Giriş
Bilgisayarla görmede canlı nesne tespiti için farklı teknikler mevcuttur; bunlar arasında Daha Hızlı R-CNN, SSD, ve YOLO. Her tekniğin sınırlamaları ve avantajları vardır. Daha Hızlı R-CNN doğruluk açısından mükemmel olsa da, gerçek zamanlı senaryolarda o kadar iyi performans göstermeyebilir ve bu durum, YOLO algoritması.
Nesne algılama, bilgisayarlı görmede temel bir öneme sahiptir ve makinelerin bir çerçeve veya ekran içindeki nesneleri tanımlamasına ve konumlandırmasına olanak tanır. Yıllar geçtikçe çeşitli nesne algılama algoritmaları geliştirildi ve YOLO en başarılılarından biri olarak ortaya çıktı. Son zamanlarda algoritmanın yeteneklerini daha da artıran YOLOv8 tanıtıldı.
Bu kapsamlı kılavuzda öne çıkan üç nesne algılama algoritmasını inceliyoruz: Daha Hızlı R-CNN, SSD (Tek Atışlı Çoklu Kutu Dedektörü) ve YOLOv8. Sanal bir ortam kurmak ve Streamlit uygulaması geliştirmek de dahil olmak üzere bu algoritmaları uygulamanın pratik yönlerini tartışıyoruz.
Öğrenme Hedefi
- Daha Hızlı R-CNN, SSD ve YOLO'yu anlayın ve aralarındaki farkları analiz edin.
- OpenCV, Supervision ve YOLOv8'i kullanarak canlı nesne algılama sistemlerinin uygulanmasında pratik deneyim kazanın.
- Roboflow ek açıklamasını kullanarak görüntü segmentasyon modelini anlama.
- Kolay bir kullanıcı arayüzü için Streamlit uygulaması oluşturun.
YOLOv8 ile görüntü segmentasyonunun nasıl yapıldığını keşfedelim!
İçindekiler
Bu makale, Veri Bilimi Blogatonu.
Daha hızlı R-CNN
Daha Hızlı R-CNN (Daha Hızlı Bölge Tabanlı Evrişimli Sinir Ağı), derin öğrenme tabanlı bir nesne algılama algoritmasıdır. R-CNN ve Fast R-CNN çerçeveleri kullanılarak değerlendirilir ve Fast R-CNN'nin bir uzantısı olarak düşünülebilir.
Bu algoritma, R-CNN'de kullanılan seçici aramanın yerine bölge teklifleri oluşturmak için Bölge Teklif Ağı'nı (RPN) sunar. RPN, evrişimli katmanları algılama ağıyla paylaşarak verimli uçtan uca eğitime olanak tanır.
Oluşturulan bölge önerileri daha sonra sınırlayıcı kutunun iyileştirilmesi ve nesne sınıflandırması için Hızlı R-CNN ağına beslenir.
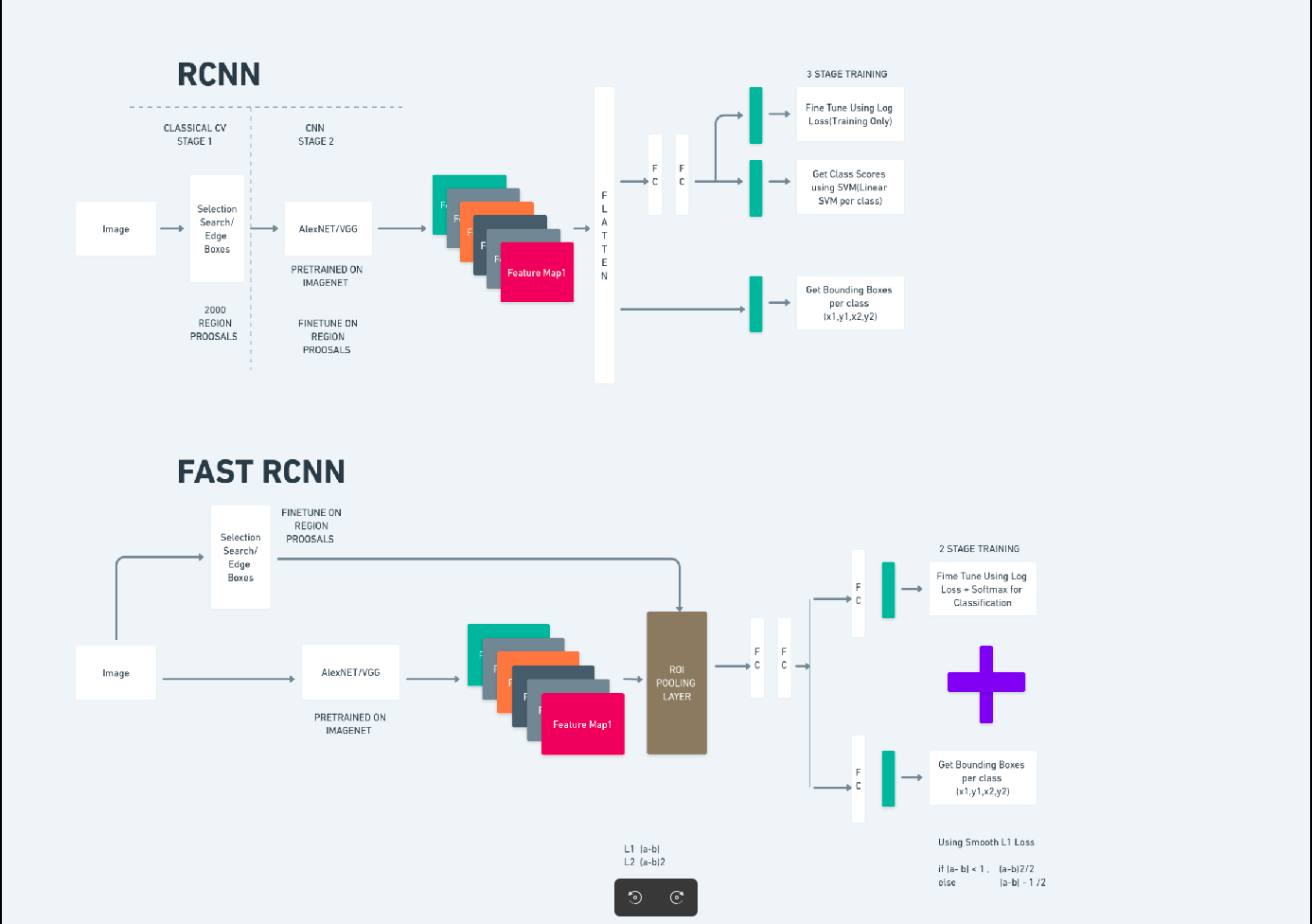
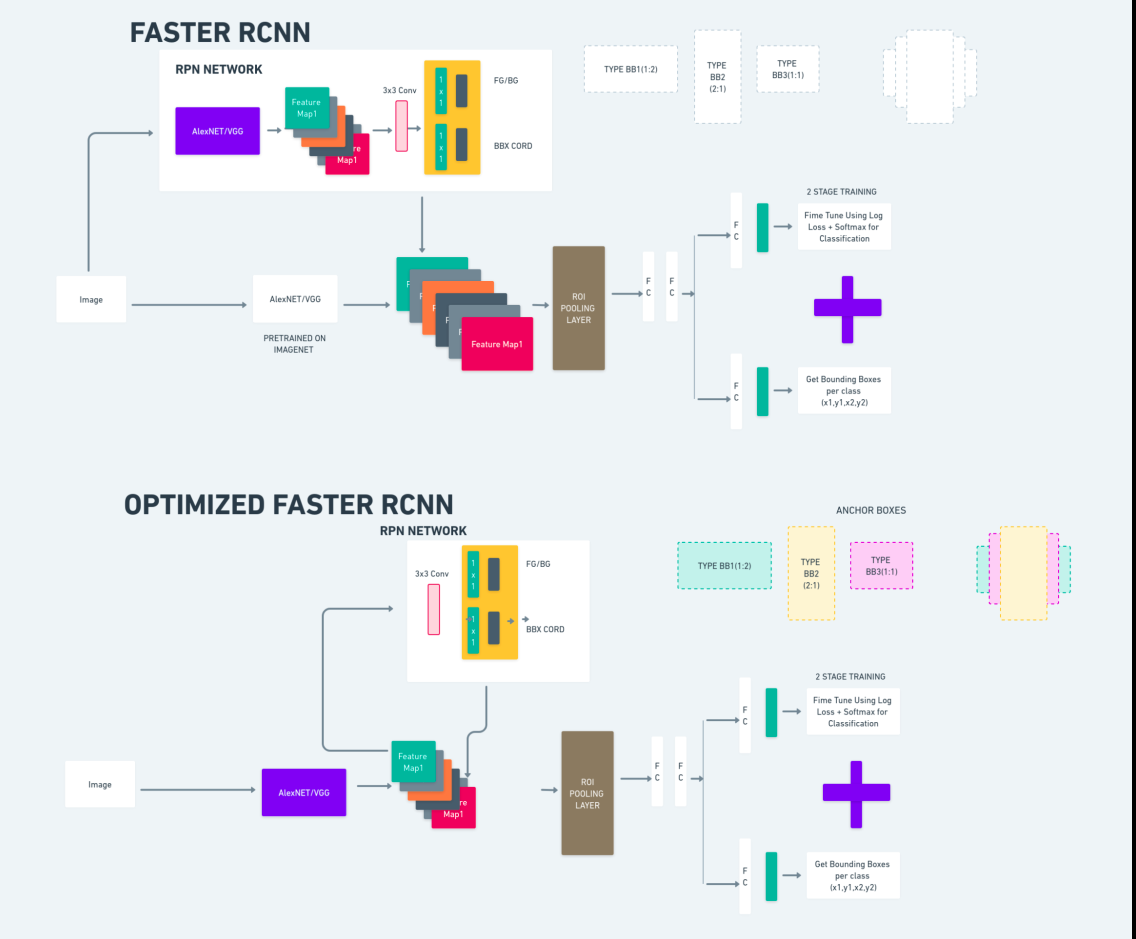
Yukarıdaki diyagram Faster R-CNN ailesini kapsamlı bir şekilde göstermektedir ve her bir algoritmanın değerlendirilmesi için anlaşılması kolaydır.
