Giriş
Sadece altı ayda, OpenAI'nin ChatGPT'si hayatımızın ayrılmaz bir parçası haline geldi. Artık sadece teknoloji ile sınırlı değil; öğrencilerden yazarlara kadar her yaştan ve meslekten insan yoğun bir şekilde kullanıyor. Bu sohbet modelleri doğruluk, hız ve insan benzeri konuşma konusunda mükemmeldir. Sadece teknolojide değil, çeşitli alanlarda önemli bir rol oynamaya hazırlanıyorlar.
Dil modellerinin gücünden yararlanan AutoGPT'ler, BabyAGI ve Langchain gibi açık kaynaklı araçlar ortaya çıktı. İstemlerle programlama görevlerini otomatikleştirin, dil modellerini veri kaynaklarına bağlayın ve yapay zeka uygulamalarını her zamankinden daha hızlı oluşturun. Langchain, PDF'ler için ChatGPT özellikli bir Soru-Cevap aracıdır ve yapay zeka uygulamaları oluşturmak için tek adrestir.
Öğrenme hedefleri
- Gradio kullanarak bir sohbet robotu arabirimi oluşturun
- Metinleri pdf'lerden çıkarın ve yerleştirmeler oluşturun
- Yerleştirmeleri Chroma vektör veritabanında saklayın
- Sorguyu arka uca gönder (Langchain zinciri)
- İlgili veri kaynaklarını bulmak için metinler üzerinde anlamsal arama yapın
- Verileri LLM'ye (ChatGPT) gönderin ve sohbet robotunda yanıtlar alın
Langchain, tüm bu adımları birkaç kod satırında gerçekleştirmeyi kolaylaştırır. Katıştırma modelleri, sohbet modelleri ve vektör veritabanları dahil olmak üzere birden çok hizmet için sarmalayıcılara sahiptir.
Bu makale, Veri Bilimi Blogatonu.
İçindekiler
Langchain nedir?
Langchain, Python'da yazılmış ve harici verilerin Büyük Dil Modellerine bağlanmasına yardımcı olan açık kaynaklı bir araçtır. GPT-4 veya GPT-3.5 gibi sohbet modellerini daha aracılı ve verilere duyarlı hale getirir. Yani, bir bakıma, Langchain LLM'leri üzerinde eğitim almadığı yeni verilerle beslemek için bir yol sağlar. Langchain, dil modelleriyle etkileşimde karmaşıklıkları ortadan kaldıran birçok zincir sağlar. Vektör katıştırmaları oluşturmak için Modeller ve vektörleri depolamak için vektör veritabanları gibi birkaç başka araca da ihtiyacımız var. Daha fazla ilerlemeden önce, metin yerleştirmelere hızlıca bir göz atalım. Bunlar nelerdir ve neden önemlidir?
Metin Gömmeleri
Metin yerleştirmeleri, Büyük Dil İşlemlerinin kalbi ve ruhudur. Teknik olarak, doğal dil içeren dil modelleri ile çalışabiliriz ancak doğal dili depolamak ve geri getirmek oldukça verimsizdir. Örneğin, bu projede, büyük veri yığınları üzerinde yüksek hızlı arama işlemleri gerçekleştirmemiz gerekecek. Doğal dil verileri üzerinde bu tür işlemleri gerçekleştirmek mümkün değildir.
Daha verimli hale getirmek için metin verilerini vektör formlarına dönüştürmemiz gerekiyor. Metinlerden gömme oluşturmak için ayrılmış makine öğrenimi modelleri vardır. Metinler çok boyutlu vektörlere dönüştürülür. Gömüldükten sonra, bu veriler üzerinde gruplayabilir, sıralayabilir, arayabilir ve daha fazlasını yapabiliriz. Ne kadar yakından ilişkili olduklarını bilmek için iki cümle arasındaki mesafeyi hesaplayabiliriz. Ve bunun en iyi yanı, bu işlemlerin geleneksel veritabanı aramaları gibi yalnızca anahtar sözcüklerle sınırlı olmaması, bunun yerine iki cümlenin anlamsal yakınlığını yakalamasıdır. Bu, Makine Öğrenimi sayesinde onu çok daha güçlü kılıyor.
