Birkaç yıl önce Veri Analizi öğrenmeye başladığımda öğrendiğim ilk şey SQL ve Pandalar oldu. Bir veri analisti olarak, SQL ve Pandas ile çalışma konusunda güçlü bir temele sahip olmak çok önemlidir. Her ikisi de veri analistlerinin veritabanlarında depolanan verileri verimli bir şekilde analiz etmesine ve değiştirmesine yardımcı olan güçlü araçlardır.
SQL ve Pandalara Genel Bakış
SQL (Structured Query Language), ilişkisel veritabanlarını yönetmek ve değiştirmek için kullanılan bir programlama dilidir. Öte yandan Pandas, veri işleme ve analizi için kullanılan bir Python kitaplığıdır.
Veri analizi, büyük miktarda veriyle çalışmayı içerir ve veritabanları genellikle bu verileri depolamak için kullanılır. SQL ve Pandalar, veri analistlerinin verileri verimli bir şekilde ayıklamasına, işlemesine ve analiz etmesine olanak tanıyan, veritabanlarıyla çalışmak için güçlü araçlar sağlar. Veri analistleri, bu araçlardan yararlanarak, başka türlü elde edilmesi zor olacak verilerden değerli içgörüler elde edebilir.
Bu yazıda, bir veritabanını okumak ve yazmak için SQL ve Pandaların nasıl kullanılacağını keşfedeceğiz.
DB'ye bağlanma
Kitaplıkları Yükleme
Pandas ile SQL veri tabanına bağlanmadan önce gerekli kütüphaneleri kurmalıyız. Gereken iki ana kitaplık Pandas ve SQLAlchemy'dir. Pandas, girişte bahsedildiği gibi büyük veri yapılarının depolanmasına izin veren popüler bir veri işleme kitaplığıdır. Bunun aksine SQLAlchemy, SQL veritabanına bağlanmak ve SQL veritabanıyla etkileşim kurmak için bir API sağlar.
Komut isteminde aşağıdaki komutları çalıştırarak Python paket yöneticisi pip'i kullanarak her iki kitaplığı da kurabiliriz.
$ pip install pandas
$ pip install sqlalchemy
Bağlantının Yapılması
Kurulan kitaplıklar ile artık SQL veritabanına bağlanmak için Pandaları kullanabiliriz.
Başlamak için, bir SQLAlchemy motor nesnesi oluşturacağız. create_engine(). create_engine() işlevi, Python kodunu veritabanına bağlar. Veritabanı türünü ve bağlantı ayrıntılarını belirten bir bağlantı dizesini bağımsız değişken olarak alır. Bu örnekte, SQLite veritabanı türünü ve veritabanı dosyasının yolunu kullanacağız.
Aşağıdaki örneği kullanarak bir SQLite veritabanı için bir motor nesnesi oluşturun:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db')
Bizim örneğimizde SQLite veritabanı dosyası student.db, Python betiğiyle aynı dizindeyse, aşağıda gösterildiği gibi dosya adını doğrudan kullanabiliriz.
engine = create_engine('sqlite:///student.db')
Pandalar ile SQL Dosyalarını Okumak
Şimdi bir bağlantı kurduğumuza göre verileri okuyalım. Bu bölümde, read_sql, read_sql_table, ve read_sql_query işlevleri ve bunların bir veritabanıyla çalışmak için nasıl kullanılacağı.
Panda'yı kullanarak SQL Sorgularını yürütme read_sql() işlev
The read_sql() bir SQL sorgusu yürütmemize ve sonuçları bir Pandas veri çerçevesine almamıza izin veren bir Pandas kitaplığı işlevidir. bu read_sql() işlevi, SQL ve Python'u birbirine bağlayarak her iki dilin gücünden yararlanmamızı sağlar. işlev sarar read_sql_table() ve read_sql_query(). read_sql() işlev, sağlanan girdiye göre dahili olarak yönlendirilir; bu, girdinin bir SQL sorgusu yürütmesi gerekiyorsa şuraya yönlendirileceği anlamına gelir: read_sql_query(), ve eğer bir veritabanı tablosu ise, şuraya yönlendirilecektir: read_sql_table().
