تعارف
دل میں ڈیٹا سائنس جھوٹ کے اعدادوشمار، جو صدیوں سے موجود ہیں لیکن آج کے ڈیجیٹل دور میں بنیادی طور پر ضروری ہیں۔ کیوں؟ کیونکہ بنیادی شماریات کے تصورات ریڑھ کی ہڈی کی حیثیت رکھتے ہیں۔ ڈیٹا کا تجزیہ، ہمیں روزانہ پیدا ہونے والے ڈیٹا کی وسیع مقدار کا احساس دلانے کے قابل بناتا ہے۔ یہ ڈیٹا کے ساتھ بات چیت کرنے جیسا ہے، جہاں اعداد و شمار صحیح سوالات پوچھنے اور ان کہانیوں کو سمجھنے میں ہماری مدد کرتے ہیں جو ڈیٹا بتانے کی کوشش کرتا ہے۔
مستقبل کے رجحانات کی پیشن گوئی کرنے اور اعداد و شمار کی بنیاد پر فیصلے کرنے سے لے کر مفروضوں کی جانچ اور کارکردگی کی پیمائش تک، اعداد و شمار وہ ٹول ہے جو ڈیٹا پر مبنی فیصلوں کے پیچھے بصیرت کو طاقت دیتا ہے۔ یہ خام ڈیٹا اور قابل عمل بصیرت کے درمیان پل ہے، جو اسے ڈیٹا سائنس کا ایک ناگزیر حصہ بناتا ہے۔
اس مضمون میں، میں نے اعداد و شمار کے 15 بنیادی تصورات مرتب کیے ہیں جو ہر ڈیٹا سائنس کے ابتدائی فرد کو معلوم ہونا چاہیے!

فہرست
1. شماریاتی نمونے اور ڈیٹا اکٹھا کرنا
ہم اعداد و شمار کے کچھ بنیادی تصورات سیکھیں گے، لیکن یہ سمجھنا کہ ہمارا ڈیٹا کہاں سے آتا ہے اور ہم اسے کیسے جمع کرتے ہیں، ڈیٹا کے سمندر میں غوطہ لگانے سے پہلے ضروری ہے۔ یہ وہ جگہ ہے جہاں آبادی، نمونے، اور مختلف نمونے لینے کی تکنیکیں عمل میں آتی ہیں۔
تصور کریں کہ ہم ایک شہر میں لوگوں کی اوسط اونچائی جاننا چاہتے ہیں۔ ہر ایک کی پیمائش کرنا عملی ہے، لہذا ہم ایک چھوٹا گروپ (نمونہ) لیتے ہیں جو بڑی آبادی کی نمائندگی کرتا ہے۔ چال یہ ہے کہ ہم اس نمونے کو کیسے منتخب کرتے ہیں۔ بے ترتیب، سٹرٹیفائیڈ، یا کلسٹر سیمپلنگ جیسی تکنیکیں اس بات کو یقینی بناتی ہیں کہ ہمارے نمونے کی اچھی طرح سے نمائندگی کی گئی ہے، تعصب کو کم کرتے ہوئے اور ہماری تلاش کو مزید قابل اعتماد بناتے ہیں۔
آبادیوں اور نمونوں کو سمجھ کر، ہم اعتماد کے ساتھ اپنی بصیرت کو نمونے سے پوری آبادی تک بڑھا سکتے ہیں، اور ہر کسی کو سروے کرنے کی ضرورت کے بغیر باخبر فیصلے کر سکتے ہیں۔
2. ڈیٹا اور پیمائش کے پیمانے کی اقسام
ڈیٹا مختلف ذائقوں میں آتا ہے، اور اعداد و شمار کی قسم کو جاننا جس کے ساتھ آپ کام کر رہے ہیں صحیح شماریاتی ٹولز اور تکنیکوں کو منتخب کرنے کے لیے بہت ضروری ہے۔
مقداری اور کوالٹیٹیو ڈیٹا
- مقداری ڈیٹا: اس قسم کا ڈیٹا نمبرز کے بارے میں ہے۔ یہ قابل پیمائش ہے اور اسے ریاضی کے حساب کتاب کے لیے استعمال کیا جا سکتا ہے۔ مقداری ڈیٹا ہمیں "کتنا" یا "کتنے" بتاتا ہے، جیسے کسی ویب سائٹ پر جانے والے صارفین کی تعداد یا شہر کا درجہ حرارت۔ یہ سیدھا اور معروضی ہے، عددی اقدار کے ذریعے ایک واضح تصویر فراہم کرتا ہے۔
- کوالٹیٹو ڈیٹا: اس کے برعکس، کوالٹیٹیو ڈیٹا خصوصیات اور وضاحتوں سے متعلق ہے۔ یہ "کس قسم" یا "کس زمرے" کے بارے میں ہے۔ اسے اعداد و شمار کے طور پر سوچیں جو خصوصیات یا صفات کو بیان کرتا ہے، جیسے کار کا رنگ یا کتاب کی صنف۔ یہ ڈیٹا ساپیکش ہے، پیمائش کے بجائے مشاہدات پر مبنی ہے۔
پیمائش کے چار پیمانے
- برائے نام پیمانہ: یہ پیمائش کی سب سے آسان شکل ہے جو کسی مخصوص ترتیب کے بغیر ڈیٹا کی درجہ بندی کے لیے استعمال ہوتی ہے۔ مثالوں میں کھانوں کی اقسام، خون کے گروپ، یا قومیت شامل ہیں۔ یہ بغیر کسی مقداری قدر کے لیبل لگانے کے بارے میں ہے۔
