Giriş
Twitter veya Linkedin olsun, Büyük Dil Modelleri (LLM'ler) her gün. Belki de bu merak uyandıran modellere neden bu kadar inanılmaz miktarda araştırma ve geliştirme yapıldığını merak etmişimdir. İtibaren ChatGPT BARD, Falcon ve diğer sayısız kişinin isimleri dönüp duruyor ve beni onların gerçek doğasını ortaya çıkarmaya hevesli bırakıyor. Bu modeller nasıl oluşturulur? Büyük dil modelleri nasıl oluşturulur? Onlara yönelttiğiniz hemen hemen her soruyu yanıtlama yeteneğine nasıl sahipler? Bu yakıcı sorular aklımda oyalandı ve merakımı körükledi. Bu doyumsuz merak içimde bir ateş yaktı ve beni LLM'ler alemine dalmaya itti.

LLM'lerdeki son teknolojiyi tartışacağımız için heyecan verici bir yolculukta bana katılın. Birlikte, gelişimlerinin ardındaki sırları çözeceğiz, olağanüstü yeteneklerini kavrayacağız ve dil işleme dünyasında nasıl devrim yarattıklarına ışık tutacağız.
Öğrenme hedefleri
- LLM'ler ve güncel durumları hakkında bilgi edinin.
- Mevcut farklı LLM'leri ve bu LLM'leri sıfırdan eğitmeye yönelik yaklaşımları anlayın
- LLM'leri eğitmek ve değerlendirmek için en iyi uygulamaları keşfedin
Kemerlerinizi bağlayın ve LLM'lerde uzmanlaşma yolculuğumuza başlayalım.
İçindekiler
Büyük Dil Modellerinin Kısa Tarihi
Büyük Dil Modellerinin geçmişi 1960'lara kadar uzanmaktadır. 1967'de MIT'de bir profesör şimdiye kadarki ilk NLP Eliza'yı doğal dili anlayacak şekilde programlayın. İnsanları anlamak ve insanlarla etkileşim kurmak için model eşleştirme ve ikame tekniklerini kullanır. Daha sonra, 1970 yılında, SHRDLU olarak bilinen insanları anlamak ve onlarla etkileşim kurmak için MIT ekibi tarafından başka bir NLP programı oluşturuldu.
1988 olarak, RNN Metin verilerinde bulunan dizi bilgisini yakalamak için mimari tanıtıldı. 2000'li yıllarda, NLP'de RNN'leri kullanan kapsamlı araştırmalar vardı. RNN'leri kullanan dil modelleri, bugüne kadarki en gelişmiş mimarilerdi. Ancak RNN'ler yalnızca daha kısa cümlelerle iyi çalışabilir, ancak uzun cümlelerle çalışamaz. Buradan, LSTM 2013 yılında tanıtıldı. Bu dönemde LSTM tabanlı uygulamalarda çok büyük gelişmeler yaşandı. Eşzamanlı olarak, dikkat mekanizmalarında da araştırmalar başladı.
LSTM ile ilgili 2 önemli endişe vardı. LSTM uzun cümleler problemini bir nebze olsun çözmüş ama gerçekten uzun cümlelerle çalışırken tam olarak başarılı olamadı. Eğitim LSTM modelleri paralelleştirilemez. Bu nedenle bu modellerin eğitimi daha uzun sürmüştür.