Langchain Araçları
Langchain, Chroma, Redis, Pinecone, Alpine db ve daha fazlası gibi tüm büyük vektör veritabanları için sarmalayıcılara sahiptir. Aynı şey LLM'ler için de geçerlidir, OpeanAI modellerinin yanı sıra Cohere'in GPT modelleri için açık kaynaklı bir alternatif olan GPT4ALL modellerini de destekler. Yerleştirmeler için OpeanAI, Cohere ve HuggingFace yerleştirmeleri için sarmalayıcılar sağlar. Ayrıca özel gömme modellerinizi de kullanabilirsiniz.
Kısacası, Langchain, temel teknolojilerle etkileşime girmenin birçok karmaşıklığını ortadan kaldıran ve herkesin AI uygulamalarını hızlı bir şekilde oluşturmasını kolaylaştıran bir meta-araçtır.
Bu yazıda kullanacağımız OpenAI yerleştirmeleri gömme oluşturmak için model. Son kullanıcılar için bir yapay zeka uygulaması dağıtmak istiyorsanız Huggingface modelleri veya Google'ın Evrensel cümle kodlayıcısı gibi herhangi bir Açık Kaynak modeli kullanmayı düşünün.
Vektörleri depolamak için kullanacağız Kroma DB, açık kaynaklı bir vektör deposu veritabanı. Alpine, Pinecone ve Redis gibi diğer veritabanlarını keşfetmekten çekinmeyin. Langchain, tüm bu vektör depoları için sarmalayıcılara sahiptir.
Bir Langchain zinciri oluşturmak için kullanacağız Sohbet Erişim Zinciri(), geçmişe sahip sohbet modelleriyle sohbet için ideal (konuşmanın bağlamını korumak için). kontrol et onların resmi belgeler farklı LLM zincirleriyle ilgili.
Geliştirme Ortamını Kurma
Kullanacağımız epeyce kütüphane var. Bu nedenle, bunları önceden kurun. Kesintisiz, karmaşadan uzak bir geliştirme ortamı oluşturmak için şunu kullanın: sanal ortamlar or liman işçisi.
gradio = "^3.27.0"
openai = "^0.27.4"
langchain = "^0.0.148"
chromadb = "^0.3.21"
tiktoken = "^0.3.3"
pypdf = "^3.8.1"
pymupdf = "^1.22.2"Şimdi, bu kitaplıkları içe aktarın
import gradio as gr
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI from langchain.document_loaders import PyPDFLoader
import os import fitz
from PIL import ImageSohbet Arayüzü Oluştur
Uygulamanın arayüzü iki ana işleve sahip olacak, biri sohbet arayüzü, diğeri ise PDF'nin ilgili sayfasını bir görüntü olarak işliyor. Bunun dışında, son kullanıcılardan OpenAI API anahtarlarını kabul etmek için bir metin kutusu. Makaleyi incelemenizi şiddetle tavsiye ederim Gradio ile bir GPT sohbet botu oluşturma sıfırdan. Makale, Gradio'nun temel özelliklerini tartışıyor. Bu makaleden pek çok şey ödünç alacağız.
Gradio Blocks sınıfı, bir web uygulaması oluşturmamızı sağlar. Row and Columns sınıfları, web uygulamasında birden çok bileşenin hizalanmasına izin verir. Bunları web arayüzünü özelleştirmek için kullanacağız.
with gr.Blocks() as demo: # Create a Gradio block with gr.Column(): with gr.Row(): with gr.Column(scale=0.8): api_key = gr.Textbox( placeholder='Enter OpenAI API key', show_label=False, interactive=True ).style(container=False) with gr.Column(scale=0.2): change_api_key = gr.Button('Change Key') with gr.Row(): chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650) show_img = gr.Image(label='Upload PDF', tool='select').style(height=680) with gr.Row(): with gr.Column(scale=0.70): txt = gr.Textbox( show_label=False, placeholder="Enter text and press enter" ).style(container=False) with gr.Column(scale=0.15): submit_btn = gr.Button('Submit') with gr.Column(scale=0.15): btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style()
Arayüz birkaç bileşenle basittir.
