Giriş
Geri Alma Artırılmış Nesil bir süredir burada. Vektör depoları, erişim çerçeveleri ve LLM'ler gibi birçok araç ve uygulama bu konsept etrafında inşa ediliyor ve bu da özel belgelerle, özellikle de Langchain ile Yarı Yapılandırılmış Verilerle çalışmayı kolaylaştırıyor. Uzun, yoğun metinlerle çalışmak hiç bu kadar kolay ve eğlenceli olmamıştı. Geleneksel RAG DOC, PDF'ler vb. gibi yapılandırılmamış metin ağırlıklı dosyalarla iyi çalışır. Ancak bu yaklaşım, PDF'lerdeki gömülü tablolar gibi yarı yapılandırılmış verilerle pek uyumlu değildir.
Yarı yapılandırılmış verilerle çalışırken genellikle iki endişe vardır.
- Geleneksel çıkarma ve metin bölme yöntemleri PDF'lerdeki tabloları hesaba katmaz. Genellikle masaları parçalamakla sonuçlanırlar. Dolayısıyla bilgi kaybına neden olur.
- Tabloların yerleştirilmesi kesin anlamsal arama anlamına gelmeyebilir.
Bu nedenle, bu makalede, bu iki endişeyi yarı yapılandırılmış verilerle ele almak için Langchain ile yarı yapılandırılmış veriler için bir Alma oluşturma hattı oluşturacağız.
Öğrenme hedefleri
- Yapılandırılmış, yapılandırılmamış ve yarı yapılandırılmış veriler arasındaki farkı anlayın.
- Retrieval Augment Generation ve Langchain hakkında küçük bir tazeleme.
- Langchain ile yarı yapılandırılmış verileri işlemek için çok vektörlü bir alıcının nasıl oluşturulacağını öğrenin.
Bu makale, Veri Bilimi Blogathon.
İçindekiler
Veri Türleri
Genellikle üç tür veri vardır. Yapılandırılmış, Yarı Yapılandırılmış ve Yapılandırılmamış.
- Yapısal Veri: Yapılandırılmış veriler standartlaştırılmış verilerdir. Veriler, satırlar ve sütunlar gibi önceden tanımlanmış bir şemayı takip eder. SQL veritabanları, Elektronik Tablolar, veri çerçeveleri vb.
- Yapılandırılmamış Veriler: Yapılandırılmamış veriler, yapılandırılmış verilerden farklı olarak hiçbir veri modelini izlemez. Veriler olabildiğince rastgeledir. Örneğin, PDF'ler, Metinler, Resimler vb.
- Yarı Yapılandırılmış Veri: Eski veri tiplerinin birleşimidir. Yapılandırılmış verilerden farklı olarak önceden tanımlanmış katı bir şemaya sahip değildir. Ancak veriler, yapılandırılmamış türlerin aksine, bazı işaretleyicilere dayanan hiyerarşik bir düzeni hâlâ korur. Örneğin, CSV'ler, HTML, PDF'lerdeki gömülü tablolar, XML'ler vb.

RAG nedir?
RAG, Erişim Artırılmış Üretim anlamına gelir. Büyük dil modellerini yeni bilgilerle beslemenin en basit yoludur. Öyleyse RAG'a hızlı bir giriş yapalım.
Tipik bir RAG boru hattında yerel dosyalar, Web sayfaları, veritabanları vb. gibi bilgi kaynaklarına, bir yerleştirme modeline, bir vektör veritabanına ve bir LLM'ye sahibiz. Verileri çeşitli kaynaklardan topluyoruz, belgeleri bölüyoruz, metin parçalarının yerleştirmelerini alıyoruz ve bunları bir vektör veritabanında saklıyoruz. Artık sorguların yerleştirmelerini vektör deposuna aktarıyoruz, belgeleri vektör deposundan alıyoruz ve son olarak LLM ile yanıtlar üretiyoruz.
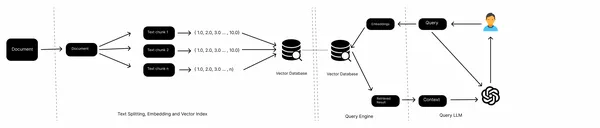
Bu, geleneksel bir RAG'nin iş akışıdır ve metinler gibi yapılandırılmamış verilerle iyi çalışır. Ancak yarı yapılandırılmış veriler söz konusu olduğunda, örneğin PDF'deki gömülü tablolar, genellikle iyi performans göstermez. Bu yazıda bu gömülü tabloların nasıl işleneceğini öğreneceğiz.
Langchain nedir?
Langchain, LLM tabanlı uygulamalar oluşturmaya yönelik açık kaynaklı bir çerçevedir. Proje, lansmanından bu yana yazılım geliştiricileri arasında geniş çapta benimsendi. Yapay zeka uygulamalarını daha hızlı oluşturmak için birleşik bir araç ve teknoloji yelpazesi sunar. Langchain, vektör depoları, belge yükleyiciler, alıcılar, yerleştirme modelleri, metin bölücüler vb. gibi araçları barındırır. Yapay zeka uygulamaları oluşturmak için tek duraklı bir çözümdür. Ancak onu diğerlerinden ayıran iki temel değer önerisi var.
