Giriş
Alanında sürekli hassasiyet ve güvenilirlik arayışı Yapay Zeka (AI) oyunun kurallarını değiştiren yenilikler getirdi. Bu stratejiler, bir dizi soruya anlamlı yanıtlar sunan üretken modellere liderlik etme açısından kritik öneme sahiptir. Üretken yapay zekanın farklı karmaşık uygulamalarda kullanılmasının önündeki en büyük engellerden biri halüsinasyondur. Meta AI Research tarafından yayınlanan son makale “Doğrulama Zinciri Büyük Dil Modellerinde Halüsinasyonu Azaltır” metin oluştururken halüsinasyonu doğrudan azaltmaya yönelik basit bir tekniği tartışıyor.
Bu makalede, halüsinasyon sorunları hakkında bilgi edineceğiz ve makalede bahsedilen CoVe kavramlarını ve özel zincirler oluşturmak için LLM'leri, LangChain Çerçevesini ve LangChain İfade Dili (LCEL) kullanarak bunun nasıl uygulanacağını inceleyeceğiz.
Öğrenme hedefleri
- Yüksek Lisans'taki halüsinasyon sorununu anlayın.
- Halüsinasyonu azaltmak için Doğrulama Zinciri (CoVe) mekanizması hakkında bilgi edinin.
- CoVe'nin avantajlarını ve dezavantajlarını öğrenin.
- CoVe'yi LangChain kullanarak uygulamayı öğrenin ve LangChain İfade Dilini anlayın.
Bu makale, Veri Bilimi Blogatonu.
İçindekiler
Yüksek Lisansta Halüsinasyon Sorunu Nedir?
Önce Yüksek Lisans'taki halüsinasyon konusunu öğrenmeye çalışalım. Otoregresif oluşturma yaklaşımını kullanan LLM modeli, önceki bağlam göz önüne alındığında sonraki kelimeyi tahmin eder. Sık görülen temalar için model, doğru belirteçlere yüksek bir olasılığı güvenle atamak için yeterli sayıda örnek gördü. Ancak model alışılmadık veya alışılmadık konular üzerinde eğitilmediği için yüksek güvenle hatalı tokenlar sunabilir. Bu, akla yatkın görünen ancak yanlış bilgilerin halüsinasyonlarına neden olur.
Aşağıda Open AI'nin ChatGPT'sinde Hintli bir yazar tarafından 2020'de yayınlanan "Küçük Şeylerin Ekonomisi" kitabı hakkında soru sorduğumda böyle bir halüsinasyon örneği var, ancak model tam bir özgüvenle yanlış cevabı tükürdü ve onu başka birinin kitabıyla karıştırdı. Nobel ödüllü Abhijit Banerjee'nin "Kötü Ekonomi" başlıklı makalesi.

Doğrulama Zinciri (CoVe) Tekniği
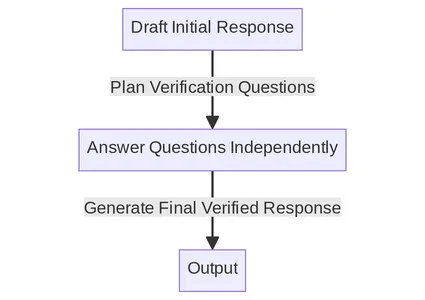
CoVe mekanizması, LLM'ler için bir kendi kendini doğrulama sistemi oluşturmak amacıyla yönlendirme ve tutarlılık kontrollerini birleştirir. Aşağıda makalede listelenen ana adımlar verilmiştir. Her adımı tek tek detaylı olarak anlamaya çalışacağız.
Zincir Sürecine Genel Bakış
- Temel Yanıt Oluşturun: Bir sorgu verildiğinde, LLM'yi kullanarak yanıtı oluşturun.
- Plan Doğrulamaları: Hem sorgu hem de temel yanıt göz önüne alındığında, orijinal yanıtta herhangi bir hata olup olmadığını kendi kendinize analiz etmenize yardımcı olabilecek bir doğrulama soruları listesi oluşturun.
- Doğrulamaları Yürütün: Her doğrulama sorusunu sırayla yanıtlayın ve dolayısıyla tutarsızlıkları veya hataları kontrol etmek için yanıtı orijinal yanıtla karşılaştırın.
- Nihai Doğrulanmış Yanıt Oluşturun: Keşfedilen tutarsızlıklar göz önüne alındığında (varsa), doğrulama sonuçlarını içeren revize edilmiş bir yanıt oluşturun.
