کیا جا سکتا ہے۔ جس طرح سے آپ اسے استعمال کرتے ہیں اور حتمی نتیجہ Hive ٹیبلز میں بکٹنگ کے مترادف ہے۔ آئس برگ بالٹی ٹرانسفارمز کے بارے میں مزید تفصیلات کے لیے رجوع کریں۔ بالٹی ٹرانسفارم کی تفصیلات.
درج ذیل مراحل کو مکمل کریں:
- ایتھینا استفسار ایڈیٹر کھولیں۔
- بکٹنگ کے ساتھ پوشیدہ تقسیم کے ساتھ آئس برگ ٹیبل بنانے کے لیے درج ذیل استفسار کو چلائیں:
آپ کا ڈیٹا درج ذیل اسکرین شاٹ کی طرح نظر آنا چاہیے۔

دو فولڈر ہیں: data اور metadata. تک ڈرل ڈاؤن data.
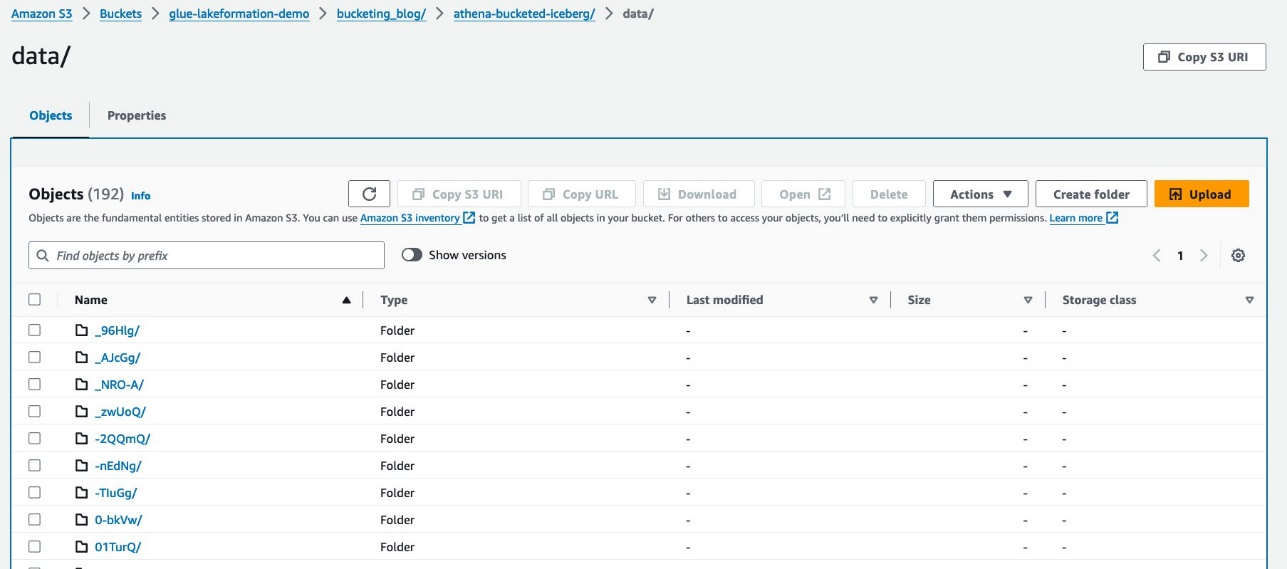
آپ کو کے تحت بے ترتیب سابقے نظر آتے ہیں۔ data فولڈر اس کی تفصیلات دیکھنے کے لیے پہلے کا انتخاب کریں۔
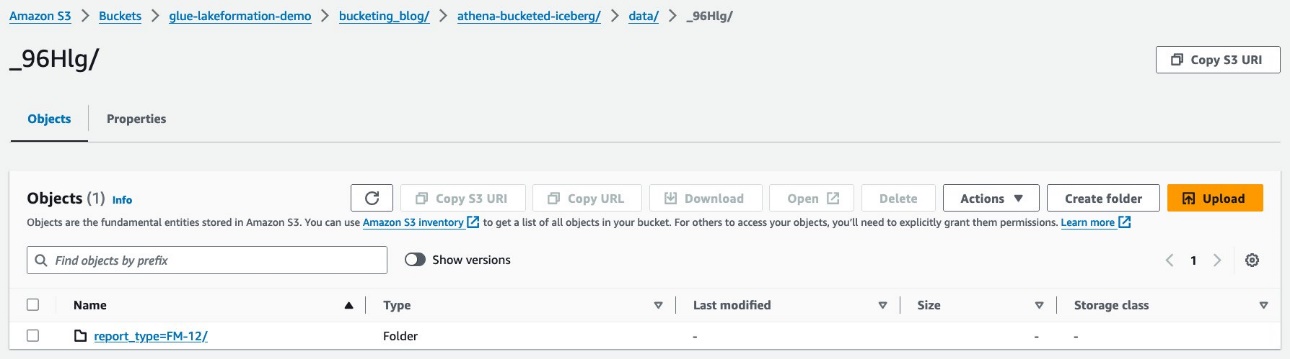
آپ کو اوپر کی سطح کی تقسیم نظر آتی ہے۔ report_type کالم اگلی سطح تک ڈرل ڈاؤن کریں۔

آپ کو دوسرے درجے کی تقسیم نظر آتی ہے، جس کے ساتھ بالٹی بنی ہوئی ہے۔ station کالم.
