Bu, etki alanınız için metin özetleme modellerinin kalitesini değerlendirebilmeniz için kuruluşlar için pratik bir kılavuz önerdiğim iki bölümden oluşan bir dizinin ikinci gönderisidir.
Metin özetlemeye giriş, bu öğreticiye genel bakış ve projemiz için bir temel oluşturma adımları (ayrıca bölüm 1 olarak da anılır) için, bkz. ilk yazı.
Bu gönderi üç bölüme ayrılmıştır:
- 2. Bölüm: Sıfır atış modeliyle özetler oluşturun
- 3. Bölüm: Bir özetleme modeli eğitin
- 4. Bölüm: Eğitilen modeli değerlendirin
2. Bölüm: Sıfır atış modeliyle özetler oluşturun
Bu yazıda, kavramını kullanıyoruz sıfır vuruşlu öğrenme (ZSL), bu, metni özetlemek için eğitilmiş ancak herhangi bir örnek görmemiş bir model kullandığımız anlamına gelir. arXiv veri kümesi. Hayatında yaptığın tek şey manzara resmiyken portre çizmeye çalışmak gibi. Resim yapmayı biliyorsun ama portre resminin inceliklerine pek aşina olmayabilirsin.
Bu bölüm için aşağıdakileri kullanıyoruz defter.
Neden sıfır vuruşlu öğrenme?
ZSL, eğitim almadan son teknoloji NLP modellerini kullanmanıza izin verdiği için son yıllarda popüler hale geldi. Ve performansları bazen oldukça şaşırtıcıdır: Büyük Bilim Araştırma Çalışma Grubu yakın zamanda, sıfır vuruşlu çoklu görev öğrenimini araştırmak için özel olarak eğitilmiş T0pp ("T Zero Plus Plus" olarak telaffuz edilir) modelini piyasaya sürdü. Genellikle altı kat daha büyük modellerden daha iyi performans gösterebilir. BÜYÜK tezgah kıyaslama yapabilir ve daha iyi performans gösterebilir GPT 3 (16 kat daha büyük) diğer NLP kriterlerinde.
ZSL'nin bir başka avantajı, onu kullanmak için sadece iki satır kod gerektirmesidir. Bunu deneyerek, veri kümemizde modele ince ayar yaptıktan sonra model performansındaki kazancı ölçmek için kullandığımız ikinci bir temel oluştururuz.
Sıfır atışlı bir öğrenme ardışık düzeni kurun
ZSL modellerini kullanmak için Hugging Face's kullanabiliriz. Boru Hattı API'sı. Bu API, yalnızca iki satır kod içeren bir metin özetleme modeli kullanmamızı sağlar. Bir NLP modelindeki ana işlem adımlarını üstlenir:
- Metni, modelin anlayabileceği bir formatta önceden işleyin.
- Önceden işlenmiş girdileri modele iletin.
- Modelin tahminlerini son işlemden geçirin, böylece onları anlamlandırabilirsiniz.
Halihazırda mevcut olan özetleme modellerini kullanır. Sarılma Yüz modeli merkezi.
Kullanmak için aşağıdaki kodu çalıştırın:
Bu kadar! Kod, bir özetleme modeli indirir ve makinenizde yerel olarak özetler oluşturur. Hangi modeli kullandığını merak ediyorsanız, şuradan bakabilirsiniz. kaynak kodu veya aşağıdaki komutu kullanın:
Bu komutu çalıştırdığımızda, metin özetleme için varsayılan modelin çağrıldığını görüyoruz. sshleifer/distilbart-cnn-12-6:
![]()
Bulabiliriz model kartı Bu model için, modelin iki veri kümesi üzerinde eğitildiğini de görebildiğimiz Hugging Face web sitesinde: CNN Dailymail veri seti ve Aşırı Özetleme (XSum) veri kümesi. Bu modelin arXiv veri kümesine aşina olmadığını ve yalnızca eğitim aldığı metinlere benzer metinleri (çoğunlukla haber makaleleri) özetlemek için kullanıldığını belirtmekte fayda var. Model adındaki 12 ve 6 sayıları sırasıyla kodlayıcı katmanlarının ve kod çözücü katmanlarının sayısını belirtir. Bunların ne olduğunu açıklamak bu eğitimin kapsamı dışındadır, ancak bununla ilgili daha fazla bilgiyi gönderide okuyabilirsiniz. BART ile tanışın modeli yaratan Sam Shleifer tarafından.
