Giriş
Verileri denetleme dünyası, üstesinden gelinmesi gereken pek çok zorluğun bulunduğu karmaşık olabilir. En büyük zorluklardan biri veri kümeleriyle uğraşırken kategorik nitelikleri ele almaktır. Bu makalede, veri denetimi, anormallik tespiti ve kategorik niteliklerin kodlanmasının modeller üzerindeki etkisi dünyasını derinlemesine inceleyeceğiz.
Denetim verileri için anormallik tespitiyle ilgili ana zorluklardan biri kategorik niteliklerin işlenmesidir. Modeller metin girişini yorumlayamadığı için kategorik niteliklerin kodlanması zorunludur. Genellikle bu, Etiket kodlaması veya One Hot kodlaması kullanılarak yapılır. Bununla birlikte, büyük bir veri kümesinde Tek-sıcak kodlama, boyutluluğun laneti nedeniyle zayıf model performansına yol açabilir.
Öğrenme hedefleri
-
Verileri denetleme kavramını ve zorlukları anlamak
- Derin denetimsiz anomali tespitinin farklı yöntemlerini değerlendirmek.
- Verilerin denetiminde anormallik tespiti için kullanılan modeller üzerinde kategorik özniteliklerin kodlanmasının etkisini anlamak.
Bu makale, Veri Bilimi Blogathon.
İçindekiler
- Auata nedir?
- Anormallik Tespiti Nedir?
- Verileri Denetlerken Karşılaşılan Büyük Zorluklar
- Anormallik Tespiti için Veri Kümelerinin Denetlenmesi
- Kategorik Niteliklerin Kodlanması
- Kategorik Kodlamalar
- Denetimsiz Anormallik Tespit Modelleri
- Kategorik Niteliklerin Kodlanması Modelleri Nasıl Etkiler?
8.1 Araba Sigortası veri kümesinin t-SNE gösterimi
8.2 Taşıt Sigortası veri kümesinin t-SNE gösterimi
8.3 Araç Talepleri veri kümesinin t-SNE gösterimi - Sonuç
Veri Denetimi nerede?
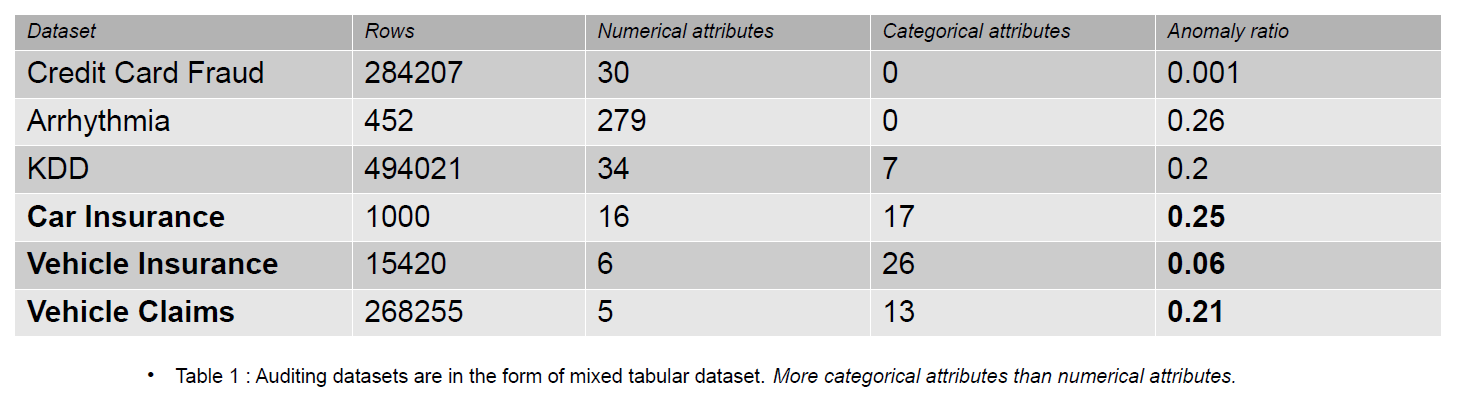
Denetim verileri, bilgi sistemleri için Günlükleri, Sigorta Taleplerini ve İzinsiz Giriş Verilerini içerebilir; Bu yazıda sunulan örnekler araçların sigorta talepleridir. Sigorta talepleri, KDD gibi anormallik tespit veri kümelerinden daha fazla sayıda kategorik özellik ile ayırt edilebilir.