Tek Çekim Çoklu Kutu Dedektörü (SSD)
The Tek Çekim Çoklu Kutu Dedektörü (SSD)) nesne algılamada popülerdir ve öncelikle bilgisayarla görme görevlerinde kullanılır. Önceki yöntem olan Faster R-CNN'de iki adım izledik: ilk adım tespit kısmını, ikincisi ise regresyonu içeriyordu. Ancak SSD ile yalnızca tek bir algılama adımı gerçekleştiriyoruz. Hızlı ve doğru bir nesne algılama modeline olan ihtiyacı karşılamak için SSD 2016 yılında piyasaya sürüldü.

SSD'nin, Daha Hızlı R-CNN gibi daha önceki nesne algılama yöntemlerine göre çeşitli avantajları vardır:
- Verimlilik: SSD tek aşamalı bir algılayıcıdır; yani ayrı bir teklif oluşturma adımı gerektirmeden sınırlayıcı kutuları ve sınıf puanlarını doğrudan tahmin eder. Bu, Faster R-CNN gibi iki aşamalı dedektörlere kıyasla daha hızlı olmasını sağlar.
- Uçtan Uca Eğitim: SSD, uçtan uca eğitilerek hem temel ağı hem de algılama kafasını ortaklaşa optimize ederek eğitim sürecini basitleştirir.
- Çok Ölçekli Özellik Füzyonu: SSD, birden çok ölçekteki özellik haritaları üzerinde çalışarak, farklı boyutlardaki nesneleri daha etkili bir şekilde algılamasına olanak tanır.
SSD, hız ve doğruluk arasında iyi bir denge kurarak hem performansın hem de verimliliğin kritik olduğu gerçek zamanlı uygulamalar için uygun hale getirir.
Yalnızca Bir Kez Bakarsınız(YOLOv8)
2015 yılında Yalnızca Bir Kez Bakarsınız (YOLO), Joseph Redmon, Santosh Divvala, Ross Girshick ve Ali Farhadi tarafından hazırlanan bir araştırma makalesinde nesne algılama algoritması olarak tanıtıldı. YOLO, yalnızca bir sinir ağının giriş olarak tam bir görüntü kullanarak sınırlayıcı kutuları ve sınıf olasılıklarını tahmin etmesini sağlayarak bir nesneyi tek geçişte doğrudan sınıflandıran tek atışlı bir algoritmadır.
Şimdi YOLOv8'i gerçek zamanlı nesne algılamada gelişmiş doğruluk ve hıza sahip son teknoloji gelişmeler olarak anlayalım. YOLOv8, COCO (Bağlamdaki Ortak Nesneler) gibi geniş bir veri kümesi üzerinde zaten eğitilmiş olan önceden eğitilmiş modellerden yararlanmanıza olanak tanır. Görüntü segmentasyonu, her nesne hakkında piksel düzeyinde bilgi sağlayarak görüntü içeriğinin daha ayrıntılı analizine ve anlaşılmasına olanak tanır.
Görüntü segmentasyonu hesaplama açısından pahalı olsa da YOLOv8 bu yöntemi sinir ağı mimarisine entegre ederek verimli ve doğru nesne segmentasyonuna olanak tanır.
YOLOv8'in Çalışma Prensibi
YOLOv8 önce giriş görüntüsünü ızgara hücrelerine bölerek çalışır. YOLOv8, bu ızgara hücrelerini kullanarak sınıf olasılıklarıyla sınırlayıcı kutuları (bbox) tahmin eder.
Daha sonra YOLOv8, çakışmayı azaltmak için NMS algoritmasını kullanır. Örneğin, görüntüde üst üste binen sınırlayıcı kutularla sonuçlanan birden fazla araba mevcutsa, NMS algoritması bu örtüşmenin azaltılmasına yardımcı olur.
Yolo V8 çeşitleri arasındaki fark: YOLOv8'in üç çeşidi mevcuttur: YOLOv8, YOLOv8-L ve YOLOv8-X. Varyantlar arasındaki temel fark, omurga ağının boyutudur. YOLOv8 en küçük omurga ağına sahipken YOLOv8-X en büyük omurga ağına sahiptir.
Fark Daha Hızlı R-CNN, SSD ve YOLO arasında
| Görünüş | Daha hızlı R-CNN | SSD | YOLO |
|---|---|---|---|
| mimari | RPN ve Hızlı R-CNN'li iki aşamalı dedektör | Tek aşamalı dedektör | Tek aşamalı dedektör |
| Bölge Teklifleri | Evet | Yok hayır | Yok hayır |
| Algılama Hızı | SSD ve YOLO'ya kıyasla daha yavaş | Daha Hızlı R-CNN ile karşılaştırıldığında daha hızlı, YOLO'dan daha yavaş | Çok hızlı |
| doğruluk | Genellikle daha yüksek doğruluk | Dengeli doğruluk ve hız | Özellikle gerçek zamanlı uygulamalar için makul doğruluk |
| Esneklik | Esnektir, çeşitli nesne boyutlarını ve en boy oranlarını işleyebilir | Birden fazla nesne ölçeğini işleyebilir | Küçük nesnelerin doğru konumlandırılmasında zorluk yaşayabilir |
| Birleşik Algılama | Yok hayır | Yok hayır | Evet |
| Hız ve Doğruluk Dengesi | Genellikle doğruluk için hızdan ödün verilir | Hızı ve doğruluğu dengeler | Yeterli doğruluğu korurken hıza öncelik verir |
Segmentasyon nedir?
Bildiğimiz gibi segmentasyon, büyük görüntüyü belirli özelliklere göre daha küçük gruplara bölmek anlamına gelir. Bir görüntüyü farklı çoklu bölümlere veya bölgelere bölmek için kullanılan bilgisayarlı görme tekniği olan görüntü bölümlendirmeyi anlayalım. Görüntüler piksellerden oluştuğundan ve Görüntü segmentasyonunda pikseller renk, yoğunluk, doku veya diğer görsel özelliklerdeki benzerliğe göre birlikte gruplandırılır.
