Bu makale, Veri Bilimi Blogathon.

Kaynak: Arxiv|Arama Motoru Dergisi
Giriş
Doğal dil işlemenin mevcut küresel BT sektöründe en popüler ve rekabetçi işlemlerden biri olduğu yaygın bir bilgidir. Tüm üst düzey kuruluşlar ve yeni gelişen girişimler, NLP ile ilgili güçlü becerilere sahip adayları arıyor.
Doğal Dil İşleme (NLP), Dilbilim, Bilgisayar Bilimi ve Yapay Zekanın kesiştiği alandır. Makinelerin insan dillerini anlamasını, analiz etmesini, manipüle etmesini ve yorumlamasını sağlayan teknolojidir.
NLP'nin şirketlerde, yeni kurulan şirketlerde ve akademide yeni çözümler geliştirmek için talebi, popülerliği ve geniş kullanımı göz önüne alındığında, sektörde kendinize bir yer edinmek için NLP'nin temellerini net bir şekilde anlamak zorunludur. Bu nedenle, bu blogda, konuyu daha iyi tanımanız ve bir sonraki röportajınızda başarılı olmanızı sağlayacak etkili bir cevap tasarlamanız için bir rehber olarak kullanabileceğiniz Klasik NLP ile ilgili on bir zorunlu sorudan oluşan bir liste hazırladım!
Öyleyse başlayalım!
Klasik NLP ile İlgili Mülakat Soruları
Klasik NLP ile ilgili ayrıntılı cevapları olan bazı sorular aşağıdadır.
Soru 1: Köklenme Nedir?
Cevap: Kökten çıkarma, bir sözcüğü sözcük köküne indirgeme işlemidir; bu genellikle yapım eklerinin kaldırılmasını da içerir.
Birçok sözcük çeşidi aynı anlamı taşır ve kök ayırma yardımıyla arama tablosu kısaltılabilir ve cümleler normalleştirilebilir; bu da Doğal Dil İşleme (NLP) ve Doğal Dil Anlama konusunda yardımcı olur.

Şekil 1: Kök Alma Örnekleri
Kaynak: Analytics Vidhya
Yukarıdaki örnekten, "tarih" ve tarihsel kelimelerinin aynı köke, "tarih"e sahip olduğunu görebiliriz; ancak kökten çıkarmanın çıktısı şudur. Bu, kökten çıkarma yaklaşımının yetersizliğini vurgulayan bir örnektir. Aşağıdaki sorularda bu konuyu daha ayrıntılı olarak ele alacağız.
Uygulamalar: Arama Motorları, Dizin Oluşturma, Etiketleme sistemleri, Duyarlılık Analizi, Spam Sınıflandırması, Belge Kümeleme vb. gibi Bilgi Erişim Sistemleri.
Soru 2: Stemming'de çok belirgin iki hatanın adını verebilir misiniz?
Stemming'in buluşsal yöntemlere dayandığı göz önüne alındığında, mükemmel olmaktan uzaktır. Köklendirmede en yaygın iki hata şunlardır:
a) Aşırı köklenme
b) Yetersiz Köklenme
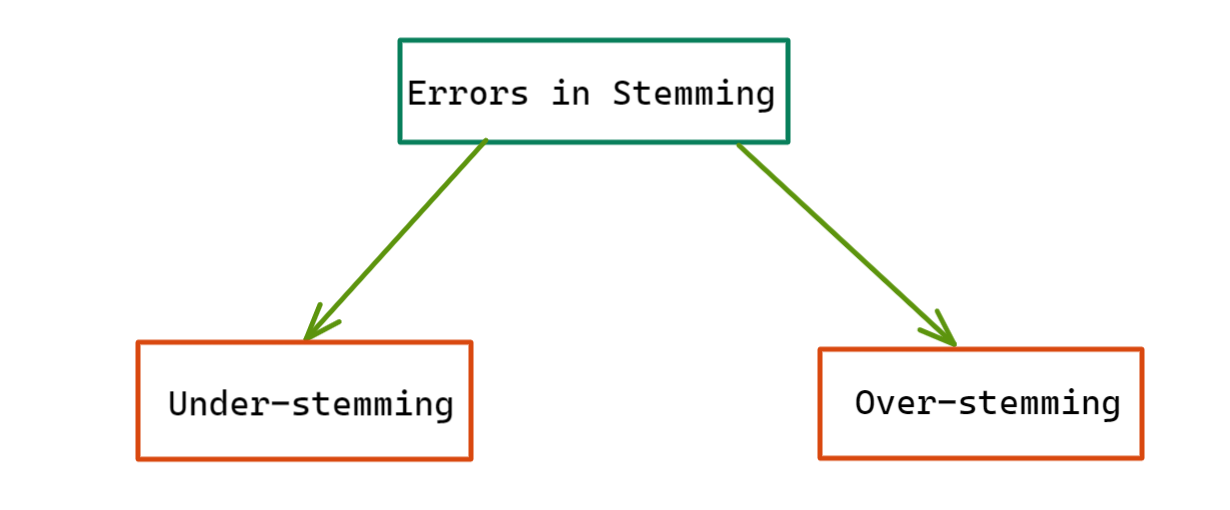
Şekil 2: Köklendirmede Hata Türleri
Kaynak: Yazar)
Bunlara daha detaylı bir göz atalım.