Ayrıntılı Örnek Kullanarak Zincir Sürecini Anlamak
İlk Yanıt Oluştur
İlk olarak sorgumuzu herhangi bir ilk yanıt oluşturması için herhangi bir özel istek olmadan LLM'ye iletiyoruz. Bu CoVe süreci için başlangıç noktası görevi görüyor. Bunun gibi temel reaksiyonlar sıklıkla halüsinasyonlara yatkın olduğundan, CoVe tekniği bu hataları daha sonraki aşamalarda keşfetmeyi ve düzeltmeyi amaçlamaktadır.
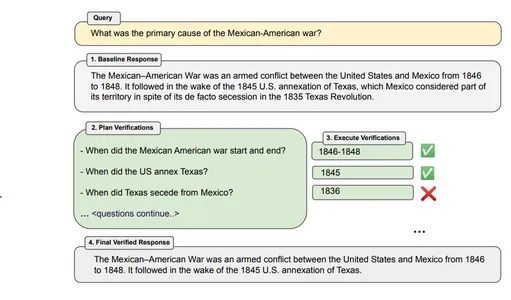
Örnek - "Meksika-Amerika Savaşı'nın temel nedeni nedir?"
Bot Tepkisi – Meksika-Amerikan Savaşı, 1846'dan 1848'e kadar Amerika Birleşik Devletleri ile Meksika arasında yaşanan silahlı çatışmaydı. Bunu, fiili olarak kendi topraklarının bir parçası olarak kabul edilen Teksas'ın 1845'te ABD tarafından ilhak edilmesinin ardından izledi. 1835 Teksas Devrimi'nde ayrılık.
Doğrulamaları Planlayın
Temel yanıtın gerçek iddialarını incelememize olanak tanıyan sorgu ve temel yanıta dayalı doğrulama soruları oluşturun. Bunu uygulamak için hem sorguya hem de temel yanıta dayalı bir dizi doğrulama sorusunu modelleyebiliriz. Doğrulama soruları esnek olabilir ve orijinal metinle tam olarak eşleştirilmesine gerek yoktur.
Örnek E-posta – Meksika – Amerika savaşı ne zaman başladı ve bitti? ABD Teksas'ı ne zaman ilhak etti? Teksas Meksika'dan ne zaman ayrıldı?
Doğrulamaları Yürütün
Doğrulama sorularını planladıktan sonra bu soruları ayrı ayrı yanıtlayabiliriz. Belgede doğrulamaları gerçekleştirmek için 4 farklı yöntem ele alınmaktadır:
1. Ortak – Bu sayede doğrulama sorularının planlanması ve yürütülmesi tek bir komutla gerçekleştirilir. Sorular ve cevapları aynı LLM isteminde verilmektedir. Doğrulama yanıtı halüsinasyona neden olabileceğinden bu yöntem genellikle önerilmez.
2. 2 Adımlı – Planlama ve yürütme, ayrı LLM istemleriyle iki adımda ayrı ayrı yapılır. Öncelikle doğrulama soruları oluşturuyoruz ve ardından bu soruları yanıtlıyoruz.
3. Faktoringli – Burada her doğrulama sorusu aynı büyük yanıt yerine bağımsız olarak yanıtlanır ve temel orijinal yanıt dahil edilmez. Farklı doğrulama soruları arasındaki karışıklığın önlenmesine yardımcı olabilir ve ayrıca daha fazla sayıda soruyu ele alabilir.
4. Faktoring + Revize – Bu yönteme bir adım daha eklenir. Her doğrulama sorusunu yanıtladıktan sonra CoVe mekanizması, yanıtların orijinal temel yanıtla eşleşip eşleşmediğini kontrol eder. Bu, ek bir istem kullanılarak ayrı bir adımda yapılır.
Harici Araçlar veya Kişisel LLM: Yanıtlarımızı doğrulayacak ve doğrulama yanıtları verecek bir araca ihtiyacımız var. Bu, LLM'nin kendisi veya harici bir araç kullanılarak gerçekleştirilebilir. Daha fazla doğruluk istiyorsak, Yüksek Lisans'a güvenmek yerine, kullanım durumumuza bağlı olarak internet arama motoru, herhangi bir referans belge veya herhangi bir web sitesi gibi harici araçları kullanabiliriz.