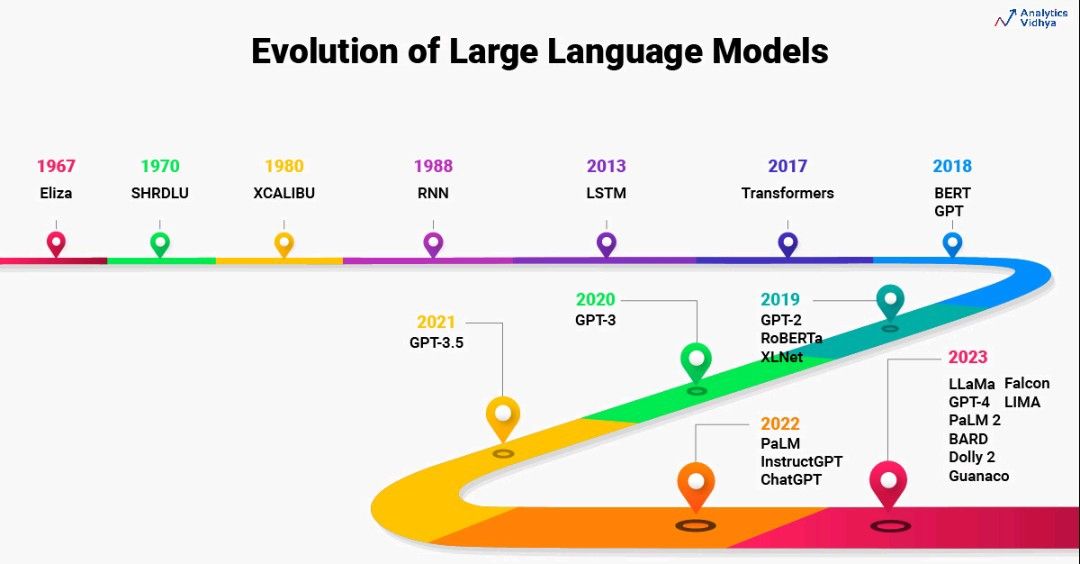
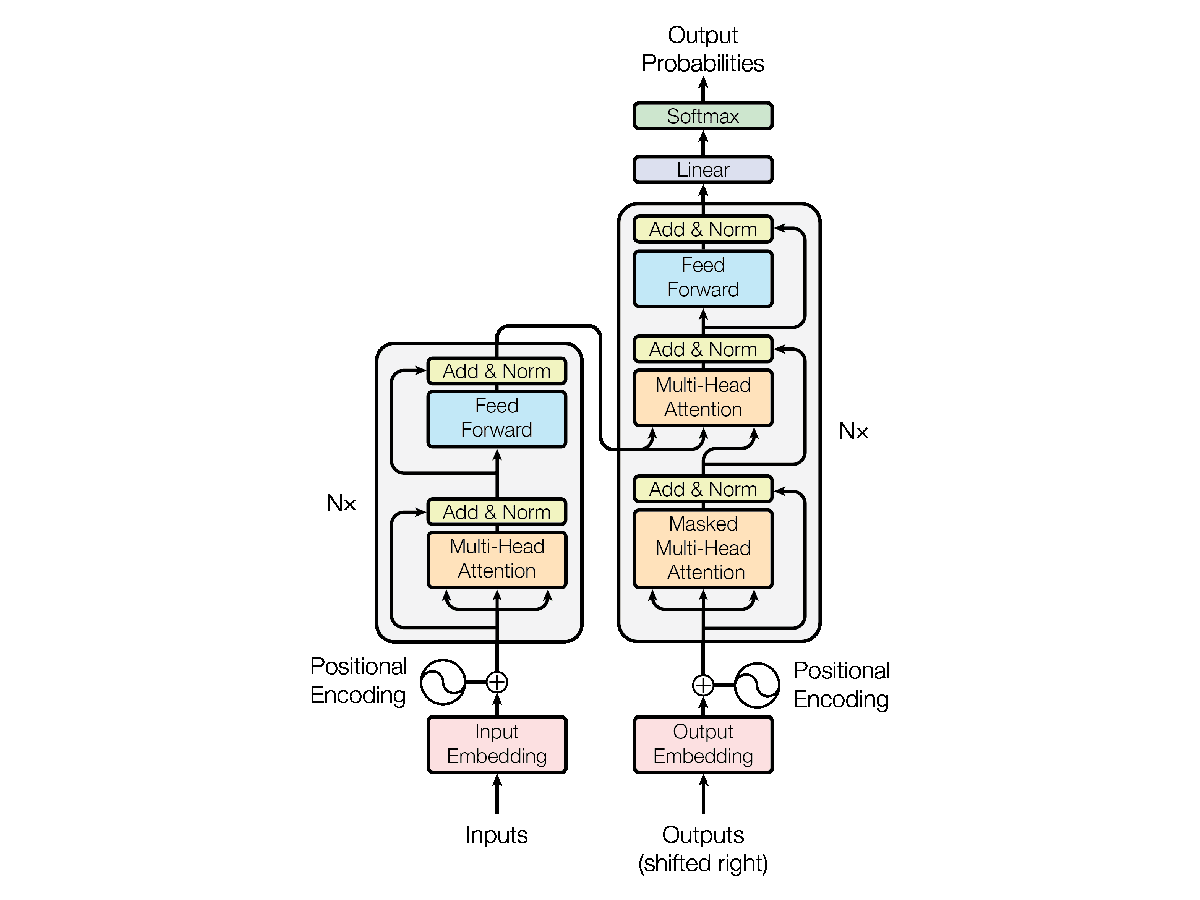
2017 yılında, NLP araştırmasında makale aracılığıyla bir atılım oldu. Dikkat İhtiyacınız Olan Her Şey. Bu makale tüm NLP manzarasında devrim yarattı. Araştırmacılar, LSTM'lerle ilgili zorlukların üstesinden gelmek için Transformers olarak bilinen yeni mimariyi tanıttı. Transformers, esasen, büyük bir hayır içeren geliştirilen ilk LLM idi. parametre sayısı. Transformers, LLM'ler için son teknoloji modeller olarak ortaya çıktı. Bugün bile, LLM'nin gelişimi transformatörlerden etkilenmeye devam ediyor.
