Giriş
İnce ayar yapma doğal dil işleme (NLP) Model, modelin hiperparametrelerinin ve mimarisinin değiştirilmesini ve tipik olarak modelin belirli bir görevdeki performansını artırmak için veri kümesinin ayarlanmasını gerektirir. Bunu, öğrenme oranını, modeldeki katman sayısını, yerleştirmelerin boyutunu ve diğer çeşitli parametreleri ayarlayarak başarabilirsiniz. İnce ayar, modelin ve işin sağlam bir şekilde kavranmasını gerektiren zaman alıcı bir prosedürdür. Bu makale Sarılma Yüz Modeline nasıl ince ayar yapılacağına bakacaktır.

Öğrenme hedefleri
- Transformers ve kişisel dikkat de dahil olmak üzere T5 modelinin yapısını anlayın.
- Daha iyi model performansı için hiperparametreleri optimize etmeyi öğrenin.
- Belirleme ve biçimlendirme de dahil olmak üzere metin verilerinin hazırlanmasında uzmanlaşın.
- Önceden eğitilmiş modellerin belirli görevlere nasıl uyarlanacağını öğrenin.
- Eğitim için veri kümelerini temizlemeyi, bölmeyi ve oluşturmayı öğrenin.
- Kayıp ve doğruluk gibi ölçümleri kullanarak model eğitimi ve değerlendirme konusunda deneyim kazanın.
- Yanıtlar veya yanıtlar oluşturmak için ince ayarlı modelin gerçek dünyadaki uygulamalarını keşfedin.
Bu makale, Veri Bilimi Blogatonu.
İçindekiler
Sarılma Yüz Modelleri Hakkında
Sarılma Yüz doğal dil işleme (NLP) modeli eğitimi ve dağıtımı için bir platform sağlayan bir firmadır. Platform, çeşitli NLP görevlerine uygun bir model kitaplığına ev sahipliği yapıyor: dil çevirisi, metin oluşturmave soru cevaplama. Bu modeller kapsamlı veri kümeleri üzerinde eğitime tabi tutulur ve çok çeşitli doğal dil işleme (NLP) faaliyetlerinde başarılı olacak şekilde tasarlanmıştır.
Hugging Face platformu ayrıca, algoritmaların belirli alanlara veya dillere uyarlanmasına yardımcı olabilecek, belirli veri kümeleri üzerinde önceden eğitilmiş modellerin ince ayarına yönelik araçlar da içerir. Platformda ayrıca uygulamalardaki önceden eğitilmiş modellere erişmek ve bunları kullanmak için API'ler ve özel modeller oluşturup bunları buluta sunmaya yönelik araçlar da bulunuyor.
Hugging Face kütüphanesini doğal dil işleme (NLP) görevleri için kullanmanın çeşitli avantajları vardır:
- Geniş model seçimi: Dil çevirisi, soru yanıtlama ve metin kategorizasyonu gibi görevlerde eğitilmiş modeller de dahil olmak üzere, Hugging Face kitaplığı aracılığıyla önemli bir dizi önceden eğitilmiş NLP modeli mevcuttur. Bu, gereksinimlerinizi tam olarak karşılayan bir model seçmenizi kolaylaştırır.
- Platformlar arası uyumluluk: Hugging Face kitaplığı standartlarla uyumludur derin öğrenme gibi sistemler TensorFlow, PyTorchve Keras, mevcut iş akışınıza entegre olmayı kolaylaştırır.
- Basit ince ayar: Hugging Face kitaplığı, veri kümenizdeki önceden eğitilmiş modellere ince ayar yapmak için araçlar içerir ve bir modeli sıfırdan eğitmeye kıyasla zamandan ve emekten tasarruf etmenizi sağlar.
- Aktif topluluk: Hugging Face kütüphanesi geniş ve aktif bir kullanıcı topluluğuna sahiptir; bu da yardım ve destek alabileceğiniz ve kütüphanenin büyümesine katkıda bulunabileceğiniz anlamına gelir.
- İyi belgelenmiş: Hugging Face kütüphanesi, başlamayı ve verimli bir şekilde nasıl kullanılacağını öğrenmeyi kolaylaştıran kapsamlı belgeler içerir.