a) Aşırı köklenme: Adından da anlaşılacağı gibi, bu durumda kelime aşırı kökleniyor, yani bir kelimenin çok fazlası kesiliyor ve bu da anlamsız köklere yol açıyor. Sonuç olarak, kelimenin anlamı sıklıkla tamamen kaybolur veya karışır. Alternatif olarak bu, kelimelerin aynı köke çözümlenmesiyle sonuçlanabilir ki bu gerçekleşmemelidir.
Örneğin: Diyelim ki evrensel, üniversite ve üniversiteler olmak üzere dört kelimemiz var. Eğer bir kök çıkarma algoritması bu kelimeleri "evren" köküne indirirse bu, algoritmanın aşırı kökten oluştuğu anlamına gelir.
Daha iyi yaklaşım ilk iki kelimeyi “univers” ve son iki kelimeyi “universi” olarak çözmek olacaktır. Ancak bu kuralların uygulanması daha fazla soruna neden olabilir.
b) Eksik köklenme: Adından da anlaşılacağı gibi, eksik köklenme, "yetersiz köklenme" anlamına gelir. Birbirinin formları olan birkaç kelimemiz olduğunda olur.
Örneğin: Veri ve datum kelimelerini “dat” ve “datu” olarak türeten bir kök çıkarma algoritması kullandığımızda. Belki bunlar “dat”a çözümlenebilir. Ama sonra şu soru ortaya çıkıyor: "Tarih" kelimesi için ne yapardık? Yoksa sadece çok spesifik bir örnek için çok spesifik bir kuralı mı uyguluyoruz?
Stemming söz konusu olduğunda bu sorular yakıcı konular haline gelir. Yeni kuralların ve buluşsal yöntemin uygulanması kolaylıkla kontrolden çıkabilir. Kökü fazla/eksik olan bir veya iki sorunun çözümü, yeni sorunların ortaya çıkmasına neden olabilir. İyi bir köklendirme algoritması oluşturmak çaba gerektirir.
Soru 3: NLTK'da Stemmer Çeşitleri Nelerdir?
Cevap: Bu kılavuzda en çok kullanılan kök ayırıcıları tartışacağız: i) Porter Stemmer, ii) Snowball Stemmer, iii) Lancaster Stemmer ve iv) Regexp Stemmer.
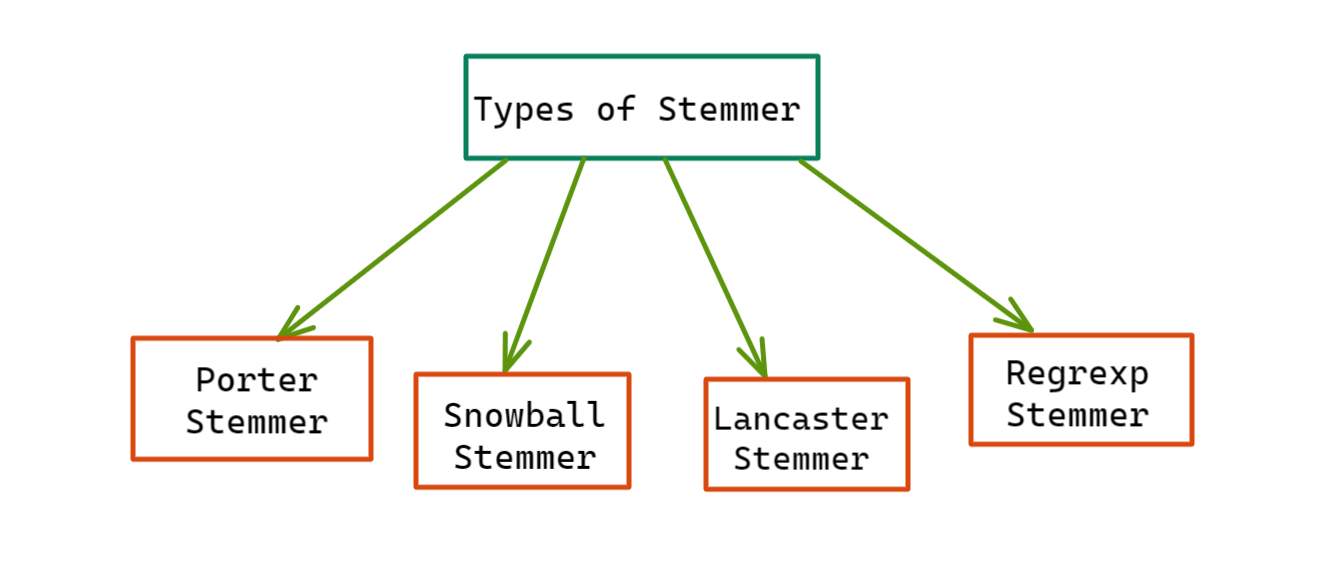
Şekil 3: NLTK'deki Stemmer Türleri
Kaynak: Yazar
Şimdi bunların her birine ayrıntılı olarak bakalım.