Kategorik özellikler, verilerimizdeki tamsayı veya karakter türünden olabilen disketlerdir. Sayısal özellikler, verilerimizdeki her zaman gerçek değerli olan sürekli niteliklerdir. Sayısal özelliklere sahip veri kümeleri, Kredi Kartı dolandırıcılığı verileri gibi anormallik tespit topluluğunda popülerdir. Kamuya açık veri kümelerinin çoğu, sigorta talep verilerinden daha az kategorik özellik içermektedir. Sigorta hasar veri setlerinde kategorik özellikler sayısal özelliklerden daha fazladır.
Bir sigorta talebi Model, Marka, Gelir, Maliyet, Sayı, Renk vb. özellikleri içerir. Denetim verilerindeki kategorik özelliklerin sayısı, Kredi Kartı ve KDD veri kümelerine göre daha fazladır. Bu veri kümeleri, denetimsiz anormallik tespit yöntemlerinde referans niteliğindedir. Aşağıdaki tabloda görüldüğü gibi Sigorta hasar veri kümeleri, sahtekarlık verilerinin davranışını anlamak açısından önemli olan daha kategorik özelliklere sahiptir.
Kategorik kodlamaların etkisini değerlendirmek için kullanılan denetim veri kümeleri Araba Sigortası, Araç Sigortası ve Araç Hasarlarıdır.
Anormallik Tespiti Nedir?
Anomali, bir veri kümesindeki normal verilerden belirli bir mesafe (Eşik) kadar uzakta bulunan bir gözlemdir. Verilerin denetlenmesi açısından sahte veri terimini tercih ediyoruz. Anormallik tespiti, makine öğrenimi veya derin öğrenme modelini kullanarak normal ve sahte veriler arasında ayrım yapar. Farklı yöntemler yoğunluk tahmini, yeniden yapılandırma hatası ve sınıflandırma yöntemleri gibi anormallik tespiti için kullanılabilir.
- Yoğunluk Tahmini – Bu yöntemler normal veri dağılımını tahmin eder ve öğrenilen dağılımdan örneklenmemişse anormal verileri sınıflandırır.
- Yeniden Yapılanma Hatası – Yeniden yapılandırma hatasına dayalı yöntemler, normal verilerin anormal verilere göre daha küçük kayıplarla yeniden oluşturulabilmesi ilkesine dayanmaktadır. Yeniden yapılandırma kaybı ne kadar yüksek olursa, verilerin anormal olma ihtimali de artar.
- Sınıflandırma Yöntemleri - Gibi sınıflandırma yöntemleri Rastgele OrmanAnormallik tespiti için İzolasyon Ormanı, Tek Sınıf – Destek Vektör Makineleri ve Yerel Aykırı Faktörler kullanılabilir. Anormallik tespitinde sınıflandırma, sınıflardan birinin anormallik olarak tanımlanmasını içerir. Yine de çoklu sınıf senaryosunda sınıflar iki gruba (0 ve 1) ayrılmaktadır ve daha az veriye sahip olan sınıf anormal sınıftır.
Yukarıdaki yöntemlerin çıktısı anormallik puanları veya yeniden yapılandırma hatalarıdır. Daha sonra anormal verileri sınıflandıracağımız eşiğe karar vermemiz gerekiyor.
