Yazara göre resim
Rastgele ormanlar gibi birçok gelişmiş makine öğrenimi modeli veya XGBoost, CatBoost veya LightGBM (ve hatta otomatik kodlayıcılar!) çok önemli bir ortak bileşene güvenin: karar ağacı!
Karar ağaçlarını anlamadan, yukarıda belirtilen gelişmiş torbalama veya gradyan artırma algoritmalarını da anlamak imkansızdır, ki bu herhangi bir veri bilimci için utanç vericidir! Öyleyse, bir karar ağacının iç işleyişini Python'da uygulayarak açıklığa kavuşturalım.
Bu makalede, öğreneceksiniz
- bir karar ağacı verileri neden ve nasıl böler,
- bilgi kazancı ve
- NumPy kullanarak Python'da karar ağaçlarının nasıl uygulanacağı.
Kodu adresinde bulabilirsiniz. benim Github'ım.
Tahmin yapmak için karar ağaçları bölme veri kümesini özyinelemeli bir şekilde daha küçük parçalara ayırın.
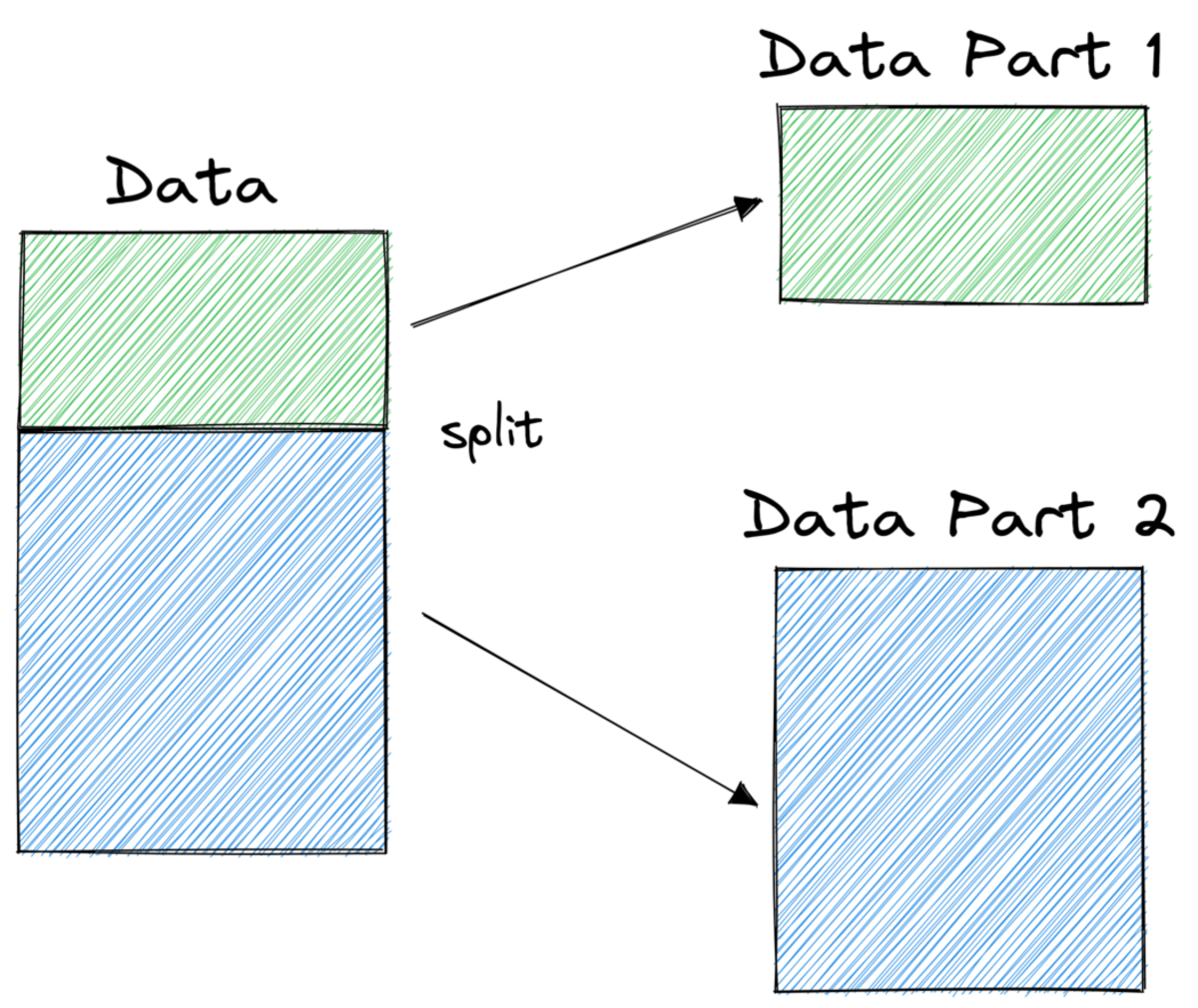
Yazara göre resim
Yukarıdaki resimde, bir bölünme örneğini görebilirsiniz - orijinal veri kümesi iki parçaya ayrılır. Bir sonraki adımda, bu parçaların her ikisi de tekrar bölünür ve bu böyle devam eder. Bu, bir tür durdurma kriteri karşılanana kadar devam eder, örneğin,
- ayırma bir parçanın boş olmasına neden olursa
- belirli bir yineleme derinliğine ulaşıldıysa
- (önceki bölmelerden sonra) veri kümesi yalnızca birkaç öğeden oluşuyorsa, bu da daha fazla bölmeyi gereksiz kılar.
