
Giriş
Kapsamlı aramıza hoş geldiniz veri analizi Netflix dünyasının derinliklerine inen blog. Dünyanın önde gelen akış platformlarından biri olan Netflix, eğlenceyi tüketme biçimimizde devrim yarattı. Geniş film ve TV şovları kütüphanesi ile dünyanın dört bir yanındaki izleyiciler için çok sayıda seçenek sunar.
Netflix'in Küresel Erişimi
Netflix kayda değer bir büyüme yaşadı ve yayın endüstrisinde baskın bir güç haline gelmek için varlığını genişletti. İşte küresel etkisini gösteren bazı dikkate değer istatistikler:
- Kullanıcı tabanı: 2022'nin ikinci çeyreğinin başında Netflix yaklaşık olarak birikmişti. 222 milyon uluslararası abone190'dan fazla ülkeyi kapsayan (Çin, Kırım, Kuzey Kore, Rusya ve Suriye hariç). Bu etkileyici rakamlar, platformun dünya çapındaki izleyiciler arasındaki yaygın kabulünün ve popülaritesinin altını çiziyor.
- Uluslar arası genişleme: 190'dan fazla ülkede kullanılabilirliği ile Netflix, küresel bir varlığı başarıyla oluşturmuştur. Şirket, çeşitli dillerde altyazı ve dublaj sunarak içeriğini yerelleştirmek için önemli çaba sarf etmiş ve farklı bir kitleye erişilebilirlik sağlamıştır.
Bu blogda, Netflix'in içerik ortamında gizlenen ilgi çekici kalıpları, trendleri ve içgörüleri keşfetmek için heyecan verici bir yolculuğa çıkıyoruz. Gücünden yararlanmak Python ve onun veri analizi Kitaplıklarda, içerik eklemelere, süre dağılımlarına, tür bağıntılarına ve hatta başlıklarda ve açıklamalarda en sık kullanılan sözcüklere ışık tutan değerli bilgileri ortaya çıkarmak için Netflix'in sunduğu geniş koleksiyona dalıyoruz.
Ayrıntılı kod parçacıkları aracılığıyla ve görselleştirme, platformun nasıl geliştiğine dair yeni bir bakış açısı sağlamak için Netflix'in içerik ekosisteminin katmanlarını kaldırıyoruz. Yayın modellerini, sezon trendlerini ve izleyici tercihlerini analiz ederek Netflix'in uçsuz bucaksız evrenindeki içerik dinamiklerini daha iyi anlamayı amaçlıyoruz.
Bu makale, Veri Bilimi Blogathon.
İçindekiler
Veri Hazırlama
Bu örnek olay incelemesinde kullanılan veriler, veri bilimi ve makine öğrenimi meraklıları için popüler bir platform olan Kaggle'dan alınmıştır. “ başlıklı veri setiNetflix Filmleri ve TV Şovları”, Kaggle'da herkese açıktır ve Netflix akış platformundaki filmler ve TV şovları hakkında değerli bilgiler sağlar.
Veri seti, her filmin veya TV şovunun farklı yönlerini açıklayan çeşitli sütunları içeren bir tablo biçiminden oluşur. Sütunları ve açıklamalarını özetleyen bir tablo aşağıdadır:
| Sütun adı | Açıklama |
|---|---|
| show_id | Her Film / TV Şovu için benzersiz kimlik |
| tip | Tanımlayıcı - Bir Film veya TV Şovu |
| başlık | Filmin / TV Şovunun Adı |
| yönetmen | Filmin Yönetmeni |
| döküm | Filmde / Gösteride rol alan aktörler |
| ülke | Filmin/Şovun çekildiği ülke |
| Ekleme Tarihi | Netflix'e eklendiği tarih |
| çıkış tarihi | Filmin / Şovun Fiili Yayın Yılı |
| değerlendirme | Filmin / Şovun TV Derecelendirmesi |
| süre | Toplam Süre – dakika veya sezon sayısı olarak |
Bu bölümde Netflix veri setinin temizliğini ve analize uygunluğunu sağlamak için veri hazırlama görevleri yapacağız. Eksik değerleri ve kopyaları ele alacağız ve gerektiğinde veri türü dönüştürmeleri gerçekleştireceğiz. Kodu inceleyelim ve her adımı inceleyelim.
Kütüphaneleri İçe Aktarma
Başlamak için, veri analizi ve görselleştirme için gerekli kitaplıkları içe aktarıyoruz. Bu kütüphaneler şunları içerir: pandalar, numpy ve matplotlib. pyplot ve seaborn. Verileri etkili bir şekilde işlemek ve görselleştirmek için gerekli işlevleri ve araçları sağlarlar.
# Importing necessary libraries for data analysis and visualization
import pandas as pd # pandas for data manipulation and analysis
import numpy as np # numpy for numerical operations
import matplotlib.pyplot as plt # matplotlib for data visualization
import seaborn as sns # seaborn for enhanced data visualizationVeri Kümesini Yükleme
Ardından, pd.read_csv() işlevini kullanarak Netflix veri kümesini yüklüyoruz. Veri kümesi 'netflix.csv' dosyasında saklanır. Yapısını anlamak için veri setinin ilk beş kaydına bakalım.
