Genel Bakış
Parametre Verimli İnce Ayar (PEFT) dünyasının derinliklerine indikçe, bu dönüştürücü yaklaşımın arkasındaki itici güçleri ve metodolojileri anlamak önemli hale geliyor. Bu makalede, PEFT yöntemlerinin Büyük Dil Modellerinin (LLM) belirli görevlere uyarlanmasını nasıl optimize ettiğini araştıracağız. PEFT'nin avantajlarını ve dezavantajlarını açığa çıkaracağız, PEFT tekniklerinin karmaşık kategorilerini inceleyeceğiz ve iki dikkat çekici tekniğin iç işleyişini deşifre edeceğiz: Düşük Sıralı Adaptasyon (LoRA) ve Nicelleştirilmiş Düşük Sıralı Adaptasyon (QLoRA). Bu yolculuk, sizi bu teknikler hakkında kapsamlı bir anlayışla donatmayı ve dil işleme çabalarınız için bu tekniklerin gücünden yararlanmanızı sağlamayı amaçlamaktadır.
Öğrenme hedefleri:
- NLP'de önceden eğitilmiş dil modelleri ve ince ayar kavramını anlayın.
- Büyük modellerde ince ayar yaparken hesaplama ve bellek gereksinimlerinin ortaya çıkardığı zorlukları keşfedin.
- LORA ve QLORA gibi Parametre Açısından Verimli İnce Ayar (PEFT) teknikleri hakkında bilgi edinin.
- PEFT yöntemlerinin avantajlarını ve dezavantajlarını keşfedin.
- T-Few, AdaMix ve MEFT dahil olmak üzere çeşitli PEFT yöntemlerini keşfedin.
- LORA ve QLORA'nın çalışma prensiplerini anlayın.
- QLORA'nın parametre verimliliğini artırmak için nicelemeyi nasıl sunduğunu öğrenin.
- LORA ve QLORA kullanarak ince ayar yapmanın pratik örneklerini keşfedin.
- PEFT tekniklerinin uygulanabilirliği ve faydaları hakkında fikir edinin.
- NLP'de parametre açısından verimli ince ayarın gelecekteki beklentilerini anlayın.
Giriş
Doğal dil işlemenin heyecan verici dünyasında, büyük ölçekli önceden eğitilmiş dil modelleri (LLM'ler) alanda devrim yarattı. Bununla birlikte, bu kadar büyük modellerin belirli görevlere göre ince ayarlanmasının, yüksek hesaplama maliyetleri ve depolama gereksinimleri nedeniyle zorlu olduğu kanıtlanmıştır. Araştırmacılar, bu sorunu çözmek için daha az eğitilebilir parametreyle yüksek görev performansı elde etmek amacıyla Parametre Verimli İnce Ayar (PEFT) tekniklerini araştırdılar.
Önceden Eğitimli Yüksek Lisans ve İnce Ayar
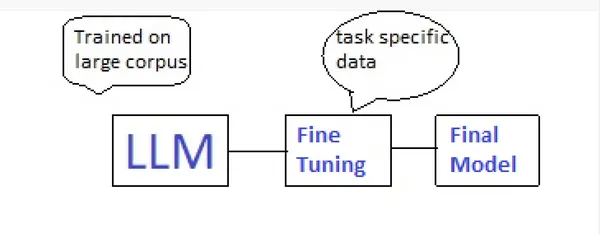
Önceden eğitilmiş LLM'ler, çok miktarda genel alan verisi üzerinde eğitilmiş dil modelleridir ve bu onları zengin dilsel kalıpları ve bilgiyi yakalama konusunda ustalaştırır. İnce ayar, bu önceden eğitilmiş modellerin belirli alt görevlere uyarlanmasını, böylece uzmanlık gerektiren görevlerde uzmanlaşmak için bilgilerinden yararlanmayı içerir. İnce ayar, önceden eğitilmiş modelin, genellikle orijinal eğitim verilerinden daha küçük ve daha odaklı, göreve özgü bir veri kümesi üzerinde eğitilmesini içerir. İnce ayar sırasında modelin parametreleri, hedef görev için performansını optimize edecek şekilde ayarlanır.