Verileri Denetlerken Karşılaşılan Büyük Zorluklar
- Kategorik Niteliklerin Ele Alınması: Model metin girişini yorumlayamadığı için kategorik niteliklerin kodlanması zorunludur. Yani değerler Label kodlaması veya One Hot kodlaması ile kodlanır. Ancak büyük bir veri kümesinde One sıcak kodlama, öznitelik sayısını artırarak verileri yüksek boyutlu bir alana dönüştürür. Modelin performansı düşük olduğundan boyutun laneti.
- Sınıflandırma için eşiğin seçilmesi: Veriler etiketlenmezse, veri kümesindeki anormalliklerin sayısını bilmediğimizden modelin performansını değerlendirmek zordur. Veri seti hakkında önceden bilgi sahibi olmak eşiğin belirlenmesini kolaylaştırır. Diyelim ki verilerimizde 5 anormal örnekten 10'i var. Yani eşiği yüzde 50 puanda seçebiliriz.
- Herkese Açık Veri Kümeleri: Denetim veri setlerinin çoğu kurumsal şirketlere ait olması ve hassas ve kişisel bilgiler içermesi nedeniyle gizlidir. Gizlilik sorunlarını azaltmanın olası bir yolu, sentetik veri kümelerini (Araç İddiaları) kullanarak eğitim vermektir.
Anormallik Tespiti için Veri Kümelerinin Denetlenmesi
Araçlara ilişkin sigorta talepleri, aracın modeli, markası, fiyatı, yılı, yakıt türü gibi özelliklerine ilişkin bilgileri içerir. Sürücü, doğum tarihi, cinsiyet ve meslek hakkında bilgiler içerir. Ek olarak talep, toplam onarım maliyeti hakkında bilgi içerebilir. Bu makalede kullanılan veri kümelerinin tümü tek bir alandandır ancak öznitelik sayısı ve örnek sayısı bakımından farklılık gösterir.
-
Araç Talepleri veri kümesi büyüktür, 250,000'den fazla satır içerir ve kategorik niteliklerinin kardinalitesi 1171'dir. Büyük boyutundan dolayı bu veri kümesi, boyutsallık lanetinden muzdariptir.
- Taşıt Sigortası veri kümesi, 15,420 satır ve 151 benzersiz kategorik değerden oluşan orta büyüklüktedir. Bu, boyutluluğun lanetinden muzdarip olma olasılığını azaltır.