Nihai Doğrulanmış Yanıt
Bu son adımda geliştirilmiş ve doğrulanmış bir yanıt oluşturulur. Birkaç adımlık bir istem kullanılır ve önceki tüm temel yanıt bağlamı ve doğrulama sorusu yanıtları dahil edilir. “Faktör+Revize” yöntemi kullanılmışsa çapraz kontrol tutarsızlığının çıktısı da sağlanır.
CoVe Tekniğinin Sınırlamaları
Doğrulama Zinciri basit ama etkili bir teknik gibi görünse de yine de bazı sınırlamaları vardır:
- Halüsinasyonun Tamamen Kaldırılmaması: Halüsinasyonların yanıttan tamamen çıkarılmasını garanti etmez ve dolayısıyla yanıltıcı bilgi üretebilir.
- Yoğun Bilgi İşlem: Yanıt oluşturmanın yanı sıra doğrulamaların oluşturulması ve yürütülmesi, hesaplama yükünü ve maliyetini artırabilir. Bu nedenle süreci yavaşlatabilir veya bilgi işlem maliyetini artırabilir.
- Modele Özel Sınırlama: Bu CoVe yönteminin başarısı büyük ölçüde modelin yeteneklerine ve hatalarını tespit edip düzeltme yeteneğine bağlıdır.
CoVe'nin LangChain Uygulaması
Algoritmanın Temel Taslağı
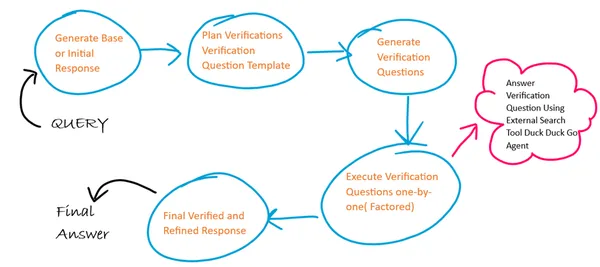
Burada CoVe'deki 4 adımın her biri için 4 farklı bilgi istemi şablonu kullanacağız ve her adımda bir önceki adımın çıktısı bir sonraki adım için girdi görevi görecektir. Ayrıca doğrulama sorularının yürütülmesinde faktörlü bir yaklaşım izliyoruz. Doğrulama sorularımıza yanıtlar oluşturmak için harici bir internet arama aracı aracısı kullanıyoruz.
1. Adım: Kitaplıkları Kurun ve Yükleyin
!pip install langchain duckduckgo-searchAdım 2: LLM Örneğini Oluşturun ve Başlatın
Ücretsiz olarak mevcut olduğundan Langchain'de Google Palm LLM'yi kullanıyorum. Bunu kullanarak Google Palm için API Anahtarı oluşturulabilir Link ve Google hesabınızı kullanarak giriş yapın.
from langchain import PromptTemplate
from langchain.llms import GooglePalm
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
API_KEY='Generated API KEY'
llm=GooglePalm(google_api_key=API_KEY)
llm.temperature=0.4
llm.model_name = 'models/text-bison-001'
llm.max_output_tokens=2048
3. Adım: İlk Temel Yanıtın Oluşturulması
Şimdi ilk temel yanıtı oluşturmak için bir bilgi istemi şablonu oluşturacağız ve bu şablonu kullanarak temel yanıt LLM zincirini oluşturacağız.
Bir LLM zinciri, zinciri oluşturmak için LangChain İfade Dilini kullanacaktır. Burada istem şablonunu LLM modeli (|) ile zincirlenmiş (|) ve son olarak Çıktı ayrıştırıcısını veriyoruz.
BASELINE_PROMPT = """Answer the below question which is asking for a concise factual answer. NO ADDITIONAL DETAILS.
Question: {query}
Answer:"""
# Chain to generate initial response
baseline_response_prompt_template = PromptTemplate.from_template(BASELINE_PROMPT)
baseline_response_chain = baseline_response_prompt_template | llm | StrOutputParser()Adım 4: Doğrulama Sorusu için Soru Şablonu Oluşturun
Şimdi bir sonraki adımda doğrulama sorularının oluşturulmasına yardımcı olacak bir doğrulama sorusu şablonu oluşturacağız.
VERIFICATION_QUESTION_TEMPLATE = """Your task is to create a verification question based on the below question provided.
Example Question: Who wrote the book 'God of Small Things' ?
Example Verification Question: Was book [God of Small Things] written by [writer]? If not who wrote [God of Small Things] ?