Bu ayrımları nasıl bulacağız? Ve neden umursayalım ki? Hadi bulalım.
Motivasyon
çözmek istediğimizi varsayalım. ikili sınıflandırma problemi şimdi kendimizi yarattığımız:
import numpy as np
np.random.seed(0) X = np.random.randn(100, 2) # features
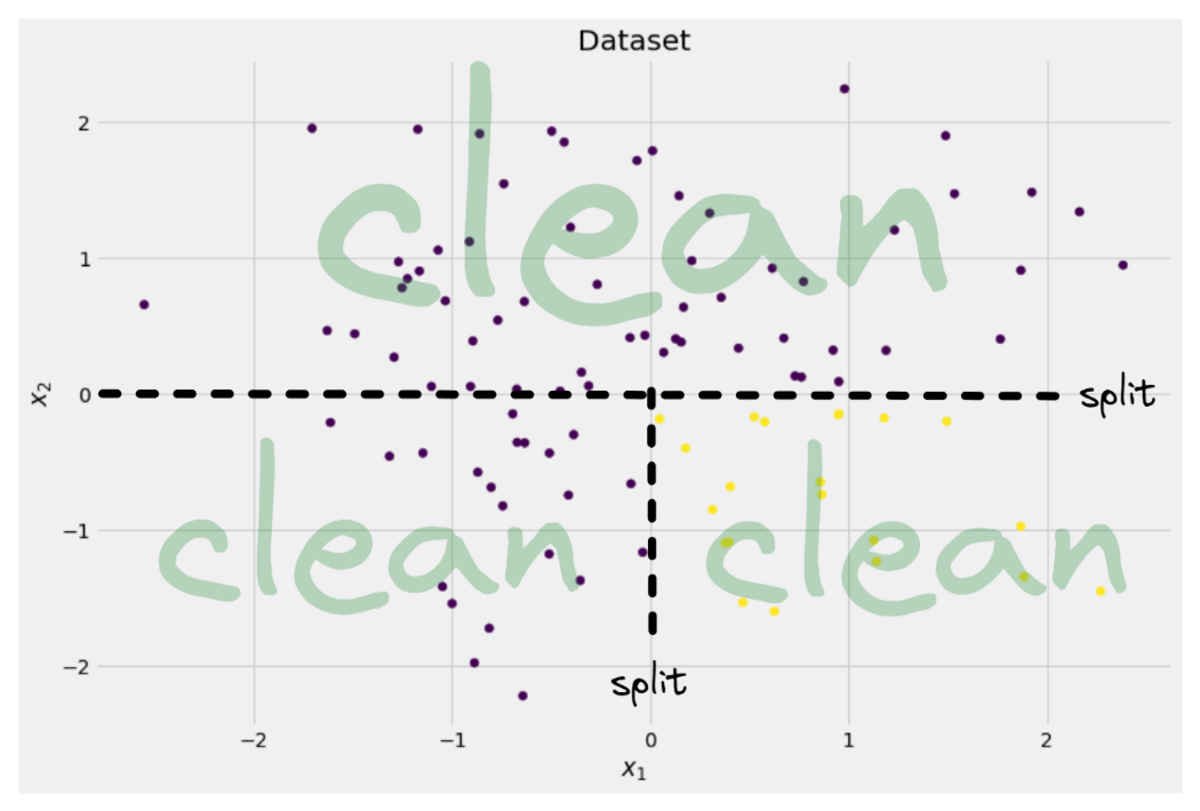
y = ((X[:, 0] > 0) * (X[:, 1] < 0)) # labels (0 and 1)İki boyutlu veriler şöyle görünür:
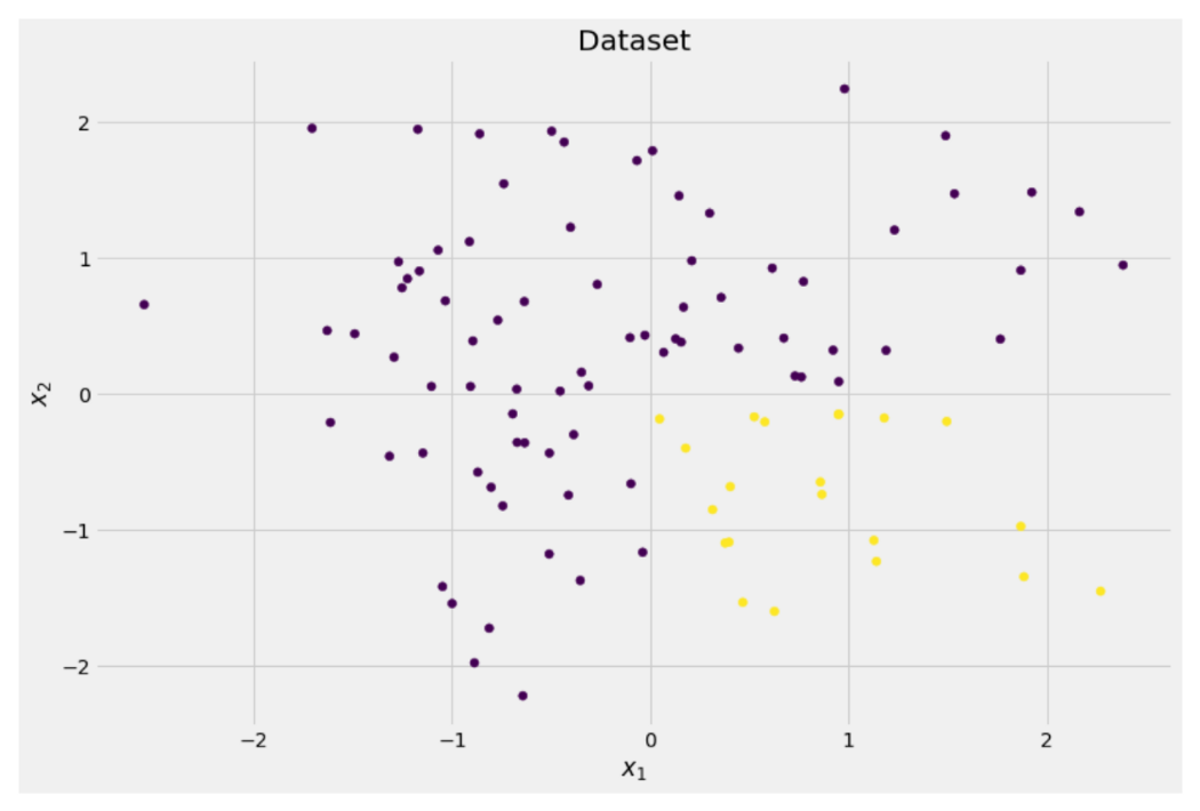
Yazara göre resim
Vakaların yaklaşık %75'inde mor ve yaklaşık %25'inde sarı olmak üzere iki farklı sınıf olduğunu görebiliriz. Bu verileri bir