آج، تمام صنعتوں کے گاہک- چاہے وہ مالیاتی خدمات، صحت کی دیکھ بھال اور لائف سائنسز، سفر اور مہمان نوازی، میڈیا اور تفریح، ٹیلی کمیونیکیشن، ایک سروس کے طور پر سافٹ ویئر (SaaS)، اور یہاں تک کہ ملکیتی ماڈل فراہم کرنے والے بھی- بڑے لینگویج ماڈلز (LLMs) استعمال کر رہے ہیں۔ سوال و جواب (QnA) چیٹ بوٹس، سرچ انجن، اور علم کی بنیاد جیسی ایپلی کیشنز بنائیں۔ یہ پیدا کرنے والا AI ایپلی کیشنز کا استعمال نہ صرف موجودہ کاروباری عمل کو خودکار بنانے کے لیے کیا جاتا ہے بلکہ ان میں یہ صلاحیت بھی ہوتی ہے کہ وہ ان ایپلی کیشنز کو استعمال کرنے والے صارفین کے لیے تجربے کو بدل دیں۔ جیسے ایل ایل ایم کے ساتھ پیشرفت کی جارہی ہے۔ Mixtral-8x7B ہدایاتآرکیٹیکچرز سے مشتق جیسے کہ ماہرین کا مرکب (MoE)، صارفین مسلسل AI ایپلی کیشنز کی کارکردگی اور درستگی کو بہتر بنانے کے طریقے تلاش کر رہے ہیں جبکہ انہیں بند اور اوپن سورس ماڈلز کی وسیع رینج کو مؤثر طریقے سے استعمال کرنے کی اجازت دے رہے ہیں۔
ایل ایل ایم کے آؤٹ پٹ کی درستگی اور کارکردگی کو بہتر بنانے کے لیے عام طور پر متعدد تکنیکوں کا استعمال کیا جاتا ہے، جیسے کہ اس کے ساتھ فائن ٹیوننگ پیرامیٹر موثر ٹھیک ٹیوننگ (PEFT), انسانی رائے سے کمک سیکھنا (RLHF)، اور کارکردگی کا مظاہرہ کر رہے ہیں۔ علم کشید. تاہم، تخلیقی AI ایپلی کیشنز بناتے وقت، آپ ایک متبادل حل استعمال کر سکتے ہیں جو بیرونی علم کو متحرک کرنے کی اجازت دیتا ہے اور آپ کو اپنے موجودہ بنیادی ماڈل کو ٹھیک کرنے کی ضرورت کے بغیر نسل کے لیے استعمال ہونے والی معلومات کو کنٹرول کرنے کی اجازت دیتا ہے۔ یہ وہ جگہ ہے جہاں Retrieval Augmented Generation (RAG) آتا ہے، خاص طور پر جنریٹیو AI ایپلی کیشنز کے لیے جو کہ ہم نے زیر بحث آنے والے زیادہ مہنگے اور مضبوط فائن ٹیوننگ متبادلات کے برخلاف ہے۔ اگر آپ اپنے روزمرہ کے کاموں میں پیچیدہ RAG ایپلی کیشنز کو لاگو کر رہے ہیں، تو آپ کو اپنے RAG سسٹمز کے ساتھ عام چیلنجوں کا سامنا کرنا پڑ سکتا ہے جیسے کہ غلط بازیافت، دستاویزات کے سائز اور پیچیدگی میں اضافہ، اور سیاق و سباق کا زیادہ بہاؤ، جو کہ پیدا کردہ جوابات کے معیار اور وشوسنییتا کو نمایاں طور پر متاثر کر سکتا ہے۔ .
یہ پوسٹ لینگ چین اور ٹولز کا استعمال کرتے ہوئے ردعمل کی درستگی کو بہتر بنانے کے لیے RAG پیٹرنز پر بحث کرتی ہے جیسے کہ سیاق و سباق کے کمپریشن جیسی تکنیکوں کے علاوہ پیرنٹ ڈاکومنٹ ریٹریور تاکہ ڈویلپرز کو موجودہ جنریٹو AI ایپلی کیشنز کو بہتر بنانے کے قابل بنایا جا سکے۔
حل جائزہ
اس پوسٹ میں، ہم BGE لارج این ایمبیڈنگ ماڈل کے ساتھ مل کر Mixtral-8x7B انسٹرکٹ ٹیکسٹ جنریشن کے استعمال کا مظاہرہ کرتے ہیں تاکہ پیرنٹ ڈاکیومنٹ ریٹریور ٹول اور سیاق و سباق کی کمپریشن تکنیک کا استعمال کرتے ہوئے Amazon SageMaker نوٹ بک پر RAG QnA سسٹم کو مؤثر طریقے سے بنایا جا سکے۔ مندرجہ ذیل خاکہ اس حل کے فن تعمیر کو واضح کرتا ہے۔
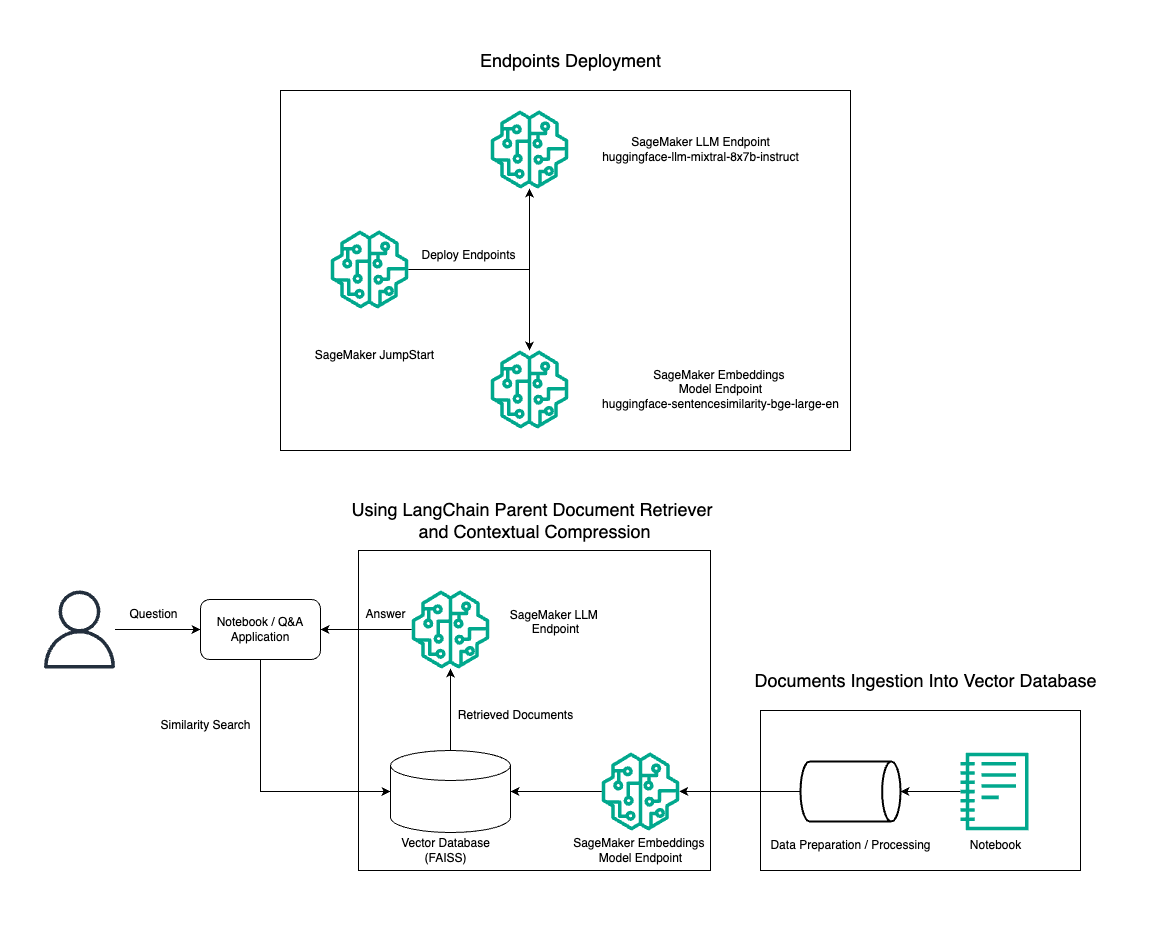
آپ اس حل کو صرف چند کلکس کا استعمال کرتے ہوئے تعینات کر سکتے ہیں۔ ایمیزون سیج میکر جمپ اسٹارٹ, ایک مکمل طور پر منظم پلیٹ فارم جو استعمال کے مختلف کیسز جیسے کہ مواد کی تحریر، کوڈ جنریشن، سوال جواب، کاپی رائٹنگ، خلاصہ، درجہ بندی، اور معلومات کی بازیافت کے لیے جدید ترین فاؤنڈیشن ماڈل پیش کرتا ہے۔ یہ پہلے سے تربیت یافتہ ماڈلز کا ایک مجموعہ فراہم کرتا ہے جسے آپ مشین لرننگ (ML) ایپلی کیشنز کی ترقی اور تعیناتی کو تیز کرتے ہوئے تیزی سے اور آسانی کے ساتھ تعینات کر سکتے ہیں۔ SageMaker JumpStart کے اہم اجزاء میں سے ایک ماڈل ہب ہے، جو پہلے سے تربیت یافتہ ماڈلز کی ایک وسیع کیٹلاگ پیش کرتا ہے، جیسے Mixtral-8x7B، مختلف کاموں کے لیے۔
