Bu makale, Veri Bilimi Blogathon.

Giriş
Bu, karayolu kazalarının ciddiyetini üç kategoriye ayırmaya yönelik çok sınıflı bir sınıflandırma projesidir. Bu proje gerçek dünya verilerine dayanıyor ve veri seti de oldukça dengesiz. Hedef değişkende üç tip yaralanma vardır: hafif, ciddi ve ölümcül.
Yol kazaları dünya çapında doğal olmayan ölümlerin başlıca nedenidir. Tüm hükümetler, ölümleri azaltmak amacıyla yolda araç kullanırken uyulması gereken ve uyulması gereken düzenlemeler konusunda farkındalığı artırmak için çok çalışıyor. Bu nedenle, bu tür kazaların ciddiyetini tahmin edecek ve ölümlerin azaltılmasına yardımcı olacak bir mekanizmaya ihtiyaç vardır.
Bu yazımızda, soruşturma kurumu tarafından gerekli önlemlerin alınması amacıyla trafik kazalarının ciddiyetini tahmin etmeye yönelik makine öğrenimi çözümü geliştirdiğimiz uçtan uca proje üzerinde çalışacağız. O halde proje tanımı ve sorun bildirimi ile başlayalım.
Makine Öğrenimi Çözümünü Anlamak
Bu veri seti, yüksek lisans öğrencilerinin araştırma çalışmaları için Etiyopya'nın Addis Ababa Alt Şehri polis departmanlarından toplandı. Veri seti, 2017-20 yıllarına ait karayolu trafik kazalarına ilişkin manuel dokümanlardan hazırlanmıştır. Veri kodlama sırasında tüm hassas bilgiler hariç tutulmuştur ve son olarak 32 özelliğe ve 12316 kaza satırına sahiptir. Daha sonra farklı sınıflandırma algoritmaları kullanılarak analiz edilerek kazanın ana nedenlerinin belirlenmesi için ön işleme tabi tutulur. Makine öğrenimi modelleri değerlendirilecek ve daha sonra son kullanıcılar için kullanılabilir hale getirilmek üzere bulut tabanlı bir platformda devreye alınacak.
Sorun bildirimi
Hedef özellik, çok sınıflı bir değişken olan “Accident_severity”dir. Görev, her bir veri bilimi süreci ve görevi üzerinden geçerek bu değişkeni diğer 31 özelliğe göre adım adım sınıflandırmaktır. Değerlendirme ölçütümüz “F1 puanınız” olacaktır.
Önkoşullar
Bu bir orta düzey proje bir ile dengesiz çok sınıflı sınıflandırma problemi. Bu projenin bazı önkoşulları.
- Sınıflandırma makine öğrenimi algoritmalarının anlaşılması gereklidir.
- Python programlama dili ve Pandas, NumPy, Matplotlib ve Scikit-Learn gibi python çerçevelerinin yanı sıra akıcı kütüphanenin temelleri hakkında bilgi gereklidir.
Veri kümesi açıklaması
- Saat — kaza saati (24 saat formatında)
- Day_of_week — Bir kazanın meydana geldiği gün
- Age_band_of_driver —Sürücünün yaş grubu
- Sex_of_driver — Sürücünün cinsiyeti
- Educational_level — Sürücünün en yüksek eğitim seviyesi
- Vehical_driver_relation — Sürücünün araçla ilişkisi nedir
- Driving_experience — Sürücünün kaç yıllık sürüş deneyimi var
- Type_of_vehicle — Aracın türü nedir
- Owner_of_vehicle — Aracın sahibi kim
- Service_year_of_vehicle — Aracın son servis yılı
- Defect_of_vehicle — Araçta herhangi bir kusur var mı yok mu?
- Area_accident_occured — Kaza alanının konumu
- Şeritler_veya_Orta refüjler — Kaza mahallinde herhangi bir şerit veya orta refüj var mı?
- Road_allignment — Arazi arazisiyle yol hizalaması
- Types_of_junction — Kaza mahallindeki kavşak türü
- Road_surface_type — Yüzey türü bir yol
- Road_surface_conditions — Yol yüzeyinin durumu neydi?
- Light_conditions — Sahadaki aydınlatma koşulları
- Weather_conditions — Kaza mahallindeki hava durumu
- Type_of_collision — Çarpışmanın türü nedir
- Number_of_vehicles_involved — Kazaya karışan toplam araç sayısı
- Number_of_casualties — Kazada ölenlerin toplam sayısı
- Araç_hareket — Kaza meydana gelmeden önce aracın nasıl hareket ettiği
- Casualty_class — Kaza sırasında ölen kişi
- Sex_of_casualty — Öldürülen kişinin cinsiyeti nedir?
- Age_band_of_casualty — Yaralının yaş grubu
- Casualty_severtiy — Yaralının ne kadar ağır yaralandığı
- Work_of_casualty — Yaralının yaptığı iş neydi?
