بڑے لینگویج ماڈلز (LLMs) کو عام طور پر بڑے عوامی طور پر دستیاب ڈیٹاسیٹس پر تربیت دی جاتی ہے جو ڈومین ایگنوسٹک ہوتے ہیں۔ مثال کے طور پر، میٹا کا لاما ماڈلز کو ڈیٹاسیٹس پر تربیت دی جاتی ہے جیسے کامن کرول, C4، ویکیپیڈیا، اور ArXiv. یہ ڈیٹاسیٹس موضوعات اور ڈومینز کی ایک وسیع رینج کو گھیرے ہوئے ہیں۔ اگرچہ نتیجے میں آنے والے ماڈل عام کاموں، جیسے کہ ٹیکسٹ جنریشن اور ہستی کی شناخت کے لیے حیرت انگیز طور پر اچھے نتائج دیتے ہیں، لیکن اس بات کا ثبوت موجود ہے کہ ڈومین کے مخصوص ڈیٹاسیٹس کے ساتھ تربیت یافتہ ماڈل ایل ایل ایم کی کارکردگی کو مزید بہتر بنا سکتے ہیں۔ مثال کے طور پر، تربیتی ڈیٹا کے لیے استعمال کیا جاتا ہے۔ بلومبرگ جی پی ٹی 51% ڈومین مخصوص دستاویزات ہیں، بشمول مالیاتی خبریں، فائلنگز، اور دیگر مالیاتی مواد۔ نتیجہ خیز LLM غیر ڈومین مخصوص ڈیٹاسیٹس پر تربیت یافتہ LLMs سے بہتر کارکردگی کا مظاہرہ کرتا ہے جب فنانس سے متعلق مخصوص کاموں پر تجربہ کیا جاتا ہے۔ کے مصنفین بلومبرگ جی پی ٹی یہ نتیجہ اخذ کیا کہ ان کا ماڈل پانچ میں سے چار مالیاتی کاموں کے لیے جانچے گئے دیگر تمام ماڈلز سے بہتر کارکردگی کا مظاہرہ کرتا ہے۔ بلومبرگ کے داخلی مالیاتی کاموں کے لیے وسیع مارجن سے ٹیسٹ کیے جانے پر ماڈل نے اور بھی بہتر کارکردگی فراہم کی — 60 پوائنٹس بہتر (100 میں سے)۔ اگرچہ آپ جامع تشخیص کے نتائج کے بارے میں مزید جان سکتے ہیں۔ کاغذ، مندرجہ ذیل نمونہ سے حاصل کیا گیا ہے۔ بلومبرگ جی پی ٹی کاغذ آپ کو مالی ڈومین کے مخصوص ڈیٹا کا استعمال کرتے ہوئے ایل ایل ایم کی تربیت کے فائدے کی ایک جھلک دکھا سکتا ہے۔ جیسا کہ مثال میں دکھایا گیا ہے، بلومبرگ جی پی ٹی ماڈل نے درست جوابات فراہم کیے جبکہ دیگر غیر ڈومین مخصوص ماڈلز نے جدوجہد کی:
یہ پوسٹ خاص طور پر مالیاتی ڈومین کے لیے ایل ایل ایم کی تربیت کے لیے ایک گائیڈ فراہم کرتی ہے۔ ہم درج ذیل کلیدی شعبوں کا احاطہ کرتے ہیں:
- ڈیٹا اکٹھا کرنا اور تیاری - مؤثر ماڈل ٹریننگ کے لیے متعلقہ مالیاتی ڈیٹا کی سورسنگ اور کیوریٹنگ پر رہنمائی
- مسلسل پری ٹریننگ بمقابلہ فائن ٹیوننگ - اپنے LLM کی کارکردگی کو بہتر بنانے کے لیے ہر ایک تکنیک کو کب استعمال کرنا ہے۔
- موثر مسلسل پری ٹریننگ - وقت اور وسائل کی بچت کرتے ہوئے مسلسل پری ٹریننگ کے عمل کو ہموار کرنے کی حکمت عملی
یہ پوسٹ Amazon Finance Technology کے اندر اپلائیڈ سائنس ریسرچ ٹیم اور AWS ورلڈ وائیڈ اسپیشلسٹ ٹیم کی عالمی مالیاتی صنعت کی مہارت کو اکٹھا کرتی ہے۔ کچھ مواد کاغذ پر مبنی ہے۔ ڈومین مخصوص بڑی زبان کے ماڈلز بنانے کے لیے موثر مسلسل پری ٹریننگ.
