Giriş
Veri bilimi denildiğinde akla ilk gelen şey not defterleri üzerinde model oluşturmak ve veriyi eğitmektir. Ancak gerçek dünyadaki veri biliminde durum böyle değil. Gerçek dünyada veri bilimcileri modeller oluşturur ve bunları üretime koyar. Üretim ortamında modelin geliştirilmesi, devreye alınması ve güvenilirliği ile verimli ve ölçeklenebilir operasyonları kolaylaştırmak arasında bir boşluk vardır. Veri bilimcilerin kullandığı yer burasıdır MLO'lar (Makine Öğrenimi İşlemleri) üretim ortamında ML uygulamaları oluşturmak ve dağıtmak için. Bu makalede, MLOps kullanarak bir müşteri kaybı tahmin projesi oluşturup dağıtacağız.

Öğrenme hedefleri
Bu yazıda şunları öğreneceksiniz:
- Projeye genel bakış
- ZenML ve MLOPS temellerini tanıtacağız.
- Tahmin için modeli yerel olarak nasıl dağıtacağınızı öğrenin
- Veri ön işleme ve mühendislik, eğitim ve modeli değerlendirme konularına girin
Bu makale, Veri Bilimi Blogatonu.
İçindekiler
Projeye Genel Bakış
Öncelikle projemizin ne olduğunu anlamamız gerekiyor. Bu proje için bir telekom şirketinden bir veri setimiz var. Şimdi kullanıcının şirket hizmetine devam edip etmeyeceğini tahmin etmek için bir model oluşturalım. Bu ML uygulamasını ZenmML'in yardımını kullanarak oluşturacağız ve ML Akışı. Bu projemizin iş akışıdır.
Projemizin İş Akışı
- Veri koleksiyonu
- Veri ön işleme
- Eğitim Modeli
- Modeli değerlendir
- açılma
MLOps nedir?
MLOps, geliştirmeden dağıtıma ve devam eden bakıma kadar uçtan uca bir makine öğrenimi yaşam döngüsüdür. MLOps, ölçeklenebilirlik, güvenilirlik ve verimlilik sağlarken makine öğrenimi modellerinin tüm yaşam döngüsünü kolaylaştırma ve otomatikleştirme uygulamasıdır.
Basit bir örnekle açıklayalım:
Şehrinizde bir gökdelen inşa ettiğinizi hayal edin. Binanın inşaatı tamamlandı. Ama elektriği, suyu, drenaj sistemi vs. yok. Gökdelen işlevsiz ve kullanışsız olacak.
Aynı durum makine öğrenimi modelleri için de geçerlidir. Bu modeller, modelin dağıtımı, ölçeklenebilirlik ve uzun vadeli bakım dikkate alınmadan tasarlanırsa etkisiz ve kullanışsız hale gelebilir. Bu, üretim ortamlarında kullanılmak üzere makine öğrenimi modelleri oluştururken veri bilimcileri için büyük bir engel teşkil ediyor.
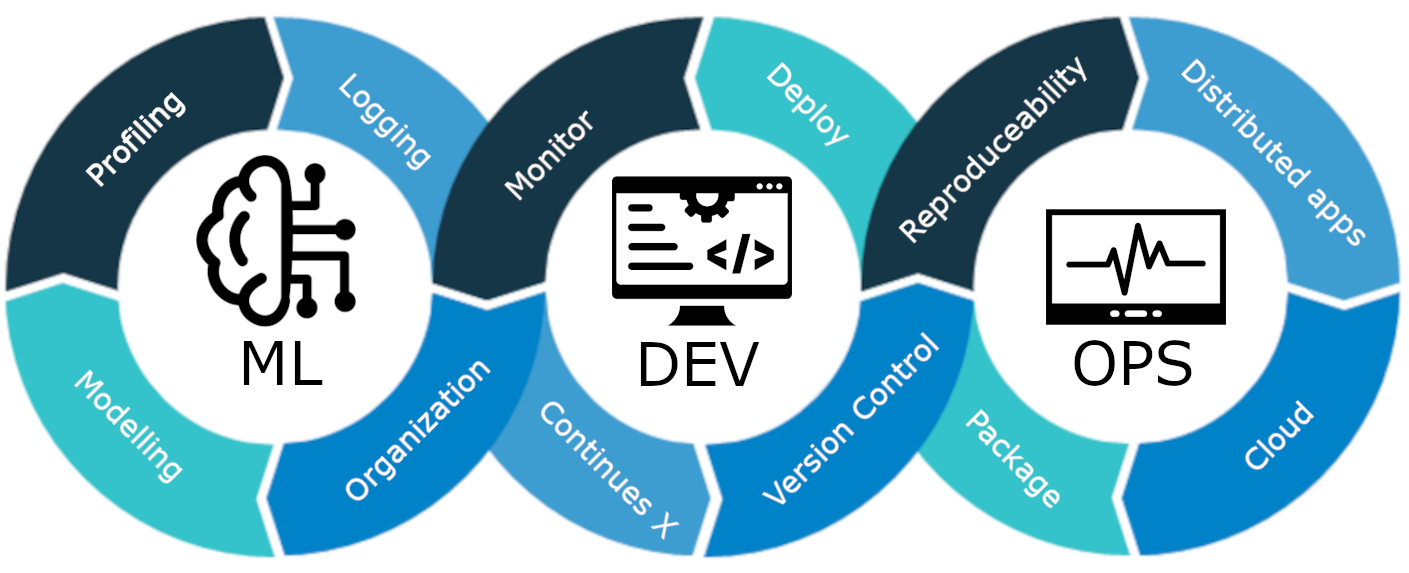
MLOps, makine öğrenimi modellerinin üretimine, dağıtımına ve uzun vadeli bakımına rehberlik eden bir dizi en iyi uygulama ve stratejidir. Bu modellerin yalnızca doğru tahminler sunmakla kalmayıp aynı zamanda şirketler için sağlam, ölçeklenebilir ve değerli varlıklar olarak kalmasını da sağlar. Dolayısıyla, MLOps olmadan tüm bu görevleri verimli bir şekilde yapmak bir kabus olacaktır ki bu da zorludur. Bu projemizde MLOps'un nasıl çalıştığını, farklı aşamalarını ve Müşteri Oluşturma konusunda uçtan uca bir projeyi anlatacağız. kayıp tahmini modeli.
ZenML'le tanışın
ZenML, taşınabilir ve üretime hazır işlem hatları oluşturmaya yardımcı olan açık kaynaklı bir MLOPS Çerçevesidir. ZenML Çerçevesi bu projeyi MLOPS kullanarak yapmamıza yardımcı olacak.
⚠️Eğer Windows kullanıcısıysanız PC'ye wsl kurmayı deneyin. Zenml Windows'ta desteklenmez.
Projelere geçmeden önce.
MLOPS'un Temel Kavramları
- Basamaklar: Adımlar, bir işlem hattı veya iş akışındaki tek görev birimleridir. Her adım, bir makine öğrenimi iş akışını geliştirmek için gerçekleştirilmesi gereken belirli bir eylemi veya işlemi temsil eder. Örneğin veri temizleme, veri ön işleme, eğitim modelleri vb. bir makine öğrenimi modeli geliştirmenin belirli adımlarıdır.