Önümüzdeki beş yıl boyunca, transformatörlere kıyasla daha iyi LLM'ler oluşturmaya odaklanan önemli araştırmalar yapıldı. LLM'nin boyutu zaman içinde katlanarak arttı. Deneyler, LLM'lerin ve veri kümelerinin boyutunu artırmanın LLM'ler hakkındaki bilgileri geliştirdiğini kanıtladı. Bu nedenle, BERT, GPT gibi LLM'ler ve bunların GPT-2, GPT-3, GPT 3.5 ve XLNet gibi varyantları, parametrelerin ve eğitim veri kümelerinin boyutunda bir artışla tanıtıldı.
2022'de NLP'de başka bir atılım daha oldu, ChatGPT. ChatGPT, istediğiniz her şeyi yanıtlayabilen, diyalog için optimize edilmiş bir LLM'dir. Birkaç ay içinde Google, BARD'ı ChatGPT'ye rakip olarak tanıttı.
Son 1 yılda yüzlerce Büyük Dil Modeli geliştirildi. Açık kaynaklı LLM'lerin listesini performans sıralamalarıyla birlikte alabilirsiniz. okuyun. Bugüne kadarki en gelişmiş LLM, Falcon 40B Instruct'tur.
Büyük Dil Modelleri nelerdir?
Basitçe şu şekilde ifade edilir: Büyük Dil Modelleri, insan dillerini anlamak için devasa veri kümeleri üzerinde eğitilmiş derin öğrenme modelleridir. Temel amacı, insan dillerini tam olarak öğrenmek ve anlamaktır. Büyük Dil Modelleri, makinelerin dilleri tıpkı bizim insanlar olarak yorumladığımız gibi yorumlamasını sağlar.
Büyük Dil Modelleri, dildeki kelimeler arasındaki kalıpları ve ilişkileri öğrenir. Örneğin dilbilgisi, kelimelerin sırası, kelime ve deyimlerin anlamı gibi dilin sözdizimsel ve anlamsal yapısını anlar. Dilin tamamını kendisi kavrama yeteneği kazanır.
Ancak dil modellerinin Büyük Dil Modellerinden tam olarak farkı nedir?
Dil modelleri ve Büyük Dil modelleri, insan dilini öğrenir ve anlar, ancak temel fark, bu modellerin geliştirilmesidir.
Dil modelleri genellikle HMM'ler veya olasılık tabanlı modeller kullanılarak geliştirilen istatistiksel modellerdir; oysa Büyük Dil Modelleri, çok büyük bir veri kümesi üzerinde eğitilmiş milyarlarca parametreye sahip derin öğrenme modelleridir.
Ama neden ilk etapta Büyük Dil Modellerine ihtiyacımız var?
Neden Büyük Dil Modelleri?
Bu sorunun cevabı basittir. LLM'ler görevden bağımsız modellerdir. Kelimenin tam anlamıyla, bu modeller herhangi bir görevi çözme yeteneğine sahiptir. Örneğin, ChatGPT bunun klasik bir örneğidir. Ne zaman ChatGPT'ye bir şey sorsanız, sizi şaşırtıyor.
