Giriş
Vektör Veritabanları, yapılandırılmamış ve yapılandırılmış verilerin temsillerinin saklanması ve indekslenmesi için başvurulacak yer haline geldi. Bu temsiller Gömme Modelleri tarafından oluşturulan vektör yerleştirmelerdir. Vektör mağazaları, Derin Öğrenme Modelleri, özellikle Büyük Dil Modelleri ile uygulama geliştirmenin ayrılmaz bir parçası haline geldi. Sürekli gelişen Vektör Mağazaları ortamında Qdrant, yakın zamanda tanıtılan ve özelliklerle dolu bir Vektör Veritabanıdır. Hadi derinlemesine bakalım ve bu konuda daha fazlasını öğrenelim.
Öğrenme hedefleri
- Daha iyi anlamak için Qdrant terminolojilerine aşina olmak
- Qdrant Cloud'a dalma ve Kümeler oluşturma
- Belgelerimizin yerleştirmelerini oluşturmayı ve bunları Qdrant Koleksiyonlarında saklamayı öğrenme
- Qdrant'ta sorgulamanın nasıl çalıştığını keşfetme
- Nasıl çalıştığını kontrol etmek için Qdrant'taki Filtrelemeyle ilgili düzeltmeler yapmak
Bu makale, Veri Bilimi Blogatonu.
İçindekiler
Gömmeler nedir?
Vektör Gömmeleri, veri türü ne olursa olsun (metin, fotoğraf, ses, video vb.) verileri sayısal biçimde (yani n boyutlu uzayda sayılar olarak veya sayısal bir vektör olarak) ifade etmenin bir yoludur. Gömmeler bize şunları sağlar: ilgili verileri bu şekilde gruplandırmak. Belirli girdiler belirli modeller kullanılarak vektörlere dönüştürülebilir. Google tarafından oluşturulan ve kelimeleri vektörlere (vektörler n boyutlu noktalardır) çeviren iyi bilinen bir yerleştirme modeline Word2Vec adı verilir. Büyük Dil Modellerinin her biri, ilgili dil için bir yerleştirme oluşturan bir yerleştirme modeline sahiptir. Yüksek Lisans.
Gömmeler ne için kullanılır?
Kelimeleri vektörlere çevirmenin bir avantajı karşılaştırmaya izin vermesidir. Sayısal girdi veya vektör eklemeleri olarak iki kelime verildiğinde, bilgisayar bunları doğrudan karşılaştıramasa bile bunları karşılaştırabilir. Benzer yerleşimlere sahip kelimeleri bir arada gruplamak mümkündür. Birbirleriyle ilişkili oldukları için Kral, Kraliçe, Prens ve Prenses terimleri bir kümede görünecektir.
Bu anlamda gömmeler, belirli bir terimle ilgili kelimeleri bulmamıza yardımcı olur. Bu, bir cümle girdiğimizde cümlelerde kullanılabilir ve sağlanan veriler ilgili cümleleri döndürür. Bu, sohbet robotları, cümle benzerliği, anormallik tespiti ve anlamsal arama dahil olmak üzere çok sayıda kullanım senaryosunun temelini oluşturur. Sunduğumuz bir PDF veya belgeye dayalı olarak soruları yanıtlamak için geliştirdiğimiz Chatbot'lar bu yerleştirme kavramından yararlanıyor. Bu yöntem, tüm Üretken Büyük Dil Modelleri tarafından, kendilerine sağlanan sorgulara benzer şekilde bağlanan içeriği elde etmek için kullanılır.
Vektör Veritabanları Nedir?
Tartışıldığı gibi, gömmeler genellikle herhangi bir veri türünün temsilidir, yapılandırılmamış olanlar n-boyutlu bir uzayda sayısal formattadır. Şimdi onları nerede saklayacağız? Geleneksel RDMS (İlişkisel Veritabanı Yönetim Sistemleri), bu vektör yerleştirmelerini depolamak için kullanılamaz. Vektör Mağazası / Vektör Veritabanlarının devreye girdiği yer burasıdır. Vektör Veritabanları, vektör yerleştirmelerini verimli bir şekilde depolamak ve almak için tasarlanmıştır. Destekledikleri katıştırma modellerine ve benzer vektörleri elde etmek için kullandıkları arama algoritmasına göre farklılık gösteren birçok Vektör Mağazası vardır.
