Giriş
Dünyasında yapay zekaMakinelerin mevcut bilgilerini geliştirmelerine ve uzmanlıkla yeni zorlukların üstesinden gelmelerine olanak tanıyan bir öğrenme tekniği hayal edin. Bu benzersiz tekniğe transfer öğrenme adı verilir. Son yıllarda üretken modellerin yeteneklerinde ve uygulamalarında bir genişlemeye tanık olduk. Üretken modellerin eğitimini basitleştirmek için transfer öğrenmeyi kullanabiliriz. Çeşitli sanat türlerinde ustalaşmış, farklı becerilerinden yararlanarak zahmetsizce bir başyapıt yaratabilen yetenekli bir sanatçıyı hayal edin. Benzer şekilde, transfer öğrenimi, makinelerin bir alanda edinilen bilgiyi başka bir alanda başarılı olmak için kullanmasını sağlar. Bilgiyi aktarmanın bu fantastik, inanılmaz yeteneği, yapay zekada bir olasılıklar dünyasının kapılarını açtı.
Öğrenme hedefleri
Bu yazıda,
- Transfer öğrenimi kavramı hakkında bilgi edinin ve makine öğrenimi dünyasında sunduğu avantajları keşfedin.
- Ayrıca transfer öğreniminin etkili bir şekilde kullanıldığı çeşitli gerçek dünya uygulamalarını da inceleyeceğiz.
- Ardından taş-kağıt-makas el hareketlerini sınıflandırmak için adım adım bir model oluşturma sürecini anlayın.
- Modelinizi etkili bir şekilde eğitmek ve test etmek için transfer öğrenme tekniklerini nasıl uygulayacağınızı keşfedin.
Bu makale, Veri Bilimi Blogathon.
İçindekiler
Transfer Öğrenimi
Çocuk olduğunuzu ve ilk kez bisiklete binmeyi heyecanla öğrenmek istediğinizi hayal edin. Dengeyi korumanız ve öğrenmeniz zor olacaktır. O zaman her şeyi sıfırdan öğrenmeniz gerekir. Dengeyi korumayı, direksiyonu tutmayı, molaları kullanmayı ve her şeyin en iyisi olacağını hatırlamak. Çok zaman alır ve birçok başarısız denemeden sonra sonunda her şeyi öğreneceksiniz.
Benzer şekilde şimdi de motosiklet öğrenmek istediğinizi hayal edin. Bu durumda çocuklukta yaptığınız gibi her şeyi sıfırdan öğrenmek zorunda değilsiniz. Artık birçok şeyi zaten biliyorsunuz. Dengeyi nasıl koruyacağınız, direksiyonu nasıl kullanacağınız, molaları nasıl kullanacağınız gibi bazı becerileriniz zaten var. Artık tüm bu becerileri aktarmanız ve dişli kullanma gibi ek beceriler öğrenmeniz gerekiyor. Bunu sizin için çok daha kolay hale getiriyoruz ve öğrenmesi daha az zaman alıyor. Şimdi transfer öğrenimini teknik açıdan anlayalım.
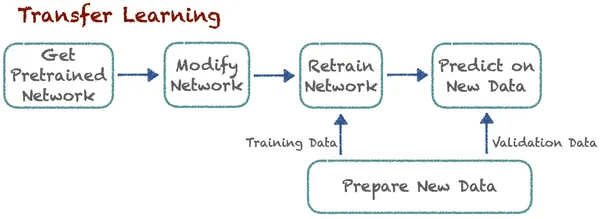
Transfer Öğrenme, uzmanların zaten keşfettiği ilgili bir dersten bilgi aktararak yeni bir görevde öğrenmeyi geliştirir. Bu teknik, algoritmaların önceden eğitilmiş modelleri kullanarak yeni işleri hatırlamasını sağlar. Diyelim ki kedileri ve köpekleri sınıflandıran bir algoritma var. Artık uzmanlar, arabaları ve kamyonları sınıflandırmak için aynı önceden eğitilmiş modeli bazı değişikliklerle kullanıyor. Buradaki temel fikir sınıflandırmadır. Burada yeni görevlerin öğrenilmesi önceden bilinen derslere dayanır. Algoritma önceden öğrenilen bu bilgiyi saklayabilir ve bu bilgiye erişebilir.
Transfer Öğreniminin Faydaları
- Daha Hızlı Öğrenme: Model sıfırdan öğrenmediğinden yeni görevleri öğrenmek çok az zaman alır. Önceden eğitilmiş bilgileri kullanarak eğitim süresini ve hesaplama kaynaklarını önemli ölçüde azaltır. Modelin bir avantaja ihtiyacı var. Bu sayede daha hızlı öğrenme avantajına sahiptir.