Mixtral-8x7B ایک MoE فن تعمیر کا استعمال کرتا ہے۔ یہ فن تعمیر اعصابی نیٹ ورک کے مختلف حصوں کو مختلف کاموں میں مہارت حاصل کرنے کی اجازت دیتا ہے، مؤثر طریقے سے کام کے بوجھ کو متعدد ماہرین کے درمیان تقسیم کرتا ہے۔ یہ نقطہ نظر روایتی فن تعمیر کے مقابلے میں بڑے ماڈلز کی موثر تربیت اور تعیناتی کو قابل بناتا ہے۔
MoE فن تعمیر کے اہم فوائد میں سے ایک اس کی توسیع پذیری ہے۔ کام کے بوجھ کو متعدد ماہرین میں تقسیم کرکے، MoE ماڈلز کو بڑے ڈیٹا سیٹس پر تربیت دی جا سکتی ہے اور ایک ہی سائز کے روایتی ماڈلز سے بہتر کارکردگی حاصل کی جا سکتی ہے۔ مزید برآں، ایم او ای ماڈل تخمینہ کے دوران زیادہ کارآمد ثابت ہو سکتے ہیں کیونکہ دیے گئے ان پٹ کے لیے ماہرین کے صرف ایک ذیلی سیٹ کو چالو کرنے کی ضرورت ہے۔
AWS پر Mixtral-8x7B ہدایات کے بارے میں مزید معلومات کے لیے، رجوع کریں۔ Mixtral-8x7B اب Amazon SageMaker JumpStart میں دستیاب ہے۔. Mixtral-8x7B ماڈل اجازت دینے والے Apache 2.0 لائسنس کے تحت، بغیر کسی پابندی کے استعمال کے لیے دستیاب کرایا گیا ہے۔
اس پوسٹ میں، ہم اس بات پر تبادلہ خیال کرتے ہیں کہ آپ کس طرح استعمال کر سکتے ہیں۔ لینگ چین موثر اور زیادہ موثر RAG ایپلی کیشنز بنانے کے لیے۔ LangChain ایک اوپن سورس Python لائبریری ہے جسے LLMs کے ساتھ ایپلی کیشنز بنانے کے لیے ڈیزائن کیا گیا ہے۔ یہ ایک ماڈیولر اور لچکدار فریم ورک فراہم کرتا ہے تاکہ LLMs کو دوسرے اجزاء کے ساتھ ملایا جا سکے، جیسے کہ علمی بنیادوں، بازیافت کے نظام، اور دیگر AI ٹولز، طاقتور اور حسب ضرورت ایپلی کیشنز بنانے کے لیے۔
ہم Mixtral-8x7B کے ساتھ SageMaker پر RAG پائپ لائن کی تعمیر کے ذریعے چلتے ہیں۔ ہم SageMaker نوٹ بک پر RAG کا استعمال کرتے ہوئے ایک موثر QnA سسٹم بنانے کے لیے BGE Large En ایمبیڈنگ ماڈل کے ساتھ Mixtral-8x7B انسٹرکٹ ٹیکسٹ جنریشن ماڈل کا استعمال کرتے ہیں۔ ہم SageMaker JumpStart کے ذریعے LLMs کی تعیناتی کا مظاہرہ کرنے کے لیے ایک ml.t3.medium مثال استعمال کرتے ہیں، جس تک SageMaker کے ذریعے تیار کردہ API کے اختتامی نقطہ کے ذریعے رسائی حاصل کی جا سکتی ہے۔ یہ سیٹ اپ LangChain کے ساتھ RAG کی جدید تکنیکوں کی تلاش، تجربہ اور اصلاح کی اجازت دیتا ہے۔ ہم FAISS ایمبیڈنگ اسٹور کے RAG ورک فلو میں انضمام کی بھی مثال دیتے ہیں، سسٹم کی کارکردگی کو بڑھانے کے لیے ایمبیڈنگز کو اسٹور کرنے اور بازیافت کرنے میں اس کے کردار کو نمایاں کرتے ہیں۔
ہم SageMaker نوٹ بک کا ایک مختصر واک تھرو انجام دیتے ہیں۔ مزید تفصیلی اور مرحلہ وار ہدایات کے لیے، ملاحظہ کریں۔ سیج میکر جمپ اسٹارٹ گٹ ہب ریپو پر مکسٹرل کے ساتھ اعلی درجے کے آر اے جی پیٹرنز.
اعلی درجے کی RAG پیٹرن کی ضرورت
اعلی درجے کے RAG پیٹرن LLMs کی پروسیسنگ، سمجھنے، اور انسان نما متن بنانے میں موجودہ صلاحیتوں کو بہتر بنانے کے لیے ضروری ہیں۔ جیسے جیسے دستاویزات کے سائز اور پیچیدگی میں اضافہ ہوتا ہے، ایک ہی ایمبیڈنگ میں دستاویز کے متعدد پہلوؤں کی نمائندگی کرنا مخصوصیت کے نقصان کا باعث بن سکتا ہے۔ اگرچہ کسی دستاویز کے عمومی جوہر کو حاصل کرنا ضروری ہے، لیکن اس کے اندر مختلف ذیلی سیاق و سباق کو پہچاننا اور ان کی نمائندگی کرنا بھی اتنا ہی اہم ہے۔ یہ ایک چیلنج ہے جس کا آپ کو اکثر بڑے دستاویزات کے ساتھ کام کرتے وقت سامنا کرنا پڑتا ہے۔ RAG کے ساتھ ایک اور چیلنج یہ ہے کہ بازیافت کے ساتھ، آپ ان مخصوص سوالات سے واقف نہیں ہیں جن سے آپ کا دستاویز کا ذخیرہ کرنے والا نظام ادخال پر نمٹائے گا۔ یہ متن (سیاق و سباق کے اوور فلو) کے نیچے دفن ہونے والے استفسار سے متعلق معلومات کا باعث بن سکتا ہے۔ ناکامی کو کم کرنے اور موجودہ RAG فن تعمیر کو بہتر بنانے کے لیے، آپ بازیافت کی غلطیوں کو کم کرنے، جواب کے معیار کو بڑھانے، اور پیچیدہ سوالوں کو سنبھالنے کو فعال کرنے کے لیے اعلی درجے کی RAG پیٹرن (پینٹ دستاویز بازیافت اور سیاق و سباق کا کمپریشن) استعمال کر سکتے ہیں۔
