Başka bir gün, başka bir klasik algoritma: k-en yakın komşular. Gibi naif Bayes sınıflandırıcı, sınıflandırma problemlerini çözmek için oldukça basit bir yöntemdir. Algoritma sezgiseldir ve rakipsiz bir eğitim süresine sahiptir, bu da onu makine öğrenimi kariyerinize yeni başladığınızda öğrenmek için harika bir aday yapar. Bunu söyledikten sonra, özellikle büyük veri kümeleri için tahminlerde bulunmak acı verecek kadar yavaştır. Birçok özelliğe sahip veri kümelerinin performansı da çok yüksek olmayabilir. boyutun laneti.
Bu makalede, öğreneceksiniz
- nasıl k-en yakın komşular sınıflandırıcı çalışır
- neden böyle tasarlandı
- neden bu ciddi dezavantajlara sahip ve tabii ki,
- NumPy kullanarak Python'da nasıl uygulanacağı.
Sınıflandırıcıyı scikit öğren-uygun bir şekilde uygulayacağımız için, makaleme de göz atmakta fayda var. Kendi özel scikit-learn Regresyonunuzu oluşturun. Ancak, scikit-learn ek yükü oldukça küçüktür ve yine de takip edebilmeniz gerekir.
Kodu adresinde bulabilirsiniz. benim Github'ım.
Bu sınıflandırıcının ana fikri şaşırtıcı derecede basit. Doğrudan sınıflandırmanın temel sorusundan türetilmiştir:
Bir x veri noktası verildiğinde, x'in herhangi bir c sınıfına ait olma olasılığı nedir?
Matematik dilinde koşullu olasılığı ararız. p(c|x). İken naif Bayes sınıflandırıcı bu olasılığı doğrudan bazı varsayımları kullanarak modellemeye çalışırsa, bu olasılığı hesaplamanın başka bir sezgisel yolu vardır — sıklıkçı olasılık görüşü.
Olasılıklar Üzerine Naif Görüş
Tamam, ama bu şimdi ne anlama geliyor? Aşağıdaki basit örneği ele alalım: Altı kenarlı, muhtemelen hileli bir zar atıyorsunuz ve altı gelme olasılığını hesaplamak istiyorsunuz, yani p(6 numaralı rulo). Bu nasıl yapılır? Peki, zarı atıyorsun n kez ve ne sıklıkta altı gösterdiğini yazın. Altı numarayı gördüyseniz k kez, altı görme olasılığının etrafında k/n. Burada yeni ya da süslü bir şey yok, değil mi?
Şimdi, örneğin koşullu bir olasılığı hesaplamak istediğimizi hayal edin.
p(rulo numarası 6 | bir çift sayı yuvarlayın)
İhtiyacın yok Bayes teoremi bunu çözmek için Sadece zarı tekrar atın ve tek bir sayı ile tüm zarları yok sayın. Koşullandırmanın yaptığı budur: sonuçları filtrelemek. Eğer zarı attıysan n kez, gördüm m çift sayılar ve k bunların altısı vardı, yukarıdaki olasılık etrafında k/m yerine k/n.
k-En Yakın Komşuları Motive Etmek
Sorunumuza geri dönelim. hesaplamak istiyoruz p(c|x) nerede x özellikleri içeren bir vektördür ve c bazı sınıftır. Kalıp örneğinde olduğu gibi, biz
- çok fazla veri noktasına ihtiyaç duyar,
- özelliklere sahip olanları filtreleyin x ve
- bu veri noktalarının ne sıklıkta sınıfa ait olduğunu kontrol edin c.
Göreceli frekans, olasılık için tahminimizdir. p(c|x).
Buradaki problemi görüyor musun?