Parametre Verimli İnce Ayar (PEFT)
PEFT yöntemleri, eğitilebilir parametrelerin sayısını önemli ölçüde azaltırken, önceden eğitilmiş LLM'lere ince ayar yapmak için etkili bir yaklaşım olarak ortaya çıkmıştır. Bu teknikler, hesaplama verimliliğini ve görev performansını dengeleyerek, kaliteden ödün vermeden en büyük LLM'lerde bile ince ayar yapılmasını mümkün kılar.
PEFT'in Avantajları ve Dezavantajları
PEFT, azaltılmış bellek kullanımı, depolama maliyeti ve çıkarım gecikmesi gibi çeşitli pratik faydalar sağlar. Birden fazla görevin aynı önceden eğitilmiş modeli paylaşmasına olanak tanıyarak bağımsız örneklerin bakım ihtiyacını en aza indirir. Ancak PEFT, geleneksel ince ayar yöntemleriyle karşılaştırıldığında ek eğitim süresi getirebilir ve performansı hiper parametre seçimlerine duyarlı olabilir.
PEFT Çeşitleri
Farklı gereksinimleri ve ödünleşimleri karşılamak için çeşitli PEFT yöntemleri geliştirilmiştir. Dikkate değer PEFT tekniklerinden bazıları arasında, daha düşük hesaplama maliyetiyle daha yüksek doğruluk elde eden T-Few ve AdaMix yer alır. Bu genel yöntem, farklı görevlerde daha iyi performans elde etmek için uyarlama modüllerinin bir karışımını ayarlar.
Farklı PEFT Yöntemlerini Keşfetmek
Öne çıkan bazı PEFT yöntemlerinin ayrıntılarına bakalım.
- T-Few: Bu yöntem, iç aktivasyonları öğrenilen vektörlerle yeniden ölçeklendiren yeni bir PEFT yaklaşımı olan (IA)3'ü kullanır. İnsanüstü performansa ulaşır ve çıkarım sırasında geleneksel ince ayara göre önemli ölçüde daha az FLOP kullanır.
- AdaMix: Tamamen denetlenen ve az atışlı görevler için aşağı akış görev performansını iyileştirmek amacıyla Houlsby veya LoRA gibi uyarlama modüllerinin bir karışımını ayarlayan genel bir PEFT yöntemi.
- MEFT: LLM'leri tersine çevrilebilir hale getiren, eğitim sırasında ara aktivasyonların önbelleğe alınmasını önleyen ve bellek ayak izini önemli ölçüde azaltan, bellek açısından verimli bir ince ayar yaklaşımı.
- QLORA: LLM'nin her katmanına enjekte edilen düşük dereceli adaptörleri kullanan, eğitilebilir parametrelerin sayısını ve GPU bellek gereksinimini büyük ölçüde azaltan etkili bir ince ayar tekniği.
Düşük Dereceli Uyarlama (LoRA)
LoRA, Transformer mimarisinin her katmanına eğitilebilir düşük dereceli matrisler enjekte ederek önceden eğitilmiş dil modellerine verimli bir şekilde ince ayar yapmak için tasarlanmış yenilikçi bir tekniktir. LoRA, aşağı yönlü görevlerde modelin performansını korurken veya geliştirirken, eğitilebilir parametrelerin sayısını ve hesaplama yükünü azaltmayı amaçlamaktadır.
LoRA Nasıl Çalışır?
- Başlangıç Noktasının Korunması: LoRA'da başlangıç noktası hipotezi çok önemlidir. Önceden eğitilmiş modelin ağırlıklarının, aşağı yönlü görevler için zaten en uygun çözüme yakın olduğu varsayılmaktadır. Böylece LoRA, önceden eğitilmiş modelin ağırlıklarını dondurur ve bunun yerine eğitilebilir düşük dereceli matrisleri optimize etmeye odaklanır.
- Düşük Sıralı Matrisler: LoRA, her katmanın öz dikkat modülüne A ve B matrisleri olarak temsil edilen düşük dereceli matrisleri ekler. Bu düşük dereceli matrisler adaptör görevi görerek modelin belirli görevlere uyum sağlamasına ve uzmanlaşmasına olanak tanırken ihtiyaç duyulan ek parametre sayısını en aza indirir.
