Giriş
ChatGPT
Modern iş dünyasının dinamik ortamında, makine öğrenimi ve operasyonların (MLOps) kesişimi, satış dönüşümü optimizasyonuna yönelik geleneksel yaklaşımları yeniden şekillendiren güçlü bir güç olarak ortaya çıktı. Makale sizi MLOps stratejilerinin satış dönüşüm başarısında devrim yaratmada oynadığı dönüştürücü rolü ele alıyor. İşletmeler daha yüksek verimlilik ve gelişmiş müşteri etkileşimleri için çabaladıkça, makine öğrenimi tekniklerinin operasyonlara entegrasyonu merkezde yer alıyor. Bu keşif, yalnızca satış süreçlerini kolaylaştırmak için değil aynı zamanda potansiyel müşterileri sadık müşterilere dönüştürmede benzeri görülmemiş bir başarının kilidini açmak için MLOps'tan yararlanan yenilikçi stratejileri ortaya çıkarıyor. Karmaşıklıklar arasında bir yolculuğa bize katılın MLO'lar ve stratejik uygulamasının satış dönüşüm ortamını nasıl yeniden şekillendirdiğini keşfedin.
Öğrenme hedefleri
- Satış optimizasyon modelinin önemi
- Verileri Temizleme, veri kümelerini dönüştürme ve veri kümelerini ön işleme
- Kedro ve Deepcheck kullanarak Uçtan Uca Dolandırıcılık tespiti oluşturma
- Streamlit ve Huggingface kullanarak modeli dağıtma
Bu makale, Veri Bilimi Blogatonu.
İçindekiler
Satış Optimizasyon Modeli Nedir?
Satış optimizasyon modeli, ürünlerin satışını en üst düzeye çıkarmak ve dönüşüm oranını artırmak için uçtan uca bir makine öğrenimi modelidir. Model, gösterim, yaş grubu, cinsiyet, Tıklama Oranı ve Tıklama Başına Maliyet gibi çeşitli parametreleri girdi olarak alır. Modeli eğittiğinizde, reklamı gördükten sonra ürünü satın alacak kişi sayısını tahmin eder.
Gerekli Önkoşullar
1) Depoyu klonlayın
git clone https://github.com/ashishk831/Final-THC.git
cd Final-THC2) Sanal ortamı oluşturun ve etkinleştirin
#create a virtual environment
python3 -m venv SOP
#Activate your virtual environment in your project folder
source SOP/bin/activate
pip install -r requirements.txt4) Kedro, Kedro-viz, Streamlit ve Deepcheck'i yükleyin
pip install streamlit
pip install Deepcheck
pip install Kedro
pip install Kedro-vizVeri tanımlaması
Kaggle'ın veri kümesinde Python uygulamasını kullanarak temel bir Veri analizi gerçekleştirelim. Veri kümesini indirmek için tıklayın .
import pandas as pd
import numpy as np
df = pd.read_csv('KAG_conversion_data.csv')
df.head()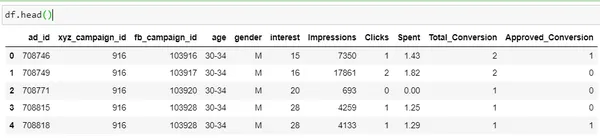
| Sütun | Açıklama |
| reklam_id | Her reklam için benzersiz bir kimlik |
| xyz_campaign_id | XYZ şirketinin her reklam kampanyasıyla ilişkili bir kimlik |
| fb_campaign_id | Facebook'un her kampanyayı nasıl izlediğiyle ilişkili bir kimlik |
| yaş | Reklamın gösterildiği kişinin yaşı |
| cinsiyet | Eklemeyi isteyen kişinin cinsiyeti gösterilir |
| faiz | kişinin ilgi alanının ait olduğu kategoriyi belirten bir kod (ilgi alanları kişinin Facebook herkese açık profilinde belirtildiği gibidir) |
| Baskı | reklamın gösterilme sayısı. |
| Tıklamalar | Söz konusu reklama ilişkin tıklama sayısı. |
| harcanmış | Bu reklamı göstermek için xyz şirketinin Facebook'a ödediği tutar |
| Toplam Dönüştürme |
Toplam Reklamı gördükten sonra ürün hakkında bilgi alan kişi sayısı |
| Onaylı Dönüştürme |
Toplam reklamı gördükten sonra ürünü satın alan kişi sayısı |
Burada “Onaylanan dönüşüm” hedef sütundur. Bizim
amaç, insanlar gördüklerinde ürünün satışını artıracak bir model tasarlamaktır.
reklam.
