
Bu makale ilk olarak yazarın sitesinde yayınlanmıştır. blog ve yazarın izniyle TOPBOTS'a yeniden yayınlandı.
ChatGPT gibi büyük dil modelleri, önce metni daha küçük birimlere bölerek metin dizilerini işler ve oluşturur. token kazanabilirsiniz.. Aşağıdaki resimde, her renkli blok benzersiz bir jetonu temsil ediyor. "Sen", "say", "yüksek sesle" ve "her zaman" gibi kısa veya yaygın sözcükler kendi belirteçleridir, oysa "atrocious", "precocious" ve "supercalifragilisticexpialidocious" gibi daha uzun veya daha az yaygın sözcükler parçalara ayrılır. daha küçük alt kelimeler
Bu süreç dizgeciklere diller arasında tekdüze değildir ve farklı dillerde eşdeğer ifadeler için üretilen belirteç sayısında eşitsizliklere yol açar. Örneğin, Birmanya veya Amharca'daki bir cümle, İngilizce'deki benzer bir mesajdan 10 kat daha fazla belirteç gerektirebilir.

Beş dile çevrilmiş aynı mesajın bir örneği ve bu mesajı tokenize etmek için gereken karşılık gelen jeton sayısı (OpenAI'nin jeton oluşturucusunu kullanarak). metin şu adresten gelir: Amazon'un MASSIVE veri kümesi.
Bu makalede, belirteçleştirme sürecini ve bunun farklı dillerde nasıl değiştiğini keşfediyorum:
- 52 farklı dile çevrilmiş kısa mesajlardan oluşan paralel bir veri kümesinde belirteç dağılımlarının analizi
- Ermenice veya Birmanca gibi bazı diller, İngilizceden 9 ila 10 kat daha fazla jeton karşılaştırılabilir mesajları tokenize etmek
- Bu dil eşitsizliğinin etkisi
- Bu fenomen AI için yeni değil — bu, Mors alfabesinde ve bilgisayar yazı tiplerinde gözlemlediklerimizle tutarlıdır.
Kendiniz deneyin!
Yaptığım, HuggingFace alanlarında kullanılabilen keşif kontrol panelini deneyin. Burada, farklı diller ve farklı belirteç oluşturucular için belirteç uzunluklarını karşılaştırabilirsiniz (bu makalede incelenmedi, ancak okuyucunun kendi başına yapmasını keşfediyorum).
MASİF paralel bir veri kümesidir Amazon tarafından tanıtıldı 1 dilde ve 52 alanda çevrilmiş 18 milyon gerçekçi, paralel kısa metinden oluşur. ben kullandım dev oluşan veri kümesinin bölünmesi Her bir dile çevrilmiş 2033 metin. veri kümesi HuggingFace'te mevcut altında lisanslıdır ve CC BY 4.0 lisansı.
Diğer birçok dil modeli belirteci varken, bu makale esas olarak şunlara odaklanmaktadır: OpenAI'nin Bayt Çifti Kodlama (BPE) belirteci (ChatGPT ve GPT-4 tarafından kullanılır) üç ana nedenden dolayı:
- İlk olarak, Denys Linkov'un makalesi birkaç belirteç oluşturucuyu karşılaştırdı ve GPT-2'nin belirteç oluşturucusunun farklı diller arasında en yüksek belirteç uzunluğu eşitsizliğine sahip olduğunu buldu. Bu, GPT-2 ve halefleri de dahil olmak üzere OpenAI modellerine odaklanmamı sağladı.
- İkincisi, ChatGPT'nin tam eğitim veri kümesine ilişkin bilgi eksikliğimiz olduğundan, OpenAI'nin kara kutu modellerini ve belirteç oluşturucularını araştırmak, davranışlarını ve çıktılarını daha iyi anlamaya yardımcı olur.