Şunlar var:
- PDF ile iletişim kurmak için bir sohbet arabirimi.
- İlgili PDF sayfalarını işlemek için bir bileşen.
- API anahtarını kabul etmek için bir metin kutusu ve bir anahtar değiştir düğmesi.
- Soru sormak için bir metin kutusu ve gönder düğmesi.
- Dosyaları yüklemek için bir düğme.
İşte web kullanıcı arayüzünün bir anlık görüntüsü.
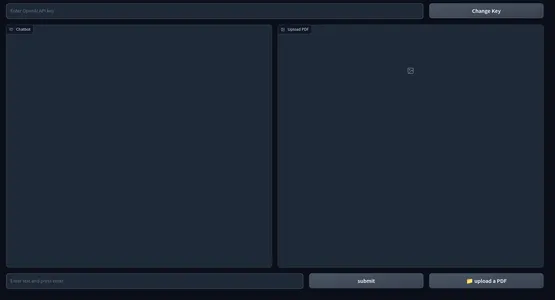
Uygulamamızın ön yüz kısmı tamamlandı. Arka uca geçelim.
Backend
İlk olarak, ele alacağımız süreçleri ana hatlarıyla açıklayalım.
- Yüklenen PDF ve OpenAI API anahtarını işleyin
- Metinleri PDF'den çıkarın ve OpenAI yerleştirmelerini kullanarak ondan metin yerleştirmeleri oluşturun.
- Vektör yerleştirmelerini ChromaDB vektör deposunda saklayın.
- Langchain ile bir Sohbet Erişimi zinciri oluşturun.
- Sorgulanan metin katıştırmaları oluşturun ve katıştırılmış belgeler üzerinde benzerlik araması yapın.
- İlgili belgeleri OpenAI sohbet modeline (gpt-3.5-turbo) gönderin.
- Cevabı alın ve sohbet arayüzünde yayınlayın.
- Web kullanıcı arayüzünde ilgili PDF sayfasını oluşturun.
Bunlar, uygulamamızın genel görünümüdür. Onu inşa etmeye başlayalım.
Gradiyo Etkinlikleri
Web kullanıcı arayüzünde belirli bir eylem gerçekleştirildiğinde, bu olaylar tetiklenir. Böylece olaylar, web uygulamasını etkileşimli ve dinamik hale getirir. Gradio, Python kodlarıyla olayları tanımlamamızı sağlar.
Gradio Events, arka uçla iletişim kurmak için daha önce tanımladığımız bileşen değişkenlerini kullanır. Uygulamamız için ihtiyaç duyduğumuz birkaç Event tanımlayacağız. Bunlar
- API anahtarı olayını gönder: API anahtarını yapıştırdıktan sonra enter tuşuna basmak bu olayı tetikleyecektir.