اس پوسٹ میں زیر بحث تکنیکوں کے ساتھ، آپ بیرونی علم کی بازیافت اور انضمام سے منسلک کلیدی چیلنجوں سے نمٹ سکتے ہیں، جس سے آپ کی درخواست کو زیادہ درست اور سیاق و سباق سے آگاہ جوابات فراہم کرنے کے قابل بنایا جا سکتا ہے۔
مندرجہ ذیل حصوں میں، ہم دریافت کرتے ہیں کہ کیسے والدین دستاویز بازیافت کرنے والے اور سیاق و سباق کمپریشن کچھ مسائل سے نمٹنے میں آپ کی مدد کر سکتے ہیں جن پر ہم نے بات کی ہے۔
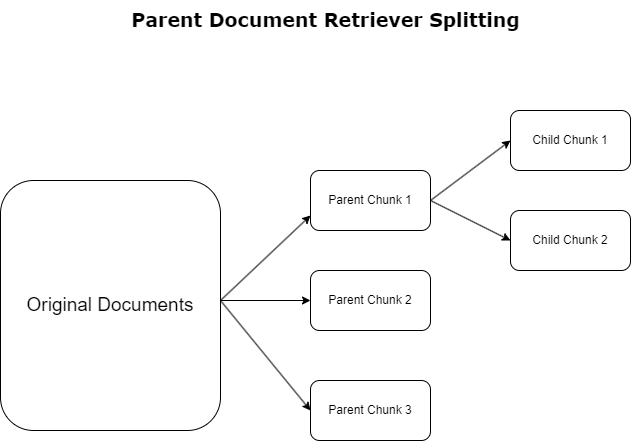
پیرنٹ دستاویز بازیافت کرنے والا
پچھلے حصے میں، ہم نے ان چیلنجوں پر روشنی ڈالی ہے جن کا سامنا RAG ایپلی کیشنز کو وسیع دستاویزات سے نمٹنے کے دوران ہوتا ہے۔ ان چیلنجوں سے نمٹنے کے لیے، والدین دستاویز بازیافت کرنے والے آنے والی دستاویزات کو درجہ بندی اور نامزد کریں۔ والدین کے دستاویزات. ان دستاویزات کو ان کی جامع نوعیت کی وجہ سے پہچانا جاتا ہے لیکن سرایت کرنے کے لیے ان کی اصل شکل میں براہ راست استعمال نہیں کیا جاتا ہے۔ ایک پوری دستاویز کو ایک ہی ایمبیڈنگ میں کمپریس کرنے کے بجائے، پیرنٹ ڈاکومنٹ بازیافت کرنے والے ان بنیادی دستاویزات کو بچے کی دستاویزات. ہر بچے کی دستاویز وسیع تر پیرنٹ دستاویز سے الگ الگ پہلوؤں یا موضوعات کو حاصل کرتی ہے۔ ان بچوں کے حصوں کی شناخت کے بعد، ہر ایک کو انفرادی سرایتیں تفویض کی جاتی ہیں، ان کے مخصوص موضوعی جوہر کو حاصل کرتے ہوئے (مندرجہ ذیل خاکہ دیکھیں)۔ بازیافت کے دوران، پیرنٹ دستاویز کو طلب کیا جاتا ہے۔ یہ تکنیک LLM کو ایک وسیع تناظر کے ساتھ پیش کرتے ہوئے، ہدف کے باوجود وسیع پیمانے پر تلاش کی صلاحیتیں فراہم کرتی ہے۔ والدین کی دستاویز بازیافت کرنے والے LLMs کو دوہرا فائدہ فراہم کرتے ہیں: درست اور متعلقہ معلومات کی بازیافت کے لیے چائلڈ ڈاکومنٹس کی ایمبیڈنگز کی خصوصیت، جوابی تیاری کے لیے والدین کی دستاویزات کی درخواست کے ساتھ، جو LLM کے نتائج کو تہہ دار اور مکمل سیاق و سباق کے ساتھ افزودہ کرتی ہے۔
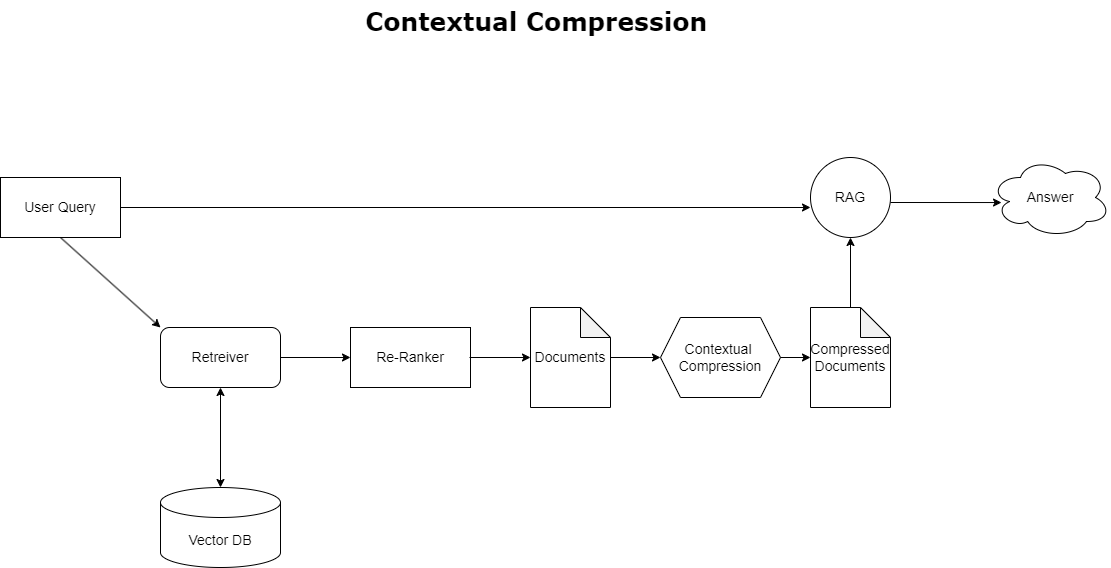
سیاق و سباق کا کمپریشن
پہلے زیر بحث سیاق و سباق کے بہاؤ کے مسئلے کو حل کرنے کے لیے، آپ استعمال کر سکتے ہیں۔ سیاق و سباق کمپریشن استفسار کے سیاق و سباق کے ساتھ سیدھ میں حاصل شدہ دستاویزات کو کمپریس اور فلٹر کرنے کے لیے، اس لیے صرف متعلقہ معلومات کو رکھا جاتا ہے اور اس پر کارروائی کی جاتی ہے۔ یہ ابتدائی دستاویز کی بازیافت کے لیے ایک بیس ریٹریور اور ان دستاویزات کو بہتر بنانے کے لیے ایک دستاویز کمپریسر کے امتزاج کے ذریعے حاصل کیا جاتا ہے تاکہ ان کے مواد کو کم کر کے یا انہیں مکمل طور پر مطابقت کی بنیاد پر خارج کر دیا جا سکے، جیسا کہ مندرجہ ذیل خاکہ میں واضح کیا گیا ہے۔ یہ ہموار طریقہ کار، سیاق و سباق کے کمپریشن ریٹریور کے ذریعے سہولت فراہم کرتا ہے، RAG ایپلیکیشن کی کارکردگی کو بہت زیادہ معلومات کے بڑے پیمانے پر صرف نکالنے اور استعمال کرنے کا طریقہ فراہم کرتا ہے۔ یہ معلومات کے اوورلوڈ اور غیر متعلقہ ڈیٹا پروسیسنگ کے مسئلے سے نمٹتا ہے، جس کے نتیجے میں رسپانس کا معیار بہتر ہوتا ہے، زیادہ سرمایہ کاری مؤثر LLM آپریشنز، اور ایک ہموار مجموعی طور پر بازیافت کا عمل ہوتا ہے۔ بنیادی طور پر، یہ ایک ایسا فلٹر ہے جو معلومات کو ہاتھ میں موجود استفسار کے مطابق تیار کرتا ہے، جو اسے بہتر کارکردگی اور صارف کی اطمینان کے لیے اپنی RAG ایپلی کیشنز کو بہتر بنانے کے لیے ڈویلپرز کے لیے ایک انتہائی ضروری ٹول بناتا ہے۔
شرائط
اگر آپ سیج میکر میں نئے ہیں، تو دیکھیں ایمیزون سیج میکر ڈویلپمنٹ گائیڈ.
حل کے ساتھ شروع کرنے سے پہلے، AWS اکاؤنٹ بنائیں. جب آپ AWS اکاؤنٹ بناتے ہیں، تو آپ کو ایک واحد سائن آن (SSO) شناخت ملتی ہے جسے اکاؤنٹ میں موجود تمام AWS سروسز اور وسائل تک مکمل رسائی حاصل ہوتی ہے۔ اس شناخت کو AWS اکاؤنٹ کہا جاتا ہے۔ جڑ صارف.