The read_sql() sözdizimi aşağıdaki gibidir:
pandas.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
SQL ve con parametreleri gereklidir; geri kalanı isteğe bağlıdır. Ancak, bu isteğe bağlı parametreleri kullanarak sonucu değiştirebiliriz. Her bir parametreye daha yakından bakalım.
sql: SQL sorgusu veya veritabanı tablosu adıcon: Bağlantı nesnesi veya bağlantı URL'siindex_col: Bu parametre, SQL sorgu sonucundan bir veya daha fazla sütunu veri çerçevesi dizini olarak kullanmamızı sağlar. Tek bir sütun veya bir sütun listesi alabilir.coerce_float: Bu parametre, sayısal olmayan değerlerin kayan sayılara dönüştürülmesi veya dize olarak bırakılması gerekip gerekmediğini belirtir. Varsayılan olarak true olarak ayarlanmıştır. Mümkünse, sayısal olmayan değerleri kayan tiplere dönüştürür.params: Parametreler, dinamik değerleri SQL sorgusuna geçirmek için güvenli bir yöntem sağlar. Bir sözlük, tuple veya listeyi geçirmek için params parametresini kullanabiliriz. Veritabanına bağlı olarak, parametrelerin sözdizimi değişir.parse_dates: Bu, sonuç veri çerçevesindeki hangi sütunun tarih olarak yorumlanacağını belirtmemizi sağlar. Tek bir sütunu, bir sütun listesini veya sütun adı olarak anahtarı ve sütun formatı olarak değeri içeren bir sözlüğü kabul eder.columns: Bu, listeden yalnızca seçilen sütunları getirmemizi sağlar.chunksize: Büyük bir veri kümesiyle çalışırken yığın boyutu önemlidir. Sorgu sonucunu daha küçük parçalar halinde alarak performansı artırır.
İşte nasıl kullanılacağına bir örnek read_sql():
Kodu:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql("SELECT * FROM Student", engine, index_col='Roll Number', parse_dates='dateOfBirth')
print(df)
print("The Data type of dateOfBirth: ", df.dateOfBirth.dtype) engine.dispose()
Çıktı:
firstName lastName email dateOfBirth
rollNumber
1 Mark Simson [email protected] 2000-02-23
2 Peter Griffen [email protected] 2001-04-15
3 Meg Aniston [email protected] 2001-09-20
Date type of dateOfBirth: datetime64[ns]
Veritabanına bağlandıktan sonra, veritabanından tüm kayıtları döndüren bir sorgu yürütürüz. Student tablo ve bunları DataFrame'de saklar df. "Roll Number" sütunu, kullanılarak bir dizine dönüştürülür. index_col parametresi ve "dateOfBirth" veri türü, "datetime64[ns]" nedeniyle parse_dates. Kullanabiliriz read_sql() sadece veri almak için değil, aynı zamanda ekleme, silme ve güncelleme gibi diğer işlemleri gerçekleştirmek için. read_sql() genel bir işlevdir.
Veritabanından Belirli Tabloları veya Görünümleri Yükleme
Belirli bir tabloyu veya görünümü Pandalar ile yükleme read_sql_table() veri tabanından bir Pandas veri çerçevesine veri okumak için başka bir tekniktir.
Nedir read_sql_table?
Pandalar kitaplığı şunları sağlar: read_sql_table herhangi bir sorgu yürütmeden SQL tablosunun tamamını okumak ve sonucu bir Pandas veri çerçevesi olarak döndürmek için özel olarak tasarlanmış işlev.
Sözdizimi read_sql_table() aşağıdaki gibidir:
pandas.read_sql_table(table_name, con, schema=None, index_col=None, coerce_float=True, parse_dates=None, columns=None, chunksize=None)
Dışında table_name ve şema, parametreler şu şekilde açıklanır: read_sql().
table_name: parametretable_nameveritabanındaki SQL tablosunun adıdır.schema: Bu isteğe bağlı parametre, tablo adını içeren şemanın adıdır.