- Boru Hatları: Makine öğrenimi görevleri için yapılandırılmış ve otomatikleştirilmiş bir süreç oluşturmak üzere birden çok adımı birbirine bağlarlar. örneğin veri işleme hattı, model değerlendirme hattı ve model eğitim hattı için.
Başlamak
Proje için sanal bir ortam oluşturun:
conda create -n churn_prediction python=3.9Daha sonra şu kütüphaneleri yükleyin:
pip install numpy pandas matplotlib scikit-learnBunu yükledikten sonra ZenML'i yükleyin:
pip install zenml["server"]Daha sonra ZenML deposunu başlatın.
zenml init
Ekranınızda bunu gösteriyorsa devam etmek için yeşil bir bayrak alacaksınız. Bir klasör başlatıldıktan sonra dizininizde .zenml oluşturulacaktır.
Dizindeki veriler için bir klasör oluşturun. Buradaki verileri alın Link:
Bu yapıya göre klasörler oluşturun.
Veri koleksiyonu
Bu adımda csv dosyamızdan verileri içe aktaracağız. Bu veriler, temizleme ve kodlama sonrasında modeli eğitmek için kullanılacaktır.
Bir dosya oluştur ingest_data.py klasörün içinde adımlar.
import pandas as pd
import numpy as np
import logging
from zenml import step class IngestData: """ Ingesting data to the workflow. """ def __init__(self, path:str) -> None: """ Args: data_path(str): path of the datafile """ self.path = path def get_data(self): df = pd.read_csv(self.path) logging.info("Reading csv file successfully completed.") return df @step(enable_cache = False)
def ingest_df(data_path:str) -> pd.DataFrame: """ ZenML step for ingesting data from a CSV file. """ try: #Creating an instance of IngestData class and ingest the data ingest_data = IngestData(data_path) df = ingest_data.get_data() logging.info("Ingesting data completed") return df except Exception as e: #Log an error message if data ingestion fails and raise the exception logging.error("Error while ingesting data") raise eİşte proje Link.
Bu kodda ilk olarak veri alımı mantığını kapsüllemek için IngestData sınıfını oluşturduk. Sonra bir oluşturduk ZenML adım, alma_df, veri toplama hattının ayrı bir birimidir.
Klasör ardışık düzeni içinde training_pipeline.py dosyası oluşturuluyor.
Kodu yaz
from zenml import pipeline from steps.ingest_data import ingest_df #Define a ZenML pipeline called training_pipeline. @pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. Args: data_path (str): The path to the data to be ingested. ''' df = ingest_df(data_path=data_path)Burada, bir dizi adımı kullanarak bir makine öğrenimi modelini eğitmek için bir eğitim hattı oluşturuyoruz.
Ardından adlı bir dosya oluşturun run_pipeline.py çalıştırmak için temel dizinde boru hattı.
from pipelines.training_pipeline import train_pipeline if __name__ == '__main__': #Run the pipeline train_pipeline(data_path="/mnt/e/Customer_churn/data/WA_Fn-UseC_-Telco-Customer-Churn.csv")Bu kod boru hattını çalıştırmak için kullanılır.
Artık Veri alımı ardışık düzenini tamamladık. Hadi çalıştıralım.
Komutu terminalinizde çalıştırın:
python run_pipeline.py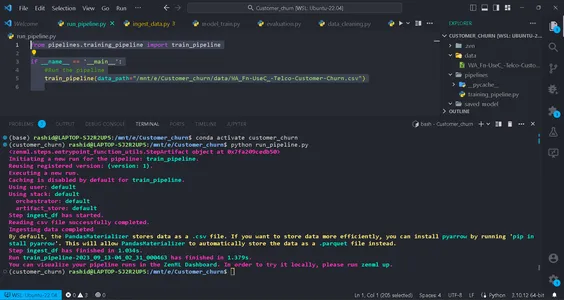
Daha sonra training_pipeline'ın başarıyla tamamlandığını gösteren komutları görebilirsiniz.
Veri ön işleme
Bu adımda verileri temizlemek için farklı stratejiler oluşturacağız. İstenmeyen sütunlar çıkarılır ve kategorik sütunlar Etiket kodlaması kullanılarak kodlanır. Son olarak veriler eğitim ve test verilerine bölünecektir.
Src Klasöründe clean_data.py adında bir dosya oluşturun.
Bu dosyada verileri temizlemeye yönelik strateji sınıfları oluşturacağız.
import pandas as pd
import numpy as np
import logging
from sklearn.model_selection import train_test_split
from abc import abstractmethod, ABC
from typing import Union
from sklearn.preprocessing import LabelEncoder class DataStrategy(ABC): @abstractmethod def handle_data(self, df:pd.DataFrame) -> Union[pd.DataFrame,pd.Series]: pass # Data Preprocessing strategy
class DataPreprocessing(DataStrategy): def handle_data(self, df: pd.DataFrame) -> Union[pd.DataFrame, pd.Series]: try: df['TotalCharges'] = df['TotalCharges'].replace(' ', 0).astype(float) df.drop('customerID', axis=1, inplace=True) df['Churn'] = df['Churn'].replace({'Yes': 1, 'No': 0}).astype(int) service = ['PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies'] for col in service: df[col] = df[col].replace({'No phone service': 'No', 'No internet service': 'No'}) logging.info("Length of df: ", len(df.columns)) return df except Exception as e: logging.error("Error in Preprocessing", e) raise e # Feature Encoding Strategy
class LabelEncoding(DataStrategy): def handle_data(self, df: pd.DataFrame) -> Union[pd.DataFrame, pd.Series]: try: df_cat = ['gender', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod'] lencod = LabelEncoder() for col in df_cat: df[col] = lencod.fit_transform(df[col]) logging.info(df.head()) return df except Exception as e: logging.error(e) raise e # Data splitting Strategy
class DataDivideStrategy(DataStrategy): def handle_data(self, df:pd.DataFrame) -> Union[pd.DataFrame, pd.Series]: try: X = df.drop('Churn', axis=1) y = df['Churn'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1) return X_train, X_test, y_train, y_test except Exception as e: logging.error("Error in DataDividing", e) raise e
Bu kod, makine öğrenimi için modüler bir veri ön işleme hattı uygular. Tahmine dayalı modelleme için veri ön işleme, özellik kodlama ve veri temizlemenin Veri Kodlama adımlarına yönelik stratejiler içerir.
1. Veri Ön İşleme: Bu sınıf, veri kümesindeki istenmeyen sütunların kaldırılmasından ve eksik değerlerin (NA değerleri) işlenmesinden sorumludur.
2. Etiket Kodlaması: LabelEncoding sınıfı, kategorik değişkenleri makine öğrenimi algoritmalarının etkili bir şekilde çalışabileceği sayısal bir formatta kodlamak için tasarlanmıştır. Metin tabanlı kategorileri sayısal değerlere dönüştürür.
3. DataDivideStratejisi: Bu sınıf, veri kümesini bağımsız değişkenler (X) ve bağımlı değişkenler (y) olarak ayırır. Daha sonra verileri eğitim ve test setlerine böler.
Verilerimizi makine öğrenimi görevlerine hazırlamak için bunları adım adım uygulayacağız.