karar ağacına beslerseniz sınıflandırıcı, bu ağaç başlangıçta aşağıdaki düşüncelere sahiptir:
“İki farklı etiket var ve bu benim için çok karışık. Verileri iki parçaya bölerek bu karışıklığı temizlemek istiyorum; bu parçalar önceki tüm verilerden daha temiz olmalı." — bilinç kazanan ağaç
Ve böylece ağaç yapar.
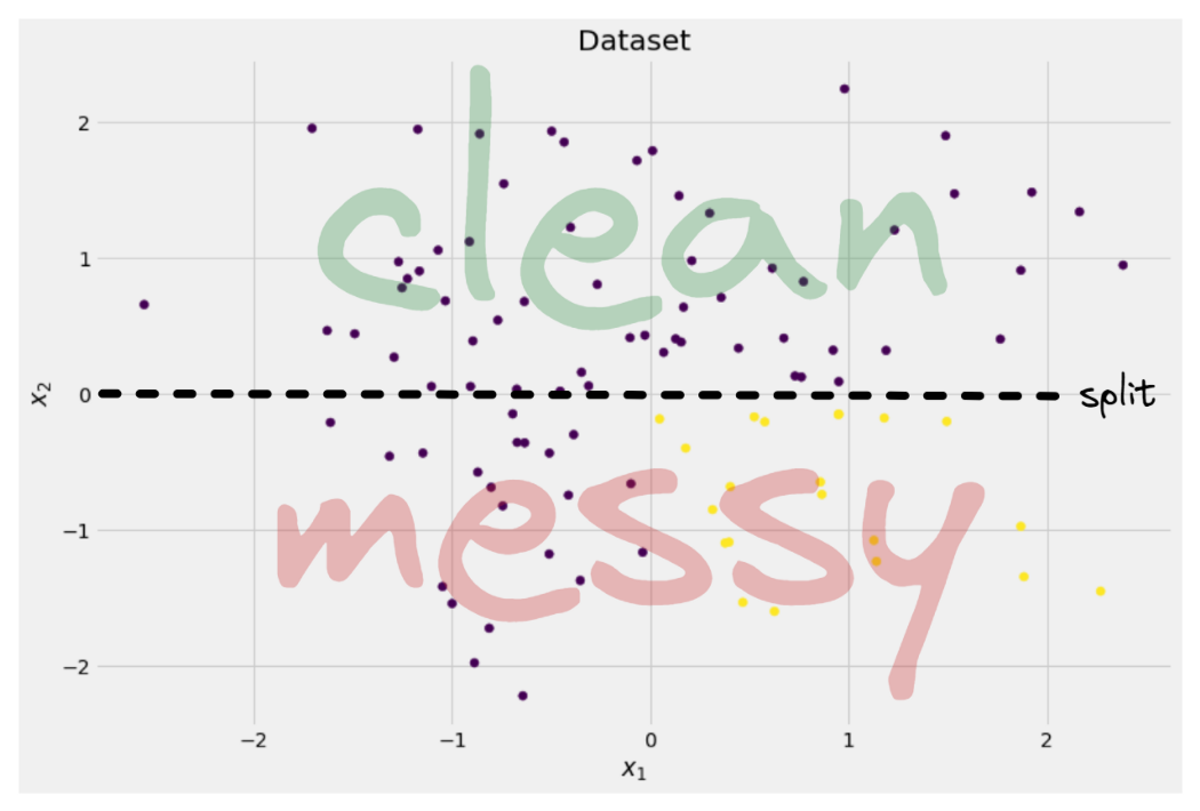
Yazara göre resim
Ağaç yaklaşık olarak bir yarık yapmaya karar verir. x-eksen. Bu, verilerin üst kısmının artık mükemmel şekilde temiz, sadece bulduğun anlamına gelir tek bir sınıf (bu durumda mor) orada.