- Fitness_of_casualty — Yaralının kondisyon seviyesi
- Pedestrain_movement — Yolda herhangi bir yaya hareketi var mıydı?
- Kaza_nedeni — Kazanın sebebi neydi?
- Accident_severity — Kaza ne kadar şiddetliydi? (Hedef değişken)
Şu ana kadar problem ifadesini ve veri açıklamalarını anladık. Şimdi, tahmine dayalı analitik sorunlarını çözmek ve makine öğrenimi çözümlerini akıcı bulutta dağıtmak için uçtan uca kod uygulamalarına bakacağız.
Makine Öğrenimi Çözümünde Veri Kümelerini Analiz Etme
Artık sorun bildirimine ve veri açıklamasına baktığımıza göre, veri kümesini geliştirme ortamımıza yüklemeye başlayacağız ve veri hazırlama ve modelleme aşamaları için kritik bilgiler bulmak üzere verileri analiz etmeye başlayacağız.
Veri kümesinin kaynağı — Buraya Tıkla
Kaggle veri kümesi bağlantısı — Buraya Tıkla
- Veri kümesini içe aktar
Bu proje üzerinde çalışmak için Kaggle ortamını kullandım. Adım adım kodu izleyerek bu proje üzerindeki çalışmayı tamamlamak için bu veri kümesini yerel ortamınızda veya tercih ettiğiniz herhangi bir bulut tabanlı IDE'de kullanabilirsiniz.
# pandaları içe aktarıyorum
veri kümesini yüklemek için pandas read_csv işlevini kullanarak pandaları pd # olarak içe aktarın
df = pd.read_csv("/kaggle/input/yol-trafik-şiddet-sınıflandırması/RTA Veri Kümesi.csv")
df.head()
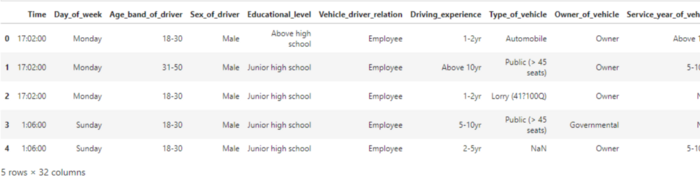
Not: Veri kümesinin büyük olması nedeniyle yukarıdaki kodun çıktısı ekran görüntüsünde tam olarak görülemiyor.
2. Veri kümesinin meta verileri
# veri kümesi bilgilerini yazdır df.info()
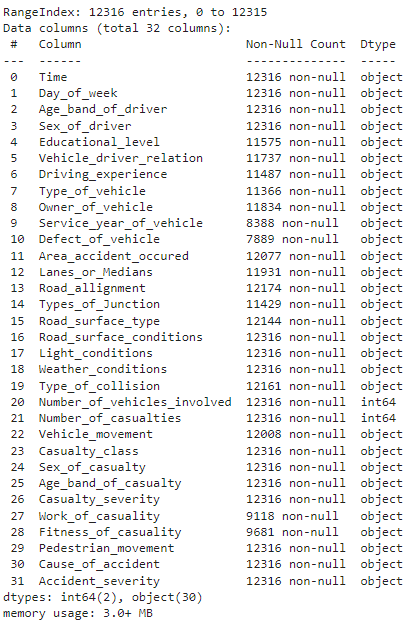
Yukarıdaki yöntem, boş olmayan değerler, her sütunun veri türleri, veri kümesinde bulunan satır ve sütun sayısı ve veri kümesinin bellek kullanımı gibi meta veri bilgilerini gösterir.
3. Her sütunda bulunan eksik değerlerin sayısını bulun
# Her sütunda bulunan eksik değerlerin sayısını bulun df.isnull().sum()
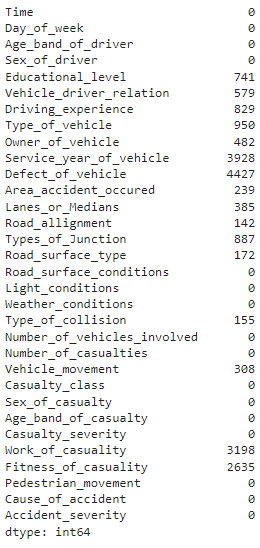
yukarıdaki kodun çıktısı
Yöntem bize her sütunda kaç tane eksik değer olduğunu gösterir. "Defect_of_Vehicle", 4427 örnekten 12316'si ile en yüksek sayıda eksik değeri gösterir.
4. Hedef değişken sınıflarının dağıtımı ve görselleştirilmesi
# hedef değişken sınıf sayıları ve çubuk grafiği print(df['Kaza_şiddeti'].value_counts()) df['Accident_severity'].value_counts().plot(tür='bar')

yukarıdaki kodun çıktısı
Daha önce problem tanımında gördüğümüz gibi, hedef değişken sınıfları oldukça dengesizdir ve doğru ve genelleştirilmiş makine öğrenimi modelleri geliştirmek için bu sorunu veri hazırlama aşamasında çözeceğiz.