- Yüksek Lisans zincirleri: Langchain birden fazla zincir sağlar. Bu zincirler, tek bir görevi gerçekleştirmek için çeşitli araçları bir araya getirir. Örneğin, ConversationalRetrievalChain bir sorgu için yanıtlar oluşturmak üzere bir LLM'yi, Vector mağaza alıcısını, yerleştirme modelini ve bir sohbet geçmişi nesnesini birbirine zincirler. Araçlar sabit kodlanmıştır ve açıkça tanımlanması gerekir.
- Yüksek Lisans acenteleri: LLM zincirlerinden farklı olarak AI temsilcilerinin sabit kodlanmış araçları yoktur. Bir aracı birbiri ardına zincirlemek yerine, LLM'nin hangisini ve ne zaman seçeceğine araçların metin açıklamalarına dayanarak karar vermesine izin verdik. Bu, onu muhakeme ve karar vermeyi içeren karmaşık LLM uygulamaları oluşturmak için ideal kılar.
RAG boru hattının inşası
Artık kavramlarla ilgili bir ön bilgimiz var. Boru hattını inşa etme yaklaşımını tartışalım. Yarı yapılandırılmış verilerle çalışmak, bilgi depolamaya yönelik geleneksel bir şemayı takip etmediğinden yanıltıcı olabilir. Yapılandırılmamış verilerle çalışmak için, bilgi çıkarmak üzere özel olarak tasarlanmış özel araçlara ihtiyacımız var. Dolayısıyla bu projede "yapılandırılmamış" adı verilen bir araç kullanacağız; PDF'lerdeki, HTML'deki, XML'deki tablolar gibi farklı yapılandırılmamış veri formatlarından bilgi çıkarmaya yönelik açık kaynaklı bir araçtır. Yapılandırılmamış, dosyalardaki birden fazla veri formatını işlemek için Tesseract ve Poppler'ı başlık altında kullanır. O halde kodlama kısmına geçmeden önce ortamımızı kuralım ve bağımlılıkları kuralım.
Dev Env'yi ayarlama
Diğer Python projelerinde olduğu gibi, bir Python ortamı açın ve Poppler ve Tesseract'ı yükleyin.
!sudo apt install tesseract-ocr
!sudo apt-get install poppler-utilsŞimdi projemizde ihtiyaç duyacağımız bağımlılıkları kuralım.
!pip install "unstructured[all-docs]" Langchain openaiArtık bağımlılıkları kurduğumuza göre verileri bir PDF dosyasından çıkaracağız.
from unstructured.partition.pdf import partition_pdf
pdf_elements = partition_pdf(
"mistral7b.pdf",
chunking_strategy="by_title",
extract_images_in_pdf=True,
max_characters=3000,
new_after_n_chars=2800,
combine_text_under_n_chars=2000,
image_output_dir_path="./"
)Bunu çalıştırmak, OCR için gerekli olan YOLOx gibi çeşitli bağımlılıkları yükleyecek ve çıkarılan verilere dayalı olarak nesne türlerini döndürecektir. Extract_images_in_pdf'nin etkinleştirilmesi, gömülü görüntülerin dosyalardan yapılandırılmamış şekilde çıkarılmasına olanak tanır. Bu, çok modlu çözümlerin uygulanmasına yardımcı olabilir.
Şimdi PDF'mizdeki öğe kategorilerini inceleyelim.
# Create a dictionary to store counts of each type
category_counts = {}
for element in pdf_elements:
category = str(type(element))
if category in category_counts:
category_counts[category] += 1
else:
category_counts[category] = 1
# Unique_categories will have unique elements
unique_categories = set(category_counts.keys())
category_countsBunu çalıştırmak, öğe kategorilerinin ve bunların sayısının çıktısını alacaktır.
Artık kolay kullanım için elemanları ayırıyoruz. Langchain'in Belge türünden miras alan bir Element türü oluşturuyoruz. Bunun amacı, işlenmesi daha kolay olan daha organize veriler sağlamaktır.
from unstructured.documents.elements import CompositeElement, Table
from langchain.schema import Document
class Element(Document):
type: str
# Categorize by type
categorized_elements = []
for element in pdf_elements:
if isinstance(element, Table):
categorized_elements.append(Element(type="table", page_content=str(element)))
elif isinstance(element, CompositeElement):
categorized_elements.append(Element(type="text", page_content=str(element)))
# Tables
table_elements = [e for e in categorized_elements if e.type == "table"]
# Text
text_elements = [e for e in categorized_elements if e.type == "text"]Çok Vektörlü Alıcı
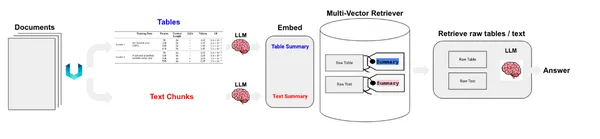
Tablo ve metin öğelerimiz var. Şimdi bunları halletmenin iki yolu var. Ham öğeleri bir belge deposunda saklayabilir veya metin özetlerini saklayabiliriz. Tablolar anlamsal aramaya zorluk teşkil edebilir; bu durumda tabloların özetlerini oluştururuz ve bunları ham tablolarla birlikte bir belge deposunda saklarız. Bunu başarmak için MultiVectorRetriever'ı kullanacağız. Bu alıcı, özet metinlerin eklerini sakladığımız bir vektör deposunu ve ham belgeleri depolamak için basit bir bellek içi belge deposunu yönetecektir.