- Son olarak, ChatGPT'nin çeşitli uygulamalarda (örneğin dil öğrenme platformlarından) yaygın olarak benimsenmesi Duolingo gibi sosyal medya uygulamalarına Snapchat), farklı dil toplulukları arasında adil dil işlemeyi sağlamak için simgeleştirme nüanslarını anlamanın önemini vurgular.
Bir metnin içerdiği belirteç sayısını hesaplamak için şunu kullanıyorum: cl100k_base tokenizer mevcut tiktokenOpenAI'nin ChatGPT modelleri ("gpt-3.5-turbo" ve "gpt-4") tarafından kullanılan BPE belirteci olan .
Bazı diller tutarlı bir şekilde daha uzun süreler için tokenize edilir
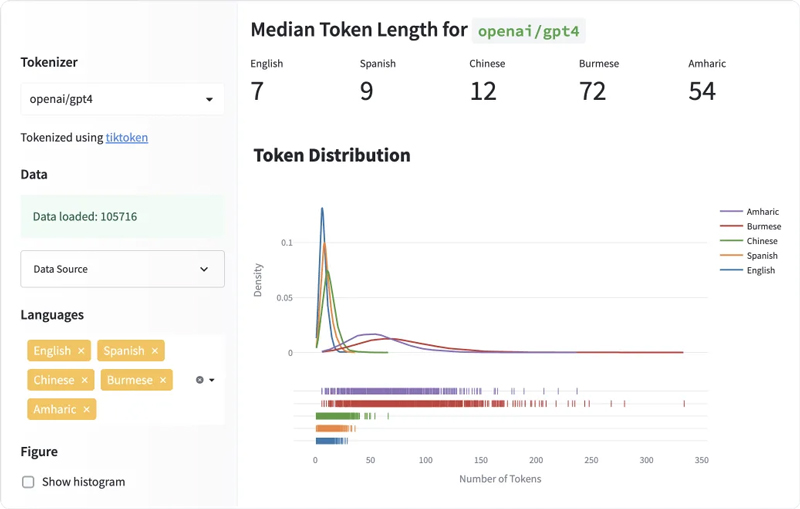
Aşağıdaki dağıtım grafiği, beş dil için belirteç uzunluklarının dağılımını karşılaştırır. İngilizce için eğri uzun ve dardır, yani İngilizce metinler sürekli olarak daha az sayıda simgeye dönüşür. Öte yandan, Hintçe ve Birmanya gibi diller için eğri kısa ve geniştir, bu da bu dillerin metinleri daha birçok simgeye ayırdığı anlamına gelir.
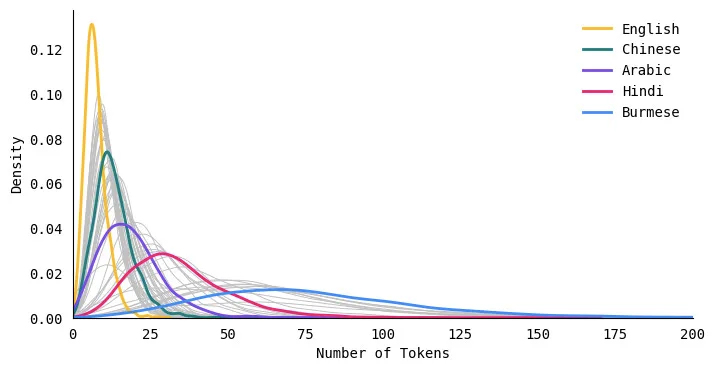
İngilizce en kısa medyan belirteç uzunluğuna sahiptir
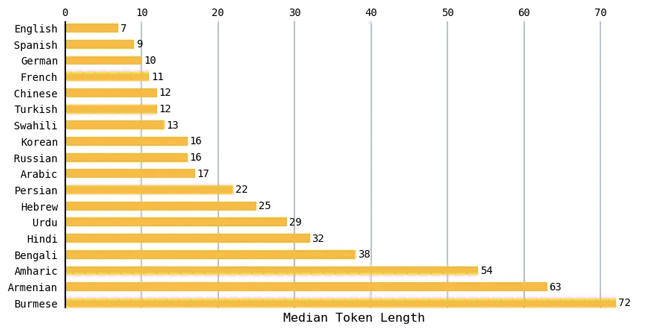
Her dil için, veri kümesindeki tüm metinler için medyan belirteç uzunluğunu hesapladım. Aşağıdaki tablo, dillerin bir alt kümesini karşılaştırmaktadır. İngilizce metinler en küçük medyan uzunluğa 7 jetonla sahipti ve Birmanya metinleri 72 jetonla en büyük medyan uzunluğa sahipti. İspanyolca, Fransızca ve Portekizce gibi Roman dilleri, İngilizce ile benzer sayıda belirteçle sonuçlanma eğilimindeydi.