Gerekli Kitaplıkları İçe Aktar
Gerekli kitaplıkların içe aktarılması, belirli bir programlama ve veri analizi etkinliği için bir araç seti oluşturmaya benzer. Çoğunlukla önceden yazılmış kod koleksiyonları olan bu kütüphaneler, geliştirmeyi hızlandırmaya yardımcı olan çok çeşitli işlevler ve araçlar sunar. Geliştiriciler ve veri bilimcileri, uygun kitaplıkları içe aktararak yeni yeteneklere erişebilir, üretkenliği artırabilir ve mevcut çözümleri kullanabilir.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split import torch from transformers import T5Tokenizer
from transformers import T5ForConditionalGeneration, AdamW import pytorch_lightning as pl
from pytorch_lightning.callbacks import ModelCheckpoint pl.seed_everything(100) import warnings
warnings.filterwarnings("ignore")
Veri Kümesini İçe Aktar
Bir veri kümesinin içe aktarılması, veri odaklı projelerde çok önemli bir ilk adımdır.
df = pd.read_csv("/kaggle/input/queestion-answer-dataset-qa/train.csv")
df.columns
df = df[['context','question', 'text']]
print("Number of records: ", df.shape[0])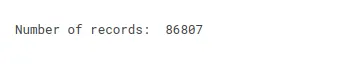
Sorun bildirimi
"Bağlam ve sorulara dayalı yanıtlar üretebilen bir model oluşturmak."
Örneğin,
Bağlam = “Örneğin, benzer durumlardan oluşan grupların kümelenmesi
benzer hastaları bulun veya müşteri segmentasyonu için kullanın
bankacılık alanı. İlişkilendirme tekniği öğeleri veya olayları bulmak için kullanılır
örneğin belirli bir müşterinin genellikle birlikte satın aldığı market ürünleri gibi sıklıkla birlikte ortaya çıkan durumlar. Anormallik tespiti anormallikleri keşfetmek için kullanılır
ve olağandışı durumlar; örneğin kredi kartı dolandırıcılığı
tespit etme."
Soru = “Anormallik tespitine örnek nedir?”
Cevap = ???????????????????????????????
df["context"] = df["context"].str.lower()
df["question"] = df["question"].str.lower()
df["text"] = df["text"].str.lower() df.head()
Parametreleri Başlat
- giriş uzunluğu: Eğitim sırasında, giriş uzunluğu olarak modele beslenen tek bir örnekteki giriş jetonlarının (örneğin, kelimeler veya karakterler) sayısını belirtiriz. Bir cümledeki sonraki kelimeyi tahmin etmek için bir dil modeli eğitiyorsanız girdi uzunluğu, cümledeki kelimelerin sayısı olacaktır.
- Çıkış uzunluğu: Eğitim sırasında modelin tek bir örnekte kelimeler veya karakterler gibi belirli miktarda çıktı jetonu üretmesi beklenir. Çıktı uzunluğu, modelin cümle içinde tahmin ettiği kelime sayısına karşılık gelir.
- Eğitim toplu boyutu: Eğitim sırasında model aynı anda birden fazla örneği işler. Eğitim toplu iş boyutunu 32 olarak ayarlarsanız model, model ağırlıklarını güncellemeden önce 32 örneği (32 ifade gibi) aynı anda işler.
- Toplu iş boyutunun doğrulanması: Eğitim toplu boyutuna benzer şekilde bu parametre, doğrulama aşamasında modelin işlediği örneklerin sayısını gösterir. Başka bir deyişle, modelin bir veri seti üzerinde test edildiğinde işlediği veri hacmini temsil eder.
- Dönemler: Bir çağ, tüm eğitim veri kümesi boyunca yapılan tek bir yolculuktur. Dolayısıyla, eğitim veri kümesi 1000 örnek içeriyorsa ve eğitim kümesi boyutu 32 ise, bir dönemin 32 eğitim adımına ihtiyacı olacaktır. Model on dönem boyunca eğitilmişse on bin örneği işlemiştir (10 * 1000 = on bin).
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu') INPUT_MAX_LEN = 512 # Input length
OUT_MAX_LEN = 128 # Output Length
TRAIN_BATCH_SIZE = 8 # Training Batch Size
VALID_BATCH_SIZE = 2 # Validation Batch Size
EPOCHS = 5 # Number of IterationT5 Trafo
The T5 modeli sıralı giriş verilerini etkili bir şekilde işlemek için tasarlanmış bir sinir ağı olan Transformer mimarisini temel alır. Birbirine bağlı bir dizi “katman” içeren bir kodlayıcı ve kod çözücüden oluşur.