فنانس ڈیٹا اکٹھا کرنا اور تیار کرنا
ڈومین کی مسلسل پری ٹریننگ کے لیے بڑے پیمانے پر، اعلیٰ معیار کے، ڈومین کے لیے مخصوص ڈیٹاسیٹ کی ضرورت ہوتی ہے۔ ڈومین ڈیٹا سیٹ کیوریشن کے لیے درج ذیل اہم اقدامات ہیں:
- ڈیٹا کے ذرائع کی شناخت کریں۔ - ڈومین کارپس کے لیے ڈیٹا کے ممکنہ ذرائع میں اوپن ویب، ویکیپیڈیا، کتابیں، سوشل میڈیا، اور اندرونی دستاویزات شامل ہیں۔
- ڈومین ڈیٹا فلٹرز - چونکہ حتمی مقصد ڈومین کارپس کو درست کرنا ہے، اس لیے آپ کو ایسے نمونوں کو فلٹر کرنے کے لیے اضافی اقدامات کرنے کی ضرورت پڑ سکتی ہے جو ہدف کے ڈومین سے غیر متعلق ہوں۔ یہ مسلسل پری ٹریننگ کے لیے بیکار کارپس کو کم کرتا ہے اور تربیت کی لاگت کو کم کرتا ہے۔
- پیشگی کارروائی - آپ ڈیٹا کوالٹی اور ٹریننگ کی کارکردگی کو بہتر بنانے کے لیے پری پروسیسنگ اقدامات کی ایک سیریز پر غور کر سکتے ہیں۔ مثال کے طور پر، ڈیٹا کے کچھ ذرائع میں کافی تعداد میں شور والے ٹوکن ہو سکتے ہیں۔ ڈپلیکیشن کو ڈیٹا کے معیار کو بہتر بنانے اور تربیت کی لاگت کو کم کرنے کے لیے ایک مفید قدم سمجھا جاتا ہے۔
مالیاتی LLM تیار کرنے کے لیے، آپ ڈیٹا کے دو اہم ذرائع استعمال کر سکتے ہیں: News CommonCrawl اور SEC فائلنگ۔ SEC فائلنگ ایک مالی بیان یا دیگر رسمی دستاویز ہے جو یو ایس سیکیورٹیز اینڈ ایکسچینج کمیشن (SEC) کو جمع کرائی گئی ہے۔ عوامی طور پر درج کمپنیوں کو باقاعدگی سے مختلف دستاویزات فائل کرنے کی ضرورت ہے۔ یہ سالوں میں دستاویزات کی ایک بڑی تعداد بناتا ہے. News CommonCrawl 2016 میں CommonCrawl کی طرف سے جاری کردہ ڈیٹا سیٹ ہے۔ اس میں پوری دنیا کی نیوز سائٹس کے خبروں کے مضامین شامل ہیں۔
News CommonCrawl پر دستیاب ہے۔ ایمیزون سادہ اسٹوریج سروس (ایمیزون S3) میں commoncrawl پر بالٹی crawl-data/CC-NEWS/. آپ کا استعمال کرتے ہوئے فائلوں کی فہرستیں حاصل کر سکتے ہیں۔ AWS کمانڈ لائن انٹرفیس (AWS CLI) اور درج ذیل کمانڈ:
In ڈومین مخصوص بڑی زبان کے ماڈلز بنانے کے لیے موثر مسلسل پری ٹریننگ، مصنفین عمومی خبروں سے مالیاتی خبروں کے مضامین کو فلٹر کرنے کے لیے URL اور مطلوبہ الفاظ پر مبنی طریقہ استعمال کرتے ہیں۔ خاص طور پر، مصنفین اہم مالیاتی خبروں کی فہرست اور مالی خبروں سے متعلق مطلوبہ الفاظ کا ایک مجموعہ برقرار رکھتے ہیں۔ ہم کسی مضمون کی شناخت مالی خبروں کے طور پر کرتے ہیں اگر یا تو وہ مالیاتی خبروں کے آؤٹ لیٹس سے آتا ہے یا URL میں کوئی مطلوبہ الفاظ دکھائے جاتے ہیں۔ یہ آسان لیکن موثر طریقہ آپ کو نہ صرف مالیاتی خبروں کی دکانوں سے بلکہ عام خبروں کے آؤٹ لیٹس کے مالیاتی حصوں سے بھی مالی خبروں کی شناخت کرنے کے قابل بناتا ہے۔
SEC فائلنگ SEC کے EDGAR (Electronic Data Gathering, Analysis, and Retrieval) ڈیٹا بیس کے ذریعے آن لائن دستیاب ہیں، جو ڈیٹا تک رسائی فراہم کرتا ہے۔ آپ EDGAR سے فائلنگ کو براہ راست کھرچ سکتے ہیں، یا APIs کا استعمال کر سکتے ہیں۔ ایمیزون سیج میکر کوڈ کی چند سطروں کے ساتھ، کسی بھی مدت کے لیے اور بڑی تعداد میں ٹکرز کے لیے (یعنی SEC تفویض کردہ شناخت کنندہ)۔ مزید جاننے کے لیے رجوع کریں۔ SEC فائلنگ بازیافت.