Ancak alt kısım hala dağınık, hatta bir anlamda eskisinden daha dağınık. Eskiden tüm veri setinde sınıf oranı 75:25 civarındaydı, ancak bu daha küçük kısımda yaklaşık 50:50'dir ve bu olabildiğince karışıktır.
Not: Burada, resimde mor ve sarının güzelce ayrılması önemli değil. sadece farklı etiketlerin ham miktarı iki parça sayılır.
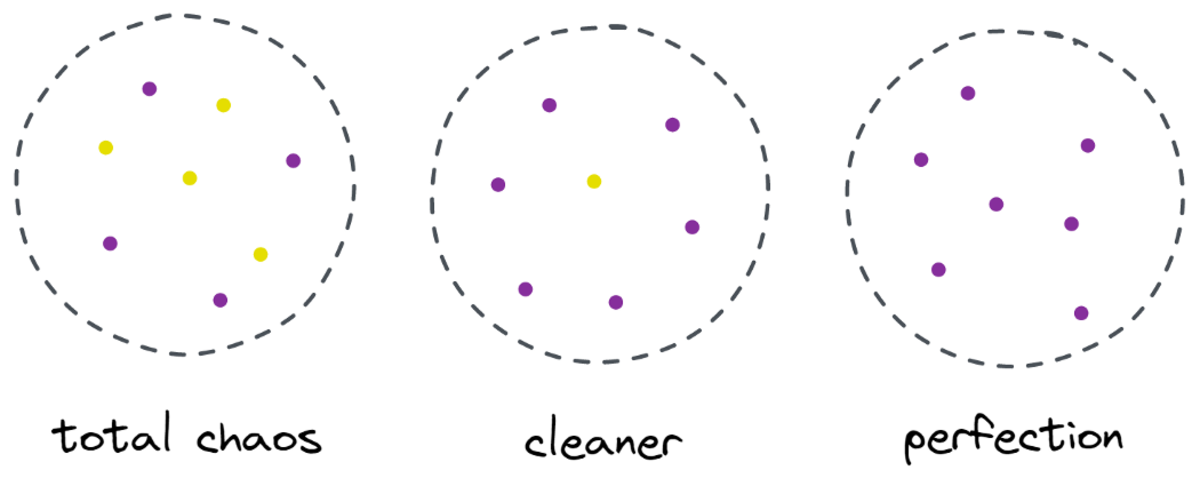
Yazara göre resim
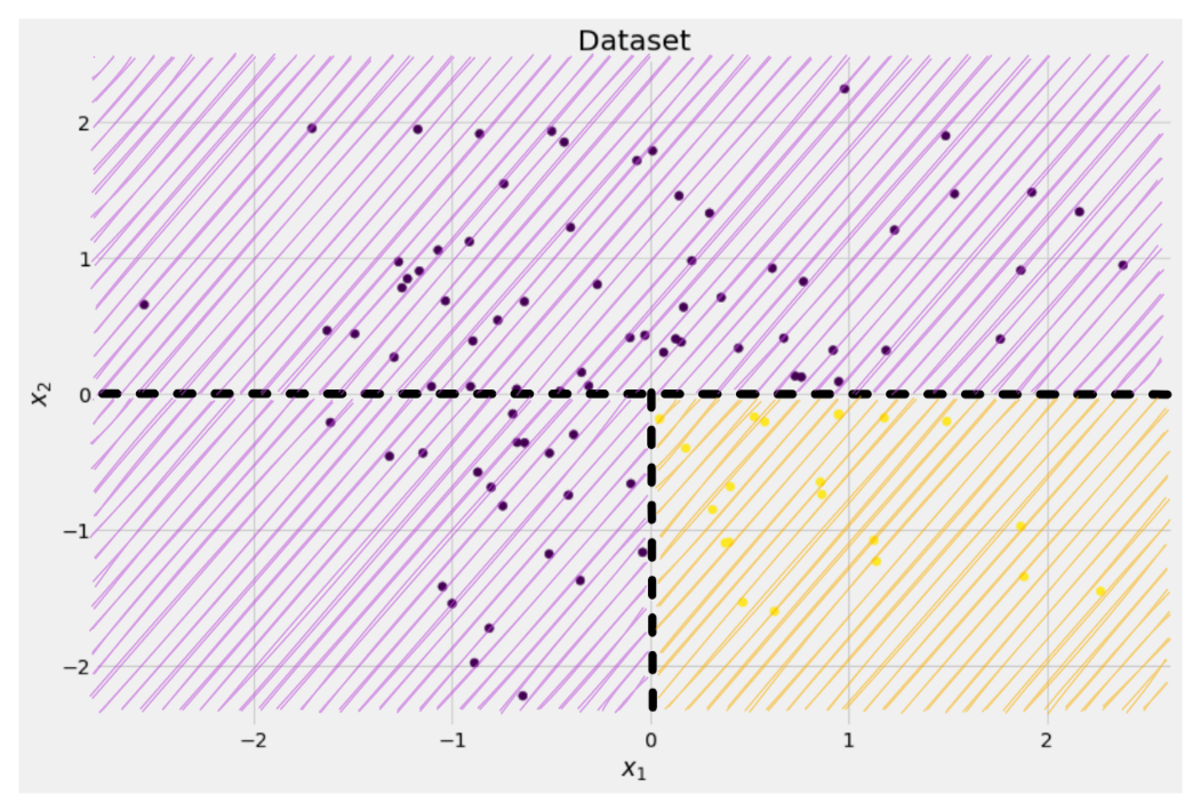
Yine de bu, ağaç için bir ilk adım olarak yeterince iyidir ve böylece devam eder. Zirvede başka bir bölünme yaratmayacak olsa da, çamça artık, temizlemek için alt kısımda başka bir yarık oluşturabilir.