- Geliştirilmiş Performans: Transfer öğrenimini kullanan modeller, özellikle her şeyi sıfırdan öğrenen modellere kıyasla, ilgili görev için önceden eğitilmiş bir modele ince ayar yaptıklarında daha iyi performans elde eder. Bu daha yüksek doğruluk ve verimliliğe yol açtı.
- Veri Verimliliği: Derin öğrenme modellerinin eğitiminin çok fazla veri gerektirdiğini biliyoruz. Ancak, bilgiyi kaynak alandan miras aldıkları için transfer öğrenme modelleri için daha küçük veri kümelerine ihtiyacımız var. Böylece büyük miktarda etiketli veriye olan ihtiyacı azaltır.
- Kaynakları kaydeder: Büyük ölçekli modelleri sıfırdan oluşturmak ve sürdürmek kaynak yoğun olabilir. Transfer öğrenimi, kuruluşların mevcut kaynakları etkili bir şekilde kullanmasını sağlar. Ayrıca eğitmek için yeterli veriyi elde etmek için çok fazla kaynağa ihtiyacımız yok.
- Sürekli Öğrenme: Sürekli öğrenme transfer öğrenmeyle sağlanabilir. Modeller sürekli olarak yeni verileri, görevleri veya ortamları öğrenebilir ve bunlara uyum sağlayabilir. Böylece makine öğreniminin olmazsa olmazı olan sürekli öğrenmeyi başarır.
- Son Teknoloji Sonuçlar: Transfer öğrenimi, en gelişmiş sonuçların elde edilmesinde çok önemli bir rol oynamıştır. Birçok makine öğrenimi yarışmasında ve kıyaslamasında en gelişmiş sonuçları elde etti. Artık bu alanda standart bir teknik haline geldi.
Transfer Öğrenme Uygulamaları
Transfer öğrenimi, yeni şeyler öğrenmeyi daha kolay hale getirmek için mevcut bilginizi kullanmaya benzer. Bilgisayar programlarının yeteneklerini geliştirmek için farklı alanlarda yaygın olarak kullanılan güçlü bir tekniktir. Şimdi transfer öğreniminin hayati bir rol oynadığı bazı ortak alanları inceleyelim.
Bilgisayar görüşü:
çok Bilgisayar görüşü Görevler, özellikle uzmanların belirli nesne tanıma görevleri için ResNet, VGG veya MobileNet gibi önceden eğitilmiş modellere ince ayar yaptığı nesne algılamada, transfer öğrenimini yaygın olarak kullanır. FaceNet ve OpenFace gibi bazı modeller, farklı aydınlatma koşulları, pozlar ve açılardaki yüzleri tanımak için transfer öğrenmeyi kullanır. Önceden eğitilmiş modeller aynı zamanda görüntü sınıflandırma görevleri için de uyarlanmıştır. Bunlara tıbbi görüntü analizi, yaban hayatı izleme ve üretimde kalite kontrol dahildir.
Doğal Dil İşleme (NLP):
Gibi bazı transfer öğrenme modelleri vardır Bert ve GPT bu modellerin duyarlılık analizi için ince ayarlandığı yer. Metnin çeşitli durumlardaki duygusunu anlayabilmeleri için Google'ın Transformer modeli, metni diller arasında çevirmek için transfer öğrenmeyi kullanır.
Otonom Araçlar:
Transfer öğrenmenin uygulanması özerk araçlar otomotiv sektöründe hızla gelişen ve kritik bir gelişme alanıdır. Bu alanda transfer öğrenmenin kullanıldığı pek çok kesim bulunmaktadır. Bunlardan bazıları nesne tespiti, nesne tanıma, yol planlama, davranış tahmini, sensör füzyonu, trafik kontrolleri ve çok daha fazlasıdır.
İçerik Üretimi:
içerik oluşturma transfer öğreniminin heyecan verici bir uygulamasıdır. GPT-3 (Generative Pre-trained Transformer 3) büyük miktarda metin verisi üzerinde eğitilmiştir. Birçok alanda yaratıcı içerik üretebilir. GPT-3 ve diğer modeller sanat, müzik, hikaye anlatımı ve kod oluşturma gibi yaratıcı içerikler üretir.
Öneri Sistemleri:
Avantajlarını hepimiz biliyoruz öneri sistemleri. Bu, hayatımızı biraz daha kolaylaştırıyor ve evet burada da transfer öğrenmeyi kullanıyoruz. Netflix ve YouTube da dahil olmak üzere birçok çevrimiçi platform, kullanıcı tercihlerine göre film ve video önermek için aktarım öğrenimini kullanır.