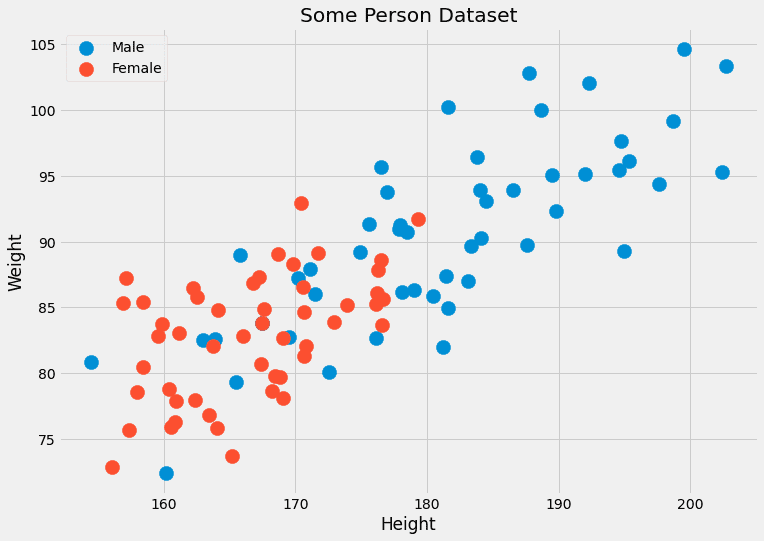
Genellikle, aynı özelliklere sahip çok sayıda veri noktamız yoktur. Çoğu zaman sadece bir, belki iki. Örneğin, iki özelliğe sahip bir veri kümesi hayal edin: kişilerin boyu (cm olarak) ve ağırlığı (kg olarak). etiketler erkek or kadın. Böylece, x=(x?, x?) Neresi x? yükseklik ve x? ağırlıktır ve c erkek ve dişi değerlerini alabilir. Bazı sahte verilere bakalım:
Yazarın resmi.
Bu iki özellik sürekli olduğundan, bırakın birkaç yüz veri noktasını, iki veri noktasına sahip olma olasılığı yok denecek kadar azdır.
Başka bir problem: (190.1, 85.2) gibi daha önce hiç görmediğimiz özelliklere sahip bir veri noktası için cinsiyeti tahmin etmek istersek ne olur? Tahmin aslında bununla ilgili. Bu yüzden bu saf yaklaşım işe yaramıyor. ne k-en yakın komşu algoritması bunun yerine şunu yapar:
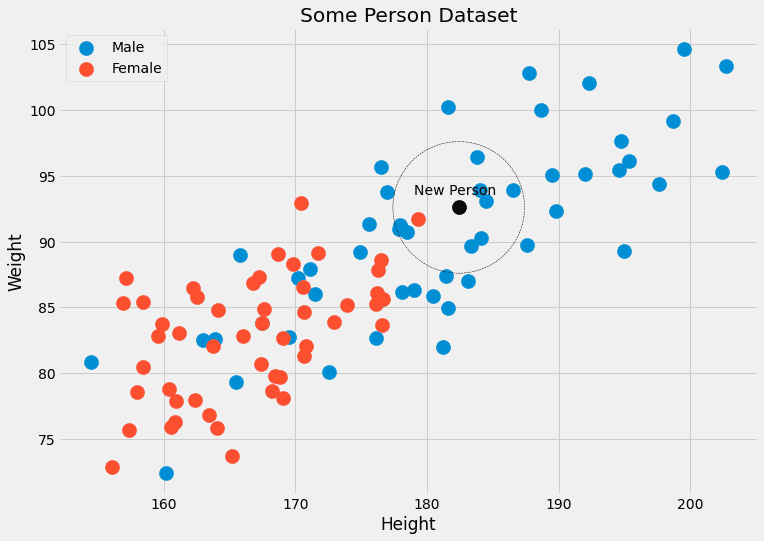
Olasılığa yaklaşmaya çalışır p(c|x) olan veri noktalarında değil kesinlikle özellikler x, ancak yakın özelliklere sahip veri noktalarıyla x.