- Anahtarı Değiştir: Bu, yeni bir API anahtarı sağlamanıza olanak tanır
- Sorgu girin: Chatbot'a metin sorguları gönderin
- Dosya Yükle: Bu, son kullanıcının bir PDF dosyası yüklemesine olanak tanır
with gr.Blocks() as demo: # Create a Gradio block with gr.Column(): with gr.Row(): with gr.Column(scale=0.8): api_key = gr.Textbox( placeholder='Enter OpenAI API key', show_label=False, interactive=True ).style(container=False) with gr.Column(scale=0.2): change_api_key = gr.Button('Change Key') with gr.Row(): chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650) show_img = gr.Image(label='Upload PDF', tool='select').style(height=680) with gr.Row(): with gr.Column(scale=0.70): txt = gr.Textbox( show_label=False, placeholder="Enter text and press enter" ).style(container=False) with gr.Column(scale=0.15): submit_btn = gr.Button('Submit') with gr.Column(scale=0.15): btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style() # Set up event handlers # Event handler for submitting the OpenAI API key api_key.submit(fn=set_apikey, inputs=[api_key], outputs=[api_key]) # Event handler for changing the API key change_api_key.click(fn=enable_api_box, outputs=[api_key]) # Event handler for uploading a PDF btn.upload(fn=render_first, inputs=[btn], outputs=[show_img]) # Event handler for submitting text and generating response submit_btn.click( fn=add_text, inputs=[chatbot, txt], outputs=[chatbot], queue=False ).success( fn=generate_response, inputs=[chatbot, txt, btn], outputs=[chatbot, txt] ).success( fn=render_file, inputs=[btn], outputs=[show_img] )Şimdiye kadar, yukarıdaki olay işleyicileri içinde adı verilen işlevlerimizi tanımlamadık. Ardından, işlevsel bir web uygulaması yapmak için tüm bu işlevleri tanımlayacağız.
API Anahtarlarını İşleyin
Her şey BYOK(Kendi Anahtarını Getir) ilkesine göre çalıştığından, bir kullanıcının API anahtarlarını kullanmak önemlidir. Bir kullanıcı bir anahtar gönderdiğinde, metin kutusu, anahtarın ayarlandığını öne süren bir bilgi istemiyle değiştirilemez hale gelmelidir. Ve “Change Key” olayı tetiklendiğinde, kutunun girdi alabilmesi gerekir.
Bunu yapmak için iki genel değişken tanımlayın.
enable_box = gr.Textbox.update(value=None,placeholder= 'Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI API key is Set',interactive=False)Fonksiyonları tanımlayın
def set_apikey(api_key): os.environ['OPENAI_API_KEY'] = api_key return disable_box def enable_api_box(): return enable_boxset_apikey işlevi bir dize girişi alır ve yürütmeden sonra metin kutusunu değişmez yapan disable_box değişkenini döndürür. Gradio Events bölümünde set_apikey fonksiyonunu çağıran api_key Submit Event tanımladık. OS kütüphanesini kullanarak API anahtarını bir ortam değişkeni olarak ayarladık.
API anahtarını değiştir düğmesinin tıklanması, metin kutusunun yeniden değişkenliğini etkinleştiren enable_box değişkenini döndürür.
Zincir Oluştur
Bu en önemli adım. Bu adım, metinlerin çıkarılmasını ve katıştırmaların oluşturulmasını ve bunların vektör depolarında saklanmasını içerir. İşleri kolaylaştıran birden çok hizmet için sarmalayıcılar sağlayan Langchain sayesinde. Öyleyse, işlevi tanımlayalım.
def process_file(file): # raise an error if API key is not provided if 'OPENAI_API_KEY' not in os.environ: raise gr.Error('Upload your OpenAI API key') # Load the PDF file using PyPDFLoader loader = PyPDFLoader(file.name) documents = loader.load() # Initialize OpenAIEmbeddings for text embeddings embeddings = OpenAIEmbeddings() # Create a ConversationalRetrievalChain with ChatOpenAI language model # and PDF search retriever pdfsearch = Chroma.from_documents(documents, embeddings,) chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.3), retriever= pdfsearch.as_retriever(search_kwargs={"k": 1}), return_source_documents=True,) return chain- API anahtarının ayarlanıp ayarlanmadığını kontrol etti. Bu, Anahtar ayarlanmazsa ön uçta bir hataya neden olur.
- PyPDFLoader kullanarak PDF dosyasını yükleyin
- Tanımlı yerleştirmeler, OpenAIEmbeddings ile çalışır.
- Gömme işlevini kullanarak PDF'deki metin listesinden bir vektör deposu oluşturdu.