Ve bu LLM'lerin bir diğer şaşırtıcı özelliği de, göreviniz için diğer önceden eğitilmiş modeller gibi modellerde gerçekten ince ayar yapmak zorunda olmamanızdır. Tek yapmanız gereken modeli istemek. İşi sizin için yapar. Bu nedenle, LLM'ler üzerinde çalıştığınız herhangi bir soruna anında çözümler sunar. Üstelik tüm sorunlarınız ve görevleriniz için tek bir model. Bu nedenle, bu modeller NLP'de Temel modeller olarak bilinir.
Farklı LLM Türleri
LLM'ler, görevlerine bağlı olarak genel olarak 2 tipte sınıflandırılabilir:
- Metnin devamı
- Diyalog optimize edildi
Metne Devam
Bu LLM'ler, giriş metnindeki bir sonraki kelime dizisini tahmin etmek için eğitilmiştir. Eldeki görevleri metne devam etmektir.
Örneğin, "How are you" metni verildiğinde, bu LLM'ler cümleyi "How are you" ile tamamlayabilir. yapmak? veya “Nasılsın? İyiyim.
Bu kategoriye giren LLM'lerin listesi Transformers, BERT, XLNet, GPT ve GPT-2, GPT-3, GPT-4 vb.
Şimdi, bu LLM'lerle ilgili sorun, cevaplamaktansa metni tamamlamada çok iyi olmasıdır. Bazen tamamlanmaktan çok cevap bekleriz.
Yukarıda tartışıldığı gibi, verilen How are you? girdi olarak, LLM metni şununla tamamlamaya çalışır: yapıyor? or İyiyim. Yanıt ikisinden biri olabilir: tamamlama veya yanıt. Bu tam olarak diyalog için optimize edilmiş LLM'lerin tanıtılmasının nedenidir.
2. Diyalog Optimize Edildi
Bu LLM'ler, tamamlamak yerine bir cevapla yanıt verir. “Nasılsın?” Girdisi verildiğinde, bu LLM'ler “İyiyim” yanıtıyla yanıt verebilir. cümleyi tamamlamak yerine
Diyalog için optimize edilmiş LLM'lerin listesi InstructGPT, ChatGPT, BARD, Falcon-40B-instruct, vs.'dir.
Şimdi, LLM'leri sıfırdan eğitmenin içerdiği zorlukları göreceğiz.
LLM Eğitiminin Zorlukları Nelerdir?
LLM'leri sıfırdan eğitmek, 2 ana faktör nedeniyle gerçekten zordur: Altyapı ve Maliyet.
Altyapı
LLM'ler, en az 1000 GB boyutunda değişen büyük bir metin külliyatında eğitilir. Bu veri kümeleri üzerinde eğitim için kullanılan modeller, milyarlarca parametre içeren çok büyüktür. Bu kadar büyük modelleri devasa metin külliyatında eğitmek için birden çok GPU'yu destekleyen bir altyapı/donanım kurmamız gerekiyor. Tek bir GPU'da GPT-3 - 175 milyar parametreli modeli eğitmek için geçen süreyi tahmin edebilir misiniz?
GPT-355'ü tek bir NVIDIA Tesla V3 GPU üzerinde eğitmek 100 yıl sürer.
Bu, tek bir GPU üzerinde LLM eğitiminin hiç mümkün olmadığını açıkça göstermektedir. Binlerce GPU ile dağıtılmış ve paralel bilgi işlem gerektirir.
Size bir fikir vermesi için, işte popüler LLM'leri eğitmek için kullanılan donanım:
- Falcon-40B, ZeRO ile birleştirilmiş bir 384D paralellik stratejisi (TP=100, PP=40, DP=3) kullanılarak 8 A4 12GB GPU üzerinde eğitildi.
- Araştırmacılar, OpenAI'nin GPT-3'ü 34 gün gibi kısa bir sürede 1,024x A100 GPU'larda eğitebileceğini hesapladı.
- PaLM (540B, Google): Toplam 6144 TPU v4 yongası kullanıldı.