Bir anlamda daha az katıdır. Boy=182.4 ve kilo=92.6 olan bir sürü kişiyi bekleyip cinsiyetlerine bakmak yerine, k-en yakın komşular insanları dikkate almaya izin verir kapat bu özelliklere sahip olmaktır. bu k Algoritmada düşündüğümüz insan sayısı, hiperparametre.
Bunlar bizim veya ızgara arama gibi bir hiperparametre optimizasyon algoritmasının seçmesi gereken parametrelerdir. Öğrenme algoritması tarafından doğrudan optimize edilmezler.
Yazarın resmi.
Algoritma
Artık algoritmayı açıklamak için ihtiyacımız olan her şeye sahibiz.
Eğitim:
- düzenlemek eğitim verileri bir şekilde. Tahmin süresi boyunca, bu sipariş bize k herhangi bir veri noktası için en yakın noktalar x.
- İşte bu kadar! 😉
Tahmin:
- Yeni bir veri noktası için x, bul k en yakın komşular organize eğitim verilerinde.
- toplam bunların etiketleri k komşular.
- Etiketin/olasılıkların çıktısını alın.
Bunu şu ana kadar uygulayamıyoruz çünkü doldurmamız gereken çok boşluk var.
- organize etmek ne demek?
- Yakınlığı nasıl ölçeriz?
- Nasıl toplanır?
değerinin yanı sıra k, bunların hepsi seçebileceğimiz şeyler ve farklı kararlar bize farklı algoritmalar veriyor. Kolaylaştıralım ve soruları aşağıdaki gibi cevaplayalım:
- Düzenleme = sadece eğitim veri setini olduğu gibi kaydedin
- Yakınlık = Öklid mesafesi
- Toplama = Ortalama
Bu bir örnek gerektirir. Resmi kişi verileriyle tekrar kontrol edelim.
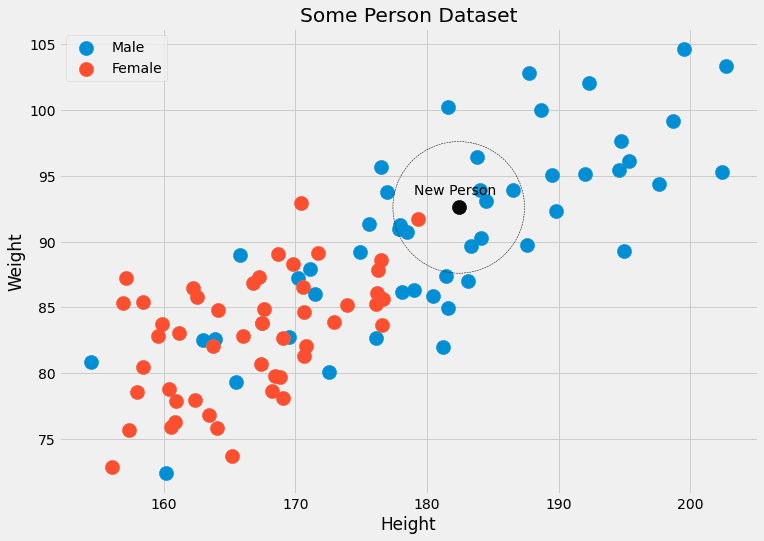
Görebiliriz ki k=Siyah olana en yakın 5 veri noktası 4 erkek etikete ve bir dişi etikete sahiptir. Böylece siyah noktaya ait olan kişinin aslında 4/5=%80 erkek ve 1/5=%20 kadın olduğu çıktısını alabiliriz. Çıktı olarak tek bir sınıfı tercih edersek, erkek döndürürüz. Sorun değil!
Şimdi uygulayalım.
En zor kısım, bir noktaya en yakın komşuları bulmaktır.