İleriye dönük olarak varsayılan modeli kullanıyoruz, ancak önceden eğitilmiş farklı modelleri denemenizi tavsiye ederim. Özetlemeye uygun tüm modeller haberimizde. sarılma yüz web sitesi. Farklı bir model kullanmak için Pipeline API'sini çağırırken model adını belirtebilirsiniz:
Çıkarıcı ve soyutlayıcı özetleme
Henüz metin özetleme için olası ancak farklı iki yaklaşımdan bahsetmedik: ekstraktif vs soyut. Çıkarıcı özetleme, bir metinden alınan alıntıları bir özette birleştirme stratejisiyken, soyutlayıcı özetleme, yeni cümleler kullanarak tümceyi başka sözcüklerle ifade etmeyi içerir. Özetleme modellerinin çoğu, yeni metin oluşturan modellere dayanır (bunlar, örneğin, doğal dil oluşturma modelleridir. GPT 3). Bu, özetleme modellerinin aynı zamanda yeni metinler ürettiği anlamına gelir, bu da onları soyutlayıcı özetleme modelleri yapar.
Sıfır atış özetleri oluşturun
Artık nasıl kullanılacağını bildiğimize göre, onu test veri setimizde kullanmak istiyoruz - aynı veri setinde kullandığımız veri seti. 1 bölümü temel oluşturmak için. Bunu aşağıdaki döngü ile yapabiliriz:
Biz kullanın min_length ve max_length Modelin oluşturduğu özeti kontrol etmek için parametreler. Bu örnekte, belirlediğimiz min_length 5'e kadar çünkü başlığın en az beş kelime uzunluğunda olmasını istiyoruz. Ve referans özetlerini (araştırma makalelerinin asıl başlıkları) tahmin ederek, 20'nin aşağıdakiler için makul bir değer olabileceğini belirledik. max_length. Ama yine, bu sadece bir ilk deneme. Proje deneme aşamasındayken, model performansının değişip değişmediğini görmek için bu iki parametre değiştirilebilir ve değiştirilmelidir.
Ek parametreler
Metin oluşturmaya zaten aşinaysanız, ışın arama, örnekleme ve sıcaklık gibi bir modelin oluşturduğu metni etkileyen daha birçok parametre olduğunu biliyor olabilirsiniz. Bu parametreler, oluşturulan metin üzerinde size daha fazla kontrol sağlar, örneğin metni daha akıcı ve daha az tekrarlı hale getirir. Bu teknikler Pipeline API'sinde mevcut değildir; kaynak kodu o min_length ve max_length dikkate alınan tek parametredir. Ancak kendi modelimizi eğitip dağıttıktan sonra bu parametrelere erişebiliriz. Bununla ilgili daha fazla bilgi bu yazının 4. bölümünde.
Model değerlendirme
Sıfır atış özetlerini ürettikten sonra, aday özetlerini referans özetleriyle karşılaştırmak için KÖTÜ işlevimizi tekrar kullanabiliriz:
Bu hesaplamayı ZSL modeliyle oluşturulan özetler üzerinde çalıştırmak bize aşağıdaki sonuçları verir:
![]()
Bunları taban çizgimizle karşılaştırdığımızda, bu ZSL modelinin aslında sadece ilk cümleyi almakla ilgili basit buluşsal yöntemimizden daha kötü performans gösterdiğini görüyoruz. Yine, bu beklenmedik bir şey değil: bu model haber makalelerini nasıl özetleyeceğini bilmesine rağmen, hiçbir zaman akademik bir araştırma makalesinin özetini özetleme örneğini görmedi.