1. Porter Stemmer: Porter kökü, her biri kök üretmek için kendi eşleme kurallarına sahip olan beş adımlı kelime azaltma (bir sonek köklendirme yaklaşımı) kullanan Porter Köklendirme Algoritmasını temel alır. Bu kök çıkarma algoritması, 1980'lerden beri oldukça eskidir. Kullanım kolaylığı ve hızlılığı ile oldukça ünlüdür.
Amacı, ortak sözcük sonlarını ortadan kaldırarak bunların ortak bir biçime dönüştürülebilmesini sağlamaktır. Genel olarak konuşursak, yeni başlayanlar için iyi bir kök sökücüdür, ancak herhangi bir üretim veya karmaşık uygulama için kullanılması pek önerilmez. Bunun yerine, araştırmada tekrarlanabilirliğin sağlanmasına yardımcı olan güzel ve basit bir kök çıkarma algoritması olarak işlev görür. Diğer kök çıkarma algoritmalarıyla karşılaştırıldığında oldukça yumuşaktır.
NLTK, Porter Stemming algoritmasını uygulayan bir PorterStemmer() modülüne sahiptir. Bunu bir örnek yardımıyla inceleyelim:
Örnek E-posta:
#Porter Stemmer modülünü nltk.stem'den içe aktarma PorterStemmer'i içe aktarma
#porter_stemmer = PorterStemmer() örneğini oluşturma #Örnek_kelimeler kelimeler = ["yemek", "yemek", "yemek", "yemek yiyenler", "yenmek", "yazmak", "yazmak", "yazar", "programlama", "programcı" ", "programlar", "programlandı", "tebrikler", "geçmiş", "tarihsel"]
w için kelimelerle: print(w + " -----> " + porter_stemmer.stem(w))
>> Çıktı:
yemek —–> yemek
yiyor —–> ye
yemek mekanı —–> yemek mekanı
restoranlar —–> restoranlar
yemiş —–> yemiş
yazma —–> yazma
yazıyor —–> yaz
yazar —–> yazar
programlama —–> program
programcı —–> program
programlar —–> program
programlanmış —–> program
tebrikler —–> tebrikler
tarih —–> tarih
tarihsel —–> tarih
2. Kartopu Stemmer: Snowball Stemmer'a Porter2 Stemmer veya "İngilizce Stemmer" da denir. Birçok dili (Arapça, Danca, Fince, Fransızca, Almanca, İspanyolca, İsveççe vb. gibi) destekleyen temel Porter Stemmer'in geliştirilmiş ve daha iyi bir sürümüdür. Üstelik Porter Stemmer'in orijinal versiyonundan biraz daha hızlı, daha doğru ve daha mantıklı. Ancak ayrıca orijinal Porter Stemmer'den çok daha agresiftir.
NLTK, Snowball köklendirme yaklaşımını uygulayan bir SnowballStemmer() modülüne sahiptir. Bir örnek yardımıyla buna bir göz atalım.
Örnek:
#SnowballStemmer modülünü nltk.stem'den içe aktarma SnowballStemmer'i içe aktar
#Snowball_stemmer örneği oluşturuluyor = SnowballStemmer("ingilizce", görmezden_stopwords = Yanlış)
#Örnek_kelimeler kelimeler = ["yemek", "yemek", "yemek mekanı", "yemek mekanları", "yenmek", "yazmak", "yazar", "yazar", "programlama", "programcı", "programlar", " programlandı", "tebrikler", "tarih", "tarihsel"]
w için kelimelerle: print(w + " -----> " + snowball_stemmer.stem(w))
>> Çıktı:
yemek —–> yemek
yiyor —–> ye
yemek mekanı —–> yemek mekanı
restoranlar —–> restoranlar
yemiş —–> yemiş
yazma —–> yazma
yazıyor —–> yaz
yazar —–> yazar
programlama —–> program
programcı —–> program
programlar —–> program
programlanmış —–> program
tebrikler —–> tebrikler
tarih —–> tarih
tarihsel —–> tarih
3. Lancaster Stemmer: Diğer kök belirleme algoritmalarıyla karşılaştırıldığında Lancaster Stemmer, birçok kelime için aşırı kökleme uyguladığı için agresif bir yaklaşım benimsiyor. Bunda bir kelime mümkün olan en kısa köke kadar kesilir, bu da dilsel olmayan ve anlamsız kökler de olabilir. Ancak bu algoritmaya kendi özel kurallarımızı kolaylıkla ekleyebiliriz. Ne olursa olsun, bunu kullanırken bu seçeneği seçmeden önce amaçlanan şeyi yaptığından emin olmamız gerekiyor.