Ücret
Yukarıdakilerden, LLM'leri sıfırdan eğitmek için GPU altyapısına çok ihtiyaç duyulduğu çok açık. Bu boyutta bir altyapının kurulması oldukça pahalıdır. Şirketler ve araştırma kurumları, LLM'leri sıfırdan kurmak ve eğitmek için milyonlarca dolar yatırım yapıyor.
GPT-3'ün sıfırdan eğitilmesinin yaklaşık 4.6 milyon dolara mal olduğu tahmin ediliyor.
Ortalama olarak, 7B parametre modelinin sıfırdan eğitilmesi kabaca 25000$'a mal olur.
Şimdi, LLM'leri sıfırdan nasıl eğiteceğimizi göreceğiz.
LLM'leri Sıfırdan Nasıl Eğitirsiniz?
LLM'lerin eğitim süreci, ister metin ister diyalog optimize edilmiş olsun, oluşturmak istediğiniz LLM türü için farklıdır. LLM'lerin performansı temel olarak 2 faktöre bağlıdır: Veri Kümesi ve Model Mimarisi. Bu ikisi, LLM'lerin performansının arkasındaki temel itici faktörlerdir.
Şimdi LLM'lerin eğitiminde yer alan farklı adımları tartışalım.
1. Metne Devam
Metni devam ettiren LLM'lerin eğitim süreci, ön eğitim LLM'leri olarak bilinir. Bu LLM'ler, metindeki bir sonraki kelimeyi tahmin etmek için kendi kendini denetleyen öğrenme konusunda eğitilirler. LLM'leri sıfırdan eğitmekle ilgili farklı adımları tam olarak göreceğiz.
A. Veri Kümesi Koleksiyonu
LLM'leri eğitmenin ilk adımı, büyük bir metin verisi külliyatı toplamaktır. Veri seti, LLM'lerin performansında en önemli rolü oynar. Son zamanlarda OpenChat, LLaMA-13B'den ilham alan en son diyalog için optimize edilmiş büyük dil modelidir. Vicuna GPT-105.7 değerlendirmesinde ChatGPT puanının %4'sine ulaşır. Başarısının ardındaki sebebi biliyor musunuz? Yüksek kaliteli verilerdir. Yalnızca ~6K veri üzerinde ince ayar yapılmıştır.
Eğitim verileri internet, web siteleri, sosyal medya platformları, akademik kaynaklar vb.
Son zamanlarda yapılan çalışmalar, artan eğitim veri kümesi çeşitliliğinin, genel etki alanları arası bilgiyi ve büyük ölçekli dil modelleri için akış aşağı genelleme yeteneğini geliştirdiğini göstermiştir.
Ne diyor? Açıklamama izin ver.
"ChatGPT, JEE'de başarısız oldu" veya "ChatGPT, UPSC'yi temizleyemedi" gibi başlıklarla karşılaşmış olabilirsiniz. Olası nedenler neler olabilir? Bunun nedeni, gerekli zeka seviyesinden yoksun olmasıdır. Bu, büyük ölçüde eğitim için kullanılan veri kümesine bağlıdır. Bu nedenle, yüksek kaliteli etki alanları arası veri kümesi, farklı görevler genelinde model genelleştirme üzerinde doğrudan bir etkiye sahip olduğundan, çeşitli veri kümelerine olan talep artmaya devam ediyor.
Yüksek kaliteli verilerle LLM'lerin potansiyelini ortaya çıkarın!
Daha önce Common Crawl, LLM'leri eğitmek için başvurulacak veri kümesiydi. Common Crawl, ham web sayfası verilerini, çıkarılan meta verileri ve 2008'den beri çıkarılan metinleri içerir. Veri kümesinin boyutu petabayt cinsindendir (1 petabayt=1e6 GB). Bu veri kümesi üzerinde eğitilen Büyük Dil Modellerinin etkili sonuçlar gösterdiği, ancak diğer görevler arasında genelleştirmede başarısız olduğu kanıtlanmıştır. Bu nedenle, adı verilen yeni bir veri kümesi İstif 22 farklı yüksek kaliteli veri setinden oluşturulmuştur. 825 GB aralığında mevcut veri kaynaklarının ve yeni veri kümelerinin birleşimidir. Son zamanlarda, ortak taramanın rafine edilmiş versiyonu şu adla piyasaya sürüldü: Rafine Web Veri Kümesi. GPT-3 ve GPT-4 için kullanılan veri kümeleri, diğerlerine göre rekabet avantajı sağlamak için açık kaynaklı değildir.