Bu stratejiler, model eğitimi ve değerlendirmesi için verilerin doğru şekilde yapılandırılmasını ve biçimlendirilmesini sağlar.
oluşturmak data_cleaning.py içinde adımlar klasör.
import pandas as pd
import numpy as np
from src.clean_data import DataPreprocessing, DataDivideStrategy, LabelEncoding
import logging
from typing_extensions import Annotated
from typing import Tuple
from zenml import step # Define a ZenML step for cleaning and preprocessing data
@step(enable_cache=False)
def cleaning_data(df: pd.DataFrame) -> Tuple[ Annotated[pd.DataFrame, "X_train"], Annotated[pd.DataFrame, "X_test"], Annotated[pd.Series, "y_train"], Annotated[pd.Series, "y_test"],
]: try: # Instantiate the DataPreprocessing strategy data_preprocessing = DataPreprocessing() # Apply data preprocessing to the input DataFrame data = data_preprocessing.handle_data(df) # Instantiate the LabelEncoding strategy feature_encode = LabelEncoding() # Apply label encoding to the preprocessed data df_encoded = feature_encode.handle_data(data) # Log information about the DataFrame columns logging.info(df_encoded.columns) logging.info("Columns:", len(df_encoded)) # Instantiate the DataDivideStrategy strategy split_data = DataDivideStrategy() # Split the encoded data into training and testing sets X_train, X_test, y_train, y_test = split_data.handle_data(df_encoded) # Return the split data as a tuple return X_train, X_test, y_train, y_test except Exception as e: # Handle and log any errors that occur during data cleaning logging.error("Error in step cleaning data", e) raise eBu adımda oluşturduğumuz stratejileri hayata geçirdik. clean_data.py
Bunu uygulayalım adım in training_pipeline.py
from zenml import pipeline #importing steps from steps.ingest_data import ingest_df
from steps.data_cleaning import cleaning_data
import logging #Define a ZenML pipeline called training_pipeline.
@pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. ''' df = ingest_df(data_path=data_path) X_train, X_test, y_train, y_test = cleaning_data(df=df)Bu kadar; eğitim hattındaki veri ön işleme adımımızı tamamladık.
Model Eğitimi
Şimdi bu projenin modelini oluşturacağız. Burada ikili bir sınıflandırma problemini öngörüyoruz. Kullanabiliriz lojistik regresyon. Odak noktamız modelin doğruluğu olmayacak. MLOps kısmını temel alacaktır.
Lojistik regresyon hakkında bilgisi olmayanlar için buradan okuyabilirsiniz. Veri ön işleme adımında uyguladığımız adımların aynısını uygulayacağız. Öncelikle bir dosya oluşturacağız training_model.py içinde src klasör.
import pandas as pd
from sklearn.linear_model import LogisticRegression
from abc import ABC, abstractmethod
import logging #Abstract model
class Model(ABC): @abstractmethod def train(self,X_train:pd.DataFrame,y_train:pd.Series): """ Trains the model on given data """ pass class LogisticReg(Model): """ Implementing the Logistic Regression model. """ def train(self, X_train: pd.DataFrame, y_train: pd.Series): """ Training the model Args: X_train: pd.DataFrame, y_train: pd.Series """ logistic_reg = LogisticRegression() logistic_reg.fit(X_train,y_train) return logistic_regTüm modellerin uygulaması gereken bir 'eğitim' yöntemiyle soyut bir Model sınıfı tanımlarız. LogisticReg sınıfı, lojistik regresyon kullanan özel bir uygulamadır. Bir sonraki adım, adımlar klasöründe config.py adlı bir dosyanın yapılandırılmasını içerir. Adımlar klasöründe config.py adlı bir dosya oluşturun.
Model Parametrelerini Yapılandırma
from zenml.steps import BaseParameters """
This file is used for used for configuring
and specifying various parameters related to your machine learning models and training process """ class ModelName(BaseParameters): """ Model configurations """ model_name: str = "logistic regression"Adı geçen dosyada config.py, içinde adımlar klasöründe, makine öğrenimi modelinizle ilgili parametreleri yapılandırıyorsunuz. Miras alan bir ModelName sınıfı yaratırsınız. Temel Parametreler Model adını belirtmek için. Bu, model tipini değiştirmeyi kolaylaştırır.
import logging import pandas as pd
from src.training_model import LogisticReg
from zenml import step
from .config import ModelName #Define a step called train_model
@step(enable_cache=False)
def train_model(X_train:pd.DataFrame,y_train:pd.Series,config:ModelName): """ Trains the data based on the configured model """ try: model = None if config == "logistic regression": model = LogisticReg() else: raise ValueError("Model name is not supported") trained_model = model.train(X_train=X_train,y_train=y_train) return trained_model except Exception as e: logging.error("Error in step training model",e) raise eAdımlar klasöründeki model_train.py adlı dosyada, ZenML kullanarak train_model adlı bir adımı tanımlayın. Bu adımın amacı, modelin adına göre bir makine öğrenimi modeli yetiştirmektir. Model adı.
Programda
Yapılandırılmış model adını kontrol edin. Eğer "lojistik regresyon" ise, LogisticReg modelinin bir örneğini oluşturduk ve bunu sağlanan eğitim verileriyle (X_train ve y_train) eğittik. Model adı desteklenmiyorsa bir hata oluşturursunuz. Bu işlem sırasında ortaya çıkan hatalar günlüğe kaydedilir ve hata ortaya çıkar.
Bundan sonra bu adımı uygulayacağız. training_pipeline.py
from zenml import pipeline from steps.ingest_data import ingest_df
from steps.data_cleaning import cleaning_data
from steps.model_train import train_model
import logging #Define a ZenML pipeline called training_pipeline.
@pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. ''' #step ingesting data: returns the data. df = ingest_df(data_path=data_path) #step to clean the data. X_train, X_test, y_train, y_test = cleaning_data(df=df) #training the model model = train_model(X_train=X_train,y_train=y_train)Şimdi işlem hattında train_model adımını uyguladık. Böylece model_train.py adımı tamamlanmış olur.
Değerlendirme Modeli
Bu adımda modelimizin ne kadar verimli olduğunu değerlendireceğiz. Bunun için test verilerini tahmin etmede doğruluk puanını kontrol edeceğiz. İlk olarak, boru hattında kullanacağımız stratejileri oluşturacağız.
Adlı bir dosya oluşturun değerlendirme_model.py klasörde src.
import logging
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
from abc import ABC, abstractmethod
import numpy as np # Abstract class for model evaluation
class Evaluate(ABC): @abstractmethod def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray) -> float: """ Abstract method to evaluate a machine learning model's performance. Args: y_true (np.ndarray): True labels. y_pred (np.ndarray): Predicted labels. Returns: float: Evaluation result. """ pass #Class to calculate accuracy score
class Accuracy_score(Evaluate): """ Calculates and returns the accuracy score for a model's predictions. """ def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray) -> float: try: accuracy_scr = accuracy_score(y_true=y_true, y_pred=y_pred) * 100 logging.info("Accuracy_score:", accuracy_scr) return accuracy_scr except Exception as e: logging.error("Error in evaluating the accuracy of the model",e) raise e
#Class to calculate Precision score
class Precision_Score(Evaluate): def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray) -> float: """ Generates and returns a precision score for a model's predictions. """ try: precision = precision_score(y_true=y_true,y_pred=y_pred) logging.info("Precision score: ",precision) return float(precision) except Exception as e: logging.error("Error in calculation of precision_score",e) raise e class F1_Score(Evaluate): def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray): """ Generates and returns an F1 score for a model's predictions. """ try: f1_scr = f1_score(y_pred=y_pred, y_true=y_true) logging.info("F1 score: ", f1_scr) return f1_scr except Exception as e: logging.error("Error in calculating F1 score", e) raise e Artık değerlendirme stratejilerini oluşturduğumuza göre, bunları modeli değerlendirmek için kullanacağız. Kodu şurada uygulayalım adım değerlendirme_model.py adımlar klasöründe. Burada hatırlama puanı, doğruluk puanı ve kesinlik puanı, modeli değerlendirmek için metrik olarak kullandığımız stratejilerdir.