Qdrant nedir?
Qdrant, güvenliğiyle bilinen Rust dilinde yerleşik, üretime hazır bir hizmet sağlayan yeni Vektör Benzerlik Arama Motoru ve bir Vector Veritabanıdır. Qdrant, yük adı verilen meta verilerle zenginleştirilmiş yüksek boyutlu Noktaları (Puanlar Vektör Yerleştirmelerinden başka bir şey değildir) depolamak, aramak ve yönetmek için tasarlanmış kullanıcı dostu bir API ile birlikte gelir. Bu veriler değerli bilgi parçaları haline gelir, arama hassasiyetini artırır ve kullanıcılara anlamlı veriler sağlar. Chroma gibi diğer Vektör Veritabanlarına aşina iseniz, Payload meta verilere benzer, vektörler hakkında bilgi içerir.
Rust'ta yazılması, Qdrant'ı ağır yükler altında bile hızlı ve güvenilir bir Vectore Mağazası haline getirir. Qdrant'ı diğer veritabanlarından ayıran şey, sağladığı istemci API'lerinin sayısıdır. Şu anda Qdrant Python, TypeSciprt/JavaScript, Rust ve Go'yu desteklemektedir. Birlikte gelir. Qdrant, Vektör indeksleme için HSNW (Hiyerarşik Gezinilebilir Küçük Dünya Grafiği) kullanır ve Kosinüs, Nokta ve Öklid gibi birçok mesafe ölçümüyle birlikte gelir. Kutudan çıktığı gibi bir öneri API'si ile birlikte gelir.
Qdrant Terminolojisini öğrenin
Qdrant'a sorunsuz bir başlangıç yapmak için, Qdrant Vektör Veritabanında kullanılan terminolojiye/ana Bileşenlere aşina olmak iyi bir uygulamadır.
Koleksiyonlar
Koleksiyonlar, her Noktanın bir vektör ve isteğe bağlı bir kimlik ve yük içerdiği Nokta kümeleri olarak adlandırılır. Aynı Koleksiyondaki Vektörler aynı boyutu paylaşmalı ve seçilen tek bir Metrik ile Değerlendirilmelidir.
Mesafe Metrikleri
Vektörlerin birbirine ne kadar yakın olduğunu ölçmek için gerekli olan uzaklık metrikleri Koleksiyon oluşturulurken seçilir. Qdrant şu Uzaklık Metriklerini sağlar: Nokta, Kosinüs ve Öklid.
Puanlar
Qdrant'taki temel varlık, noktalar bir vektör yerleştirmeden, isteğe bağlı bir kimlikten ve ilişkili bir yükten oluşur;
id: Her vektör yerleştirme için benzersiz bir tanımlayıcı
vektör: Görüntüler, metinler, belgeler, PDF'ler, videolar, ses vb. gibi yapılandırılmış veya yapılandırılmamış formatlarda olabilen verilerin yüksek boyutlu temsili.
yük: Bir vektörle ilişkili verileri içeren isteğe bağlı bir JSON nesnesi. Bu, meta verilere benzer olarak düşünülebilir ve arama sürecini filtrelemek için bununla çalışabiliriz.
Depolama
Qdrant iki depolama seçeneği sunar:
- Bellek İçi Depolama: Tüm vektörleri RAM'de saklar, kalıcılık görevlerine disk erişimini en aza indirerek hızı optimize eder.
- Memmap Depolama: Hız ve kalıcılık gereksinimlerini dengeleyerek diskteki bir dosyaya bağlı bir sanal adres alanı oluşturur.