- عام پیمانہ: ڈیٹا کو یہاں ترتیب دیا جا سکتا ہے یا درجہ بندی کیا جا سکتا ہے، لیکن اقدار کے درمیان وقفوں کی وضاحت نہیں کی گئی ہے۔ مطمئن، غیر جانبدار اور غیر مطمئن جیسے اختیارات کے ساتھ اطمینان بخش سروے کے بارے میں سوچیں۔ یہ ہمیں ترتیب بتاتا ہے لیکن درجہ بندی کے درمیان فاصلہ نہیں۔
- وقفہ پیمانہ: وقفہ ترازو ڈیٹا کو ترتیب دیتا ہے اور اندراجات کے درمیان فرق کو درست کرتا ہے۔ تاہم، کوئی اصل صفر پوائنٹ نہیں ہے۔ ایک اچھی مثال سیلسیس میں درجہ حرارت ہے۔ 10 ° C اور 20 ° C کے درمیان فرق وہی ہے جو 20 ° C اور 30 ° C کے درمیان ہے، لیکن 0 ° C کا مطلب درجہ حرارت کی عدم موجودگی نہیں ہے۔
- تناسب کا پیمانہ: سب سے زیادہ معلوماتی پیمانے میں وقفہ پیمانے کی تمام خصوصیات کے علاوہ ایک بامعنی صفر پوائنٹ ہوتا ہے، جس سے طول و عرض کا درست موازنہ کیا جا سکتا ہے۔ مثالوں میں وزن، قد، اور آمدنی شامل ہیں۔ یہاں، ہم کہہ سکتے ہیں کہ کوئی چیز دوسرے سے دوگنا ہے۔
3 وضاحتی اعداد و شمار
امیجن وضاحتی اعداد و شمار آپ کے ڈیٹا کے ساتھ آپ کی پہلی تاریخ کے طور پر۔ یہ بنیادی باتوں کو جاننے کے بارے میں ہے، وسیع اسٹروک جو آپ کے سامنے کیا ہے اس کی وضاحت کرتے ہیں۔ وضاحتی اعدادوشمار کی دو اہم اقسام ہیں: مرکزی رجحان اور تغیر پذیری کے اقدامات۔
مرکزی رجحان کے اقدامات: یہ ڈیٹا کی کشش ثقل کے مرکز کی طرح ہیں۔ وہ ہمیں ہمارے ڈیٹا سیٹ کی مخصوص یا نمائندہ واحد قدر دیتے ہیں۔
مطلب: اوسط کا حساب تمام اقدار کو جوڑ کر اور قدروں کی تعداد سے تقسیم کر کے لگایا جاتا ہے۔ یہ تمام جائزوں کی بنیاد پر ریستوراں کی مجموعی درجہ بندی کی طرح ہے۔ اوسط کا حسابی فارمولا ذیل میں دیا گیا ہے:

اوسط: درمیانی قدر جب ڈیٹا کو سب سے چھوٹے سے بڑے تک ترتیب دیا جاتا ہے۔ اگر مشاہدات کی تعداد برابر ہے، تو یہ دو درمیانی نمبروں کی اوسط ہے۔ یہ ایک پل کا درمیانی نقطہ تلاش کرنے کے لیے استعمال ہوتا ہے۔
اگر n برابر ہے، تو میڈین دو مرکزی نمبروں کا اوسط ہے۔
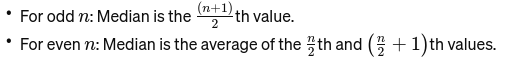
موڈ: یہ ڈیٹا سیٹ میں اکثر ہونے والی قدر۔ اسے ایک ریستوراں میں سب سے مشہور ڈش سمجھیں۔
تغیر کے اقدامات: جب کہ مرکزی رجحان کے اقدامات ہمیں مرکز میں لاتے ہیں، تغیر کے اقدامات ہمیں پھیلاؤ یا پھیلاؤ کے بارے میں بتاتے ہیں۔
رینج: اعلیٰ اور کم ترین اقدار کے درمیان فرق۔ یہ پھیلاؤ کا بنیادی خیال دیتا ہے۔
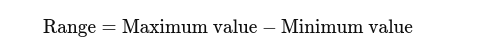
تغیر: پیمائش کرتا ہے کہ سیٹ میں ہر ایک نمبر اوسط سے کتنا دور ہے اور اس طرح سیٹ کے ہر دوسرے نمبر سے۔ نمونے کے لیے، یہ اس طرح لگایا جاتا ہے:
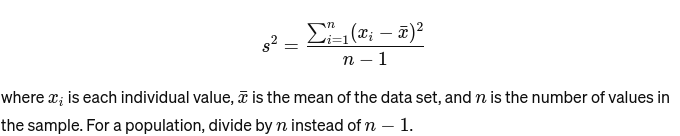
معیاری انحراف: تغیر کا مربع جڑ وسط سے اوسط فاصلے کا پیمانہ فراہم کرتا ہے۔ یہ بیکر کے کیک کے سائز کی مستقل مزاجی کا اندازہ لگانے کے مترادف ہے۔ اس کی نمائندگی اس طرح کی جاتی ہے:
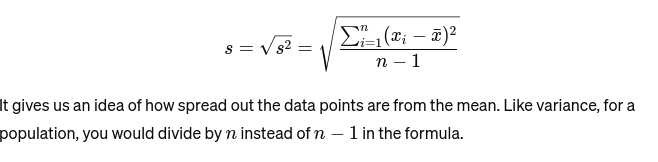
اس سے پہلے کہ ہم اعداد و شمار کے اگلے بنیادی تصور پر جائیں، یہاں ایک ہے۔ شماریاتی تجزیہ کے لیے ابتدائی رہنما آپ کے لئے!
