Giriş
Yapay zeka ve makine öğreniminin ortaya çıkışı, bilgiyle etkileşim şeklimizde devrim yaratarak bilginin alınmasını, anlaşılmasını ve kullanılmasını kolaylaştırdı. Bu uygulamalı kılavuzda, PDF belgeleri denizinde zahmetsizce gezinmek için LLamA2 ve LLamAIndex tarafından desteklenen, son teknoloji ürünü dil modellerinden ve indeksleme çerçevelerinden yararlanan gelişmiş bir Soru-Cevap asistanı oluşturmayı keşfediyoruz. Bu eğitim, geliştiricileri, veri bilimcilerini ve teknoloji meraklılarını, NLP alanındaki devlerin omuzlarında duran bir Geri Almayla Artırılmış Nesil (RAG) Sistemi oluşturmaya yönelik araç ve bilgilerle güçlendirmek için tasarlanmıştır.
Yapay zeka destekli bir Soru-Cevap asistanının yaratılışını açığa çıkarma arayışımızda bu kılavuz, karmaşık teorik kavramlar ile bunların gerçek dünya senaryolarındaki pratik uygulamaları arasında bir köprü görevi görüyor. LLamA2'nin gelişmiş dil kavrayışını LLamAIndex'in verimli bilgi alma yetenekleriyle bütünleştirerek, soruları hassasiyetle yanıtlayan ve NLP alanındaki potansiyel ve zorluklara ilişkin anlayışımızı derinleştiren bir sistem oluşturmayı hedefliyoruz. Bu makale, meraklılar ve profesyoneller için kapsamlı bir yol haritası görevi görüyor ve en son modeller ile bilgi teknolojisinin sürekli gelişen talepleri arasındaki sinerjiyi vurguluyor.

Öğrenme hedefleri
- Hugging Face'in LLamA2 modelini kullanarak bir RAG Sistemi geliştirin.
- Birden fazla PDF belgesini entegre edin.
- Verimli erişim için dizin belgeleri.
- Bir sorgu sistemi oluşturun.
- Çeşitli soruları yanıtlayabilen güçlü bir asistan yaratın.
- Sadece teorik yönlerden ziyade pratik uygulamaya odaklanın.
- Uygulamalı kodlama ve gerçek dünya uygulamalarıyla meşgul olun.
- NLP'nin karmaşık dünyasını erişilebilir ve ilgi çekici hale getirin.
İçindekiler
LLamA2 Modeli
LLamA2, doğal dil işlemede, dil modelleriyle mümkün olanın sınırlarını zorlayan bir yenilik işaretidir. Hem verimlilik hem de etkililik için tasarlanan mimarisi, benzeri görülmemiş bir anlayışa ve insan benzeri metinlerin oluşturulmasına olanak tanır. BERT ve GPT gibi öncekilerden farklı olarak LLamA2, dil işleme konusunda daha incelikli bir yaklaşım sunarak soru yanıtlama gibi derin kavrama gerektiren görevlerde özellikle usta olmasını sağlıyor. Özetlemeden çeviriye kadar çeşitli NLP görevlerindeki kullanımı, karmaşık dilsel zorlukların üstesinden gelmedeki çok yönlülüğünü ve yeteneğini sergiliyor.

LLamAIndex'i Anlamak
İndeksleme, herhangi bir verimli bilgi erişim sisteminin omurgasıdır. Belge indeksleme ve sorgulama için tasarlanmış bir çerçeve olan LLamAIndex, geniş belge koleksiyonlarını yönetmek için kusursuz bir yol sunarak öne çıkıyor. Bu sadece bilgi depolamakla ilgili değil; onu göz açıp kapayıncaya kadar erişilebilir ve geri alınabilir hale getirmekle ilgilidir.

LLamAIndex'in önemi abartılamaz, çünkü kapsamlı veritabanlarında gerçek zamanlı sorgu işlemeyi mümkün kılarak Soru-Cevap yardımcımızın kapsamlı bir bilgi tabanından alınan hızlı ve doğru yanıtlar sunabilmesini sağlar.
Tokenizasyon ve Yerleştirmeler
Dil modellerini anlamanın ilk adımı, tokenizasyon olarak bilinen bir süreç olan metni yönetilebilir parçalara ayırmayı içerir. Bu temel görev, verilerin daha sonraki işlemlere hazırlanması açısından çok önemlidir. Tokenizasyonun ardından, kelimeleri ve cümleleri sayısal vektörlere çeviren yerleştirme kavramı devreye giriyor.