میں سائن ان کرنا AWS مینجمنٹ کنسول ای میل ایڈریس اور پاس ورڈ کا استعمال کرتے ہوئے جو آپ نے اکاؤنٹ بنانے کے لیے استعمال کیا تھا آپ کو اپنے اکاؤنٹ میں موجود تمام AWS وسائل تک مکمل رسائی فراہم کرتا ہے۔ ہم پرزور مشورہ دیتے ہیں کہ آپ روٹ یوزر کو روزمرہ کے کاموں، حتیٰ کہ انتظامی کاموں کے لیے بھی استعمال نہ کریں۔
اس کے بجائے، پر عمل کریں سیکورٹی کے بہترین طریقوں in AWS شناخت اور رسائی کا انتظام (IAM)، اور ایک انتظامی صارف اور گروپ بنائیں. اس کے بعد روٹ صارف کی اسناد کو محفوظ طریقے سے مقفل کریں اور انہیں صرف اکاؤنٹ اور سروس کے انتظام کے چند کام انجام دینے کے لیے استعمال کریں۔
Mixtral-8x7b ماڈل کو ml.g5.48xlarge مثال درکار ہے۔ SageMaker JumpStart 100 سے زیادہ مختلف اوپن سورس اور تھرڈ پارٹی فاؤنڈیشن ماڈلز تک رسائی اور تعینات کرنے کا ایک آسان طریقہ فراہم کرتا ہے۔ کرنے کے لئے SageMaker JumpStart سے Mixtral-8x7B کی میزبانی کے لیے ایک اینڈ پوائنٹ لانچ کریں۔، آپ کو اختتامی نقطہ کے استعمال کے لیے ml.g5.48xlarge مثال تک رسائی حاصل کرنے کے لیے سروس کوٹہ میں اضافے کی درخواست کرنے کی ضرورت پڑ سکتی ہے۔ آپ کر سکتے ہیں۔ سروس کوٹہ بڑھانے کی درخواست کریں۔ کنسول کے ذریعے، AWS کمانڈ لائن انٹرفیس (AWS CLI)، یا API ان اضافی وسائل تک رسائی کی اجازت دینے کے لیے۔
سیج میکر نوٹ بک مثال قائم کریں اور انحصار انسٹال کریں۔
شروع کرنے کے لیے، SageMaker نوٹ بک مثال بنائیں اور مطلوبہ انحصار انسٹال کریں۔ سے رجوع کریں۔ GitHub repo ایک کامیاب سیٹ اپ کو یقینی بنانے کے لیے۔ نوٹ بک مثال قائم کرنے کے بعد، آپ ماڈل کو تعینات کر سکتے ہیں۔
آپ اپنے ترجیحی مربوط ترقیاتی ماحول (IDE) پر مقامی طور پر نوٹ بک بھی چلا سکتے ہیں۔ یقینی بنائیں کہ آپ کے پاس Jupyter نوٹ بک لیب انسٹال ہے۔
ماڈل تعینات کریں۔
Mixtral-8X7B Instruct LLM ماڈل کو SageMaker JumpStart پر تعینات کریں:
SageMaker JumpStart پر BGE Large En ایمبیڈنگ ماڈل کو تعینات کریں:
LangChain مرتب کریں۔
تمام ضروری لائبریریوں کو درآمد کرنے اور Mixtral-8x7B ماڈل اور BGE Large En embeddings ماڈل کو تعینات کرنے کے بعد، آپ اب LangChain ترتیب دے سکتے ہیں۔ مرحلہ وار ہدایات کے لیے، ملاحظہ کریں۔ GitHub repo.
ڈیٹا کی تیاری
اس پوسٹ میں، ہم QnA کو انجام دینے کے لیے شیئر ہولڈرز کے لیے ایمیزون کے کئی سالوں کے خطوط کو بطور ٹیکسٹ کارپس استعمال کرتے ہیں۔ ڈیٹا تیار کرنے کے مزید تفصیلی اقدامات کے لیے، ملاحظہ کریں۔ GitHub repo.
سوال جواب
ڈیٹا تیار ہونے کے بعد، آپ LangChain کی طرف سے فراہم کردہ ریپر استعمال کر سکتے ہیں، جو ویکٹر اسٹور کے گرد لپیٹ کر LLM کے لیے ان پٹ لیتا ہے۔ یہ ریپر مندرجہ ذیل اقدامات انجام دیتا ہے:
- ان پٹ سوال لیں۔
- ایک سوال ایمبیڈنگ بنائیں۔
- متعلقہ دستاویزات حاصل کریں۔
- دستاویزات اور سوال کو پرامپٹ میں شامل کریں۔
- پرامپٹ کے ساتھ ماڈل کو طلب کریں اور پڑھنے کے قابل انداز میں جواب تیار کریں۔
اب جبکہ ویکٹر اسٹور موجود ہے، آپ سوالات پوچھنا شروع کر سکتے ہیں:
باقاعدہ بازیافت کا سلسلہ
پچھلے منظر نامے میں، ہم نے آپ کے سوال کا سیاق و سباق سے آگاہ جواب حاصل کرنے کا تیز اور سیدھا طریقہ تلاش کیا۔ اب آئیے RetrievalQA کی مدد سے مزید حسب ضرورت آپشن کو دیکھتے ہیں، جہاں آپ اپنی مرضی کے مطابق کر سکتے ہیں کہ کس طرح حاصل کی گئی دستاویزات کو chain_type پیرامیٹر کا استعمال کرتے ہوئے پرامپٹ میں شامل کیا جائے۔ اس کے علاوہ، یہ کنٹرول کرنے کے لیے کہ کتنے متعلقہ دستاویزات کو بازیافت کیا جانا چاہیے، آپ مختلف آؤٹ پٹ دیکھنے کے لیے درج ذیل کوڈ میں k پیرامیٹر کو تبدیل کر سکتے ہیں۔ بہت سے منظرناموں میں، آپ یہ جاننا چاہیں گے کہ LLM نے جواب تیار کرنے کے لیے کون سے ماخذ دستاویزات کا استعمال کیا۔ آپ ان دستاویزات کو استعمال کرکے آؤٹ پٹ میں حاصل کرسکتے ہیں۔ return_source_documents، جو LLM پرامپٹ کے سیاق و سباق میں شامل کردہ دستاویزات کو واپس کرتا ہے۔ RetrievalQA آپ کو ایک حسب ضرورت پرامپٹ ٹیمپلیٹ فراہم کرنے کی بھی اجازت دیتا ہے جو ماڈل کے لیے مخصوص ہو سکتا ہے۔
آئیے ایک سوال پوچھتے ہیں:
پیرنٹ دستاویز بازیافت کرنے والا سلسلہ
کی مدد سے ایک زیادہ جدید RAG آپشن کو دیکھتے ہیں۔ Parent DocumentRetriever. دستاویز کی بازیافت کے ساتھ کام کرتے وقت، آپ کو درست سرایت کے لیے دستاویز کے چھوٹے حصوں کو ذخیرہ کرنے اور مزید سیاق و سباق کو محفوظ رکھنے کے لیے بڑی دستاویزات کے درمیان تجارت کا سامنا کرنا پڑ سکتا ہے۔ بنیادی دستاویز بازیافت کرنے والا ڈیٹا کے چھوٹے ٹکڑوں کو تقسیم اور ذخیرہ کرکے اس توازن کو ختم کرتا ہے۔
ہم ایک استعمال کرتے ہیں parent_splitter اصل دستاویزات کو بڑے ٹکڑوں میں تقسیم کرنا جسے پیرنٹ دستاویزات کہتے ہیں اور a child_splitter اصل دستاویزات سے چھوٹے بچوں کے دستاویزات بنانے کے لیے:
چائلڈ دستاویزات کو پھر ایمبیڈنگ کا استعمال کرتے ہوئے ویکٹر اسٹور میں انڈیکس کیا جاتا ہے۔ یہ مماثلت کی بنیاد پر متعلقہ چائلڈ دستاویزات کی موثر بازیافت کے قابل بناتا ہے۔ متعلقہ معلومات کو بازیافت کرنے کے لیے، پیرنٹ ڈاکومنٹ بازیافت کرنے والا پہلے بچے کی دستاویزات کو ویکٹر اسٹور سے لاتا ہے۔ اس کے بعد یہ ان بچوں کی دستاویزات کے لیے والدین کی شناخت تلاش کرتا ہے اور متعلقہ بڑے والدین کے دستاویزات کو واپس کرتا ہے۔