4. ڈیٹا ویزولائزیشن۔
ڈیٹا کی نمائش ڈیٹا کے ساتھ کہانیاں سنانے کا فن اور سائنس ہے۔ یہ ہمارے تجزیہ کے پیچیدہ نتائج کو ٹھوس اور قابل فہم چیز میں بدل دیتا ہے۔ تحقیقی ڈیٹا کے تجزیے کے لیے یہ بہت اہم ہے، جہاں کا مقصد ابھی تک رسمی نتیجہ اخذ کیے بغیر ڈیٹا سے پیٹرن، ارتباط اور بصیرت کا پتہ لگانا ہے۔
- چارٹس اور گرافس: بنیادی باتوں سے شروع کرتے ہوئے، بار چارٹس، لائن گرافس، اور پائی چارٹس ڈیٹا میں بنیادی بصیرت فراہم کرتے ہیں۔ وہ ڈیٹا ویژولائزیشن کے ABCs ہیں، جو کسی بھی ڈیٹا کہانی سنانے والے کے لیے ضروری ہیں۔
ہمارے پاس نیچے بار چارٹ (بائیں) اور لائن چارٹ (دائیں) کی مثال ہے۔
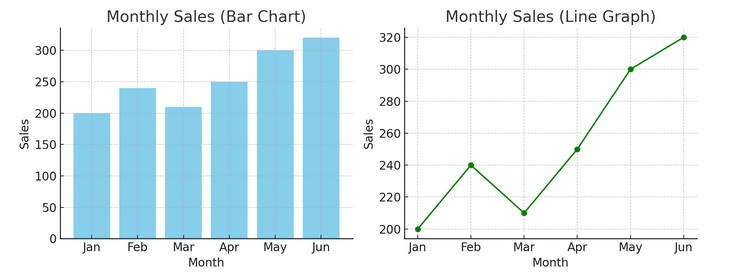
- اعلی درجے کی تصورات: جیسا کہ ہم گہرائی میں غوطہ لگاتے ہیں، گرمی کے نقشے، بکھرے ہوئے پلاٹ، اور ہسٹوگرام زیادہ باریک بینی سے تجزیہ کرنے کی اجازت دیتے ہیں۔ یہ ٹولز ٹرینڈز، ڈسٹری بیوشن اور آؤٹ لیرز کی شناخت میں مدد کرتے ہیں۔
ذیل میں سکیٹر پلاٹ اور ہسٹوگرام کی ایک مثال ہے۔

تصورات خام ڈیٹا اور انسانی ادراک کو ملاتے ہیں، جو ہمیں پیچیدہ ڈیٹاسیٹس کی فوری تشریح اور احساس کرنے کے قابل بناتے ہیں۔
5. امکانات کی بنیادی باتیں
احتمال شماریات کی زبان کی گرامر ہے۔ یہ واقعات کے ہونے کے امکانات یا امکانات کے بارے میں ہے۔ شماریاتی نتائج کی تشریح اور پیشین گوئیاں کرنے کے لیے امکانات میں تصورات کو سمجھنا ضروری ہے۔
- آزاد اور منحصر واقعات:
- آزاد واقعات: ایک واقعہ کا نتیجہ دوسرے کے نتائج کو متاثر نہیں کرتا۔ ایک سکے کو پلٹانے کی طرح، ایک پلٹنے پر سر حاصل کرنے سے اگلے پلٹنے کے امکانات تبدیل نہیں ہوتے ہیں۔
- منحصر واقعات: ایک واقعہ کا نتیجہ دوسرے کے نتیجے پر اثر انداز ہوتا ہے۔ مثال کے طور پر، اگر آپ ڈیک سے کارڈ کھینچتے ہیں اور اسے تبدیل نہیں کرتے ہیں، تو آپ کے دوسرے مخصوص کارڈ کے ڈرائنگ کے امکانات بدل جاتے ہیں۔
امکان اعداد و شمار کے بارے میں قیاس آرائیاں کرنے کی بنیاد فراہم کرتا ہے اور شماریاتی اہمیت اور مفروضے کی جانچ کو سمجھنے کے لیے اہم ہے۔
6. مشترکہ امکانی تقسیم
امکانی تقسیم اعداد و شمار کے ماحولیاتی نظام میں مختلف پرجاتیوں کی طرح ہیں، ہر ایک اپنے اطلاق کے طاق کے مطابق ہے۔
- عام تقسیم: اس کی شکل کی وجہ سے اسے اکثر گھنٹی کا وکر کہا جاتا ہے، یہ تقسیم اس کے اوسط اور معیاری انحراف سے نمایاں ہوتی ہے۔ بہت سے شماریاتی ٹیسٹوں میں یہ ایک عام مفروضہ ہے کیونکہ بہت سے متغیر قدرتی طور پر حقیقی دنیا میں اس طرح تقسیم ہوتے ہیں۔
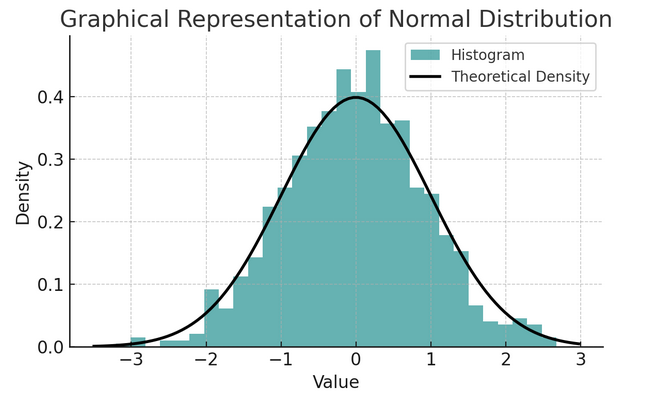
تجرباتی اصول یا 68-95-99.7 اصول کے نام سے جانا جاتا اصولوں کا ایک مجموعہ عام تقسیم کی خصوصیات کا خلاصہ کرتا ہے، جو یہ بتاتا ہے کہ وسط کے ارد گرد ڈیٹا کیسے پھیلایا جاتا ہے۔