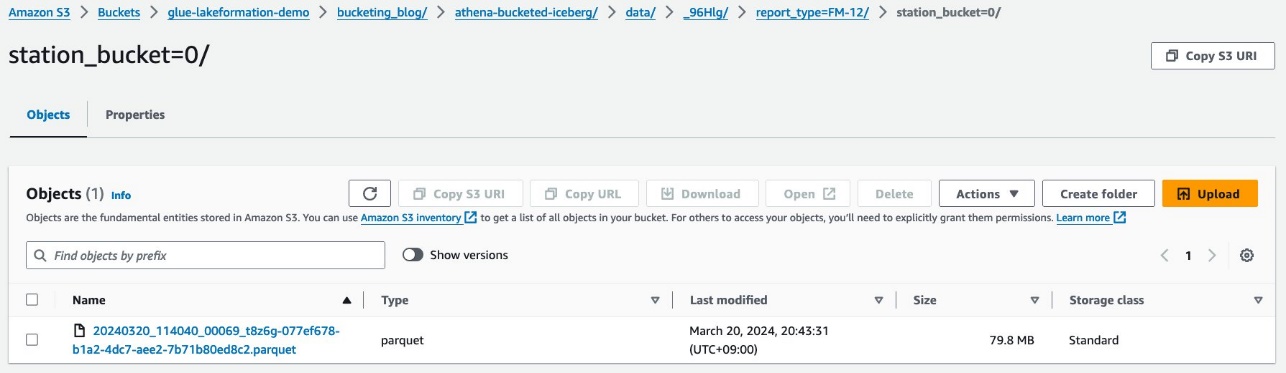
پارکیٹ ڈیٹا فائلیں ان فولڈرز کے نیچے موجود ہیں۔
- درج ذیل بیان کے ساتھ بالٹی والے ٹیبل سے استفسار کریں:
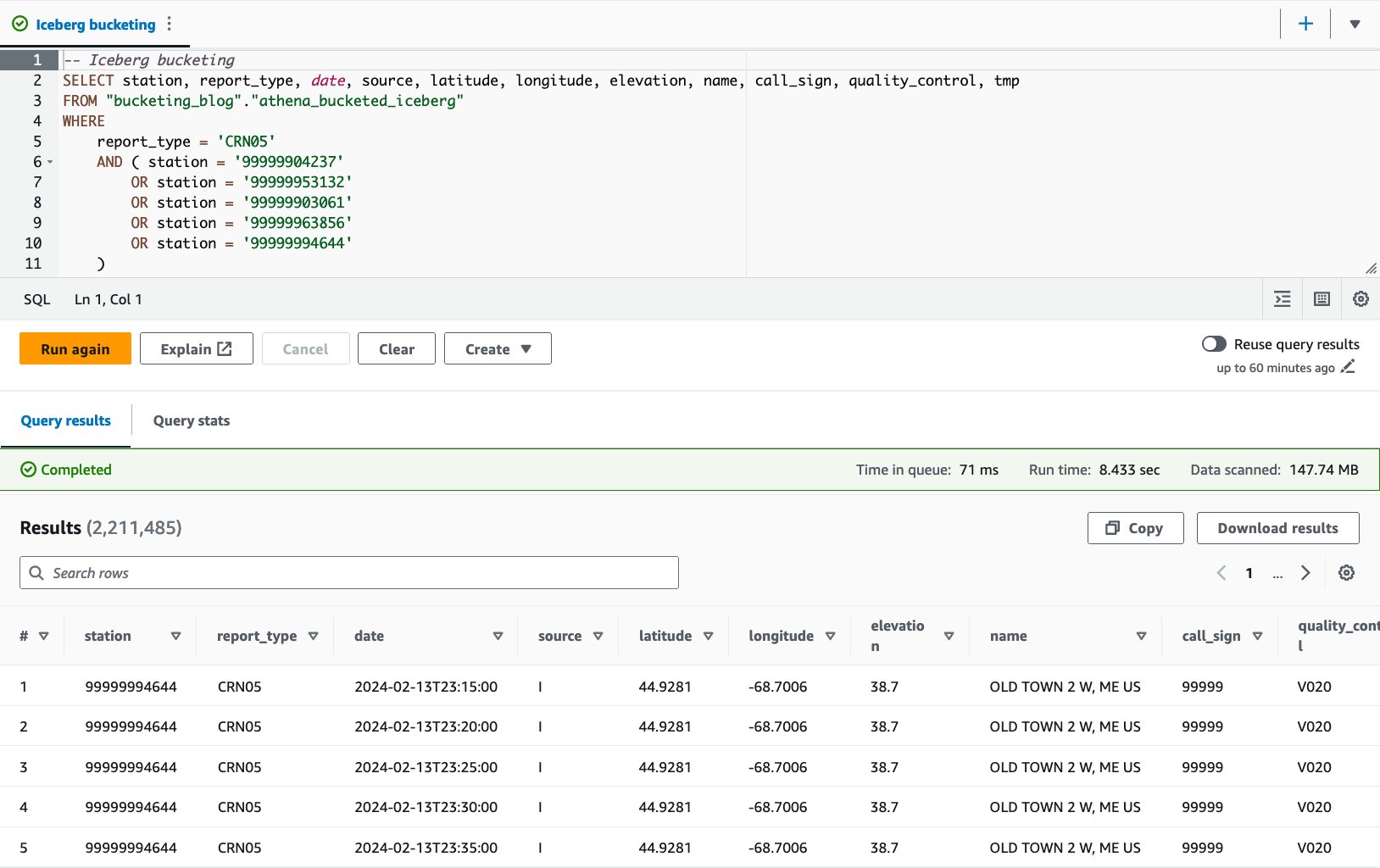
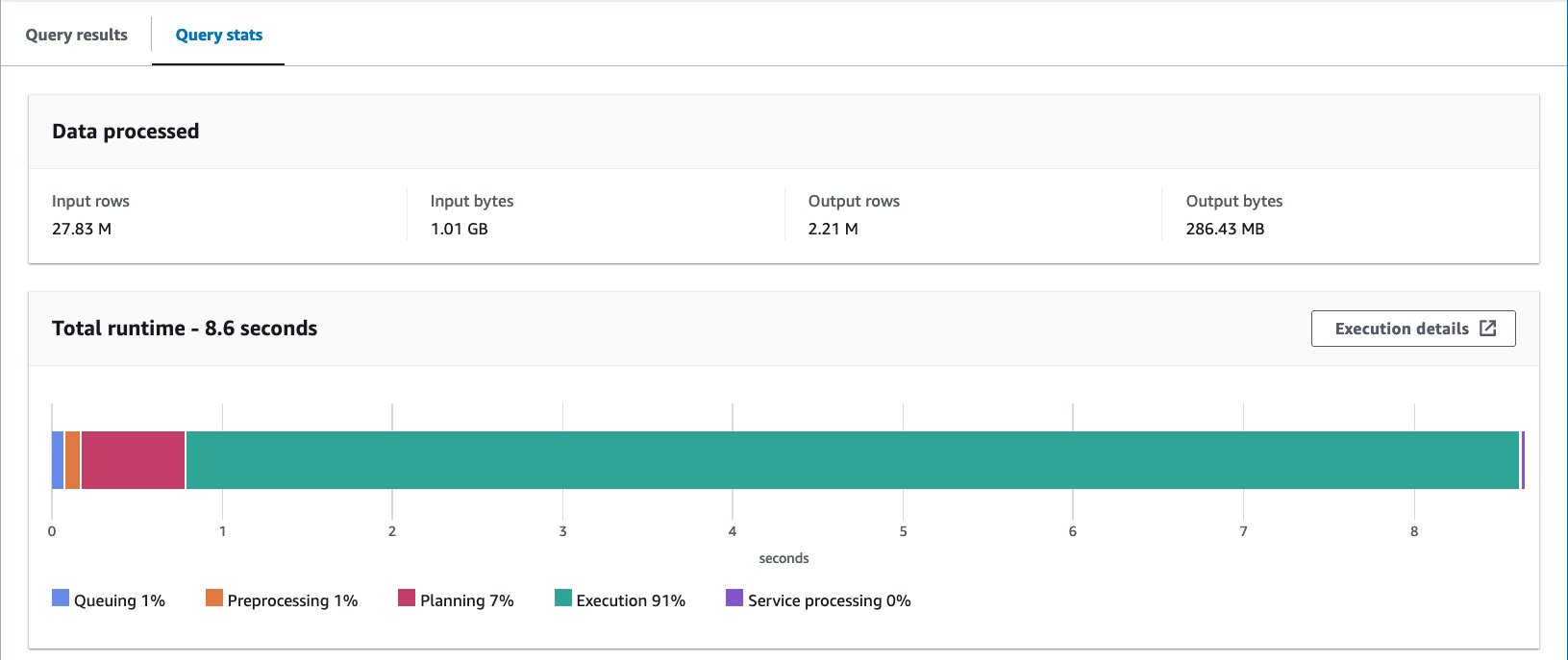
آئس برگ بکیٹڈ ٹیبل کے ساتھ، 10 سوالات کا اوسط رن ٹائم 8.03 سیکنڈ ہے، اور 148 ملین ریکارڈ واپس کرنے کے لیے 2.21 MB ڈیٹا اسکین کیا جاتا ہے۔ یہ AWS Glue یا Athena کے ساتھ بکٹنگ کے مقابلے میں کم کارگر ہے، لیکن آئس برگ کی مختلف خصوصیات کے فوائد پر غور کرتے ہوئے، یہ قابل قبول حد کے اندر ہے۔
نتائج کی نمائش
درج ذیل جدول میں تمام نتائج کا خلاصہ کیا گیا ہے۔
| . | noaa_remote_original | athena_non_bucketed | athena_bucketed | glue_bucketed | athena_bucketed_iceberg |
| فارمیٹ | CSV | چھڑی | چھڑی | چھڑی | آئس برگ (پارکیٹ) |
| سمپیڑن | N / A | پرسکون | پرسکون | پرسکون | پرسکون |
| کے ذریعے تخلیق کیا گیا۔ | N / A | ایتھینا سی ٹی اے ایس | ایتھینا سی ٹی اے ایس | گلو ای ٹی ایل | آئس برگ کے ساتھ ایتھینا سی ٹی اے ایس |
| انجن | N / A | ٹریل | ٹریل | اپاچی چمک | اپاچی آئس برگ |