B. Veri Kümesi Ön İşlemeg
Bir sonraki adım, veri kümesini önceden işlemek ve temizlemektir. Veri kümesi birden çok web sayfasından ve farklı kaynaklardan tarandığından, genellikle veri kümesi çeşitli nüanslar içerebilir. Bu nüansları ortadan kaldırmalı ve model eğitimi için yüksek kaliteli bir veri seti hazırlamalıyız.
Belirli ön işleme adımları aslında üzerinde çalıştığınız veri kümesine bağlıdır. Yaygın ön işleme adımlarından bazıları HTML Kodunu kaldırmayı, yazım hatalarını düzeltmeyi, toksik/yanlı verileri ortadan kaldırmayı, emojiyi metin eşdeğerine dönüştürmeyi ve veri tekilleştirmeyi içerir. Veri tekilleştirme, LLM'leri eğitirken en önemli ön işleme adımlarından biridir. Veri tekilleştirme, yinelenen içeriği eğitim topluluğundan kaldırma sürecini ifade eder.
Çeşitli veri kaynaklarından derlendiği için eğitim verilerinin birbirinin aynısı veya hemen hemen aynı cümleleri içerebileceği açıktır. Veri tekilleştirmeye 2 temel nedenden dolayı ihtiyacımız var: Modelin aynı verileri tekrar tekrar ezberlememesine yardımcı olur. Eğitim ve test verileri tekrarlanmayan bilgiler içerdiğinden LLM'leri daha iyi değerlendirmemize yardımcı olur. Mükerrer bilgiler içeriyorsa, eğitim setinde gördüğü bilgilerin test seti sırasında çıktı olarak verilme olasılığı çok yüksektir. Sonuç olarak, bildirilen rakamlar doğru olmayabilir. Veri tekilleştirme teknikleri hakkında daha fazla bilgi edinebilirsiniz okuyun.
C. Veri Kümesi Hazırlama
Bir sonraki adım, modeli eğitmek için girdi ve çıktı çiftlerini oluşturmaktır. Ön eğitim aşamasında, LLM'ler metindeki bir sonraki belirteci tahmin etmek için eğitilir. Dolayısıyla, giriş ve çıkış çiftleri buna göre oluşturulur.
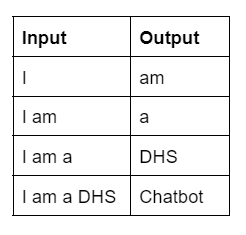
Örneğin, basit bir korpus-
- Örnek 1: Ben bir DHS Chatbot'um.
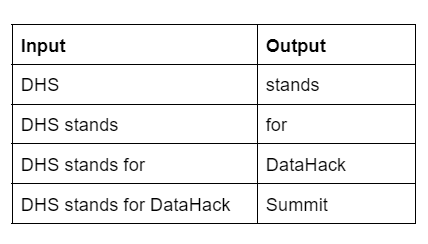
- Örnek 2: DHS, DataHack Zirvesi anlamına gelir.
- Örnek 3: Size DHS hakkında bilgi verebilirim
Örnek 1 durumunda, giriş-çıkış çiftlerini aşağıdaki gibi oluşturabiliriz.
Benzer şekilde, örnek 2 durumunda, aşağıda giriş ve çıkış çiftlerinin bir listesi bulunmaktadır.
Her giriş ve çıkış çifti, eğitim için modele aktarılır. Şimdi sırada ne var? Model mimarisini tanımlayalım.
D. Model Mimarisi
Bir sonraki adım, model mimarisini tanımlamak ve LLM'yi eğitmektir.
Bugün itibariyle çok büyük bir hayır var. geliştirilmekte olan LLM'lerin sayısı. Farklı LLM'lere genel bir bakış elde edebilirsiniz. okuyun. LLM'leri oluştururken araştırmacılar tarafından takip edilen standart bir süreç vardır. Araştırmacıların çoğu, modelin gerçek hiperparametreleriyle birlikte GPT-3 gibi mevcut bir Büyük Dil Modeli mimarisiyle başlar. Ardından, son teknoloji ürünü bir model mimarisi elde etmek için model mimarisini ve hiperparametreleri değiştirin.