Temel karşılaştırma
Şimdi iki temel oluşturduk: biri basit buluşsal yöntem kullanan ve diğeri ZSL modeliyle. ROUGE puanlarını karşılaştırarak, basit buluşsal yöntemin şu anda derin öğrenme modelinden daha iyi performans gösterdiğini görüyoruz.
![]()
Bir sonraki bölümde, aynı derin öğrenme modelini alıp performansını iyileştirmeye çalışıyoruz. Bunu arXiv veri setinde eğiterek yapıyoruz (bu adıma aynı zamanda ince ayar). Genel olarak metni nasıl özetleyeceğini zaten bildiği gerçeğinden yararlanıyoruz. Daha sonra ona arXiv veri setimizin birçok örneğini gösteriyoruz. Derin öğrenme modelleri, üzerinde eğitildikten sonra veri kümelerindeki kalıpları belirlemede son derece iyidir, bu nedenle modelin bu özel görevde daha iyi olmasını bekliyoruz.
3. Bölüm: Bir özetleme modeli eğitin
Bu bölümde, 2. bölümde sıfır atış özetleri için kullandığımız modeli eğitiyoruz (sshleifer/distilbart-cnn-12-6) veri setimizde. Buradaki fikir, modele birçok örnek göstererek araştırma makalelerinin özetlerinin nasıl göründüğünü öğretmektir. Zaman içinde modelin bu veri kümesindeki kalıpları tanıması gerekir, bu da daha iyi özetler oluşturmasına olanak tanır.
Verileri, yani metinleri ve ilgili özetleri etiketlediyseniz, bir modeli eğitmek için bunları kullanmanız gerektiğini bir kez daha belirtmekte fayda var. Yalnızca bunu yaparak model, belirli veri kümenizin kalıplarını öğrenebilir.
Model eğitimi için tam kod aşağıdadır defter.
Bir eğitim işi ayarlayın
Bir derin öğrenme modelinin eğitimi bir dizüstü bilgisayarda birkaç hafta alacağından, Amazon Adaçayı Yapıcı yerine eğitim işleri. Daha fazla ayrıntı için, bkz. Amazon SageMaker ile Model Eğitin. Bu yazıda, GPU hesaplama örneklerini kullanmamıza izin vermelerinin yanı sıra, bu eğitim işlerini kullanmanın avantajını kısaca vurgulayacağım.
Kullanabileceğimiz bir GPU örneği kümemiz olduğunu varsayalım. Bu durumda, eğitim ortamını diğer makinelerde kolayca çoğaltabilmemiz için eğitimi çalıştırmak için muhtemelen bir Docker görüntüsü oluşturmak isteriz. Daha sonra gerekli paketleri kuruyoruz ve birkaç örnek kullanmak istediğimiz için dağıtılmış eğitim de kurmamız gerekiyor. Eğitim bittiğinde bu bilgisayarları maliyetli olduğu için bir an önce kapatmak istiyoruz.
Eğitim işlerini kullanırken tüm bu adımlar bizden soyutlanır. Aslında, bir modeli, eğitim parametrelerini belirterek ve ardından sadece bir yöntemi çağırarak açıklandığı şekilde eğitebiliriz. SageMaker, eğitim tamamlandığında GPU örneklerini durdurmak da dahil olmak üzere gerisini halleder, böylece daha fazla maliyete neden olmaz.