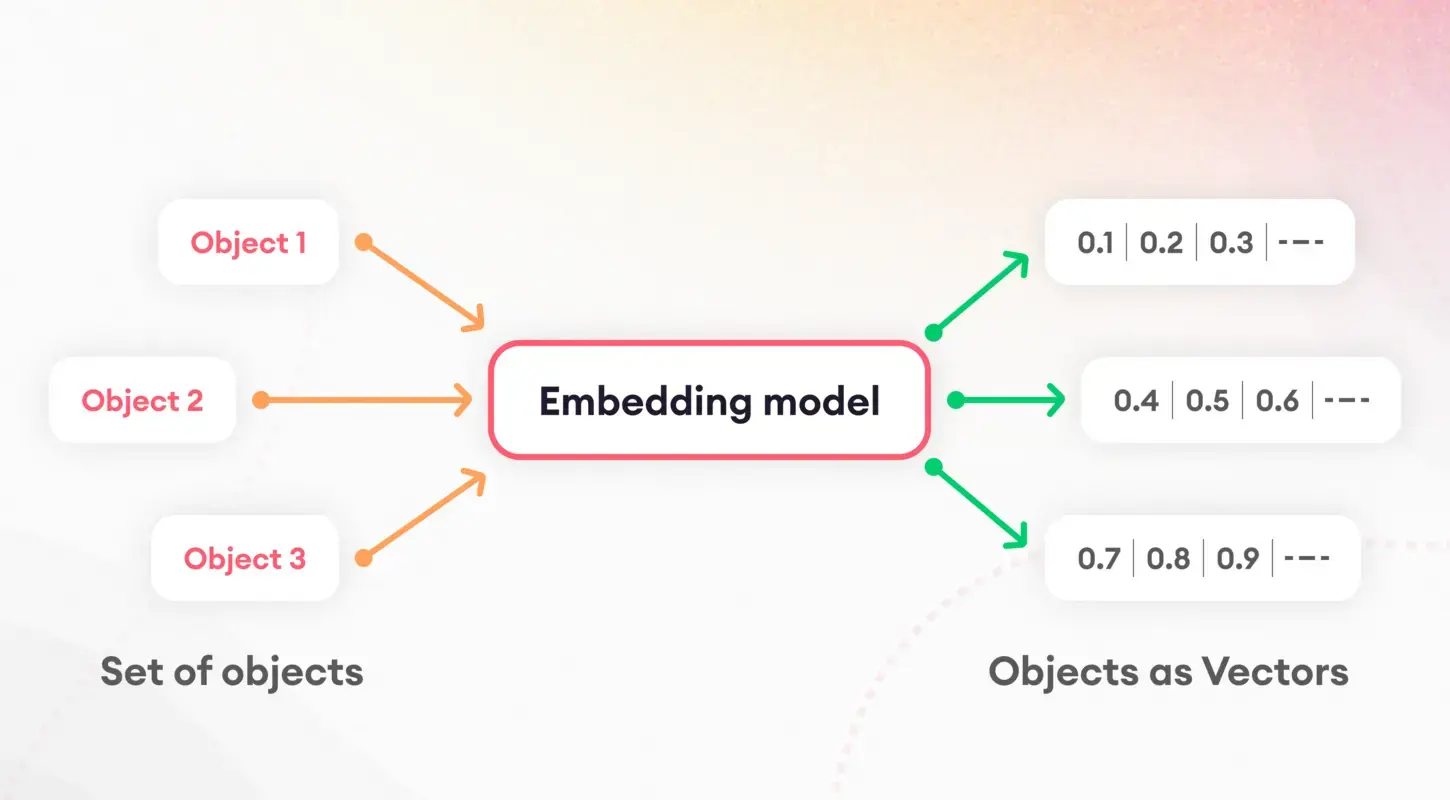
Bu yerleştirmeler dilsel özelliklerin özünü yakalayarak modellerin metnin altında yatan anlamsal özellikleri ayırt etmesini ve kullanmasını sağlar. Özellikle cümle yerleştirmeler, belge benzerliği ve erişim gibi görevlerde önemli bir rol oynayarak indeksleme stratejimizin temelini oluşturur.