آئیے ایک سوال پوچھتے ہیں:
سیاق و سباق کی کمپریشن چین
آئیے ایک اور اعلی درجے کی RAG آپشن کو دیکھتے ہیں جسے کہا جاتا ہے۔ سیاق و سباق کمپریشن. بازیافت کے ساتھ ایک چیلنج یہ ہے کہ عام طور پر ہم نہیں جانتے کہ جب آپ سسٹم میں ڈیٹا داخل کرتے ہیں تو آپ کے دستاویز کے اسٹوریج سسٹم کو ان مخصوص سوالات کا سامنا کرنا پڑے گا۔ اس کا مطلب یہ ہے کہ استفسار سے متعلق سب سے زیادہ متعلقہ معلومات کو بہت سارے غیر متعلقہ متن کے ساتھ دستاویز میں دفن کیا جاسکتا ہے۔ اس مکمل دستاویز کو آپ کی درخواست کے ذریعے پاس کرنا زیادہ مہنگی LLM کالز اور غریب جوابات کا باعث بن سکتا ہے۔
سیاق و سباق کی کمپریشن بازیافت دستاویز کے ذخیرہ کرنے والے نظام سے متعلقہ معلومات کی بازیافت کے چیلنج سے نمٹتی ہے، جہاں متعلقہ ڈیٹا کو بہت سارے متن پر مشتمل دستاویزات میں دفن کیا جاسکتا ہے۔ دیے گئے استفسار کے سیاق و سباق کی بنیاد پر بازیافت شدہ دستاویزات کو کمپریس اور فلٹر کرنے سے، صرف انتہائی متعلقہ معلومات واپس کی جاتی ہیں۔
سیاق و سباق کے کمپریشن بازیافت کو استعمال کرنے کے لیے، آپ کو ضرورت ہوگی:
- ایک بیس بازیافت - یہ ابتدائی بازیافت ہے جو استفسار کی بنیاد پر اسٹوریج سسٹم سے دستاویزات حاصل کرتا ہے۔
- ایک دستاویز کمپریسر - یہ جزو ابتدائی طور پر حاصل شدہ دستاویزات کو لیتا ہے اور انفرادی دستاویزات کے مواد کو کم کرکے یا غیر متعلقہ دستاویزات کو یکسر چھوڑ کر، استفسار کے سیاق و سباق کا استعمال کرتے ہوئے مطابقت کا تعین کر کے انہیں مختصر کرتا ہے۔
ایل ایل ایم چین ایکسٹریکٹر کے ساتھ سیاق و سباق کا کمپریشن شامل کرنا
سب سے پہلے، اپنے بیس ریٹریور کو a کے ساتھ لپیٹیں۔ ContextualCompressionRetriever. آپ ایک شامل کریں گے۔ ایل ایل ایم چین ایکسٹریکٹر، جو ابتدائی طور پر واپس کی گئی دستاویزات پر اعادہ کرے گا اور ہر ایک سے صرف وہی مواد نکالے گا جو استفسار سے متعلق ہے۔
کا استعمال کرتے ہوئے سلسلہ شروع کریں۔ ContextualCompressionRetriever کے ساتھ ایک LLMChainExtractor اور کے ذریعے پرامپٹ پاس کریں۔ chain_type_kwargs دلیل.
آئیے ایک سوال پوچھتے ہیں:
LLM چین فلٹر کے ساتھ دستاویزات کو فلٹر کریں۔
۔ ایل ایل ایم چین فلٹر ایک قدرے آسان لیکن زیادہ مضبوط کمپریسر ہے جو یہ فیصلہ کرنے کے لیے LLM چین کا استعمال کرتا ہے کہ ابتدائی طور پر حاصل کی گئی دستاویزات میں سے کن کو فلٹر کرنا ہے اور کن کو واپس کرنا ہے، بغیر دستاویز کے مواد میں ہیرا پھیری کیے:
کا استعمال کرتے ہوئے سلسلہ شروع کریں۔ ContextualCompressionRetriever کے ساتھ ایک LLMChainFilter اور کے ذریعے پرامپٹ پاس کریں۔ chain_type_kwargs دلیل.
آئیے ایک سوال پوچھتے ہیں:
نتائج کا موازنہ کریں۔
درج ذیل جدول تکنیک کی بنیاد پر مختلف سوالات کے نتائج کا موازنہ کرتا ہے۔
| تکنیک | سوال 1 | سوال 2 | موازنہ |
| AWS کیسے تیار ہوا؟ | ایمیزون کامیاب کیوں ہے؟ | ||
| ریگولر ریٹریور چین آؤٹ پٹ | AWS (Amazon Web Services) ابتدائی طور پر غیر منافع بخش سرمایہ کاری سے $85B کے سالانہ ریونیو رن ریٹ کے کاروبار میں مضبوط منافع کے ساتھ تیار ہوا، وسیع رینج کی خدمات اور خصوصیات پیش کرتا ہے، اور Amazon کے پورٹ فولیو کا ایک اہم حصہ بنتا ہے۔ شکوک و شبہات اور قلیل مدتی مشکلات کا سامنا کرنے کے باوجود، AWS نے جدت پیدا کرنا، نئے گاہکوں کو راغب کرنا، اور فعال صارفین کو منتقل کرنا جاری رکھا، جو کہ چستی، اختراع، لاگت کی کارکردگی، اور سیکورٹی جیسے فوائد کی پیشکش کرتا ہے۔ AWS نے نئی صلاحیتیں فراہم کرنے اور اپنے صارفین کے لیے جو کچھ ممکن ہے اسے تبدیل کرنے کے لیے اپنی طویل مدتی سرمایہ کاری کو بھی بڑھایا، بشمول چپ ڈیولپمنٹ۔ | ایمیزون اپنی مسلسل جدت اور نئے شعبوں جیسے ٹیکنالوجی کے بنیادی ڈھانچے کی خدمات، ڈیجیٹل ریڈنگ ڈیوائسز، آواز سے چلنے والے پرسنل اسسٹنٹس، اور تھرڈ پارٹی مارکیٹ پلیس جیسے نئے کاروباری ماڈلز میں توسیع کی وجہ سے کامیاب ہے۔ آپریشنز کو تیزی سے پیمانہ کرنے کی اس کی صلاحیت، جیسا کہ اس کی تکمیل اور نقل و حمل کے نیٹ ورک کی تیزی سے توسیع میں دیکھا گیا ہے، اس کی کامیابی میں بھی اہم کردار ادا کرتا ہے۔ مزید برآں، ایمیزون کی توجہ اپنے عمل میں اصلاح اور کارکردگی کے حصول پر مرکوز کرنے کے نتیجے میں پیداواری صلاحیت میں بہتری اور لاگت میں کمی آئی ہے۔ ایمیزون بزنس کی مثال کمپنی کی مختلف شعبوں میں اپنی ای کامرس اور لاجسٹک طاقتوں سے فائدہ اٹھانے کی صلاحیت کو اجاگر کرتی ہے۔ | باقاعدگی سے بازیافت کرنے والے سلسلہ کے جوابات کی بنیاد پر، ہم نے محسوس کیا کہ اگرچہ یہ طویل جوابات فراہم کرتا ہے، لیکن یہ سیاق و سباق کے زیادہ بہاؤ کا شکار ہے اور فراہم کردہ استفسار کا جواب دینے کے سلسلے میں کارپس سے کسی بھی اہم تفصیلات کا ذکر کرنے میں ناکام رہتا ہے۔ باقاعدہ بازیافت کا سلسلہ گہرائی یا سیاق و سباق کی بصیرت کے ساتھ باریکیوں کو حاصل کرنے کے قابل نہیں ہے، ممکنہ طور پر دستاویز کے اہم پہلوؤں سے محروم ہے۔ |
