Giriş
Üretken yapay zeka şu anda tüm dünyada yaygın olarak kullanılıyor. Büyük Dil Modellerinin sağlanan metni anlama ve buna dayalı bir metin oluşturma yeteneği, Chatbot'lardan Metin analizörlerine kadar çok sayıda uygulamaya yol açmıştır. Ancak çoğu zaman bu Büyük Dil Modelleri, metni olduğu gibi, yapılandırılmamış bir şekilde üretir. Bazen LLM'ler tarafından oluşturulan çıktının bir yapı formatında, örneğin bir JSON (JavaScript Object Notation) formatında olmasını isteriz. Diyelim ki bir sosyal medya gönderisini kullanarak analiz ediyoruz. Yüksek Lisansve başka bir görevi gerçekleştirmek için LLM tarafından kodun kendisinde JSON/python değişkeni olarak oluşturulan çıktıya ihtiyacımız var. Bunu İstem Mühendisliği ile başarmak mümkündür ancak istemleri düzeltmek çok zaman alır. Bunu çözmek için LangChain, LLM'nin çıktı depolamasını yapılandırılmış bir formata dönüştürmek için üzerinde çalışılabilecek Çıkış Ayrıştırmalarını tanıttı.

Öğrenme hedefleri
- Büyük Dil Modelleri tarafından oluşturulan çıktının yorumlanması
- Pydantic ile özel Veri Yapıları oluşturma
- Bilgi İstemi Şablonlarının önemini anlamak ve LLM Çıktısını biçimlendiren bir tane oluşturmak
- LangChain ile Yüksek Lisans çıktısı için format talimatlarını nasıl oluşturacağınızı öğrenin
- JSON verilerini bir Pydantic Nesnesine nasıl ayrıştırabileceğimizi görün
Bu makale, Veri Bilimi Blogatonu.
LangChain ve Çıktı Ayrıştırma Nedir?
Dil Zinciri Kısa sürede Büyük Dil Modelleri içeren uygulamalar oluşturmanıza olanak tanıyan bir Python Kitaplığıdır. OpenAI GPT LLM'ler de dahil olmak üzere çok çeşitli modelleri destekler. Google'ın PaLM'sive hatta Hugging Face'te bulunan Falcon, Llama ve çok daha fazlası gibi açık kaynaklı modeller. LangChain ile İstemleri Büyük Dil Modellerine göre özelleştirmek çocuk oyuncağıdır ve aynı zamanda giriş ve çıkışların yerleştirmelerini saklayabilen bir vektör deposuyla birlikte gelir. Böylece herhangi bir belgeyi dakikalar içinde sorgulayabilen uygulamalar oluşturmak için birlikte çalışılabilir.
LangChain, Büyük Dil Modellerinin aracılar aracılığıyla internetten bilgilere erişmesini sağlar. Ayrıca, Büyük Dil Modelleri tarafından oluşturulan çıktıdan verileri yapılandırmamıza olanak tanıyan çıktı ayrıştırıcıları da sunar. LangChain, Liste Ayrıştırıcısı, Tarih Saat Ayrıştırıcısı, Enum Ayrıştırıcısı vb. gibi farklı Çıkış Ayrıştırıcılarıyla birlikte gelir. Bu makalede, LLM'ler tarafından oluşturulan çıktıyı JSON formatına ayrıştırmamızı sağlayan JSON ayrıştırıcısını inceleyeceğiz. Aşağıda, bir LLM çıktısının bir Pydantic Nesnesine nasıl ayrıştırıldığını ve böylece Python değişkenlerinde kullanıma hazır bir verinin nasıl oluşturulduğunu gösteren tipik bir akışı gözlemleyebiliriz.

Başlarken – Modelin Kurulumu
Bu bölümde LangChain ile model kurulumu yapacağız. Bu makale boyunca Geniş Dil Modelimiz olarak PaLM'yi kullanacağız. Ortamımız için Google Colab'ı kullanacağız. PaLM'yi başka herhangi bir Büyük Dil Modeli ile değiştirebilirsiniz. Öncelikle gerekli modülleri import ederek başlayacağız.
!pip install google-generativeai langchain- Bu, PaLM modeliyle çalışmak için LangChain kütüphanesini ve google-generativeai kütüphanesini indirecektir.
- Langchain kütüphanesi, özel istemler oluşturmak ve büyük dil modelleri tarafından oluşturulan çıktıyı ayrıştırmak için gereklidir.