Yazara göre resim
Et voilà, parça başına yalnızca tek bir renk (etiket) bulduğumuz için üç ayrı parçanın her biri tamamen temiz.
Artık tahmin yapmak gerçekten çok kolay: Yeni bir veri noktası gelirse, sadece hangisini kontrol edersiniz? Üç parça yatar ve ona karşılık gelen rengi verir. Bu artık çok iyi çalışıyor çünkü her bölüm çamça. Kolay değil mi?
Yazara göre resim
Tamam, hakkında konuşuyorduk çamça ve dağınık veriler, ancak şimdiye kadar bu kelimeler yalnızca bazı belirsiz fikirleri temsil ediyor. Herhangi bir şeyi uygulamak için, tanımlamanın bir yolunu bulmalıyız. temizlik.
Temizlik Önlemleri
Örneğin, bazı etiketlerimiz olduğunu varsayalım.
y_1 = [0, 0, 0, 0, 0, 0, 0, 0] y_2 = [1, 0, 0, 0, 0, 0, 1, 0]
y_3 = [1, 0, 1, 1, 0, 0, 1, 0]sezgisel, y₁ en temiz etiket setidir ve ardından y₂ ve sonra y₃. Şimdiye kadar çok iyi, ama bu davranışa nasıl rakamlar koyabiliriz? Belki de akla gelen en kolay şey şudur:
Sadece sıfırların miktarını ve birlerin miktarını sayın. Mutlak farklarını hesaplayın. Daha güzel hale getirmek için dizilerin uzunluğuna bölerek normalleştirin.
Örneğin, y₂ toplam 8 girişi vardır — 6 sıfır ve 2 bir. Bu nedenle, özel tanımlı temizlik puanı |6 – 2| / 8 = 0.5. Temizlik puanlarını hesaplamak kolaydır y₁ ve y₃ sırasıyla 1.0 ve 0.0'dır. Burada genel formülü görebiliriz:
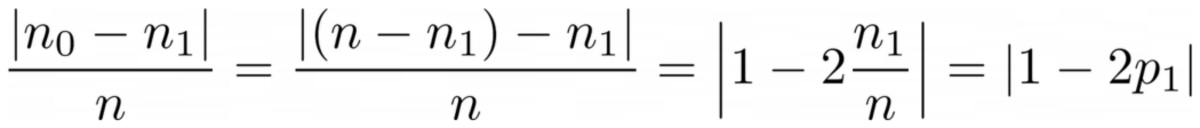
Yazara göre resim
Burada, n₀ ve n₁ sırasıyla sıfır ve birlerin sayılarıdır, n = n₀ + n₁ dizinin uzunluğu ve p₁ = n₁ / n 1 etiketin payıdır.
Bu formülle ilgili sorun şu ki, özellikle iki sınıfın durumuna göre uyarlanmış, ancak çoğu zaman çok sınıflı sınıflandırmayla ilgileniyoruz. Oldukça iyi çalışan bir formül, Gini kirlilik ölçüsü:
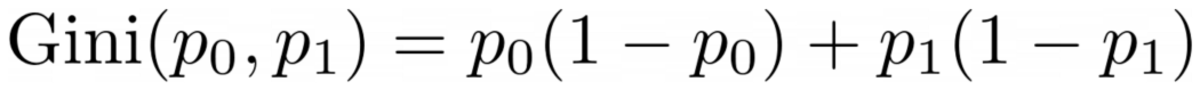
Yazara göre resim
veya genel durum:
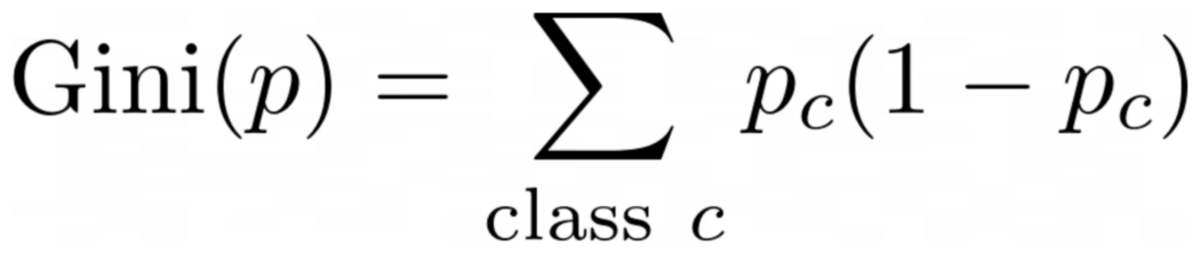
Yazara göre resim
O kadar iyi çalışıyor ki scikit-learn varsayılan önlem olarak benimsedi onun için DecisionTreeClassifier sınıf.