Model Niceleme
Model nicemleme, Soru-Cevap asistanımızın performansını ve verimliliğini artırmaya yönelik bir strateji sunar. Modelin sayısal hesaplamalarının hassasiyetini azaltarak boyutunu önemli ölçüde azaltabilir ve çıkarım sürelerini hızlandırabiliriz. Hassasiyet ve verimlilik arasında bir denge sağlarken, bu süreç özellikle mobil cihazlar veya web uygulamaları gibi kaynakların kısıtlı olduğu ortamlarda değerlidir. Dikkatli bir uygulamayla nicemleme, azaltılmış gecikme ve depolama gereksinimlerinden yararlanırken yüksek düzeyde doğruluk sağlamamıza olanak tanır.
ServiceContext ve Sorgu Motoru
LLamAIndex içindeki ServiceContext, kaynakları ve yapılandırmaları yönetmek için merkezi bir merkez olup, sistemimizin sorunsuz ve verimli bir şekilde çalışmasını sağlar. Yapıştırıcı, uygulamamızı bir arada tutarak, uygulamalar arasında kesintisiz entegrasyon sağlar. LLamA2 modeli, yerleştirme işlemi ve dizine eklenen belgeler. Öte yandan sorgu motoru, kullanıcı sorgularını işleyen, ilgili bilgiyi hızlı bir şekilde getirmek için dizine alınmış verilerden yararlanan güçlü bir araçtır. Bu ikili kurulum, Soru-Cevap yardımcımızın karmaşık sorguları kolayca yönetebilmesini ve kullanıcılara hızlı ve doğru yanıtlar sunabilmesini sağlar.
Uygulama
Uygulamaya geçelim. Bu projeyi oluşturmak için Google Colab'ı kullandığımı lütfen unutmayın.
!pip install pypdf
!pip install -q transformers einops accelerate langchain bitsandbytes
!pip install sentence_transformers
!pip install llama_indexBu komutlar, model etkileşimi için transformatörler ve yerleştirmeler için cümle_transformerleri de dahil olmak üzere gerekli kitaplıkları yükleyerek ortamı hazırlar. Llama_index'in kurulumu indeksleme çerçevemiz için çok önemlidir.
Daha sonra bileşenlerimizi başlatıyoruz (Google Colab'ın Dosyalar bölümünde “data” adında bir klasör oluşturduğunuzdan emin olun ve ardından PDF'yi klasöre yükleyin):
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.prompts.prompts import SimpleInputPrompt
# Reading documents and setting up the system prompt
documents = SimpleDirectoryReader("/content/data").load_data()
system_prompt = """
You are a Q&A assistant. Your goal is to answer questions based on the given documents.
"""
query_wrapper_prompt = SimpleInputPromptOrtamımızı ayarladıktan ve belgeleri okuduktan sonra, LLamA2 modelinin yanıtlarına rehberlik edecek bir sistem istemi oluşturuyoruz. Bu şablon, modelin çıktısının doğruluk ve uygunluk beklentilerimizle uyumlu olmasını sağlamada etkilidir.
!huggingface-cli login
Yukarıdaki komut, Hugging Face'in geniş model deposuna erişim sağlayan bir ağ geçididir. Kimlik doğrulama için bir belirteç gerektirir.
Aşağıdaki bağlantıyı ziyaret etmeniz gerekiyor: Sarılma Yüz (önce Hugging Face'te oturum açtığınızdan emin olun), ardından Yeni bir Belirteç oluşturun, proje için bir Ad girin, Okundu Olarak Yaz'ı seçin ve ardından Belirteç oluştur'a tıklayın.
Bu adım, geliştirme ortamınızı güvence altına almanın ve kişiselleştirmenin önemini vurgulamaktadır.
import torch
llm = HuggingFaceLLM(
context_window=4096,
max_new_tokens=256,
generate_kwargs={"temperature": 0.0, "do_sample": False},
system_prompt=system_prompt,
query_wrapper_prompt=query_wrapper_prompt,
tokenizer_name="meta-llama/Llama-2-7b-chat-hf",
model_name="meta-llama/Llama-2-7b-chat-hf",
device_map="auto",
model_kwargs={"torch_dtype": torch.float16, "load_in_8bit":True}
)Burada LLamA2 modelini Soru-Cevap sistemimiz için uyarlanmış belirli parametrelerle başlatıyoruz. Bu kurulum, modelin çok yönlülüğünü ve farklı bağlamlara ve uygulamalara uyum sağlama yeteneğini vurgulamaktadır.