- ChatOpenAI (varsayılan olarak ChatOpenAI, gpt-3.5-turbo kullanır) ile bir zincir tanımladı, bir temel alıcı (benzerlik araması kullanır).
Yanıt Oluştur
Zincir oluşturulduktan sonra zinciri arayacağız ve sorgularımızı göndereceğiz. Konuşmaların bağlamını korumak ve yanıtları sohbet arayüzüne aktarmak için sorgularla birlikte bir sohbet geçmişi gönderin. Fonksiyonu tanımlayalım.
def generate_response(history, query, btn): global COUNT, N, chat_history # Check if a PDF file is uploaded if not btn: raise gr.Error(message='Upload a PDF') # Initialize the conversation chain only once if COUNT == 0: chain = process_file(btn) COUNT += 1 # Generate a response using the conversation chain result = chain({"question": query, 'chat_history':chat_history}, return_only_outputs=True) # Update the chat history with the query and its corresponding answer chat_history += [(query, result["answer"])] # Retrieve the page number from the source document N = list(result['source_documents'][0])[1][1]['page'] # Append each character of the answer to the last message in the history for char in result['answer']: history[-1][-1] += char # Yield the updated history and an empty string yield history, ''
- Yüklenen PDF yoksa bir hata verir.
- process_file işlevini yalnızca bir kez çağırır.
- Sorguları ve sohbet geçmişini zincire gönderir
- En alakalı yanıtın sayfa numarasını alır.
- Ön uca verim yanıtları.
Bir PDF Dosyasının Görüntüsünü Oluşturma
Son adım, PDF dosyasının görüntüsünü en alakalı yanıtla oluşturmaktır. Belgenin görüntülerini işlemek için PyMuPdf ve PIL kitaplıklarını kullanabiliriz.
def render_file(file): global N # Open the PDF document using fitz doc = fitz.open(file.name) # Get the specific page to render page = doc[N] # Render the page as a PNG image with a resolution of 300 DPI pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72)) # Create an Image object from the rendered pixel data image = Image.frombytes('RGB', [pix.width, pix.height], pix.samples) # Return the rendered image return image
- Dosyayı PyMuPdf's Fitz ile açın.
- İlgili sayfayı alın.
- Sayfa için piksel haritasını alın.
- Görüntüyü PIL'in Image sınıfından oluşturun.
Herhangi bir PDF ile sohbet etmek için işlevsel bir web uygulaması için yapmamız gereken her şey bu.
Her şeyi bir araya getirmek
#import csv
import gradio as gr
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI from langchain.document_loaders import PyPDFLoader
import os import fitz
from PIL import Image # Global variables
COUNT, N = 0, 0
chat_history = []
chain = ''
enable_box = gr.Textbox.update(value=None, placeholder='Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value='OpenAI API key is Set', interactive=False) # Function to set the OpenAI API key
def set_apikey(api_key): os.environ['OPENAI_API_KEY'] = api_key return disable_box # Function to enable the API key input box
def enable_api_box(): return enable_box # Function to add text to the chat history
def add_text(history, text): if not text: raise gr.Error('Enter text') history = history + [(text, '')] return history # Function to process the PDF file and create a conversation chain
def process_file(file): if 'OPENAI_API_KEY' not in os.environ: raise gr.Error('Upload your OpenAI API key') loader = PyPDFLoader(file.name) documents = loader.load() embeddings = OpenAIEmbeddings() pdfsearch = Chroma.from_documents(documents, embeddings) chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.3), retriever=pdfsearch.as_retriever(search_kwargs={"k": 1}), return_source_documents=True) return chain # Function to generate a response based on the chat history and query