Bunları adım adım uygulayalım. Adlı bir dosya oluşturun değerlendirme.py adımlarla:
import logging
import pandas as pd
import numpy as np
from zenml import step
from src.evaluate_model import ClassificationReport, ConfusionMatrix, Accuracy_score
from typing import Tuple
from typing_extensions import Annotated
from sklearn.base import ClassifierMixin @step(enable_cache=False)
def evaluate_model( model: ClassifierMixin, X_test: pd.DataFrame, y_test: pd.Series
) -> Tuple[ Annotated[np.ndarray,"confusion_matix"], Annotated[str,"classification_report"], Annotated[float,"accuracy_score"], Annotated[float,"precision_score"], Annotated[float,"recall_score"] ]: """ Evaluate a machine learning model's performance using common metrics. """ try: y_pred = model.predict(X_test) precision_score_class = Precision_Score() precision_score = precision_score_class.evaluate_model(y_pred=y_pred,y_true=y_test) mlflow.log_metric("Precision_score ",precision_score) accuracy_score_class = Accuracy_score() accuracy_score = accuracy_score_class.evaluate_model(y_true=y_test, y_pred=y_pred) logging.info("accuracy_score:",accuracy_score) return accuracy_score, precision_score except Exception as e: logging.error("Error in evaluating model",e) raise eŞimdi bu adımı boru hattında uygulayalım. training_pipeline.py dosyasını güncelleyin:
Bu kod bir tanımlar değerlendirme_modeli makine öğrenimi hattına adım atın. Eğitimli bir sınıflandırma modeli (model), bağımsız test verileri (X_testi) ve test verileri için doğru etiketler (y_testi) giriş olarak. Daha sonra ortak sınıflandırma ölçümlerini kullanarak modelin performansını değerlendirir ve aşağıdaki gibi sonuçları döndürür: hassaslık_skoru ve doğruluk_skoru.
Şimdi bu adımı boru hattında uygulayalım. Güncelleme training_pipeline.py:
from zenml import pipeline from steps.ingest_data import ingest_df
from steps.data_cleaning import cleaning_data
from steps.model_train import train_model
from steps.evaluation import evaluate_model
import logging #Define a ZenML pipeline called training_pipeline.
@pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. Args: data_path (str): The path to the data to be ingested. ''' #step ingesting data: returns the data. df = ingest_df(data_path=data_path) #step to clean the data. X_train, X_test, y_train, y_test = cleaning_data(df=df) #training the model model = train_model(X_train=X_train,y_train=y_train) #Evaluation metrics of data accuracy_score, precision_score = evaluate_model(model=model,X_test=X_test, y_test=y_test)Bu kadar. Artık eğitim hattını tamamladık. Koşmak
python run_pipeline.py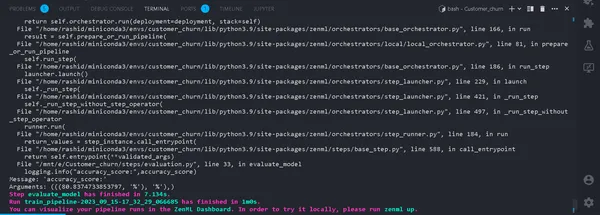
Terminalde. Başarılı bir şekilde çalışırsa. Artık yerel olarak bir eğitim hattını çalıştırmayı tamamladığımıza göre şu şekilde görünecek:
Deney Takipçisi nedir?
Deney izleyici, makine öğrenimi geliştirme sürecindeki çeşitli deneyleri kaydetmek, izlemek ve yönetmek için kullanılan bir makine öğrenimi aracıdır.
Veri bilimcileri en iyi sonuçları elde etmek için farklı modeller üzerinde denemeler yapar. Bu nedenle verileri takip etmeye ve farklı modeller kullanmaya devam etmeleri gerekiyor. Bunu bir Excel sayfası kullanarak manuel olarak kaydetmeleri onlar için çok zor olacaktır.
ML akışı
MLflow, makine öğrenimindeki deneyleri verimli bir şekilde izlemek ve yönetmek için değerli bir araçtır. Deney izlemeyi, model yinelemelerini ve ilgili verileri izlemeyi otomatikleştirir. Bu, model geliştirme sürecini kolaylaştırır ve sonuçların görselleştirilmesi için kullanıcı dostu bir arayüz sağlar.
MLflow'u ZenML ile entegre etmek, makine öğrenimi operasyonları çerçevesinde deneme sağlamlığını ve yönetimini artırır.
ZenML ile MLflow'u kurmak için şu adımları izleyin:
- MLflow entegrasyonunu yükleyin:
- MLflow entegrasyonunu yüklemek için aşağıdaki komutu kullanın:
zenml integration install mlflow -y2. MLflow deneme izleyicisini kaydedin:
Bu komutu kullanarak MLflow'a bir deneme izleyicisi kaydedin:
zenml experiment-tracker register mlflow_tracker --flavor=mlflow3. Bir Yığın Kaydetme:
ZenML'de Yığın, ML iş akışınızdaki görevleri tanımlayan bileşenlerin bir koleksiyonudur. ML işlem hattı adımlarının verimli bir şekilde organize edilmesine ve yönetilmesine yardımcı olur. Şunlarla bir Yığın kaydedin:
Daha fazla ayrıntıyı adresinde bulabilirsiniz. belgeleme.
zenml model-deployer register mlflow --flavor=mlflow
zenml stack register mlflow_stack -a default -o default -d mlflow -e mlflow_tracker --setBu, Yığınınızı yapı depolaması, orkestratörler, dağıtım hedefleri ve deneme takibi için belirli ayarlarla ilişkilendirir.
4. Yığın Ayrıntılarını Görüntüle:
Yığınınızın bileşenlerini aşağıdakileri kullanarak görüntüleyebilirsiniz:
zenml stack describeBu, "mlflow_tracker" Yığınıyla ilişkili bileşenleri görüntüler.
Şimdi eğitim modeline bir deneme izleyicisi uygulayalım ve modeli değerlendirelim:
Bileşenlerin adını mlflow_tracker olarak görebilirsiniz.