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from llama_index.embeddings.langchain import LangchainEmbedding
embed_model = LangchainEmbedding(
HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2"))Gömme modelinin seçimi, belgelerimizin anlamsal özünü yakalamak açısından kritik öneme sahiptir. Cümle Dönüştürücülerini kullanarak, sistemimizin metin içeriğinin benzerliğini ve alaka düzeyini doğru bir şekilde ölçebilmesini ve böylece indeksleme sürecinin etkinliğini arttırmasını sağlıyoruz.
service_context = ServiceContext.from_defaults(
chunk_size=1024,
llm=llm,
embed_model=embed_model
)ServiceContext, LLamA2 modelimizi birbirine bağlayan ve modeli uyumlu bir çerçeveye yerleştiren varsayılan ayarlarla başlatılır. Bu adım, tüm sistem bileşenlerinin uyumlu hale getirilmesini ve indeksleme ve sorgulama işlemlerine hazır olmasını sağlar.
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
query_engine = index.as_query_engine()Bu satırlar, belgelerimizi indekslediğimiz ve sorgu motorunu hazırladığımız kurulum sürecimizin son noktasını işaret ediyor. Bu kurulum, veri hazırlığını eyleme geçirilebilir içgörülere dönüştürmek için çok önemlidir ve Soru-Cevap yardımcımızın dizine eklenen içeriğe dayalı olarak sorgulara yanıt vermesini sağlar.
response = query_engine.query("Give me a Summary of the PDF in 10 pointers.")
print(response)Son olarak, belge koleksiyonumuzdan elde edilen özetleri ve öngörüleri sorgulayarak sistemimizi test ettik. Bu etkileşim, Soru-Cevap yardımcımızın pratik faydasını gösterir ve LLamA2, LLamAIndex ve temeldekilerin kusursuz entegrasyonunu sergiler. NLP teknolojileri bu da bunu mümkün kılıyor.
Çıktı:

Etik ve Yasal Etkiler
Yapay zeka destekli Soru-Cevap sistemlerinin geliştirilmesi, çeşitli etik ve yasal hususları ön plana çıkarır. Eğitim verilerindeki potansiyel önyargıların ele alınması, yanıtlarda adalet ve tarafsızlığın sağlanması kadar önemlidir. Ayrıca, bu sistemler genellikle hassas bilgileri işlediğinden, veri gizliliği düzenlemelerine bağlılık son derece önemlidir. Geliştiriciler, kullanıcıları ve sağlanan bilgilerin bütünlüğünü koruyan etik ilkelere bağlı kalarak bu zorluklarla titizlikle ve dürüstlükle başa çıkmalıdır.
Gelecekteki Yönler ve Zorluklar
Soru-Cevap sistemleri alanı, çok modlu etkileşimlerden alana özgü uygulamalara kadar yenilik fırsatlarıyla doludur. Ancak bu gelişmeler, geniş belge koleksiyonlarını barındıracak şekilde ölçeklendirme ve kullanıcı sorgularında çeşitlilik sağlama gibi kendi zorluklarını da beraberinde getiriyor. LLamA2 gibi modellerin ve LLamAIndex gibi indeksleme çerçevelerinin devam eden gelişimi ve iyileştirilmesi, bu engellerin aşılması ve NLP'de mümkün olanın sınırlarının zorlanması açısından kritik öneme sahiptir.
Vaka Çalışmaları ve Örnekler
Müşteri hizmetleri botları ve eğitim araçları gibi Soru-Cevap sistemlerinin gerçek dünyadaki uygulamaları, LLamA2 ve LLamAIndex gibi teknolojilerin çok yönlülüğünün ve etkisinin altını çiziyor. Bu vaka çalışmaları, yapay zekanın çeşitli sektörlerdeki pratik uygulamalarını gösteriyor ve başarı öykülerini ve öğrenilen dersleri vurgulayarak gelecekteki gelişmeler için değerli bilgiler sağlıyor.