def generate_response(history, query, btn): global COUNT, N, chat_history, chain if not btn: raise gr.Error(message='Upload a PDF') if COUNT == 0: chain = process_file(btn) COUNT += 1 result = chain({"question": query, 'chat_history': chat_history}, return_only_outputs=True) chat_history += [(query, result["answer"])] N = list(result['source_documents'][0])[1][1]['page'] for char in result['answer']: history[-1][-1] += char yield history, '' # Function to render a specific page of a PDF file as an image
def render_file(file): global N doc = fitz.open(file.name) page = doc[N] # Render the page as a PNG image with a resolution of 300 DPI pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72)) image = Image.frombytes('RGB', [pix.width, pix.height], pix.samples) return image # Gradio application setup
with gr.Blocks() as demo: # Create a Gradio block with gr.Column(): with gr.Row(): with gr.Column(scale=0.8): api_key = gr.Textbox( placeholder='Enter OpenAI API key', show_label=False, interactive=True ).style(container=False) with gr.Column(scale=0.2): change_api_key = gr.Button('Change Key') with gr.Row(): chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650) show_img = gr.Image(label='Upload PDF', tool='select').style(height=680) with gr.Row(): with gr.Column(scale=0.70): txt = gr.Textbox( show_label=False, placeholder="Enter text and press enter" ).style(container=False) with gr.Column(scale=0.15): submit_btn = gr.Button('Submit') with gr.Column(scale=0.15): btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style() # Set up event handlers # Event handler for submitting the OpenAI API key api_key.submit(fn=set_apikey, inputs=[api_key], outputs=[api_key]) # Event handler for changing the API key change_api_key.click(fn=enable_api_box, outputs=[api_key]) # Event handler for uploading a PDF btn.upload(fn=render_first, inputs=[btn], outputs=[show_img]) # Event handler for submitting text and generating response submit_btn.click( fn=add_text, inputs=[chatbot, txt], outputs=[chatbot], queue=False ).success( fn=generate_response, inputs=[chatbot, txt, btn], outputs=[chatbot, txt] ).success( fn=render_file, inputs=[btn], outputs=[show_img] )
demo.queue()
if __name__ == "__main__": demo.launch()Artık her şeyi yapılandırdığımıza göre, uygulamamızı başlatalım.
Uygulamayı aşağıdaki komutla hata ayıklama modunda başlatabilirsiniz.
gradio uygulaması.py
Aksi takdirde, uygulamayı Python komutuyla da çalıştırabilirsiniz. Aşağıda son ürünün bir anlık görüntüsü var. GitHub deposu kodları.
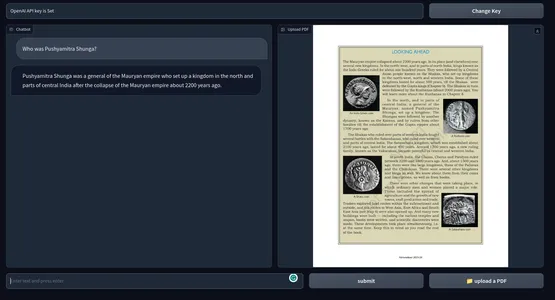
[Gömülü içerik]
Olası İyileştirmeler
Mevcut uygulama harika çalışıyor. Ama daha iyi hale getirmek için yapabileceğiniz birkaç şey var.
- Bu, uzun vadede pahalı olabilecek OpenAI yerleştirmelerini kullanır. Üretime hazır bir uygulama için herhangi bir çevrimdışı katıştırma modeli daha uygun olabilir.
- Prototipleme için gradio iyidir, ancak gerçek dünya için Next Js veya Svelte gibi modern bir javascript çerçevesine sahip bir uygulama, performans ve estetik açısından çok daha iyi olacaktır.
- İlgili metinleri bulmak için kosinüs benzerliğini kullandık. Bazı durumlarda, bir KNN yaklaşımı daha iyi olabilir.
- Yoğun metin içeriğine sahip PDF'ler için daha küçük metin parçaları oluşturmak daha iyi olabilir.
- Model ne kadar iyi olursa, performans o kadar iyi olur. Diğer LLM'lerle deneyler yapın ve sonuçları karşılaştırın.