NLTK ayrıca Lancaster köklendirme yaklaşımını uygulayan LancasterStemmer() modülüne de sahiptir. Bir örnek yardımıyla buna bir göz atalım.
Örnek:
#LancasterStemmer modülünü nltk.stem'den içe aktarma LancasterStemmer'i içe aktar
#Lancaster_stemmer başlatılıyor = LancasterStemmer()
#Örnek_kelimeler kelimeler = ["yemek", "yemek", "yemek mekanı", "yemek mekanları", "yenmek", "yazmak", "yazar", "yazar", "programlama", "programcı", "programlar", " programlandı", "tebrikler", "tarih", "tarihsel"]
w için kelimelerle: print(w + " -----> " + lancaster_stemmer.stem(w))
> Çıktı:
yemek —–> yemek
yiyor —–> ye
restoran —–> restoran
lokantalar —–> lokanta
yemiş —–> ye
yazma —–> yazmak
yazıyor —–> yaz
yazar —–> yaz
programlama —–> program
programcı —–> program
programlar —–> program
programlanmış —–> program
tebrikler —–> tebrikler
geçmiş —–> geçmiş
tarihsel —–> geçmiş
Çıktılardan da görebileceğimiz gibi, Lancaster agresif bir lemmatizasyon yaklaşımı kullanıyor!
4. Regexp Stemmer: Regex kökü, morfolojik ekleri tanımlamak için normal ifadeler kullanır. Burada belirli düzenli ifadelerle eşleşen alt dizeler atılır.
NLTK, Regrx köklendirme yaklaşımını uygulamak için RegexpStemmer() modülüne sahiptir. Aşağıdaki örnek yardımıyla bunu anlayalım:
#RegexpStemmer modülünü nltk.stem'den içe aktarma RegexpStemmer'i içe aktarma
#Örnekleştirme regexp_stemmer = RegexpStemmer("ing$|s$|es$|able$|e$|cal$|ing$|$ing", min=8)
#Örnek_kelimeler kelimeler = ["yemek", "yemek", "yemek mekanı", "yemek mekanları", "yenmek", "yazmak", "yazar", "yazar", "programlama", "programcı", "programlar", " programlandı", "tebrikler", "tarih", "tarihsel"]
w için kelimelerle: print(w + " -----> " + regexp_stemmer.stem(w))
>> Çıktı:
yemek —–> yemek
yiyor —–> yiyor
restoran —–> restoran
restoranlar —–> restoranlar
yemiş —–> yemiş
yazma —–> yazmak
yazıyor —–> yaz
yazar —–> yazar
programlama —–> program
programcı —–> programcı
programlar —–> program
programlanmış —–> programlanmış
tebrikler —–> tebrikler
geçmiş —–> geçmiş
tarihsel —–> tarih
Soru 4: Lemmatizasyon Nedir?
Cevap: Lemmatizasyon bir süreçtir Kelime dağarcığı kullanımı ve kelimelerin morfolojik analizi ile bir kelimeyi kelime köküne (lemma) indirgemek, yazımları doğru olan ve genellikle daha anlamlı olan. Bir kelimeyi kendi lemmasına indirgemek için, lemmatizasyon algoritmasının konuşmanın bir kısmını (POS) bilmesi gerekir. Bu da konuşma etiketleyicinin bir parçası gibi daha fazla hesaplamalı dilbilim gücü gerektirir.
Lemmatizasyonun bir kelimeyi kendi lemmasına çözümleyebilmesi için konuşmanın kendi bölümünü bilmesi gerekir. Bu ekstra hesaplama gerektirir ve genellikle daha anlamlıdır. İngilizce ile çalışırken lemmatizasyonu hızlı bir şekilde kullanabiliriz. Ancak lemmatizer'ın tüm kelimeleri istenilen lemmalara indirgemesi için onu konuşma etiketleri kısmıyla beslemeniz gerekir. Üstelik, WordNet veritabanını temel aldığından (biraz eşanlamlılar ağı veya eş anlamlılar sözlüğü gibi çalışır), orada güçlü bir bağlantı yoksa zaten doğru lemmayı elde edemeyiz.