Örneğin, bir görüntü ağaçlar, arabalar veya insanlar içeriyorsa görüntü segmentasyonu, görüntüyü anlamlı nesneleri veya görüntünün bölümlerini temsil eden farklı sınıflara böler. Görüntü segmentasyonu, tıbbi görüntüleme, uydu görüntüsü analizi, bilgisayarlı görmede nesne tanıma ve daha fazlası gibi farklı alanlarda yaygın olarak kullanılmaktadır.

Segmentasyon kısmında öncelikle Robflow kullanarak ilk YOLOv8 segmentasyon modelini oluşturuyoruz. Daha sonra segmentasyon görevini gerçekleştirmek için segmentasyon modelini içe aktarıyoruz. Şu soru ortaya çıkıyor: Görev yalnızca bir algılama algoritmasıyla tamamlanabilecekken neden segmentasyon modelini yaratıyoruz?
Segmentasyon, bir sınıfın tam vücut görüntüsünü elde etmemizi sağlar. Tespit algoritmaları nesnelerin varlığını tespit etmeye odaklanırken segmentasyon, nesnelerin tam sınırlarını çizerek daha kesin bir anlayış sağlar. Bu, görüntüde bulunan nesnelerin daha doğru konumlandırılmasına ve anlaşılmasına yol açar.
Bununla birlikte, segmentasyon genellikle tespit algoritmalarına kıyasla daha yüksek zaman karmaşıklığı içerir çünkü ek açıklamaların ayrılması ve modelin oluşturulması gibi ek adımlar gerektirir. Bu dezavantaja rağmen, segmentasyonun sunduğu artan hassasiyet, hassas nesne tanımlamasının çok önemli olduğu görevlerde hesaplama maliyetinden daha ağır basabilir.
YOLOv8 ile Adım Adım Canlı Tespit ve Görüntü Segmentasyonu
Bu konseptte, conda kullanarak sanal bir ortam oluşturma, venv'yi etkinleştirme ve pip kullanarak gereksinim paketlerini kurma adımlarını araştırıyoruz. önce normal python betiğini oluşturuyoruz, ardından akıcı uygulamayı oluşturuyoruz.
Adım 1: Conda kullanarak Sanal Ortam Oluşturun
conda create -p ./venv python=3.8 -yAdım2: Sanal Ortamı Etkinleştirin
conda activate ./venv
3. Adım: gereksinimleri.txt dosyasını oluşturun
Terminali açın ve aşağıdaki betiği yapıştırın:
touch requirements.txtAdım 4: Nano Komutunu kullanın ve gereksinimleri.txt dosyasını düzenleyin
Gereksinimler.txt'yi oluşturduktan sonra, gereksinimleri.txt'yi düzenlemek için aşağıdaki komutu yazın.
nano requirements.txtYukarıdaki betiği çalıştırdıktan sonra bu kullanıcı arayüzünü görebilirsiniz.
Ona gerekli paketleri yazın.
ultralytics==8.0.32
supervision==0.2.1
streamlitDaha sonra tuşuna basın. “ctrl+o”(bu komut düzenleme bölümünü kaydeder) ve ardından tuşuna basın. "Giriş"
“ tuşuna bastıktan sonraCtrl+x”. dosyadan çıkabilirsiniz. ve ana yola gidiyoruz.
Adım 5: gereksinimleri.txt dosyasını yükleme
pip install -r requirements.txtAdım 6: Python Komut Dosyasını Oluşturun
Terminalde aşağıdaki betiği yazın veya komut diyebiliriz.
touch main.pyMain.py'yi oluşturduktan sonra terminalde write komutunu kullandığınız vs kodunu açın,
code Adım 7: Python Komut Dosyasını Yazma
import cv2
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
cv2.imshow("yolov8", frame)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
Bu komutu çalıştırdıktan sonra kameranızın açık olduğunu ve bir parçanızı tespit ettiğini görebilirsiniz. cinsiyet ve arka plan kısımları gibi.
Adım 7: Kolaylaştırılmış Uygulama oluşturun
import cv2
import streamlit as st
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Set page title and header
st.title("Live Object Detection with YOLOv8")
# Button to start the camera
start_camera = st.button("Start Camera")
if start_camera:
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
st.image(frame, channels="BGR", use_column_width=True)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
if __name__ == "__main__":
main()
Bu scriptimizde Streamlit uygulamasını oluşturup butonu oluşturuyoruz, böylece butona bastıktan sonra cihazınızın kamerası açılıyor ve çerçeve içindeki kısmı algılıyor.
Bu betiği bu komutu kullanarak çalıştırın.
streamlit run app.py
# first create the app.py then paste the above code and run this script.Yukarıdaki komutu çalıştırdıktan sonra aşağıdaki gibi bir erişim hatasıyla karşılaştığınızı varsayalım:
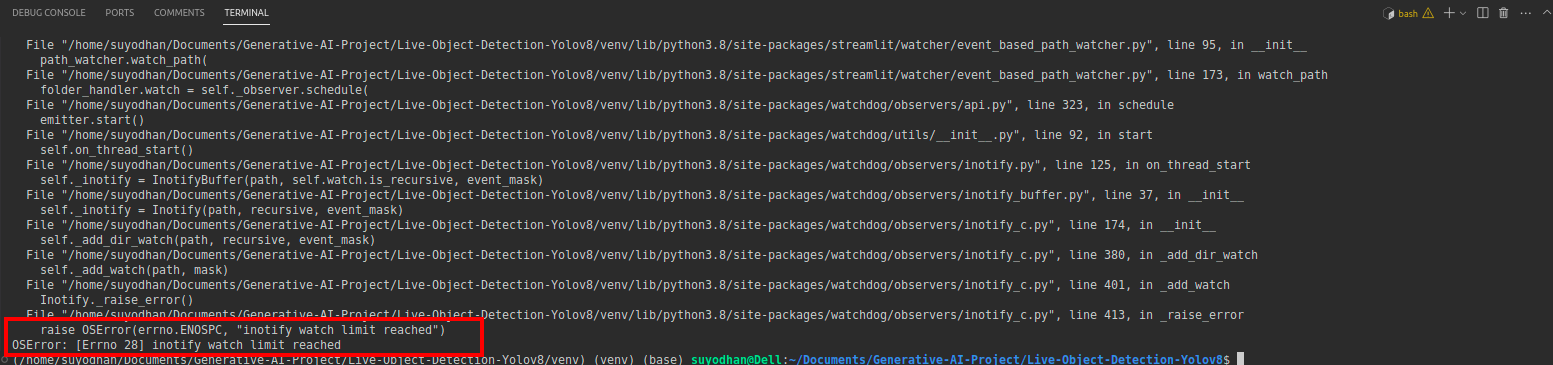
daha sonra bu komuta basın,
sudo sysctl fs.inotify.max_user_watches=524288Şifrenizi yazmak istediğiniz komuta bastıktan sonra sudo komutunu kullanıyoruz çünkü sudo is god :)
Komut dosyasını yeniden çalıştırın. ve akıcı uygulamayı görebilirsiniz.