Veritabanına bağlantı oluşturduktan sonra kullanacağımız read_sql_table yüklemek için işlev Student tabloyu bir Pandas DataFrame'e dönüştürün.
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql_table('Student', engine)
print(df.head()) engine.dispose()
Çıktı:
rollNumber firstName lastName email dateOfBirth
0 1 Mark Simson [email protected] 2000-02-23
1 2 Peter Griffen [email protected] 2001-04-15
2 3 Meg Aniston [email protected] 2001-09-20
Bunun, bellek açısından yoğun olabilecek büyük bir tablo olduğunu varsayacağız. nasıl kullanabileceğimizi keşfedelim. chunksize Bu sorunu gidermek için parametre.
En iyi uygulamalar, endüstri tarafından kabul edilen standartlar ve dahil edilen hile sayfası ile Git'i öğrenmek için uygulamalı, pratik kılavuzumuza göz atın. Googling Git komutlarını durdurun ve aslında öğrenmek o!
Kodu:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df_iterator = pd.read_sql_table('Student', engine, chunksize = 1) for df in df_iterator: print(df.head()) engine.dispose()
Çıktı:
rollNumber firstName lastName email dateOfBirth
0 1 Mark Simson [email protected] 2000-02-23
0 2 Peter Griffen [email protected] 2001-04-15
0 3 Meg Aniston [email protected] 2001-09-20
Lütfen unutmayın ki chunksize Burada 1 kullanıyorum çünkü masamda sadece 3 kaydım var.
DB'yi Doğrudan Pandaların SQL Söz Dizimi ile Sorgulama
Veritabanından içgörü çıkarmak, veri analistleri ve bilim adamları için önemli bir kısımdır. Bunu yapmak için, read_sql_query() fonksiyonu.
read_sql_query() nedir?
Pandaları Kullanmak read_sql_query() işlevi, SQL sorguları çalıştırabilir ve sonuçları doğrudan bir DataFrame'e alabiliriz. bu read_sql_query() işlevi özellikle için oluşturulur SELECT ifadeler. gibi diğer işlemler için kullanılamaz. DELETE or UPDATE.
Sözdizimi:
pandas.read_sql_query(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, chunksize=None, dtype=None, dtype_backend=_NoDefault.no_default)
Tüm parametre açıklamaları, read_sql() işlev. İşte bir örnek read_sql_query():
Kodu:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql_query('Select firstName, lastName From Student Where rollNumber = 1', engine)
print(df) engine.dispose()
Çıktı:
firstName lastName
0 Mark Simson
Pandas ile SQL Dosyaları Yazma
Verileri analiz ederken, birkaç girişin değiştirilmesi gerektiğini veya verileri içeren yeni bir tablo veya görünümün gerekli olduğunu keşfettiğimizi varsayalım. Yeni bir kaydı güncellemek veya eklemek için bir yöntem kullanmaktır. read_sql() ve bir sorgu yazın. Ancak, bu yöntem uzun olabilir. Pandalar, denilen harika bir yöntem sağlar. to_sql() bunun gibi durumlar için.
Bu bölümde öncelikle veritabanında yeni bir tablo oluşturacağız ve daha sonra var olan bir tabloyu düzenleyeceğiz.
SQL Veritabanında Yeni Tablo Oluşturma
Yeni bir tablo oluşturmadan önce, önce tartışalım to_sql() detayda.
Nedir to_sql()?
The to_sql() Pandas kitaplığının işlevi, veritabanını yazmamıza veya güncellememize izin verir. bu to_sql() işlevi, DataFrame verilerini bir SQL veritabanına kaydedebilir.