Hızlı astar
Bunu Python'da nasıl yapabileceğinize dair küçük bir örnek yapalım. ile başlıyoruz
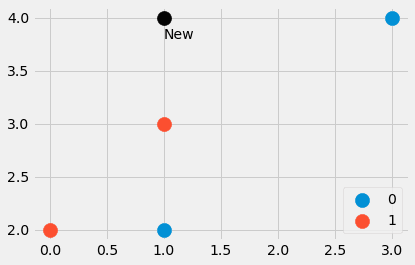
import numpy as np features = np.array([[1, 2], [3, 4], [1, 3], [0, 2]])
labels = np.array([0, 0, 1, 1]) new_point = np.array([1, 4])
Yazarın resmi.
Dört veri noktasının yanı sıra başka bir noktadan oluşan küçük bir veri seti oluşturduk. En yakın noktalar hangileri? Ve yeni noktanın etiketi 0 mı yoksa 1 mi olmalı? Hadi öğrenelim. yazarak
distances = ((features - new_point)**2).sum(axis=1)bize mesafeler=[4, 4, 1, 5] şeklinde dört değer verir. karesi Öklid uzaklığı new_point diğer tüm noktalara features . Tatlı! Üç numaralı noktanın en yakın olduğunu, ardından bir ve iki numaralı noktaların geldiğini görebiliriz. Dördüncü nokta en uzak noktadır.
Şimdi [4, 4, 1, 5] dizisinden en yakın noktaları nasıl çıkarabiliriz? A distances.argsort() yardım eder. Sonuç [2, 0, 1, 3] olup, bize dizin 2'ye sahip veri noktasının en küçük (üç numaralı nokta), sonra dizin 0'a sahip nokta, ardından dizin 1'e ve son olarak da dizine sahip nokta olduğunu söyler. 3 en büyüğüdür.
Bunu not et argsort ilk 4'ü koy distances ikinciden önce 4. Sıralama algoritmasına bağlı olarak bunun tersi de olabilir ama bu giriş yazısında bu ayrıntılara girmeyelim.
Örneğin, en yakın üç komşuyu istiyorsak, onları nasıl elde edebiliriz?
distances.argsort()[:3]ve etiketler bu en yakın noktalara şu şekilde karşılık gelir:
labels[distances.argsort()[:3]][1, 0, 0] elde ederiz, burada 1, (1, 4)'e en yakın noktanın etiketidir ve sıfırlar, sonraki en yakın iki noktaya ait etiketlerdir.
İhtiyacımız olan tek şey bu, hadi gerçek anlaşmaya geçelim.
Nihai Kod
Koda oldukça aşina olmalısınız. Tek yeni fonksiyon np.bincount etiketlerin oluşumlarını sayar. Bir uyguladığıma dikkat edin predict_proba olasılıkları hesaplamak için ilk yöntem. yöntem predict sadece bu yöntemi çağırır ve bir kullanarak en yüksek olasılıkla dizini (=sınıf) döndürür. argmaxişlev. Sınıf, 0'dan sınıfları bekliyor C-1, nerede C sınıf sayısıdır.
Yasal Uyarı: Bu kod optimize edilmemiştir, sadece eğitim amaçlıdır.
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.utils.validation import check_X_y, check_array, check_is_fitted class KNNClassifier(BaseEstimator, ClassifierMixin): def __init__(self, k=3): self.k = k def fit(self, X, y): X, y = check_X_y(X, y) self.X_ = np.copy(X) self.y_ = np.copy(y) self.n_classes_ = self.y_.max() + 1 return self def predict_proba(self, X): check_is_fitted(self) X = check_array(X) res = [] for x in X: distances = ((self.X_ - x)**2).sum(axis=1) smallest_distances = distances.argsort()[:self.k] closest_labels = self.y_[smallest_distances] count_labels = np.bincount( closest_labels, minlength=self.n_classes_ ) res.append(count_labels / count_labels.sum()) return np.array(res) def predict(self, X): check_is_fitted(self) X = check_array(X) res = self.predict_proba(X) return res.argmax(axis=1)Ve bu kadar! Küçük bir test yapıp scikit-learn ile uyuşup uyuşmadığını görebiliriz. k-en yakın komşu sınıflandırıcı.