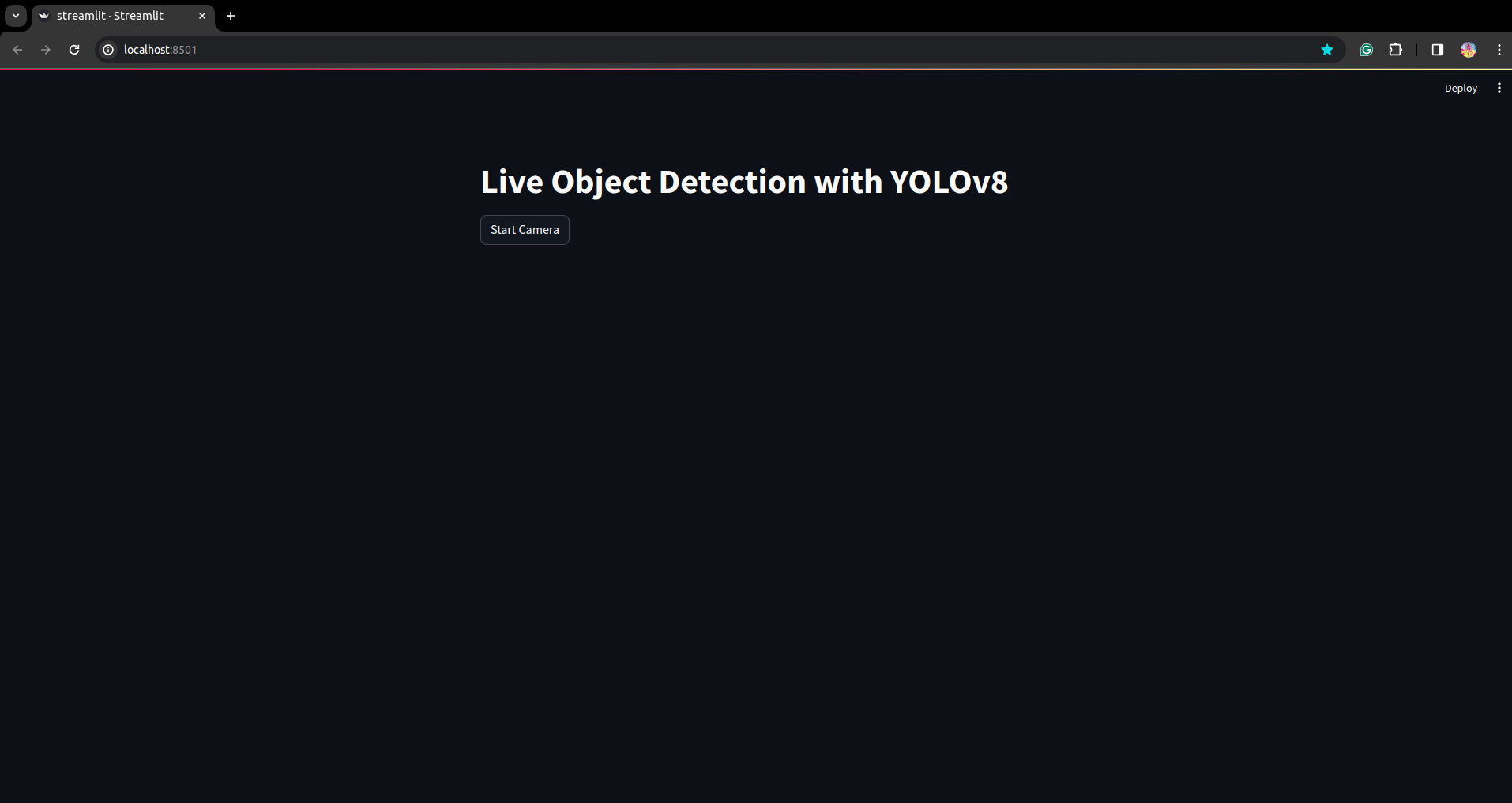
Burada başarılı bir canlı tespit uygulaması oluşturabiliriz bir sonraki bölümde segmentasyon kısmını göreceğiz.
Ek Açıklama Adımları
Adım 1: Roboflow Kurulumu
İmzaladıktan sonra “Proje Oluştur”. burada proje ve açıklama grubunu oluşturabilirsiniz.

Adım2: Veri Kümesi İndirme
Burada basit örneği ele alacağız, ancak bunu sorun bildiriminizde kullanmak istiyorsunuz, bu yüzden burada ördek veri kümesini kullanıyorum.
Buna git Link ve ördek veri kümesini indirin.

Klasörü oradan çıkarın, üç klasörü görebilirsiniz: tren, test ve val.
Adım 3: Veri Kümesini roboflow'a yükleme
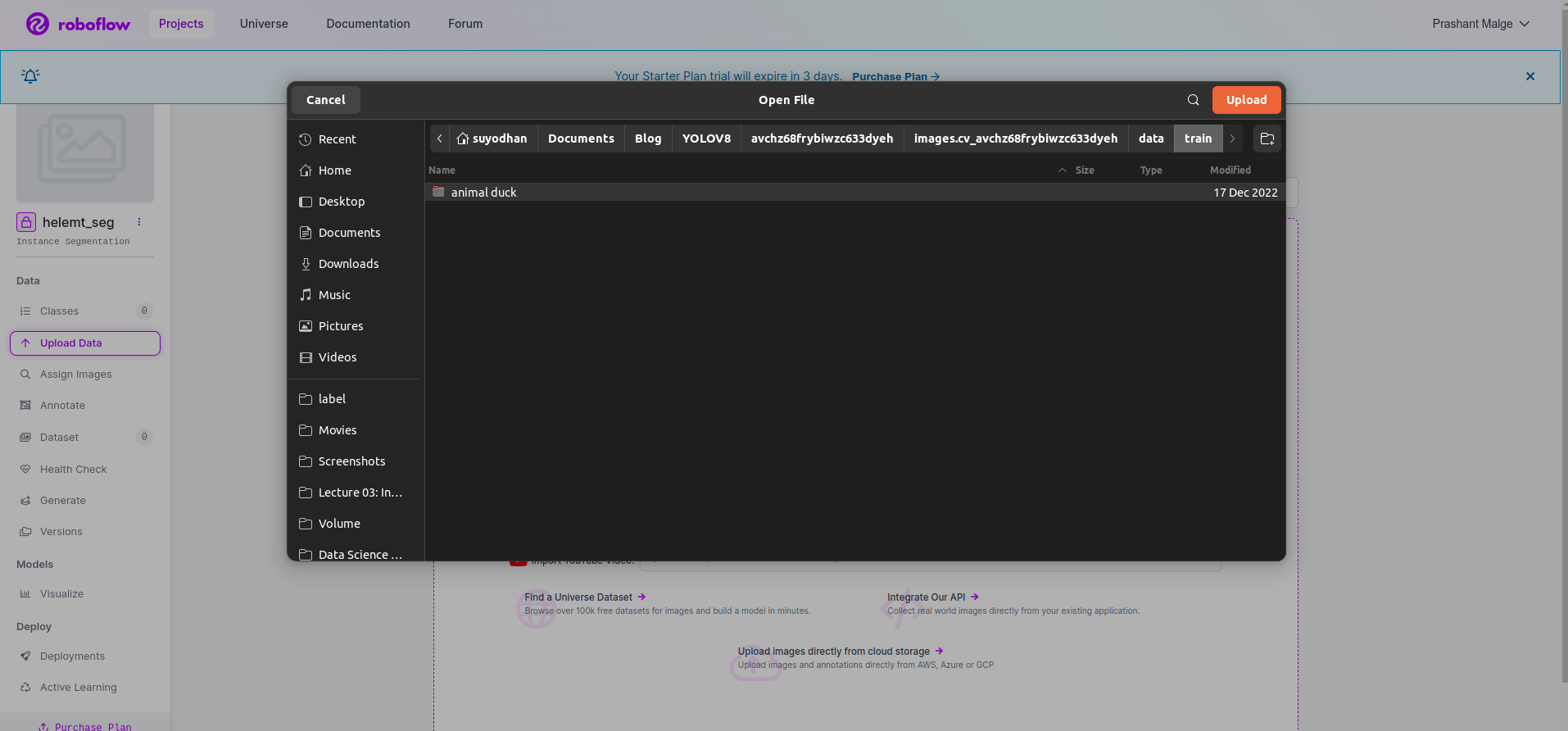
Projeyi roboflow'da oluşturduktan sonra burada bu kullanıcı arayüzünü görebilirsiniz, veri kümenizi yükleyebilirsiniz, böylece yalnızca tren parçası görsellerini yüklüyorsunuz “dosya Seç" seçeneği.