Qdrant'ı hızlı bir şekilde kullanmaya başlayabilmemiz için bilmemiz gereken ana kavramlar bunlar
Qdrant Cloud – İlk Kümemizi Oluşturma
Qdrant, vektörlerin depolanması ve yönetilmesi için ölçeklenebilir bir bulut hizmeti sağlar. Hatta kredi kartı bilgisi içermeyen, sonsuza kadar ücretsiz 1 GB'lık bir Küme sağlar. Bu bölümde Qdrant Cloud ile Hesap oluşturma ve ilk Cluster'ımızı oluşturma sürecini ele alacağız.
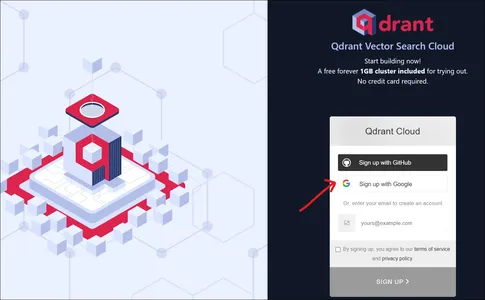
Qdrant web sitesine gittiğimizde yukarıdaki gibi bir açılış sayfasıyla karşılaşacağız. Qdrant'a Google Hesabı veya GitHub Hesabı ile kayıt olabiliriz.
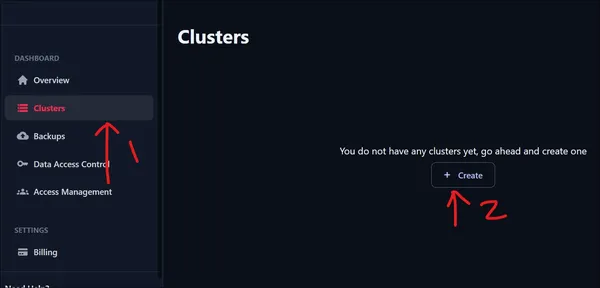
Giriş yaptıktan sonra, yukarıda gösterilen kullanıcı arayüzü ile karşılaşacağız. Bir Küme oluşturmak için sol bölmeye gidin ve Kontrol Paneli altındaki Kümeler seçeneğine tıklayın. Yeni oturum açtığımız için sıfır kümemiz var. Yeni bir Küme oluşturmak için Küme Oluştur'a tıklayın.
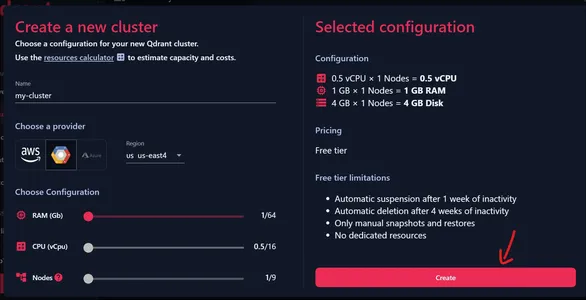
Artık Cluster’ımıza bir isim verebiliriz. Tüm Yapılandırmaların başlangıç konumuna ayarlandığından emin olun, çünkü bu bize ücretsiz bir Küme kazandırır. Yukarıda gösterilen sağlayıcılardan birini seçip onunla ilişkili bölgelerden birini seçebiliriz.
Mevcut Yapılandırmayı Kontrol Edin
Sol tarafta mevcut Yapılandırmayı, yani 0.5 vCPU, 1 GB RAM ve 4 GB Disk Depolamayı görebiliriz. Kümemizi oluşturmak için Oluştur'a tıklayın.
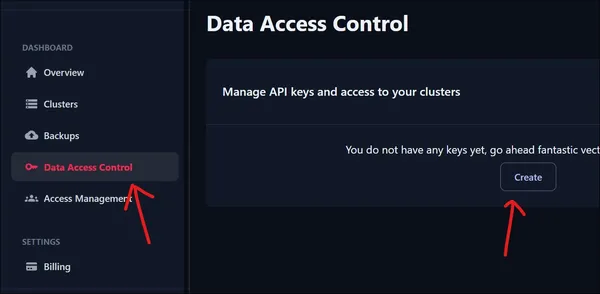
Yeni oluşturulan Kümemize erişmek için bir API Anahtarına ihtiyacımız var. Yeni bir API anahtarı oluşturmak için Kontrol Paneli altındaki Veri Erişim Kontrolü'ne gidin. Yeni bir API anahtarı oluşturmak için Oluştur Düğmesine tıklayın.