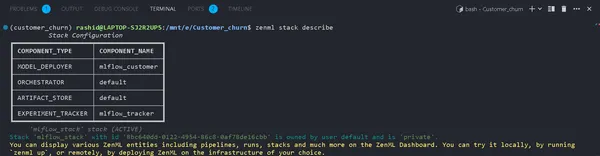
ZenML Experiment Tracker'ı Kurma
Öncelikle güncellemeye başlayın train_model.py:
import logging
import mlflow
import pandas as pd
from src.training_model import LogisticReg
from sklearn.base import ClassifierMixin
from zenml import step
from .config import ModelName
#import from zenml.client import Client # Obtain the active stack's experiment tracker
experiment_tracker = Client().active_stack.experiment_tracker #Define a step called train_model
@step(experiment_tracker = experiment_tracker.name,enable_cache=False)
def train_model( X_train:pd.DataFrame, y_train:pd.Series, config:ModelName ) -> ClassifierMixin: """ Trains the data based on the configured model Args: X_train: pd.DataFrame = Independent training data, y_train: pd.Series = Dependent training data. """ try: model = None if config.model_name == "logistic regression": #Automatically logging scores, model etc.. mlflow.sklearn.autolog() model = LogisticReg() else: raise ValueError("Model name is not supported") trained_model = model.train(X_train=X_train,y_train=y_train) logging.info("Training model completed.") return trained_model except Exception as e: logging.error("Error in step training model",e) raise eBu kodda, deneme izleyiciyi kullanarak ayarladık. mlflow.sklearn.autolog()Modelle ilgili tüm ayrıntıları otomatik olarak günlüğe kaydeden, deneyleri izlemeyi ve analiz etmeyi kolaylaştıran.
içinde değerlendirme.py
from zenml.client import Client experiment_tracker = Client().active_stack.experiment_tracker @step(experiment_tracker=experiment_tracker.name, enable_cache = False)Ardışık Düzeni Çalıştırma
Güncelleyin run_pipeline.py komut dosyası şu şekilde:
from pipelines.training_pipeline import train_pipeline
from zenml.client import Client
if __name__ == '__main__': #printimg the experiment tracking uri print(Client().active_stack.experiment_tracker.get_tracking_uri()) #Run the pipeline train_pipeline(data_path="/mnt/e/Customer_churn/data/WA_Fn-UseC_-Telco-Customer-Churn.csv")Kopyalayın ve bu komuta yapıştırın.
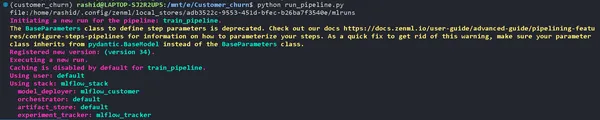
mlflow ui --backend-store-uri "--uri on the top of "file:/home/ "Deneylerinizi Keşfedin
MLflow kullanıcı arayüzünü açmak için yukarıdaki komut tarafından oluşturulan bağlantıya tıklayın. Burada bir bilgi hazinesi bulacaksınız:
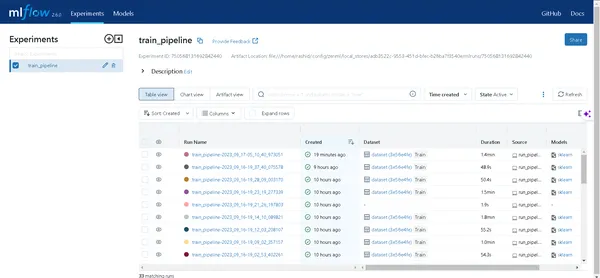
- Boru Hatları: Çalıştırdığınız tüm işlem hatlarına kolayca erişin.
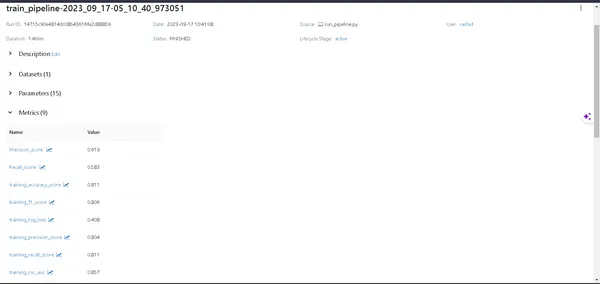
- Model Detayları: Modeliniz hakkındaki her ayrıntıyı ortaya çıkarmak için bir ardışık düzene tıklayın.
- Metrikleri: Modelinizin performansını görselleştirmek için ölçümler bölümüne dalın.
Artık makine öğrenimi deneme takibinizi ZenML ve MLflow ile fethedebilirsiniz!
açılma
Bir sonraki bölümde bu modeli dağıtacağız. Bu kavramları bilmeniz gerekir:
a). Sürekli Dağıtım Boru Hattı
Bu işlem hattı model dağıtım sürecini otomatikleştirecektir. Bir model değerlendirme kriterlerini geçtikten sonra otomatik olarak üretim ortamına dağıtılır. Örneğin veri ön işleme, veri temizleme, veriyi eğitme, model değerlendirme vb. ile başlar.
a). Çıkarım Dağıtım Ardışık Düzeni
Çıkarım Dağıtım Hattı, gerçek zamanlı veya toplu çıkarım için makine öğrenimi modellerinin dağıtımına odaklanır. Çıkarım Dağıtım Hattı, üretim ortamında tahminler yapmak için modellerin dağıtılmasında uzmanlaşmıştır. Örneğin kullanıcıların metin gönderebileceği bir API uç noktası kurar. Modelin kullanılabilirliğini ve ölçeklenebilirliğini sağlar ve gerçek zamanlı performansını izler. Bu işlem hatları, makine öğrenimi sistemlerinin verimliliğini ve etkinliğini korumak için önemlidir. Şimdi sürekli boru hattını uygulayacağız.
Adlı bir dosya oluşturun dağıtım_pipeline.py boru hatları klasöründe.
import numpy as np
import json
import logging
import pandas as pd
from zenml import pipeline, step
from zenml.config import DockerSettings
from zenml.constants import DEFAULT_SERVICE_START_STOP_TIMEOUT
from zenml.integrations.constants import MLFLOW
from zenml.integrations.mlflow.model_deployers.mlflow_model_deployer import ( MLFlowModelDeployer,
)
from zenml.integrations.mlflow.services import MLFlowDeploymentService
from zenml.integrations.mlflow.steps import mlflow_model_deployer_step
from zenml.steps import BaseParameters, Output
from src.clean_data import FeatureEncoding
from .utils import get_data_for_test
from steps.data_cleaning import cleaning_data
from steps.evaluation import evaluate_model
from steps.ingest_data import ingest_df # Define Docker settings with MLflow integration
docker_settings = DockerSettings(required_integrations = {MLFLOW}) #Define class for deployment pipeline configuration
class DeploymentTriggerConfig(BaseParameters): min_accuracy:float = 0.92 @step def deployment_trigger( accuracy: float, config: DeploymentTriggerConfig,
): """ It trigger the deployment only if accuracy is greater than min accuracy. Args: accuracy: accuracy of the model. config: Minimum accuracy thereshold. """ try: return accuracy >= config.min_accuracy except Exception as e: logging.error("Error in deployment trigger",e) raise e # Define a continuous pipeline
@pipeline(enable_cache=False,settings={"docker":docker_settings})
def continuous_deployment_pipeline( data_path:str, min_accuracy:float = 0.92, workers: int = 1, timeout: int = DEFAULT_SERVICE_START_STOP_TIMEOUT
): df = ingest_df(data_path=data_path) X_train, X_test, y_train, y_test = cleaning_data(df=df) model = train_model(X_train=X_train, y_train=y_train) accuracy_score, precision_score = evaluate_model(model=model, X_test=X_test, y_test=y_test) deployment_decision = deployment_trigger(accuracy=accuracy_score) mlflow_model_deployer_step( model=model, deploy_decision = deployment_decision, workers = workers, timeout = timeout )Makine Öğrenimi Projesi için ZenML Çerçevesi
Bu kod, ZenML Çerçevesini kullanan bir makine öğrenimi projesi için sürekli dağıtımı tanımlar.