- Google-generativeai kütüphanesi Google'ın PaLM modeliyle etkileşime girmemize olanak sağlayacak.
PaLM API Anahtarı
PaLM ile çalışmak için MakerSuite web sitesine kaydolarak alabileceğimiz bir API anahtarına ihtiyacımız olacak. Daha sonra gerekli tüm kütüphanelerimizi içe aktaracağız ve PaLM modelini başlatmak için API Anahtarını aktaracağız.
import os
import google.generativeai as palm
from langchain.embeddings import GooglePalmEmbeddings
from langchain.llms import GooglePalm os.environ['GOOGLE_API_KEY']= 'YOUR API KEY'
palm.configure(api_key=os.environ['GOOGLE_API_KEY']) llm = GooglePalm()
llm.temperature = 0.1 prompts = ["Name 5 planets and line about them"]
llm_result = llm._generate(prompts)
print(llm_result.generations[0][0].text)- Burada ilk olarak Google PaLM'in (Pathways Dil Modeli) bir örneğini oluşturduk ve onu değişkene atadık. lm
- Bir sonraki adımda ayarları yapıyoruz. sıcaklık Modelimizin halüsinasyon görmesini istemediğimiz için modelimizi 0.1'e ayarladık.
- Daha sonra liste halinde bir Prompt oluşturduk ve onu değişkene aktardık. istemleri
- İstemi PaLM'ye iletmek için, ._generate() yöntemini kullanın ve ardından İstem listesini ona iletin ve sonuçlar değişkende saklanır. llm_result
- Son olarak son adımda sonucu çağırarak yazdırıyoruz. .nesiller ve onu çağırarak metne dönüştürmek .Metin yöntem
Bu istemin çıktısı aşağıda görülebilir
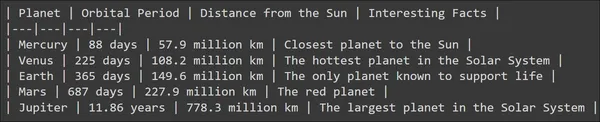
Büyük Dil Modelinin adil bir çıktı ürettiğini ve LLM'nin de bazı satırlar ekleyerek ona bir yapı eklemeye çalıştığını görebiliriz. Peki ya her modele ait bilgiyi bir değişkende saklamak istersem? Peki ya gezegenin adını, yörünge periyodunu ve güneşe olan uzaklığını, bunların hepsini ayrı ayrı bir değişkende saklamak istersem? Model tarafından oluşturulan çıktı, bunu başarmak için doğrudan çalışılamaz. Böylece Çıktı Ayrıştırmalarına ihtiyaç duyulur.
Pydantic Çıkış Ayrıştırıcısı ve Bilgi İstemi Şablonu Oluşturma
Bu bölümde langchain'den pydantic çıktı ayrıştırıcısını tartışacağız. Önceki örnekte çıktı yapılandırılmamış bir formattaydı. Büyük Dil Modeli tarafından oluşturulan bilgileri yapılandırılmış bir formatta nasıl saklayabileceğimize bakın.
Kod Uygulama
Aşağıdaki koda bakarak başlayalım:
from pydantic import BaseModel, Field, validator
from langchain.output_parsers import PydanticOutputParser class PlanetData(BaseModel): planet: str = Field(description="This is the name of the planet") orbital_period: float = Field(description="This is the orbital period in the number of earth days") distance_from_sun: float = Field(description="This is a float indicating distance from sun in million kilometers") interesting_fact: str = Field(description="This is about an interesting fact of the planet")- Burada Veri Yapısı oluşturmak için Pydantic Paketini içe aktarıyoruz. Ve bu Veri Yapısında, LLM'den gelen çıktıyı ayrıştırarak çıktıyı saklayacağız.
- Burada Pydantic'i kullanarak bir Veri Yapısı oluşturduk. Gezegen Verileri aşağıdaki verileri saklayan
- Gezegen: Modele girdi olarak vereceğimiz gezegen adıdır.
- Yörünge Dönemi: Bu, belirli bir gezegenin Dünya günleri cinsinden yörünge periyodunu içeren değişken bir değerdir.
- Güneş'e Uzaklık: Bu, bir gezegenin Güneş'e olan mesafesini gösteren bir şamandıradır
- İlginç gerçek: Bu, sorulan gezegen hakkında ilginç bir gerçeği içeren bir dizi.