- Araba Sigortası veri seti, etiketler ve %25 anormal örneklerle küçüktür ve benzer sayıda sayısal ve kategorik özellik içerir. 169 benzersiz kategorisiyle boyutluluğun lanetinden etkilenmez.
Kategorik Niteliklerin Kodlanması
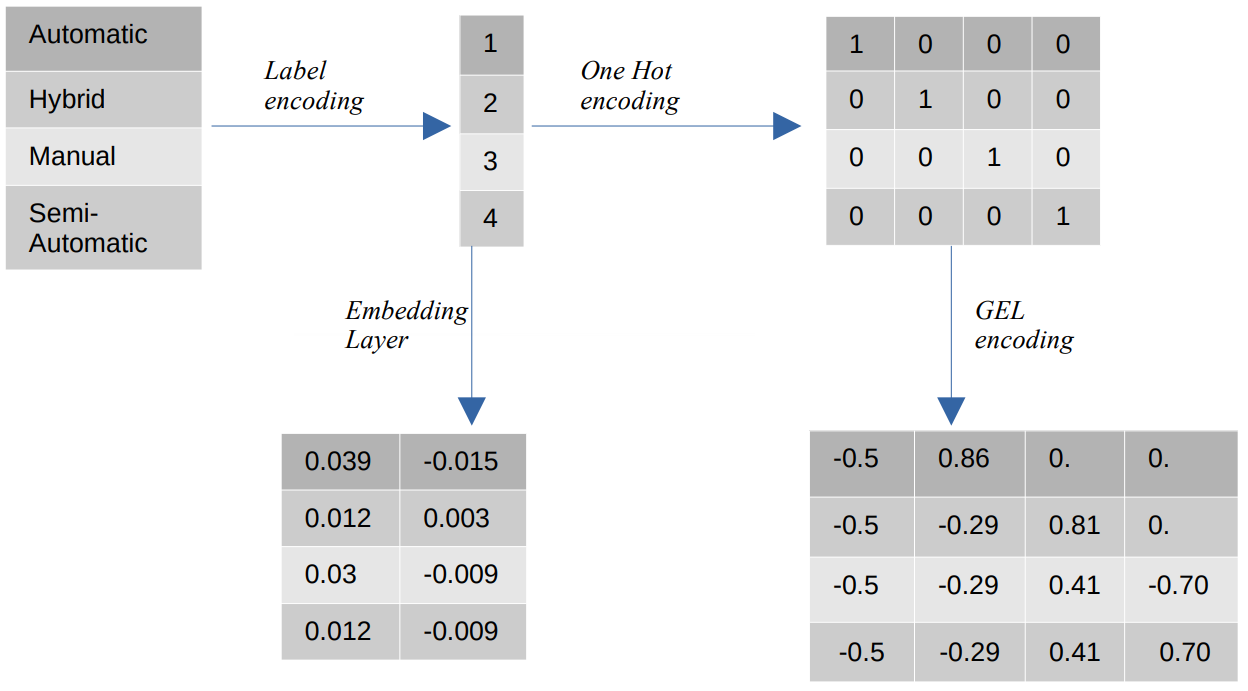
Kategorik değerlerin farklı kodlamaları
- Etiket Kodlama – Etiket kodlamada kategorik değerler, 1 ile kategori sayısı arasındaki sayısal tamsayı değerlerle değiştirilir. Etiket kodlaması, sıra değerleri için kategorileri amaçlanan şekilde temsil eder. Yine de özellikler nominal olduğunda, kategorik değerler belirli bir sıraya uymadığından gösterim yanlıştır.
Örneğin bir özellikte Otomatik, Hibrit, Manuel, Yarı Otomatik gibi kategorilerimiz varsa etiket kodlaması bu değerleri {1: Otomatik, 2: Hibrit, 3: Manuel, 4:Yarı Otomatik} değerlerine dönüştürür. Bu gösterim, kategorik değerler hakkında bilgi vermez ancak {0: Düşük, 1: Orta, 2: Yüksek} gibi bir gösterim, Düşük özellik değişkenine daha düşük bir sayısal değer atandığı için net bir gösterim sağlar. Bu nedenle etiket kodlama sıralı değerler için daha iyi ancak nominal değerler için dezavantajlıdır. - Bir Sıcak Kodlama – Bir Sıcak kodlama, ikili değerlerden oluşan veri kümesindeki her kategorik değeri ayrı bir özelliğe dönüştüren nominal kodlama değerleri sorununu çözmek için kullanılır. Örneğin dört farklı kategorinin {1, 2, 3, 4} olarak kodlanması durumunda One Hot kodlama {Otomatik: [1,0,0,0], Hibrit: [0,1,0,0 gibi yeni özellikler yaratacaktır. ,0,0,1,0], Manuel: [0,0,0,1], Yarı Otomatik: [XNUMX]}.
Veri kümesinin boyutu bu durumda doğrudan veri kümesinde mevcut olan kategorilerin sayısına bağlıdır. Sonuç olarak Tek Sıcak kodlama, bu kodlama yönteminin bir dezavantajı olan boyutluluk lanetine yol açabilir. - GEL Kodlama – GEL kodlama, denetimli ve denetimsiz öğrenme yöntemlerinde kullanılabilecek bir yerleştirme tekniğidir. One Hot kodlama ilkesine dayanır ve One Hot kodlama kullanılarak kodlanan kategorik özelliklerin boyutsallığını azaltmak için kullanılabilir.