5. Veri kümesinin keşfedici veri analizi
Sürücülerin eğitim düzeylerini öğrenelim
# Araç sürücülerinin eğitim düzeyleri df['Eğitim_düzeyi'].value_counts().plot(tür='bar')
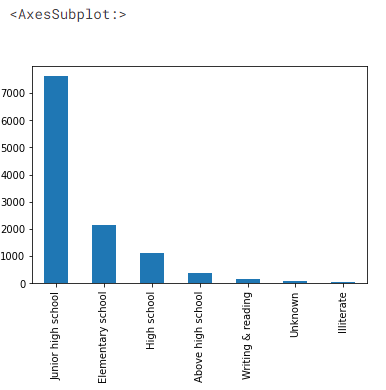
veri kümesinin çıktısı
7000'den fazla sürücünün ortaokula kadar eğitim aldığını ve sürücülerin yalnızca küçük bir kısmının lise üstü eğitim aldığını görüyoruz.
- 'Dabl' kütüphanesini kullanarak otomatik veri görselleştirme
# Dabl kütüphanesini kullanarak veri setini görselleştirme pip kurulum dabl
ithalat dabl
dabl.plot(df, target_col='Kaza_şiddeti')

yukarıdaki kodun çıktısı
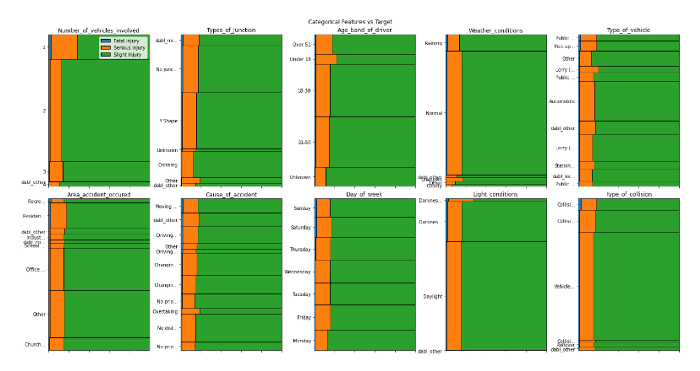
yukarıdaki kodun çıktısı
Yalnızca bir satır kod kullanarak giriş özellikleri ile hedef değişken arasındaki ilişkileri görselleştirebiliriz. Şu ana kadar yaptığımız analizlerden aşağıdaki öngörüleri elde edebiliriz:
- Yaralı sayısı ne kadar fazla olursa, kaza yerinde ölümcül yaralanma olasılığı da o kadar yüksek olur
- Ne kadar çok araç karışırsa ciddi yaralanma olasılığı da o kadar yüksek olur
- Light_conditions'ın karanlık olması daha ciddi yaralanmalara neden olabilir
- Veriler son derece dengesiz
- Gibi özellikler
area_accident_occured,Cause_of_accident,Day_of_week,type_of_junctionölümcül yaralanmalara neden olan temel özellikler gibi görünüyor - Görünüşe göre yol yüzeyi ve yol koşulları ciddi veya ölümcül kazaları etkilemiyor
(Not: Bu yazının sonuna bu projenin github repository linkini ekleyeceğim, böylece kod hakkında detaylı bilgiye ulaşabilirsiniz)
- 'Yol yüzeyi türü' sütunu ile hedef 'kazanın ciddiyeti' arasındaki ilişki
# road_surface_type ve kaza ciddiyeti özelliğinin çubuk grafiğini çizin
plt.figure(figsize=(6,5))
sns.countplot(x='Road_surface_type', hue='Accident_severity', data=df)
plt.xlabel('Rode surafce türü')
plt.xticks(döndürme=60)
plt.show
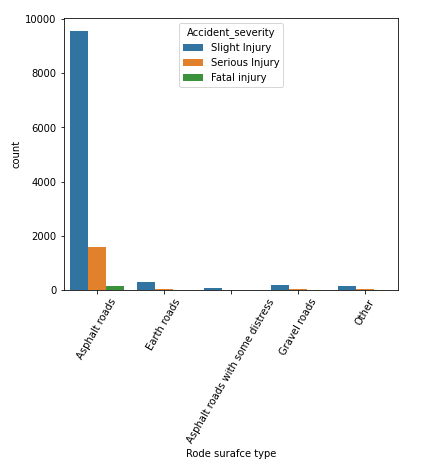
yukarıdaki kodun çıktısı
Veri setimizde en çok kazanın “asfalt yollarda” meydana geldiğini, bunu “toprak yollarda” takip ettiğini öğrenebiliyoruz. Burada ölümcül yaralanmaların çoğunun asfalt yollarda meydana geldiğini söyleyebiliriz, dolayısıyla hedef sınıfı tahmin etmede önemli bir değişken olmayabilir.
Şimdi yukarıdaki bulgulara dayanarak ham verileri modelleme ve değerlendirme amacıyla ön işleme tabi tutacağız.