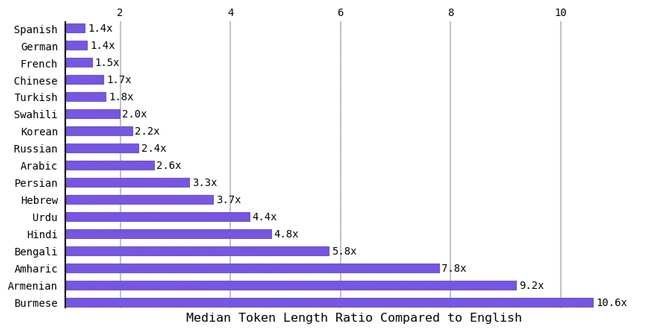
İngilizce en kısa ortalama belirteç uzunluğuna sahip olduğundan, diğer dillerin ortanca belirteç uzunluğunun İngilizceye oranını hesapladım. Hintçe ve Bengalce gibi diller (bu dillerden herhangi birini konuşan 800 milyondan fazla insan), İngilizce'nin yaklaşık 5 katı kadar bir medyan belirteç uzunluğuyla sonuçlandı. Bu oran Ermenice için İngilizcenin 9 katı, Birmanca için İngilizcenin 10 katıdır. Başka bir deyişle, aynı duyguyu ifade etmek için bazı diller 10 kata kadar daha fazla belirteç gerektirir.
Simgeleştirme dili eşitsizliğinin sonuçları
Genel olarak, daha fazla belirteç gerektirmesi (aynı mesajı farklı bir dilde belirtmek için) şu anlama gelir:
- Komut istemine ne kadar bilgi koyabileceğinizle sınırlısınız (çünkü bağlam penceresi sabittir). Mart 2023 itibariyle, GPT-3 girişinde 4K belirteç alabilir ve GPT-4 8K veya 32K belirteç alabilir [1]
- Daha fazla paraya mal olur
- Çalıştırmak daha uzun sürer
OpenAI'nin modelleri, İngilizce'nin baskın dil olmadığı ülkelerde giderek daha fazla kullanılıyor. BenzerWeb.com'a göre Amerika Birleşik Devletleri, Ocak-Mart 10'te ChatGPT'ye gönderilen trafiğin yalnızca %2023'unu oluşturuyordu.
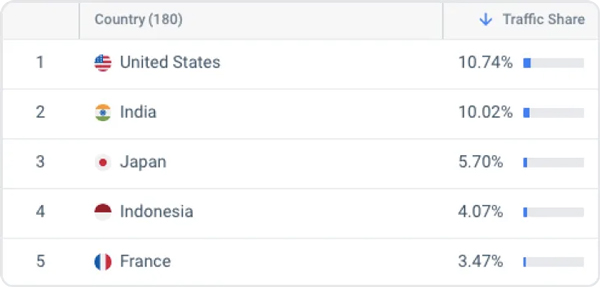
Ek olarak, ChatGPT kullanıldı Pakistan'da bir çocuk kaçırma davasında kefalet verilecek ve İdari görevler için Japonya'da. ChatGPT ve benzeri modeller dünya çapında ürün ve hizmetlere giderek daha fazla entegre olurken, bu tür eşitsizlikleri anlamak ve ele almak çok önemlidir.