- Gömme Katmanı - Kelime yerleştirmeler, benzer kelimelerin benzer kodlamalara sahip olduğu kompakt ve yoğun bir temsil kullanmanın bir yolunu sağlar. Gömme, eğitilebilir parametreler olan kayan nokta değerlerinin yoğun bir vektörüdür. Kelime yerleştirmeler 8 boyutludan (küçük veri kümeleri için) 1024 boyutluya (büyük veri kümeleri için) kadar değişebilir.
Daha yüksek boyutlu bir yerleştirme, kelimeler arasındaki daha ayrıntılı ilişkileri yakalayabilir ancak öğrenilmesi için daha fazla veri gerektirir. Gömme katmanı, matriste bulunan her kelimeyi belirli boyuttaki bir vektöre dönüştüren bir arama tablosudur.
Denetimsiz Anormallik Tespit Modelleri
Gerçek dünyada veriler çoğu durumda etiketlenmez ve verileri etiketlemek pahalı ve zaman alıcıdır. Bu nedenle değerlendirmelerimizde denetimsiz modeller kullanacağız.
- SOM - Kendi Kendini Organize Eden Harita (SOM), geri yayılımlı öğrenmeyi kullanmak yerine nöronların ağırlıklarının rekabetçi bir şekilde güncellendiği rekabetçi bir öğrenme yöntemidir. SOM, her biri giriş vektörüyle aynı boyutta bir ağırlık vektörüne sahip olan bir nöron haritasından oluşur. Ağırlık vektörü, eğitim başlamadan önce rastgele ağırlıklarla başlatılır. Eğitim sırasında her girdi, bir mesafe ölçüsüne (örneğin Öklid mesafesi) dayalı olarak haritadaki nöronlarla karşılaştırılır ve girdi vektörüne minimum mesafeye sahip nöron olan En İyi Eşleştirme Birimi (BMU) ile eşleştirilir.
BMU'nun ağırlıkları, giriş vektörünün ağırlıklarıyla güncellenir ve komşu nöronlar, komşuluk yarıçapına (sigma) göre güncellenir. Nöronlar en iyi eşleşen birim olmak için birbirleriyle yarıştıklarından bu süreç rekabetçi öğrenme olarak bilinir. Sonuçta normal örneklerdeki nöronlar anormal olanlardan daha yakındır. Anomali puanları, girdi örneği ile en iyi eşleşen birimin ağırlıkları arasındaki fark olan nicemleme hatasıyla tanımlanır. Daha yüksek bir niceleme hatası, numunenin bir anormallik olma olasılığının daha yüksek olduğunu gösterir. - DAGMM – Derin Otomatik Kodlama Gauss Karışım Modeli (DAGMM), anormalliklerin düşük olasılıklı bir bölgede bulunduğunu varsayan bir yoğunluk tahmin yöntemidir. Ağ iki bölüme ayrılmıştır: otomatik kodlayıcı kullanarak verileri daha düşük boyutlara yansıtmak için kullanılan bir sıkıştırma ağı ve Gauss karışım modelinin parametrelerini tahmin etmek için kullanılan bir tahmin ağı. DAGMM k sayıda Gauss karışımını tahmin eder; burada k, 1'den N'ye kadar herhangi bir sayı olabilir (veri noktalarının sayısı) ve normal noktaların yüksek yoğunluklu bir bölgede yer aldığı varsayılır; bu, bir bölgeden örneklenme olasılığının olduğu anlamına gelir. Gauss karışımı normal noktalar için anormal numunelere göre daha yüksektir. Anormallik puanları numunenin tahmini enerjisi ile tanımlanır.
- RSRAE – Denetimsiz Anomali Tespiti için Sağlam Yüzey Kurtarma Katmanı, verileri ilk önce bir otomatik kodlayıcı kullanarak daha düşük bir boyuta yansıtan bir yeniden yapılandırma hatası yöntemidir. Gizli temsil daha sonra aykırı değerlere karşı dayanıklı olan doğrusal bir altuzay üzerine dik bir projeksiyona tabi tutulur. Kod çözücü daha sonra çıktıyı doğrusal altuzaydan yeniden oluşturur. Bu yöntemde, daha yüksek bir yeniden yapılandırma hatası, numunenin bir anormallik olma olasılığının daha yüksek olduğunu gösterir.