# Loading the dataset from a CSV file
df = pd.read_csv('netflix.csv') # Displaying the first few rows of the dataset
df.head()Tanımlayıcı istatistikler
Veri kümesinin genel özelliklerini anlamak çok önemlidir. tanımlayıcı istatistikler. Sayı, ortalama, standart sapma, minimum, maksimum ve çeyrekler gibi sayısal nitelikler hakkında fikir edinebiliriz.
# Computing descriptive statistics for the dataset
df.describe()Kısa Özet
Veri kümesinin kısa bir özetini almak için df.info() işlevini kullanırız. Boş olmayan değerlerin sayısı ve her sütunun veri türleri hakkında bilgi sağlar. Bu özet, eksik değerlerin ve veri türleriyle ilgili olası sorunların belirlenmesine yardımcı olur.
# Obtaining information about the dataset
df.info()Eksik Değerleri Ele Alma
Eksik değerler doğru analizi engelleyebilir. Bu veri kümesi, df kullanarak her sütundaki eksik değerleri araştırır. sıfırdır().sum(). Eksik değerlere sahip sütunları belirlemeyi ve her sütundaki eksik veri yüzdesini belirlemeyi amaçlıyoruz.
# Checking for missing values in the dataset
df.isnull().sum()Eksik değerlerin üstesinden gelmek için farklı sütunlar için farklı stratejiler kullanırız. Her adımı inceleyelim:
çoğaltır
Yinelenenler analiz sonuçlarını bozabilir, bu nedenle bunları ele almak çok önemlidir. Df.duplicated().sum() kullanarak yinelenen kayıtları belirler ve kaldırırız.
# Checking for duplicate rows in the dataset
df.duplicated().sum()Belirli Sütunlardaki Eksik Değerleri İşleme
"Yönetmen" ve "oyuncu" sütunlarında, veri bütünlüğünü korumak ve analizde herhangi bir yanlılığı önlemek için eksik değerleri "Veri Yok" olarak değiştiririz.
# Replacing missing values in the 'director' column with 'No Data'
df['director'].replace(np.nan, 'No Data', inplace=True) # Replacing missing values in the 'cast' column with 'No Data'
df['cast'].replace(np.nan, 'No Data', inplace=True)Tutarlılığı sağlamak ve veri kaybını en aza indirmek için 'ülke' sütununda eksik değerleri modla (en sık oluşan değer) dolduruyoruz.
# Filling missing values in the 'country' column with the mode value
df['country'] = df['country'].fillna(df['country'].mode()[0])"Derecelendirme" sütunu için, programın "türüne" göre eksik değerleri dolduruyoruz. Filmler ve diziler için 'derecelendirme' modunu ayrı ayrı atarız.
# Finding the mode rating for movies and TV shows
movie_rating = df.loc[df['type'] == 'Movie', 'rating'].mode()[0]
tv_rating = df.loc[df['type'] == 'TV Show', 'rating'].mode()[0] # Filling missing rating values based on the type of content
df['rating'] = df.apply(lambda x: movie_rating if x['type'] == 'Movie' and pd.isna(x['rating']) else tv_rating if x['type'] == 'TV Show' and pd.isna(x['rating']) else x['rating'], axis=1)"Süre" sütunu için, gösterinin "türüne" göre eksik değerleri dolduruyoruz. Filmler ve TV şovları için 'süre' modunu ayrı ayrı atarız.
# Finding the mode duration for movies and TV shows
movie_duration_mode = df.loc[df['type'] == 'Movie', 'duration'].mode()[0]
tv_duration_mode = df.loc[df['type'] == 'TV Show', 'duration'].mode()[0] # Filling missing duration values based on the type of content
df['duration'] = df.apply(lambda x: movie_duration_mode if x['type'] == 'Movie' and pd.isna(x['duration']) else tv_duration_mode if x['type'] == 'TV Show' and pd.isna(x['duration']) else x['duration'], axis=1)Kalan Eksik Değerleri Düşürme
Belirli sütunlardaki eksik değerleri işledikten sonra, analiz için temiz bir veri kümesi sağlamak üzere eksik değerlere sahip kalan satırları çıkarırız.
# Dropping rows with missing values
df.dropna(inplace=True)Tarih İşleme
Tarihle ilgili özniteliklere dayalı daha fazla analiz sağlamak için pd.to_datetime() kullanarak 'date_added' sütununu tarih saat biçimine dönüştürüyoruz.
# Converting the 'date_added' column to datetime format
df["date_added"] = pd.to_datetime(df['date_added'])Ek Veri Dönüşümleri
Analiz yeteneklerimizi geliştirmek için 'eklenen_tarih' sütunundan ek öznitelikler çıkarıyoruz. Bu zamansal yönlere dayalı eğilimleri analiz etmek için ay ve yıl değerlerini kaldırırız.
# Extracting month, month name, and year from the 'date_added' column
df['month_added'] = df['date_added'].dt.month
df['month_name_added'] = df['date_added'].dt.month_name()
df['year_added'] = df['date_added'].dt.yearVeri Dönüşümü: Oyuncular, Ülke, Listelenen Yer ve Yönetmen
Kategorik öznitelikleri daha etkili bir şekilde analiz etmek için, onları daha yavaş keşif ve analize izin vererek ayrı veri çerçevelerine dönüştürüyoruz.