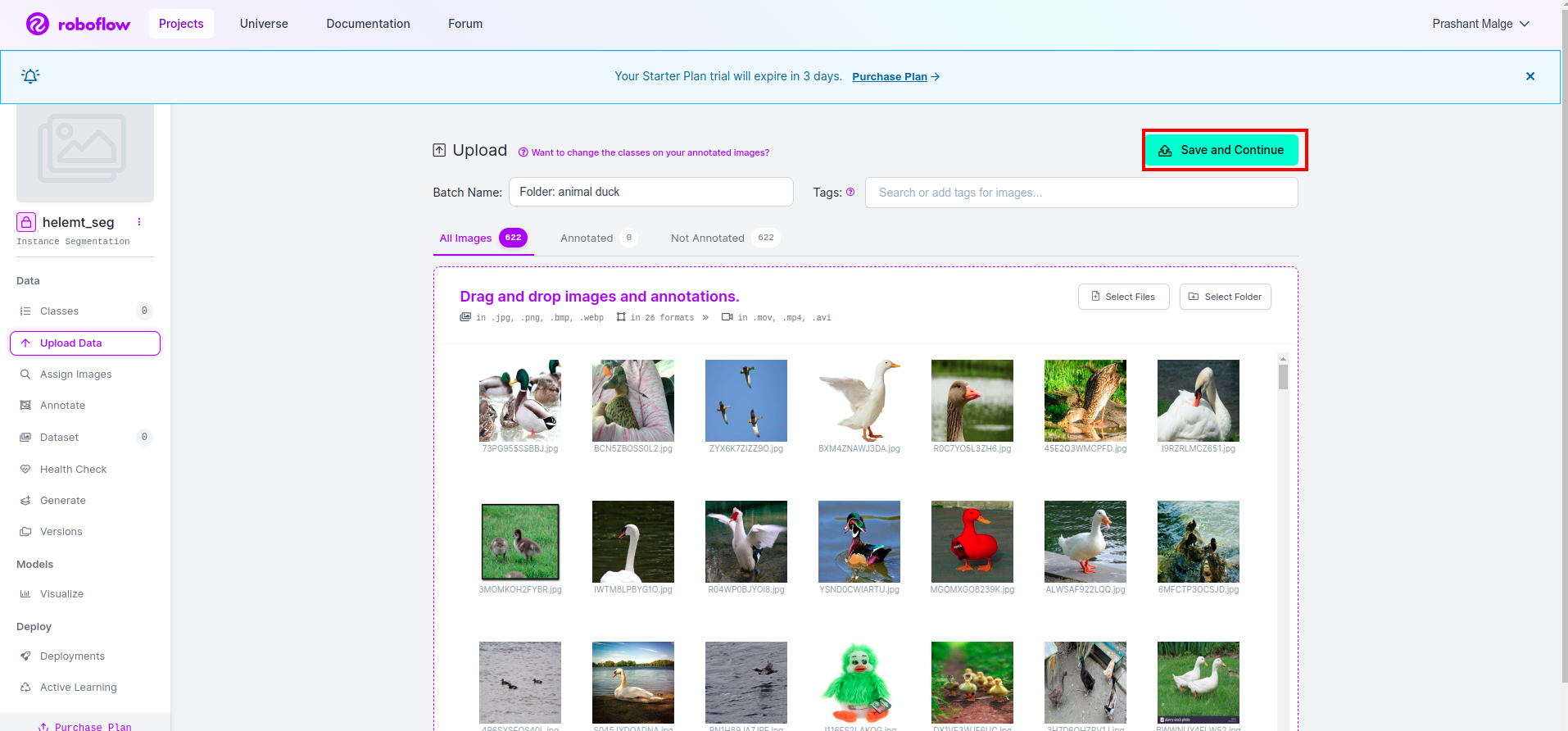
Ardından "kaydet ve devam Et" kırmızı dikdörtgen kutuda işaretlediğim seçenek
Adım4: Sınıf Adını Ekleyin
Sonra git sınıf kısmı sol taraftaki kırmızı kutuyu işaretleyin. ve sınıf adını şu şekilde yazın: ördek, Yeşil kutuya tıkladıktan sonra.
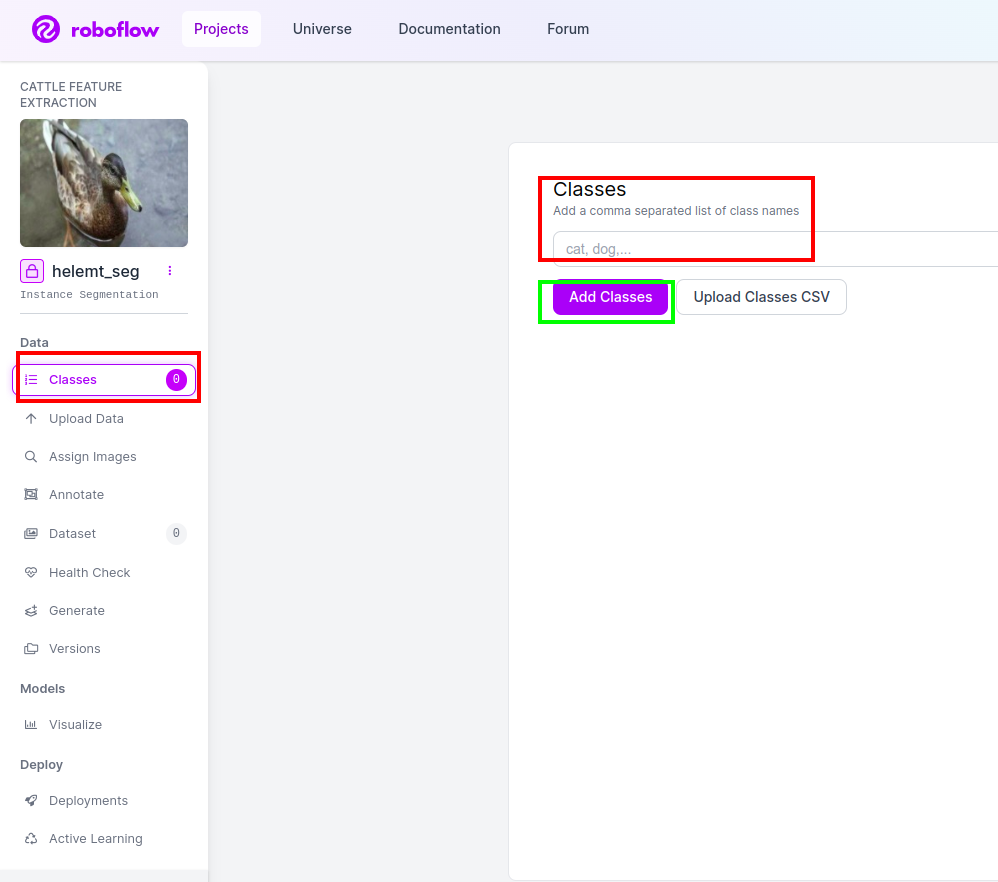
Artık kurulumumuz tamamlandı ve açıklama kısmı gibi bir sonraki kısım da basit.
Adım 5: Başlatın ek açıklama kısmı
Git ek açıklama seçeneği Kırmızı kutuyu işaretledim ve ardından yeşil kutuda işaretlediğim gibi açıklama kısmını başlat kısmına tıkladım.
Bu kullanıcı arayüzünü görebileceğiniz ilk resme tıklayın. Bunu gördükten sonra manuel açıklama seçeneğini tıklayın.