Doğal Dil İşlemede Dil Eşitsizliği
Doğal dil işlemedeki (NLP) bu dijital uçurum, aktif bir araştırma alanıdır. Hesaplamalı bir dilbilim konferansında yayınlanan araştırma makalelerinin %70'i yalnızca İngilizce'yi değerlendirdi.[2] Çok dilli modeller, düşük kaynaklı dillerdeki çeşitli NLP görevlerinde, İngilizce gibi yüksek kaynaklı dillere göre daha kötü performans gösterir.[3] Göre W3Techs (World Wide Web Technology Surveys), İngilizce, İnternet'teki içeriğin yarısından fazlasına (%55.6) hakimdir.[4]
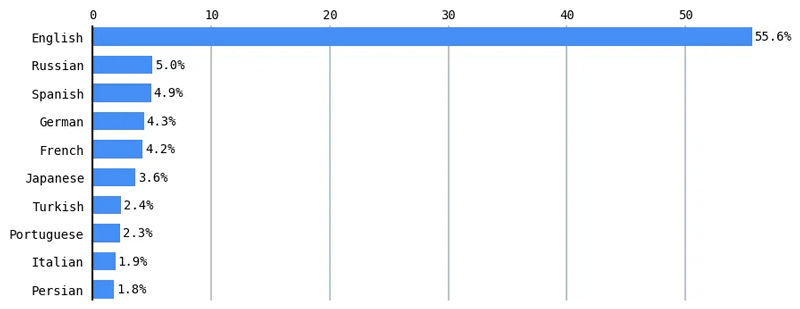
Benzer şekilde, İngilizce telafi eder Common Crawl topluluğunun %46'sından fazlası (İnternetten milyarlarca web sayfası on yılı aşkın bir süredir tarandı), sürümleri Google'ın T5 ve OpenAI'nin GPT-3'ü (ve muhtemelen ChatGPT ve GPT-4) gibi birçok büyük dili eğitmek için kullanılmıştır. Common Crawl, GPT-60 eğitim verilerinin %3'ını oluşturur.[5]
NLP'deki dijital uçurumun ele alınması, yapay zeka odaklı teknolojilerde adil dil temsili ve performansı sağlamak için çok önemlidir. Bu açığı kapatmak, araştırmacıların, geliştiricilerin ve dilbilimcilerin, doğal dil işleme alanında daha kapsayıcı ve çeşitli bir dil manzarasını teşvik ederek, düşük kaynaklı dillerin geliştirilmesine öncelik vermeleri ve bu dillere yatırım yapmaları için ortak bir çaba göstermelerini gerektirmektedir.
Tarihsel örnek: Mors Kodu kullanarak Çin Tipografisini Temsil Etmek
Farklı diller için teknolojik maliyetlerdeki bu tür bir eşitsizlik, yapay zeka ve hatta bilgi işlem için yeni değildir.
Yüz yılı aşkın bir süre önce, zamanının devrim niteliğindeki teknolojisi olan telgraf ("çağının interneti"), günümüzün büyük dil modellerinde gördüğümüze benzer dil eşitsizlikleriyle karşı karşıya kaldı. Telgraf, açık alışveriş ve işbirliği vaatlerine rağmen, diller arasında hız ve maliyet açısından farklılıklar sergiledi. Örneğin, Çince bir mesajın kodlanması ve iletilmesi (İngilizce'deki eşdeğer bir mesaja kıyasla)
- 2 kat daha pahalı
- 15-20 kat daha uzun sürdü
Tanıdık geliyor mu
Telgraf “her şeyden önce tasarlandı Batı alfabetik dilleri için, her şeyden önce İngilizce.”[6] Mors kodu, noktalara ve çizgilere farklı uzunluklar ve maliyetler atadı, bu da İngilizce için uygun maliyetli bir sistemle sonuçlandı. Ancak ideogramlara dayanan Çin dili, telgrafta zorluklarla karşılaştı. Viguier adlı bir Fransız, Çince karakterler için Mors alfabesine bir eşleme sistemi tasarladı.