Veri Hazırlama
“Time” sütununun veri tipini “datetime” veri tipine değiştirerek veri setinin ön işlemesine başlayacağız. Daha sonra verileri modellemeye hazırlamak için günün saati özelliğini çıkaracağız.
# nesne türü sütununu tarihsaat veri türü sütununa dönüştürün
df['Time'] = pd.to_datetime(df['Time']) # Zaman sütunundan 'Günün_Saati' özelliği çıkarılıyor
yeni_df = df.copy()
new_df['Günün_Saati'] = new_df['Saat'].dt.saat
n_df = new_df.drop('Zaman', eksen=1)
n_df.head()
yukarıdaki kodun çıktısı
Eksik değer muamelesi
Bu zamana kadar, önceki aşamadan elde edilen bilgilere dayanarak daha ileri işlemler için seçilecek bir özellik alt kümesine sahip olacağız. Bir özellik alt kümesi seçeceğiz ve ardından eksik değerleri Pandas kütüphanesinin “fillna()” yöntemini kullanarak işleyeceğiz.
Bizim bağlamımızda, eksik değerlerin araştırma sırasında bulunamamış olabileceğini varsayarak, değer olarak "bilinmeyen"i doldurarak eksik değerleri ele alacağız.
# NaN eksik çünkü hizmet bilgisi mevcut olmayabilir, 'Bilinmeyenler' olarak dolduracağız
feature_df['Service_year_of_vehicle'] = feature_df['Service_year_of_vehicle'].fillna('Unknown')
feature_df['Kavşak Tipleri'] = feature_df['Kavşak Tipleri'].fillna('Bilinmeyen')
feature_df['Area_accident_occured'] = feature_df['Area_accident_occured'].fillna('Bilinmeyen')
feature_df['Driving_experience'] = feature_df['Driving_experience'].fillna('unknown')
feature_df['Araç_Tipi'] = feature_df['Araç_Tipi'].fillna('Diğer')
feature_df['Vehicle_driver_relation'] = feature_df['Vehicle_driver_relation'].fillna('Bilinmeyen')
feature_df['Eğitim_seviyesi'] = feature_df['Eğitim_seviyesi'].fillna('Bilinmeyen')
feature_df['Çarpışma Türü'] = feature_df['Çarpışma Türü'].fillna('Bilinmeyen') # özellik bilgisi
feature_df.info()
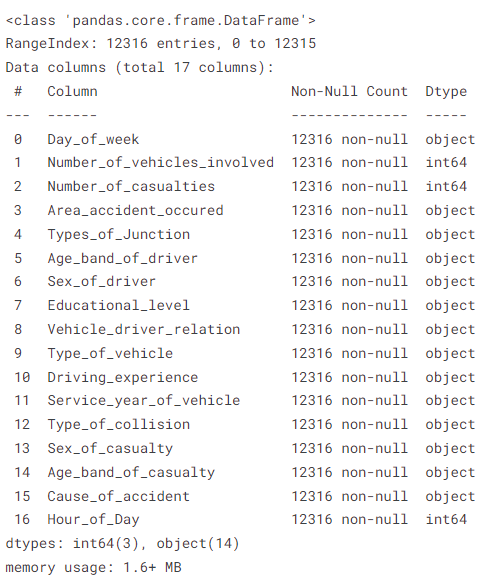
veri çerçevesinin çıktısı
Görebildiğimiz gibi, özellik setimiz artık önceki ham veri setine kıyasla sıfır boş değere sahip. Şimdi diğer veri ön işleme adımlarına geçelim.
'get_dummies()' yöntemini kullanarak One-Hot kodlaması
Pandaların 'get_dummies()' özelliği kategorik sütunları sayısal özelliklere dönüştürmek için kullanılabilir. aşağıdaki kod parçasını görelim:
# Tek bir sıcak kodlama özelliği kullanarak kodlamak için kategorik özellikler = ['Haftanın_Günü','İlgili_araç_sayısı','Yaralı_sayısı','Kaza_olan_oluşan', 'Kavşak Türleri','Sürücü Yaş Bandı','Sürücünün Cinsiyeti','Eğitim_düzeyi', 'Araç_sürücü_ilişkisi', 'Araç_tipi ','Sürüş_deneyimi','Aracın Hizmet Yılı','Çarpışma Türü', 'Yaralının Cinsiyeti','Yaralının Yaş Grubu','Kazanın_Nedeni','Günün_Saati'] # giriş özelliklerinin ayarlanması X ve hedef y X = özellik_df[özellikler] # burada özellikler arasından seçilir 'nesne' veri türü y = n_df['Accident_severity'] # çalışırken kodlama için pandas get_dummies yöntemini kullanacağız encoded_df = pd.get_dummies(X, drop_first=Doğru) encoded_df.shape -----------------------------------[Çıktı]----------- -------------------------- (12316, 106)
Kodlamanın bir sonucu olarak, kodlanmış veri çerçevesinde artık 106 sütunumuz var ve bunları modelleme amacıyla yalnızca önemli özellikleri tutmak için daha fazla ön işleme tabi tutacağız.