'cast', 'country', 'listed_in' ve 'director' sütunları için değerleri virgül ayırıcıya göre ayırdık ve her değer için ayrı satırlar oluşturduk. Bu dönüşüm, verileri daha ayrıntılı bir düzeyde analiz etmemizi sağlar.
# Splitting and expanding the 'cast' column
df_cast = df['cast'].str.split(',', expand=True).stack()
df_cast = df_cast.reset_index(level=1, drop=True).to_frame('cast')
df_cast['show_id'] = df['show_id'] # Splitting and expanding the 'country' column
df_country = df['country'].str.split(',', expand=True).stack()
df_country = df_country.reset_index(level=1, drop=True).to_frame('country')
df_country['show_id'] = df['show_id'] # Splitting and expanding the 'listed_in' column
df_listed_in = df['listed_in'].str.split(',', expand=True).stack()
df_listed_in = df_listed_in.reset_index(level=1, drop=True).to_frame('listed_in')
df_listed_in['show_id'] = df['show_id'] # Splitting and expanding the 'director' column
df_director = df['director'].str.split(',', expand=True).stack()
df_director = df_director.reset_index(level=1, drop=True).to_frame('director')
df_director['show_id'] = df['show_id']Bu veri hazırlama adımlarını tamamladıktan sonra, daha fazla analiz için temiz ve dönüştürülmüş bir veri setimiz var. Bu ilk veri manipülasyonları, Netflix veri setini keşfetmenin ve akış platformunun veri odaklı stratejilerine ilişkin içgörüleri ortaya çıkarmanın temelini oluşturuyor.
Açıklayıcı Veri Analizi
İçerik Türlerinin Dağılımı
Netflix kitaplığındaki içeriğin dağılımını belirlemek için aşağıdaki kodu kullanarak içerik türlerinin (filmler ve diziler) yüzde dağılımını hesaplayabiliriz:
# Calculate the percentage distribution of content types
x = df.groupby(['type'])['type'].count()
y = len(df)
r = ((x/y) * 100).round(2) # Create a DataFrame to store the percentage distribution
mf_ratio = pd.DataFrame(r)
mf_ratio.rename({'type': '%'}, axis=1, inplace=True) # Plot the 3D-effect pie chart
plt.figure(figsize=(12, 8))
colors = ['#b20710', '#221f1f']
explode = (0.1, 0)
plt.pie(mf_ratio['%'], labels=mf_ratio.index, autopct='%1.1f%%', colors=colors, explode=explode, shadow=True, startangle=90, textprops={'color': 'white'}) plt.legend(loc='upper right')
plt.title('Distribution of Content Types')
plt.show()
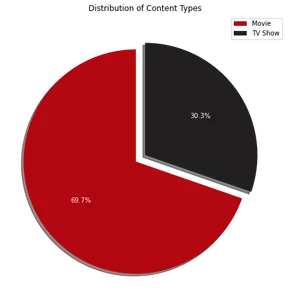
Pasta grafiği görselleştirmesi, Netflix'teki içeriğin yaklaşık %70'inin filmden, kalan %30'unun ise TV şovlarından oluştuğunu gösteriyor. Ardından, Netflix'in popüler olduğu ilk 10 ülkeyi belirlemek için aşağıdaki kodu kullanabiliriz:
Netflix'in Popüler Olduğu İlk 10 Ülke
Ardından, Netflix'in popüler olduğu ilk 10 ülkeyi belirlemek için aşağıdaki kodu kullanabiliriz:
# Remove white spaces from 'country' column
df_country['country'] = df_country['country'].str.rstrip() # Find value counts
country_counts = df_country['country'].value_counts() # Select the top 10 countries
top_10_countries = country_counts.head(10) # Plot the top 10 countries
plt.figure(figsize=(16, 10))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_countries) - 1)
bar_plot = sns.barplot(x=top_10_countries.index, y=top_10_countries.values, palette=colors) plt.xlabel('Country')
plt.ylabel('Number of Titles')
plt.title('Top 10 Countries Where Netflix is Popular') # Add count values on top of each bar
for index, value in enumerate(top_10_countries.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()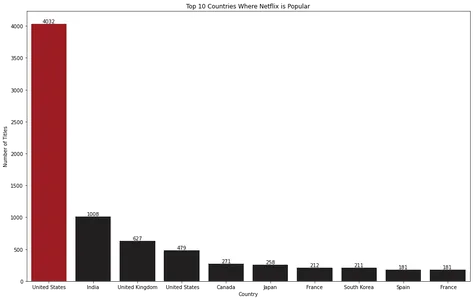
Çubuk grafik görselleştirmesi, ABD'nin Netflix'in en popüler olduğu ülke olduğunu ortaya koyuyor.