- SOM-DAGMM- Kendi Kendini Düzenleyen Harita (SOM) - Derin Otomatik Kodlama Gauss Karışım Modeli (DAGMM) aynı zamanda bir yoğunluk tahmin modelidir. DAGMM gibi, normal veri noktalarının olasılık dağılımını da tahmin eder ve öğrenilen dağılımdan örneklenme olasılığı düşük olan bir veri noktasını anormallik olarak sınıflandırır. SOM-DAGMM ve DAGMM arasındaki temel fark, SOM-DAGMM'nin, DAGMM durumunda eksik topolojik bilgiyi tahmin ağına sağlayan giriş örneği için normalleştirilmiş SOM koordinatlarını içermesidir. Amaç aynı zamanda DAGMM'ye benzer, çünkü anormallik puanları numunenin tahmini enerjisine göre tanımlanır ve düşük enerji, numunenin bir anormallik olma olasılığının daha yüksek olduğunu gösterir.
Daha sonra, kategorik nitelikleri ele almanın zorluğunu ele alacağız.
Kategorik Niteliklerin Kodlanması Modelleri Nasıl Etkiler?
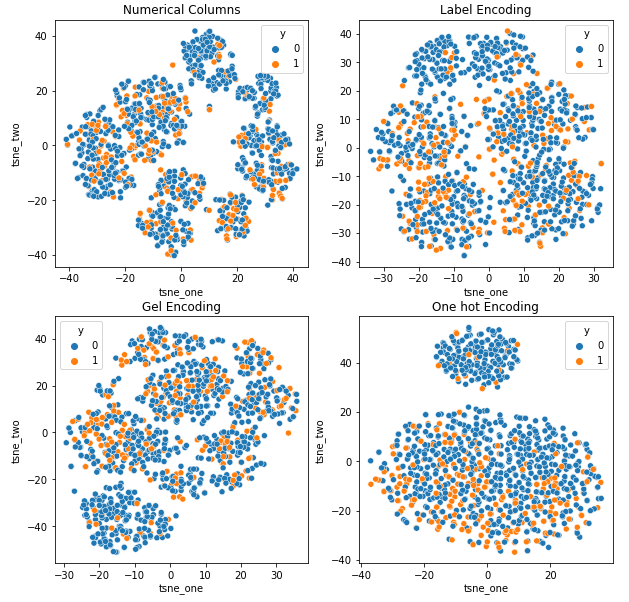
Farklı kodlamaların veri kümeleri üzerindeki etkisini anlamak amacıyla, farklı kodlamalara ilişkin verilerin düşük boyutlu temsillerini görselleştirmek için t-SNE'yi kullanacağız. t-SNE, yüksek boyutlu verileri daha düşük boyutlu bir alana yansıtarak görselleştirmeyi kolaylaştırır. Aynı veri kümesinin farklı kodlamalarının t-SNE görselleştirmeleri ve sayısal sonuçları karşılaştırılarak, ortaya çıkan gösterimlerde ve kodlamanın veri kümesi üzerindeki etkisinin anlaşılmasında fark gözlemlenir.