1. Gerekli kitaplıkları içe aktarın: Modelin dağıtımı için gerekli kitaplıkların içe aktarılması.
2. Docker Ayarları: Docker, Docker ayarlarını MLflow ile kullanılacak şekilde yapılandırarak bu modellerin tutarlı bir şekilde paketlenmesine ve çalıştırılmasına yardımcı olur.
3. DeploymentTriggerConfig: Bir modelin konuşlandırılması için minimum doğruluk eşiğinin yapılandırıldığı sınıftır.
4. dağıtım_tetikleyici: Model doğruluğu minimum doğruluğu aşarsa bu adım geri dönecektir.
5. sürekli_deployment_pipeline: Bu işlem hattı birkaç adımdan oluşur: verilerin alınması, verilerin temizlenmesi, modelin eğitilmesi ve modelin değerlendirilmesi. Ve model yalnızca minimum doğruluk eşiğini karşıladığında konuşlandırılacaktır.
Daha sonra, çıkarım hattını dağıtım_pipeline.py dosyasında uygulayacağız.
import logging
import pandas as pd
from zenml.steps import BaseParameters, Output
from zenml.integrations.mlflow.model_deployers.mlflow_model_deployer import MLFlowModelDeployer
from zenml.integrations.mlflow.services import MLFlowDeploymentService class MLFlowDeploymentLoaderStepParameters(BaseParameters): pipeline_name: str step_name: str running: bool = True @step(enable_cache=False)
def dynamic_importer() -> str: data = get_data_for_test() return data @step(enable_cache=False)
def prediction_service_loader( pipeline_name: str, pipeline_step_name: str, running: bool = True, model_name: str = "model",
) -> MLFlowDeploymentService: model_deployer = MLFlowModelDeployer.get_active_model_deployer() existing_services = model_deployer.find_model_server( pipeline_name=pipeline_name, pipeline_step_name=pipeline_step_name, model_name=model_name, running=running, ) if not existing_services: raise RuntimeError( f"No MLflow prediction service deployed by the " f"{pipeline_step_name} step in the {pipeline_name} " f"pipeline for the '{model_name}' model is currently " f"running." ) return existing_services[0] @step
def predictor(service: MLFlowDeploymentService, data: str) -> np.ndarray: service.start(timeout=10) data = json.loads(data) prediction = service.predict(data) return prediction @pipeline(enable_cache=False, settings={"docker": docker_settings})
def inference_pipeline(pipeline_name: str, pipeline_step_name: str): batch_data = dynamic_importer() model_deployment_service = prediction_service_loader( pipeline_name=pipeline_name, pipeline_step_name=pipeline_step_name, running=False, ) prediction = predictor(service=model_deployment_service, data=batch_data) return prediction
Bu kod, MLflow aracılığıyla dağıtılmış bir makine öğrenimi modelini kullanarak tahminler yapmak için bir işlem hattı oluşturur. Verileri içe aktarır, dağıtılan modeli yükler ve bunu tahminlerde bulunmak için kullanır.
Fonksiyonu oluşturmamız gerekiyor get_data_for_test() in utils.py boru hatları klasöründe. Böylece kodumuzu daha verimli yönetebiliriz.
import logging import pandas as pd from src.clean_data import DataPreprocessing, LabelEncoding # Function to get data for testing purposes
def get_data_for_test(): try: df = pd.read_csv('./data/WA_Fn-UseC_-Telco-Customer-Churn.csv') df = df.sample(n=100) data_preprocessing = DataPreprocessing() data = data_preprocessing.handle_data(df) # Instantiate the FeatureEncoding strategy label_encode = LabelEncoding() df_encoded = label_encode.handle_data(data) df_encoded.drop(['Churn'],axis=1,inplace=True) logging.info(df_encoded.columns) result = df_encoded.to_json(orient="split") return result except Exception as e: logging.error("e") raise eŞimdi modeli dağıtmak ve dağıtılan modeli tahmin etmek için oluşturduğumuz işlem hattını uygulayalım.
oluşturmak run_deployment.py proje dizinindeki dosya:
import click # For handling command-line arguments
import logging from typing import cast
from rich import print # For console output formatting # Import pipelines for deployment and inference
from pipelines.deployment_pipeline import (
continuous_deployment_pipeline, inference_pipeline
)
# Import MLflow utilities and components
from zenml.integrations.mlflow.mlflow_utils import get_tracking_uri
from zenml.integrations.mlflow.model_deployers.mlflow_model_deployer import ( MLFlowModelDeployer
)
from zenml.integrations.mlflow.services import MLFlowDeploymentService # Define constants for different configurations: DEPLOY, PREDICT, DEPLOY_AND_PREDICT
DEPLOY = "deploy"
PREDICT = "predict"
DEPLOY_AND_PREDICT = "deploy_and_predict" # Define a main function that uses Click to handle command-line arguments
@click.command()
@click.option( "--config", "-c", type=click.Choice([DEPLOY, PREDICT, DEPLOY_AND_PREDICT]), default=DEPLOY_AND_PREDICT, help="Optionally you can choose to only run the deployment " "pipeline to train and deploy a model (`deploy`), or to " "only run a prediction against the deployed model " "(`predict`). By default both will be run " "(`deploy_and_predict`).",
)
@click.option( "--min-accuracy", default=0.92, help="Minimum accuracy required to deploy the model",
)
def run_main(config:str, min_accuracy:float ): # Get the active MLFlow model deployer component mlflow_model_deployer_component = MLFlowModelDeployer.get_active_model_deployer() # Determine if the user wants to deploy a model (deploy), make predictions (predict), or both (deploy_and_predict) deploy = config == DEPLOY or config == DEPLOY_AND_PREDICT predict = config == PREDICT or config == DEPLOY_AND_PREDICT # If deploying a model is requested: if deploy: continuous_deployment_pipeline( data_path='/mnt/e/Customer_churn/data/WA_Fn-UseC_-Telco-Customer-Churn.csv', min_accuracy=min_accuracy, workers=3, timeout=60 ) # If making predictions is requested: if predict: # Initialize an inference pipeline run inference_pipeline( pipeline_name="continuous_deployment_pipeline", pipeline_step_name="mlflow_model_deployer_step", ) # Print instructions for viewing experiment runs in the MLflow UI print( "You can run:n " f"[italic green] mlflow ui --backend-store-uri '{get_tracking_uri()}" "[/italic green]n ...to inspect your experiment runs within the MLflow" " UI.nYou can find your runs tracked within the " "`mlflow_example_pipeline` experiment. There you'll also be able to " "compare two or more runs.nn" ) # Fetch existing services with the same pipeline name, step name, and model name existing_services = mlflow_model_deployer_component.find_model_server( pipeline_name = "continuous_deployment_pipeline", pipeline_step_name = "mlflow_model_deployer_step", ) # Check the status of the prediction server: if existing_services: service = cast(MLFlowDeploymentService, existing_services[0]) if service.is_running: print( f"The MLflow prediciton server is running locally as a daemon" f"process service and accepts inference requests at: n" f" {service.prediction_url}n" f"To stop the service, run" f"[italic green] zenml model-deployer models delete" f"{str(service.uuid)}'[/italic green]." ) elif service.is_failed: print( f"The MLflow prediciton server is in a failed state: n" f" Last state: '{service.status.state.value}'n" f" Last error: '{service.status.last_error}'" ) else: print( "No MLflow prediction server is currently running. The deployment" "pipeline must run first to train a model and deploy it. Execute" "the same command with the '--deploy' argument to deploy a model." ) # Entry point: If this script is executed directly, run the main function
if __name__ == "__main__": run_main()Bu kod, MLFlow ve ZenMl kullanarak makine öğrenimi modelini yönetmek ve dağıtmak için kullanılan bir komut satırı komut dosyasıdır.