مندرجہ ذیل جدول ڈیٹا کے دونوں ذرائع کی اہم تفصیلات کا خلاصہ کرتا ہے۔
| . | نیوز کامن کرول | ایس ای سی فائلنگ |
| کوریج | 2016-2022 | 1993-2022 |
| سائز | 25.8 بلین الفاظ | 5.1 بلین الفاظ |
ڈیٹا کو تربیتی الگورتھم میں فیڈ کرنے سے پہلے مصنفین کچھ اضافی پری پروسیسنگ مراحل سے گزرتے ہیں۔ سب سے پہلے، ہم مشاہدہ کرتے ہیں کہ SEC فائلنگ میں ٹیبلز اور اعداد و شمار کو ہٹانے کی وجہ سے شور والا متن ہوتا ہے، اس لیے مصنفین مختصر جملوں کو ہٹا دیتے ہیں جنہیں ٹیبل یا فگر لیبل سمجھا جاتا ہے۔ دوم، ہم نئے مضامین اور فائلنگ کو ڈپلیکیٹ کرنے کے لیے ایک مقامی حساس ہیشنگ الگورتھم کا اطلاق کرتے ہیں۔ SEC فائلنگز کے لیے، ہم دستاویز کی سطح کے بجائے سیکشن کی سطح پر نقل کرتے ہیں۔ آخر میں، ہم دستاویزات کو ایک لمبی تار میں جوڑتے ہیں، اسے ٹوکنائز کرتے ہیں، اور ٹوکنائزیشن کو زیادہ سے زیادہ ان پٹ لمبائی کے ٹکڑوں میں ٹکڑا دیتے ہیں جس کی تربیت کے لیے ماڈل کے ذریعے تعاون کیا جاتا ہے۔ یہ مسلسل پری ٹریننگ کے تھرو پٹ کو بہتر بناتا ہے اور تربیت کی لاگت کو کم کرتا ہے۔
مسلسل پری ٹریننگ بمقابلہ فائن ٹیوننگ
زیادہ تر دستیاب LLMs عمومی مقصد کے ہوتے ہیں اور ان میں ڈومین کے لیے مخصوص صلاحیتوں کی کمی ہوتی ہے۔ ڈومین LLMs نے میڈیکل، فنانس، یا سائنسی ڈومینز میں کافی کارکردگی دکھائی ہے۔ LLM کے لیے ڈومین کے لیے مخصوص علم حاصل کرنے کے لیے، چار طریقے ہیں: شروع سے تربیت، مسلسل پری ٹریننگ، ڈومین کے کاموں پر انسٹرکشن فائن ٹیوننگ، اور Retrieval Augmented Generation (RAG)۔
روایتی ماڈلز میں، فائن ٹیوننگ کا استعمال عام طور پر کسی ڈومین کے لیے مخصوص ٹاسک ماڈل بنانے کے لیے کیا جاتا ہے۔ اس کا مطلب ہے متعدد کاموں کے لیے متعدد ماڈلز کو برقرار رکھنا جیسے ہستی نکالنا، ارادے کی درجہ بندی، جذبات کا تجزیہ، یا سوال کا جواب دینا۔ LLMs کی آمد کے ساتھ، سیاق و سباق میں سیکھنے یا اشارہ دینے جیسی تکنیکوں کا استعمال کرتے ہوئے علیحدہ ماڈلز کو برقرار رکھنے کی ضرورت متروک ہو گئی ہے۔ یہ متعلقہ لیکن الگ الگ کاموں کے لیے ماڈلز کے اسٹیک کو برقرار رکھنے کے لیے درکار کوشش کو بچاتا ہے۔
بدیہی طور پر، آپ ڈومین کے مخصوص ڈیٹا کے ساتھ شروع سے LLMs کو تربیت دے سکتے ہیں۔ اگرچہ ڈومین ایل ایل ایم بنانے کا زیادہ تر کام شروع سے تربیت پر مرکوز ہے، لیکن یہ ممنوعہ طور پر مہنگا ہے۔ مثال کے طور پر، GPT-4 ماڈل کی قیمت ہے۔ $ 100 ملین سے زیادہ تربیت دینے کے لئے. ان ماڈلز کو اوپن ڈومین ڈیٹا اور ڈومین ڈیٹا کے مرکب پر تربیت دی جاتی ہے۔ مسلسل پری ٹریننگ ماڈلز کو شروع سے پری ٹریننگ کی لاگت کے بغیر ڈومین سے متعلق علم حاصل کرنے میں مدد کر سکتی ہے کیونکہ آپ صرف ڈومین ڈیٹا پر موجودہ اوپن ڈومین LLM کو پہلے سے تربیت دیتے ہیں۔