Film/TV Şovu Sayısına Göre En İyi 10 Oyuncu
Filmlerde ve dizilerde en çok rol alan ilk 10 oyuncuyu belirlemek için aşağıdaki kodu kullanabilirsiniz:
# Count the occurrences of each actor
cast_counts = df_cast['cast'].value_counts()[1:] # Select the top 10 actors
top_10_cast = cast_counts.head(10) plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_cast) - 1)
bar_plot = sns.barplot(x=top_10_cast.index, y=top_10_cast.values, palette=colors) plt.xlabel('Actor')
plt.ylabel('Number of Appearances')
plt.title('Top 10 Actors by Movie/TV Show Count') # Add count values on top of each bar
for index, value in enumerate(top_10_cast.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()
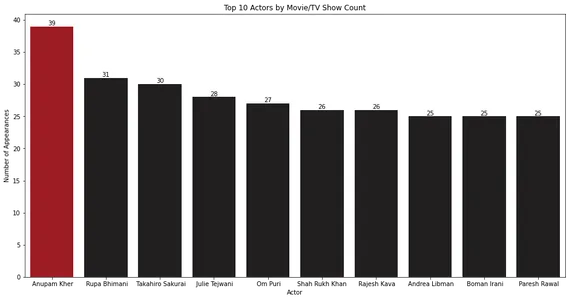
Çubuk grafik, Anupam Kher'in filmlerde ve TV şovlarında en yüksek görünüme sahip olduğunu gösteriyor.
Film/TV Şovu Sayısına Göre En İyi 10 Yönetmen
En çok film ya da dizi yönetmenliği yapan ilk 10 yönetmeni belirlemek için aşağıdaki kodu kullanabilirsiniz:
# Count the occurrences of each actor
director_counts = df_director['director'].value_counts()[1:] # Select the top 10 actors
top_10_directors = director_counts.head(10) plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_directors) - 1)
bar_plot = sns.barplot(x=top_10_directors.index, y=top_10_directors.values, palette=colors) plt.xlabel('Director')
plt.ylabel('Number of Movies/TV Shows')
plt.title('Top 10 Directors by Movie/TV Show Count') # Add count values on top of each bar
for index, value in enumerate(top_10_directors.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()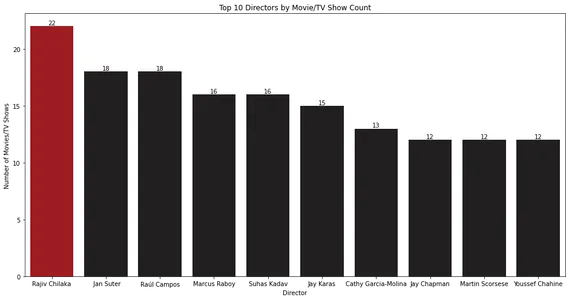
Çubuk grafik, en çok film veya TV şovuna sahip ilk 10 yönetmeni gösterir. Rajiv Chilaka, Netflix kütüphanesindeki en çok içeriği yönetmiş görünüyor.
Film/TV Şovu Sayısına Göre En İyi 10 Kategori
İçeriğin farklı kategorilerdeki dağılımını analiz etmek için aşağıdaki kodu kullanabilirsiniz:
df_listed_in['listed_in'] = df_listed_in['listed_in'].str.strip() # Count the occurrences of each actor
listed_in_counts = df_listed_in['listed_in'].value_counts() # Select the top 10 actors
top_10_listed_in = listed_in_counts.head(10) plt.figure(figsize=(12, 8))
bar_plot = sns.barplot(x=top_10_listed_in.index, y=top_10_listed_in.values, palette=colors) # Customize the plot
plt.xlabel('Category')
plt.ylabel('Number of Movies/TV Shows')
plt.title('Top 10 Categories by Movie/TV Show Count')
plt.xticks(rotation=45) # Add count values on top of each bar
for index, value in enumerate(top_10_listed_in.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') # Show the plot
plt.show()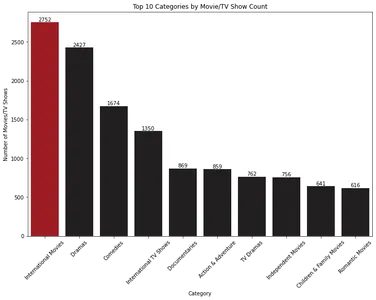
Çubuk grafik, sayılarına göre en iyi 10 film ve TV programı kategorisini gösterir. “Uluslararası Filmler” en baskın kategori olurken, onu “Dramalar” takip ediyor.