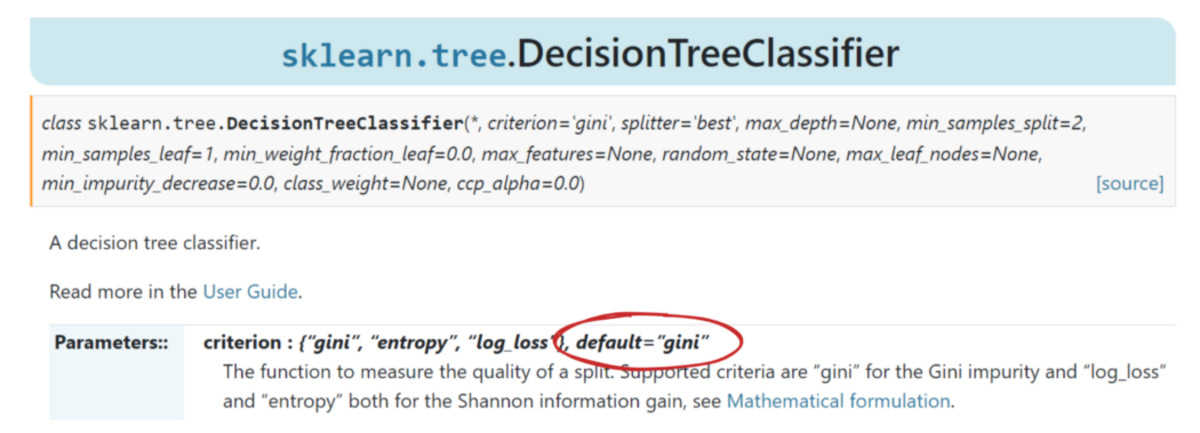
Yazara göre resim
Not: Gini ölçüleri dağınıklık temizlik yerine Örnek: bir liste yalnızca tek bir sınıf içeriyorsa (=çok temiz veri!), o zaman toplamdaki tüm terimler sıfırdır, dolayısıyla toplam sıfırdır. En kötü durum, tüm sınıfların tam sayıda görünmesidir, bu durumda Gini 1–1/C nerede C sınıf sayısıdır.
Artık temizlik/dağınıklık için bir ölçümüz olduğuna göre, bunun iyi ayrımlar bulmak için nasıl kullanılabileceğini görelim.
Bölmeleri Bulma
Aralarından seçim yapabileceğimiz birçok ayrım var ama hangisi iyi? Gini kirlilik ölçüsü ile birlikte ilk veri setimizi tekrar kullanalım.
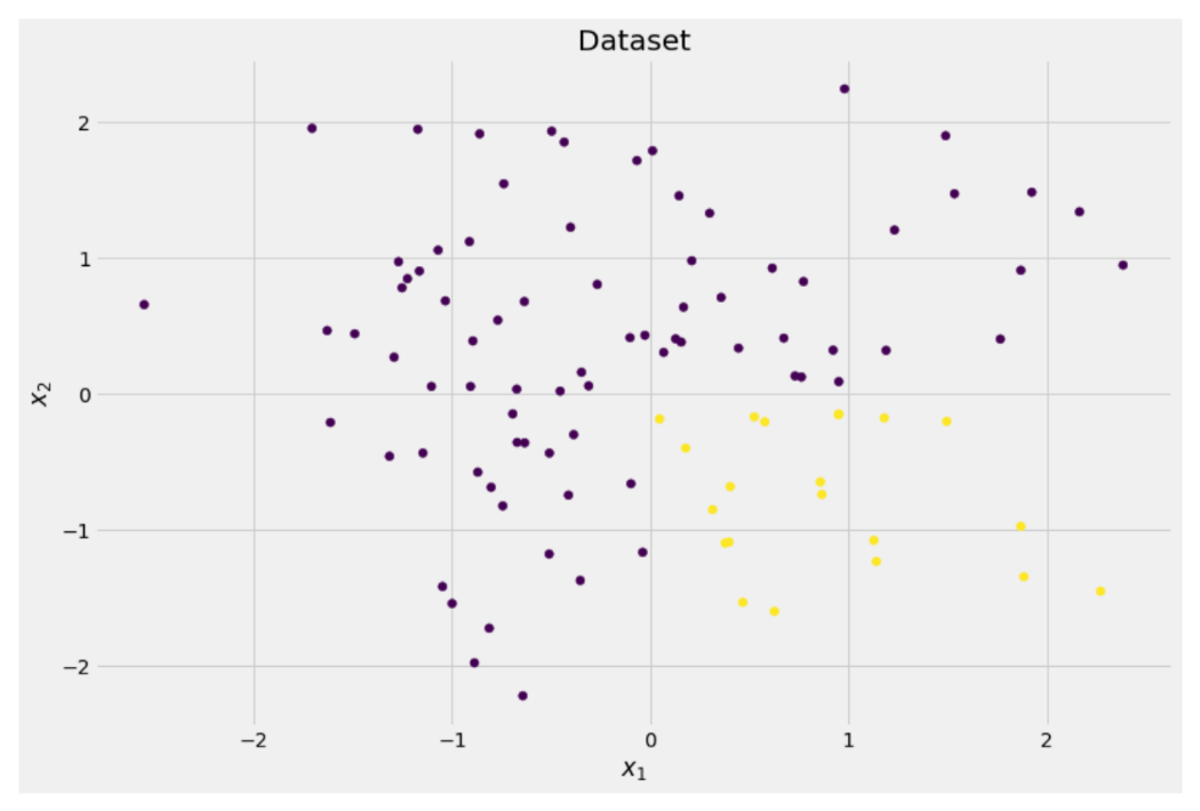
Yazara göre resim
Şimdi puanları saymayacağız, ancak %75'inin mor ve %25'inin sarı olduğunu varsayalım. Gini tanımını kullanarak, tüm veri kümesinin safsızlığı