Kodlayıcı ve kod çözücü katmanları çeşitli "dikkat" mekanizmalarını ve "ileri besleme" ağlarını içerir. Dikkat mekanizmaları, modelin diğer zamanlarda girdi dizisinin farklı bölümlerine odaklanmasını sağlar. Aynı zamanda, ileri beslemeli ağlar, bir dizi ağırlık ve önyargı kullanarak giriş verilerini değiştirir.
T5 modeli aynı zamanda girdi dizisindeki her bir öğenin diğer tüm öğelere dikkat etmesini sağlayan "öz-dikkat" özelliğini de kullanır. Bu, modelin, birçok NLP uygulaması için kritik olan, girdi verilerindeki kelimeler ve ifadeler arasındaki bağlantıları tanımasına olanak tanır.
Kodlayıcı ve kod çözücüye ek olarak T5 modeli, önceki kelimelere dayalı olarak sonraki kelimeyi sırayla tahmin eden bir "dil modeli kafası" içerir. Bu, modelin tutarlı ve doğal görünen çıktı sağlaması gereken çeviri ve metin üretimi işleri için kritik öneme sahiptir.
T5 modeli, sıralı girdilerin yüksek verimli ve doğru şekilde işlenmesi için tasarlanmış geniş ve gelişmiş bir sinir ağını temsil eder. Çeşitli metin veri kümeleri üzerinde kapsamlı bir eğitimden geçmiştir ve geniş bir yelpazedeki doğal dil işleme görevlerini ustalıkla yerine getirebilmektedir.
T5Tokenleştirici
T5Tokenizer, bir metni, her biri tek bir kelimeyi veya noktalama işaretini temsil eden bir jeton listesine dönüştürmek için kullanılır. Belirteç ayırıcı ayrıca, metnin başlangıcını ve bitişini belirtmek ve çeşitli cümleleri ayırt etmek için giriş metnine benzersiz belirteçler ekler.
T5Tokenizer, karakter düzeyinde ve kelime düzeyinde tokenizasyon ile SentencePiece tokenizer ile karşılaştırılabilir bir alt kelime düzeyinde tokenizasyon stratejisinin bir kombinasyonunu kullanır. Eğitim verilerindeki her karakterin veya karakter dizisinin sıklığına göre giriş metnini alt sözcüklere ayırır. Bu, tokenizer'ın eğitim verilerinde yer almayan ancak test verilerinde görünen sözcük dışı (OOV) terimlerle başa çıkmasına yardımcı olur.
T5Tokenizer ayrıca cümlelerin başlangıcını ve sonunu belirtmek ve bunları bölmek için metne benzersiz belirteçler ekler. Örneğin, bir cümlenin başlangıcını ve sonunu belirtmek için s > ve / s > simgelerini ve dolguyu belirtmek için pad > simgelerini ekler.
MODEL_NAME = "t5-base" tokenizer = T5Tokenizer.from_pretrained(MODEL_NAME, model_max_length= INPUT_MAX_LEN)
print("eos_token: {} and id: {}".format(tokenizer.eos_token, tokenizer.eos_token_id)) # End of token (eos_token)
print("unk_token: {} and id: {}".format(tokenizer.unk_token, tokenizer.eos_token_id)) # Unknown token (unk_token)
print("pad_token: {} and id: {}".format(tokenizer.pad_token, tokenizer.eos_token_id)) # Pad token (pad_token)

Veri Seti Hazırlama
PyTorch ile uğraşırken, genellikle bir veri kümesi sınıfını kullanarak verilerinizi modelde kullanılmak üzere hazırlarsınız. Veri kümesi sınıfı, diskten veri yüklemek ve tokenizasyon ve sayısallaştırma gibi gerekli hazırlık prosedürlerini yürütmekten sorumludur. Sınıfın ayrıca veri kümesinden dizine göre tek bir öğe elde etmek için kullanılan getitem işlevini de uygulaması gerekir.
Başlatma yöntemi veri kümesini metin listesi, etiket listesi ve belirteçle doldurur. Len işlevi veri kümesindeki örneklerin sayısını döndürür. Get item işlevi, bir veri kümesinden dizine göre tek bir öğe döndürür. Bir dizin kimliğini kabul eder ve simgeleştirilmiş giriş ve etiketleri çıkarır.