Kedro Kullanarak Model Geliştirme
Bu projeyi uçtan uca oluşturmak için Kedro aracını kullanacağız. Kedro, üretime hazır bir makine öğrenimi modeli oluşturmak için kullanılan ve çeşitli avantajlar sunan açık kaynaklı bir araçtır.
- Karmaşıklığın üstesinden gelir: Başarılı testlerden sonra üretime aktarılabilecek test verileri için bir yapı sağlar.
- Standardizasyon: Proje için standart şablon sağlar. Başkaları için anlaşılmasını kolaylaştırmak.
- Üretime Hazır: Tekrarlanabilir, bakımı yapılabilir ve modüler deneylere geçiş yapabileceğiniz keşif koduyla kod kolaylıkla üretime aktarılabilir.
Devamını Oku: Kedro Framework'ün İzlenecek Yolu
Boru Hattı Yapısı
Kedro'da bir proje oluşturmak için aşağıdaki adımları izleyin.
#create project
kedro new
#create pipeline
kedro pipeline create <pipeline-name>
#Run kedro
kedro run
#Visualizing pipeline
kedro vizKedro'yu kullanarak aşağıda gösterilen uçtan uca model hattını tasarlayacağız.
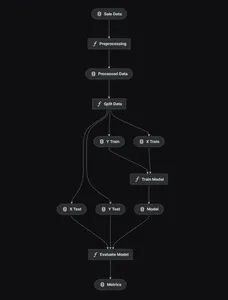
Veri ön işleme
- Eksik değerleri kontrol edin ve bunları halledin.
- İki yeni sütun TO ve TBM oluşturuluyor.
- Sütun değişkenini sayısala dönüştürme.
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
def preprocessing(data: pd.DataFrame):
data.gender = data.gender.apply(lambda x: 1 if x=="M" else 0)
data['CTR'] = ((data['Clicks']/data['Impressions'])*100)
data['CPC'] = data['Spent']/data['Clicks']
data['CPC'] = data['CPC'].replace(np.nan,0)
encoder=LabelEncoder()
encoder.fit(data["age"])
data["age"]=encoder.transform(data["age"])
#data.Approved_Conversion = data.Approved_Conversion.apply(lambda x: 0 if x==0 else 1)
preprocessed_data = data.copy()
return preprocessed_dataBölünmüş veriler
import pandas as pd
from sklearn.model_selection import train_test_split
def split_data(processed_data: pd.DataFrame):
X = processed_data[['ad_id', 'age', 'gender', 'interest', 'Spent',
'Total_Conversion','CTR', 'CPC']]
y = processed_data["Approved_Conversion"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1,
random_state=42)
return X_train, X_test, y_train, y_testYukarıdaki veri seti, model eğitimi amacıyla eğitim veri seti ve test veri seti olarak bölünmüştür.
Model Eğitimi
from sklearn.ensemble import RandomForestRegressor
def train_model(X_train, y_train):
model = RandomForestRegressor(n_estimators = 50, random_state = 0, max_samples=0.75)
model.fit(X_train, y_train)
return model
Modeli eğitmek için RandomForestRegressor modülünü kullanacağız. RandomForestRegressor ile tek başımıza n_estimators random_state ve max_samples gibi diğer parametreleri iletiyoruz.
Değerlendirme
import numpy as np
import logging
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error, max_error
def evaluate_model(model, X_test, y_test):
y_pred = model.predict(X_test)
mae=mean_absolute_error(y_test, y_pred)
mse=mean_squared_error(y_test, y_pred)
rmse=np.sqrt(mse)
r2score=r2_score(y_test, y_pred)
me = max_error(y_test, y_pred)
print("MAE Of Model is: ",mae)
print("MSE Of Model is: ",mse)
print("RMSE Of Model is: ",rmse)
print("R2_Score Of Model is: ",r2score)
logger = logging.getLogger(__name__)
logger.info("Model has a coefficient R^2 of %.3f on test data.", r2score)
return {"r2_score": r2score, "mae": mae, "max_error": me}Model eğitildikten sonra MAE, MSE, RMSE ve R2 puanı gibi bir dizi temel ölçüm kullanılarak değerlendirilir.