Örneğin,
- Falcon, son teknoloji bir LLM'dir. Açık kaynaklı LLM liderlik tablosunda ilk sırada yer alır. Falcon, birkaç ince ayar ile GPT-3 mimarisinden esinlenmiştir.
e. Hiperparametre Arama
Hiperparametre ayarı zaman ve maliyet açısından da oldukça pahalı bir işlemdir. Milyar parametreli model için bu deneyi yaptığınızı hayal edin. Mümkün değil değil mi? Bu nedenle, ideal yöntem, mevcut araştırma çalışmasının hiperparametrelerini kullanmaktır; örneğin, karşılık gelen mimariyle çalışırken GPT-3'ün hiperparametrelerini kullanın ve ardından küçük ölçekte en uygun hiperparametreleri bulun ve ardından bunları son model.
Deneyler şunlardan herhangi birini veya tümünü içerebilir: ağırlık başlatma, konumsal yerleştirmeler, optimize edici, aktivasyon, öğrenme hızı, ağırlık azalması, kayıp fonksiyonu, dizi uzunluğu, katman sayısı, dikkat başlığı sayısı, parametre sayısı, yoğun ve seyrek katmanlar, parti boyutu ve bırakma.
Şimdi popüler hiperparametreler için en iyi uygulamaları tartışalım.
- Parti boyutu: İdeal olarak, GPU belleğine uyan büyük parti boyutunu seçin.
- Öğrenme Hızı Planlayıcısı: Bunu yapmanın en iyi yolu, eğitim ilerledikçe öğrenme oranını azaltmaktır. Bu, yerel minimumların üstesinden gelecek ve model kararlılığını artıracaktır. Yaygın olarak kullanılan Öğrenme Hızı Planlayıcılarından bazıları, Adım Azalması ve Üstel Azalma'dır.
- Ağırlık Başlatma: Model yakınsaması büyük ölçüde eğitimden önce başlatılan ağırlıklara bağlıdır. Uygun ağırlıkların başlatılması daha hızlı yakınsama sağlar. Transformatörler için yaygın olarak kullanılan ağırlık başlatma, T-Fixup'tır.
- Düzenlileştirme: LLM'lerin fazla uydurmaya eğilimli olduğu kanıtlanmıştır. Bu nedenle, toplu normalleştirme, bırakma, l1/l2 düzenlemesinin kullanılması modelin aşırı uydurmanın üstesinden gelmesine yardımcı olacak teknikleri kullanmak gereklidir.
2. Diyalog için optimize edilmiş LLM'ler
Diyalog için optimize edilmiş LLM'lerde ilk adım, yukarıda tartışılan ön eğitim LLM'leriyle aynıdır. Ön eğitimden sonra, bu LLM'ler artık metni tamamlama yeteneğine sahiptir. Şimdi, belirli bir soruya bir yanıt oluşturmak için LLM, soru ve yanıtları içeren denetimli bir veri kümesi üzerinde ince ayara tabi tutulmuştur. Bu adımın sonunda, modeliniz artık bir soruya cevap üretebilir.
ChatGPT, diyalog için optimize edilmiş bir LLM'dir. ChatGPT'nin eğitim yöntemi, yukarıda açıklanan adımlara benzer. Ön eğitim ve denetimli ince ayar dışında RLHF olarak bilinen ek bir adım içermesi yeterlidir.
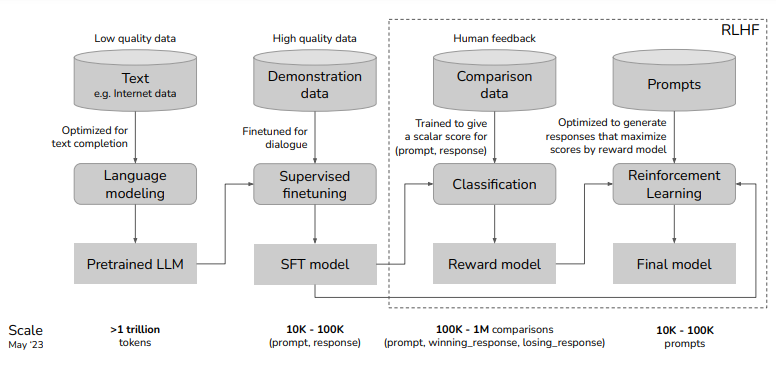
Ancak son zamanlarda, diye bilinen bir gazete çıktı. LIMA: Daha Az, Daha Fazla Hizalama içindir. İlk etapta RLHF'ye hiç ihtiyacınız olmadığını ortaya koyuyor. İhtiyacınız olan tek şey, büyük miktarda veri kümesi üzerinde ön eğitim ve 1000 veriden daha az yüksek kaliteli bir veri üzerinde denetimli ince ayar yapmaktır.