Şekil 4: Lemmatizasyon Örnekleri
Kaynak: blog.bitext.com
Uygulama: Bilgi Erişimi, Sohbet Robotları, Soru Yanıtlama, Duygu Analizi, Belge Kümeleme vb.
Soru 5: Lemmatizasyon kelimesi nedir?
Cevap: NLTK, wordnet derleminin etrafını saran WordNetLemmatizer sınıfına sahiptir. Bu sınıf, bir lemma bulmak için WordNet Corpuclass'taki morphy() işlevini kullanır. Şimdi bu sınıfı daha iyi anlamak için bir örneğe bakalım.
Örnek 1: Post etiketi açıkça tanımlanmadığında.
import nltk nltk.download('wordnet') nltk.download('omw-1.4')
#WordNetLemmatizer modülünü nltk.stem'den içe aktarma WordNetLemmatizer'ı içe aktarın
#lemmatizer'ın başlatılması = WordNetLemmatizer()
#Örnek_kelimeler kelimeler = ["yemek", "yemek", "yemek mekanı", "yemek mekanları", "yenmek", "yazmak", "yazar", "yazar", "programlama", "programcı", "programlar", " programlandı", "tebrikler", "tarih", "tarihsel"]
Çıktı:
yemek —–> yemek
yiyor —–> yiyor
restoran —–> restoran
lokantalar —–> lokanta
yemiş —–> yemiş
yazma —–> yazma
yazıyor —–> yazıyor
yazar —–> yazar
programlama —–> programlama
programcı —–> programcı
programlar —–> program
programlanmış —–> programlanmış
tebrikler —–> tebrikler
geçmiş —–> geçmiş
tarihsel —–> tarihsel
Örnek 2: Post etiketi açıkça tanımlandığında!
içe aktarma nltk
nltk.download('wordnet')
nltk.download('omw-1.4')
#WordNetLemmatizer modülünü nltk.stem'den içe aktarma WordNetLemmatizer'ı içe aktarın
#lemmatizer'ın başlatılması = WordNetLemmatizer()
#Örnek_kelimeler kelimeler = ["yemek", "yemek", "yemek mekanı", "yemek mekanları", "yenmek", "yazmak", "yazar", "yazar", "programlama", "programcı", "programlar", " programlandı", "tebrikler", "tarih", "tarihsel"]
Aşağıdaki kod parçasında, pos etiketini açıkça "v" (fiil, yalnızca gösterim amacıyla) olarak tanımlayacağımıza dikkat edin.
> Çıktı:
yemek —–> yemek
yiyor —–> ye
restoran —–> restoran
restoranlar —–> restoranlar
yemiş —–> ye
yazma —–> yazma
yazıyor —–> yaz
yazar —–> yazar
programlama —–> program
programcı —–> programcı
programlar —–> program
programlanmış —–> program
tebrikler —–> tebrikler
geçmiş —–> geçmiş
tarihsel —–> tarihsel
Yukarıdaki çıktıdan, POS etiketini bir fiil olarak tanımladığımız için bu lemmatizer'ın fiiller için iyi çalıştığını fark edebiliriz; bu da, eğer aynı anda belirli gruplara lemmatizasyon uygularsak, bunun çok etkili bir yöntem olabileceğini düşündürmektedir. kök salıyor!
Köklenme ve Lemmatizasyon arasında ayrım yapın.