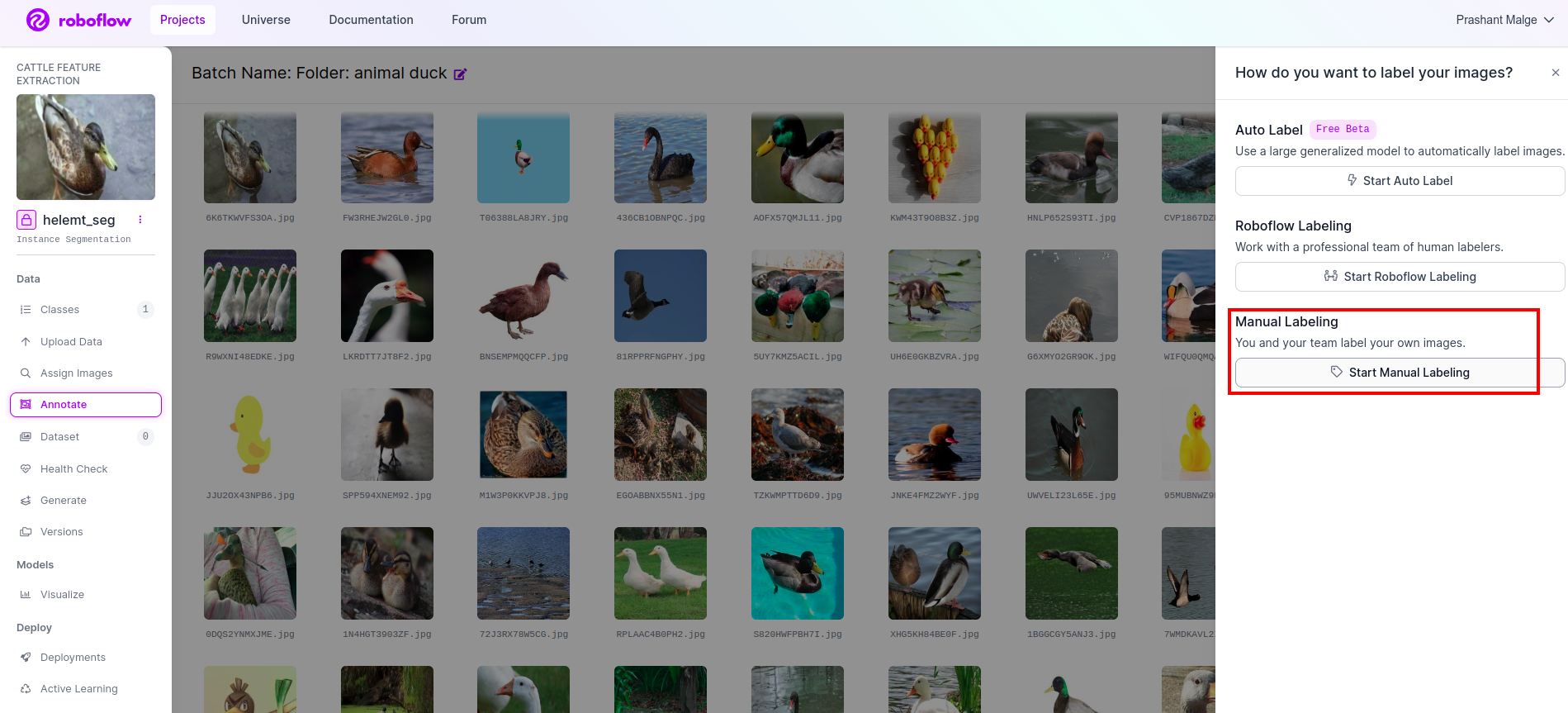
Ardından görevi atayabilmeniz için e-posta kimliğinizi veya ekip arkadaşınızın adını ekleyin.
Bu kullanıcı arayüzünü görebileceğiniz ilk resme tıklayın. çoklu polinom modelini seçebilmeniz için burada kırmızı kutuya tıklayın.
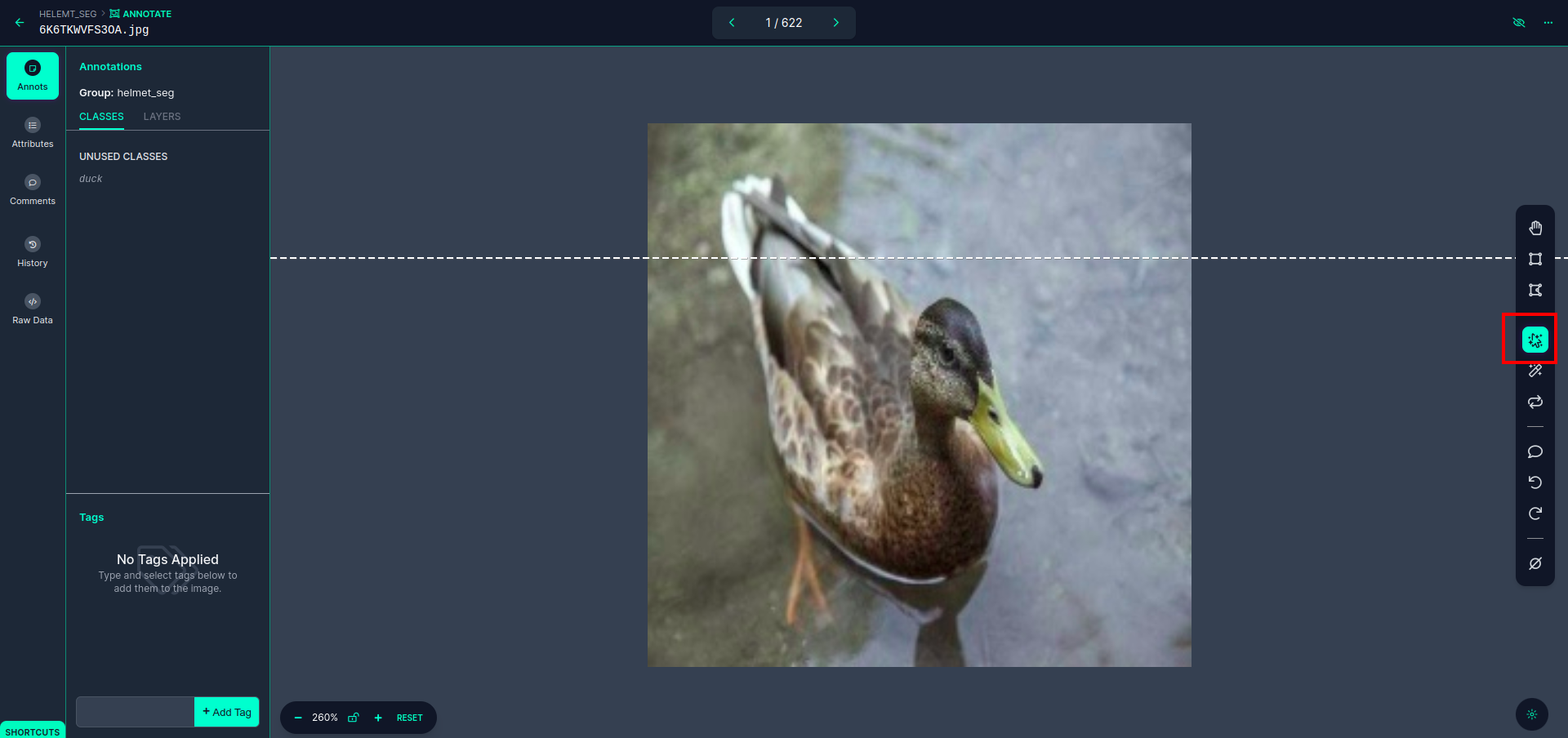
Kırmızı kutuya tıkladıktan sonra varsayılan modeli seçin ve ördek nesnesine tıklayın. Bu, görüntüyü otomatik olarak bölümlere ayıracaktır. Daha sonra bir sonraki bölüme tıklayın ve kaydedin. Daha sonra sol tarafta sınıf adını görebileceğiniz kırmızı bir kutu içinde işaretlenmiş göreceksiniz.