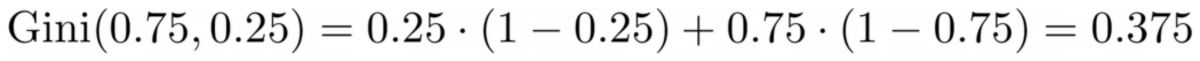
Yazara göre resim
Veri setini şuraya bölersek x-eksen, daha önce yapıldığı gibi:
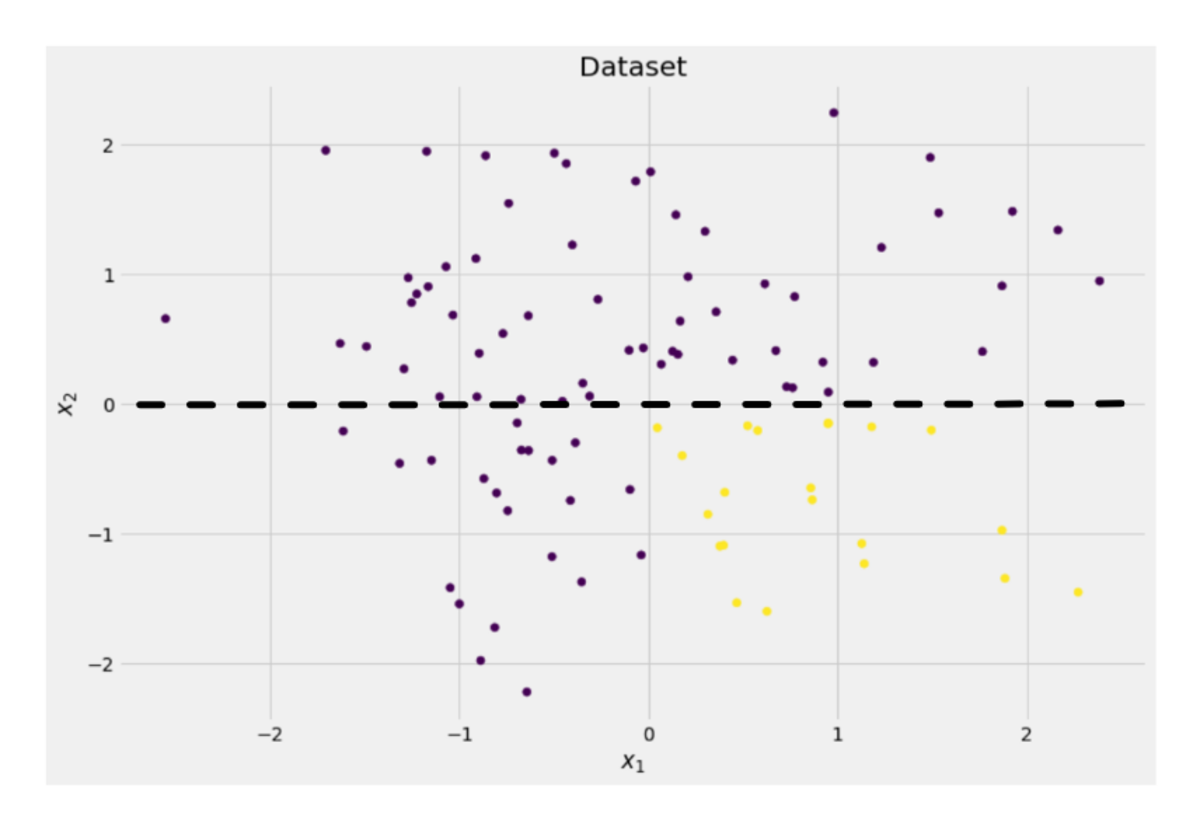
Yazara göre resim
The üst kısım 0.0 Gini safsızlığına sahiptir ve alt kısım
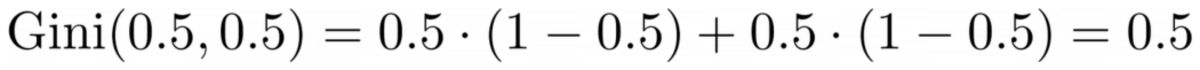
Yazara göre resim
Ortalama olarak, iki parça (0.0 + 0.5) / 2 = 0.25 Gini safsızlığına sahiptir; bu, önceki tüm veri kümesinin 0.375 değerinden daha iyidir. olarak da ifade edebiliriz. bilgi kazancı:
Bu bölmenin bilgi kazancı 0.375 – 0.25 = 0.125'tir.
Bu kadar kolay. Bilgi kazancı ne kadar yüksekse (yani, Gini safsızlığı ne kadar düşükse), o kadar iyidir.
Not: Eşit derecede iyi olan başka bir ilk bölme, y ekseni boyunca olacaktır.