68-95-99.7 اصول (تجرباتی اصول)
یہ اصول بالکل عام تقسیم پر لاگو ہوتا ہے اور درج ذیل کا خاکہ پیش کرتا ہے:
- 68٪ اعداد و شمار کا اوسط (μ) کے ایک معیاری انحراف (σ) کے اندر آتا ہے۔
- 95٪ اعداد و شمار کا وسط کے دو معیاری انحراف میں آتا ہے۔
- تقریبا 99.7٪ اعداد و شمار کا اوسط کے تین معیاری انحراف کے اندر آتا ہے۔
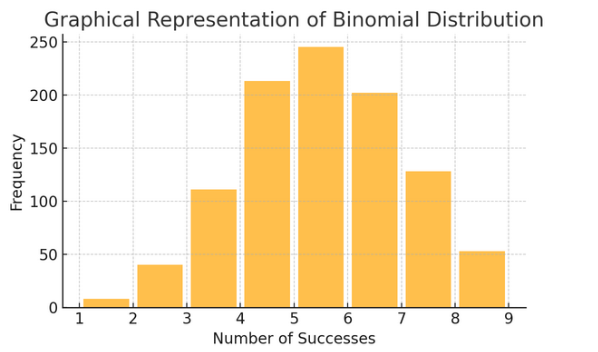
دو عددی تقسیم: یہ تقسیم ان حالات پر لاگو ہوتی ہے جن کے دو نتائج (جیسے کامیابی یا ناکامی) کئی بار دہرائے جاتے ہیں۔ یہ ماڈل ایونٹس میں مدد کرتا ہے جیسے سکے کو پلٹنا یا صحیح/غلط ٹیسٹ لینا۔
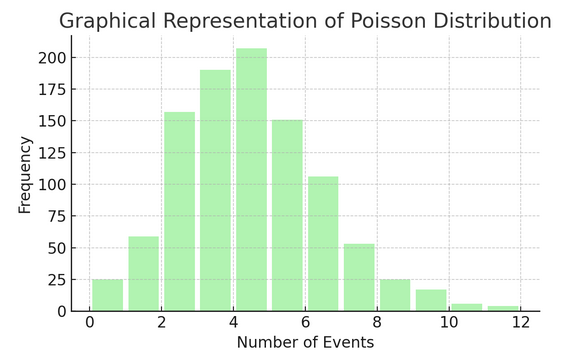
زہر کی تقسیم ایک مخصوص وقفہ یا جگہ پر کچھ ہونے کی تعداد کو شمار کرتا ہے۔ یہ ان حالات کے لیے مثالی ہے جہاں واقعات آزادانہ اور مستقل طور پر ہوتے ہیں، جیسے آپ کو موصول ہونے والی روزانہ کی ای میلز۔
ہر تقسیم کے فارمولوں اور خصوصیات کا اپنا ایک سیٹ ہوتا ہے، اور صحیح کا انتخاب آپ کے ڈیٹا کی نوعیت اور آپ کیا معلوم کرنے کی کوشش کر رہے ہیں اس پر منحصر ہوتا ہے۔ ان تقسیموں کو سمجھنا شماریات دانوں اور ڈیٹا سائنسدانوں کو حقیقی دنیا کے مظاہر کا نمونہ بنانے اور مستقبل کے واقعات کی درست پیشین گوئی کرنے کی اجازت دیتا ہے۔
7 مفروضے کا امتحان
سوچو مفروضے کا امتحان اعدادوشمار میں جاسوسی کے کام کے طور پر۔ یہ جانچنے کا ایک طریقہ ہے کہ آیا ہمارے ڈیٹا کے بارے میں کوئی خاص نظریہ درست ہو سکتا ہے۔ یہ عمل دو مخالف مفروضوں سے شروع ہوتا ہے:
- null hypothesis (H0): یہ پہلے سے طے شدہ مفروضہ ہے، یہ بتاتا ہے کہ وہاں اثر یا فرق ہے۔ یہ کہہ رہا ہے، "نہیں" یہاں نیا ہے۔
- "متبادل مفروضہ (H1 یا Ha): یہ جمود کو چیلنج کرتا ہے، اثر یا فرق تجویز کرتا ہے۔ یہ دعوی کرتا ہے، "کچھ دلچسپ ہو رہا ہے۔"
مثال: جانچ کرنا کہ آیا کسی غذا پر عمل نہ کرنے کے مقابلے میں ایک نیا ڈائیٹ پروگرام وزن میں کمی کا باعث بنتا ہے۔
- null hypothesis (H0): نیا ڈائیٹ پروگرام وزن میں کمی کا باعث نہیں بنتا (نئے ڈائیٹ پروگرام کی پیروی کرنے والوں اور نہ کرنے والوں کے درمیان وزن میں کمی میں کوئی فرق نہیں)۔
- متبادل مفروضہ (H1): نیا ڈائیٹ پروگرام وزن میں کمی کا باعث بنتا ہے (اس کی پیروی کرنے والوں اور نہ کرنے والوں کے درمیان وزن میں کمی میں فرق)۔
مفروضے کی جانچ میں ثبوت (ہمارے ڈیٹا) کی بنیاد پر ان دونوں کے درمیان انتخاب کرنا شامل ہے۔
قسم I اور II کی خرابی اور اہمیت کی سطح:
- قسم I کی خرابی: ایسا تب ہوتا ہے جب ہم غلط مفروضے کو رد کر دیتے ہیں۔ یہ ایک بے گناہ کو سزا دیتا ہے۔