Explanation: In the above example the verification question focused only on the ANSWER_ENTITY (name of the writer) and QUESTION_ENTITY (book name).
Similarly you need to focus on the ANSWER_ENTITY and QUESTION_ENTITY from the actual question and generate verification question.
Actual Question: {query}
Final Verification Question:"""
# Chain to generate a question template for verification answers
verification_question_template_prompt_template = PromptTemplate.from_template(VERIFICATION_QUESTION_TEMPLATE)
verification_question_template_chain = verification_question_template_prompt_template | llm | StrOutputParser()Adım 5: Doğrulama Sorusu Oluşturun
Şimdi yukarıda tanımlanan doğrulama sorusu şablonunu kullanarak doğrulama soruları oluşturacağız:
VERIFICATION_QUESTION_PROMPT= """Your task is to create a series of verification questions based on the below question, the verfication question template and baseline response.
Example Question: Who wrote the book 'God of Small Things' ?
Example Verification Question Template: Was book [God of Small Things] written by [writer]? If not who wrote [God of Small Things]?
Example Baseline Response: Jhumpa Lahiri
Example Verification Question: 1. Was God of Small Things written by Jhumpa Lahiri? If not who wrote God of Small Things ?
Explanation: In the above example the verification questions focused only on the ANSWER_ENTITY (name of the writer) and QUESTION_ENTITY (name of book) based on the template and substitutes entity values from the baseline response.
Similarly you need to focus on the ANSWER_ENTITY and QUESTION_ENTITY from the actual question and substitute the entity values from the baseline response to generate verification questions.
Actual Question: {query}
Baseline Response: {base_response}
Verification Question Template: {verification_question_template}
Final Verification Questions:"""
# Chain to generate the verification questions
verification_question_generation_prompt_template = PromptTemplate.from_template(VERIFICATION_QUESTION_PROMPT)
verification_question_generation_chain = verification_question_generation_prompt_template | llm | StrOutputParser()
Adım 6: Doğrulama Sorusunu Yürütün
Burada doğrulama sorusunu yürütmek için harici arama aracı aracısını kullanacağız. Bu aracı, LangChain'in Aracı ve Araçlar modülü ve DuckDuckGo arama modülü kullanılarak oluşturulmuştur.
Not – Birden fazla istek, istekler arasındaki zaman kısıtlamaları nedeniyle hatayla sonuçlanabileceğinden, arama aracılarında dikkatli kullanılması gereken zaman kısıtlamaları vardır.
from langchain.agents import ConversationalChatAgent, AgentExecutor
from langchain.tools import DuckDuckGoSearchResults
#create search agent
search = DuckDuckGoSearchResults()
tools = [search]
custom_system_message = "Assistant assumes no knowledge & relies on internet search to answer user's queries."
max_agent_iterations = 5
max_execution_time = 10
chat_agent = ConversationalChatAgent.from_llm_and_tools(
llm=llm, tools=tools, system_message=custom_system_message
)
search_executor = AgentExecutor.from_agent_and_tools(
agent=chat_agent,
tools=tools,
return_intermediate_steps=True,
handle_parsing_errors=True,
max_iterations=max_agent_iterations,
max_execution_time = max_execution_time
)
# chain to execute verification questions
verification_chain = RunnablePassthrough.assign(
split_questions=lambda x: x['verification_questions'].split("n"), # each verification question is passed one by one factored approach
) | RunnablePassthrough.assign(
answers = (lambda x: [{"input": q,"chat_history": []} for q in x['split_questions']])| search_executor.map() # search executed for each question independently
) | (lambda x: "n".join(["Question: {} Answer: {}n".format(question, answer['output']) for question, answer in zip(x['split_questions'], x['answers'])]))# Create final refined response
Adım 7: Nihai Ayrıntılı Yanıt Oluşturun
Şimdi istem şablonunu ve llm zincirini tanımladığımız son hassas yanıtı oluşturacağız.
FINAL_ANSWER_PROMPT= """Given the below `Original Query` and `Baseline Answer`, analyze the `Verification Questions & Answers` to finally provide the refined answer.