Yukarıda gösterildiği gibi, API'yi oluşturmak için ihtiyacımız olan Kümeyi seçeceğimiz bir açılır menü sunulacak. Elimizde tek bir Cluster olduğu için onu seçip OK butonuna tıklıyoruz.
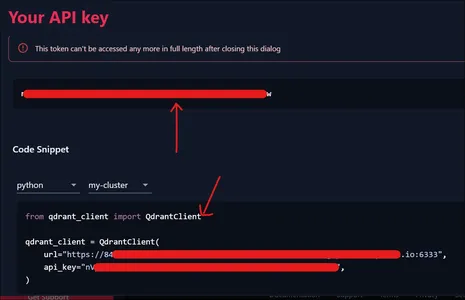
Daha sonra size yukarıda gösterilen API Token sunulacaktır. Ayrıca görüntünün aşağıdaki kısmını görürsek, bir sonraki bölümde kullanacağımız Cluster'ımıza bağlanmak için kod pasajı bile bize verilmektedir.
Qdrant – Uygulamalı
Bu bölümde Qdrant Vector Database ile çalışacağız. Öncelikle gerekli kütüphaneleri import ederek başlayacağız.
!pip install sentence-transformers
!pip install qdrant_clientİlk satır cümle dönüştürücü Python kütüphanesini kurar. Cümle dönüştürücü kitaplığı cümle, metin ve görüntü yerleştirmeleri oluşturmak için kullanılır. Gömme oluşturmak amacıyla farklı gömme modellerini içe aktarmak için bu kütüphaneyi kullanabiliriz. Sonraki ifade Python için qdrant istemcisini yükler. Clientimizi oluşturarak başlayalım.
from qdrant_client import QdrantClient
client = QdrantClient(
url="YOUR CLUSTER URL",
api_key="YOUR API KEY",
)
Qdrant İstemcisi
Yukarıdaki şekilde somutlaştırıyoruz müşteri içe aktararak Qdrant İstemcisi sınıf ve Küme URL'sini ve API Anahtarı bir süre önce oluşturduğumuz şey. Daha sonra gömme modelimizi getireceğiz.
# bringing in our embedding model
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')Yukarıdaki kodda şunu kullandık: CümleTransformer sınıf ve bir model başlattı. Aldığımız yerleştirme modeli tüm-mpnet-base-v2. Bu, oldukça popüler bir genel amaçlı vektör yerleştirme modelidir. Bu model metni alacak ve çıktısını alacaktır. 768-boyutlu vektör. Verilerimizi tanımlayalım.
# data
documents = [
"""Elephants, the largest land mammals, exhibit remarkable intelligence and
social bonds, relying on their powerful trunks for communication and various
tasks like lifting objects and gathering food.""",
""" Penguins, flightless birds adapted to life in the water, showcase strong
social structures and exceptional parenting skills. Their sleek bodies
enable efficient swimming, and they endure
harsh Antarctic conditions in tightly-knit colonies. """,
"""Cars, versatile modes of transportation, come in various shapes and
sizes, from compact city cars to powerful sports vehicles, offering a
range of features for different preferences and needs.""",
"""Motorbikes, nimble two-wheeled machines, provide a thrilling and
liberating riding experience, appealing to enthusiasts who appreciate
speed, agility, and the open road.""",
"""Tigers, majestic big cats, are solitary hunters with distinctive
striped fur. Their powerful build and stealthy movements make them
formidable predators, but their populations are threatened
due to habitat loss and poaching."""