Cevap:
| Ruh hali | Lemmatizasyon | |
| Kökten çıkarma, bir sözcüğü sözcüğüne indirgeme işlemidir kökBu genellikle yapım eklerinin kaldırılmasını içerir ve çoğu zaman yanlış anlamlara ve yazımlara yol açar. | Lemmatizasyon bir sözcüğü sözcüğüne indirgeme işlemidir kök, yazılışı doğru olan ve daha anlamlı olan. | |
| Kökten ayırma genellikle türevsel olarak ilişkili kelimeleri daraltır. Ve bir kök gerçek bir kelime olabilir veya olmayabilir. | Lemmatizasyon genellikle yalnızca bir lemmanın farklı çekim biçimlerini çökertir. Ve bir lemma gerçek bir dil kelimesidir. | |
| Kural Temelli Yaklaşım: Stemmer'lar dile özgü kurallar kullanır ve Lemmatizer'dan daha az bilgiye ihtiyaç duyarlar. Ayrıca bazı alan adlarının özel/alanlara özgü kurallara da ihtiyacı olabilir. |
|
|
| Dil uygulaması geliştirirken dilin önemli olduğu durumlarda kökten alma genellikle tercih edilmez. | Dile özgü bir uygulama geliştirirken, Lemmatization, kök formları eşleştirmek için bir derlemi taradığı için tercih edilir. Ancak kökten ayırmayla karşılaştırıldığında, yeni bir dil için bir lemmatizer oluşturmak zordur çünkü dilin yapısı hakkında çok daha fazla bilgiye ihtiyaç duyar. | |
| Hız söz konusu olduğunda, bağlamı anlamadan kelimeleri kestiği için Kök Alma tercih edilir. | Hızın önemli olduğu durumlarda Lemmatizasyon, tüm derlemi tarayacağı için genellikle tercih edilmez ve bu da zaman alır. | |
| Öyle daha az doğru. | Öyle daha kesin Stemming'den daha. | |
| Öyle hesaplama açısından daha az pahalı. Bu nedenle bütçe önemliyse büyük veri kümeleri için seçilebilir. | Öyle hesaplama açısından daha pahalı çünkü bir arama tablosu içerir ve aynı zamanda tüm külliyatı tarar. | |
| Örnek: "Önemli" belirteci ile karşılaşıldığında yalnızca "araba" çıktısı alınabilir, bu yanlıştır. | Örnek: "Önemli" kelimesiyle karşılaştırıldığında, lemmatizasyon yalnızca "ilgili" çıktısını verebilir ki bu doğrudur. |
![Stemming [Porter Stemmer] Vs. Lemmatizasyon [WordNet Lemmatizer]](https://zephyrnet.com/wp-content/uploads/2022/11/a-comprehensive-guide-for-interview-questions-on-classical-nlp-9.png)
Şekil 5: Stemming [Porter Stemmer] Vs. Lemmatizasyon [WordNet Lemmatizer]
Kaynak: baeldung.com
Soru 7: Token ve Tokenizasyon Nedir?
Cevap: dizgeciklere bir ifadeyi, cümleyi, paragrafı veya bir veya daha fazla metin belgesini daha küçük birimlere ayırmaktır.
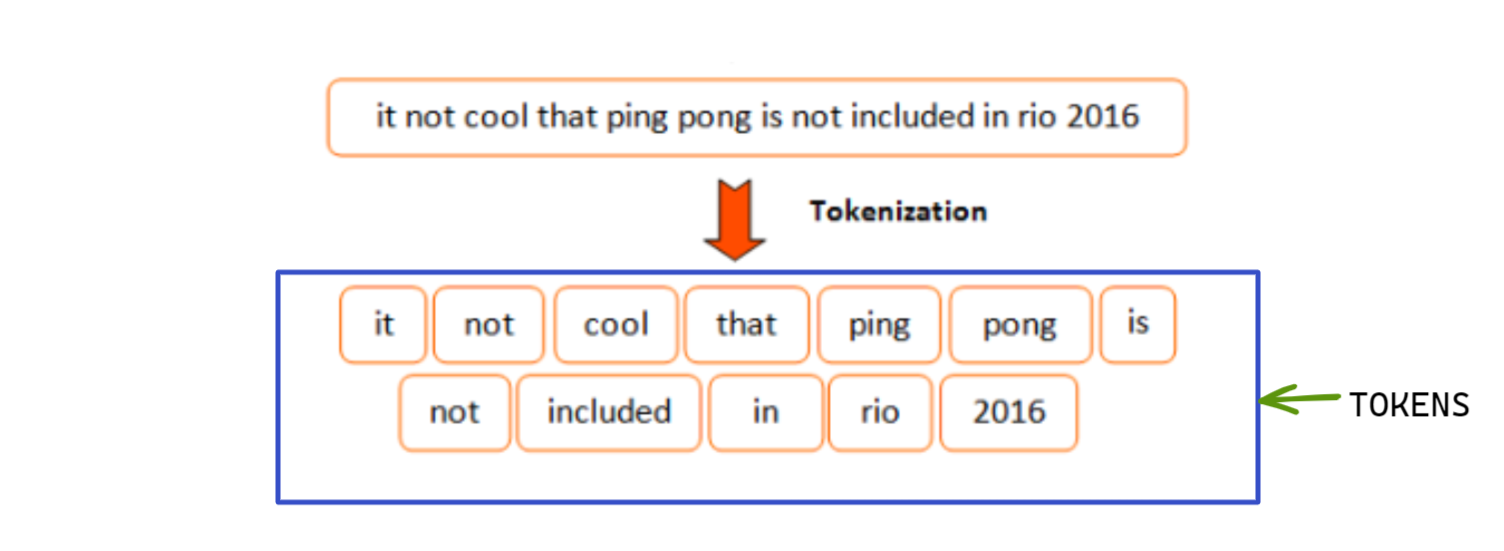
Şekil 6: Tokenları ve tokenizasyonu gösteren diyagram; Basitlik açısından burada kelime tokenizasyonu gösterilmiştir
Kaynak: Analytics Vidhya
Küçük birimlerin her birine jeton adı verilir. Bu belirteçler herhangi bir şey olabilir; örneğin bir karakter, kelime, alt kelime, cümle vb. Farklı algoritmalar, farklı türde belirteçler kullanır. Aşağıdaki örnekler size farklı tokenizer türleri hakkında genel bir fikir verecektir.