Zamanla Eklenen Filmler ve TV Şovları
Filmlerin ve TV şovlarının zaman içinde eklenmesini analiz etmek için aşağıdaki kodu kullanabilirsiniz:
# Filter the DataFrame to include only Movies and TV Shows
df_movies = df[df['type'] == 'Movie']
df_tv_shows = df[df['type'] == 'TV Show'] # Group the data by year and count the number of Movies and TV Shows # added in each year
movies_count = df_movies['year_added'].value_counts().sort_index()
tv_shows_count = df_tv_shows['year_added'].value_counts().sort_index() # Create a line chart to visualize the trends over time
plt.figure(figsize=(16, 8))
plt.plot(movies_count.index, movies_count.values, color='#b20710', label='Movies', linewidth=2)
plt.plot(tv_shows_count.index, tv_shows_count.values, color='#221f1f', label='TV Shows', linewidth=2) # Fill the area under the line charts
plt.fill_between(movies_count.index, movies_count.values, color='#b20710')
plt.fill_between(tv_shows_count.index, tv_shows_count.values, color='#221f1f') # Customize the plot
plt.xlabel('Year')
plt.ylabel('Count')
plt.title('Movies & TV Shows Added Over Time')
plt.legend() # Show the plot
plt.show()
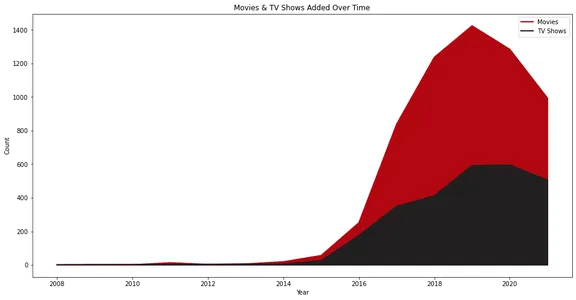
Çizgi grafik, zaman içinde Netflix'e eklenen filmlerin ve TV şovlarının sayısını gösterir. Filmler ve TV şovları için ayrı satırlarla, içerik eklemelerindeki büyümeyi ve trendleri görsel olarak temsil eder.
Netflix, 2015 yılından itibaren gerçek büyümesini gördü ve yıllar içinde TV Şovlarından daha fazla Film eklediğini görebiliriz.
Ayrıca 2020 yılında içerik eklemenin düşmesi de ilginç. Bunun nedeni pandemi durumundan kaynaklanıyor olabilir.
Ardından, eklenen içeriklerin farklı aylara göre dağılımını keşfedeceğiz. Bu analiz, kalıpları belirlememize ve Netflix'in yeni içerikleri ne zaman kullanıma sunacağını anlamamıza yardımcı olur.
Aya Göre Eklenen İçerik
Bunu araştırmak için, 'eklenen_tarih' sütunundan ayı çıkarır ve her ayın oluşumlarını sayarız. Bu verileri bir çubuk grafik olarak görselleştirmek, içeriğin en fazla eklendiği ayları hızlı bir şekilde belirlememizi sağlar.
# Extract the month from the 'date_added' column
df['month_added'] = pd.to_datetime(df['date_added']).dt.month_name() # Define the order of the months
month_order = ['January', 'February', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November', 'December'] # Count the number of shows added in each month
monthly_counts = df['month_added'].value_counts().loc[month_order] # Determine the maximum count
max_count = monthly_counts.max() # Set the color for the highest bar and the rest of the bars
colors = ['#b20710' if count == max_count else '#221f1f' for count in monthly_counts] # Create the bar chart
plt.figure(figsize=(16, 8))
bar_plot = sns.barplot(x=monthly_counts.index, y=monthly_counts.values, palette=colors) # Customize the plot
plt.xlabel('Month')
plt.ylabel('Count')
plt.title('Content Added by Month') # Add count values on top of each bar
for index, value in enumerate(monthly_counts.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') # Rotate x-axis labels for better readability
plt.xticks(rotation=45) # Show the plot
plt.show()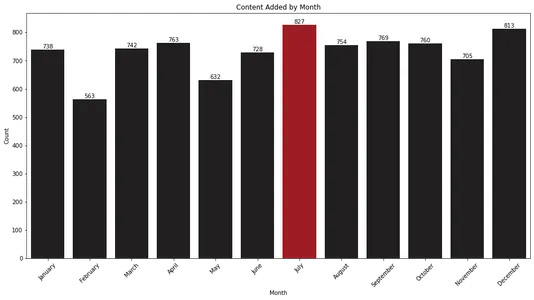
Çubuk grafik, Temmuz ve Aralık aylarının Netflix'in kitaplığına en fazla içerik eklediği aylar olduğunu gösteriyor. Bu bilgiler, bu aylarda yeni çıkacakları tahmin etmek isteyen izleyiciler için değerli olabilir.
Netflix'in içerik analizinin bir diğer önemli yönü de derecelendirmelerin dağılımını anlamaktır. Her derecelendirme kategorisinin sayısını inceleyerek platformdaki en yaygın içerik türlerini belirleyebiliriz.
Derecelendirmelerin Dağılımı
Her derecelendirme kategorisinin oluşumlarını hesaplayarak başlıyoruz ve bunları bir çubuk grafik kullanarak görselleştiriyoruz. Bu görselleştirme, derecelendirmelerin dağılımına net bir genel bakış sağlar.
# Count the occurrences of each rating
rating_counts = df['rating'].value_counts() # Create a bar chart to visualize the ratings
plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(rating_counts) - 1)
sns.barplot(x=rating_counts.index, y=rating_counts.values, palette=colors) # Customize the plot
plt.xlabel('Rating')
plt.ylabel('Count')
plt.title('Distribution of Ratings') # Rotate x-axis labels for better readability
plt.xticks(rotation=45) # Show the plot
plt.show()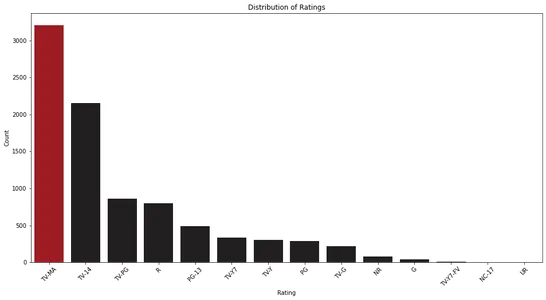
Çubuk grafiği incelediğimizde, Netflix'teki derecelendirme dağılımını gözlemleyebiliriz. En yaygın derecelendirme kategorilerini ve bunların göreli sıklığını belirlememize yardımcı olur.