| میز کا سائز (GB) | 155.8 | 5.0 | 5.0 | 5.8 | 5.0 |
| S3 آبجیکٹ کی تعداد | 53360 | 376 | 192 | 192 | 195 |
| تقسیم کیا ہے؟ | ہاں لیکن مختلف طریقے سے | جی ہاں | جی ہاں | جی ہاں | جی ہاں |
| بالٹی ہے؟ | نہیں | نہیں | جی ہاں | جی ہاں | جی ہاں |
| بکٹنگ فارمیٹ | N / A | N / A | چھتہ | چنگاری | ہمھنڈ |
| بالٹیوں کی تعداد | N / A | N / A | 16 | 16 | 16 |
| اوسط رن ٹائم (سیکنڈ) | 29.178 | 10.950 | 7.815 | 7.089 | 8.030 |
| اسکین شدہ سائز (MB) | 206640.0 | 358.6 | 69.1 | 87.8 | 147.7 |
ساتھ athena_bucketed, glue_bucketed، اور athena_bucketed_iceberg، آپ 10 سیکنڈ کے تاخیر کے ہدف کو پورا کرنے کے قابل تھے۔ بکٹنگ کے ساتھ، آپ نے رن ٹائم میں 25-40% کمی اور اسکین سائز میں 60-85% کمی دیکھی، جو تاخیر اور لاگت کی اصلاح دونوں میں حصہ ڈال سکتی ہے۔
جیسا کہ آپ نتیجہ سے دیکھ سکتے ہیں، اگرچہ تقسیم کاری رن ٹائم اور اسکین سائز دونوں کو کم کرنے میں اہم کردار ادا کرتی ہے، لیکن بکٹنگ ان کو مزید کم کرنے میں بھی حصہ ڈال سکتی ہے۔