Kodu test etme
Test için başka bir küçük veri kümesi oluşturalım.
from sklearn.datasets import make_blobs
import numpy as np X, y = make_blobs(n_samples=20, centers=[(0,0), (5,5), (-5, 5)], random_state=0)
X = np.vstack([X, np.array([[2, 4], [-1, 4], [1, 6]])])
y = np.append(y, [2, 1, 0])Bu şuna benzer:
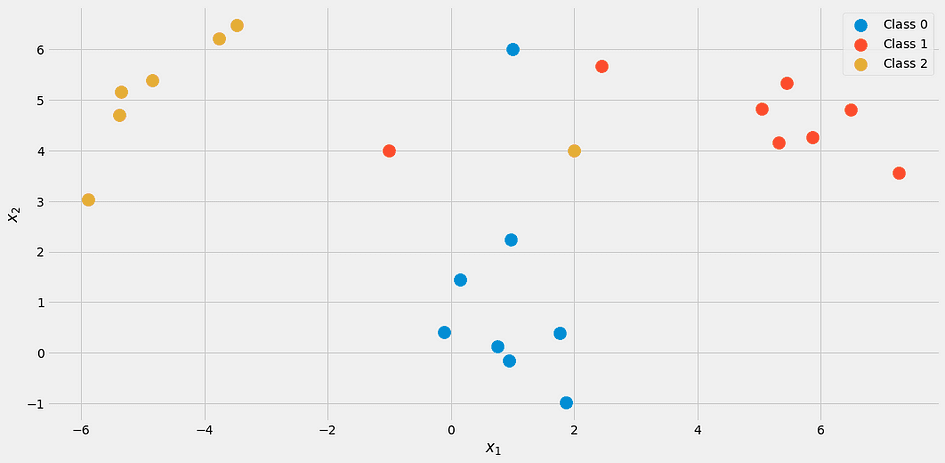
Yazarın resmi.
Sınıflandırıcımızı kullanarak k = 3
my_knn = KNNClassifier(k=3)
my_knn.fit(X, y) my_knn.predict_proba([[0, 1], [0, 5], [3, 4]])elde ederiz
array([[1. , 0. , 0. ], [0.33333333, 0.33333333, 0.33333333], [0. , 0.66666667, 0.33333333]])Çıktıyı aşağıdaki gibi okuyun: Birinci puan %100 1. sınıfa aittir, ikinci puan %33 ile her sınıfta eşit olarak yer alır ve üçüncü puan yaklaşık %67 2. sınıf ve %33 3. sınıfa aittir.
Somut etiketler istiyorsanız, deneyin
my_knn.predict([[0, 1], [0, 5], [3, 4]])[0, 0, 1] çıktısı verir. Eşitlik durumunda uyguladığımız şekliyle modelin alt sınıfı çıkardığını unutmayın, bu nedenle nokta (0, 5) sınıf 0'a ait olarak sınıflandırılır.
Resmi kontrol ederseniz, mantıklı. Ama scikit-learn'ün yardımıyla kendimizi rahatlatalım.
from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X, y) my_knn.predict_proba([[0, 1], [0, 5], [3, 4]])Sonuç:
array([[1. , 0. , 0. ], [0.33333333, 0.33333333, 0.33333333], [0. , 0.66666667, 0.33333333]])Vay! Her şey iyi gözüküyor. Güzel olduğu için algoritmanın karar sınırlarını kontrol edelim.