Ayrıca, tokenize edilmiş girişlerin doldurulması ve kesilmesi gibi çeşitli ön işleme adımlarının dahil edilmesi de gelenekseldir. Ayrıca etiketleri tensörlere de dönüştürebilirsiniz.
class T5Dataset: def __init__(self, context, question, target): self.context = context self.question = question self.target = target self.tokenizer = tokenizer self.input_max_len = INPUT_MAX_LEN self.out_max_len = OUT_MAX_LEN def __len__(self): return len(self.context) def __getitem__(self, item): context = str(self.context[item]) context = " ".join(context.split()) question = str(self.question[item]) question = " ".join(question.split()) target = str(self.target[item]) target = " ".join(target.split()) inputs_encoding = self.tokenizer( context, question, add_special_tokens=True, max_length=self.input_max_len, padding = 'max_length', truncation='only_first', return_attention_mask=True, return_tensors="pt" ) output_encoding = self.tokenizer( target, None, add_special_tokens=True, max_length=self.out_max_len, padding = 'max_length', truncation= True, return_attention_mask=True, return_tensors="pt" ) inputs_ids = inputs_encoding["input_ids"].flatten() attention_mask = inputs_encoding["attention_mask"].flatten() labels = output_encoding["input_ids"] labels[labels == 0] = -100 # As per T5 Documentation labels = labels.flatten() out = { "context": context, "question": question, "answer": target, "inputs_ids": inputs_ids, "attention_mask": attention_mask, "targets": labels } return out Veri Yükleyici
DataLoader sınıfı, verileri paralel ve toplu olarak yükleyerek, normalde bellekte depolanamayacak kadar büyük olacak büyük veri kümeleriyle çalışmayı mümkün kılar. DataLoader sınıfını, yüklenecek verileri içeren bir veri kümesi sınıfıyla birleştirme.
Veri yükleyici, bir transformatör modelini eğitirken veri kümesi üzerinde yineleme yapmaktan ve eğitim veya değerlendirme için bir veri kümesini modele döndürmekten sorumludur. DataLoader sınıfı, toplu iş boyutu, çalışan iş parçacığı sayısı ve her çağdan önce verilerin karıştırılıp karıştırılmayacağı da dahil olmak üzere verilerin yüklenmesini ve ön işlenmesini kontrol etmek için çeşitli parametreler sunar.
class T5DatasetModule(pl.LightningDataModule): def __init__(self, df_train, df_valid): super().__init__() self.df_train = df_train self.df_valid = df_valid self.tokenizer = tokenizer self.input_max_len = INPUT_MAX_LEN self.out_max_len = OUT_MAX_LEN def setup(self, stage=None): self.train_dataset = T5Dataset( context=self.df_train.context.values, question=self.df_train.question.values, target=self.df_train.text.values ) self.valid_dataset = T5Dataset( context=self.df_valid.context.values, question=self.df_valid.question.values, target=self.df_valid.text.values ) def train_dataloader(self): return torch.utils.data.DataLoader( self.train_dataset, batch_size= TRAIN_BATCH_SIZE, shuffle=True, num_workers=4 ) def val_dataloader(self): return torch.utils.data.DataLoader( self.valid_dataset, batch_size= VALID_BATCH_SIZE, num_workers=1 )Model Binası
PyTorch'ta bir transformatör modeli oluştururken genellikle torch'tan türetilen yeni bir sınıf oluşturarak başlarsınız. nn.Module. Bu sınıf, katmanlar ve ileri işlev de dahil olmak üzere modelin mimarisini açıklar. Sınıfın init işlevi, genellikle modelin farklı düzeylerini örneklendirerek ve bunları sınıf nitelikleri olarak atayarak modelin mimarisini tanımlar.
İleri yöntem, verilerin model üzerinden ileri yönde iletilmesinden sorumludur. Bu yöntem girdi verilerini kabul eder ve çıktıyı oluşturmak için modelin katmanlarını uygular. İleri yöntem, girdiyi bir dizi katmandan geçirmek ve sonucu döndürmek gibi modelin mantığını uygulamalıdır.
Sınıfın init işlevi bir gömme katmanı, bir transformatör katmanı ve tamamen bağlı bir katman oluşturur ve bunları sınıf nitelikleri olarak atar. Forward yöntemi, gelen x verisini kabul eder, verilen aşamalardan geçerek işler ve sonucu döndürür. Bir transformatör modelini eğitirken, eğitim süreci genellikle iki aşamadan oluşur: eğitim ve doğrulama.