'LabelEncoder()' yöntemini kullanarak kodlamayı hedefleyin
# labelencoder'ı sklearn.preprocessing'den içe aktar
sklearn.preprocessing'den LabelEncoder'ı içe aktarın # labelencoder nesnesi oluşturun
lb = Etiket Kodlayıcı()
lb.fit(y)
y_encoded = lb.transform(y)
print("Kodlanmış etiketler:",lb.classes_)
y_en = pd.Series(y_encoded) -----------------------------------[Çıktı]---- ------------------------------
Kodlanmış etiketler: ['Ölümcül yaralanma' 'Ciddi Yaralanma' 'Hafif Yaralanma']
Artık, "Kbest" özelliklerini daha fazla seçmek ve dengesiz bir veri kümesini ele almak için kodlanmış bir veri çerçevesi nesnesi olarak "encoded_df"ye ve kodlanmış bir hedef sütun olarak "y_en"e sahibiz.
'Chi2' İstatistiğini kullanarak özellik seçimi
# kategorik çıktı, kategorik giriş için chi2 kullanan özellik seçme yöntemi sklearn.feature_selection'dan SelectKBest'i içe aktar, chi2 fs = KBest'i seç(chi2, k=50) X_new = fs.fit_transform(encoded_df, y_en) # Seçilen özellikleri al cols = fs.get_feature_names_out() # seçilen özellikleri veri çerçevesine dönüştürür fs_df = pd.DataFrame(X_new, sütunlar=sütunlar)
Kodlanmış veri çerçevesinden 50 özellik arasından en iyi 106 özelliği seçiyoruz ve bunları “fs_df” adı verilen yeni bir veri çerçevesi nesnesinde saklıyoruz. Hedef özelliğin kategorik bir değişken olması durumunda “Chi2” istatistiği, hedef özelliğin sürekli bir değişken olması durumunda ise “Pearson katsayısı” kullanılır. Şimdi kategorik özellikleri dengelemek için veri kümesini örnekleyelim.
'SMOTENC' tekniği kullanılarak dengesizlik verilerinin işlenmesi
Scikit-learn kütüphanesinin, adında bir uzantı kütüphanesi vardır. “Dengesiz-öğrenme” dengesiz verileri işlemek için çeşitli yöntemlere sahiptir. (Resmi belgeler — Buraya Tıkla).
Üst örnekleme ve azınlık sınıfı örnekleri için şunları kullanacağız: “Nominal ve Sürekli için Sentetik Azınlık Aşırı Örnekleme Tekniği” (SMOTENC) tekniklerini projemizde kullandık. Bu yöntem, veri kümesini doğru şekilde örneklemek amacıyla kategorik ve sürekli özellikler için tasarlanmıştır.
# SMOTENC nesnesini imblearn kütüphanesinden imblearn.over_sampling'den içe aktarma SMOTENC'i içe aktar # kategorik özellikler için SMOTENC tekniği için kategorik özellikler n_cat_index = np.array(range(3,50)) # SMOTENC sınıfıyla smote nesnesi oluşturma smote = SMOTENC(categorical_features=n_cat_index, random_state=42, n_jobs=True) X_n, y_n = smote.fit_resample(fs_df,y_en) # yeni örneklenmiş veri kümesinin şeklini yazdır X_n.shape, y_n.shape -----------------------------------[Çıktı]----- ----------------------------- ((31245, 50), (31245,)) # hedef sınıfların dağılımını yazdır print(y_n.value_counts()) -----------------------------------[Çıktı]---- ------------------------------ 2 10415 1 10415 0 10415 veri türü: int64
Şimdi görebileceğiniz gibi, toplam olarak örneklenmiş yeni bir veri kümemiz var. 31245 örnekler. Hedef sınıflarımızın her birinin 10415 örnekler ve veri kümesi artık modelleme görevleri için dengelenmiştir.
Makine Öğrenimi Modelleme
Şimdi rastgele orman makine öğrenimi algoritmasını kullanarak bir sınıflandırma makine öğrenimi modeli geliştirelim. Bir ML modeli geliştirmek ve bir sonraki adımda değerlendirmek için Scikit-Learn kütüphanesinin çeşitli sınıflarını içe aktaracağız.
# gerekli kütüphaneyi içe aktar sklearn.model_selection'dan train_test_split'i içe aktar sklearn.ensemble'dan RandomForestClassifier'ı içe aktarın sklearn.metrics'ten, kafa karışıklığı_matrix, sınıflandırma_raporu, f1_score'u içe aktarın # eğitim ve test bölümü ve hedef özellikleri tahmin etmek için temel model oluşturma X_trn, X_tst, y_trn, y_tst = train_test_split(X_n, y_n, test_size=0.2, random_state=42) # rastgele orman temel çizgisini kullanan modelleme rf = RandomForestClassifier(n_estimators=800, max_length=20, random_state=42) rf.fit(X_trn, y_trn) # test verilerine göre tahmin yapma tahminler = rf.predict(X_tst) # tren puanı rf.score(X_trn, y_trn) -----------------------------------[Çıktı]------------ ----------------------- 0.9416306609057449
Şimdi, n_estimators = 800 ve max_length = 20 olan bir rastgele orman modeli geliştirdik. Sonuçları doğrulamak ve yeni girdi verilerine dayanarak tahminler yapmak için bu modeli test verileri üzerinde değerlendireceğiz.