کسی کام پر انسٹرکشن فائن ٹیوننگ کے ساتھ، آپ ماڈل کو ڈومین کا علم حاصل نہیں کر سکتے کیونکہ LLM صرف انسٹرکشن فائن ٹیوننگ ڈیٹاسیٹ میں موجود ڈومین کی معلومات حاصل کرتا ہے۔ جب تک کہ انسٹرکشن فائن ٹیوننگ کے لیے ایک بہت بڑا ڈیٹا سیٹ استعمال نہ کیا جائے، یہ ڈومین کا علم حاصل کرنے کے لیے کافی نہیں ہے۔ اعلیٰ معیار کے انسٹرکشن ڈیٹا سیٹس کو سورس کرنا عام طور پر مشکل ہوتا ہے اور یہی وجہ ہے کہ LLMs کو پہلی جگہ استعمال کرنا ہے۔ اس کے علاوہ، ایک کام پر ہدایات ٹھیک کرنے سے دوسرے کاموں کی کارکردگی متاثر ہو سکتی ہے (جیسا کہ میں دیکھا گیا ہے۔ اس اخبار)۔ تاہم، انسٹرکشن فائن ٹیوننگ پری ٹریننگ متبادل میں سے کسی ایک سے بھی زیادہ سرمایہ کاری مؤثر ہے۔
مندرجہ ذیل اعداد و شمار روایتی کام کے لیے مخصوص فائن ٹیوننگ کا موازنہ کرتا ہے۔ بمقابلہ سیاق و سباق سیکھنے کا نمونہ LLMs کے ساتھ۔
 RAG ایک LLM کی رہنمائی کا سب سے مؤثر طریقہ ہے تاکہ ڈومین میں موجود ردعمل پیدا کیا جا سکے۔ اگرچہ یہ معاون معلومات کے طور پر ڈومین سے حقائق فراہم کر کے ردعمل پیدا کرنے کے لیے ماڈل کی رہنمائی کر سکتا ہے، لیکن یہ ڈومین کے لیے مخصوص زبان حاصل نہیں کرتا کیونکہ LLM اب بھی جوابات پیدا کرنے کے لیے غیر ڈومین زبان کے طرز پر انحصار کر رہا ہے۔
RAG ایک LLM کی رہنمائی کا سب سے مؤثر طریقہ ہے تاکہ ڈومین میں موجود ردعمل پیدا کیا جا سکے۔ اگرچہ یہ معاون معلومات کے طور پر ڈومین سے حقائق فراہم کر کے ردعمل پیدا کرنے کے لیے ماڈل کی رہنمائی کر سکتا ہے، لیکن یہ ڈومین کے لیے مخصوص زبان حاصل نہیں کرتا کیونکہ LLM اب بھی جوابات پیدا کرنے کے لیے غیر ڈومین زبان کے طرز پر انحصار کر رہا ہے۔
مسلسل پری ٹریننگ لاگت کے لحاظ سے پری ٹریننگ اور انسٹرکشن فائن ٹیوننگ کے درمیان ایک درمیانی بنیاد ہے جبکہ ڈومین کے لیے مخصوص علم اور انداز حاصل کرنے کا ایک مضبوط متبادل ہے۔ یہ ایک عام ماڈل فراہم کر سکتا ہے جس پر محدود ہدایات کے اعداد و شمار پر مزید ہدایات کی فائن ٹیوننگ کی جا سکتی ہے۔ مسلسل پری ٹریننگ خصوصی ڈومینز کے لیے ایک سرمایہ کاری مؤثر حکمت عملی ہو سکتی ہے جہاں نیچے دھارے کے کاموں کا سیٹ بڑا یا نامعلوم ہے اور لیبل لگا ہوا انسٹرکشن ٹیوننگ ڈیٹا محدود ہے۔ دوسرے منظرناموں میں، انسٹرکشن فائن ٹیوننگ یا RAG زیادہ موزوں ہو سکتی ہے۔
فائن ٹیوننگ، آر اے جی، اور ماڈل ٹریننگ کے بارے میں مزید جاننے کے لیے، دیکھیں فاؤنڈیشن ماڈل کو ٹھیک بنائیں, بازیافت اگمینٹڈ جنریشن (RAG)، اور ایمیزون سیج میکر کے ساتھ ایک ماڈل کو تربیت دیں۔بالترتیب اس پوسٹ کے لیے، ہم موثر مسلسل پری ٹریننگ پر توجہ مرکوز کرتے ہیں۔
موثر مسلسل پری ٹریننگ کا طریقہ کار
مسلسل پری ٹریننگ مندرجہ ذیل طریقہ کار پر مشتمل ہے:
- ڈومین-اڈاپٹیو کنٹینیوئل پری ٹریننگ (DACP) - کاغذ میں ڈومین مخصوص بڑی زبان کے ماڈلز بنانے کے لیے موثر مسلسل پری ٹریننگ، مصنفین مسلسل Pythia لینگویج ماڈل سوٹ کو مالیاتی کارپس پر پہلے سے تربیت دیتے ہیں تاکہ اسے فنانس ڈومین میں ڈھال سکیں۔ مقصد پورے مالیاتی ڈومین کے ڈیٹا کو اوپن سورس ماڈل میں فیڈ کرکے مالیاتی LLMs بنانا ہے۔ چونکہ ٹریننگ کارپس ڈومین میں تمام کیوریٹڈ ڈیٹا سیٹس پر مشتمل ہوتا ہے، اس لیے نتیجے میں آنے والے ماڈل کو فنانس سے متعلق مخصوص علم حاصل کرنا چاہیے، اس طرح مختلف مالیاتی کاموں کے لیے ایک ورسٹائل ماڈل بننا چاہیے۔ اس کا نتیجہ FinPythia ماڈلز میں ہوتا ہے۔
- ٹاسک ایڈاپٹیو کنٹینیوئل پری ٹریننگ (TACP) - مصنفین ماڈلز کو لیبل شدہ اور بغیر لیبل والے ٹاسک ڈیٹا پر پہلے سے تربیت دیتے ہیں تاکہ انہیں مخصوص کاموں کے لیے تیار کیا جا سکے۔ بعض حالات میں، ڈویلپر ڈومین کے عمومی ماڈل کی بجائے ان ڈومین کاموں کے گروپ پر بہتر کارکردگی پیش کرنے والے ماڈلز کو ترجیح دے سکتے ہیں۔ TACP کو مستقل پری ٹریننگ کے طور پر ڈیزائن کیا گیا ہے جس کا مقصد ہدف شدہ کاموں پر کارکردگی کو بڑھانا ہے، بغیر لیبل والے ڈیٹا کی ضروریات کے۔ خاص طور پر، مصنفین مسلسل اوپن سورس ماڈلز کو ٹاسک ٹوکنز (بغیر لیبل کے) پر پہلے سے تربیت دیتے ہیں۔ TACP کی بنیادی حد فاؤنڈیشن LLMs کی بجائے ٹاسک مخصوص LLMs کی تعمیر میں ہے، جس کی وجہ تربیت کے لیے بغیر لیبل والے ٹاسک ڈیٹا کا واحد استعمال ہے۔ اگرچہ DACP بہت بڑا کارپس استعمال کرتا ہے، لیکن یہ ممنوعہ طور پر مہنگا ہے۔ ان حدود کو متوازن کرنے کے لیے، مصنفین نے دو طریقے تجویز کیے ہیں جن کا مقصد ڈومین کے لیے مخصوص فاؤنڈیشن ایل ایل ایم بنانا ہے جبکہ ہدف کے کاموں پر اعلیٰ کارکردگی کو برقرار رکھا جائے:
- موثر ٹاسک-ملتے جلتے DACP (ETS-DACP) - مصنفین مالیاتی کارپس کے ایک ذیلی سیٹ کو منتخب کرنے کی تجویز پیش کرتے ہیں جو سرایت کرنے والی مماثلت کا استعمال کرتے ہوئے ٹاسک ڈیٹا سے بہت ملتا جلتا ہے۔ اس سب سیٹ کو مسلسل پری ٹریننگ کے لیے استعمال کیا جاتا ہے تاکہ اسے مزید موثر بنایا جا سکے۔ خاص طور پر، مصنفین مسلسل اوپن سورسڈ LLM کو مالیاتی کارپس سے نکالے گئے چھوٹے کارپس پر پہلے سے تربیت دیتے ہیں جو تقسیم کے ہدف کے کاموں کے قریب ہے۔ اس سے ٹاسک کی کارکردگی کو بہتر بنانے میں مدد مل سکتی ہے کیونکہ لیبل والے ڈیٹا کی ضرورت نہ ہونے کے باوجود ہم ٹاسک ٹوکنز کی تقسیم کے لیے ماڈل کو اپناتے ہیں۔
- موثر ٹاسک-ایگنوسٹک DACP (ETA-DACP) - مصنفین نے ایسے میٹرکس کا استعمال کرنے کی تجویز پیش کی ہے جیسے پرلیکسیٹی اور ٹوکن ٹائپ اینٹروپی جس میں موثر مسلسل پری ٹریننگ کے لیے مالیاتی کارپس سے نمونے منتخب کرنے کے لیے ٹاسک ڈیٹا کی ضرورت نہیں ہوتی ہے۔ یہ نقطہ نظر ایسے منظرناموں سے نمٹنے کے لیے ڈیزائن کیا گیا ہے جہاں ٹاسک ڈیٹا دستیاب نہیں ہے یا وسیع ڈومین کے لیے زیادہ ورسٹائل ڈومین ماڈلز کو ترجیح دی جاتی ہے۔ مصنفین ڈیٹا کے نمونوں کو منتخب کرنے کے لیے دو جہتوں کو اپناتے ہیں جو ڈومین کی معلومات کو پری ٹریننگ ڈومین ڈیٹا کے ذیلی سیٹ سے حاصل کرنے کے لیے اہم ہیں: نیاپن اور تنوع۔ نیاپن، ٹارگٹ ماڈل کے ذریعے ریکارڈ کی گئی پریشانی سے ماپا جاتا ہے، اس معلومات سے مراد ہے جو ایل ایل ایم نے پہلے نہیں دیکھی تھی۔ اعلی نیاپن کے ساتھ ڈیٹا ایل ایل ایم کے لیے نئے علم کی نشاندہی کرتا ہے، اور اس طرح کے ڈیٹا کو سیکھنا زیادہ مشکل سمجھا جاتا ہے۔ یہ مسلسل پری ٹریننگ کے دوران گہری ڈومین کے علم کے ساتھ عام LLMs کو اپ ڈیٹ کرتا ہے۔ دوسری طرف تنوع، ڈومین کارپس میں ٹوکن کی اقسام کی تقسیم کے تنوع کو حاصل کرتا ہے، جسے زبان کی ماڈلنگ پر نصاب سیکھنے کی تحقیق میں ایک مفید خصوصیت کے طور پر دستاویز کیا گیا ہے۔
مندرجہ ذیل اعداد و شمار ETS-DACP (بائیں) بمقابلہ ETA-DACP (دائیں) کی مثال کا موازنہ کرتا ہے۔

ہم مرتب شدہ مالیاتی کارپس سے ڈیٹا پوائنٹس کو فعال طور پر منتخب کرنے کے لیے دو نمونے لینے کی اسکیمیں اپناتے ہیں: سخت نمونے اور نرم نمونے۔ سابقہ پہلے مالیاتی کارپس کو متعلقہ میٹرکس کے ذریعہ درجہ بندی کرکے اور پھر ٹاپ-k نمونوں کو منتخب کرکے کیا جاتا ہے، جہاں k کا پہلے سے تعین تربیتی بجٹ کے مطابق ہوتا ہے۔ مؤخر الذکر کے لیے، مصنفین میٹرک اقدار کے مطابق ہر ڈیٹا پوائنٹس کے لیے نمونے لینے کا وزن تفویض کرتے ہیں، اور پھر تربیتی بجٹ کو پورا کرنے کے لیے تصادفی طور پر k ڈیٹا پوائنٹس کا نمونہ بناتے ہیں۔
نتیجہ اور تجزیہ
مصنفین مسلسل پری ٹریننگ کی افادیت کی چھان بین کے لیے مالیاتی کاموں کی ایک صف پر نتیجے میں آنے والے مالیاتی LLMs کا جائزہ لیتے ہیں:
- فنانشل فریز بینک - مالی خبروں پر جذبات کی درجہ بندی کا کام۔
- FiQA SA - مالی خبروں اور سرخیوں پر مبنی ایک پہلو پر مبنی جذبات کی درجہ بندی کا کام۔
- شہ سرخی - ایک بائنری درجہ بندی کا کام اس بات پر کہ آیا کسی مالیاتی ادارے کی سرخی میں کچھ معلومات شامل ہیں۔
- NER - ایس ای سی رپورٹس کے کریڈٹ رسک اسیسمنٹ سیکشن پر مبنی ایک مالیاتی نامی ادارہ نکالنے کا کام۔ اس کام میں الفاظ PER، LOC، ORG، اور MISC کے ساتھ تشریح کیے گئے ہیں۔
چونکہ مالیاتی LLMs ہدایات کے مطابق ہیں، مصنفین مضبوطی کی خاطر ہر کام کے لیے 5 شاٹ سیٹنگ میں ماڈلز کا جائزہ لیتے ہیں۔ اوسطاً، FinPythia 6.9B نے چار کاموں میں Pythia 6.9B کو 10% پیچھے چھوڑ دیا، جو ڈومین کے لیے مخصوص مسلسل پری ٹریننگ کی افادیت کو ظاہر کرتا ہے۔ 1B ماڈل کے لیے، بہتری کم گہری ہے، لیکن کارکردگی اب بھی اوسطاً 2% بہتر ہوتی ہے۔
مندرجہ ذیل اعداد و شمار دونوں ماڈلز پر DACP سے پہلے اور بعد میں کارکردگی کے فرق کو واضح کرتا ہے۔

مندرجہ ذیل اعداد و شمار Pythia 6.9B اور FinPythia 6.9B کے ذریعہ تیار کردہ دو قابلیت کی مثالوں کو ظاہر کرتا ہے۔ سرمایہ کار مینیجر اور مالیاتی اصطلاح سے متعلق مالیات سے متعلق دو سوالات کے لیے، Pythia 6.9B اصطلاح کو نہیں سمجھتا یا نام کو نہیں پہچانتا، جبکہ FinPythia 6.9B تفصیلی جوابات درست طریقے سے تیار کرتا ہے۔ قابلیت کی مثالیں یہ ظاہر کرتی ہیں کہ مسلسل پری ٹریننگ LLMs کو اس عمل کے دوران ڈومین کا علم حاصل کرنے کے قابل بناتی ہے۔