Buna ek olarak, Hugging Face ve AWS, 2022'nin başlarında, Hugging Face modellerini SageMaker'da eğitmeyi daha da kolaylaştıran bir ortaklık duyurdu. Bu işlevsellik, Hugging Face'in geliştirilmesiyle sağlanır. AWS Derin Öğrenme Kapları (DLC'ler). Bu kapsayıcılar, Hugging Face Transformers, Tokenizers ve bu kaynakları eğitim ve çıkarım işleri için kullanmamıza izin veren Veri Kümeleri kitaplığını içerir. Kullanılabilir DLC görüntülerinin listesi için bkz. Sarılma Yüz Derin Öğrenme Kapsayıcıları Resimleri. Güvenlik yamalarıyla korunurlar ve düzenli olarak güncellenirler. Bu DLC'ler ve Hugging Face modellerinin nasıl eğitileceğine dair birçok örnek bulabiliriz. Kucaklayan Yüz Python SDK'sı aşağıda GitHub repo.
Bu örneklerden birini şablon olarak kullanıyoruz çünkü amacımız için ihtiyacımız olan hemen hemen her şeyi yapıyor: bir özetleme modeli eğitmek belirli bir veri kümesinde dağıtılmış bir şekilde (birden fazla GPU örneği kullanarak).
Ancak hesaba katmamız gereken bir şey, bu örneğin doğrudan Hugging Face veri kümesi merkezinden bir veri kümesi kullanmasıdır. Kendi özel verilerimizi sağlamak istediğimiz için not defterini biraz değiştirmemiz gerekiyor.
Verileri eğitim işine iletin
Kendi veri setimizi getirdiğimizi hesaba katmak için kullanmamız gerekiyor kanallar. Daha fazla bilgi için bkz. Amazon SageMaker Eğitim Bilgilerini Nasıl Sağlar?.
Şahsen bu terimi biraz kafa karıştırıcı buluyorum, bu yüzden aklımda her zaman haritalama duyduğumda kanallar, çünkü ne olduğunu daha iyi görselleştirmeme yardımcı oluyor. Açıklamama izin verin: Daha önce öğrendiğimiz gibi, eğitim işi bir dizi Amazon Elastik Bilgi İşlem Bulutu (Amazon EC2) bir Docker görüntüsü oluşturur ve bunun üzerine kopyalar. Ancak, veri kümelerimiz şurada saklanır: Amazon Basit Depolama Hizmeti (Amazon S3) ve bu Docker görüntüsü tarafından erişilemez. Bunun yerine, eğitim işinin verileri Amazon S3'ten bir ön tanımlamaya kopyalaması gerekir.
bu Docker görüntüsünde yerel olarak yol bulundu. Bunu yapma yöntemi, eğitim işine verilerin Amazon S3'te nerede bulunduğunu ve eğitim işinin erişebilmesi için Docker görüntüsünde verilerin nereye kopyalanması gerektiğini söylememizdir. Biz harita yerel yolla Amazon S3 konumu.
Eğitim işinin hiperparametreler bölümünde yerel yolu belirledik:
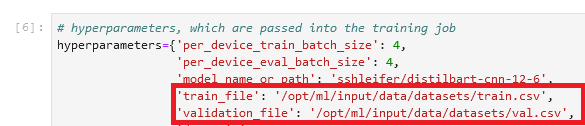
Ardından, eğitimi başlatan fit() yöntemini çağırırken eğitim işine verilerin Amazon S3'te nerede olduğunu söyleriz:
![]()
Klasör adının ardından /opt/ml/input/data kanal adıyla eşleşir (datasets). Bu, eğitim işinin verileri Amazon S3'ten yerel yola kopyalamasını sağlar.
Eğitime başla
Artık eğitim işine başlamaya hazırız. Daha önce de belirtildiği gibi, bunu arayarak yapıyoruz. fit() yöntem. Eğitim işi yaklaşık 40 dakika sürer. SageMaker konsolunda ilerlemeyi takip edebilir ve ek bilgileri görebilirsiniz.
![]()
Eğitim işi tamamlandığında, yeni eğitilmiş modelimizi değerlendirmenin zamanı geldi.