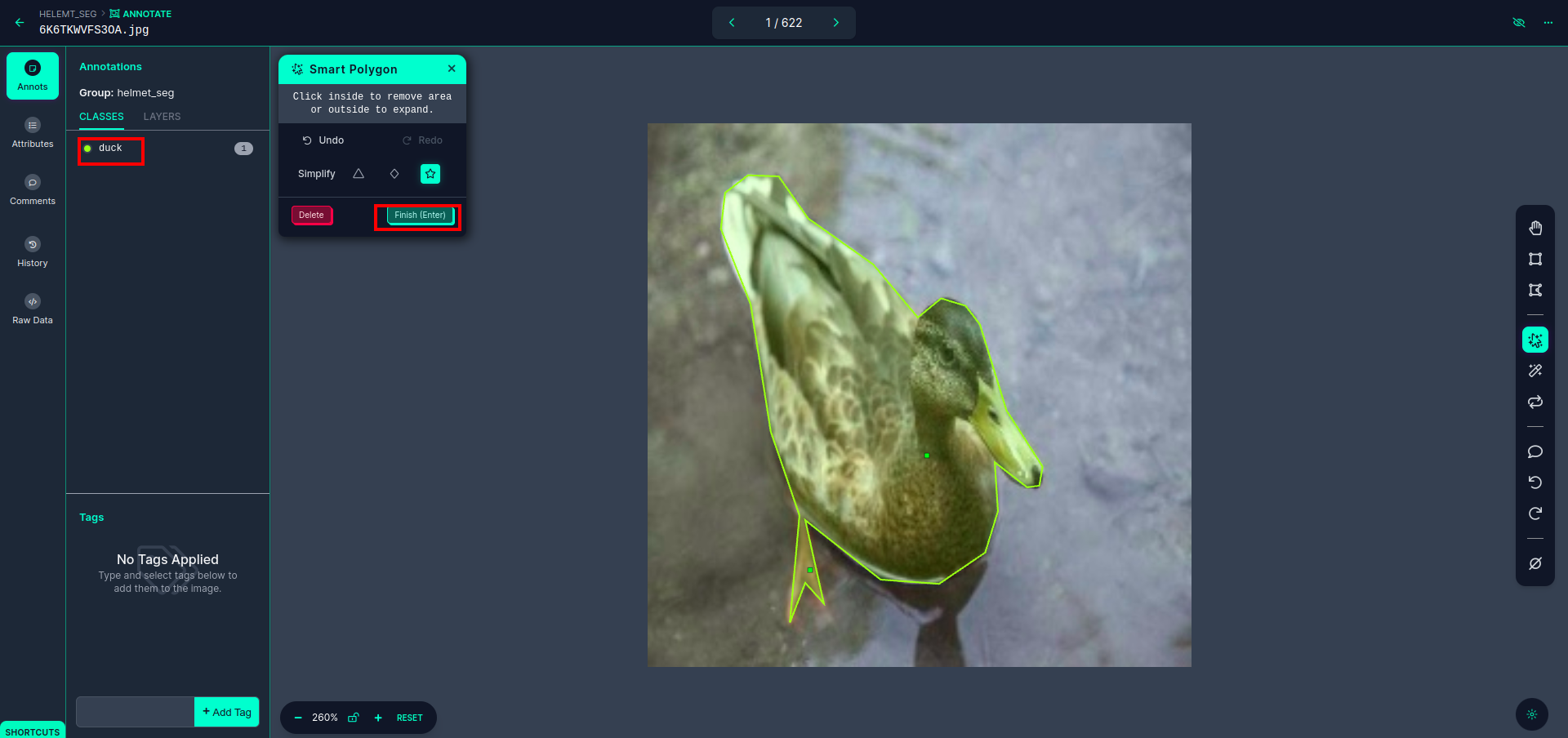
Tıkla kaydet&gir seçenek. tüm resimlere açıklama ekleyin.
YOLOv8 formatı için görselleri ekleyin. Sağ tarafta ek açıklama bölümünde resim ekleme seçeneğini göreceksiniz. Burada iki bölüm oluşturulur: biri açıklamalı görüntüler için, diğeri ise açıklamasız görüntüler için.
- İlk önce sol taraftaki “açıklama ekle” o zaman seçenek eklemek görüntüler veri kümesine.
- Daha sonra bir sonraki “Görsel ekle".
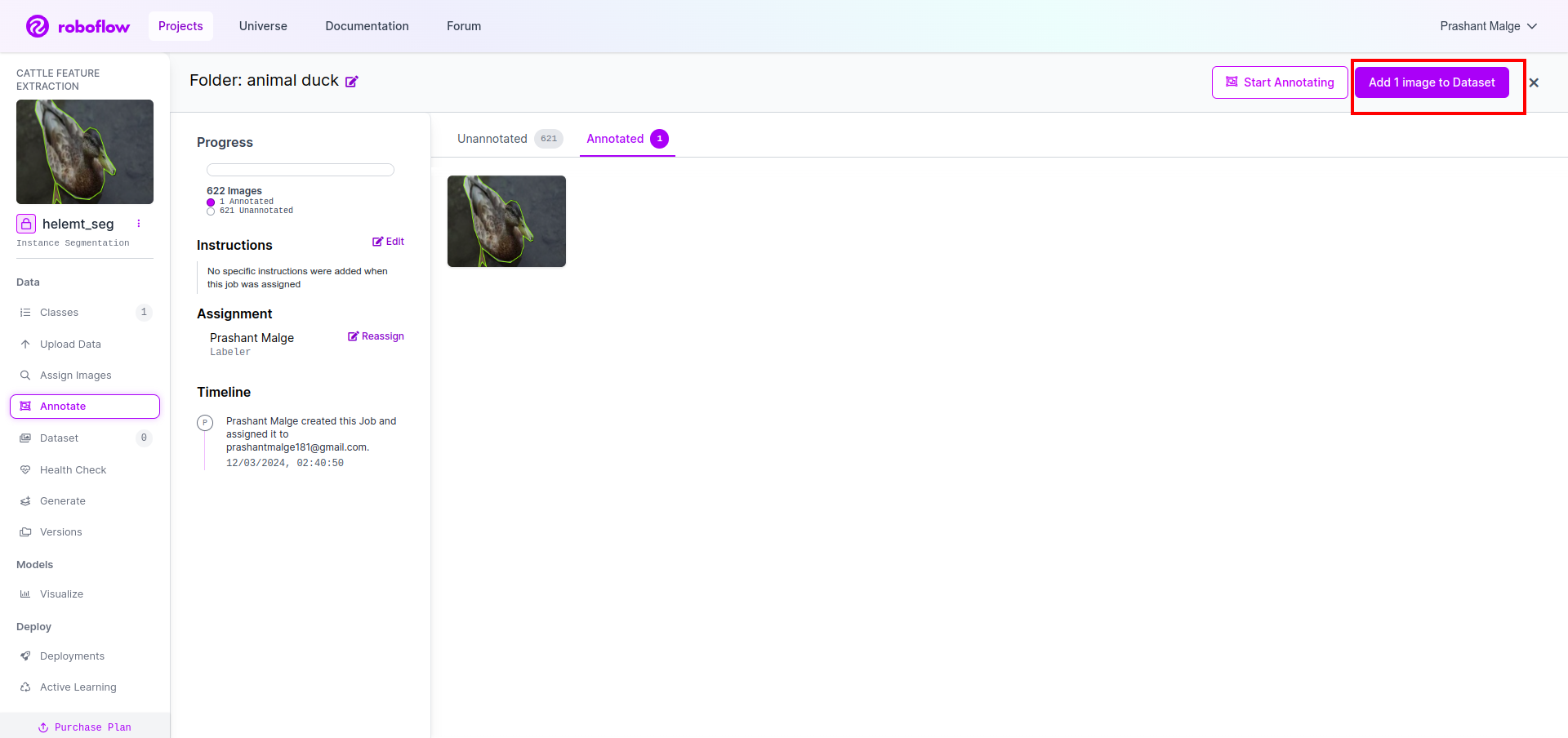
Şimdi son olarak veri setini oluşturuyoruz, sol taraftaki “Oluştur” seçeneğine tıklayın, ardından seçeneği işaretleyin ve devam et seçeneğine basın.