]
Yukarıda, document adında bir değişkenimiz var ve bu değişken 5 stringlik bir liste içeriyor (her birini tek bir document gibi ele alalım). Her veri dizisi belirli bir konuyla ilgilidir. Bazı veriler elementlerle, bazıları ise otomobillerle ilgilidir. Veriler için yerleştirmeler oluşturalım.
# embedding the data
embeddings = model.encode(documents)
print(embeddings.shape)Biz kullanın kodlamak() Verilerimizi kodlamak için model nesnesinin işlevi. Kodlamak için doküman listesini doğrudan kodlamak() sonuçta ortaya çıkan vektör yerleştirmelerini işlev ve yerleştirme değişkeninde saklayın. Burada yazdırılacak olan gömmelerin şeklini bile yazdırıyoruz (5, 768). Bunun nedeni 5 Veri Noktamız yani 5 belgemiz olması ve her belge için 768 Boyutun vektör gömmesinin oluşturulmasıdır.
Koleksiyonunuzu oluşturun
Şimdi Koleksiyonumuzu oluşturacağız.
from qdrant_client.http.models import VectorParams, Distance
client.create_collection(
collection_name = "my-collection",
vectors_config = VectorParams(size=768,distance=Distance.COSINE)
)
- Bir Koleksiyon oluşturmak için istemci nesnesinin create_collection() işleviyle çalışırız ve "Koleksiyon_adı“Koleksiyonumuzun adını yani “koleksiyonum”u geçiyoruz
- Vektör Paramları: Bu sınıftan qdrant vektör konfigürasyonu içindir, örneğin vektör yerleştirme boyutu nedir, mesafe ölçüsü nedir ve benzeri
- Mesafe: Bu sınıftan qdrant vektörleri sorgulamak için hangi mesafe ölçümünün kullanılacağını tanımlamak içindir
- Şimdi vektör_yapılandırması Yapılandırmamızı ilettiğimiz değişken, yani vektör yerleştirmelerin boyutu 786ve kullanmak istediğimiz mesafe ölçümü KOSİNÜS
Vektör Gömmeleri Ekle
Artık Koleksiyonumuzu başarıyla oluşturduk. Şimdi vektör yerleştirmelerimizi bu Koleksiyona ekleyeceğiz.
from qdrant_client.http.models import Batch
client.upsert (
collection_name = "my-collection",
points = Batch(
ids = [1,2,3,4,5],
payloads= [
{"category":"animals"},
{"category":"animals"},
{"category":"automobiles"},
{"category":"automobiles"},
{"category":"animals"}
],
vectors = embeddings.tolist()
)
)
- Qdrant'a veri eklemek için şunu çağırırız: yukarı() yöntemini seçin ve Koleksiyon adını ve Puanlarını girin. Yukarıda öğrendiğimiz gibi, bir Nokta vektörlerden, isteğe bağlı bir indeksten ve yüklerden oluşur. Yığın Qdrant'ın sınıfı, verileri tek tek eklemek yerine toplu olarak eklememize olanak tanır.
- kimlikleri: Belgelerimize ID veriyoruz. Şu anda listemizde 1 adet belgemiz olduğu için 5'den 5'e kadar bir değer veriyoruz.
- yükleri: Daha önce de gördüğümüz gibi yük gibi vektörler hakkında bilgi içerir meta. Bunu anahtar/değer çiftleri halinde sağlıyoruz. Sağladığımız her belge için yük burada her belgeye kategori bilgisini atamaktayız.
- vektörler: Bunlar belgelerin vektör yerleştirmeleridir. Numpy dizisinden listeye dönüştürüyoruz ve besliyoruz.
Böylece, bu kodu çalıştırdıktan sonra vektör yerleştirmeleri Koleksiyona eklenir. Eklenip eklenmediklerini kontrol etmek için Qdrant Cloud'un sağladığı bulut kontrol panelini ziyaret edebiliriz. Bunun için aşağıdakileri yapıyoruz:
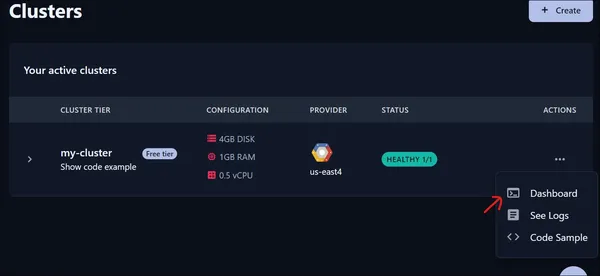
Kontrol paneline tıklıyoruz ve ardından yeni bir sayfa açılıyor.