- Sıra Eksikliği: LoRA'nın ardındaki önemli bir anlayış, adaptasyon sırasında gözlemlenen ağırlık değişikliklerinin (∆W) sıra eksikliğidir. Bu, modelin uyarlamasının, orijinal ağırlık matrislerinden çok daha düşük bir sıralamayla etkili bir şekilde temsil edilebilecek değişiklikleri içerdiğini göstermektedir. LoRA, parametre verimliliği elde etmek için bu gözlemden yararlanır.
LoRA'nın Avantajları
- Azaltılmış Parametre Yükü: Tüm parametrelere ince ayar yapmak yerine düşük dereceli matrisler kullanan LoRA, eğitilebilir parametrelerin sayısını önemli ölçüde azaltarak onu bellek açısından daha verimli ve hesaplama açısından daha ucuz hale getirir.
- Verimli Görev Değiştirme: LoRA, önceden eğitilmiş modelin birden fazla görev arasında paylaşılmasına olanak tanıyarak her görev için ayrı ince ayarlı örnekler bulundurma ihtiyacını azaltır. Bu, dağıtım sırasında hızlı ve sorunsuz görev değiştirmeyi kolaylaştırarak depolama ve değiştirme maliyetlerini azaltır.
- Çıkarım Gecikmesi Yok: LoRA'nın doğrusal tasarımı, tamamen ince ayarlı modellere kıyasla ek çıkarım gecikmesi sağlamaz ve bu da onu gerçek zamanlı uygulamalar için uygun kılar.
Nicelenmiş Düşük Sıralı Uyarlama (QLoRA)
QLoRA, ince ayar sırasında parametre verimliliğini artırmak için nicelemeyi daha da sunan LoRA'nın bir uzantısıdır. 4-bit NormalFloat (NF4) niceleme ve Çift Niceleme tekniklerini tanıtırken LoRA ilkelerini temel alır.
- NF4 Nicelemesi: NF4 nicemleme, önceden eğitilmiş sinir ağı ağırlıklarının doğal dağılımından, genellikle belirli standart sapmalara sahip sıfır merkezli normal dağılımlardan yararlanır. NF4 nicelemesi, tüm ağırlıkları NF1 (-1 ila 4) aralığına uyan sabit bir dağılıma dönüştürerek, pahalı niceliksel tahmin algoritmalarına ihtiyaç duymadan ağırlıkları etkili bir şekilde nicelleştirir.
- Çift Niceleme: Çift Niceleme, niceleme sabitlerinin bellek yükünü giderir. Çift Niceleme, niceleme sabitlerini kendileri niceleyerek performanstan ödün vermeden bellek ayak izini önemli ölçüde azaltır. İşlem, ikinci niceleme adımı için blok boyutu 8 olan 256 bitlik Kayan Noktaların kullanılmasını içerir ve bu da önemli miktarda bellek tasarrufu sağlar.
QLoRA'nın Avantajları
- Daha Fazla Bellek Azaltma: QLoRA, nicelemeyi tanıtarak daha da yüksek bellek verimliliği elde eder ve bu da onu özellikle kaynak kısıtlı cihazlara büyük modellerin dağıtılmasında değerli kılar.
- Performansın Korunması: Parametre açısından verimli yapısına rağmen QLoRA, yüksek model kalitesini korur ve çeşitli aşağı yönlü görevlerde tamamen ince ayarlı modellerle aynı hatta daha iyi performans gösterir.
- Çeşitli LLM'lere Uygulanabilirlik: QLoRA, RoBERTa, DeBERTa, GPT-2 ve GPT-3 dahil olmak üzere farklı dil modellerine uygulanabilen çok yönlü bir tekniktir ve araştırmacıların çeşitli LLM mimarileri için parametre açısından verimli ince ayarları keşfetmesine olanak tanır.
PEFT Kullanarak Büyük Dil Modellerine İnce Ayar Yapma
QLORA kullanarak büyük bir dil modeline ince ayar yapmaya yönelik bir kod örneğiyle bu kavramları uygulamaya koyalım.