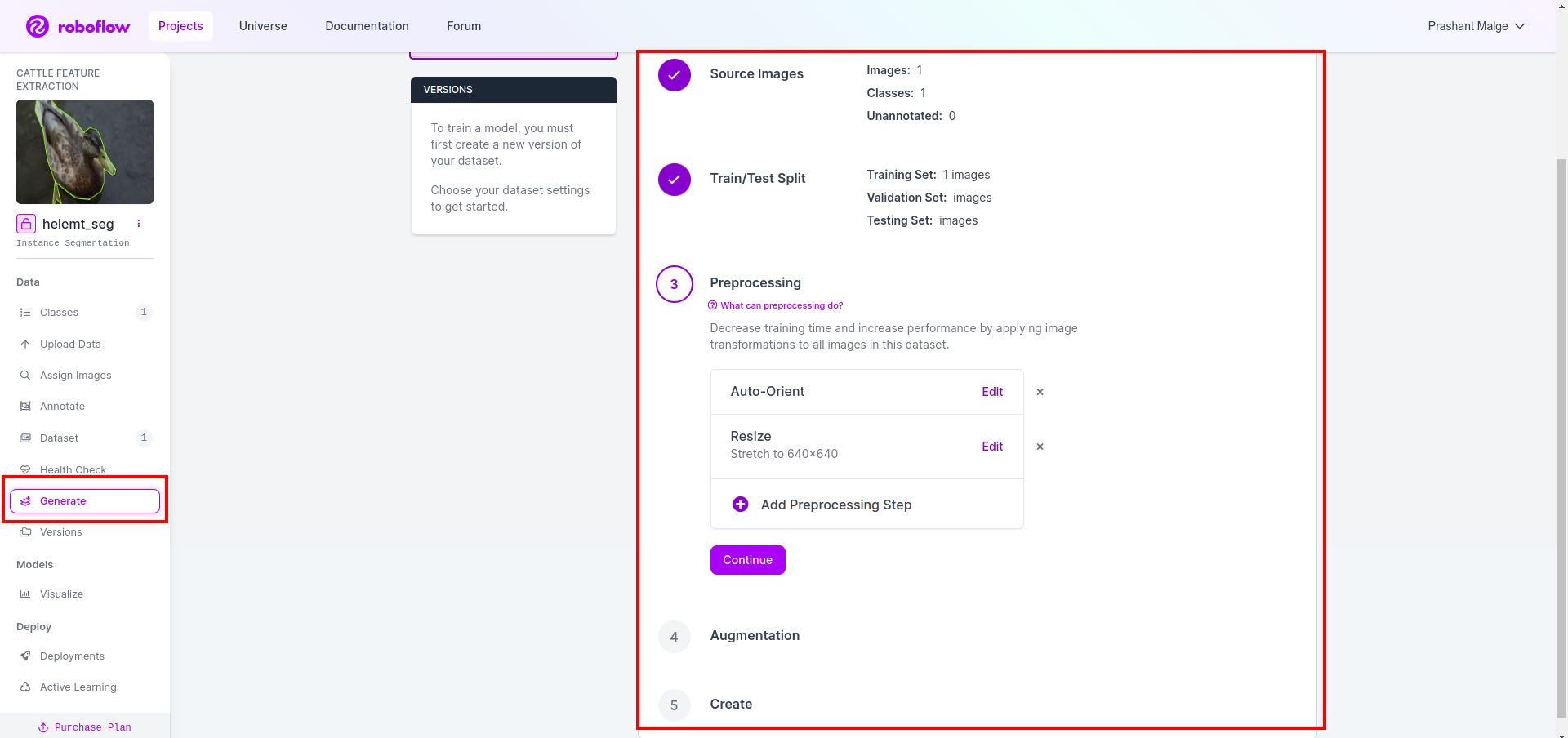
Daha sonra veri kümesi bölme seçeneğinin kullanıcı arayüzünü alırsınız, burada görüntülerin otomatik olarak bölündüğü tren, test ve val klasörlerini kontrol edebilirsiniz. ve yukarıdaki kırmızı kutuya tıklayın Veri Kümesini Dışa Aktar seçeneği ve zip dosyasını indirin. zip dosyası klasör yapısı şuna benzer…
root_file.zip
│
├── test
│ ├── Images
│ └── labels
│
├── train
│ ├── Images
│ └── labels
│
├── val
│ ├── Images
│ └── labels
│
├── data.yaml
└── Readme.roboflow.txt
Adım 6: Görüntü segmentasyon modelini eğitmek için komut dosyasını yazın
Bu bölümde öncelikle Drive'ı kullanarak Google Collab dosyasını oluşturup ardından veri kümenizi yükleyeceksiniz. ve Google Collab'ı kullanarak Google Drive'ı aktarın.
1. Bu komutu şunun için kullanın: Google Drive'ı bağlayın
from google.colab import drive
drive.mount('/content/gdrive')2. Veri dizinini tanımlayın Sabit değişkeni kullanın.
DATA_DIR = '/content/drive/MyDrive/YoloV8/Data/'3. Gerekli paketin kurulumu, Ultralytics'i yükleyin
!pip install ultralytics4. Kütüphanelerin içe aktarılması
import os
from ultralytics import YOLO5. Yükle önceden eğitilmiş YOLOv8 model (burada farklı modelimiz var ayrıca resmi belgeleri kontrol edin, orada farklı modeli görebilirsiniz)
model = YOLO('yolov8n-seg.pt')
# load a pretrained model (recommended for training)
6. Modeli Eğit
model.train(data='/content/drive/MyDrive/YoloV8/Data/data.yaml', epochs=2, imgsz=640)
# Update the path & and join this line together Sürücünüzü kontrol etmeyin Model adı klasörü oluşturulur ve bu modeli istediğimiz tahmin için model kaydedilir.
7. Modeli Tahmin Et
#Update the path
model_path = '/content/drive/MyDrive/YoloV8/Model/train2/weights/last.pt'
#Update the path
image_path = '/content/drive/MyDrive/YoloV8/Data/val/1be566eccffe9561.png'
img = cv2.imread(image_path)
H, W, _ = img.shape
model = YOLO(model_path)
results = model(img)
for result in results:
for j, mask in enumerate(result.masks.data):
mask = mask.numpy() * 255
mask = cv2.resize(mask, (W, H))
cv2.imwrite('./output.png', mask)Burada segmentasyon görüntüsünün kaydedildiğini görebilirsiniz.

Artık nihayet hem canlı tespit hem de görüntü segmentasyon modellerini oluşturabiliriz.
Sonuç
Bu blogda YOLOv8 ile canlı nesne algılamayı ve görüntü segmentasyonunu araştırıyoruz. Canlı algılama için, önceden eğitilmiş bir YOLOv8 modelini içe aktarıyoruz ve kamerayı açmak ve nesneleri algılamak için bilgisayarlı görme kitaplığı OpenCV'yi kullanıyoruz. Ayrıca çekici bir kullanıcı arayüzü için Streamlit uygulaması oluşturuyoruz.
Daha sonra YOLOv8 ile görüntü segmentasyonuna geçiyoruz. Önceden eğitilmiş bir modeli içe aktarıyoruz ve özel bir veri kümesi üzerinde transfer öğrenimi gerçekleştiriyoruz. Bundan önce, veri kümesi açıklaması için Roboflow'u araştırdık ve aşağıdaki gibi araçlara kullanımı kolay bir alternatif sağladık: Etiket Görüntüsü.
Son olarak ördek içeren bir görsel tahmin ediyoruz. Görseldeki nesne her ne kadar kuş gibi görünse de sınıf adını “” olarak belirtiyoruz.ördekGösteri amaçlı.
Önemli Noktalar
- Faster R-CNN, SSD ve en yeni YOLOv8 gibi nesne algılama modelleri hakkında bilgi edinme.
- Ek açıklama aracı Roboflow'u ve YOLOv8 segmentasyon modelleri için veri kümeleri oluşturmadaki rolünü anlamak.
- OpenCV (cv2) ve Denetim kullanarak canlı nesne algılamayı keşfederek pratik becerileri geliştirin.
- YOLOv8'i kullanarak bir segmentasyon modelini eğitmek ve dağıtmak, uygulamalı deneyim kazanmak.
Sık Sorulan Sorular
A. Nesne tespiti, genellikle etraflarına sınırlayıcı kutular çizerek bir görüntü içindeki birden fazla nesnenin tanımlanmasını ve yerinin belirlenmesini içerir. Görüntü segmentasyonu ise görüntüyü piksel benzerliğine dayalı olarak parçalara veya bölgelere bölerek nesne sınırlarının daha ayrıntılı anlaşılmasını sağlar.
A. YOLOv8, ağ mimarisi, eğitim teknikleri ve optimizasyondaki gelişmeleri birleştirerek önceki sürümleri geliştirir. YOLOv3'e kıyasla daha iyi doğruluk, hız ve verimlilik sunabilir.
C. YOLOv8, donanım yeteneklerine ve model optimizasyonuna bağlı olarak gömülü cihazlarda gerçek zamanlı nesne tespiti için kullanılabilir. Ancak kaynak kısıtlı cihazlarda gerçek zamanlı performans elde etmek için model budama veya niceleme gibi optimizasyonlar gerekebilir.
C. Roboflow, sezgisel açıklama araçları, veri kümesi yönetimi özellikleri ve çeşitli açıklama formatları için destek sunar. Ek açıklama sürecini kolaylaştırır, işbirliğine olanak tanır ve sürüm kontrolü sağlayarak görüntü işleme projeleri için veri kümelerini oluşturmayı ve yönetmeyi kolaylaştırır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2024/03/live-object-detection-and-image-segmentation-with-yolov8/