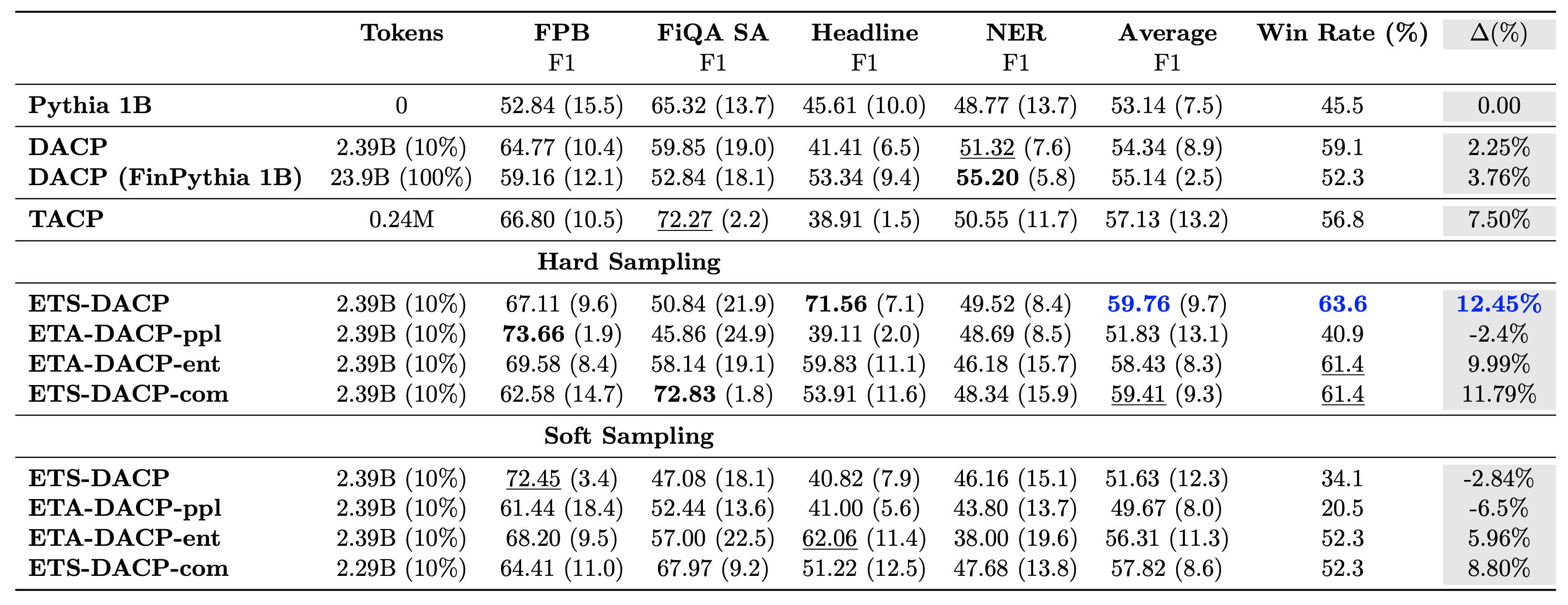
مندرجہ ذیل جدول مختلف موثر مسلسل پری ٹریننگ طریقوں کا موازنہ کرتا ہے۔ ETA-DACP-ppl ETA-DACP ہے جو الجھن (نوولٹی) پر مبنی ہے، اور ETA-DACP-ent انٹروپی (تنوع) پر مبنی ہے۔ ETS-DACP-com تینوں میٹرکس کی اوسط سے ڈیٹا کے انتخاب کے ساتھ DACP کی طرح ہے۔ نتائج سے چند نکات درج ذیل ہیں:
- ڈیٹا سلیکشن کے طریقے کارآمد ہیں۔ - وہ صرف 10% تربیتی ڈیٹا کے ساتھ معیاری مسلسل پری ٹریننگ سے آگے نکل جاتے ہیں۔ موثر مسلسل پری ٹریننگ بشمول Task-Similar DACP (ETS-DACP)، Entropy (ESA-DACP-ent) پر مبنی Task-Agnostic DACP اور تینوں میٹرکس (ETS-DACP-com) پر مبنی ٹاسک-سیملر ڈی اے سی پی معیاری DACP سے بہتر کارکردگی کا مظاہرہ کرتی ہے۔ اوسطاً اس حقیقت کے باوجود کہ وہ مالیاتی کارپس کے صرف 10% پر تربیت یافتہ ہیں۔
- ٹاسک سے آگاہ ڈیٹا کا انتخاب چھوٹی زبان کے ماڈلز کی تحقیق کے مطابق بہترین کام کرتا ہے۔ – ETS-DACP تمام طریقوں میں بہترین اوسط کارکردگی کو ریکارڈ کرتا ہے اور تینوں میٹرکس کی بنیاد پر، دوسری بہترین ٹاسک کارکردگی کو ریکارڈ کرتا ہے۔ اس سے پتہ چلتا ہے کہ LLMs کے معاملے میں ٹاسک کی کارکردگی کو بڑھانے کے لیے بغیر لیبل والے ٹاسک ڈیٹا کا استعمال اب بھی ایک موثر طریقہ ہے۔
- ٹاسک-ایگنوسٹک ڈیٹا کا انتخاب دوسرے نمبر پر ہے۔ – ESA-DACP-ent ٹاسک سے آگاہی ڈیٹا سلیکشن اپروچ کی کارکردگی کی پیروی کرتا ہے، جس کا مطلب یہ ہے کہ ہم اب بھی فعال طور پر اعلیٰ معیار کے نمونے منتخب کرکے کام کی کارکردگی کو بڑھا سکتے ہیں جو مخصوص کاموں سے منسلک نہیں ہیں۔ یہ اعلیٰ کام کی کارکردگی کو حاصل کرتے ہوئے پورے ڈومین کے لیے مالیاتی LLMs بنانے کی راہ ہموار کرتا ہے۔
مسلسل پری ٹریننگ کے حوالے سے ایک اہم سوال یہ ہے کہ کیا یہ غیر ڈومین کاموں پر کارکردگی کو منفی طور پر متاثر کرتا ہے۔ مصنفین چار وسیع پیمانے پر استعمال ہونے والے عام کاموں پر مسلسل پہلے سے تربیت یافتہ ماڈل کا بھی جائزہ لیتے ہیں: ARC، MMLU، TruthQA، اور HellaSwag، جو سوال کے جواب، استدلال اور تکمیل کی صلاحیت کی پیمائش کرتے ہیں۔ مصنفین کو معلوم ہوتا ہے کہ مسلسل پری ٹریننگ غیر ڈومین کی کارکردگی کو بری طرح متاثر نہیں کرتی ہے۔ مزید تفصیلات کے لیے رجوع کریں۔ ڈومین مخصوص بڑی زبان کے ماڈلز بنانے کے لیے موثر مسلسل پری ٹریننگ.
نتیجہ
اس پوسٹ نے مالیاتی ڈومین کے لیے LLMs کی تربیت کے لیے ڈیٹا اکٹھا کرنے اور مسلسل پری ٹریننگ کی حکمت عملیوں کے بارے میں بصیرت پیش کی ہے۔ آپ مالیاتی کاموں کے لیے اپنے ایل ایل ایم کی تربیت شروع کر سکتے ہیں۔ ایمیزون سیج میکر ٹریننگ or ایمیزون بیڈرک آج.