ایتھینا سی ٹی اے ایس سیدھا سیدھا اور تیز رفتار ہے جو بکٹنگ کے عمل کو مکمل کر سکتا ہے۔ AWS Glue ETL اعلی درجے کے استعمال کے معاملات کو حاصل کرنے کے لئے زیادہ لچکدار اور توسیع پذیر ہے۔ آپ اپنی ضرورت اور استعمال کے معاملے کی بنیاد پر کسی بھی طریقہ کا انتخاب کر سکتے ہیں، کیونکہ آپ کسی بھی آپشن کے ذریعے بکٹنگ کا فائدہ اٹھا سکتے ہیں۔
نتیجہ
اس پوسٹ میں، ہم نے دکھایا کہ ایتھینا CTAS اور AWS Glue ETL کے ذریعے تقسیم اور بکٹنگ کے ساتھ آپ کے ٹیبل ڈیٹا لے آؤٹ کو کیسے بہتر بنایا جائے۔ ہم نے دکھایا کہ بکٹنگ استفسار میں تاخیر کو تیز کرنے اور اسکین کے سائز کو کم کرنے میں معاونت کرتی ہے تاکہ اخراجات کو مزید بہتر بنایا جا سکے۔ ہم نے پوشیدہ تقسیم کے ذریعے آئس برگ ٹیبل کے لیے بکٹنگ پر بھی تبادلہ خیال کیا۔
ڈیٹا اسکین کو کم کرکے ڈیٹا لے آؤٹ کو بہتر بنانے کے لیے صرف ایک تکنیک کو بکیٹ کرنا۔ آپ کے پورے ڈیٹا لے آؤٹ کو بہتر بنانے کے لیے، ہم تجویز کرتے ہیں کہ دوسرے آپشنز پر غور کریں جیسے تقسیم کرنا، کالم فائل فارمیٹ استعمال کرنا، اور بکٹنگ کے ساتھ مل کر کمپریشن۔ یہ آپ کے ڈیٹا کو استفسار کی کارکردگی کو مزید بڑھانے کے قابل بنا سکتا ہے۔
مبارک بالٹی!
مصنفین کے بارے میں