| پیرنٹ ڈاکومنٹ ریٹریور آؤٹ پٹ | AWS (Amazon Web Services) کا آغاز 2 میں ایلسٹک کمپیوٹ کلاؤڈ (EC2006) سروس کے فیچر کے ساتھ ناقص ابتدائی آغاز کے ساتھ ہوا، جس میں صرف ایک ڈیٹا سینٹر میں، دنیا کے ایک خطے میں، صرف لینکس آپریٹنگ سسٹم کی مثالوں کے ساتھ ایک مثال کا سائز فراہم کیا گیا۔ ، اور بہت سی اہم خصوصیات کے بغیر جیسے مانیٹرنگ، لوڈ بیلنسنگ، آٹو اسکیلنگ، یا مستقل اسٹوریج۔ تاہم، AWS کی کامیابی نے انہیں تیزی سے دہرانے اور گمشدہ صلاحیتوں کو شامل کرنے کی اجازت دی، آخر کار مختلف ذائقوں، سائزز، اور کمپیوٹ، اسٹوریج، اور نیٹ ورکنگ کی اصلاح کی پیشکش کرنے کے ساتھ ساتھ قیمت اور کارکردگی کو مزید آگے بڑھانے کے لیے اپنی چپس (گریویٹن) تیار کرنے کی اجازت دی۔ . AWS کے تکراری جدت طرازی کے عمل کو 20 سالوں کے دوران مالیاتی اور عوامی وسائل میں اہم سرمایہ کاری کی ضرورت ہوتی ہے، اکثر اس سے پہلے کہ وہ ادائیگی کب کرے گی، تاکہ کسٹمر کی ضروریات کو پورا کیا جا سکے اور طویل مدتی کسٹمر کے تجربات، وفاداری اور شیئر ہولڈرز کے لیے منافع کو بہتر بنایا جا سکے۔ | ایمیزون مسلسل اختراع کرنے، مارکیٹ کے بدلتے ہوئے حالات کے مطابق ڈھالنے اور مختلف مارکیٹ کے حصوں میں صارفین کی ضروریات کو پورا کرنے کی صلاحیت کی وجہ سے کامیاب ہے۔ یہ Amazon Business کی کامیابی سے ظاہر ہوتا ہے، جس نے کاروباری صارفین کو انتخاب، قدر اور سہولت فراہم کر کے سالانہ مجموعی فروخت میں تقریباً $35B کا اضافہ کیا ہے۔ ای کامرس اور لاجسٹکس کی صلاحیتوں میں ایمیزون کی سرمایہ کاری نے پرائم کے ساتھ خریدو جیسی خدمات کی تخلیق کو بھی قابل بنایا ہے، جو براہ راست صارف سے صارفین کی ویب سائٹس والے تاجروں کو آراء سے خریداری میں تبدیلی لانے میں مدد کرتی ہے۔ | بنیادی دستاویز بازیافت کرنے والا AWS کی ترقی کی حکمت عملی کی تفصیلات میں مزید گہرائی سے اترتا ہے، بشمول صارفین کے تاثرات کی بنیاد پر نئی خصوصیات شامل کرنے کا تکراری عمل اور خصوصیت سے محروم ابتدائی لانچ سے غالب مارکیٹ پوزیشن تک کا تفصیلی سفر، جبکہ سیاق و سباق سے بھرپور جواب فراہم کرتا ہے۔ . جوابات تکنیکی اختراعات اور مارکیٹ کی حکمت عملی سے لے کر تنظیمی کارکردگی اور کسٹمر فوکس تک وسیع پیمانے پر پہلوؤں کا احاطہ کرتے ہیں، مثالوں کے ساتھ کامیابی میں کردار ادا کرنے والے عوامل کا ایک جامع نظریہ فراہم کرتے ہیں۔ یہ پیرنٹ دستاویز بازیافت کرنے والے کی ہدف شدہ ابھی تک وسیع پیمانے پر تلاش کی صلاحیتوں سے منسوب کیا جاسکتا ہے۔ |
| ایل ایل ایم چین ایکسٹریکٹر: سیاق و سباق کمپریشن آؤٹ پٹ | AWS ایمیزون کے اندر ایک چھوٹے پروجیکٹ کے طور پر شروع کر کے تیار ہوا، جس میں اہم سرمایہ کاری کی ضرورت ہوتی ہے اور کمپنی کے اندر اور باہر دونوں طرف سے شکوک و شبہات کا سامنا کرنا پڑتا ہے۔ تاہم، AWS نے ممکنہ حریفوں کے بارے میں ایک اہم آغاز کیا تھا اور وہ اس قدر پر یقین رکھتا تھا جو یہ گاہکوں اور Amazon کو لا سکتا ہے۔ AWS نے سرمایہ کاری جاری رکھنے کا ایک طویل مدتی عہد کیا، جس کے نتیجے میں 3,300 میں 2022 سے زیادہ نئی خصوصیات اور خدمات شروع کی گئیں۔ AWS نے تبدیل کر دیا ہے کہ کس طرح صارفین اپنے ٹیکنالوجی کے بنیادی ڈھانچے کا انتظام کرتے ہیں اور مضبوط منافع کے ساتھ $85B سالانہ ریونیو رن ریٹ کاروبار بن گیا ہے۔ AWS نے اپنی پیشکشوں میں بھی مسلسل بہتری لائی ہے، جیسے کہ اپنے ابتدائی آغاز کے بعد اضافی خصوصیات اور خدمات کے ساتھ EC2 کو بڑھانا۔ | فراہم کردہ سیاق و سباق کی بنیاد پر، Amazon کی کامیابی کو کتاب فروخت کرنے والے پلیٹ فارم سے ایک متحرک تھرڈ پارٹی سیلر ایکو سسٹم کے ساتھ عالمی مارکیٹ میں اس کی اسٹریٹجک توسیع، AWS میں ابتدائی سرمایہ کاری، Kindle اور Alexa کو متعارف کرانے میں جدت، اور خاطر خواہ ترقی سے منسوب کیا جا سکتا ہے۔ 2019 سے 2022 تک کی سالانہ آمدنی میں۔ اس نمو کے نتیجے میں تکمیلی مرکز کے نقش کی توسیع، آخری میل کے نقل و حمل کے نیٹ ورک کی تخلیق، اور ایک نئے ترتیب دینے والے مرکز کے نیٹ ورک کی تعمیر کا باعث بنی، جو پیداواری صلاحیت اور لاگت میں کمی کے لیے موزوں تھے۔ | ایل ایل ایم چین ایکسٹریکٹر کلیدی نکات کو جامع طور پر کور کرنے اور غیر ضروری گہرائی سے بچنے کے درمیان توازن برقرار رکھتا ہے۔ یہ متحرک طور پر استفسار کے سیاق و سباق سے مطابقت رکھتا ہے، لہذا آؤٹ پٹ براہ راست متعلقہ اور جامع ہے۔ |
| ایل ایل ایم چین فلٹر: سیاق و سباق کمپریشن آؤٹ پٹ | AWS (Amazon Web Services) ابتدائی طور پر فیچر ناقص لانچ کر کے تیار ہوا لیکن ضروری صلاحیتوں کو شامل کرنے کے لیے کسٹمر کے تاثرات کی بنیاد پر تیزی سے دہرایا گیا۔ اس نقطہ نظر نے AWS کو 2 میں EC2006 کو محدود خصوصیات کے ساتھ لانچ کرنے کی اجازت دی اور پھر مسلسل نئی خصوصیات شامل کیں، جیسے اضافی مثال کے سائز، ڈیٹا سینٹرز، ریجنز، آپریٹنگ سسٹم کے اختیارات، مانیٹرنگ ٹولز، لوڈ بیلنسنگ، آٹو اسکیلنگ، اور مستقل اسٹوریج۔ وقت گزرنے کے ساتھ، AWS کسٹمر کی ضروریات، چستی، اختراع، لاگت کی کارکردگی، اور سیکورٹی پر توجہ مرکوز کرتے ہوئے ایک خصوصیت سے محروم سروس سے اربوں ڈالر کے کاروبار میں تبدیل ہو گیا۔ AWS کے پاس اب $85B کا سالانہ ریونیو رن ریٹ ہے اور یہ ہر سال 3,300 سے زیادہ نئی خصوصیات اور خدمات پیش کرتا ہے، جو اسٹارٹ اپس سے لے کر ملٹی نیشنل کمپنیوں اور پبلک سیکٹر کی تنظیموں تک وسیع پیمانے پر صارفین کو پورا کرتا ہے۔ | ایمیزون اپنے جدید کاروباری ماڈلز، مسلسل تکنیکی ترقی، اور اسٹریٹجک تنظیمی تبدیلیوں کی وجہ سے کامیاب ہے۔ کمپنی نے نئے آئیڈیاز متعارف کروا کر روایتی صنعتوں کو مستقل طور پر متاثر کیا ہے، جیسے کہ مختلف مصنوعات اور خدمات کے لیے ایک ای کامرس پلیٹ فارم، ایک تھرڈ پارٹی مارکیٹ پلیس، کلاؤڈ انفراسٹرکچر سروسز (AWS)، Kindle e-reader، اور Alexa وائس سے چلنے والا پرسنل اسسٹنٹ۔ . مزید برآں، Amazon نے اپنی کارکردگی کو بہتر بنانے کے لیے ساختی تبدیلیاں کی ہیں، جیسے کہ لاگت اور ترسیل کے اوقات کو کم کرنے کے لیے اپنے امریکی تکمیلی نیٹ ورک کو دوبارہ منظم کرنا، اس کی کامیابی میں مزید معاون ہے۔ | LLM چین ایکسٹریکٹر کی طرح، LLM چین فلٹر اس بات کو یقینی بناتا ہے کہ اگرچہ اہم نکات کا احاطہ کیا گیا ہے، لیکن آؤٹ پٹ ان صارفین کے لیے موثر ہے جو جامع اور سیاق و سباق کے جوابات تلاش کر رہے ہیں۔ |