- قسم II کی خرابی: یہ اس وقت ہوتا ہے جب ہم کسی غلط مفروضے کو مسترد کرنے میں ناکام رہتے ہیں۔ یہ ایک مجرم کو آزاد ہونے دیتا ہے۔
- اہمیت کی سطح (α): یہ ہے۔ یہ فیصلہ کرنے کے لیے حد ہے کہ باطل مفروضے کو مسترد کرنے کے لیے کتنے ثبوت کافی ہیں۔ یہ اکثر 5% (0.05) پر سیٹ کیا جاتا ہے، جو قسم I کی غلطی کے 5% خطرے کی نشاندہی کرتا ہے۔
8. اعتماد کے وقفے
اعتماد کے وقفے ہمیں قدروں کی ایک رینج دیں جس کے اندر ہم توقع کرتے ہیں کہ آبادی کا درست پیرامیٹر (جیسے اوسط یا تناسب) ایک خاص اعتماد کی سطح (عام طور پر 95%) کے ساتھ گرے گا۔ یہ غلطی کے مارجن کے ساتھ کھیلوں کی ٹیم کے فائنل اسکور کی پیشین گوئی کرنے کے مترادف ہے۔ ہم کہہ رہے ہیں، "ہمیں 95% یقین ہے کہ حقیقی اسکور اس حد کے اندر ہوگا۔"
اعتماد کے وقفوں کی تشکیل اور تشریح کرنے سے ہمیں اپنے تخمینوں کی درستگی کو سمجھنے میں مدد ملتی ہے۔ وقفہ جتنا وسیع ہوگا، ہمارا تخمینہ کم درست ہے، اور اس کے برعکس۔
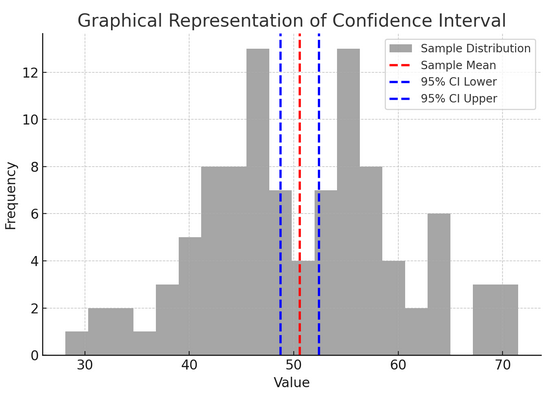
مندرجہ بالا اعداد و شمار اعداد و شمار میں اعتماد کے وقفے (CI) کے تصور کو واضح کرتا ہے، نمونے کی تقسیم اور اس کے 95% اعتماد کے وقفے کا استعمال کرتے ہوئے نمونے کے اوسط کے ارد گرد۔
یہاں تصویر میں اہم اجزاء کی خرابی ہے:
- نمونے کی تقسیم (گرے ہسٹوگرام): یہ 100 ڈیٹا پوائنٹس کی تقسیم کی نمائندگی کرتا ہے جو تصادفی طور پر عام تقسیم سے 50 کے اوسط اور 10 کے معیاری انحراف کے ساتھ پیدا ہوتا ہے۔ ہسٹوگرام بصری طور پر یہ ظاہر کرتا ہے کہ ڈیٹا پوائنٹس وسط کے گرد کیسے پھیلے ہیں۔
- نمونہ کا مطلب (سرخ ڈیشڈ لائن): یہ لائن نمونے کے ڈیٹا کی اوسط (اوسط) قدر کی نشاندہی کرتی ہے۔ یہ نقطہ تخمینہ کے طور پر کام کرتا ہے جس کے ارد گرد ہم اعتماد کا وقفہ بناتے ہیں۔ اس صورت میں، یہ نمونہ کی تمام اقدار کی اوسط کی نمائندگی کرتا ہے۔
- 95% اعتماد کا وقفہ (بلیو ڈیشڈ لائنز): یہ دو لائنیں نمونے کے وسط کے ارد گرد 95% اعتماد کے وقفے کی نچلی اور اوپری حدود کو نشان زد کرتی ہیں۔ وقفہ کا حساب اوسط (SEM) کی معیاری غلطی اور مطلوبہ اعتماد کی سطح (1.96% اعتماد کے لیے 95) کے مطابق Z-اسکور کا استعمال کرتے ہوئے کیا جاتا ہے۔ اعتماد کا وقفہ بتاتا ہے کہ ہمیں 95% یقین ہے کہ آبادی کا مطلب اس حد کے اندر ہے۔
9. ارتباط اور وجہ
ارتباط اور سبب اکثر گھل مل جاتے ہیں، لیکن وہ مختلف ہیں:
- باہمی تعلق: دو متغیرات کے درمیان تعلق یا ایسوسی ایشن کی نشاندہی کرتا ہے۔ جب ایک بدل جاتا ہے تو دوسرا بھی بدل جاتا ہے۔ ارتباط کی پیمائش -1 سے 1 تک کے ارتباطی گتانک سے کی جاتی ہے۔ 1 یا -1 کے قریب کی قدر ایک مضبوط رشتہ کی نشاندہی کرتی ہے، جب کہ 0 کوئی تعلق نہیں بتاتا ہے۔