Training_step yöntemi, genellikle aşağıdakileri içeren tek bir eğitim adımının gerçekleştirilmesinin gerekçesini belirtir:
- modelden ileri geçiş
- kaybın hesaplanması
- gradyanların hesaplanması
- Modelin parametrelerinin güncellenmesi
Training_step yöntemi gibi val_step yöntemi de modeli bir doğrulama kümesinde değerlendirmek için kullanılır. Genellikle şunları içerir:
- modelden ileri geçiş
- değerlendirme ölçütlerinin hesaplanması
class T5Model(pl.LightningModule): def __init__(self): super().__init__() self.model = T5ForConditionalGeneration.from_pretrained(MODEL_NAME, return_dict=True) def forward(self, input_ids, attention_mask, labels=None): output = self.model( input_ids=input_ids, attention_mask=attention_mask, labels=labels ) return output.loss, output.logits def training_step(self, batch, batch_idx): input_ids = batch["inputs_ids"] attention_mask = batch["attention_mask"] labels= batch["targets"] loss, outputs = self(input_ids, attention_mask, labels) self.log("train_loss", loss, prog_bar=True, logger=True) return loss def validation_step(self, batch, batch_idx): input_ids = batch["inputs_ids"] attention_mask = batch["attention_mask"] labels= batch["targets"] loss, outputs = self(input_ids, attention_mask, labels) self.log("val_loss", loss, prog_bar=True, logger=True) return loss def configure_optimizers(self): return AdamW(self.parameters(), lr=0.0001)
Model Eğitimi
Veri kümesi üzerinde gruplar halinde yineleme yapmak, girdiyi model aracılığıyla göndermek ve hesaplanan gradyanlara ve bir dizi optimizasyon kriterine dayalı olarak modelin parametrelerini değiştirmek, bir transformatör modelini eğitmek için olağan bir durumdur.
def run(): df_train, df_valid = train_test_split( df[0:10000], test_size=0.2, random_state=101 ) df_train = df_train.fillna("none") df_valid = df_valid.fillna("none") df_train['context'] = df_train['context'].apply(lambda x: " ".join(x.split())) df_valid['context'] = df_valid['context'].apply(lambda x: " ".join(x.split())) df_train['text'] = df_train['text'].apply(lambda x: " ".join(x.split())) df_valid['text'] = df_valid['text'].apply(lambda x: " ".join(x.split())) df_train['question'] = df_train['question'].apply(lambda x: " ".join(x.split())) df_valid['question'] = df_valid['question'].apply(lambda x: " ".join(x.split())) df_train = df_train.reset_index(drop=True) df_valid = df_valid.reset_index(drop=True) dataModule = T5DatasetModule(df_train, df_valid) dataModule.setup() device = DEVICE models = T5Model() models.to(device) checkpoint_callback = ModelCheckpoint( dirpath="/kaggle/working", filename="best_checkpoint", save_top_k=2, verbose=True, monitor="val_loss", mode="min" ) trainer = pl.Trainer( callbacks = checkpoint_callback, max_epochs= EPOCHS, gpus=1, accelerator="gpu" ) trainer.fit(models, dataModule) run()Model Tahmini
Yeni girdiyi kullanarak T5 gibi ince ayarlı bir NLP modeliyle tahminlerde bulunmak için şu adımları takip edebilirsiniz:
- Yeni Girişi Ön İşlemden Geçirin: Yeni giriş metninizi, eğitim verilerinize uyguladığınız ön işlemeyle eşleşecek şekilde simgeleştirin ve önceden işleyin. Modelin beklediği doğru formatta olduğundan emin olun.
- Çıkarım için İnce Ayarlı Modeli Kullanın: Daha önce eğittiğiniz veya bir kontrol noktasından yüklediğiniz ince ayarlı T5 modelinizi yükleyin.