Daha Fazla Bilgi: Derin Öğrenme için Transfer Öğrenmeyi Anlamak
Üretken Modellerin Geliştirilmesi
Üretken modeller, hızla gelişen yapay zeka alanındaki en heyecan verici ve devrim niteliğindeki kavramlardan biridir. Transfer öğrenimi, birçok açıdan üretken yapay zeka modellerinin işlevselliğini ve performansını iyileştirebilir. GAN'lar (Üretken Rekabetçi Ağlar) or VAE'ler (Varyasyonel Otomatik Kodlayıcılar). Transfer öğreniminin temel faydalarından biri, modellerin edinilen bilgiyi farklı ilgili görevlerde kullanmasına izin vermesidir. Üretken modellerin kapsamlı eğitim gerektirdiğini biliyoruz. Daha iyi sonuçlar elde etmek için, onu büyük veri kümeleri üzerinde eğitmek önemlidir; bu, transfer öğrenimi tarafından güçlü bir şekilde desteklenen bir uygulamadır. Modeller sıfırdan başlamak yerine önceden var olan bilgilerle faaliyet başlatabilir.
GAN'lar veya VAE'ler söz konusu olduğunda uzmanlar, modelin ayırıcı veya kodlayıcı-kod çözücü kısımlarını daha geniş bir veri kümesi veya etki alanı üzerinde önceden eğitebilir. Bu eğitim sürecini hızlandırabilir. Üretken modeller, yüksek kaliteli içerik oluşturmak için genellikle büyük miktarda alana özgü verilere ihtiyaç duyar. Transfer öğrenimi, yalnızca daha küçük veri kümeleri gerektirdiğinden bu sorunu çözebilir. Aynı zamanda üretken modellerin sürekli öğrenilmesini ve uyarlanmasını da kolaylaştırır.
Transfer öğrenimi, üretken yapay zeka modellerinin geliştirilmesinde halihazırda pratik uygulamalar bulmuştur. Görüntü oluşturmak ve kod yazmak için GPT-3 gibi metin tabanlı modelleri uyarlamak için kullanılmıştır. GAN'lar söz konusu olduğunda transfer öğrenimi, hiper gerçekçi görüntüler oluşturmaya yardımcı olabilir. Üretken yapay zeka daha iyi olmaya devam ettikçe, transfer öğrenimi onun daha da mükemmel şeyler yapmasına yardımcı olma açısından son derece önemli olacaktır.
MobilNet V2
Google, bilgisayarla görme ve derin öğrenme uygulamalarında yaygın olarak kullanılan, önceden eğitilmiş sağlam bir sinir ağı mimarisi olan MobileNetV2'yi yarattı. Başlangıçta bu modelin, çeşitli görevlerde üstün performans elde etmeyi hedefleyerek görüntüleri hızlı bir şekilde işlemesi ve analiz etmesi amaçlandı. Artık birçok bilgisayarlı görme görevi için çok sevilen bir seçenektir. MobileNetV2 özellikle hafif ve verimli olacak şekilde tasarlanmıştır. Nispeten az sayıda parametre alır ve son derece doğru, etkileyici sonuçlar elde eder.
Verimliliğine rağmen MobileNetV2, çeşitli bilgisayarlı görme görevlerinde yüksek doğruluğu korur. MobileNetV2 ters çevrilmiş artıklar konseptini sunar. Bir katmanın çıktısının girişine eklendiği geleneksel artıkların aksine, ters çevrilmiş artıklar, bilgiyi üretime eklemek için bir kısayol bağlantısı kullanır. Modeli daha derin ve daha verimli hale getirir.
Tersine çevrilmiş artıklar, bir katmanın çıktısının girdisine eklendiği geleneksel artıkların aksine, bilgiyi üretime eklemek için bir kısayol bağlantısı kullanır. Bu önceden eğitilmiş MobileNetV2 modelini alıp belirli uygulamalar için ince ayar yapabilirsiniz. Böylece, hem zamandan hem de hesaplama kaynaklarından tasarruf sağlar ve hesaplama maliyetinin azalmasına yol açar. Etkinliği ve verimliliği nedeniyle MobileNetV2 endüstride ve araştırmalarda yaygın olarak kullanılmaktadır. TensorFlow Hub, önceden eğitilmiş MobileNetV2 modellerine kolay erişim sağlar. Modelin Tensorflow tabanlı projelere entegre edilmesini kolaylaştırır.
Taş-Kağıt-Makas Sınıflandırması
Bir inşaat yapmaya başlayalım makine öğrenme Taş-kağıt-makas sınıflandırma görevi için model. Uygulamak için transfer öğrenme tekniğini kullanacağız. Bunun için MobileNet V2 önceden eğitilmiş modelini kullanıyoruz.

Taş-Kağıt-Makas Veri Kümesi
'Taş Kağıt Makas' veri kümesi 2,892 görselden oluşan bir koleksiyondur. Her üç farklı pozda da farklı ellerden oluşur. Bunlar,
- Kaya: Sıkılmış yumruk.
- Kağıt: Açık avuç içi.
- Makas: İki uzatılmış parmak bir V oluşturuyor.