Aşağıdaki cümleye bir göz atın:
Cümle: "Tokenizasyonu öğreniyoruz."
1) Kelime Tabanlı Tokenizasyon: Bunda cümle bir sınırlayıcıya göre kelimelere bölünür. En yaygın sınırlayıcı boşluktur.
Kelime Tabanlı Tokenizer Çıktısı: [“Biz”, “biz”, “öğreniyoruz”, “hakkında”, “Tokenizasyon.”]
2) Alt Kelime Tabanlı Belirleyici: Bunda cümle alt kelimelere bölünmüştür.
Alt Kelime Tabanlı Tokenizer Çıktısı: [“Biz”, “biz”, “öğreniyoruz”, “about”, “Token”, “ization.”]
3) Karakter Tabanlı Tokenizasyon: Bunda cümle karakterlere bölünmüştür.
Karakter Tabanlı Tokenizer Çıkışı: ["W", "e", "a", "r", "e", "l", "e", "a", "r", "n", "i" , "n", "g", "a", "b", "o", "u", "t", "T", "o", "k", "e", "n", " i", "z", "a", "t", "i", "o", "n", "."]
4) Cümle Tabanlı Tokenizasyon: Bunda metin tek tek cümlelere bölünmüştür.
example_text = “Hindistan Güney Asya'da bir ülkedir. Bölgeye göre yedinci en büyük ülke.”
Cümle Tabanlı Tokenizer Çıktısı: ["Hindistan, Güney Asya'da bir ülkedir.", "Bölgeye göre yedinci en büyük ülkedir."]
Tüm NLP modelleri ham metni jeton düzeyinde işlediğinden jetonlar NLP'nin temelidir. Bu belirteçler, bir derlem/veri kümesindeki benzersiz belirteçlerin bir koleksiyonu olan kelime dağarcığını oluşturur. Daha sonra bu kelime dağarcığı sayılara (ID'ler) dönüştürülür ve bu da modellemeyi kolaylaştırır.
Soru 8: White Space Tokenizer nedir? Avantajları ve dezavantajları nelerdir?
Cevap: Boşluk belirteci, boşluk sınırlayıcıyla karşılaşıldığında metni/cümleyi/paragrafı böler.
split() işlevindeki varsayılan ayırıcı boşluk olduğundan, bir dizenin .split() yöntemi kullanılarak uygulanabilir.
example_sentence = "Güneş'i kaybolmadan yakalayın."' print(example_sentence.split())
>> Çıktı: ['Yakala', 'Güneş', 'önce', “o”, 'gitti.']
Whitespace Tokenizer'ın Dezavantajları: Yukarıdaki örnekte görebileceğimiz gibi, boşluk belirteci noktalama işaretli belirteçler üretir. Üstelik toplu olarak değerlendirilmesi gereken ifadeleri bile bölüyor. örneğin, bileşik coğrafi konumlar (“Andhra Pradesh”, “Uttar Pradesh”), dile özgü ifadeler (), eşdizimler (fast food), vb. [Referans için aşağıdaki örneklere bakın]
geo_location = "Andra Pradeş" print(geo_location.split())
>> Çıktı: ['Andra', 'Pradeş']
ifade = "sizin için" print(expression.split())
>> Çıktı: ['por', 'favor']
sıralama = "fast food" print(collocation.split())
>> Çıktı: ['hızlı', 'yemek']
Whitespace Tokenizer'ın Avantajları: En basit ve en hızlı tokenizasyon yaklaşımıdır. Kısa çizgileri (örneğin, oturum açma) ve kesme işaretlerini (örneğin, yapamam) korur. Aşağıdaki örneklerin yardımıyla bunu pekiştirelim:
example2 = "oturum aç" print(example2.split())
>> Çıktı: ['oturum açma']
example3 = "yazdırılamıyor"(example3.split())
>> Çıktı: [“yapamam”]
Bu nedenle, boşluk belirteci kısa çizgileri ve kesme işaretlerini korur.
Soru 9: WhitespaceTokenizer()'ın özelliği nedir? Bunun için bir örnek üretebilir misiniz?