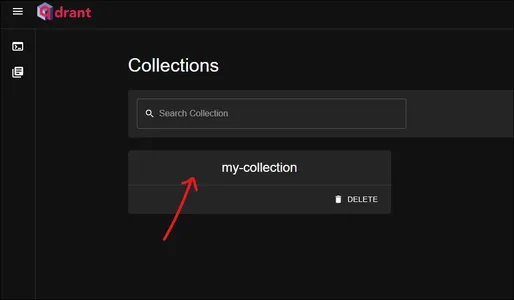
Bu qdrant kontrol panelidir. “benim koleksiyonum” koleksiyonu burada. İçinde ne olduğunu görmek için üzerine tıklayın.

Qdrant bulutunda Puanlarımızın (vektörler + yük + kimlikler) Kümemizdeki Koleksiyonumuza gerçekten eklendiğini gözlemliyoruz. Takip bölümünde bu vektörlerin nasıl sorgulanacağını öğreneceğiz.
Qdrant Vektör Veritabanını Sorgulama
Bu bölümde vektör veritabanını sorgulamayı ele alacağız ve hatta filtrelenmiş bir sonuç elde etmek için bazı filtreler eklemeyi deneyeceğiz. Qdrant vektör veritabanımızı sorgulamak için öncelikle bir sorgu vektörü oluşturmamız gerekir; bunu şu şekilde yapabiliriz:
query = model.encode(['Animals live in the forest'])Sorgu Yerleştirme
Aşağıdakiler bizim yaratacağımız sorgu yerleştirme. Daha sonra bunu kullanarak, en alakalı vektör yerleştirmelerini elde etmek için vektör mağazamızı sorgulayacağız.
client.search(
collection_name = "my-collection",
query_vector = query[0],
limit = 4
)
Arama() Sorgusu
Sorgulamak için şunu kullanıyoruz: arama() istemci nesnesinin yöntemini seçin ve ona aşağıdakileri iletin:
- Koleksiyon_adı: Koleksiyonumuzun adı
- sorgu_vektörü: Vektör deposunda aramak istediğimiz sorgu vektörü
- sınır: Kaç tane arama çıktısı istiyoruz? arama() sınırlama işlevi de
Kodun çalıştırılması aşağıdaki çıktıyı üretecektir:
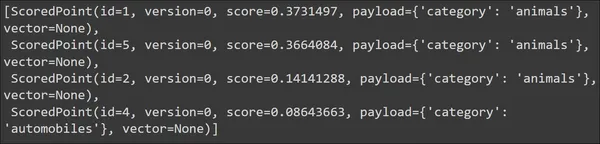
Sorgumuzda en çok alınan belgelerin hayvanlar kategorisine ait olduğunu görüyoruz. Böylece aramanın etkili olduğunu söyleyebiliriz. Şimdi bunu başka bir sorguyla deneyelim ki bize farklı sonuçlar versin. Vektörler varsayılan olarak görüntülenmez/getirilmez, dolayısıyla Yok olarak ayarlanır.
query = model.encode(['Vehicles are polluting the world'])
client.search(
collection_name = "my-collection",
query_vector = query[0],
limit = 3
)

Araçlarla İlgili Sorgu
Bu sefer verdik sorgu ile ilişkili araçlar vektör veritabanı, ilgili Kategorinin (otomobil) belgelerini en üstte başarıyla getirmeyi başardı. Şimdi biraz filtreleme yapmak istersek ne olur? Bunu şu şekilde yapabiliriz:
from qdrant_client.http.models import Filter, FieldCondition, MatchValue
query = model.encode(['Animals live in the forest'])
custom_filter = Filter(
must = [
FieldCondition(
key = "category",
match = MatchValue(
value="animals"
),
)
]
)
- Öncelikle sorgu yerleştirmemizi/vektörümüzü oluşturuyoruz
- Burada ithal ediyoruz filtre, Saha Durumu, ve Eşleşme Değeri qdrant kütüphanesindeki sınıflar.