sözdizimi to_sql():
DataFrame.to_sql(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None, method=None)
Bir tek name ve con parametrelerin çalıştırılması zorunludur to_sql(); ancak, diğer parametreler ek esneklik ve özelleştirme seçenekleri sağlar. Her parametreyi ayrıntılı olarak tartışalım:
name: Oluşturulacak veya değiştirilecek SQL tablosunun adı.con: Veritabanının bağlantı nesnesi.schema: Tablonun şeması (isteğe bağlı).if_exists: Bu parametrenin varsayılan değeri “başarısız”dır. Bu parametre, tablo zaten mevcutsa yapılacak eyleme karar vermemizi sağlar. Seçenekler arasında "başarısız", "değiştir" ve "ekle" yer alır.index: index parametresi bir boolean değeri kabul eder. Varsayılan olarak, True olarak ayarlanmıştır, yani DataFrame'in indeksi SQL tablosuna yazılacaktır.index_label: Bu isteğe bağlı parametre, dizin sütunları için bir sütun etiketi belirlememizi sağlar. Varsayılan olarak, dizin tabloya yazılır, ancak bu parametre kullanılarak belirli bir ad verilebilir.chunksize: SQL veritabanında bir seferde yazılacak satır sayısı.dtype: Bu parametre, sütun adları olarak anahtarları ve veri türleri olarak değerleri içeren bir sözlüğü kabul eder.method: method parametresi, SQL'e veri eklemek için kullanılan yöntemi belirtmeye izin verir. Varsayılan olarak Yok olarak ayarlanmıştır, bu da pandaların veritabanına dayalı olarak en verimli yolu bulacağı anlamına gelir. Yöntem parametreleri için iki ana seçenek vardır:multi: Tek bir SQL sorgusuna birden fazla satır eklenmesine izin verir. Ancak, tüm veritabanları çok satırlı eklemeyi desteklemez.