Sınıflandırma raporunu test veri kümesine yazdıralım.
# test veri kümesine ilişkin sınıflandırma raporu classif_re = sınıflandırma_raporu(y_tst, tahminler) print(classif_re) ------------------------[Çıktı]----------- -------------------------- hassas geri çağırma f1 puanı desteği 0 0.94 0.96 0.95 2085 1 0.84 0.83 0.84 2100 2 0.86 0.87 0.86 2064 doğruluk 0.88 6249 makro ortalama 0.88 0.88 0.88 6249 modelin ağırlıklı ortalama 0.88 0.88 0.88 6249 # f1_score'u f1score = f1_score(y_tst,tahminler, ortalama='ağırlıklı') print(f1score) ------------------------[Çıktı]---------- -------------------------- 0.8838187418909502
Modelin, eğitim veri setindeki %88'e kıyasla test verilerinde %94 doğruluk arşivlediğini görebiliriz. Modelimiz test veri kümesinde iyi performans gösteriyor gibi görünüyor ve son kullanıcılar için erişilebilir hale getirmek için modeli modern bulut üzerinde dağıtmaya hazırız.
Veri Kümesinin Streamlit Kullanılarak Dağıtılması
Artık verileri analiz ettiğimize ve test veri kümesinde f88_score'un %1'ini içeren bir makine öğrenimi modeli oluşturduğumuza göre, akıcı kitaplığı kullanarak bir web arayüzü geliştirmek için ML işlem hattına devam edeceğiz. Streamlit'i kullanarak makine öğrenimi destekli web uygulamaları oluşturmak son derece kolaydır çünkü herhangi bir ön uç teknoloji bilmenize gerek yoktur. Üstelik Streamlit, özel alt alan adlarıyla ücretsiz bulut dağıtımı sağlıyor ve bu da onu ML destekli uygulamaların dağıtımı için tercih edilen bir seçenek haline getiriyor.
Model nesnesini kaydederek ve giriş özelliklerini seçerek başlayalım. Web uygulamasından makine öğrenimi modelini çıkarmak için web uygulamaları oluşturmaya yönelik 10 özellik seçtik. Bunun dışında, kategorik girişleri ilgili kodlamalara dönüştürmek için sıralı kodlayıcı nesnesini de kaydedeceğiz.
# veri çerçevesinden 7 kategorik özellik seçme iş kütüphanesini içe aktar sklearn.preprocessing'den içe aktar OrdinalEncoder new_fea_df = feature_df[['Type_of_collision','Age_band_of_driver','Sex_of_driver', 'Educational_level','Service_year_of_vehicle','Day_of_week','Area_accident_occured']] oencoder2 = OrdinalEncoder() encoded_df3 = pd.DataFrame(oencoder2.fit_transform(new_fea_df)) encoded_df3.columns = new_fea_df.columns # çıkarım hattı için sıralı kodlayıcı nesnesini kaydedin joblib.dump(oencoder, "ordinal_encoder2.joblib")
Şimdi, çıkarım için son modeli eğitmek üzere yedi kategorik özelliği üç sayısal özellikle birleştireceğiz.
# model çıkarımı için eğitilecek son veri çerçevesi s_final_df = pd.concat([feature_df[['Number_of_vehicles_involved','Number_of_casualties','Hour_of_ay']],encoded_df3], axis=1) # hedef özellikleri tahmin etmek için eğitim ve test bölümü ve temel model oluşturma X_trn2, X_tst2, y_trn2, y_tst2 = train_test_split(s_final_df, y_en, test_size=0.2, random_state=42) # rastgele orman temel çizgisini kullanan modelleme rf = RandomForestClassifier(n_estimators=700, max_length=20, random_state=42) rf.fit(X_trn2, y_trn2) # model nesnesini kaydet joblib.dump(rf, "rta_model_deploy3.joblib", sıkıştırma=9)
Proje havuzumuza aşağıdaki dört dosyayı yükleyeceğiz:
- gereksinimler.txt
- uygulama.py
- ordinal_encoder2.joblib
- rta_model_deploy3.joblib
Tüm bağımlılıkları gereksinimler.txt dosyasına yükleyin
pandalar numpy streamlit scikit-learn joblib shap matplotlib ipython Yastık
Bir app.py dosyası oluşturun ve trafik kazalarının ciddiyetini tahmin etmek amacıyla son kullanıcıdan girdi almak için form tabanlı kullanıcı arayüzüne sahip bir çıkarım hattı yazın.