Esasen, her Çin ideogramı, daha sonra Mors alfabesine çevrilmesi gereken dört basamaklı bir kodla eşleştirildi. Bu, kod defterindeki (anlamlı korelasyonlardan yoksun olan) kodları aramak uzun zaman aldı ve iletilmesi daha maliyetliydi (çünkü her karakter dört basamakla temsil ediliyordu ve tek bir hanenin iletilmesi tek bir harften daha pahalıydı). Bu uygulama Çinceyi telgraf hızı ve maliyeti açısından diğer dillere göre dezavantajlı bir duruma sokmuştur.
Başka bir örnek: Yazı tiplerini temsil etmede eşitsizlik
Başlangıçta 52 dili tek bir kelime bulutunda görselleştirmeye çalıştım. Sonunda, dillerin çoğunun düzgün şekilde oluşturulmadığı böyle bir şeyle karşılaştım.

Bu, beni tüm dil komut dosyalarını işleyebilecek bir yazı tipi bulmaya çalışırken bir tavşan deliğine götürdü. Bu mükemmel yazı tipini bulmak için Google Yazı Tipleri'ne gittim ve mevcut olmadığını gördüm. Aşağıda, bu 52 dilin Google Yazı Tiplerinden 3 farklı yazı tipinde nasıl oluşturulacağını gösteren bir ekran görüntüsü verilmiştir.

Bu makalenin başındaki kelime bulutunu oluşturmak için, tüm dil komut dosyalarını ve görüntülenen kelimeleri birer birer işlemek için gerekli 17 yazı tipi dosyasını (ehm) manuel olarak indirdim. İstenilen etkiyi elde etsem de, örneğin tüm dillerimin aynı alfabeyi (Latin alfabesi gibi) kullanması durumunda olacağından çok daha fazla işti.
Bu makalede, dil modellerindeki dil eşitsizliğini, metni simgeleştirme yoluyla nasıl işlediklerine bakarak inceledim.
- 52 dile çevrilmiş paralel metinlerden oluşan bir veri kümesi kullanarak, bazı dillerin aynı mesajı İngilizce olarak ifade etmek için 10 kata kadar daha fazla belirteç gerektirdiğini gösterdim.
- Ben paylaştım farklı dilleri ve belirteçleri keşfedebileceğiniz pano
- Bu eşitsizliğin performans, parasal maliyet ve zaman açısından belirli diller üzerindeki etkilerini tartıştım.
- Bu fenomeni Çin Mors alfabesi ve telgrafının tarihsel durumuyla karşılaştırarak, bu dilbilimsel teknolojik eşitsizlik modelinin nasıl yeni olmadığını gösterdim.
NLP simgeleştirmesindeki dil eşitsizlikleri, yapay zekada acil bir sorunu ortaya koyuyor: eşitlik ve kapsayıcılık. ChatGPT gibi modeller ağırlıklı olarak İngilizce ile eğitildiğinden, Hint-Avrupa ve Latin alfabesi olmayan diller, engelleyici simgeleştirme maliyetleri nedeniyle engellerle karşılaşır. Yapay zeka için daha kapsayıcı ve erişilebilir bir gelecek sağlamak ve nihayetinde dünya çapındaki çeşitli dil topluluklarına fayda sağlamak için bu eşitsizliklerin ele alınması çok önemlidir.
Ek
Bayt Çifti Kodlama Simgeleştirme
Doğal dil işleme alanında, belirteçler, dil modellerinin metni işlemesini ve anlamasını sağlamada çok önemli bir rol oynar. Farklı modeller, bir cümleyi sözcüklere, karakterlere veya sözcüklerin bölümlerine bölmek gibi (alt sözcükler olarak da bilinir; örneğin "sürekli"yi "sabit" ve "ly" olarak bölmek gibi) bir cümleyi tokenize etmek için farklı yöntemler kullanır.