Artık bir gezegen hakkında bilgi almak için Büyük Dil Modelini sorgulamayı ve tüm bu verileri LLM çıktısını ayrıştırarak PlanetData Veri Yapısında saklamayı hedefliyoruz. Bir LLM çıktısını Pydantic Veri Yapısına ayrıştırmak için LangChain, PydanticOutputParser adında bir ayrıştırıcı sunar. Bu ayrıştırıcıya aşağıdaki gibi tanımlanabilen PlanetData Sınıfını aktarıyoruz:
planet_parser = PydanticOutputParser(pydantic_object=PlanetData)Ayrıştırıcıyı adlı bir değişkende saklıyoruz. planet_parser. Ayrıştırıcı nesnesinin adı verilen bir yöntemi vardır. get_format_instructions() LLM'ye çıktının nasıl oluşturulacağını söyler. Yazdırmayı deneyelim
from pprint import pp
pp(planet_parser.get_format_instructions())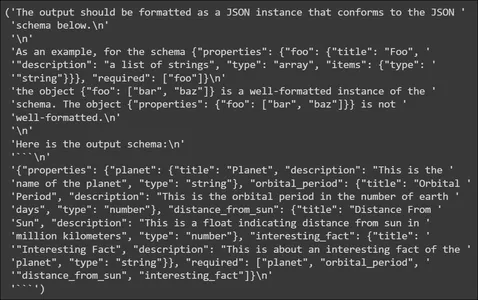
Yukarıda format talimatlarının LLM tarafından oluşturulan çıktının nasıl formatlanacağına dair bilgiler içerdiğini görüyoruz. LLM'ye verileri bir JSON şemasında çıkarmasını söyler, böylece bu JSON Pydantic Veri Yapısına ayrıştırılabilir. Ayrıca bir çıktı şeması örneği de sağlar. Daha sonra bir Bilgi İstemi Şablonu oluşturacağız.
Bilgi İstemi Şablonu
from langchain import PromptTemplate, LLMChain template_string = """You are an expert when it comes to answering questions about planets You will be given a planet name and you will output the name of the planet, it's orbital period in days Also it's distance from sun in million kilometers and an interesting fact ```{planet_name}``` {format_instructions} """ planet_prompt = PromptTemplate( template=template_string, input_variables=["planet_name"], partial_variables={"format_instructions": planet_parser
.get_format_instructions()}
)
- Bilgi İstemi Şablonumuzda, girdi olarak bir gezegen adı vereceğimizi ve LLM'nin Yörünge Periyodu, Güneş'ten Uzaklık gibi bilgileri ve gezegen hakkında ilginç bir gerçeği içeren çıktı üretmesi gerektiğini söylüyoruz.
- Daha sonra bu şablonu şuraya atadık: PrompTemplate() ve ardından giriş değişkeninin adını sağlayın girdi_değişkenleri parametre, bizim durumumuzda gezegen_adı
- Ayrıca, LLM'ye çıktının JSON formatında nasıl oluşturulacağını anlatan, daha önce gördüğümüz format içi talimatlar da veriyoruz.
Bir gezegen adı vermeyi deneyelim ve Büyük Dil Modeline gönderilmeden önce İstemin nasıl göründüğünü gözlemleyelim.
input_prompt = planet_prompt.format_prompt(planet_name='mercury')
pp(input_prompt.to_string())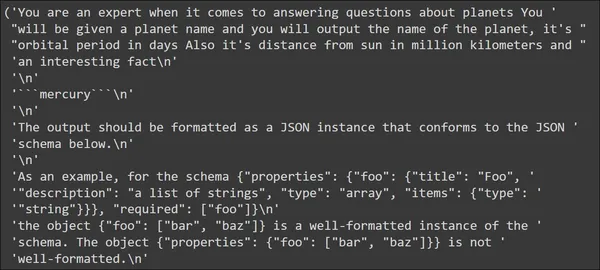
Çıktıda ilk olarak “cıva” girişi ile tanımladığımız şablonun göründüğünü görüyoruz. Bunu format talimatları takip ediyor. Bu format talimatları LLM'nin JSON verileri oluşturmak için kullanabileceği talimatları içerir.