# tüm uygulama bağımlılıklarını içe aktar
pandaları pd olarak içe aktar
numpy'yi np olarak içe aktar
sklearn'i içe aktar
Streamlit'i st olarak içe aktar
iş kütüphanesini içe aktar
ithalat şekli
matplotlib'i içe aktar
IPython'dan get_ipython'u içe aktarın
PIL içe aktarma Görüntüsünden kodlayıcıyı ve model nesnesini yükleyin
model = joblib.load("rta_model_deploy3.joblib")
encoder = joblib.load("ordinal_encoder2.joblib") st.set_option('deprecation.showPyplotGlobalUse', False) # 1: ciddi yaralanma, 2: Hafif yaralanma, 0: Ölümcül Yaralanma st.set_page_config(page_title=Kaza Önem Derecesi Tahmin Uygulaması ", page_icon = "🚧", düzen = "geniş") #açılır menü için seçenek listesi oluşturma
options_day = ['Pazar', "Pazartesi", "Salı", "Çarşamba", "Perşembe", "Cuma", "Cumartesi"]
options_age = ['18-30', '31-50', '51 Yaş Üstü', 'Bilinmiyor', '18 Yaş Altı'] # dahil olan araç sayısı: 1 ile 7 arası
# ölü sayısı: 1 ila 8 arası
Günün # saati: 0 ile 23 arası options_types_collision = ['Araçla araç çarpışması','Yol kenarındaki nesnelerle çarpışma', 'Yayalarla çarpışma','Devrilme','Hayvanlarla çarpışma', 'Bilinmiyor','Çarpışma yol kenarına park edilmiş araçlarla','Araçlardan düşme', 'Diğer','Trenli'] options_sex = ['Erkek','Kadın','Bilinmeyen'] options_education_level = ['Ortaokul','İlkokul' ,'Lise', 'Bilinmiyor','Lise üstü','Yazma ve okuma','Okur-yazar değil'] options_services_year = ['Bilinmiyor','2-5 yaş','10 yaş üstü','5-10 yaş', '1-2 yıl','1 yıldan az'] options_acc_area = ['Diğer', 'Ofis alanları', 'Yerleşim alanları', ' Kilise alanları', ' Sanayi alanları', 'Okul alanları', ' Eğlence alanları', ' Dış Mekan kırsal alanlar', 'Hastane alanları', 'Pazar alanları', 'Kırsal köy alanları', 'Bilinmiyor', 'Kırsal köy alanlarıOfis alanları', 'Rekreasyon alanları'] # özellikler listesi
özellikler = ['İlgili araç_sayısı','Yaralı_sayısı','Günün_Saati','Çarpışma_Tipi','Sürücünün_yaşı_bandı','Sürücünün Cinsiyeti', 'Eğitim_düzeyi','Araç_Hizmet_yılı','Haftanın_Günü','Kaza_olan_alanı']
Kullanıcıdan alınacak tüm girişleri tanımladıktan sonra, ön uçta oluşturulacak kullanıcı arayüzünü geliştirmek için 'main()' işlevini tanımlayabiliriz.
# HTML sözdizimini kullanarak web uygulamasına bir başlık verin
st.markdown("
Kaza Önem Derecesi Tahmin Uygulaması 🚧
", unsafe_allow_html=True) # form tabanlı yaklaşımla kullanıcıdan girdi almak için bir main() işlevi tanımlayın
def main(): with st.form("road_traffic_severity_form"): st.subheader("Lütfen aşağıdaki girişleri girin:") No_vehicles = st.slider("Katılan araç sayısı:",1,7, değer=0, format="%d") No_casualties = st.slider("Yaralı sayısı:",1,8, value=0, format="%d") Saat = st.slider("Günün saati:", 0 , 23, value=0, format="%d") çarpışma = st.selectbox("Çarpışma türü:",options=options_types_collision) Age_band = st.selectbox("Sürücü yaş grubu?:", options=options_age) Cinsiyet = st.selectbox("Sürücünün cinsiyeti:", options=options_sex) Eğitim = st.selectbox("Sürücünün eğitimi:",options=options_education_level) service_vehicle = st.selectbox("Aracın hizmet yılı:", options= options_services_year) Day_week = st.selectbox("Haftanın günü:", options=options_day) Accident_area = st.selectbox("Kaza alanı:", options=options_acc_area) submit = st.form_submit_button("Tahmin") # kullanarak kodlama sıralı kodlayıcı ve gönderilip gönderilmeyeceğini tahmin edin: input_array = np.array([collision, Age_band,Sex,Education,service_vehicle, Day_week,Accident_area], ndmin=2) encoded_arr = list(encoder.transform(input_array).ravel()) num_arr = [Araç Yok, Yaralı Yok, Saat] pred_arr = np.array(num_arr + encoded_arr).reshape(1,-1) # tüm girdi özelliklerinden hedefi tahmin et tahmin = model.predict(pred_arr) if tahmin == 0: st. write(f"Şiddet tahmini Ölümcül Yaralanmadır⚠") elif tahmin == 1: st.write(f"Şiddet tahmini ciddi yaralanmadır") else: st.write(f"Şiddet tahmini hafif yaralanmadır") st .subheader("Tahminleri anlamak için açıklanabilir yapay zeka (XAI)")
# Shap kütüphanesini kullanan açıklanabilir yapay zeka shap.initjs() shap_values = shap.TreeExplainer(model).shap_values(pred_arr) st.write(f"Tahmin için {tahmin}") shap.force_plot(shap.TreeExplainer(model).expected_value[ 0], shap_values[0], pred_arr, feature_names=features, matplotlib=True,show=False).savefig("pred_force_plot.jpg", bbox_inches='tight') img = Image.open("pred_force_plot.jpg") # tahminleri açıklamak için ön uçta shap grafiğini oluşturun st.image(img, caption='shap kullanarak model açıklaması') st.write("Geliştiren: Avi kumar Talaviya") st.markdown("""Bana ulaşın üzerinde: [Twitter](https://twitter.com/avikumart_) | [Linkedin](https://www.linkedin.com/in/avi-kumar-talaviya-739153147/) | [Kaggle](https:/ /www.kaggle.com/avikumart) """)
Son olarak, üzerinde çalıştığınız projeyi net bir şekilde sergilemek için ön tarafa proje açıklamasını ve sorun bildirimini yazın.