- filtre: Bir Filter nesnesi oluşturmak için bu sınıfı kullanın
- Dosyalanma Durumu: Bu sınıf, aramamızı filtrelemek istediğimiz şey gibi filtrelemeyi oluşturmak içindir.
- Eşleşme Değeri: Bu sınıf, qdrant vektörü db'nin belirli bir anahtar için hangi değeri filtrelemesini istediğimizi anlatmak içindir
Yani yukarıdaki kodda temel olarak bir oluşturduğumuzu söylüyoruz. filtre bu kontrol eder Saha Durumu bu anahtar “kategori" içinde Yükünü maçlar(Eşleşme Değeri) değer "hayvanlar”. Bu, basit bir filtre için biraz büyük görünebilir, ancak bu yaklaşım, bir kodla uğraşırken kodumuzu daha yapılandırılmış hale getirecektir. Yükünü çok fazla bilgi içeriyor ve birden fazla anahtara göre filtreleme yapmak istiyoruz. Şimdi aramamızda filtreyi kullanalım.
client.search(
collection_name = "my-collection",
query_vector = query[0],
query_filter = custom_filter,
limit = 4
)
Sorgu_filtresi
Burada, bu sefer, teslim oluyoruz bile. sorgu_filtresi alan değişken Özel Filtre tanımladığımız. Eşleşen ilk 4 belgeyi almak için 4 sınırını koruduğumuzu unutmayın. Sorgu hayvanlarla ilgilidir. Kodun çalıştırılması aşağıdaki çıktıyla sonuçlanacaktır:

Çıktıda 3 belgemiz olmasına rağmen yalnızca en yakın ilk 5 Belgeyi aldık. Bunun nedeni, filtremizi yalnızca hayvan kategorilerini seçecek şekilde ayarlamış olmamız ve bu kategoriye ait yalnızca 3 belgenin bulunmasıdır. Bu şekilde, vektör yerleştirmelerini qdrant bulutunda saklayabilir, bu gömme vektörleri üzerinde vektör araması yapabilir, en yakın olanları alabilir ve hatta çıktıyı filtrelemek için filtreler uygulayabiliriz:
Uygulamalar
Aşağıdaki uygulamalar Qdrant Vektör Veritabanını kullanabilir:
- Öneri Sistemleri: Qdrant, yüksek boyutlu vektörleri verimli bir şekilde eşleştirerek öneri motorlarını güçlendirebilir; bu da onu akış hizmetleri, e-ticaret veya sosyal medya gibi platformlarda kişiselleştirilmiş içerik önerileri için uygun hale getirir.
- Görüntü ve Multimedya Erişimi: Qdrant'ın görüntüleri ve multimedya içeriğini temsil eden vektörleri işleme yeteneğinden yararlanan uygulamalar, görüntü veritabanları veya multimedya arşivleri için etkili arama ve alma işlevlerini uygulayabilir.
- Doğal Dil İşleme (NLP) Uygulamaları: Qdrant'ın vektör yerleştirme desteği, onu anlamsal arama, belge benzerliği eşleştirme ve büyük miktarlarda metinsel veri kümeleriyle uğraşan uygulamalardaki içerik önerisi gibi NLP görevleri için değerli kılar.
- Anomali tespiti: Qdrant'ın yüksek boyutlu vektör araması anormallik tespit sistemlerinde çalıştırılabilir. Normal davranışı temsil eden vektörleri gelen verilerle karşılaştırarak ağ güvenliği veya endüstriyel izleme gibi alanlardaki anormallikler tespit edilebilir.