Görüntülerde farklı ırklardan, yaşlardan ve cinsiyetlerden insanların elleri yer alıyor. Tüm resimler aynı düz beyaz arka plana sahiptir. Bu çeşitlilik onu makine öğrenimi ve bilgisayarlı görme uygulamaları için değerli bir kaynak haline getirir. Bu, hem fazla takmanın hem de az takmanın önlenmesine yardımcı olur.
Veri Kümesini Yükleme ve Keşfetme
Gerekli temel kütüphaneleri içe aktararak başlayalım. Bu proje, veri kümesi için tensorflow, tensorflow hub'ı, tensorflow veri kümeleri, görselleştirme için matplotlib, numpy ve işletim sistemi gerektirir.
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
import matplotlib.pylab as plt
import numpy as np
import os
Tensorflow veri kümelerini kullanarak "Taş Kağıt Makas" veri kümesini yükleyin. Burada ona dört parametre sağlıyoruz. Yüklememiz gereken veri setinin adını belirtmemiz gerekiyor. İşte rock_paper_scissors. Veri kümesi hakkında bilgi istemek için with_info'yu True olarak ayarlayın. Daha sonra, veri kümesini denetlenen biçimde yüklemek için as_supervised değerini True olarak ayarlayın.
Ve son olarak yüklemek istediğimiz bölmeleri tanımlayın. Burada bölümleri eğitmemiz ve test etmemiz gerekiyor. Veri kümelerini ve bilgileri ilgili değişkenlere yükleyin.
datasets, info = tfds.load( name='rock_paper_scissors', # Specify the name of the dataset you want to load. with_info=True, # To request information about the dataset as_supervised=True, # Load the dataset in a supervised format. split=['train', 'test'] # Define the splits you want to load.
)
Bilgiyi Yazdır
Şimdi bilgileri yazdırın. Veri kümesinin tüm ayrıntılarını yayınlayacaktır. Ad, sürüm, açıklama, orijinal veri kümesi kaynağı, özellikler, toplam görsel sayısı, bölünmüş sayılar, yazar ve daha birçok ayrıntı.
info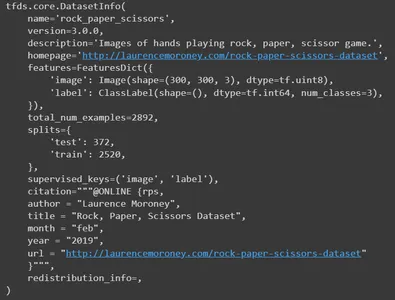
Şimdi eğitim veri kümesinden bazı örnek görselleri yazdırın.
train, info_train = tfds.load(name='rock_paper_scissors', with_info=True, split='train')
tfds.show_examples(info_train,train)
Çocuklara öncelikle “Taş Kağıt Makas” veri setini yüklüyoruz. Load () fonksiyonu, eğitim ve test bölümlerini ayrı ayrı belirtir. Daha sonra .concatenate() yöntemini kullanarak eğitim ve test veri kümelerini birleştiriyoruz. Son olarak, birleştirilmiş veri kümesini .shuffle() yöntemini kullanarak 3000 arabellek boyutuyla karıştırıyoruz. Artık, eğitim ve test verilerini birleştiren tek bir veri kümesi değişkeniniz var.
dataset=datasets[0].concatenate(datasets[1])
dataset=dataset.shuffle(3000)Skip() ve take() yöntemlerini kullanarak tüm veri kümesini eğitim, test ve doğrulama veri kümelerine bölmeliyiz. Doğrulama için veri kümesinin ilk 600 örneğini kullanırız. Daha sonra ilk 600 görseli hariç tutarak geçici bir veri seti oluşturuyoruz. Bu geçici veri kümesinde test için ilk 400 fotoğrafı seçiyoruz. Yine eğitim veri setinde ilk 400 görseli atladıktan sonra geçici veri setinin tüm resimlerini alır.
Verilerin nasıl bölündüğünün bir özeti aşağıda verilmiştir:
- rsp_val: Doğrulama için 600 örnek.
- rsp_test: Test için 400 örnek.
- rsp_train: Eğitim için kalan örnekler.
rsp_val=dataset.take(600)
rsp_test_temp=dataset.skip(600)
rsp_test=rsp_test_temp.take(400)
rsp_train=rsp_test_temp.skip(400)Şimdi eğitim veri setinde kaç tane resim olduğunu görelim.
len(list(rsp_train)) #1892
#It has 1892 images in totalVeri ön işleme
Şimdi veri setimiz için bazı ön işlemeler yapalım. Bunun için bir fonksiyon ölçeği tanımlayacağız. Görüntüyü ve ona karşılık gelen etiketi argüman olarak ona ileteceğiz. Cast metodunu kullanarak görselin veri tipini float32'ye dönüştüreceğiz. Daha sonra bir sonraki adımda görüntünün piksel değerlerini normalleştirmemiz gerekiyor. Görüntünün piksel değerlerini [0, 1] aralığına ölçeklendirir. Görüntüyü yeniden boyutlandırma, tüm girdi görüntülerinin, genellikle derin öğrenme modellerini eğitirken gerekli olan tam boyutlara sahip olmasını sağlamak için yaygın bir ön işleme adımıdır. Böylece [224,224] boyutundaki görselleri döndüreceğiz. Etiketler için onehot kodlama yapacağız. Üç sınıfınız (Taş, Kağıt, Makas) varsa, etiket one-hot kodlanmış bir vektöre dönüştürülecektir. Bu vektör döndürülüyor.