Tür Korelasyon Isı Haritası
Türler, Netflix'teki içeriğin sınıflandırılmasında ve düzenlenmesinde önemli bir rol oynar. Türler arasındaki ilişkiyi analiz etmek, farklı içerik türleri arasındaki ilginç ilişkileri ortaya çıkarabilir.
Tür bağıntısını araştırmak ve onu sıfırlarla doldurmak için bir tür verisi DataFrame oluşturuyoruz. Orijinal DataFrame'deki her satırı yineleyerek, DataFrame tür verilerini listelenen türlere göre güncelleriz. Daha sonra bu tür verilerini kullanarak bir korelasyon matrisi oluşturuyoruz ve bunu bir ısı haritası olarak görselleştiriyoruz.
# Extracting unique genres from the 'listed_in' column
genres = df['listed_in'].str.split(', ', expand=True).stack().unique() # Create a new DataFrame to store the genre data
genre_data = pd.DataFrame(index=genres, columns=genres, dtype=float) # Fill the genre data DataFrame with zeros
genre_data.fillna(0, inplace=True) # Iterate over each row in the original DataFrame and update the genre data DataFrame
for _, row in df.iterrows(): listed_in = row['listed_in'].split(', ') for genre1 in listed_in: for genre2 in listed_in: genre_data.at[genre1, genre2] += 1 # Create a correlation matrix using the genre data
correlation_matrix = genre_data.corr() # Create the heatmap
plt.figure(figsize=(20, 16))
sns.heatmap(correlation_matrix, annot=False, cmap='coolwarm') # Customize the plot
plt.title('Genre Correlation Heatmap')
plt.xticks(rotation=90)
plt.yticks(rotation=0) # Show the plot
plt.show()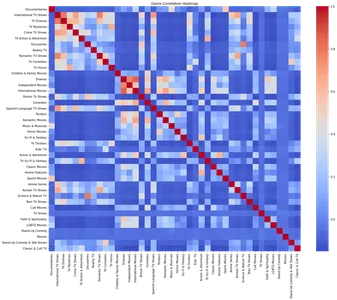
Isı haritası, farklı türler arasındaki ilişkiyi gösterir. Isı haritasını analiz ederek, TV Dramaları ve Uluslararası TV Şovları, Romantik TV Şovları ve Uluslararası TV Şovları gibi belirli türler arasında güçlü pozitif korelasyonlar belirleyebiliriz.
Film Uzunluklarının ve TV Şovu Bölüm Sayılarının Dağılımı
Filmlerin ve TV şovlarının Sürelerini anlamak, içeriğin uzunluğu hakkında fikir verir ve izleyicilerin izleme sürelerini planlamalarına yardımcı olur. Film uzunluklarının ve TV şov sürelerinin dağılımını inceleyerek Netflix'te bulunan içeriği daha iyi anlayabiliriz.
Bunu başarmak için, 'süre' sütunundan film uzunluklarını ve TV programı bölüm sayılarını çıkarıyoruz. Ardından, film uzunluklarının ve TV programı sürelerinin dağılımını görselleştirmek için histogramlar ve kutu çizimleri çizeriz.
# Extract the movie lengths and TV show episode counts
movie_lengths = df_movies['duration'].str.extract('(d+)', expand=False).astype(int)
tv_show_episodes = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Plot the histogram
plt.figure(figsize=(10, 6))
plt.hist(movie_lengths, bins=10, color='#b20710', label='Movies')
plt.hist(tv_show_episodes, bins=10, color='#221f1f', label='TV Shows') # Customize the plot
plt.xlabel('Duration/Episode Count')
plt.ylabel('Frequency')
plt.title('Distribution of Movie Lengths and TV Show Episode Counts')
plt.legend() # Show the plot
plt.show()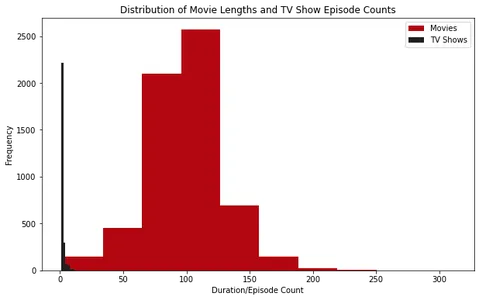
Histogramları incelediğimizde, Netflix'teki çoğu filmin süresinin 100 dakika civarında olduğunu gözlemleyebiliriz. Öte yandan, Netflix'teki çoğu dizinin yalnızca bir sezonu vardır.
Ayrıca kutu grafiklerini incelediğimizde yaklaşık 2.5 saatten uzun filmlerin aykırı sayıldığını görebiliriz. TV şovları için dört mevsimden fazla olanları bulmak alışılmadık bir durumdur.