- وجہ: اس کا مطلب یہ ہے کہ ایک متغیر میں تبدیلی براہ راست دوسرے میں تبدیلی کا باعث بنتی ہے۔ یہ ارتباط سے زیادہ مضبوط دعویٰ ہے اور اس کے لیے سخت جانچ کی ضرورت ہے۔
صرف اس وجہ سے کہ دو متغیرات باہم مربوط ہیں اس کا مطلب یہ نہیں ہے کہ ایک دوسرے کا سبب بنتا ہے۔ یہ "وجہ" کے ساتھ "تعلق" کو الجھانے کا ایک کلاسک معاملہ ہے۔
10. سادہ لکیری رجعت
سادہ لکیری رجعت مشاہدہ شدہ ڈیٹا میں لکیری مساوات کو فٹ کر کے دو متغیر کے درمیان تعلق کو ماڈل کرنے کا ایک طریقہ ہے۔ ایک متغیر کو وضاحتی متغیر (آزاد) سمجھا جاتا ہے، اور دوسرا انحصار متغیر ہے۔
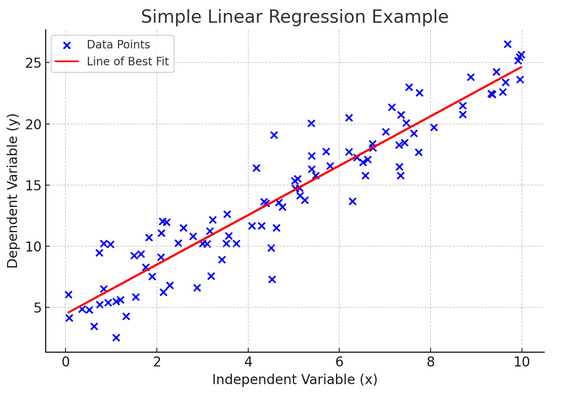
سادہ لکیری رجعت ہمیں یہ سمجھنے میں مدد کرتی ہے کہ کس طرح آزاد متغیر میں تبدیلیاں منحصر متغیر کو متاثر کرتی ہیں۔ یہ پیشین گوئی کے لیے ایک طاقتور ٹول ہے اور بہت سے دوسرے پیچیدہ شماریاتی ماڈلز کے لیے بنیادی ہے۔ دو متغیرات کے درمیان تعلق کا تجزیہ کرکے، ہم باخبر پیش گوئیاں کر سکتے ہیں کہ وہ کیسے تعامل کریں گے۔
سادہ لکیری رجعت آزاد متغیر (تفصیلی متغیر) اور منحصر متغیر کے درمیان ایک لکیری تعلق کو فرض کرتی ہے۔ اگر ان دو متغیرات کے درمیان تعلق خطی نہیں ہے، تو سادہ لکیری رجعت کے مفروضوں کی خلاف ورزی ہو سکتی ہے، جو ممکنہ طور پر غلط پیشین گوئیوں یا تشریحات کا باعث بنتی ہے۔ اس طرح، سادہ لکیری رجعت کو لاگو کرنے سے پہلے ڈیٹا میں لکیری تعلق کی تصدیق ضروری ہے۔
11. ایک سے زیادہ لکیری رجعت
ایک سے زیادہ لکیری رجعت کو سادہ لکیری رجعت کی توسیع کے طور پر سوچیں۔ پھر بھی، چمکتے ہوئے آرمر (پیش گوئی کرنے والے) میں ایک نائٹ کے ساتھ نتیجہ کی پیشن گوئی کرنے کی بجائے، آپ کے پاس پوری ٹیم ہے۔ یہ ون آن ون باسکٹ بال گیم سے پوری ٹیم کی کوشش میں اپ گریڈ کرنے جیسا ہے، جہاں ہر کھلاڑی (پیش گوئی کرنے والا) منفرد مہارت لاتا ہے۔ خیال یہ دیکھنا ہے کہ متعدد متغیرات ایک ساتھ کس طرح ایک نتیجہ پر اثر انداز ہوتے ہیں۔
تاہم، ایک بڑی ٹیم کے ساتھ تعلقات کو سنبھالنے کا چیلنج آتا ہے، جسے ملٹی کولینریٹی کہا جاتا ہے۔ یہ اس وقت ہوتا ہے جب پیشن گوئی کرنے والے ایک دوسرے کے بہت قریب ہوتے ہیں اور اسی طرح کی معلومات کا اشتراک کرتے ہیں۔ تصور کریں کہ باسکٹ بال کے دو کھلاڑی مسلسل ایک ہی شاٹ لینے کی کوشش کر رہے ہیں۔ وہ ایک دوسرے کے راستے میں آ سکتے ہیں. رجعت ہر پیش گو کی منفرد شراکت کو دیکھنا مشکل بنا سکتی ہے، ممکنہ طور پر ہماری سمجھ کو کم کر دیتی ہے کہ کون سے متغیرات اہم ہیں۔
12. لاجسٹک ریگریشن
جبکہ لکیری رجعت مسلسل نتائج کی پیشین گوئی کرتی ہے (جیسے درجہ حرارت یا قیمتیں) لاجسٹک رجعت استعمال کیا جاتا ہے جب نتیجہ یقینی ہو (جیسا کہ ہاں/نہیں، جیت/ ہار)۔ مختلف عوامل کی بنیاد پر یہ اندازہ لگانے کی کوشش کریں کہ آیا کوئی ٹیم جیتے گی یا ہارے گی۔ لاجسٹک ریگریشن آپ کی جانے والی حکمت عملی ہے۔