 تاکیشی نکاتانی ٹوکیو میں پروفیشنل سروسز ٹیم کے پرنسپل بگ ڈیٹا کنسلٹنٹ ہیں۔ ان کے پاس آئی ٹی انڈسٹری میں 26 سال کا تجربہ ہے، ڈیٹا انفراسٹرکچر کی تعمیر میں مہارت کے ساتھ۔ چھٹی کے دنوں میں، وہ راک ڈرمر یا موٹر سائیکل سوار ہو سکتا ہے۔
تاکیشی نکاتانی ٹوکیو میں پروفیشنل سروسز ٹیم کے پرنسپل بگ ڈیٹا کنسلٹنٹ ہیں۔ ان کے پاس آئی ٹی انڈسٹری میں 26 سال کا تجربہ ہے، ڈیٹا انفراسٹرکچر کی تعمیر میں مہارت کے ساتھ۔ چھٹی کے دنوں میں، وہ راک ڈرمر یا موٹر سائیکل سوار ہو سکتا ہے۔
 نوریٹاکا سیکیاما AWS Glue ٹیم میں ایک پرنسپل بگ ڈیٹا آرکیٹیکٹ ہے۔ وہ صارفین کی مدد کے لیے سافٹ ویئر کے نمونے بنانے کا ذمہ دار ہے۔ اپنے فارغ وقت میں، وہ اپنی روڈ بائیک کے ساتھ سائیکل چلانے سے لطف اندوز ہوتا ہے۔
نوریٹاکا سیکیاما AWS Glue ٹیم میں ایک پرنسپل بگ ڈیٹا آرکیٹیکٹ ہے۔ وہ صارفین کی مدد کے لیے سافٹ ویئر کے نمونے بنانے کا ذمہ دار ہے۔ اپنے فارغ وقت میں، وہ اپنی روڈ بائیک کے ساتھ سائیکل چلانے سے لطف اندوز ہوتا ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/big-data/optimize-data-layout-by-bucketing-with-amazon-athena-and-aws-glue-to-accelerate-downstream-queries/