Öncelikle daha önce çıkardığımız tablo ve metin verilerini özetlemek için bir özetleme zinciri oluşturun.
from langchain.chat_models import cohere
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
prompt_text = """You are an assistant tasked with summarizing tables and text.
Give a concise summary of the table or text. Table or text chunk: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
model = cohere.ChatCohere(cohere_api_key="your_key")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
tables = [i.page_content for i in table_elements]
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
texts = [i.page_content for i in text_elements]
text_summaries = summarize_chain.batch(texts, {"max_concurrency": 5})Verileri özetlemek için Cohere LLM'yi kullandım; GPT-4 gibi OpenAI modellerini kullanabilirsiniz. Daha iyi modeller daha iyi sonuçlar doğuracaktır. Bazen modeller tablo detaylarını mükemmel şekilde yakalayamayabilir. Bu nedenle yetenekli modelleri kullanmak daha iyidir.
Şimdi MultivectorRetriever'ı yaratıyoruz.
from langchain.retrievers import MultiVectorRetriever
from langchain.prompts import ChatPromptTemplate
import uuid
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.document import Document
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name="collection",
embedding_function=OpenAIEmbeddings(openai_api_key="api_key"))
# The storage layer for the parent documents
store = InMemoryStore()
id_key = ""id"
# The retriever
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
)
# Add texts
doc_ids = [str(uuid.uuid4()) for _ in texts]
summary_texts = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(text_summaries)
]
retriever.vectorstore.add_documents(summary_texts)
retriever.docstore.mset(list(zip(doc_ids, texts)))
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content=s, metadata={id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
Metin ve tabloların özet yerleştirmelerini depolamak için Chroma vektör deposunu ve ham verileri depolamak için bellek içi belge deposunu kullandık.
RAG
Artık alıcımız hazır olduğuna göre Langchain Expression Language'ı kullanarak bir RAG boru hattı oluşturabiliriz.
from langchain.schema.runnable import RunnablePassthrough
# Prompt template
template = """Answer the question based only on the following context,
which can include text and tables::
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature=0.0, openai_api_key="api_key")
# RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
Artık vektör mağazasından alınan yerleştirmelere göre sorular sorabilir ve yanıtlar alabiliriz.
chain.invoke(input = "What is the MT bench score of Llama 2 and Mistral 7B Instruct??")Sonuç
Yarı yapılandırılmış veri formatında pek çok bilgi gizli kalır. Ve bu veriler üzerinde geleneksel RAG'ı çıkarmak ve gerçekleştirmek zordur. Bu makalede, PDF'deki metinleri ve gömülü tabloları çıkarmaktan, Langchain ile çok vektörlü bir alıcı ve RAG ardışık düzeni oluşturmaya geçtik. İşte makaleden önemli çıkarımlar.
Önemli Noktalar
- Geleneksel RAG sıklıkla, metin bölme sırasında tabloları bölme ve kesin olmayan anlamsal aramalar gibi yarı yapılandırılmış verilerle uğraşırken zorluklarla karşı karşıya kalır.
- Yarı yapılandırılmış verilere yönelik açık kaynaklı bir araç olan Yapılandırılmamış, PDF'lerden veya benzer yarı yapılandırılmış verilerden gömülü tabloları çıkarabilir.
- Langchain ile daha iyi anlamsal arama için tabloları, metinleri ve özetleri belge depolarında depolamak üzere çok vektörlü bir alıcı oluşturabiliriz.
Sık Sorulan Sorular
C: Yarı yapılandırılmış veriler, yapılandırılmış verilerden farklı olarak katı bir şemaya sahip değildir ancak hiyerarşileri zorunlu kılan başka işaretleyici biçimlerine sahiptir.
C. Yarı yapılandırılmış veri örnekleri CSV, E-postalar, HTML, XML, parke dosyaları vb.'dir.
A. LangChain, büyük dil modellerini kullanarak uygulamaların oluşturulmasını kolaylaştıran açık kaynaklı bir çerçevedir. Sohbet robotları, RAG, soru cevaplama ve üretken görevler dahil olmak üzere çeşitli görevler için kullanılabilir.
A. RAG işlem hattı, belgeleri harici veri depolarından alır, bunları bir bilgi tabanında depolamak için işler ve sorgulamak için araçlar sağlar.
A. Llama Index açıkça arama ve alma uygulamalarını tasarlarken, Langchain özel AI aracıları oluşturma esnekliği sunar.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/12/building-a-rag-pipeline-for-semi-structured-data-with-langchain/