Bugün itibariyle OpenChat, LLaMA-13B'den ilham alan en son diyalog için optimize edilmiş büyük dil modelidir. Vicuna GPT-105.7 değerlendirmesinde ChatGPT puanının %4'sine ulaşır. Yalnızca 6k yüksek kaliteli veriler üzerinde ince ayar yapılmıştır.
LLM'leri Nasıl Değerlendiriyorsunuz?
LLM'lerin değerlendirilmesi öznel olamaz. LLM'lerin performansını değerlendirmek mantıklı bir süreç olmalıdır.
Sınıflandırma veya regresyon problemlerinde, gerçek etiketlere ve tahmin edilen etiketlere sahibiz ve ardından modelin ne kadar iyi performans gösterdiğini anlamak için ikisini de karşılaştırırız. Bunun için karışıklık matrisine bakıyoruz değil mi? Peki ya büyük dil modelleri? Sadece metni oluştururlar.
LLM'leri değerlendirmenin 2 yolu vardır: İçsel ve dışsal yöntemler.
İçsel Yöntemler
Geleneksel Dil modelleri, şaşkınlık, karakter başına bit sayısı vb. içsel yöntemler kullanılarak değerlendirilmiştir. Bu ölçümler, dil cephesindeki performansı, yani modelin bir sonraki kelimeyi ne kadar iyi tahmin edebildiğini izler.
Dış Yöntemler
Günümüzde LLM'lerdeki gelişmelerle birlikte, performanslarını değerlendirmek için dışsal yöntemler tercih edilmektedir. LLM'leri değerlendirmenin önerilen yolu, problem çözme, muhakeme, matematik, bilgisayar bilimi ve MIT, JEE gibi rekabetçi sınavlar gibi farklı görevlerde ne kadar iyi performans gösterdiklerine bakmaktır.
EleutherAI adlı bir çerçeve yayınladı Dil Modeli Değerlendirme Donanımı LLM'lerin performansını karşılaştırmak ve değerlendirmek. Hugging face, topluluk tarafından geliştirilen açık kaynaklı LLM'leri değerlendirmek için değerlendirme çerçevesini entegre etti.
Önerilen çerçeve, LLM'leri 4 farklı veri kümesinde değerlendirir. Nihai puan, her bir veri kümesinden alınan puanların toplamıdır.
- AI2 Reasoning Challenge: İlkokul öğrencileri için tasarlanmış bir bilim soruları koleksiyonu.
- HellaSwag: Son teknoloji modelleri, insanlar için nispeten kolay olan sağduyulu çıkarımlar yapmaya zorlayan bir test (yaklaşık %95 doğruluk).
- MMLU: Bir metin modelinin çoklu görev doğruluğunu değerlendiren kapsamlı bir test. Temel matematik, ABD tarihi, bilgisayar bilimi, hukuk ve daha fazlasını kapsayan 57 farklı görev içerir.
- TruthfulQA: Bir modelin doğru yanıtlar üretme ve çevrimiçi olarak yaygın olarak bulunan yanlış bilgileri yeniden üretmekten kaçınma eğilimini değerlendirmek için özel olarak oluşturulmuş bir test.
Ayrıca Oku: Büyük Dil Modelleri (LLM) Üzerine 10 Heyecan Verici Proje
Son Notlar
Umarım artık kendi büyük dil modellerinizi oluşturmaya hazırsınızdır!
Düşüncesi olan var mı? Aşağıda yorum yapın.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. Otomotiv / EV'ler, karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- Blok Ofsetleri. Çevre Dengeleme Sahipliğini Modernleştirme. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/07/build-your-own-large-language-models/