- çağrılabilir fonksiyon: Burada insert için özel bir fonksiyon yazabilir ve metod parametrelerini kullanarak çağırabiliriz.
İşte kullanarak bir örnek to_sql():
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') data = {'Name': ['Paul', 'Tom', 'Jerry'], 'Age': [9, 8, 7]}
df = pd.DataFrame(data) df.to_sql('Customer', con=engine, if_exists='fail') engine.dispose()
Veritabanında "Ad" ve "Yaş" adlı iki alanla Müşteri adlı yeni bir tablo oluşturulur.
Veritabanı anlık görüntüsü:
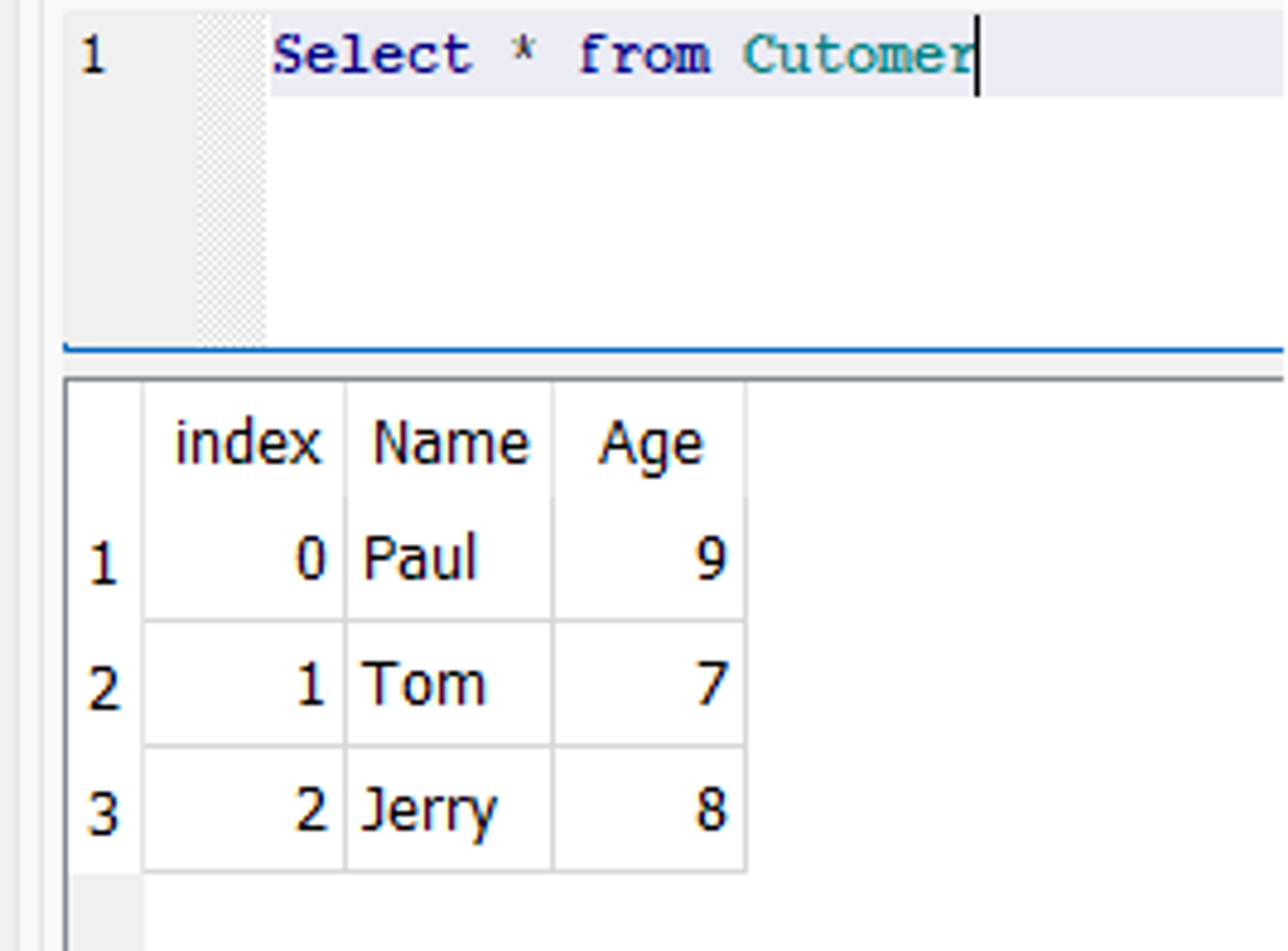
Mevcut Tabloları Pandas Dataframes ile Güncelleme
Bir veritabanındaki verileri güncellemek, özellikle büyük verilerle uğraşırken karmaşık bir iştir. Ancak, kullanarak to_sql() Pandas'taki işlev bu görevi çok daha kolaylaştırabilir. Veritabanındaki mevcut tabloyu güncellemek için, to_sql() fonksiyonu ile birlikte kullanılabilir. if_exists parametre "değiştir" olarak ayarlandı. Bu, mevcut tablonun üzerine yeni veriler yazacaktır.
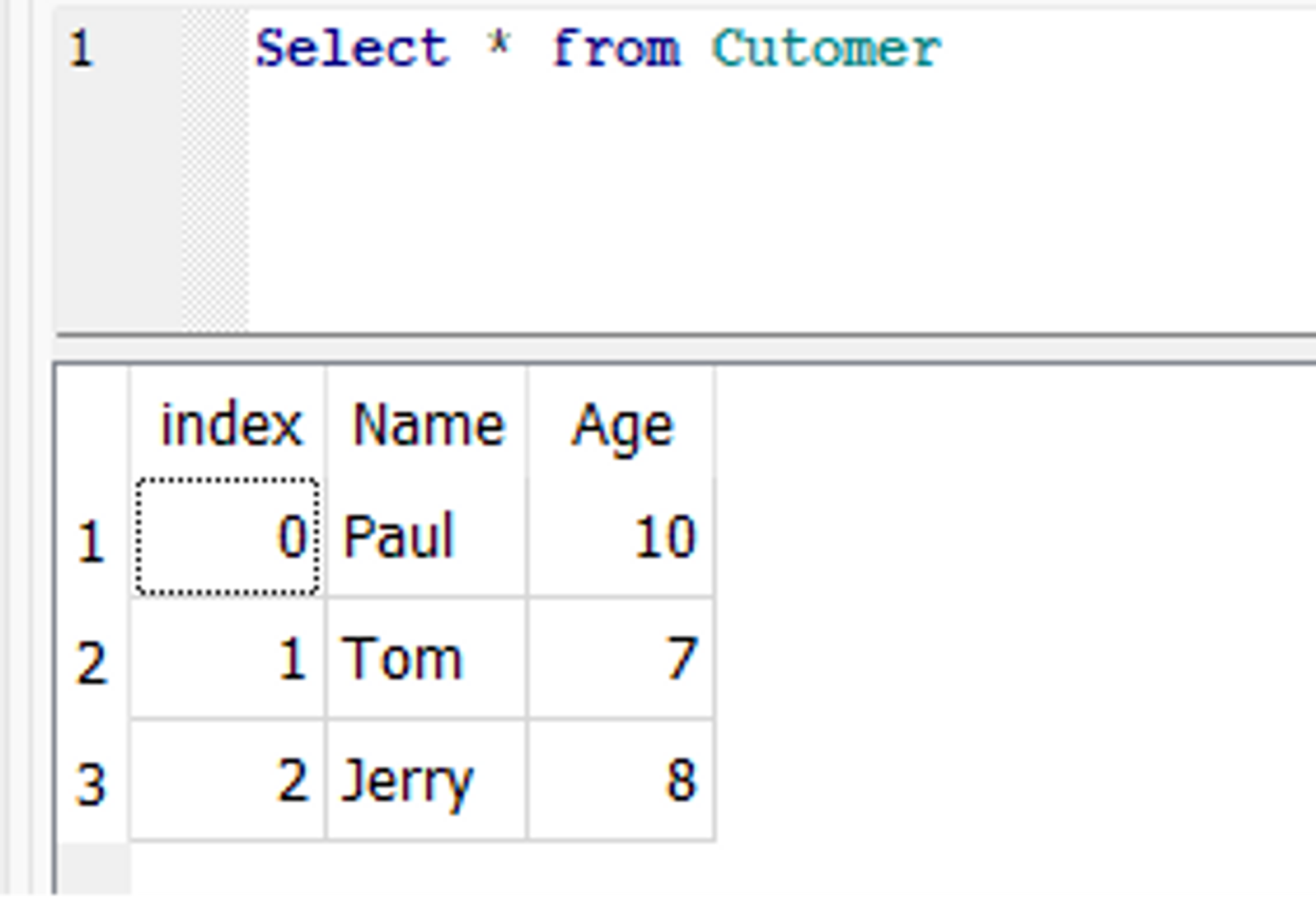
İşte bir örnek to_sql() bu, daha önce oluşturulmuş olanı günceller Customer masa. Diyelim ki, içinde Customer tablosunda Paul adlı bir müşterinin yaşını 9'dan 10'a güncellemek istiyoruz. Bunu yapmak için önce DataFrame'deki ilgili satırı değiştirebilir ve ardından to_sql() veritabanını güncelleme işlevi.