a,b,c = st.sütunlar([0.2,0.6,0.2])
b ile: st.image("vllkyt19n98psusds8.jpg", use_column_width=True) # proje ve kod dosyaları hakkında açıklama st.subheader("🧾Description:")
st.text("""Bu veri seti Addis Ababa İlçe Emniyet Müdürlüklerinden yüksek lisans araştırması için toplanmıştır. Veri seti 2017-20 yılı karayolu trafik kazalarına ilişkin manuel dokümanlardan hazırlanmıştır. Tüm hassas bilgiler veri kodlaması sırasında hariç tutulmuştur ve son olarak 32 özelliğe ve 12316 kaza örneğine sahiptir.
Daha sonra ön işleme tabi tutulur ve farklı makine öğrenimi sınıflandırma algoritmaları kullanılarak analiz edilerek kazanın ana nedenlerinin belirlenmesi sağlanır. """) st.markdown("Veri kümesinin kaynağı: [Buraya Tıklayın](https://www.narcis.nl/dataset/RecordID/oai%3Aeasy.dans.knaw.nl%3Aeasy-dataset%3A191591)" ) st.subheader("🧭 Sorun Açıklaması:")
st.text("""Hedef özellik, çok sınıflı bir değişken olan Accident_severity'dir. Görev, her günün görevini gözden geçirerek bu değişkeni diğer 31 özelliğe göre adım adım sınıflandırmaktır. Değerlendirme metriği, f1-score """) st.markdown("Lütfen projenin GitHub depo bağlantısını bulun: [Buraya Tıklayın](https://github.com/avikumart/Road-Traffic-Severity-Classification-Project)") # run ana işlev if __name__ == '__main__': main()
Bu kadar! Kolaylaştırılmış bir uygulamayı tek bir tıklamayla başlatmak için proje dosyalarını github deposuna göndermeniz ve basitleştirilmiş hesabınızda oturum açmanız yeterlidir!
Streamlit'te bir uygulamanın nasıl dağıtılacağı hakkında daha fazla bilgi için Analytics Vidhya 'da yayınlanan önceki makaleme göz atın. Buraya Tıkla
Proje deposuna erişebilirsiniz okuyun
Dağıtılan web uygulamasını görüntüleyebilirsiniz okuyun
Sonuç
Sonuç olarak, uçtan uca veri bilimi ve makine öğrenimi projesi, trafik kazalarında ölümlerin önlenmesine yardımcı olmak için veri analizi ve tahmin kullanma potansiyelini başarıyla ortaya koydu. Sağlanan verileri kapsamlı bir şekilde analiz ederek ve olası kazaların ciddiyetini tahmin etmek için bir makine öğrenimi modelini eğiterek, soruşturma kurumu çabalarını ve kaynaklarını en yüksek riskli durumlara göre önceliklendirebilir. Bu proje, karmaşık sorunları çözmek için veriye dayalı yaklaşımları kullanmanın değerini ve bu girişimlere sürekli yatırım yapmanın önemini vurgulamaktadır. Bu makaledeki önemli çıkarımlara bakalım.
- Tahmine dayalı analiz gerçekleştirmek için sorunun ve altında yatan verilerin kapsamlı bir şekilde anlaşılması gerekir.
- Makine öğrenimi modelleri geliştirmek için içgörüler bulmak ve veri kümesini önceden işlemek için keşifsel veri analizi.
- Bir makine öğrenimi hattı geliştirin ve bunu tek tıklamayla modern bulutta devreye alın
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/01/machine-learning-solution-predicting-road-accident-severity/