Cevap: Nltk tarafından sunulan WhitespaceTokenizer() işlevini kullanarak, boşluklar, yeni satırlar ve sekmeler olmadan bir kelime veya cümle dizisinden belirteçleri çıkarabiliriz.
Örnek:
# WhitespaceTokenizer()'ı nltk'den nltk.tokenize'den içe aktarıyoruz import WhitespaceTokenizer # Sınıf için bir değişken oluşturma WhitespaceTokenizer tk = WhitespaceTokenizer() # Örnek example_case = "Bu pizza güzel." # Tokenleştirme çıktısı = tk.tokenize(example_case) #Output print(output)
>> Çıktı: ['Bu', 'pizza', 'bu', 'iyi.']
Soru 10: NLTK'nin word_tokenize()'si nedir? Bunu tokenizasyon için nasıl kullanırsınız?
Cevap: Doğal Dil Araç Kiti, metni kelimelere bölen word_tokenize() adı verilen bir belirteç sağlar.
Düzenli ifadeyi a) standart İngilizce kısaltmaları bölmek, b) noktalama işaretlerinin çoğunu ayrı belirteçler olarak ele almak, c) tırnak işaretlerini ve tek virgülleri arkalarında boşluk geldiğinde bölmek ve d) sonda gelen ayrı noktalar (noktalama işaretleri) için kullanır. bir satırın (EoL)
Daha iyi anlamak için aşağıdaki örneğe bakalım:
import nltk nltk.download("punkt") word_data = "Güneş olmadan yapamam." nltk_word_tokens = nltk.word_tokenize(word_data) print(nltk_word_tokens)
>> Çıktı: ['Ben', 'ca', “yapmıyorum”, 'yapmıyorum', 'olmadan', 'the', 'Güneş', '.']
Soru 11: NLTK'nin sent_tokenize()'si nedir? Bunu tokenizasyon için nasıl kullanırsınız?
Cevap: Doğal Dil Araç Kiti, metni (paragraf/belge vb.) cümlelere bölen sent_tokenize() adında bir belirteç içerir. Aşağıda aynısının bir örneği verilmiştir:
import nltk nltk.download("punkt") example_sentence = "Güneşli sabahlar kışın favorimdir. Altın rengi Güneş beni mutlu eder." sent_nltk_tokens = nltk.sent_tokenize(example_sentence) print(sent_nltk_tokens)
>> Çıktı: ['Güneşli sabahlar kışın favorimdir.', 'Altın Güneş beni mutlu ediyor.']
Sonuç
Bu makale, Klasik NLP ile ilgili veri bilimi röportajlarında sorulabilecek en zorunlu, röportajı kazandıran sorulardan bazılarını kapsamaktadır. Bu röportaj sorularını kullanarak, NLP'nin farklı kavramlarına ilişkin anlayışınızı geliştirebilir ve etkili yanıtlar formüle edip bunları görüşmeciye sunabilirsiniz.
Özetlemek gerekirse, Klasik NLP mülakat sorularından bazı önemli çıkarımlar şunlardır:
1. Kökten ayırma, bir kelimeyi kelime köküne indirgeme işlemidir ve genellikle yapım eklerinin kaldırılmasını da içerir.
2. Köklendirmenin buluşsal yöntemlere dayandığı dikkate alındığında; dolayısıyla mükemmel olmaktan uzaktır. Köklendirmede en yaygın iki hata a) Aşırı Köklendirme ve b) Eksik Köklendirme'dir.
3. En sık kullanılan kök ayırıcılar i) Porter Stemmer, ii) Snowball Stemmer, iii) Lancaster Stemmer ve iv) Regexp Stemmer'dir. Lancaster en agresif saplayıcıdır, yani bunda aşırı saplama oldukça belirgindir.
4. Köklendirme ve Lemmatizasyon, Arama Motorları, Dizin Oluşturma, Etiketleme sistemleri, Duyarlılık Analizi, Spam Sınıflandırması, Belge Kümeleme vb. gibi Bilgi Erişim Sistemlerinde kullanılabilir.
5. Tokenizasyon, bir cümleyi, cümleyi, paragrafı veya bir veya daha fazla metin belgesini daha küçük birimlere ayırmaktır. Bu birimlerin her birine jeton adı verilir. Bu belirteçler herhangi bir şey olabilir; örneğin bir karakter, kelime, alt kelime, cümle vb.
6. Boşluk belirteci, boşluk sınırlayıcıyla karşılaşıldığında metni/cümleyi/paragrafı böler.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- Akıllı para. Avrupa'nın En İyi Bitcoin ve Kripto Borsası.Buraya Tıkla
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2022/11/a-comprehensive-guide-for-interview-questions-on-classical-nlp/