Yaygın bir belirteçleştirme denir Bayt Çifti Kodlama (BPE). Bu, OpenAI tarafından ChatGPT modelleri için kullanılan kodlamadır. BPE, sık kullanılan kelimeleri olduğu gibi tutarken, nadir kelimeleri anlamlı alt kelimelere ayırmayı amaçlamaktadır. BPE algoritmasının kapsamlı bir açıklaması şu adreste bulunabilir: HuggingFace Transformers kursu.
Diller için Belirteç Dağıtımına Daha Derin Dalış
Amazon'un MASSIVE veri setini, o dilin Wikipedia sayfasının bilgi kutusu bölümünü kullanarak 52 dilin her biri hakkındaki bilgileri kullanarak, yazı yazısı (örn. Latin, Arap alfabesi) ve dilin baskın olduğu ana coğrafi bölge (ilgiliyse) gibi bilgileri elde ederek artırdım. . Ek olarak meta verileri kullanıyorum Dünya Dil Yapıları Atlası gibi bilgileri elde etmek için dil ailesi (örn. Hint-Avrupa, Çin-Tibet).[7]
Bu makaledeki aşağıdaki analizlerin Wikipedia, The World Atlas of Language Structures ve Amazon MASSIVE veri kümesi tarafından yapılan varsayımları desteklediğini unutmayın. Dilbilim uzmanı olmadığım için, Wikipedia ve Dünya Atlası'ndaki her şeyin, baskın coğrafi bölge veya dil ailesiyle ilgili olarak kanonik olarak doğru kabul edildiğini varsaymak zorunda kaldım.
Ayrıca, bir lehçeye karşı bir dili neyin oluşturduğuna dair tartışmalar vardır. Örneğin, Çince ve Arapça gibi diller, insanların anlamayabileceği farklı biçimlere sahipken, yine de tek dil olarak adlandırılırlar. Öte yandan, Hintçe ve Urduca çok benzerdir ve bazen Hindustani adı verilen tek bir dil olarak gruplandırılır. Bu zorluklar nedeniyle, neyin dil veya lehçe sayılacağına karar verirken dikkatli olmamız gerekiyor.
Dile göre dağılım. Ben seçtim En çok konuşulan 12 dil (hem birinci dili hem de ikinci dili konuşanların birleşimi).
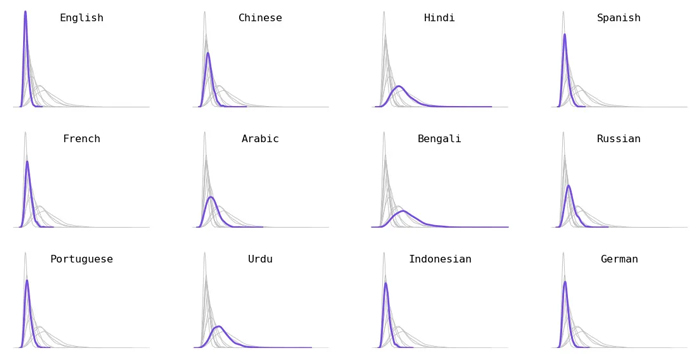
Dil ailesine göre dağılım. Hint-Avrupa (örn. İsveççe, Fransızca), Avustronezya dilleri (örn. Endonezya dili, Tagalog) ve Ural dilleri (örn. Macarca, Fince) daha kısa belirteçlerle sonuçlandı. Dravid dilleri (örn. Tamilce, Kannada) daha uzun simgelere sahip olma eğilimindeydi.

Ana coğrafi bölgeye göre dağılım. Tüm diller tek bir coğrafi bölgeye özgü değildir (birçok bölgeye yayılmış olan Arapça, İngilizce ve İspanyolca gibi) — bu diller bu bölümden çıkarılmıştır. Çoğunlukla Avrupa'da konuşulan diller simge uzunluğunda daha kısa olma eğilimindeyken, çoğunlukla Orta Doğu, Orta Asya ve Afrika Boynuzu'nda konuşulan dillerin simge uzunluğu daha uzun olma eğilimindedir.