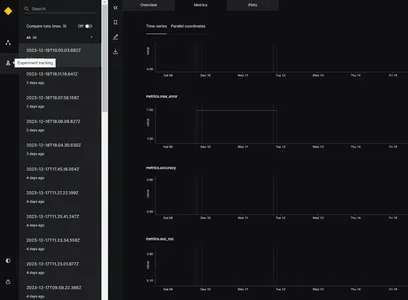
Deney Takipçisi
Model performansını izlemek ve en iyi modeli seçmek için deneme izleyiciyi kullanacağız. Deneme izleyicinin işlevi, uygulama çalıştırıldığında denemeyle ilgili tüm bilgileri kaydetmektir. Kedro'da deney izleyiciyi etkinleştirmek için katalog.xml dosyasını güncelleyebiliriz. Versiyonlanan parametrenin Doğru olarak ayarlanması gerekir. Örnek aşağıdadır
model:
type: pickle.PickleDataSet
filepath: data/06_models/model.pkl
backend: pickle
versioned: TrueBu, model sonucunun izlenmesine ve model sürümünün kaydedilmesine yardımcı olur. Burada, geliştirme aşamasında model performansını takip etmek için değerlendirme adımında deneme izleyiciyi kullanacağız.
Model yürütüldüğünde, resimde gösterildiği gibi farklı zaman damgaları için MAE, MSE, RMSE ve R2 puanı gibi farklı değerlendirme ölçümleri üretecektir. Yukarıdaki değerlendirme ölçütlerine dayanarak en iyi model seçilebilir.
Deepcheck: Veri ve Model İzleme İçin
Model üretimde devreye alındığında, veri kalitesinin zaman içinde değişme olasılığı vardır ve bu nedenle model performansı da değişebilir. Bu sorunu çözmek için üretim ortamındaki verileri izlememiz gerekiyor. Bunun için açık kaynak kodlu Deepcheck aracını kullanacağız. Deepcheck, model koduyla kolayca entegre edilebilen Label-drift ve Feature-Drift gibi yerleşik kitaplıklara sahiptir.
- ÖzellikDrift: – Kayma, model performansının düşmesine bağlı olarak zaman içinde veri dağılımında meydana gelen bir değişiklik anlamına gelir. FeaturDift, veri kümesinin tek bir özelliğinde değişiklik meydana geldiği anlamına gelir.
- Labeldrift: – Labeldrift, bir veri kümesinin temel gerçek etiketleri zaman içinde değiştiğinde meydana gelir. Çoğunlukla etiket kriterlerindeki değişiklik nedeniyle ortaya çıkar.
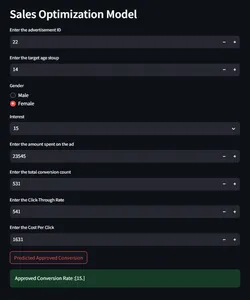
Model Tahmini ve İzlemeyi Streamlit ile Bütünleştirme
Şimdi, dönüşüm oranını kontrol etmek amacıyla verilen giriş parametreleri üzerinde tahmin yapmak için modelle etkileşime girecek bir kullanıcı arayüzü oluşturacağız.