Örneğin etiket 1 (Kağıt) ise [0, 1, 0]'a dönüştürülecektir. Burada her öğe bir sınıfa karşılık gelir. “1”, söz konusu sınıfa (Kağıt) karşılık gelen konuma yerleştirilir. Benzer şekilde, kaya etiketleri için vektör [1, 0, 0], makas için ise [0, 0, 1] olacaktır.
Kod
def scale(image, label): image = tf.cast(image, tf.float32) image /= 255.0 return tf.image.resize(image,[224,224]), tf.one_hot(label, 3)Şimdi eğitim, test ve doğrulama için toplu ve önceden işlenmiş veri kümeleri oluşturmak üzere bir işlev tanımlayın. Önceden tanımlanmış ölçek fonksiyonunu üç veri kümesinin tümüne uygulayın. Toplu iş boyutunu 64 olarak tanımlayın ve bunu bağımsız değişken olarak iletin. Bu, modellerin genellikle bireysel örneklerden ziyade veri grupları üzerinde eğitildiği derin öğrenmede yaygındır. Aşırı uyumdan kaçınmak için tren veri kümesini karıştırmamız gerekiyor. Son olarak, ölçeklendirilmiş üç veri kümesinin tümünü döndürün.
def get_dataset(batch_size=64): train_dataset_scaled = rsp_train.map(scale).shuffle(1900).batch(batch_size) test_dataset_scaled = rsp_test.map(scale).batch(batch_size) val_dataset_scaled = rsp_val.map(scale).batch(batch_size) return train_dataset_scaled, test_dataset_scaled, val_dataset_scaledget_dataset işlevini kullanarak üç veri kümesini ayrı ayrı yükleyin. Ardından treni ve doğrulama veri kümelerini önbelleğe alın. Önbelleğe alma, özellikle veri kümelerini depolamak için yeterli belleğe sahip olduğunuzda, veri yükleme performansını artırmak için değerli bir tekniktir. Önbelleğe alma, verilerin belleğe yüklenmesi ve eğitim ve doğrulama adımları sırasında daha hızlı erişim için orada tutulması anlamına gelir. Bu, özellikle eğitim süreciniz birden fazla dönemi içeriyorsa, aynı verilerin depolama alanından tekrar tekrar yüklenmesini önleyeceği için eğitimi hızlandırabilir.
train_dataset, test_dataset, val_dataset = get_dataset()
train_dataset.cache()
val_dataset.cache()Önceden Eğitilmiş Model Yükleniyor
Tensorflow Hub'ı kullanarak önceden eğitilmiş bir MobileNet V2 özellik çıkarıcı yükleyin. Ve bunu bir katman olarak yapılandırın Keras modeli. Bu MobileNet modeli büyük bir veri kümesi üzerinde eğitilmiştir ve görüntülerden özellikler çıkarmak için kullanılabilir. Şimdi MobileNet V2 özellik çıkarıcıyı kullanarak bir keras katmanı oluşturun. Burada giriş_şeklini (224, 224, 3) olarak belirtin. Bu, modelin 224×224 piksel boyutlarında ve üç renk kanalına (RGB) sahip giriş görüntüleri beklediğini gösteriyor. Bu katmanın eğitilebilir özelliğini Yanlış olarak ayarlayın. Bunu yapmanız, eğitim süreciniz sırasında önceden eğitilmiş MobileNet V2 modeline ince ayar yapmak istemediğinizi gösterir. Ancak bunun üzerine özel katmanlarınızı ekleyebilirsiniz.