Original Query: {query}
Baseline Answer: {base_response}
Verification Questions & Answer Pairs:
{verification_answers}
Final Refined Answer:"""
# Chain to generate the final answer
final_answer_prompt_template = PromptTemplate.from_template(FINAL_ANSWER_PROMPT)
final_answer_chain = final_answer_prompt_template | llm | StrOutputParser()Adım 8: Tüm Zincirleri Birleştirin
Şimdi daha önce tanımladığımız tüm zincirleri tek seferde sıralı çalışacak şekilde bir araya getiriyoruz.
chain = RunnablePassthrough.assign(
base_response=baseline_response_chain
) | RunnablePassthrough.assign(
verification_question_template=verification_question_template_chain
) | RunnablePassthrough.assign(
verification_questions=verification_question_generation_chain
) | RunnablePassthrough.assign(
verification_answers=verification_chain
) | RunnablePassthrough.assign(
final_answer=final_answer_chain
)
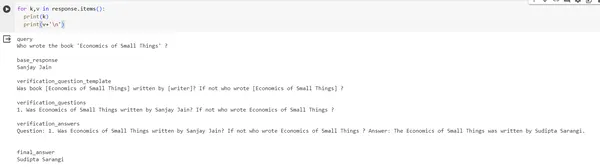
response = chain.invoke({"query": "Who wrote the book 'Economics of Small Things' ?"})
print(response)#output of response
{'query': "Who wrote the book 'Economics of Small Things' ?", 'base_response': 'Sanjay Jain', 'verification_question_template': 'Was book [Economics of Small Things] written by [writer]? If not who wrote [Economics of Small Things] ?', 'verification_questions': '1. Was Economics of Small Things written by Sanjay Jain? If not who wrote Economics of Small Things ?', 'verification_answers': 'Question: 1. Was Economics of Small Things written by Sanjay Jain? If not who wrote Economics of Small Things ? Answer: The Economics of Small Things was written by Sudipta Sarangi n', 'final_answer': 'Sudipta Sarangi'}Çıktı resmi:
Sonuç
Çalışmada önerilen Doğrulama Zinciri (CoVe) tekniği, büyük dil modelleri oluşturmayı, yanıtları hakkında daha eleştirel düşünmeyi ve gerekirse kendilerini düzeltmeyi amaçlayan bir stratejidir. Bunun nedeni, bu yöntemin doğrulamayı daha küçük, daha yönetilebilir sorgulara bölmesidir. Ayrıca modelin önceki yanıtlarını incelemesinin yasaklanmasının, hataların veya "halüsinasyonların" tekrarlanmasını önlemeye yardımcı olduğu da gösterilmiştir. Basitçe modelin yanıtlarını iki kez kontrol etmesini gerektirmek, sonuçları önemli ölçüde artırır. CoVe'ye dış kaynaklardan bilgi almasına izin vermek gibi daha fazla yetenek vermek, etkinliğini artırmanın bir yolu olabilir.
Önemli Noktalar
- Zincir süreci, yanıtımızın farklı bölümlerini doğrulamamızı sağlayan çeşitli teknik kombinasyonlarını içeren kullanışlı bir araçtır.
- Pek çok avantajın yanı sıra, Zincir sürecinin farklı araç ve mekanizmalar kullanılarak azaltılabilen belirli sınırlamaları da vardır.
- Bu CoVe sürecini uygulamak için LangChain paketinden yararlanabiliriz.
Sık Sorulan Sorular
C. Halüsinasyonu farklı düzeylerde azaltmanın birçok yolu vardır: İstem Düzeyi (Düşünce Ağacı, Düşünce Zinciri), Model Düzeyi (Zıt Katmanlarla DoLa Kod Çözme) ve Otomatik Kontrol (CoVe).
C. Google Arama API'si vb. Harici Arama Araçlarının desteğini kullanarak CoVe'deki doğrulama sürecini geliştirebiliriz ve alan adı ve özel kullanım durumları için RAG gibi alma tekniklerini kullanabiliriz.
C. Şu anda bu mekanizmayı uygulayan kullanıma hazır bir açık kaynaklı araç mevcut değil ancak Serp API, Google Arama ve Lang Chains'in yardımıyla kendi başımıza bir araç oluşturabiliriz.
A. Alma Artırılmış Üretim (RAG) tekniği, LLM'nin bu alana özgü verilerden almaya dayalı olarak gerçek anlamda doğru yanıtlar üretebildiği alana özgü kullanım durumları için kullanılır.
C. Makalede yüksek lisans olarak Llama 65B modeli kullanılmış, daha sonra sorular oluşturmak ve modele rehberlik sağlamak için birkaç örnekten yararlanarak bilgi istemi mühendisliğini kullanmışlardır.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/12/chain-of-verification-implementation-using-langchain-expression-language-and-llm/