Şimdi modeli dağıtalım.
Bu komutu terminalinizde çalıştırın.
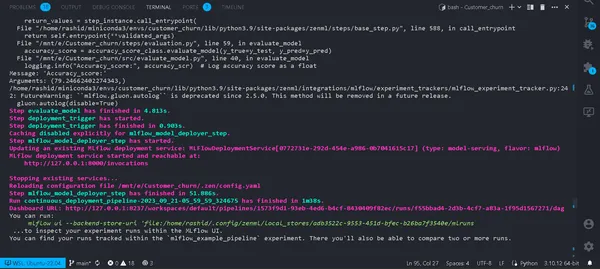
python run_deployment.py --config deploy
Artık modelimizi devreye aldık. İşlem hattınız başarıyla çalıştırılacak ve bunları zenml kontrol panelinde görüntüleyebilirsiniz.
python run_deployment.py --config predictTahmin Sürecini Başlatma
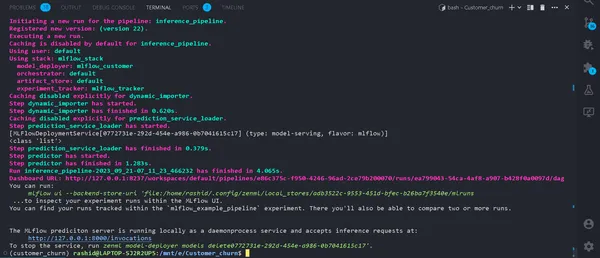
Artık MLFlow tahmin sunucumuz çalışıyor.
Verileri girmek ve sonuçları görmek için bir web uygulamasına ihtiyacımız var. Neden sıfırdan bir web uygulaması oluşturmamız gerektiğini merak ediyor olmalısınız.
Tam olarak değil. Makine öğrenimi modelimiz için hızlı ve kolay ön uç web uygulaması oluşturmaya yardımcı olan açık kaynaklı bir ön uç çerçevesi olan Streamlit'i kullanacağız.
Kitaplığı yükleyin
pip install streamlitProje dizininizde Streamlit_app.py adında bir dosya oluşturun.
import json
import logging
import numpy as np
import pandas as pd
import streamlit as st
from PIL import Image
from pipelines.deployment_pipeline import prediction_service_loader
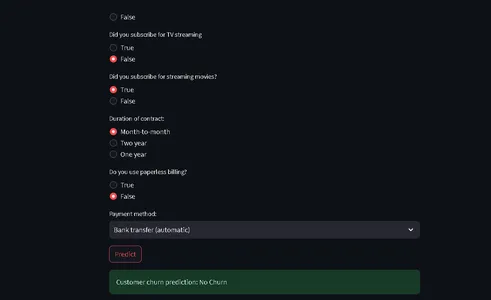
from run_deployment import main def main(): st.title("End to End Customer Satisfaction Pipeline with ZenML") st.markdown( """ #### Problem Statement The objective here is to predict the customer satisfaction score for a given order based on features like order status, price, payment, etc. I will be using [ZenML](https://zenml.io/) to build a production-ready pipeline to predict the customer satisfaction score for the next order or purchase. """ ) st.markdown( """ Above is a figure of the whole pipeline, we first ingest the data, clean it, train the model, and evaluate the model, and if data source changes or any hyperparameter values changes, deployment will be triggered, and (re) trains the model and if the model meets minimum accuracy requirement, the model will be deployed. """ ) st.markdown( """ #### Description of Features This app is designed to predict the customer satisfaction score for a given customer. You can input the features of the product listed below and get the customer satisfaction score. | Models | Description | | ------------- | - | | SeniorCitizen | Indicates whether the customer is a senior citizen. | | tenure | Number of months the customer has been with the company. | | MonthlyCharges | Monthly charges incurred by the customer. | | TotalCharges | Total charges incurred by the customer. | | gender | Gender of the customer (Male: 1, Female: 0). | | Partner | Whether the customer has a partner (Yes: 1, No: 0). | | Dependents | Whether the customer has dependents (Yes: 1, No: 0). | | PhoneService | Whether the customer has dependents (Yes: 1, No: 0). | | MultipleLines | Whether the customer has multiple lines (Yes: 1, No: 0). | | InternetService | Type of internet service (No: 1, Other: 0). | | OnlineSecurity | Whether the customer has online security service (Yes: 1, No: 0). | | OnlineBackup | Whether the customer has online backup service (Yes: 1, No: 0). | | DeviceProtection | Whether the customer has device protection service (Yes: 1, No: 0). | | TechSupport | Whether the customer has tech support service (Yes: 1, No: 0). | | StreamingTV | Whether the customer has streaming TV service (Yes: 1, No: 0). | | StreamingMovies | Whether the customer has streaming movies service (Yes: 1, No: 0). | | Contract | Type of contract (One year: 1, Other: 0). | | PaperlessBilling | Whether the customer has paperless billing (Yes: 1, No: 0). | | PaymentMethod | Payment method (Credit card: 1, Other: 0). | | Churn | Whether the customer has churned (Yes: 1, No: 0). | """ ) payment_options = { 2: "Electronic check", 3: "Mailed check", 1: "Bank transfer (automatic)", 0: "Credit card (automatic)" } contract = { 0: "Month-to-month", 2: "Two year", 1: "One year" } def format_func(PaymentMethod): return payment_options[PaymentMethod] def format_func_contract(Contract): return contract[Contract] display = ("male", "female") options = list(range(len(display))) # Define the data columns with their respective values SeniorCitizen = st.selectbox("Are you senior citizen?", options=[True, False],) tenure = st.number_input("Tenure") MonthlyCharges = st.number_input("Monthly Charges: ") TotalCharges = st.number_input("Total Charges: ") gender = st.radio("gender:", options, format_func=lambda x: display[x]) Partner = st.radio("Do you have a partner? ", options=[True, False]) Dependents = st.radio("Dependents: ", options=[True, False]) PhoneService = st.radio("Do you have phone service? : ", options=[True, False]) MultipleLines = st.radio("Do you Multiplines? ", options=[True, False]) InternetService = st.radio("Did you subscribe for Internet service? ", options=[True, False]) OnlineSecurity = st.radio("Did you subscribe for OnlineSecurity? ", options=[True, False]) OnlineBackup = st.radio("Did you subscribe for Online Backup service? ", options=[True, False]) DeviceProtection = st.radio("Did you subscribe for device protection only?", options=[True, False]) TechSupport =st.radio("Did you subscribe for tech support? ", options=[True, False]) StreamingTV = st.radio("Did you subscribe for TV streaming", options=[True, False]) StreamingMovies = st.radio("Did you subscribe for streaming movies? ", options=[True, False]) Contract = st.radio("Duration of contract: ", options=list(contract.keys()), format_func=format_func_contract) PaperlessBilling = st.radio("Do you use paperless billing? ", options=[True, False]) PaymentMethod = st.selectbox("Payment method:", options=list(payment_options.keys()), format_func=format_func) # You can use PaymentMethod to get the selected payment method's numeric value if st.button("Predict"): service = prediction_service_loader( pipeline_name="continuous_deployment_pipeline", pipeline_step_name="mlflow_model_deployer_step", running=False, ) if service is None: st.write( "No service could be found. The pipeline will be run first to create a service." ) run_main() try: data_point = { 'SeniorCitizen': int(SeniorCitizen), 'tenure': tenure, 'MonthlyCharges': MonthlyCharges, 'TotalCharges': TotalCharges, 'gender': int(gender), 'Partner': int(Partner), 'Dependents': int(Dependents), 'PhoneService': int(PhoneService), 'MultipleLines': int(MultipleLines), 'InternetService': int(InternetService), 'OnlineSecurity': int(OnlineSecurity), 'OnlineBackup': int(OnlineBackup), 'DeviceProtection': int(DeviceProtection), 'TechSupport': int(TechSupport), 'StreamingTV': int(StreamingTV), 'StreamingMovies': int(StreamingMovies), 'Contract': int(Contract), 'PaperlessBilling': int(PaperlessBilling), 'PaymentMethod': int(PaymentMethod) } # Convert the data point to a Series and then to a DataFrame data_point_series = pd.Series(data_point) data_point_df = pd.DataFrame(data_point_series).T # Convert the DataFrame to a JSON list json_list = json.loads(data_point_df.to_json(orient="records")) data = np.array(json_list) for i in range(len(data)): logging.info(data[i]) pred = service.predict(data) logging.info(pred) st.success(f"Customer churn prediction: {'Churn' if pred == 1 else 'No Churn'}") except Exception as e: logging.error(e) raise e if __name__ == "__main__": main()Bu kod, müşteri verilerine ve demografik ayrıntılara dayalı olarak bir telekomünikasyon şirketindeki müşteri kaybını tahmin etmek için bir StreamLit'in ön uç sağlayacağını tanımlar.
Kullanıcılar, kullanıcı dostu bir Arayüz aracılığıyla bilgilerini girebilir ve kod, tahminlerde bulunmak için eğitimli bir makine öğrenimi modelini (ZenML ve MLflow ile birlikte dağıtılan) kullanır.
Tahmin edilen sonuç daha sonra kullanıcıya görüntülenir.
Şimdi şu komutu çalıştırın:
⚠️ tahmin modelinizin çalıştığından emin olun
streamlit run streamlit_app.pyLinki tıkla.
Bu kadar; projemizi tamamladık.

Bu kadar; Profesyonellerin tüm sürece nasıl yaklaştıklarını anlatan uçtan uca makine öğrenimi projemizi başarıyla tamamladık.
Sonuç
Müşteri kaybı tahmin modelinin geliştirilmesi ve devreye alınması yoluyla makine öğrenimi işlemlerinin (MLOps) bu kapsamlı incelemesinde, MLOps'un makine öğrenimi yaşam döngüsünü kolaylaştırmadaki dönüşümsel gücüne tanık olduk. Projemiz, veri toplama ve ön işlemeden model eğitimi, değerlendirme ve devreye almaya kadar MLOps'un geliştirme ve üretim arasındaki boşluğu doldurmadaki temel rolünü sergiliyor. Kuruluşlar giderek daha fazla veri odaklı karar almaya güvendikçe, burada gösterilen verimli ve ölçeklenebilir uygulamalar, MLOps'un makine öğrenimi uygulamalarının başarısını sağlamadaki kritik önemini vurgulamaktadır.
Önemli Noktalar
- MLOps (Makine Öğrenimi Operasyonları), uçtan uca makine öğrenimi yaşam döngüsünü düzene koymada, verimli, güvenilir ve ölçeklenebilir operasyonlar sağlamada çok önemlidir.
- ZenML ve MLflow, makine öğrenimi modellerinin gerçek dünya uygulamalarında geliştirilmesini, izlenmesini ve dağıtılmasını kolaylaştıran güçlü çerçevelerdir.
- Temizleme, kodlama ve bölme dahil olmak üzere uygun veri ön işlemesi, sağlam makine öğrenimi modelleri oluşturmanın temelini oluşturur.
- Doğruluk, kesinlik, geri çağırma ve F1 puanı gibi değerlendirme metrikleri, model performansına ilişkin kapsamlı bir anlayış sağlar.
- MLflow gibi deney izleme araçları, veri bilimi projelerinde işbirliğini ve deney yönetimini geliştirir.
- Sürekli ve çıkarımlı dağıtım hatları, üretim ortamlarında model verimliliğini ve kullanılabilirliğini korumak için kritik öneme sahiptir.
Sık Sorulan Sorular
MLOPS, Makine Öğrenimi Operasyonlarının geliştirmeden Veri Toplama'ya kadar uçtan uca bir makine öğrenimi yaşam döngüsü olduğu anlamına gelir. Tüm makine öğrenimi döngüsünü tasarlamak ve otomatikleştirmek için bir dizi uygulamadır. Makine öğrenimi modellerinin geliştirilmesi ve eğitiminden dağıtıma, izlemeye ve sürekli bakıma kadar her aşamayı kapsar. MLOps çok önemlidir çünkü makine öğrenimi uygulamalarının ölçeklenebilirliğini, güvenilirliğini ve verimliliğini sağlar. Veri bilimcilerinin doğru tahminler sağlayan güçlü makine öğrenimi uygulamaları oluşturmasına yardımcı olur.
MLOps ve DevOps, kendi alanlarındaki süreçleri kolaylaştırmak ve otomatikleştirmek konusunda benzer hedeflere sahiptir. DevOps öncelikle yazılım geliştirme ve yazılım dağıtım hattına odaklanır. Yazılım geliştirmeyi hızlandırmayı, kod kalitesini artırmayı ve dağıtım güvenilirliğini artırmayı amaçlamaktadır. MLOps, makine öğrenimi projelerinin özel ihtiyaçlarını karşılayarak yapay zeka ve veri biliminden yararlanmayı önemli bir uygulama haline getiriyor.
Bu, projede karşılaşacağınız yaygın bir hatadır. Sadece koş
'zenml aşağı'
sonra
'zenml bağlantısını kes'
boru hattını tekrar çalıştırın. Çözülecek.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/10/a-mlops-enhanced-customer-churn-prediction-project/