Büyük Dil Modelini Test Etme
Bu bölümde girdimizi LLM'ye göndereceğiz ve oluşturulan verileri gözlemleyeceğiz. Önceki bölümde LLM'ye gönderildiğinde giriş dizemizin nasıl olacağına bakın.
input_prompt = planet_prompt.format_prompt(planet_name='mercury')
output = llm(input_prompt.to_string())
pp(output)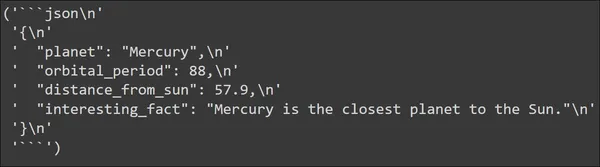
Büyük Dil Modeli tarafından oluşturulan çıktıyı görebiliriz. Çıktı aslında bir JSON formatında oluşturulur. JSON verileri, PlanetData Veri Yapımızda tanımladığımız tüm anahtarları içerir. Ve her anahtarın sahip olmasını beklediğimiz bir değeri vardır.
Şimdi bu JSON verisini yapmış olduğumuz Veri Yapısına ayrıştırmamız gerekiyor. Bu daha önce tanımladığımız PydanticOutputParser ile kolaylıkla yapılabilir. Şu koda bakalım:
parsed_output = planet_parser.parse(output)
print("Planet: ",parsed_output.planet)
print("Orbital period: ",parsed_output.orbital_period)
print("Distance From the Sun(in Million KM): ",parsed_output.distance_from_sun)
print("Interesting Fact: ",parsed_output.interesting_fact)Planet_parser için parse() yönteminin çağrılması, çıktıyı alır ve ardından ayrıştırır ve onu bir Pydantic Nesnesine, bizim durumumuzda bir PlanetData Nesnesine dönüştürür. Böylece çıktı, yani Büyük Dil Modeli tarafından oluşturulan JSON, PlannetData Veri Yapısına ayrıştırılır ve artık buradan bireysel verilere erişebiliriz. Yukarıdakilerin çıktısı şu şekilde olacaktır:

JSON verisindeki anahtar/değer çiftlerinin Pydantic Verilerine doğru bir şekilde ayrıştırıldığını görüyoruz. Başka bir gezegenle deneyelim ve çıktıyı gözlemleyelim
input_prompt = planet_prompt.format_prompt(planet_name='venus')
output = llm(input_prompt.to_string()) parsed_output = planet_parser.parse(output)
print("Planet: ",parsed_output.planet)
print("Orbital period: ",parsed_output.orbital_period)
print("Distance From the Sun: ",parsed_output.distance_from_sun)
print("Interesting Fact: ",parsed_output.interesting_fact)
“Venüs” girişi için LLM'nin çıktı olarak bir JSON oluşturabildiğini ve bunun Pydantic Data'ya başarıyla ayrıştırıldığını görüyoruz. Bu şekilde çıktı ayrıştırma yoluyla Büyük Dil Modelleri tarafından oluşturulan bilgileri doğrudan kullanabiliriz.
Potansiyel Uygulamalar ve Kullanım Durumları
Bu bölümde, bu çıktı ayrıştırma tekniklerini kullanabileceğimiz bazı potansiyel gerçek dünya uygulamalarını/kullanım durumlarını inceleyeceğiz. Çıkarmada/çıkarma sonrasında Ayrıştırma'yı kullanın, yani herhangi bir veri türünü çıkardığımızda, çıkarılan bilgilerin diğer uygulamalar tarafından tüketilebilmesi için onu ayrıştırmak istiyoruz. Uygulamalardan bazıları şunlardır:
- Ürün Şikayet Çıkarma ve Analizi: Yeni bir marka piyasaya çıktığında ve yeni ürünlerini piyasaya sürdüğünde ilk yapmak istediği şey ürünün performansını kontrol etmektir ve bunu değerlendirmenin en iyi yollarından biri de bu ürünleri kullanan tüketicilerin sosyal medya paylaşımlarını analiz etmektir. Çıktı ayrıştırıcıları ve LLM'ler, marka ve ürün adları ve hatta tüketicinin sosyal medya gönderilerinden şikayetler gibi bilgilerin çıkarılmasına olanak tanır. Bu Büyük Dil Modelleri, bu verileri çıktı ayrıştırma yoluyla Pythonic değişkenlerinde saklar ve bunları veri görselleştirmeleri için kullanmanıza olanak tanır.