# Step 1: Load the pre-trained model and tokenizer
from transformers import BertTokenizer, BertForMaskedLM, QLORAdapter model_name = "bert-base-uncased"
pretrained_model = BertForMaskedLM.from_pretrained(model_name)
tokenizer = BertTokenizer.from_pretrained(model_name) # Step 2: Prepare the dataset
texts = ["[CLS] Hello, how are you? [SEP]", "[CLS] I am doing well. [SEP]"]
train_encodings = tokenizer(texts, truncation=True, padding="max_length", return_tensors="pt")
labels = torch.tensor([tokenizer.encode(text, add_special_tokens=True) for text in texts]) # Step 3: Define the QLORAdapter class
adapter = QLORAdapter(input_dim=768, output_dim=768, rank=64)
pretrained_model.bert.encoder.layer[0].attention.output = adapter # Step 4: Fine-tuning the model
optimizer = torch.optim.AdamW(adapter.parameters(), lr=1e-5)
loss_fn = nn.CrossEntropyLoss() for epoch in range(10): optimizer.zero_grad() outputs = pretrained_model(**train_encodings.to(device)) logits = outputs.logits loss = loss_fn(logits.view(-1, logits.shape[-1]), labels.view(-1)) loss.backward() optimizer.step() # Step 5: Inference with the fine-tuned model
test_text = "[CLS] How are you doing today? [SEP]"
test_input = tokenizer(test_text, return_tensors="pt")
output = pretrained_model(**test_input)
predicted_ids = torch.argmax(output.logits, dim=-1)
predicted_text = tokenizer.decode(predicted_ids[0])
print("Predicted text:", predicted_text)
Sonuç
Yüksek Lisans'ların parametre açısından verimli ince ayarı, hesaplama ve bellek gereksinimlerinin ortaya çıkardığı zorlukları ele alan, hızla gelişen bir alandır. LORA ve QLORA gibi teknikler, görev performansından ödün vermeden verimliliğin ince ayarını optimize etmeye yönelik yenilikçi stratejiler göstermektedir. Bu yöntemler, büyük dil modellerinin gerçek dünyadaki uygulamalara yerleştirilmesi için umut verici bir yol sunarak NLP'yi her zamankinden daha erişilebilir ve pratik hale getiriyor.
Sık Sorulan Sorular
C: Parametre açısından verimli ince ayarın amacı, önceden eğitilmiş dil modellerini belirli görevlere uyarlamaktır. Geleneksel ince ayar yöntemlerinin hesaplama ve bellek yükünü en aza indirirken.
C: QLoRA, karmaşık niceleme teknikleri olmadan ağırlıkları etkili bir şekilde ölçerek düşük dereceli uyarlama sürecine nicelemeyi getiriyor. Bu, model performansını korurken bellek verimliliğini artırır.
C: LoRA, parametre yükünü azaltır, verimli görev değiştirmeyi destekler ve çıkarım gecikmesini korur; bu da onu parametre açısından verimli ince ayar için pratik bir çözüm haline getirir.
C: PEFT teknikleri araştırmacıların büyük dil modellerine verimli bir şekilde ince ayar yapmalarını sağlar. Hesaplama kaynaklarından ödün vermeden çeşitli aşağı yönlü görevlerde kullanımlarını optimize etme.
C: QLoRA, RoBERTa, DeBERTa, GPT-2 ve GPT-3 dahil olmak üzere çeşitli dil modellerine uygulanır ve farklı mimariler için parametre açısından verimli ince ayar seçenekleri sunar.
NLP alanı gelişmeye devam ediyor. LORA ve QLORA gibi parametre açısından verimli ince ayar teknikleri, LLM'lerin çeşitli uygulamalarda daha erişilebilir ve pratik dağıtımının yolunu açıyor.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. Otomotiv / EV'ler, karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- ChartPrime. Ticaret Oyununuzu ChartPrime ile yükseltin. Buradan Erişin.
- Blok Ofsetleri. Çevre Dengeleme Sahipliğini Modernleştirme. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/08/lora-and-qlora/