Araba Sigortası veri kümesinin t-SNE temsili
Taşıt Sigortası veri kümesinin t-SNE gösterimi
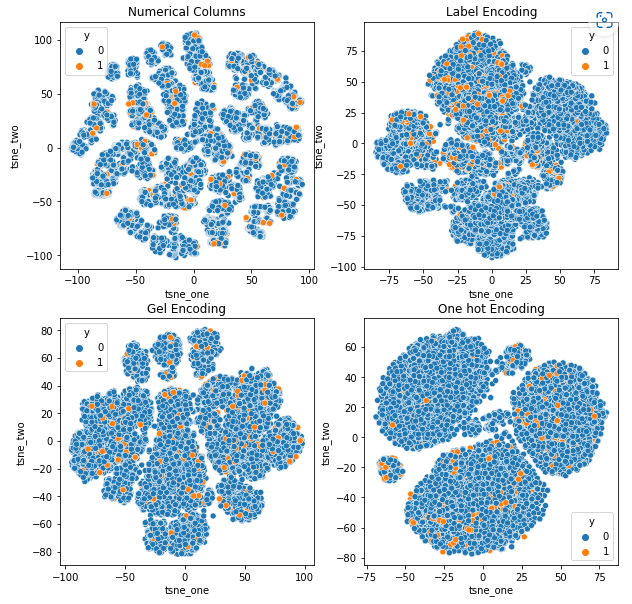
-
Satır sayısı Araba Sigortası veri kümesindekinden daha fazla olduğundan veriler birbirine daha yakındır. One Hot kodlamada artan boyutsallık ile ayırmak zorlaşır.
-
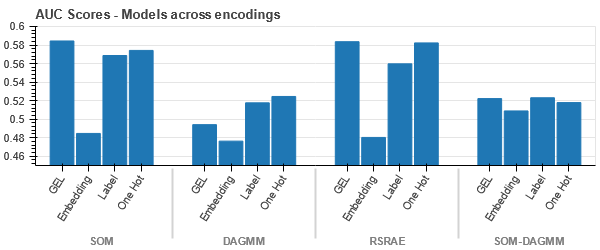
GEL kodlaması, DAGMM dışındaki tüm durumlarda One Hot kodlamasından daha iyidir.
Araç Talepleri veri kümesinin t-SNE gösterimi
-
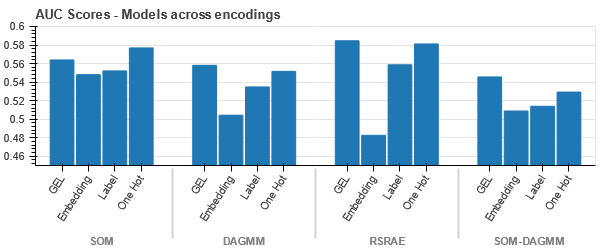
Veriler her durumda sıkı bir şekilde bağlanmıştır, bu da artan boyutluluk nedeniyle ayrılmayı zorlaştırır. Bu, artan boyutsallık nedeniyle modellerin zayıf performansının nedenlerinden biridir.
- SOM, bu veri kümesi için diğer tüm modellerden daha iyi performans göstermektedir. Yine de gömme katmanı çoğu durumda daha uygundur ve bu da bize kodlamaya bir alternatif sağlar kategorik özellikler anormallik tespiti için.
Sonuç
Bu makalede, veri denetimi, anormallik tespiti ve kategorik kodlamalara kısa bir genel bakış sunulmaktadır. Verilerin denetlenmesinde kategorik niteliklerin ele alınmasının zor olduğunu anlamak önemlidir. Niteliklerin kodlanmasının modeller üzerindeki etkisini anlayarak veri kümelerindeki anormallik tespit doğruluğunu geliştirebiliriz. Bu makaleden temel çıkarımlar şunlardır:
- Veri boyutu arttıkça kategorik nitelikler için GEL kodlama ve Gömme katmanları gibi alternatif kodlama yaklaşımlarının kullanılması önemlidir çünkü One Hot kodlama uygun değildir.
- Tek bir model tüm veri kümeleri için çalışmaz. Tablosal veri kümeleri için alan bilgisi son derece önemlidir.
- Kodlama yönteminin seçimi model seçimine bağlıdır.
Modellerin değerlendirilmesine ilişkin kod şu adreste mevcuttur: GitHub.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/01/impact-of-categorical-encodings-on-anomaly-detection-methods/