import streamlit as st
import pandas as pd
import joblib
import numpy as np
st.sidebar.header("Model Prediction or Report")
selected_report = st.sidebar.selectbox("Select from below", ["Model Prediction",
"Data Integrity","Feature Drift", "Label Drift"])
if selected_report=="Model Prediction":
st.header("Sales Optimization Model")
#def predict(ad_id, age, gender, interest, Impressions, Clicks, Spent,
#Total_Conversion, CTR, CPC):
def predict(ad_id, age, gender, interest, Spent, Total_Conversion, CTR, CPC):
if gender == 'Male':
gender = 0
else:
gender = 1
ad_id = int(ad_id)
age = int(age)
gender = int(gender)
interest = int(interest)
#Impressions = int(Impressions)
#Clicks = int(Clicks)
Spent = float(Spent)
Total_Conversion = int(Total_Conversion)
CTR = float(CTR*0.000001)
CPC = float(CPC)
input=np.array([[ad_id, age, gender, interest, Spent,
Total_Conversion, CTR, CPC]]).astype(np.float64)
model = joblib.load('model/model.pkl')
# Make prediction
prediction = model.predict(input)
prediction= np.round(prediction)
# Return the predicted value for Approved_Conversion
return prediction
ad_id = st.number_input('Enter the advertisement ID',min_value = 0)
age = st.number_input('Enter the target age stoup',min_value = 0)
gender = st.radio("Gender",('Male','Female'))
interest = st.selectbox('Interest', [2, 7, 10, 15, 16, 18, 19, 20, 21, 22, 23,
24, 25,
26, 27, 28, 29, 30, 31, 32, 36, 63, 64, 65, 66, 100, 101, 102,
103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114])
#Impressions = st.number_input('Enter the number of impressions',min_value = 0)
#Clicks = st.number_input('Enter the number of clicks',min_value = 0)
Spent = st.number_input('Enter the amount spent on the ad',min_value = 0)
Total_Conversion = st.number_input('Enter the total conversion count',
min_value = 0)
CTR = st.number_input('Enter the Click-Through Rate',min_value = 0)
CPC = st.number_input('Enter the Cost Per Click',min_value = 0)
if st.button("Predicted Approved Conversion"):
output = predict(ad_id, age, gender, interest, Spent, Total_Conversion,
CTR, CPC)
st.success("Approved Conversion Rate :{}".format(output))
else:
st.header("Sales Model Monitoring Report")
report_file_name = "report/"+ selected_report.replace(" ", "") + ".html"
HtmlFile = open(report_file_name, 'r', encoding='utf-8')
source_code = HtmlFile.read()
st.components.v1.html(source_code, width=1200, height=1500, scrolling=True)
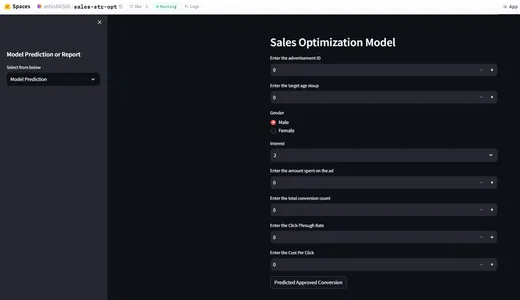
HuggingFace Kullanarak Dağıtım
Artık uçtan uca bir satış optimizasyon modeli oluşturduğumuza göre, modeli HuggingFace kullanarak dağıtacağız. Huggingface'de model dağıtımı için README.md dosyasını yapılandırmamız gerekiyor. Huggingface CI/CD ile ilgilenir. Dosyada her değişiklik olduğunda olduğu gibi, değişiklikleri izleyecek ve uygulamayı yeniden konuşlandıracaktır. Benioku.md dosya yapılandırması aşağıdadır.
title: {{Sale-str-opt}}
emoji: {{Sale-str-opt}}
colorFrom: {{colorFrom}}
colorTo: {{colorTo}}
sdk: {{sdk}}
sdk_version: {{sdkVersion}}
app_file: app.py
pinned: falseHuggingFace Uygulama Demosu
Bulut versiyonu için tıklayın .
Sonuç
- Makine öğrenimi uygulamaları, bilinmeyen pazardaki test dönüşüm oranını vererek işletmenin ürün talebini bilmesine yardımcı olabilir.
- Satış optimizasyon modelini kullanan işletme, doğru hedef kitleyi hedefleyebilir.
- Bu uygulama iş gelirinin artmasına yardımcı olur.
- Verilerin gerçek zamanlı olarak izlenmesi, model değişikliğinin ve kullanıcı davranışı değişikliğinin izlenmesine de yardımcı olabilir.
Sık Sorulan Sorular
C. Satış optimizasyon modelinin amacı, reklamı gördükten sonra ürünü satın alacak müşteri sayısını tahmin etmektir.
A. Verilerin izlenmesi, veri kümesinin ve model davranışının izlenmesine yardımcı olur.
C. Evet, huggingface'in kullanımı ücretsiz olup temel özellik 2 vCPU ve 16 GB RAM'dir.
C. Model izleme aşamasında rapor seçimine ilişkin katı kurallar yoktur, deepcheck'te model kayması, dağıtım kayması gibi birçok yerleşik kütüphane bulunur.
A. Streamlit, geliştirme aşamasında hataların düzeltilmesine yardımcı olan yerel dağıtıma yardımcı olur.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2024/01/mlops-strategies-for-sales-conversion-success/