Senaryo yazarak dökümü. Latin, Arap ve Kiril alfabeleri dışında, diğer tüm diller kendi özgün yazılarını kullanırlar. İkincisi çok farklı pek çok benzersiz yazıyı (Korece, İbranice ve Gürcüce yazılar gibi) bir araya getirirken, bu eşsiz yazılar kesinlikle daha uzun değerlere tokenize olur. Daha kısa değerlere simgeleyen Latin tabanlı betiklerle karşılaştırıldığında.

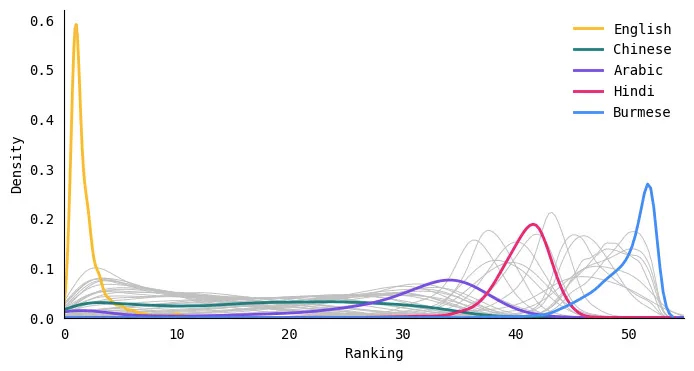
İngilizce neredeyse her zaman 1. sıradadır
Veri kümesindeki her metin için, tüm dilleri belirteç sayısına göre sıraladım — en az belirteci olan dil 1. sırada ve en çok belirteci olan dil 52. sırada yer aldı. Sonra, her dilin dağılımını çizdim. sıralama. Temel olarak, bu, her dilin belirteç uzunluğunun bu veri kümesindeki diğer dillerle nasıl karşılaştırıldığını göstermelidir. Aşağıdaki şekilde, dillerden birkaçını etiketledim (diğer diller arka planda gri çizgiler olarak görünüyor).
Bazı dillerin belirteçlerinin İngilizce'den daha az olduğu birkaç durum olsa da (Endonezce veya Norveççe'deki birkaç örnek gibi), İngilizce neredeyse her zaman bir numaradır. Bu kimseyi şaşırtmıyor mu? Beni en çok şaşırtan şey net bir #2 veya #3 olmamasıydı. İngilizce dil metinleri sürekli olarak en kısa belirteçleri üretir ve sıralama diğer diller için biraz daha dalgalanır.
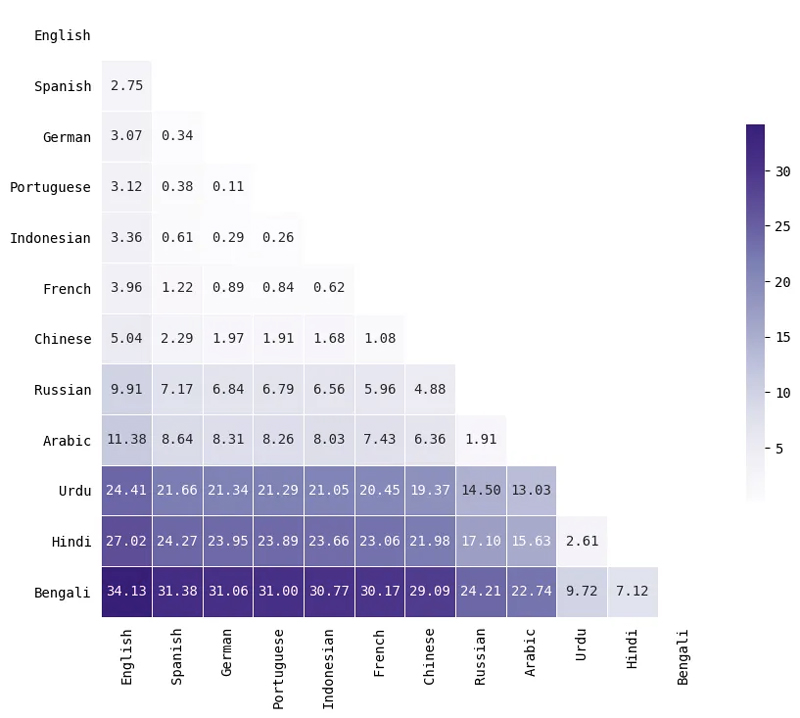
Earth Mover'ın Mesafesini kullanarak belirteç dağıtım farklılıklarını ölçme
İki dil arasındaki belirteç uzunluğu dağılımının ne kadar farklı olduğunu ölçmek için toprak taşıyıcının mesafesi (Aynı zamanda Wasserstein mesafesi) iki dağıtım arasında. Temel olarak, bu ölçüm bir dağıtımı diğerine dönüştürmek için gereken minimum "iş" miktarını hesaplar. Daha büyük değerler, dağılımların birbirinden daha uzak (daha farklı) olduğu anlamına gelirken, daha küçük değerler, dağılımların oldukça benzer olduğu anlamına gelir.