ان مختلف تکنیکوں کا موازنہ کرنے پر، ہم دیکھ سکتے ہیں کہ AWS کی ایک سادہ سروس سے ایک پیچیدہ، ملٹی بلین ڈالر کی ہستی میں منتقلی کی تفصیل، یا Amazon کی اسٹریٹجک کامیابیوں کی وضاحت کرنے جیسے سیاق و سباق میں، ریگولر ریٹریور چین میں درستگی کا فقدان ہے جتنی جدید ترین تکنیکیں پیش کرتی ہیں، کم ھدف شدہ معلومات کی طرف جاتا ہے. اگرچہ زیر بحث جدید تکنیکوں کے درمیان بہت کم فرق نظر آتے ہیں، لیکن وہ باقاعدہ بازیافت کی زنجیروں سے کہیں زیادہ معلوماتی ہیں۔
صحت کی دیکھ بھال، ٹیلی کمیونیکیشن، اور مالیاتی خدمات جیسی صنعتوں کے صارفین کے لیے جو اپنی ایپلی کیشنز میں RAG کو لاگو کرنے کے خواہاں ہیں، درستگی فراہم کرنے، فالتو پن سے بچنے، اور معلومات کو مؤثر طریقے سے کمپریس کرنے میں باقاعدہ بازیافت کی حدود کی وجہ سے ان ضروریات کو پورا کرنے کے مقابلے میں یہ کم موزوں ہے۔ زیادہ جدید پیرنٹ دستاویز بازیافت کرنے اور سیاق و سباق کے کمپریشن تکنیکوں تک۔ قیمت کی کارکردگی کو بہتر بنانے میں مدد کرتے ہوئے، یہ تکنیکیں آپ کو درکار متمرکز، اثر انگیز بصیرت میں وسیع مقدار میں معلومات حاصل کرنے کے قابل ہیں۔
صاف کرو
نوٹ بک چلانے کے بعد، استعمال میں آنے والے وسائل کے چارجز کی وصولی سے بچنے کے لیے اپنے بنائے گئے وسائل کو حذف کر دیں:
نتیجہ
اس پوسٹ میں، ہم نے ایک ایسا حل پیش کیا ہے جو آپ کو LLMs کی معلومات کو پروسیس کرنے اور تیار کرنے کی صلاحیت کو بڑھانے کے لیے پیرنٹ ڈاکومنٹ ریٹریور اور سیاق و سباق کے کمپریشن چین تکنیک کو لاگو کرنے کی اجازت دیتا ہے۔ ہم نے SageMaker JumpStart کے ساتھ دستیاب Mixtral-8x7B Instruct اور BGE Large En ماڈلز کے ساتھ RAG کی ان جدید تکنیکوں کا تجربہ کیا۔ ہم نے ایمبیڈنگز اور دستاویز کے ٹکڑوں اور انٹرپرائز ڈیٹا اسٹورز کے ساتھ انضمام کے لیے مستقل اسٹوریج کا استعمال کرتے ہوئے بھی دریافت کیا۔
ہم نے جو تکنیکیں انجام دی ہیں وہ نہ صرف ایل ایل ایم ماڈلز تک رسائی اور بیرونی علم کو شامل کرنے کے طریقے کو بہتر کرتی ہیں بلکہ ان کے نتائج کے معیار، مطابقت اور کارکردگی کو بھی نمایاں طور پر بہتر کرتی ہیں۔ لینگویج جنریشن کی صلاحیتوں کے ساتھ بڑے ٹیکسٹ کارپورا سے بازیافت کو جوڑ کر، یہ جدید RAG تکنیک LLMs کو مزید حقائق پر مبنی، مربوط اور سیاق و سباق کے مطابق مناسب ردعمل پیدا کرنے کے قابل بناتی ہے، جس سے مختلف قدرتی زبان کی پروسیسنگ کے کاموں میں ان کی کارکردگی میں اضافہ ہوتا ہے۔
سیج میکر جمپ اسٹارٹ اس حل کے مرکز میں ہے۔ SageMaker JumpStart کے ساتھ، آپ اوپن اور کلوز سورس ماڈلز کی وسیع درجہ بندی تک رسائی حاصل کرتے ہیں، ML کے ساتھ شروع کرنے کے عمل کو ہموار کرتے ہوئے اور تیز تجربہ اور تعیناتی کو فعال کرتے ہیں۔ اس حل کی تعیناتی شروع کرنے کے لیے، میں نوٹ بک پر جائیں۔ GitHub repo.
مصنفین کے بارے میں
 نیتین وجیاسوارن AWS میں ایک حل آرکیٹیکٹ ہے۔ اس کی توجہ کا مرکز جنریٹو AI اور AWS AI ایکسلریٹر ہے۔ انہوں نے کمپیوٹر سائنس اور بائیو انفارمیٹکس میں بیچلر کی ڈگری حاصل کی ہے۔ Niithiyn جنریٹو AI GTM ٹیم کے ساتھ مل کر کام کرتا ہے تاکہ AWS صارفین کو متعدد محاذوں پر فعال کیا جا سکے اور ان کے جنریٹو AI کو اپنانے کو تیز کیا جا سکے۔ وہ ڈلاس ماویرکس کا شوقین پرستار ہے اور جوتے جمع کرنے سے لطف اندوز ہوتا ہے۔
نیتین وجیاسوارن AWS میں ایک حل آرکیٹیکٹ ہے۔ اس کی توجہ کا مرکز جنریٹو AI اور AWS AI ایکسلریٹر ہے۔ انہوں نے کمپیوٹر سائنس اور بائیو انفارمیٹکس میں بیچلر کی ڈگری حاصل کی ہے۔ Niithiyn جنریٹو AI GTM ٹیم کے ساتھ مل کر کام کرتا ہے تاکہ AWS صارفین کو متعدد محاذوں پر فعال کیا جا سکے اور ان کے جنریٹو AI کو اپنانے کو تیز کیا جا سکے۔ وہ ڈلاس ماویرکس کا شوقین پرستار ہے اور جوتے جمع کرنے سے لطف اندوز ہوتا ہے۔
 سیبسٹین بسٹیلو AWS میں ایک حل آرکیٹیکٹ ہے۔ وہ AI/ML ٹیکنالوجیز پر توجہ مرکوز کرتا ہے جس میں تخلیقی AI اور کمپیوٹ ایکسلریٹر کے لیے گہرے جذبے ہیں۔ AWS میں، وہ صارفین کو جنریٹیو AI کے ذریعے کاروباری قدر کو کھولنے میں مدد کرتا ہے۔ جب وہ کام پر نہیں ہوتا ہے، تو وہ خاصی کافی کا ایک بہترین کپ پینے اور اپنی بیوی کے ساتھ دنیا کو تلاش کرنے سے لطف اندوز ہوتا ہے۔
سیبسٹین بسٹیلو AWS میں ایک حل آرکیٹیکٹ ہے۔ وہ AI/ML ٹیکنالوجیز پر توجہ مرکوز کرتا ہے جس میں تخلیقی AI اور کمپیوٹ ایکسلریٹر کے لیے گہرے جذبے ہیں۔ AWS میں، وہ صارفین کو جنریٹیو AI کے ذریعے کاروباری قدر کو کھولنے میں مدد کرتا ہے۔ جب وہ کام پر نہیں ہوتا ہے، تو وہ خاصی کافی کا ایک بہترین کپ پینے اور اپنی بیوی کے ساتھ دنیا کو تلاش کرنے سے لطف اندوز ہوتا ہے۔