feature_extractor = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/4"
feature_extractor_layer = hub.KerasLayer(feature_extractor, input_shape=(224,224,3))
feature_extractor_layer.trainable = FalseYapı Modeli
MobileNet V2 özellik çıkarıcı katmanına katmanlar ekleyerek TensorFlow Keras Sequential modelini oluşturmanın zamanı geldi. feature_extractor_layer'a bir bırakma katmanı ekleyeceğiz. Burada bırakma oranını 0.5 olarak belirleyeceğiz. Bu düzenleme yöntemi, aşırı uyumu önlemek için yaptığımız şeydir. Eğitim sırasında bırakma oranı 0.5 olarak ayarlanırsa model birimlerin ortalama %50'sini düşürecektir. Daha sonra üç çıkış birimine sahip yoğun bir katman ekliyoruz ve bu adımda 'softmax' aktivasyon fonksiyonunu kullanıyoruz. 'Softmax' çok sınıflı sınıflandırma problemlerini çözmek için yaygın olarak kullanılan bir aktivasyon fonksiyonudur. Her giriş görüntüsünün sınıflarına (Taş, Kağıt, Makas) göre olasılık dağılımını hesaplar. Daha sonra modelin özetini yazdırın.
model = tf.keras.Sequential([ feature_extractor_layer, tf.keras.layers.Dropout(0.5), tf.keras.layers.Dense(3,activation='softmax')
]) model.summary()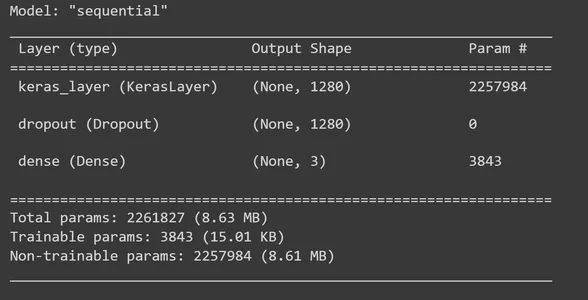
Modelimizi derlemenin zamanı geldi. Bunun için Adam optimizer ve C.ategoricalCrossentropy kayıp fonksiyonunu kullanıyoruz. from_logits=True bağımsız değişkeni, modelinizin çıktısının olasılık dağılımları yerine ham logitler (normalleştirilmemiş puanlar) ürettiğini gösterir. Eğitim sırasında izleme yapmak için doğruluk ölçümlerini kullanırız.
model.compile( optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True), metrics=['acc'])Geri arama adı verilen işlevler, her partinin veya çağın sonu da dahil olmak üzere, eğitimin farklı aşamalarında yürütülebilir. Bu bağlamda, eğitim sırasında parti düzeyinde kayıp ve doğruluk değerlerinin toplanması ve kaydedilmesi amacıyla TensorFlow Keras'ta özel bir geri arama tanımlıyoruz.
class CollectBatchStats(tf.keras.callbacks.Callback): def __init__(self): self.batch_losses = [] self.batch_acc = [] def on_train_batch_end(self, batch, logs=None): self.batch_losses.append(logs['loss']) self.batch_acc.append(logs['acc']) self.model.reset_metrics()Şimdi oluşturulan sınıfın bir nesnesini oluşturun. Ardından modeli fit_generator yöntemini kullanarak eğitin. Bunu yapmak için gerekli parametreleri sağlamamız gerekiyor. Eğitilmesi gereken dönem sayısını, doğrulama veri kümesini ve geri aramaları ayarlayan bir eğitim veri kümesine ihtiyacımız var.
batch_stats_callback = CollectBatchStats() history = model.fit_generator(train_dataset, epochs=5, validation_data=val_dataset, callbacks = [batch_stats_callback])Visualizations
Matplotlib'i kullanarak, CollectBatchStats geri çağrısı tarafından toplanan verileri kullanarak eğitim adımlarındaki eğitim kaybını çizin. Eğitim ilerledikçe kaybın nasıl optimize edildiğini sahada gözlemleyebiliyoruz.
plt.figure()
plt.ylabel("Loss")
plt.xlabel("Training Steps")
plt.ylim([0,2])
plt.plot(batch_stats_callback.batch_losses)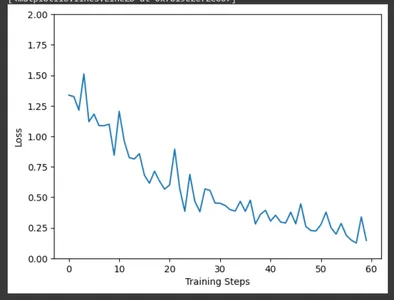
Benzer şekilde, eğitim adımlarına göre doğruluk grafiğini çizin. Burada da eğitim ilerledikçe doğruluk oranının arttığını gözlemleyebiliyoruz.
plt.figure()
plt.ylabel("Accuracy")
plt.xlabel("Training Steps")
plt.ylim([0,1])
plt.plot(batch_stats_callback.batch_acc)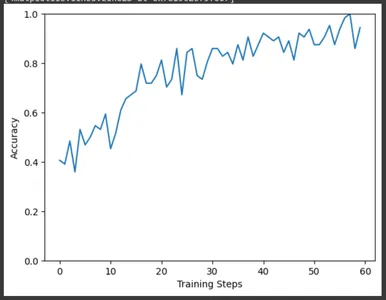
Değerlendirme ve Sonuçlar
Modelimizi bir test veri seti kullanarak değerlendirmenin zamanı geldi. Sonuç değişkeni, test kaybı ve model derlemesi sırasında tanımladığınız diğer ölçümler de dahil olmak üzere değerlendirme sonuçlarını içerecektir. Test kaybını ve test doğruluğunu sonuç dizisinden çıkarın ve yazdırın. Modelimiz için 0.14 kayıp ve %96 civarında doğruluk elde edeceğiz.