İşte dillerin küçük bir alt kümesi. Mesafenin belirteçlerin uzunluğu hakkında hiçbir şey söylemediğini, belirteç uzunluklarının dağılımının iki dil için ne kadar benzer olduğunu unutmayın. Örneğin, dillerin kendileri dilbilimsel anlamda benzer olmasa da, Arapça ve Rusça benzer dağılımlara sahiptir.
1. AI'yı açın. “Modeller”. OpenAI API'sı. Arşivlenmiş 17 Mart 2023 tarihinde orijinalinden. Erişim tarihi: 18 Mart 2023.
2. Sebastian Ruder, Ivan Vulić ve Anders Søgaard. 2022. NLP'de Kare Bir Önyargı: Araştırma Manifoldunun Çok Boyutlu Keşfine Doğru. içinde Hesaplamalı Dilbilim Derneği'nin Bulguları: ACL 2022, sayfa 2340–2354, Dublin, İrlanda. Hesaplamalı Dilbilim Derneği.
3. Shijie Wu ve Mark Dredze. 2020. Çok Dilli BERT'de Tüm Diller Eşit mi Yaratılmıştır?. içinde 5. NLP için Temsili Öğrenme Çalıştayı Bildiri Kitabı, sayfa 120–130, Çevrimiçi. Hesaplamalı Dilbilim Derneği.
4. Web siteleri için içerik dillerinin kullanım istatistikleri”. Arşivlenmiş 30 Nisan 2023 tarihinde orjinalinden.
5. Brown, Tom ve ark. "Dil modelleri çok az öğrenenlerdir." Sinirsel bilgi işleme sistemlerindeki gelişmeler 33 (2020): 1877 – 1901.
6. Jin Tsu. Karakterlerin Krallığı: Çin'i Modern Kılan Dil Devrimi. New York: Riverhead Books, 2022 (s. 124).
7. Dryer, Matthew S. & Haspelmath, Martin (editörler) 2013. WALS Online (v2020.3) [Veri seti]. Zenodo. https://doi.org/10.5281/zenodo.7385533. Şu adresten çevrimiçi olarak bulunabilir: https://wals.info, 2023–04–30'da erişildi.
Bu makaleyi beğendiniz mi? Daha fazla AI araştırma güncellemesi için kaydolun.
Bunun gibi daha özet makaleler yayınladığımızda size haber vereceğiz.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- EVM Finans. Merkezi Olmayan Finans için Birleşik Arayüz. Buradan Erişin.
- Kuantum Medya Grubu. IR/PR Güçlendirilmiş. Buradan Erişin.
- PlatoAiStream. Web3 Veri Zekası. Bilgi Genişletildi. Buradan Erişin.
- Kaynak: https://www.topbots.com/all-languages-are-not-tokenized-equal/