یہ لکیری مساوات کو تبدیل کرتا ہے تاکہ اس کا آؤٹ پٹ 0 اور 1 کے درمیان آجائے، جو کسی خاص زمرے سے تعلق رکھنے کے امکان کو ظاہر کرتا ہے۔ یہ ایک جادوئی عینک رکھنے کی طرح ہے جو مسلسل اسکورز کو ایک واضح "یہ یا وہ" منظر میں تبدیل کرتا ہے، جس سے ہمیں واضح نتائج کی پیشن گوئی کرنے کی اجازت ملتی ہے۔
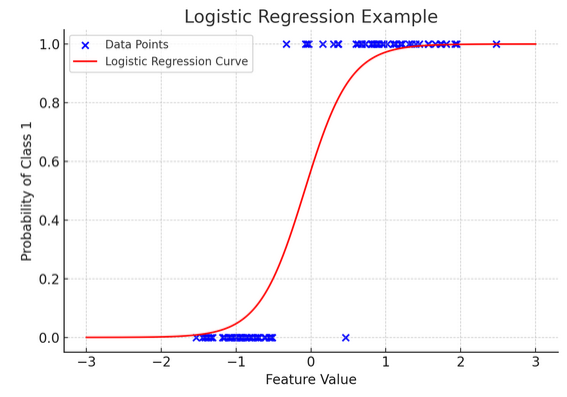
گرافیکل نمائندگی مصنوعی بائنری درجہ بندی ڈیٹاسیٹ پر لاگو لاجسٹک ریگریشن کی ایک مثال کی وضاحت کرتی ہے۔ نیلے نقطے ڈیٹا پوائنٹس کی نمائندگی کرتے ہیں، ایکس محور کے ساتھ ان کی پوزیشن خصوصیت کی قدر اور y محور زمرہ (0 یا 1) کی نشاندہی کرتی ہے۔ سرخ وکر مختلف خصوصیات کی اقدار کے لیے کلاس 1 (مثلاً "جیت") سے تعلق رکھنے کے امکان کی لاجسٹک ریگریشن ماڈل کی پیشین گوئی کی نمائندگی کرتا ہے۔ جیسا کہ آپ دیکھ سکتے ہیں، وکر کلاس 0 کے امکان سے کلاس 1 میں آسانی سے منتقل ہوتا ہے، جو ایک بنیادی مسلسل خصوصیت کی بنیاد پر واضح نتائج کی پیش گوئی کرنے کی ماڈل کی صلاحیت کو ظاہر کرتا ہے۔ میں
لاجسٹک ریگریشن کا فارمولا بذریعہ دیا گیا ہے:

یہ فارمولہ لاجسٹک فنکشن کا استعمال کرتے ہوئے لکیری مساوات کے آؤٹ پٹ کو 0 اور 1 کے درمیان امکان میں تبدیل کرتا ہے۔ یہ تبدیلی ہمیں آزاد متغیر xx کی قدر کی بنیاد پر کسی خاص زمرے سے تعلق رکھنے کے امکانات کے طور پر آؤٹ پٹ کی تشریح کرنے کی اجازت دیتی ہے۔
13. ANOVA اور Chi-Square ٹیسٹ
انووا (تغیر کا تجزیہ) اور چی اسکوائر ٹیسٹ اعداد و شمار کی دنیا میں جاسوسوں کی طرح ہیں، مختلف رازوں کو حل کرنے میں ہماری مدد کرتے ہیں۔ میںt ہمیں متعدد گروپوں میں ذرائع کا موازنہ کرنے کی اجازت دیتا ہے یہ دیکھنے کے لیے کہ آیا کم از کم ایک شماریاتی لحاظ سے مختلف ہے۔ اس کو کوکیز کے کئی بیچوں سے چکھنے کے نمونوں کے طور پر سمجھیں تاکہ یہ معلوم کیا جا سکے کہ آیا کسی بیچ کا ذائقہ نمایاں طور پر مختلف ہے۔
دوسری طرف، Chi-Square ٹیسٹ کو واضح ڈیٹا کے لیے استعمال کیا جاتا ہے۔ اس سے ہمیں یہ سمجھنے میں مدد ملتی ہے کہ آیا دو متغیر متغیرات کے درمیان کوئی اہم تعلق ہے۔ مثال کے طور پر، کیا کسی شخص کی پسندیدہ موسیقی کی صنف اور اس کی عمر کے درمیان کوئی تعلق ہے؟ Chi-Square ٹیسٹ ایسے سوالات کے جوابات میں مدد کرتا ہے۔
14. مرکزی حد کا نظریہ اور ڈیٹا سائنس میں اس کی اہمیت
۔ مرکزی حد نظریہ (CLT) ایک بنیادی شماریاتی اصول ہے جو تقریباً جادوئی محسوس ہوتا ہے۔ یہ ہمیں بتاتا ہے کہ اگر آپ آبادی سے کافی نمونے لیتے ہیں اور ان کے ذرائع کا حساب لگاتے ہیں، تو وہ ذرائع آبادی کی اصل تقسیم سے قطع نظر، ایک عام تقسیم (گھنٹی کا وکر) بنائیں گے۔ یہ ناقابل یقین حد تک طاقتور ہے کیونکہ یہ ہمیں آبادی کے بارے میں اندازہ لگانے کی اجازت دیتا ہے یہاں تک کہ جب ہم ان کی صحیح تقسیم کو نہیں جانتے ہیں۔