- Tahminler Oluşturun: Tahmin için önceden işlenmiş yeni girişi modele aktarın. T5 durumunda yanıt oluşturmak için created yöntemini kullanabilirsiniz.
train_model = T5Model.load_from_checkpoint("/kaggle/working/best_checkpoint-v1.ckpt") train_model.freeze() def generate_question(context, question): inputs_encoding = tokenizer( context, question, add_special_tokens=True, max_length= INPUT_MAX_LEN, padding = 'max_length', truncation='only_first', return_attention_mask=True, return_tensors="pt" ) generate_ids = train_model.model.generate( input_ids = inputs_encoding["input_ids"], attention_mask = inputs_encoding["attention_mask"], max_length = INPUT_MAX_LEN, num_beams = 4, num_return_sequences = 1, no_repeat_ngram_size=2, early_stopping=True, ) preds = [ tokenizer.decode(gen_id, skip_special_tokens=True, clean_up_tokenization_spaces=True) for gen_id in generate_ids ] return "".join(preds)Tahmin
ince ayarlı T5 modelini yeni girdiyle kullanarak bir tahmin oluşturalım:
bağlam = “Benzer durumların gruplandırılması, örneğin,
benzer hastaları bulabilir veya müşteri segmentasyonu için kullanabilir
bankacılık alanı. Öğeleri veya olayları bulmak için ilişkilendirme tekniğini kullanma
genellikle birlikte satın alınan market ürünleri gibi sıklıkla birlikte ortaya çıkar
belirli bir müşteri tarafından. Anormal olanı keşfetmek için anormallik tespitini kullanma
ve olağandışı durumlar, örneğin kredi kartı dolandırıcılığının tespiti."
que = “Anormallik tespitine örnek nedir?”
print(generate_question(bağlam, kuyruk))

context = "Classification is used when your target is categorical, while regression is used when your target variable
is continuous. Both classification and regression belong to the category of supervised machine learning algorithms." que = "When is classification used?" print(generate_question(context, que))

Sonuç
Bu makalede, bir soru yanıtlama görevi için bir doğal dil işleme (NLP) modeline, özellikle de T5 modeline ince ayar yapma yolculuğuna çıktık. Bu süreç boyunca çeşitli NLP modeli geliştirme ve dağıtım hususlarını inceledik.
Anahtar teslimatlar:
- Yeteneklerini destekleyen kodlayıcı-kod çözücü yapısını ve öz-dikkat mekanizmalarını araştırdı.
- Hiperparametre ayarlama sanatı, model performansını optimize etmek için önemli bir beceridir.
- Öğrenme oranları, parti boyutları ve model boyutlarıyla denemeler yapmak, modelde etkili bir şekilde ince ayar yapmamıza olanak sağladı.
- Ham metin verilerini tokenleştirme, doldurma ve model girişi için uygun bir formata dönüştürme konusunda uzman.
- Önceden eğitilmiş ağırlıkların yüklenmesi, model katmanlarının değiştirilmesi ve bunların belirli görevlere uyarlanması da dahil olmak üzere ince ayarlara odaklanıldı.
- Verilerin nasıl temizlenip yapılandırılacağını, eğitim ve doğrulama kümelerine nasıl bölüneceğini öğrendi.
- Girdi bağlamına ve sorulara dayalı olarak nasıl yanıtlar veya cevaplar üretebileceğini göstererek gerçek dünyadaki faydasını sergiledi.
Sık Sorulan Sorular
Cevap: NLP'de ince ayar yapmak, belirli bir görev veya veri kümesi için performansını optimize etmek amacıyla önceden eğitilmiş bir modelin hiperparametrelerini ve mimarisini değiştirmeyi içerir.
Cevap: Transformer mimarisi bir sinir ağı mimarisidir. Sıralı verileri işlemede mükemmeldir ve T5 gibi modellerin temelini oluşturur. Bağlamı anlamak için kişisel dikkat mekanizmalarını kullanır.
Cevap: NLP'de sıralı görevlerde kodlayıcı-kod çözücü yapısını kullanırız. Kodlayıcı giriş verilerini işler ve kod çözücü çıkış verilerini üretir.
Cevap: Evet, ince ayarlı modelleri metin oluşturma, çeviri ve soru cevaplama dahil olmak üzere gerçek dünyadaki çeşitli NLP görevlerine uygulayabilirsiniz.
Cevap: Başlamak için Hugging Face gibi kütüphaneleri keşfedebilirsiniz. Bu kitaplıklar, veri kümelerinize ince ayar yapmak için önceden eğitilmiş modeller ve araçlar sunar. NLP temellerini ve derin öğrenme kavramlarını öğrenmek de çok önemlidir.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/10/hugging-face-fine-tuning-tutorial/