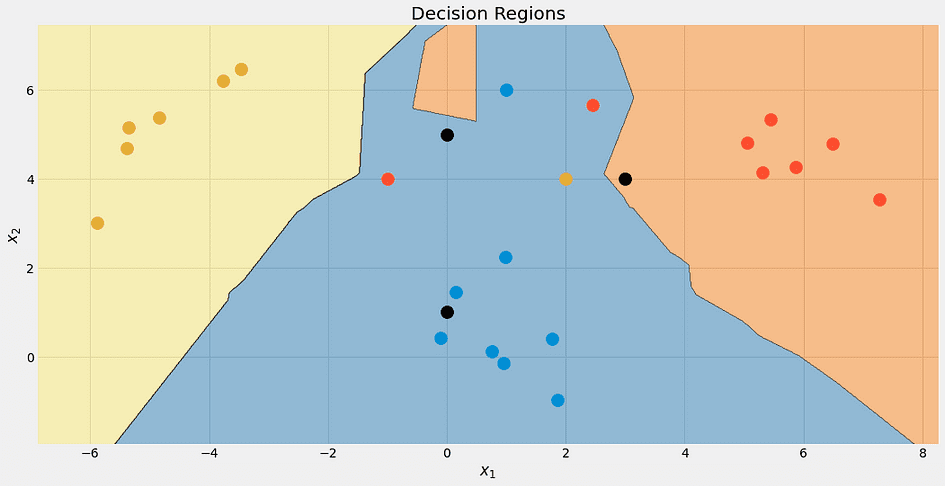
Yazarın resmi.
Yine, en üstteki siyah nokta %100 mavi değildir. %33 mavi, kırmızı ve sarıdır, ancak algoritma deterministik olarak en düşük sınıf olan maviye karar verir.
Farklı değerler için karar sınırlarını da kontrol edebiliriz. k.
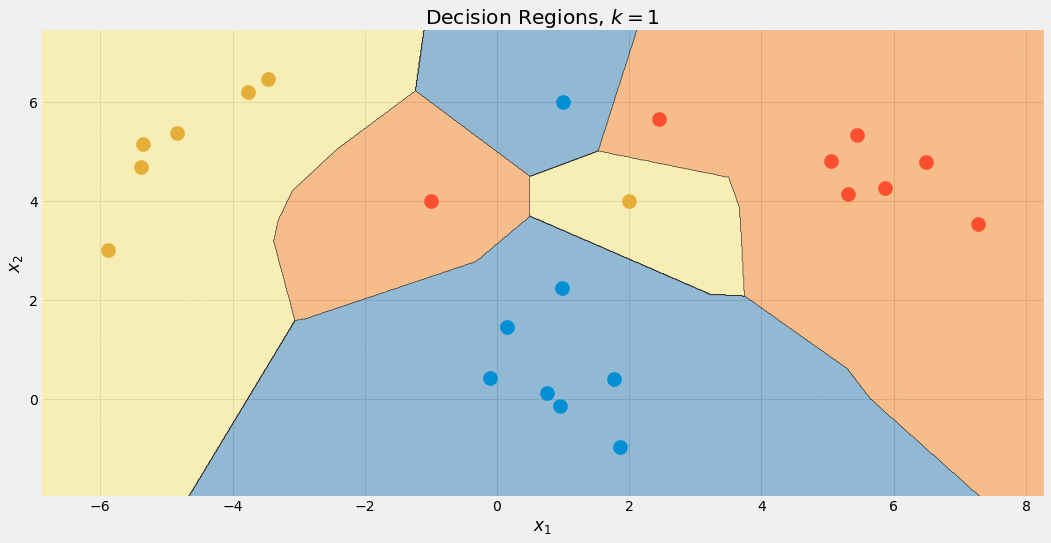
Yazarın resmi.
Bu sınıfın bu ayrıcalıklı muamelesi nedeniyle mavi bölgenin sonunda büyüdüğüne dikkat edin. için de görebiliriz k=1 sınırlar karmakarışık: model aşırı oturma. Uç noktanın diğer tarafında, k veri kümesinin boyutu kadar büyüktür ve tüm noktalar toplama adımı için kullanılır. Böylece, her veri noktası aynı tahmini alır: çoğunluk sınıfı. model yetersiz uyan bu durumda. Tatlı nokta, arada bir yerdedir ve hiperparametre optimizasyon teknikleri kullanılarak bulunabilir.
Sonuna gelmeden önce, bu algoritmanın hangi problemlere sahip olduğuna bakalım.