Yıllara Göre Film/TV Şovu Sürelerinin Eğilimi
Film uzunluklarının ve TV şovu bölüm sayılarının yıllar içinde nasıl geliştiğini anlamak için çizgi grafikler çizebiliriz. Bu eğilimleri analiz ederek içerik süresindeki kalıpları veya kaymaları belirleme.
Film uzunluklarını ve TV şovu bölüm sayılarını 'süre' sütunundan çıkararak başlıyoruz. Ardından, yıllar içinde film uzunluklarındaki ve TV şovu bölümlerindeki değişiklikleri görselleştirmek için çizgi grafikler oluşturuyoruz.
import seaborn as sns
import matplotlib.pyplot as plt # Extract the movie lengths and TV show episodes from the 'duration' column
movie_lengths = df_movies['duration'].str.extract('(d+)', expand=False).astype(int)
tv_show_episodes = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Create line plots for movie lengths and TV show episodes
plt.figure(figsize=(16, 8)) plt.subplot(2, 1, 1)
sns.lineplot(data=df_movies, x='release_year', y=movie_lengths, color=colors[0])
plt.xlabel('Release Year')
plt.ylabel('Movie Length')
plt.title('Trend of Movie Lengths Over the Years') plt.subplot(2, 1, 2)
sns.lineplot(data=df_tv_shows, x='release_year', y=tv_show_episodes,color=colors[1])
plt.xlabel('Release Year')
plt.ylabel('TV Show Episodes')
plt.title('Trend of TV Show Episodes Over the Years') # Adjust the layout and spacing
plt.tight_layout() # Show the plots
plt.show()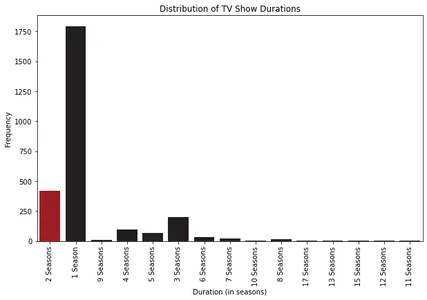
Çizgi grafikleri inceleyerek, heyecan verici modeller gözlemliyoruz. Film uzunluğunun başlangıçta 1963-1964 yıllarına kadar arttığını, sonra yavaş yavaş düştüğünü ve ortalama 100 dakika civarında sabitlendiğini görebiliriz. Bu, izleyici tercihlerinde zaman içinde bir değişiklik olduğunu gösterir.
TV şovu bölümleriyle ilgili olarak, Netflix'teki çoğu TV şovunun bir ila üç sezonu olduğu 2000'lerin başından beri tutarlı bir eğilim fark ettik. Bu, izleyiciler arasında daha kısa dizilerin veya sınırlı dizi formatlarının tercih edildiğini gösterir.
Başlıklarda ve Açıklamalarda En Yaygın Sözcükler
Başlıklarda ve açıklamalarda kullanılan en yaygın sözcükleri analiz etmek, Netflix'teki temalar ve içerik odağı hakkında fikir verebilir. Netflix içeriğinin başlıklarına ve açıklamalarına dayanarak bu kalıpları ortaya çıkarmak için kelime bulutları oluşturabiliriz.
from wordcloud import WordCloud # Concatenate all the titles into a single string
text = ' '.join(df['title']) wordcloud = WordCloud(width = 800, height = 800, background_color ='white', min_font_size = 10).generate(text) # plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0) plt.show() # Concatenate all the titles into a single string
text = ' '.join(df['description']) wordcloud = WordCloud(width = 800, height = 800, background_color ='white', min_font_size = 10).generate(text) # plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0) plt.show()
Başlıklar için kelime bulutu incelendiğinde “Aşk”, “Kız”, “Erkek”, “Hayat” ve “Dünya” gibi terimlerin sıklıkla kullanıldığını ve romantik, reşit olma ve dramın varlığını gösterdiğini görüyoruz. Netflix'in içerik kitaplığındaki türler.
Açıklamalar için kelime bulutunu incelediğimizde, "hayat", "bul" ve "aile" gibi baskın kelimelerin, Netflix'in içeriğinde yaygın olan kişisel yolculuklar, ilişkiler ve aile dinamikleri temalarını akla getirdiğini fark ettik.
Filmler ve TV Şovları için Süre Dağılımı
Filmler ve TV şovları için süre dağılımını analiz etmek, Netflix'te bulunan tipik içerik uzunluğunu anlamamızı sağlar. Bu dağılımları görselleştirmek ve aykırı değerleri veya standart süreleri belirlemek için kutu grafikleri oluşturabiliriz.