ڈیٹا سائنس میں، CLT بہت سی تکنیکوں کو زیر کرتا ہے، جو ہمیں عام طور پر تقسیم کیے گئے ڈیٹا کے لیے بنائے گئے ٹولز کو استعمال کرنے کے قابل بناتا ہے، یہاں تک کہ جب ہمارا ڈیٹا ابتدائی طور پر ان معیارات پر پورا نہ اترتا ہو۔ یہ شماریاتی طریقوں کے لیے ایک عالمگیر اڈاپٹر تلاش کرنے کے مترادف ہے، بہت سے طاقتور ٹولز کو مزید حالات میں قابلِ اطلاق بنانا۔
15. Bias-Variance Tradeoff
In پیشن گوئی ماڈلنگ اور مشین لرننگ، تعصب-تغیر تجارت ایک اہم تصور ہے جو غلطی کی دو اہم اقسام کے درمیان تناؤ کو نمایاں کرتا ہے جو ہمارے ماڈلز کو خراب کر سکتا ہے۔ تعصب سے مراد حد سے زیادہ سادہ ماڈلز کی غلطیاں ہیں جو بنیادی رجحانات کو اچھی طرح سے گرفت میں نہیں لاتی ہیں۔ ایک خمیدہ سڑک کے ذریعے سیدھی لائن کو فٹ کرنے کی کوشش کا تصور کریں۔ آپ نشان کو یاد کریں گے. اس کے برعکس، بہت پیچیدہ ماڈلز کے تغیرات ڈیٹا میں شور کو اس طرح گرفت میں لیتے ہیں جیسے یہ ایک حقیقی نمونہ ہو — جیسے کہ ہر موڑ کو ٹریس کرنا اور یہ سوچتے ہوئے کہ یہ آگے کا راستہ ہے۔
فن کل غلطی کو کم کرنے کے لیے ان دونوں کو متوازن کرنے میں مضمر ہے، اس میٹھی جگہ کو تلاش کرنا جہاں آپ کا ماڈل بالکل صحیح ہے — درست نمونوں کو حاصل کرنے کے لیے کافی پیچیدہ لیکن بے ترتیب شور کو نظر انداز کرنے کے لیے کافی آسان ہے۔ یہ ایک گٹار ٹیوننگ کی طرح ہے; اگر یہ بہت تنگ یا ڈھیلا ہے تو یہ ٹھیک نہیں لگے گا۔ تعصب-تغیر تجارت ان دونوں کے درمیان کامل توازن تلاش کرنے کے بارے میں ہے۔ تعصب-تغیر کی تجارت ہمارے شماریاتی ماڈلز کو درست طریقے سے نتائج کی پیشین گوئی کرنے میں بہترین کارکردگی کا مظاہرہ کرنے کا نچوڑ ہے۔
نتیجہ
اعداد و شمار کے نمونے لینے سے لے کر تعصب کے فرق تک، یہ اصول محض علمی تصورات نہیں ہیں بلکہ بصیرت انگیز ڈیٹا کے تجزیہ کے لیے ضروری ٹولز ہیں۔ وہ ڈیٹا کے خواہشمند سائنسدانوں کو وسیع ڈیٹا کو قابل عمل بصیرت میں تبدیل کرنے کی مہارتوں سے آراستہ کرتے ہیں، اعداد و شمار پر زور دیتے ہوئے ڈیجیٹل دور میں ڈیٹا پر مبنی فیصلہ سازی اور جدت طرازی کی ریڑھ کی ہڈی کی حیثیت رکھتے ہیں۔
کیا ہم نے اعداد و شمار کا کوئی بنیادی تصور چھوڑا ہے؟ ہمیں نیچے تبصرہ سیکشن میں بتائیں۔
ہماری ریسرچ کریں آخر سے آخر تک شماریات گائیڈ ڈیٹا سائنس کو موضوع کے بارے میں جاننے کے لیے!
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://www.analyticsvidhya.com/blog/2024/03/basic-statistics-concepts/