مصنفین کے بارے میں
 یونگ زی Amazon FinTech میں ایک اپلائیڈ سائنسدان ہے۔ وہ فنانس کے لیے بڑے لینگوئج ماڈلز اور جنریٹیو اے آئی ایپلی کیشنز تیار کرنے پر توجہ مرکوز کرتا ہے۔
یونگ زی Amazon FinTech میں ایک اپلائیڈ سائنسدان ہے۔ وہ فنانس کے لیے بڑے لینگوئج ماڈلز اور جنریٹیو اے آئی ایپلی کیشنز تیار کرنے پر توجہ مرکوز کرتا ہے۔
 کرن اگروال Amazon FinTech کے ساتھ ایک سینئر اپلائیڈ سائنٹسٹ ہے جس کا فوکس جنریٹیو AI پر فنانس کے استعمال کے معاملات کے لیے ہے۔ کرن کے پاس ٹائم سیریز کے تجزیہ اور این ایل پی کا وسیع تجربہ ہے، جس میں محدود لیبل والے ڈیٹا سے سیکھنے میں خاص دلچسپی ہے۔
کرن اگروال Amazon FinTech کے ساتھ ایک سینئر اپلائیڈ سائنٹسٹ ہے جس کا فوکس جنریٹیو AI پر فنانس کے استعمال کے معاملات کے لیے ہے۔ کرن کے پاس ٹائم سیریز کے تجزیہ اور این ایل پی کا وسیع تجربہ ہے، جس میں محدود لیبل والے ڈیٹا سے سیکھنے میں خاص دلچسپی ہے۔
 اعتزاز احمد ایمیزون میں ایک اپلائیڈ سائنس مینیجر ہے جہاں وہ فنانس میں مشین لرننگ اور جنریٹو اے آئی کی مختلف ایپلی کیشنز بنانے والے سائنسدانوں کی ٹیم کی قیادت کرتا ہے۔ اس کی تحقیقی دلچسپیاں NLP، جنریٹو AI، اور LLM ایجنٹس میں ہیں۔ انہوں نے ٹیکساس اے اینڈ ایم یونیورسٹی سے الیکٹریکل انجینئرنگ میں پی ایچ ڈی کی ڈگری حاصل کی۔
اعتزاز احمد ایمیزون میں ایک اپلائیڈ سائنس مینیجر ہے جہاں وہ فنانس میں مشین لرننگ اور جنریٹو اے آئی کی مختلف ایپلی کیشنز بنانے والے سائنسدانوں کی ٹیم کی قیادت کرتا ہے۔ اس کی تحقیقی دلچسپیاں NLP، جنریٹو AI، اور LLM ایجنٹس میں ہیں۔ انہوں نے ٹیکساس اے اینڈ ایم یونیورسٹی سے الیکٹریکل انجینئرنگ میں پی ایچ ڈی کی ڈگری حاصل کی۔
 چنگ وی لی ایمیزون ویب سروسز میں مشین لرننگ کا ماہر ہے۔ انہوں نے پی ایچ ڈی کی ڈگری حاصل کی۔ آپریشنز ریسرچ میں جب اس نے اپنے مشیر کے ریسرچ گرانٹ اکاؤنٹ کو توڑا اور نوبل انعام دینے میں ناکام رہے جس کا اس نے وعدہ کیا تھا۔ فی الحال وہ مالیاتی خدمات میں صارفین کو AWS پر مشین لرننگ سلوشنز بنانے میں مدد کرتا ہے۔
چنگ وی لی ایمیزون ویب سروسز میں مشین لرننگ کا ماہر ہے۔ انہوں نے پی ایچ ڈی کی ڈگری حاصل کی۔ آپریشنز ریسرچ میں جب اس نے اپنے مشیر کے ریسرچ گرانٹ اکاؤنٹ کو توڑا اور نوبل انعام دینے میں ناکام رہے جس کا اس نے وعدہ کیا تھا۔ فی الحال وہ مالیاتی خدمات میں صارفین کو AWS پر مشین لرننگ سلوشنز بنانے میں مدد کرتا ہے۔
 راگھویندر آرنی AWS انڈسٹریز کے اندر کسٹمر ایکسلریشن ٹیم (CAT) کی قیادت کرتا ہے۔ CAT صارفین کی ایک عالمی کراس فنکشنل ٹیم ہے جو کلاؤڈ آرکیٹیکٹس، سافٹ ویئر انجینئرز، ڈیٹا سائنسدانوں، اور AI/ML ماہرین اور ڈیزائنرز کا سامنا کرتی ہے جو جدید پروٹو ٹائپنگ کے ذریعے جدت طرازی کرتی ہے، اور خصوصی تکنیکی مہارت کے ذریعے کلاؤڈ آپریشنل ایکسیلنس کو آگے بڑھاتی ہے۔
راگھویندر آرنی AWS انڈسٹریز کے اندر کسٹمر ایکسلریشن ٹیم (CAT) کی قیادت کرتا ہے۔ CAT صارفین کی ایک عالمی کراس فنکشنل ٹیم ہے جو کلاؤڈ آرکیٹیکٹس، سافٹ ویئر انجینئرز، ڈیٹا سائنسدانوں، اور AI/ML ماہرین اور ڈیزائنرز کا سامنا کرتی ہے جو جدید پروٹو ٹائپنگ کے ذریعے جدت طرازی کرتی ہے، اور خصوصی تکنیکی مہارت کے ذریعے کلاؤڈ آپریشنل ایکسیلنس کو آگے بڑھاتی ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