- Müşteri Desteği: Müşteri desteği için LLM'lerle sohbet robotları oluştururken önemli görevlerden biri müşterinin sohbet geçmişinden bilgi çıkarmak olacaktır. Bu bilgiler tüketicilerin ürün/hizmetle ilgili ne gibi sorunlarla karşılaştığı gibi önemli detayları içerir. Bu bilgileri çıkarmak için özel kod oluşturmak yerine LangChain çıktı ayrıştırıcılarını kullanarak bu ayrıntıları kolayca çıkarabilirsiniz.
- İş İlanı Bilgileri: Indeed, LinkedIn vb. gibi iş arama platformlarını geliştirirken, iş ilanlarından iş unvanları, şirket adları, yılların deneyimi ve iş tanımları dahil olmak üzere ayrıntıları çıkarmak için LLM'leri kullanabiliriz. Çıktı ayrıştırma, bu bilgileri iş eşleştirme ve öneriler için yapılandırılmış JSON verileri olarak kaydedebilir. Bu bilginin LLM çıktısından doğrudan LangChain Çıkış Ayrıştırıcıları aracılığıyla ayrıştırılması, bu ayrı ayrıştırma işlemini gerçekleştirmek için gereken gereksiz kodun çoğunu ortadan kaldırır.
Sonuç
Büyük Dil Modelleri mükemmeldir çünkü olağanüstü metin oluşturma yetenekleri sayesinde her kullanım durumuna tam anlamıyla uyum sağlayabilirler. Ancak çoğu zaman, iş üretilen çıktıyı gerçekten kullanmaya geldiğinde yetersiz kalırlar; çıktıyı ayrıştırmak için önemli miktarda zaman harcamak zorunda kalırız. Bu makalede, bu soruna ve LangChain'in Çıkış Ayrıştırıcılarını, özellikle de LLM'den oluşturulan JSON verilerini ayrıştırıp bir Pydantic Nesnesine dönüştürebilen JSON ayrıştırıcısını kullanarak bu sorunu nasıl çözebileceğimize bir göz attık.
Önemli Noktalar
Bu makaledeki önemli çıkarımlardan bazıları şunlardır:
- LangChain, mevcut Büyük Dil Modelleri ile uygulamalar oluşturabilen bir Python Kütüphanesidir.
- LangChain, Büyük Dil Modelleri tarafından oluşturulan çıktıyı ayrıştırmamıza olanak tanıyan Çıktı Ayrıştırıcıları sağlar.
- Pydantic, LLM'lerden gelen çıktıyı ayrıştırırken kullanılabilecek özel Veri Yapıları tanımlamamıza olanak tanır.
- LangChain, Pydantic JSON ayrıştırıcısının yanı sıra Liste Ayrıştırıcısı, Tarih Saat Ayrıştırıcısı, Enum Ayrıştırıcısı vb. gibi farklı Çıkış Ayrıştırıcıları da sağlar.
Sık Sorulan Sorular
A. JavaScript Nesne Gösterimi'nin kısaltması olan JSON, yapılandırılmış verilere yönelik bir formattır. Anahtar-değer çiftleri biçiminde veriler içerir.
C. Pydantic, özel veri yapıları oluşturan ve veri doğrulama işlemini gerçekleştiren bir Python kütüphanesidir. Her veri parçasının atanan türle eşleşip eşleşmediğini doğrular, böylece sağlanan verileri doğrular.
A. Bunu Prompt Engineering ile yapın; burada Prompt üzerinde değişiklik yapmak LLM'nin çıktı olarak JSON verileri oluşturmasını sağlayabilir. Bu süreci kolaylaştırmak için LangChain'in Çıkış Ayrıştırıcıları vardır ve bu görev için kullanabilirsiniz.
A. LangChain'deki Çıkış Ayrıştırıcıları, Büyük Dil Modelleri tarafından oluşturulan çıktıyı yapılandırılmış bir şekilde biçimlendirmemize olanak tanır. Bu, diğer görevler için Büyük Dil Modellerindeki bilgilere kolayca erişmemizi sağlar.
A. LangChain, Pydantic Ayrıştırıcı, Liste Parsr, Enum Ayrıştırıcı, Datetime Ayrıştırıcı vb. gibi farklı çıktı ayrıştırıcılarıyla birlikte gelir.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/11/structured-llm-output-storage-and-parsing-in-python/