4. Bölüm: Eğitilen modeli değerlendirin
Eğitilmiş modelimizi değerlendirmek, ZSL modelini değerlendirdiğimiz 2. bölümde yaptığımıza çok benzer. Modeli çağırır ve aday özetleri oluşturur ve ROUGE puanlarını hesaplayarak bunları referans özetleriyle karşılaştırırız. Ama şimdi, model Amazon S3'te şu adla adlandırılan bir dosyada oturuyor: model.tar.gz (tam yeri bulmak için konsoldaki eğitim işini kontrol edebilirsiniz). Peki, özetler oluşturmak için modele nasıl erişeceğiz?
İki seçeneğimiz var: ZSL modeliyle 2. bölümde yaptığımıza benzer şekilde modeli bir SageMaker uç noktasına dağıtın veya yerel olarak indirin. Bu eğitimde ben modeli bir SageMaker uç noktasına dağıtın çünkü daha uygun ve uç nokta için daha güçlü bir örnek seçerek, çıkarım süresini önemli ölçüde kısaltabiliriz. GitHub deposu şunları içerir: defter bu, modelin yerel olarak nasıl değerlendirileceğini gösterir.
Bir model dağıtın
Eğitimli bir modeli SageMaker'da dağıtmak genellikle çok kolaydır (tekrar aşağıdaki örneğe bakın). GitHub Hugging Face'den). Model eğitildikten sonra arayabiliriz estimator.deploy() ve SageMaker gerisini bizim için arka planda yapıyor. Eğitimimizde bir not defterinden diğerine geçeceğimiz için, dağıtmadan önce eğitim işini ve ilişkili modeli bulmamız gerekir:
![]()
Model konumunu aldıktan sonra onu bir SageMaker uç noktasına dağıtabiliriz:
SageMaker'da dağıtım basittir çünkü aşağıdakileri kullanır: SageMaker Kucaklayan Yüz Çıkarım Araç Seti, SageMaker'da Transformers modellerini sunmak için açık kaynaklı bir kitaplık. Normalde bir çıkarım komut dosyası sağlamamız bile gerekmez; araç seti bununla ilgilenir. Ancak bu durumda, araç seti Pipeline API'sini tekrar kullanır ve 2. bölümde tartıştığımız gibi Pipeline API, ışın arama ve örnekleme gibi gelişmiş metin oluşturma tekniklerini kullanmamıza izin vermez. Bu sınırlamayı önlemek için, özel çıkarım komut dosyası.
İlk değerlendirme
Yeni eğitilmiş modelimizin ilk değerlendirmesi için, aday özetlerini oluşturmak için sıfır atış modeliyle 2. bölümdeki parametreleri kullanıyoruz. Bu, elma-elma karşılaştırması yapmanızı sağlar:
Model tarafından oluşturulan özetleri referans özetleriyle karşılaştırırız:
![]()
Bu cesaret verici! Modeli herhangi bir hiperparametre ayarı olmadan eğitmeye yönelik ilk girişimimiz, ROUGE puanlarını önemli ölçüde iyileştirdi.
![]()
İkinci değerlendirme
Şimdi, modelle oynamak için ışın arama ve örnekleme gibi bazı daha gelişmiş teknikleri kullanmanın zamanı geldi. Bu parametrelerin her birinin ne yaptığıyla ilgili ayrıntılı bir açıklama için bkz. Metin nasıl oluşturulur: Transformers ile dil üretimi için farklı kod çözme yöntemlerinin kullanılması. Bu parametrelerden bazıları için yarı rasgele bir değerler kümesiyle deneyelim:
Modelimizi bu parametrelerle çalıştırırken aşağıdaki puanları alıyoruz:
![]()
Bu pek umduğumuz gibi olmadı - ROUGE puanları aslında biraz düştü. Ancak bunun, bu parametreler için farklı değerler denemekten sizi vazgeçirmesine izin vermeyin. Aslında bu, kurulum aşamasını bitirip, projenin deneme aşamasına geçiş yaptığımız noktadır.