 ارمانڈو ڈیاز۔ AWS میں ایک حل آرکیٹیکٹ ہے۔ وہ تخلیقی AI، AI/ML، اور ڈیٹا تجزیات پر توجہ مرکوز کرتا ہے۔ AWS میں، Armando صارفین کو جدید تخلیقی AI صلاحیتوں کو ان کے سسٹمز میں ضم کرنے، جدت اور مسابقتی فائدہ کو فروغ دینے میں مدد کرتا ہے۔ جب وہ کام پر نہیں ہوتا ہے، تو وہ اپنی بیوی اور خاندان کے ساتھ وقت گزارنے، پیدل سفر کرنے اور دنیا کا سفر کرنے میں لطف اندوز ہوتا ہے۔
ارمانڈو ڈیاز۔ AWS میں ایک حل آرکیٹیکٹ ہے۔ وہ تخلیقی AI، AI/ML، اور ڈیٹا تجزیات پر توجہ مرکوز کرتا ہے۔ AWS میں، Armando صارفین کو جدید تخلیقی AI صلاحیتوں کو ان کے سسٹمز میں ضم کرنے، جدت اور مسابقتی فائدہ کو فروغ دینے میں مدد کرتا ہے۔ جب وہ کام پر نہیں ہوتا ہے، تو وہ اپنی بیوی اور خاندان کے ساتھ وقت گزارنے، پیدل سفر کرنے اور دنیا کا سفر کرنے میں لطف اندوز ہوتا ہے۔
 ڈاکٹر فاروق صابر AWS میں ایک سینئر مصنوعی ذہانت اور مشین لرننگ اسپیشلسٹ سولیوشن آرکیٹیکٹ ہیں۔ انہوں نے آسٹن کی یونیورسٹی آف ٹیکساس سے الیکٹریکل انجینئرنگ میں پی ایچ ڈی اور ایم ایس کی ڈگریاں اور جارجیا انسٹی ٹیوٹ آف ٹیکنالوجی سے کمپیوٹر سائنس میں ایم ایس کی ڈگریاں حاصل کیں۔ اس کے پاس 15 سال سے زیادہ کام کا تجربہ ہے اور وہ کالج کے طلباء کو پڑھانا اور ان کی رہنمائی کرنا بھی پسند کرتا ہے۔ AWS میں، وہ صارفین کو ڈیٹا سائنس، مشین لرننگ، کمپیوٹر ویژن، مصنوعی ذہانت، عددی اصلاح، اور متعلقہ ڈومینز میں اپنے کاروباری مسائل کی تشکیل اور حل کرنے میں مدد کرتا ہے۔ ڈیلاس، ٹیکساس میں مقیم، وہ اور اس کا خاندان سفر کرنا اور طویل سڑک کے سفر پر جانا پسند کرتا ہے۔
ڈاکٹر فاروق صابر AWS میں ایک سینئر مصنوعی ذہانت اور مشین لرننگ اسپیشلسٹ سولیوشن آرکیٹیکٹ ہیں۔ انہوں نے آسٹن کی یونیورسٹی آف ٹیکساس سے الیکٹریکل انجینئرنگ میں پی ایچ ڈی اور ایم ایس کی ڈگریاں اور جارجیا انسٹی ٹیوٹ آف ٹیکنالوجی سے کمپیوٹر سائنس میں ایم ایس کی ڈگریاں حاصل کیں۔ اس کے پاس 15 سال سے زیادہ کام کا تجربہ ہے اور وہ کالج کے طلباء کو پڑھانا اور ان کی رہنمائی کرنا بھی پسند کرتا ہے۔ AWS میں، وہ صارفین کو ڈیٹا سائنس، مشین لرننگ، کمپیوٹر ویژن، مصنوعی ذہانت، عددی اصلاح، اور متعلقہ ڈومینز میں اپنے کاروباری مسائل کی تشکیل اور حل کرنے میں مدد کرتا ہے۔ ڈیلاس، ٹیکساس میں مقیم، وہ اور اس کا خاندان سفر کرنا اور طویل سڑک کے سفر پر جانا پسند کرتا ہے۔
 مارکو پنیو ایک سولیوشن آرکیٹیکٹ ہے جس کی توجہ AI حکمت عملی پر مرکوز ہے، AI سلوشنز کا اطلاق ہوتا ہے اور AWS پر صارفین کو ہائپر اسکیل میں مدد کرنے کے لیے تحقیق کرنا ہے۔ مارکو ایک ڈیجیٹل مقامی کلاؤڈ ایڈوائزر ہے جس کا فن ٹیک، ہیلتھ کیئر اور لائف سائنسز، سافٹ ویئر کے طور پر ایک سروس، اور حال ہی میں ٹیلی کمیونیکیشن انڈسٹریز میں تجربہ ہے۔ وہ مشین لرننگ، مصنوعی ذہانت، اور انضمام اور حصول کا جذبہ رکھنے والا ایک قابل ٹیکنولوجسٹ ہے۔ مارکو سیٹل، WA میں مقیم ہے اور اپنے فارغ وقت میں لکھنے، پڑھنے، ورزش کرنے اور ایپلی کیشنز بنانے سے لطف اندوز ہوتا ہے۔
مارکو پنیو ایک سولیوشن آرکیٹیکٹ ہے جس کی توجہ AI حکمت عملی پر مرکوز ہے، AI سلوشنز کا اطلاق ہوتا ہے اور AWS پر صارفین کو ہائپر اسکیل میں مدد کرنے کے لیے تحقیق کرنا ہے۔ مارکو ایک ڈیجیٹل مقامی کلاؤڈ ایڈوائزر ہے جس کا فن ٹیک، ہیلتھ کیئر اور لائف سائنسز، سافٹ ویئر کے طور پر ایک سروس، اور حال ہی میں ٹیلی کمیونیکیشن انڈسٹریز میں تجربہ ہے۔ وہ مشین لرننگ، مصنوعی ذہانت، اور انضمام اور حصول کا جذبہ رکھنے والا ایک قابل ٹیکنولوجسٹ ہے۔ مارکو سیٹل، WA میں مقیم ہے اور اپنے فارغ وقت میں لکھنے، پڑھنے، ورزش کرنے اور ایپلی کیشنز بنانے سے لطف اندوز ہوتا ہے۔
 اے جے دھیمین AWS میں ایک حل آرکیٹیکٹ ہے۔ وہ جنریٹو AI، سرور لیس کمپیوٹنگ اور ڈیٹا اینالیٹکس میں مہارت رکھتا ہے۔ وہ مشین لرننگ ٹیکنیکل فیلڈ کمیونٹی میں ایک فعال رکن/مشیر ہے اور اس نے مختلف AI/ML موضوعات پر کئی سائنسی مقالے شائع کیے ہیں۔ وہ صارفین کے ساتھ کام کرتا ہے، جس میں اسٹارٹ اپ سے لے کر انٹرپرائزز تک، AWSome جنریٹیو AI سلوشنز تیار کرنے کے لیے۔ وہ خاص طور پر جدید ڈیٹا اینالیٹکس کے لیے بڑی زبان کے ماڈلز کا فائدہ اٹھانے اور حقیقی دنیا کے چیلنجوں سے نمٹنے کے لیے عملی ایپلی کیشنز کی تلاش کے بارے میں خاص طور پر پرجوش ہے۔ کام سے باہر، AJ کو سفر کرنا اچھا لگتا ہے، اور اس وقت دنیا کے ہر ملک کا دورہ کرنے کا مقصد 53 ممالک میں ہے۔
اے جے دھیمین AWS میں ایک حل آرکیٹیکٹ ہے۔ وہ جنریٹو AI، سرور لیس کمپیوٹنگ اور ڈیٹا اینالیٹکس میں مہارت رکھتا ہے۔ وہ مشین لرننگ ٹیکنیکل فیلڈ کمیونٹی میں ایک فعال رکن/مشیر ہے اور اس نے مختلف AI/ML موضوعات پر کئی سائنسی مقالے شائع کیے ہیں۔ وہ صارفین کے ساتھ کام کرتا ہے، جس میں اسٹارٹ اپ سے لے کر انٹرپرائزز تک، AWSome جنریٹیو AI سلوشنز تیار کرنے کے لیے۔ وہ خاص طور پر جدید ڈیٹا اینالیٹکس کے لیے بڑی زبان کے ماڈلز کا فائدہ اٹھانے اور حقیقی دنیا کے چیلنجوں سے نمٹنے کے لیے عملی ایپلی کیشنز کی تلاش کے بارے میں خاص طور پر پرجوش ہے۔ کام سے باہر، AJ کو سفر کرنا اچھا لگتا ہے، اور اس وقت دنیا کے ہر ملک کا دورہ کرنے کا مقصد 53 ممالک میں ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