Sorunlar aşağıdaki gibidir:
- En yakın komşuları bulmak, özellikle saf uygulamamızla çok zaman alıyor. Yeni bir veri noktasının sınıfını tahmin etmek istiyorsak, onu veri kümemizdeki yavaş olan diğer tüm noktalarla karşılaştırmalıyız. Gelişmiş veri yapılarını kullanarak verileri düzenlemenin daha iyi yolları vardır, ancak sorun hala devam etmektedir.
- 1 numaralı problemin ardından: Genellikle modelleri daha hızlı, daha güçlü bilgisayarlarda eğitirsiniz ve daha sonra modeli daha zayıf makinelerde dağıtabilirsiniz. Örneğin, derin öğrenmeyi düşünün. Ama için k-en yakın komşular, eğitim süresi kolay ve ağır işler tahmin süresi içinde yapılır, ki bu bizim istediğimiz değildir.
- En yakın komşular hiç yakın değilse ne olur? O zaman hiçbir anlam ifade etmiyorlar. Az sayıda özelliğe sahip veri kümelerinde bu durum zaten olabiliyor, ancak daha da fazla özellik ile bu sorunla karşılaşma şansı büyük ölçüde artıyor. Bu aynı zamanda insanların boyutsallığın laneti olarak adlandırdıkları şeydir. Güzel bir görselleştirme bulunabilir Cassie Kozyrkov'un bu gönderisi.
Özellikle 2. sorun nedeniyle, k- Vahşi doğada çok sık en yakın komşu sınıflandırıcı. Yine de bilmeniz gereken güzel bir algoritma ve küçük veri kümeleri için de kullanabilirsiniz, bunda yanlış bir şey yok. Ancak binlerce özelliğe sahip milyonlarca veri noktanız varsa işler zorlaşır.
Bu yazıda, nasıl yapıldığını tartıştık. k-en yakın komşu sınıflandırıcının çalışması ve tasarımının neden anlamlı olduğu. Bir veri noktasının olasılığını tahmin etmeye çalışır. x bir sınıfa ait c mümkün olan en yakın veri noktalarını kullanarak x. Bu çok doğal bir yaklaşımdır ve bu nedenle bu algoritma genellikle makine öğrenimi kurslarının başında öğretilir.
oluşturmanın gerçekten basit olduğunu unutmayın. k-en yakın komşu gerileyen, fazla. Sınıf oluşumlarını saymak yerine, bir tahmin elde etmek için en yakın komşuların etiketlerinin ortalamasını alın. Bunu kendi başınıza uygulayabilirsiniz, bu sadece küçük bir değişiklik!
Ardından, scikit-learn API'sini taklit ederek basit bir şekilde uyguladık. Bu, bu tahmin aracını scikit-learn'ün işlem hatları ve ızgara aramalarında da kullanabileceğiniz anlamına gelir. Hiperparametreye bile sahip olduğumuz için bu büyük bir avantajdır. k ızgara arama, rastgele arama veya Bayes optimizasyonu kullanarak optimize edebilirsiniz.
Ancak, bu algoritmanın bazı ciddi sorunları var. Büyük veri kümeleri için uygun değildir ve tahmin yapmak için daha zayıf makinelerde konuşlandırılamaz. Boyutsallığın lanetine yatkınlığı ile birlikte, teorik olarak güzel ancak sadece daha küçük veri kümeleri için kullanılabilen bir algoritmadır.
Robert Kübler METRO.digital'de Veri Bilimcisi ve Towards Data Science'ta Yazardır.
orijinal. İzinle yeniden yayınlandı.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. Otomotiv / EV'ler, karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- Blok Ofsetleri. Çevre Dengeleme Sahipliğini Modernleştirme. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/2023/06/theory-practice-building-knearest-neighbors-classifier.html?utm_source=rss&utm_medium=rss&utm_campaign=from-theory-to-practice-building-a-k-nearest-neighbors-classifier