Sonuç ve sonraki adımlar
Deneme aşamasının kurulumunu tamamladık. Bu iki bölümlük dizide, verilerimizi indirip hazırladık, basit bir buluşsal yöntem ile bir temel oluşturduk, sıfır vuruşlu öğrenmeyi kullanarak başka bir temel oluşturduk ve ardından modelimizi eğittik ve performansta önemli bir artış gördük. Şimdi daha da iyi özetler oluşturmak için yarattığımız her parçayla oynama zamanı. Aşağıdakileri göz önünde bulundur:
- Verileri uygun şekilde önceden işleyin – Örneğin, yasak kelimeleri ve noktalama işaretlerini kaldırın. Bu kısmı hafife almayın—birçok veri bilimi projesinde, veri ön işleme en önemli yönlerden biridir (en önemli değilse de) ve veri bilimcileri genellikle zamanlarının çoğunu bu görevle harcarlar.
- Farklı modeller deneyin – Eğitimimizde, özetlemek için standart modeli kullandık (
sshleifer/distilbart-cnn-12-6), Fakat daha birçok model Bu görev için kullanabileceğiniz kullanılabilir. Bunlardan biri kullanım durumunuza daha uygun olabilir. - Hiperparametre ayarını gerçekleştirin – Modeli eğitirken belirli bir hiperparametre seti kullandık (öğrenme hızı, dönem sayısı vb.). Bu parametreler kesin değildir - tam tersi. Model performansınızı nasıl etkilediklerini anlamak için bu parametreleri değiştirmelisiniz.
- Metin üretimi için farklı parametreler kullanın – Işın arama ve örneklemeyi kullanmak için farklı parametrelerle özetler oluşturmanın bir turunu zaten yaptık. Farklı değerler ve parametreler deneyin. Daha fazla bilgi için bkz. Metin nasıl oluşturulur: Transformers ile dil üretimi için farklı kod çözme yöntemlerinin kullanılması.
Umarım sonuna kadar gelmişsinizdir ve bu öğreticiyi faydalı bulmuşsunuzdur.
Yazar Hakkında
![]() heiko hotz AI ve Makine Öğrenimi için Kıdemli Çözüm Mimarıdır ve AWS içindeki Doğal Dil İşleme (NLP) topluluğuna liderlik eder. Bu görevden önce, Amazon'un AB Müşteri Hizmetlerinde Veri Bilimi Başkanıydı. Heiko, müşterilerimizin AWS'deki AI/ML yolculuklarında başarılı olmalarına yardımcı olur ve Sigortacılık, Finansal Hizmetler, Medya ve Eğlence, Sağlık Hizmetleri, Kamu Hizmetleri ve İmalat dahil olmak üzere birçok sektördeki kuruluşlarla birlikte çalışmıştır. Heiko boş zamanlarında mümkün olduğunca çok seyahat eder.
heiko hotz AI ve Makine Öğrenimi için Kıdemli Çözüm Mimarıdır ve AWS içindeki Doğal Dil İşleme (NLP) topluluğuna liderlik eder. Bu görevden önce, Amazon'un AB Müşteri Hizmetlerinde Veri Bilimi Başkanıydı. Heiko, müşterilerimizin AWS'deki AI/ML yolculuklarında başarılı olmalarına yardımcı olur ve Sigortacılık, Finansal Hizmetler, Medya ve Eğlence, Sağlık Hizmetleri, Kamu Hizmetleri ve İmalat dahil olmak üzere birçok sektördeki kuruluşlarla birlikte çalışmıştır. Heiko boş zamanlarında mümkün olduğunca çok seyahat eder.
- Akıllı para. Avrupa'nın En İyi Bitcoin ve Kripto Borsası.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. SERBEST ERİŞİM.
- KriptoHawk. Altcoin Radarı. Ücretsiz deneme.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/part-2-set-up-a-text-summarization-project-with-hugging-face-transformers/