Sonuç
Bu kılavuz, LLamA2 ve LLamAIndex'in temel kavramlarından pratik uygulama adımlarına kadar PDF tabanlı bir Soru-Cevap asistanı oluşturma sürecini ele almıştır. Yapay zekanın bilgi alma ve işleme konusundaki yeteneklerini keşfetmeye ve genişletmeye devam ettikçe, bilgiyle etkileşimimizi dönüştürme potansiyeli sınırsızdır. Bu araçlar ve öngörülerle donanmış olarak, daha akıllı ve duyarlı sistemlere doğru yolculuk daha yeni başlıyor.
Önemli Noktalar
- Bilgi Etkileşiminde Devrim Yaratıyor: LLamA2 ve LLamAIndex tarafından örneklenen yapay zeka ve makine öğreniminin entegrasyonu, bilgiye erişme ve onu kullanma şeklimizi dönüştürerek geniş PDF belge koleksiyonlarında zahmetsizce gezinebilen gelişmiş Soru-Cevap asistanlarının önünü açtı.
- Teori ve Uygulama Arasındaki Pratik Köprü: Bu kılavuz, teorik kavramlar ile pratik uygulama arasındaki boşluğu doldurarak geliştiricilere ve teknoloji meraklılarına, en son teknolojiye sahip NLP modellerinden ve indeksleme çerçevelerinden yararlanan Alma-Artırılmış Üretim (RAG) Sistemleri oluşturma yetkisi verir.
- Verimli İndekslemenin Önemi: LLamAIndex, geniş belge koleksiyonlarını indeksleyerek verimli bilgi alımında çok önemli bir rol oynar. Bu, kullanıcı sorularına hızlı ve doğru yanıtlar verilmesini sağlar ve Soru-Cevap asistanının genel işlevselliğini geliştirir.
- Performans ve Verimlilik için Optimizasyon: Model nicemleme gibi teknikler, Soru-Cevap asistanlarının performansını ve verimliliğini artırarak doğruluktan ödün vermeden gecikme ve depolama gereksinimlerinin azaltılmasına olanak tanır.
- Etik Hususlar ve Geleceğe Yönelik Yönergeler: Yapay zeka destekli Soru-Cevap sistemlerinin geliştirilmesi, önyargının azaltılması ve veri gizliliği de dahil olmak üzere etik ve yasal sonuçların ele alınmasını gerektirir. Geleceğe bakıldığında, Soru-Cevap sistemlerindeki gelişmeler yenilik fırsatları sunarken aynı zamanda kullanıcı sorgularının ölçeklenebilirliği ve çeşitliliği konusunda da zorluklar ortaya çıkarıyor
Sıkça Sorulan Sorular
Cevap. LLamA2, dil işlemeye daha incelikli bir yaklaşım sunarak soru yanıtlama gibi derin kavrama görevlerine olanak tanır. Mimarisi verimliliği ve etkililiği ön planda tutarak çeşitli NLP görevlerinde çok yönlü olmasını sağlar.
Cevap. LLamAIndex, kapsamlı veritabanlarında gerçek zamanlı sorgu işlemeyi kolaylaştıran, belge indeksleme ve sorgulamaya yönelik bir çerçevedir. Soru-Cevap asistanlarının kapsamlı bilgi tabanlarından ilgili bilgileri hızlı bir şekilde alabilmelerini sağlar.
Cevap. Yerleştirmeler, özellikle cümle yerleştirmeleri, metin içeriğinin anlamsal özünü yakalayarak benzerlik ve alaka düzeyinin doğru bir şekilde ölçülmesine olanak tanır. Bu, indeksleme sürecinin etkinliğini artırarak asistanın ilgili yanıtları verme yeteneğini geliştirir.
Cevap. Model nicemleme, sayısal hesaplamaların boyutunu azaltarak performansı ve verimliliği optimize eder, böylece gecikme ve depolama gereksinimlerini azaltır. Hassasiyet ve verimlilik arasında bir denge sağlarken kaynakların kısıtlı olduğu ortamlarda değerlidir.
Cevap. Geliştiriciler, eğitim verilerindeki potansiyel önyargıları ele almalı, yanıtlarda adalet ve tarafsızlığı sağlamalı ve veri gizliliği düzenlemelerine uymalıdır. Etik ilkelerin desteklenmesi, kullanıcıları korur ve Soru-Cevap asistanı tarafından sağlanan bilgilerin bütünlüğünü korur.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2024/04/a-hands-on-guide-to-creating-a-pdf-based-qa-assistant-with-llama-and-llamaindex/