result=model.evaluate(test_dataset)
test_loss = result[0] # Test loss
test_accuracy = result[1] # Test accuracy
print(f"Test Loss: {test_loss}")
print(f"Test Accuracy: {test_accuracy}") #Test Loss: 0.14874716103076935
#Test Accuracy: 0.9674999713897705
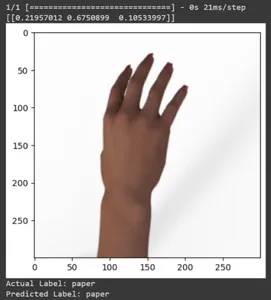
Bazı test görüntüleri için tahmine bakalım. Bu döngü, rsp_test veri kümesindeki ilk on örnek boyunca yinelenir. Görüntüyü ve etiketi ön işlemek için ölçek işlevini uygulayın. Markanın görselinin ölçeklendirilmesini ve one-hot kodlamasını gerçekleştiriyoruz. Gerçek etiketi (tek sıcak kodlanmış formattan dönüştürülmüş) ve tahmin edilen etiketi (tahminlerde en yüksek olasılığa sahip sınıfa göre) yazdıracaktır.
for test_sample in rsp_test.take(10): image, label = test_sample[0], test_sample[1] image_scaled, label_arr= scale(test_sample[0], test_sample[1]) image_scaled = np.expand_dims(image_scaled, axis=0) img = tf.keras.preprocessing.image.img_to_array(image) pred=model.predict(image_scaled) print(pred) plt.figure() plt.imshow(image) plt.show() print("Actual Label: %s" % info.features["label"].names[label.numpy()]) print("Predicted Label: %s" % info.features["label"].names[np.argmax(pred)])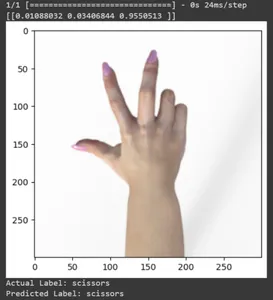
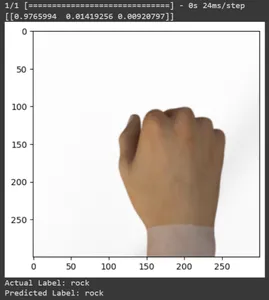
Tüm test görüntülerinin tahminlerini yazdıralım. Eğitilmiş TensorFlow Keras modelinizi kullanarak test veri kümesinin tamamı için tahminler üretecek ve ardından her tahmin için en yüksek olasılığa sahip sınıf etiketlerini (sınıf endeksleri) çıkaracaktır.
np.argmax(model.predict(test_dataset),axis=1)Modelin tahminleri için karışıklık matrisini yazdırın. Karışıklık matrisi, modelin tahminlerinin etiketlerle nasıl örtüştüğünün ayrıntılı bir dökümünü sağlar. Bir sınıflandırma modelinin performansını değerlendirmek için değerli bir araçtır. Her sınıfa gerçek pozitifler, gerçek negatifler ve yanlış pozitifler verir.
for f0,f1 in rsp_test.map(scale).batch(400): y=np.argmax(f1, axis=1) y_pred=np.argmax(model.predict(f0),axis=1) print(tf.math.confusion_matrix(labels=y, predictions=y_pred, num_classes=3)) #Output tf.Tensor(
[[142 3 0] [ 1 131 1] [ 0 1 121]], shape=(3, 3), dtype=int32) Eğitilen Modeli Kaydetme ve Yükleme
Eğitilen modeli kaydedin. Böylece modeli kullanmanız gerektiğinde her şeyi sıfırdan öğretmek zorunda kalmazsınız. Modeli yüklemeniz ve tahmin için kullanmanız gerekir.
model.save('./path/', save_format='tf')Modeli yükleyerek kontrol edelim.
loaded_model = tf.keras.models.load_model('path')Benzer şekilde, daha önce yaptığımız gibi, test veri setindeki bazı örnek görsellerle modeli test edelim.