Kodu:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql_table('Customer', engine) df.loc[df['Name'] == 'Paul', 'Age'] = 10 df.to_sql('Customer', con=engine, if_exists='replace') engine.dispose()
Veritabanında Paul'ün yaşı güncellendi:
Sonuç
Sonuç olarak, Pandas ve SQL, okuma ve SQL veritabanına veri yazma gibi veri analizi görevleri için güçlü araçlardır. Pandas, SQL veritabanına bağlanmak, veritabanındaki verileri bir Pandas veri çerçevesine okumak ve veri çerçevesi verilerini veritabanına geri yazmak için kolay bir yol sağlar.
Pandas kitaplığı, bir veri çerçevesindeki verilerin işlenmesini kolaylaştırırken SQL, bir veritabanındaki verileri sorgulamak için güçlü bir dil sağlar. Verileri okumak ve yazmak için hem Pandaları hem de SQL'i kullanmak, özellikle veriler çok büyük olduğunda, veri analizi görevlerinde zamandan ve emekten tasarruf sağlayabilir. Genel olarak, SQL ve Panda'lardan birlikte yararlanmak, veri analistlerinin ve bilim adamlarının iş akışlarını kolaylaştırmasına yardımcı olabilir.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoAiStream. Web3 Veri Zekası. Bilgi Genişletildi. Buradan Erişin.
- Adryenn Ashley ile Geleceği Basmak. Buradan Erişin.
- PREIPO® ile PRE-IPO Şirketlerinde Hisse Al ve Sat. Buradan Erişin.
- Kaynak: https://stackabuse.com/reading-and-writing-sql-files-in-pandas/