- Ürün Arama ve Eşleştirme: Qdrant, e-ticaret platformlarında, ürün özelliklerini temsil eden vektörleri eşleştirerek ürün arama yeteneklerini geliştirebilir ve kullanıcı tercihlerine göre doğru ve etkili ürün önerilerini kolaylaştırabilir.
- Sosyal Ağlarda İçerik Bazlı Filtreleme: Qdrant'ın vektör araması, içerik tabanlı filtreleme için sosyal ağlarda uygulanabilir. Kullanıcılar, vektör temsillerinin benzerliğine dayalı olarak ilgili içeriği alabilir ve bu da kullanıcı etkileşimini artırır.
Sonuç
Verilerin verimli şekilde temsil edilmesine yönelik talep arttıkça Qdrant, sağlam ve güvenlik merkezli Rust diliyle yazılmış, Açık Kaynak, özelliklerle dolu bir vektör benzerlik arama motoru olarak öne çıkıyor. Qdrant, tüm popüler Mesafe Metriklerini içerir ve vektör aramamızı filtrelemek için sağlam bir yol sağlar. Zengin özellikleri, bulut tabanlı mimarisi ve sağlam terminolojisiyle Qdrant, vektör benzerlik arama teknolojisinde yeni bir çağın kapılarını açıyor. Alanında yeni olmasına rağmen birçok programlama dili için istemci kitaplıkları sağlar ve boyuta göre verimli bir şekilde ölçeklenen bir bulut sağlar.
Önemli Noktalar
Temel çıkarımlardan bazıları şunlardır:
- Rust'ta üretilen Qdrant, ağır yükler altında bile hem hız hem de güvenilirlik sağlayarak onu yüksek performanslı vektör depoları için en iyi seçim haline getiriyor.
- Qdrant'ı diğerlerinden ayıran şey, istemci API'lerini desteklemesi ve Python, TypeScript/JavaScript, Rust ve Go geliştiricilerine hizmet vermesidir.
- Qdrant, HSNW algoritmasından yararlanır ve Nokta, Kosinüs ve Öklid dahil olmak üzere farklı mesafe ölçümleri sunarak geliştiricilerin kendi özel kullanım durumlarına uygun ölçümü seçmesine olanak tanır.
- Qdrant, ölçeklenebilir bir bulut hizmetiyle buluta sorunsuz bir şekilde geçiş yaparak keşif için ücretsiz katman seçeneği sunar. Bulut tabanlı mimarisi, veri hacminden bağımsız olarak optimum performansı sağlar.
Sık Sorulan Sorular
C: Qdrant, Rust'ta yazılmış bir vektör benzerlik arama motoru ve vektör mağazasıdır. Python, TypeScript/JavaScript, Rust ve Go için API'ler sağlayan hızı, güvenilirliği ve zengin istemci desteğiyle öne çıkıyor.
C: Qdrant, HSNW algoritmasını kullanır ve Nokta, Kosinüs ve Öklid gibi farklı mesafe ölçümleri sağlar. Geliştiriciler koleksiyon oluştururken kendi özel kullanım durumlarına uygun metriği seçebilirler.
C: Önemli Bileşenler Koleksiyonları, Mesafe Ölçümlerini, Noktaları (vektörler, isteğe bağlı kimlikler ve veriler) ve Depolama seçeneklerini (Bellek İçi ve Memmap) içerir.
C: Evet, Qdrant bulut hizmetleriyle sorunsuz bir şekilde bütünleşerek ölçeklenebilir bir bulut çözümü sağlar. Bulutta yerel mimari, değişen veri hacimlerine ve bilgi işlem ihtiyaçlarına göre değişiklik yaparak optimum performansı sağlar.
C: Qdrant, yük bilgilerinin filtrelenmesine olanak tanır. Kullanıcılar, Qdrant kitaplığını kullanarak, arama sonuçlarını hassaslaştırmak için yük anahtarlarına ve değerlere dayalı koşullar vererek filtreleri tanımlayabilir.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/11/a-deep-dive-into-qdrant-the-rust-based-vector-database/