for test_sample in rsp_test.take(10): image, label = test_sample[0], test_sample[1] image_scaled, label_arr= scale(test_sample[0], test_sample[1]) image_scaled = np.expand_dims(image_scaled, axis=0) img = tf.keras.preprocessing.image.img_to_array(image) pred=loaded_model.predict(image_scaled) print(pred) plt.figure() plt.imshow(image) plt.show() print("Actual Label: %s" % info.features["label"].names[label.numpy()]) print("Predicted Label: %s" % info.features["label"].names[np.argmax(pred)])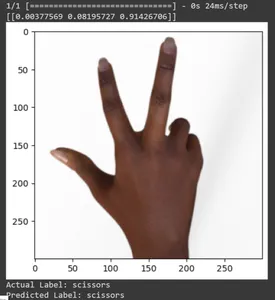
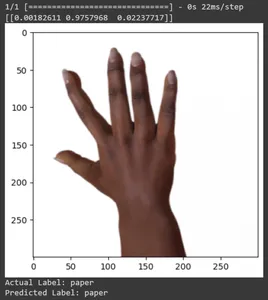
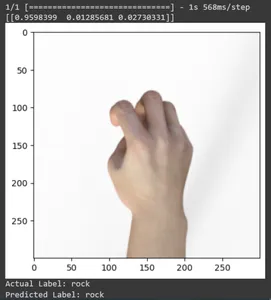
Sonuç
Bu yazıda Taş-Kağıt-Makas sınıflandırma görevi için transfer öğrenmeyi uyguladık. Bu görev için önceden eğitilmiş bir Mobilenet V2 modelini kullandık. Modelimiz %96 civarında bir doğrulukla başarılı bir şekilde çalışmaktadır. Tahmin görsellerinde modelimizin ne kadar iyi tahmin yaptığını görebiliyoruz. Son üç çekim, el pozu kusurlu olsa bile ne kadar mükemmel olduğunu gösteriyor. "Makas"ı temsil etmek için iki parmak konfigürasyonu kullanmak yerine üç parmağınızı açın. “Rock” için tamamen sıkılmış bir yumruk oluşturmayın. Ancak yine de modelimiz karşılık gelen sınıfı anlayabilir ve mükemmel bir şekilde tahmin edebilir.
Önemli Noktalar
- Transfer öğrenimi tamamen bilginin transfer edilmesiyle ilgilidir. Önceki görevde kazanılan bilgi yeni bir işin öğrenilmesinde kullanılır.
- Transfer öğrenimi, makine öğrenimi alanında devrim yaratma potansiyeline sahiptir. Hızlandırılmış öğrenme ve geliştirilmiş performans dahil olmak üzere çeşitli faydalar sağlar.
- Transfer öğrenimi, modellerin zaman içinde yeni bilgilerle, görevlerle veya ortamla başa çıkmak için değişebildiği sürekli öğrenmeyi teşvik eder.
- Makine öğrenmesi modellerinin etkinliğini ve verimliliğini artıran esnek ve etkili bir yöntemdir.
- Bu makalede transfer öğrenimi, faydaları ve uygulamaları hakkında her şeyi öğrendik. Ayrıca taş-kağıt-makas sınıflandırma görevini gerçekleştirmek için yeni bir veri kümesi üzerinde önceden eğitilmiş bir model kullanarak uyguladık.
Sıkça Sorulan Sorular (SSS)
A. Transfer Öğrenme, daha önce keşfedilmiş ilgili bir dersten bilgi aktarımı yoluyla yeni bir görevde öğrenmenin iyileştirilmesidir. Bu teknik, algoritmaların önceden eğitilmiş modelleri kullanarak yeni işleri hatırlamasını sağlar.
C. Taş-Kağıt-Makas veri kümesini kendi veri kümenizle değiştirerek bu projeyi diğer görüntü sınıflandırma görevlerine uyarlayabilirsiniz. Ayrıca modelde yeni işin gereksinimlerine göre ince ayar yapmanız gerekir.
A. MobileNet V2, TensorFlow Hub'da bulunan, önceden eğitilmiş bir özellik çıkarıcı modelidir. Transfer öğrenme senaryolarında uygulayıcılar genellikle MobileNetV2'yi bir özellik çıkarıcı olarak kullanır. Üstüne göreve özgü katmanlar ekleyerek, önceden eğitilmiş MobileNetV2 modeline belirli bir görev için ince ayar yaparlar. Yaklaşımı, çeşitli bilgisayarla görme görevlerinde hızlı ve etkili eğitime olanak tanıyor.
C. TensorFlow, Google tarafından geliştirilen açık kaynaklı bir makine öğrenimi çerçevesidir. Makine öğrenimi modellerini ve yoğun öğrenme modellerini oluşturmak ve eğitmek için yaygın olarak kullanılır.
C. İnce ayar, önceden eğitilmiş bir modeli aldığınız ve onu daha düşük bir öğrenme oranıyla özel göreviniz için daha ileri düzeyde eğittiğiniz, paylaşılan bir transfer öğrenme tekniğidir. Bu, modelin bilgisini hedef görevin nüanslarına uyarlamasına olanak tanır.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/10/transfer-learning-a-rock-paper-scissors-case-study/