Pratik Kullanım Örnekleri
Eğitimden Hukuka, Akademiye kadar birçok alanda veya kişinin büyük metinler üzerinden geçmesini gerektiren hayal edebileceğiniz herhangi bir alanda araçları kullanın. PDF'ler için ChatGPT'nin pratik kullanım örneklerinden bazıları şunlardır:
- Eğitim Kurumları: Öğrenciler ders kitaplarını, çalışma materyallerini ve ödevlerini yükleyebilir ve araç soruları yanıtlayabilir ve belirli bölümleri açıklayabilir. Bu, genel öğrenme sürecini öğrenciler için daha az yorucu hale getirebilir.
- Yasal: Hukuk firmaları, PDF formatında çok sayıda yasal belge ile uğraşmak zorundadır. Bu araç, vaka belgelerinden, yasal sözleşmelerden ve tüzüklerden uygun bilgileri çıkarmak için kullanılabilir. Avukatların hükümleri, içtihatları ve diğer bilgileri daha hızlı bulmasına yardımcı olabilir.
- Akademi: Araştırma akademisyenleri genellikle Araştırma makaleleri ve teknik belgelerle ilgilenir. Literatürü özetleyebilen, belgeleri analiz edebilen ve yanıtlar sağlayabilen bir araç, toplam zamandan büyük ölçüde tasarruf sağlayabilir ve üretkenliği artırabilir.
- İdare: hükümet ofisler ve diğer idari departmanlar, günlük olarak bol miktarda form, başvuru ve raporla ilgilenir. Belgeleri yanıtlayan bir sohbet robotu kullanmak, yönetim sürecini düzene sokarak herkesin zamandan ve paradan tasarruf etmesini sağlayabilir.
- Finans: Finansal raporları analiz etmek ve tekrar tekrar gözden geçirmek sıkıcıdır. Bu, bir chatbot kullanılarak daha kolay hale getirilebilir. Aslında bir stajyer.
- medya: Gazeteciler ve Analistler, yanıtları hızlı bir şekilde bulmak için büyük metin külliyatını sorgulamak için chatGPT özellikli bir PDF soru yanıtlama aracı kullanabilir.
chatGPT özellikli bir PDF Soru-Cevap aracı, PDF metin yığınlarından daha hızlı bilgi toplayabilir. Metin verileri için bir arama motoru gibidir. Sadece PDF'ler için değil, aynı zamanda küçük bir kod düzenlemesi ile bu aracı metin verileri içeren her şeye genişletebiliriz.
Sonuç
Yani, bu tamamen ChatGPT ile herhangi bir PDF dosyasıyla sohbet etmek için bir sohbet botu oluşturmakla ilgiliydi. Langchain sayesinde yapay zeka uygulamaları oluşturmak çok daha kolay hale geldi. Makaleden bazı önemli çıkarımlar şunlardır:
- Gradio, AI uygulamalarının prototipini oluşturmak için açık kaynaklı bir araçtır. Uygulamanın ön ucunu Gradio ile oluşturduk.
- Langchain, AI uygulamaları oluşturmamıza izin veren başka bir açık kaynaklı araçtır. Temel hizmetlerle kolayca etkileşim kurmamızı sağlayan popüler LLM'ler ve vektör veri depoları için sarmalayıcılara sahiptir.
- Uygulamamızın arka uç sistemlerini oluşturmak için Langchain kullandık.
- OpenAI modelleri, uygulamamız için genel olarak çok önemliydi. PDF'lerle sohbet etmek için OpenAI yerleştirmelerini ve GPT 3.5 motorunu kullandık.
- PDF'ler ve diğer metin verileri için ChatGPT özellikli bir Soru-Cevap aracı, bilgi görevlerini kolaylaştırmada uzun bir yol kat edebilir.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoAiStream. Web3 Veri Zekası. Bilgi Genişletildi. Buradan Erişin.
- Adryenn Ashley ile Geleceği Basmak. Buradan Erişin.
- PREIPO® ile PRE-IPO Şirketlerinde Hisse Al ve Sat. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/05/build-a-chatgpt-for-pdfs-with-langchain/