# Extracting and converting the duration for movies
df_movies['duration'] = df_movies['duration'].str.extract('(d+)', expand=False).astype(int) # Creating a boxplot for movie duration
plt.figure(figsize=(10, 6))
sns.boxplot(data=df_movies, x='type', y='duration')
plt.xlabel('Content Type')
plt.ylabel('Duration')
plt.title('Distribution of Duration for Movies')
plt.show() # Extracting and converting the duration for TV shows
df_tv_shows['duration'] = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Creating a boxplot for TV show duration
plt.figure(figsize=(10, 6))
sns.boxplot(data=df_tv_shows, x='type', y='duration')
plt.xlabel('Content Type')
plt.ylabel('Duration')
plt.title('Distribution of Duration for TV Shows')
plt.show()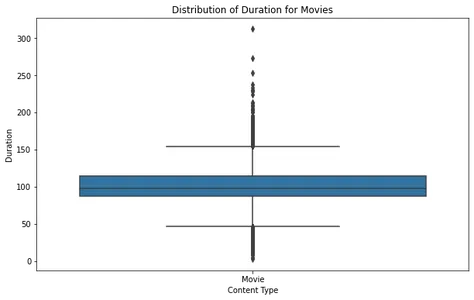
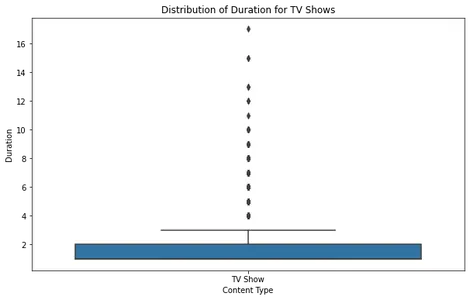
Film kutusu olay örgüsünü incelediğimizde, çoğu filmin makul bir süre aralığında yer aldığını ve birkaç aykırı değerin yaklaşık 2.5 saati aştığını görebiliriz. Bu, Netflix'teki çoğu filmin standart bir izleme süresine uyacak şekilde tasarlandığını gösterir.
TV şovları için kutu planı, çoğu şovun birden dört sezona kadar sürdüğünü ve çok az sayıda aykırı dizinin daha uzun sürelere sahip olduğunu ortaya koyuyor. Bu, Netflix'in daha kısa dizi formatlarına odaklandığını gösteren önceki eğilimlerle uyumludur.
Sonuç
Bu makalenin yardımıyla, hakkında bilgi edinebildik-
- Miktar: Analizimiz, Netflix'in içerik kitaplıklarına filmlerin hakim olduğu beklentisiyle uyumlu olarak, TV dizilerinden daha fazla film eklediğini ortaya çıkardı.
- İçerik Ekleme: Temmuz, Netflix'in en fazla içerik eklediği ay olarak ortaya çıktı ve onu yakından takip eden Aralık ayı, içerik yayınlama konusunda stratejik bir yaklaşıma işaret ediyor.
- Tür Korelasyonu: TV dizileri ve uluslararası TV şovları, romantik ve uluslararası TV şovları ve bağımsız filmler ve dramalar gibi çeşitli türler arasında güçlü pozitif ilişkiler gözlemlendi. Bu korelasyonlar, izleyici tercihleri ve içerik ara bağlantıları hakkında bilgi sağlar.
- Film Süreleri: Film sürelerinin analizi, 1960'larda zirveye ulaştığını, ardından 100 dakika civarında bir sabitlenme olduğunu ve zaman içinde film uzunluklarında bir trend olduğunu vurguladı.
- TV Şovu Bölümleri: Netflix'teki çoğu TV şovunun bir sezonu var, bu da izleyiciler arasında daha kısa dizilerin tercih edildiğini gösteriyor.
- Ortak Temalar: Aşk, yaşam, aile ve macera gibi kelimeler başlıklarda ve açıklamalarda sıklıkla kullanılmış ve Netflix içeriğinde tekrar eden temalar yakalanmıştır.
- Derecelendirme Dağılımı: Derecelendirmelerin yıllar içindeki dağılımı, gelişen içerik ortamı ve izleyicilerin kabulü hakkında bilgiler sunar.
- Veriye Dayalı Görüşler: Veri analizi yolculuğumuz, verilerin Netflix'in içerik ortamının gizemlerini çözmedeki gücünü göstererek izleyiciler ve içerik oluşturucular için değerli bilgiler sağladı.
- Sürekli İlgi: Akış endüstrisi geliştikçe, bu kalıpları ve eğilimleri anlamak, Netflix'in ve geniş kitaplığının dinamik ortamında gezinmek için giderek daha önemli hale geliyor.
- Mutlu Yayın: Bu blogun Netflix dünyasına aydınlatıcı ve eğlenceli bir yolculuk olduğunu umarız ve sürekli değişen içerik tekliflerindeki büyüleyici hikayeleri keşfetmenizi öneririz. Verilerin akış maceralarınıza rehberlik etmesine izin verin!
Resmi Belgeler ve Kaynaklar
Lütfen analizimizde kullanılan kütüphanelerin resmi bağlantılarını aşağıda bulabilirsiniz. Bu kitaplıklar tarafından sağlanan yöntemler ve işlevler hakkında daha fazla bilgi için bu bağlantılara başvurabilirsiniz:
- Pandalar: https://pandas.pydata.org/
- Dizi: https://numpy.org/
- matplotlib: https://matplotlib.org/
- Bilim: https://scipy.org/
- Denizde doğan: https://seaborn.pydata.org/
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoAiStream. Web3 Veri Zekası. Bilgi Genişletildi. Buradan Erişin.
- Adryenn Ashley ile Geleceği Basmak. Buradan Erişin.
- PREIPO® ile PRE-IPO Şirketlerinde Hisse Al ve Sat. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/06/netflix-case-study-eda-unveiling-data-driven-strategies-for-streaming/