Akılda tutulması gereken önemli bir şey, yararlı olduğudur. parçaların boyutuna göre parçaların Gini safsızlıklarını tartın. Örneğin, varsayalım ki
- 1. bölüm 50 veri noktasından oluşur ve 0.0 Gini safsızlığına sahiptir ve
- 2. kısım 450 veri noktasından oluşur ve 0.5 Gini safsızlığına sahiptir,
o zaman ortalama Gini safsızlığı (0.0 + 0.5) / 2 = 0.25 değil, 50 / (50 + 450) * 0.0 + 450 / (50 + 450) * 0.5 = olmalıdır. 0.45.
Tamam, peki en iyi ayrımı nasıl bulacağız? Basit ama ayıltıcı cevap:
Sadece tüm bölmeleri deneyin ve en yüksek bilgi kazancına sahip olanı seçin. Temelde kaba kuvvet yaklaşımıdır.
Daha kesin olmak gerekirse, standart karar ağaçları koordinat eksenleri boyunca bölmelerÖrneğin, xᵢ = c bazı özellikler için i ve eşik c. Bu demektir ki,
- bölünmüş verilerin bir kısmı tüm veri noktalarından oluşur x ile xᵢcve
- tüm noktaların diğer kısmı x ile xᵢ ≥ c.
Bu basit bölme kurallarının pratikte yeterince iyi olduğu kanıtlanmıştır, ancak elbette bu mantığı başka bölmeler oluşturmak için de genişletebilirsiniz (örn. xᵢ + 2xⱼ = 3, Örneğin).
Harika, şimdi başlamak için ihtiyacımız olan tüm malzemeler bunlar!
Karar ağacını şimdi uygulayacağız. Düğümlerden oluştuğu için, bir tanımlayalım. Node önce sınıf.
from dataclasses import dataclass @dataclass
class Node: feature: int = None # feature for the split value: float = None # split threshold OR final prediction left: np.array = None # store one part of the data right: np.array = None # store the other part of the dataBir düğüm, bölmek için kullandığı özelliği bilir (feature) ve bölme değeri (value). value karar ağacının nihai tahmini için bir depolama alanı olarak da kullanılır. İkili bir ağaç oluşturacağımız için, her düğümün sol ve sağ çocuklarını bilmesi gerekir. left ve right .
Şimdi asıl karar ağacı uygulamasını yapalım. Onu scikit-learn uyumlu hale getiriyorum, dolayısıyla bazı sınıfları kullanıyorum. sklearn.base . Buna aşina değilseniz, hakkındaki makaleme göz atın. scikit-learn uyumlu modeller nasıl oluşturulur.
Hadi uygulayalım!
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin class DecisionTreeClassifier(BaseEstimator, ClassifierMixin): def __init__(self): self.root = Node() @staticmethod def _gini(y): """Gini impurity.""" counts = np.bincount(y) p = counts / counts.sum() return (p * (1 - p)).sum() def _split(self, X, y): """Bruteforce search over all features and splitting points.""" best_information_gain = float("-inf") best_feature = None best_split = None for feature in range(X.shape[1]): split_candidates = np.unique(X[:, feature]) for split in split_candidates: left_mask = X[:, feature] split X_left, y_left = X[left_mask], y[left_mask] X_right, y_right = X[~left_mask], y[~left_mask] information_gain = self._gini(y) - ( len(X_left) / len(X) * self._gini(y_left) + len(X_right) / len(X) * self._gini(y_right) ) if information_gain > best_information_gain: best_information_gain = information_gain best_feature = feature best_split = split return best_feature, best_split def _build_tree(self, X, y): """The heavy lifting.""" feature, split = self._split(X, y) left_mask = X[:, feature] split X_left, y_left = X[left_mask], y[left_mask] X_right, y_right = X[~left_mask], y[~left_mask] if len(X_left) == 0 or len(X_right) == 0: return Node(value=np.argmax(np.bincount(y))) else: return Node( feature, split, self._build_tree(X_left, y_left), self._build_tree(X_right, y_right), ) def _find_path(self, x, node): """Given a data point x, walk from the root to the corresponding leaf node. Output its value.""" if node.feature == None: return node.value else: if x[node.feature] node.value: return self._find_path(x, node.left) else: return self._find_path(x, node.right) def fit(self, X, y): self.root = self._build_tree(X, y) return self def predict(self, X): return np.array([self._find_path(x, self.root) for x in X])Ve bu kadar! Scikit-learn ile ilgili sevdiğiniz tüm şeyleri şimdi yapabilirsiniz:
dt = DecisionTreeClassifier().fit(X, y)
print(dt.score(X, y)) # accuracy # Output
# 1.0Ağaç düzensiz olduğu için çok fazla uyuyor, bu nedenle mükemmel tren puanı. Görünmeyen verilerde doğruluk daha kötü olacaktır. Ayrıca ağacın nasıl göründüğünü de kontrol edebiliriz.
print(dt.root) # Output (prettified manually):
# Node(
# feature=1,
# value=-0.14963454032767076,
# left=Node(
# feature=0,
# value=0.04575851730144607,
# left=Node(
# feature=None,
# value=0,
# left=None,
# right=None
# ),
# right=Node(
# feature=None,
# value=1,
# left=None,
# right=None
# )
# ),
# right=Node(
# feature=None,
# value=0,
# left=None,
# right=None
# )
# )Bir resim olarak, bu olurdu:
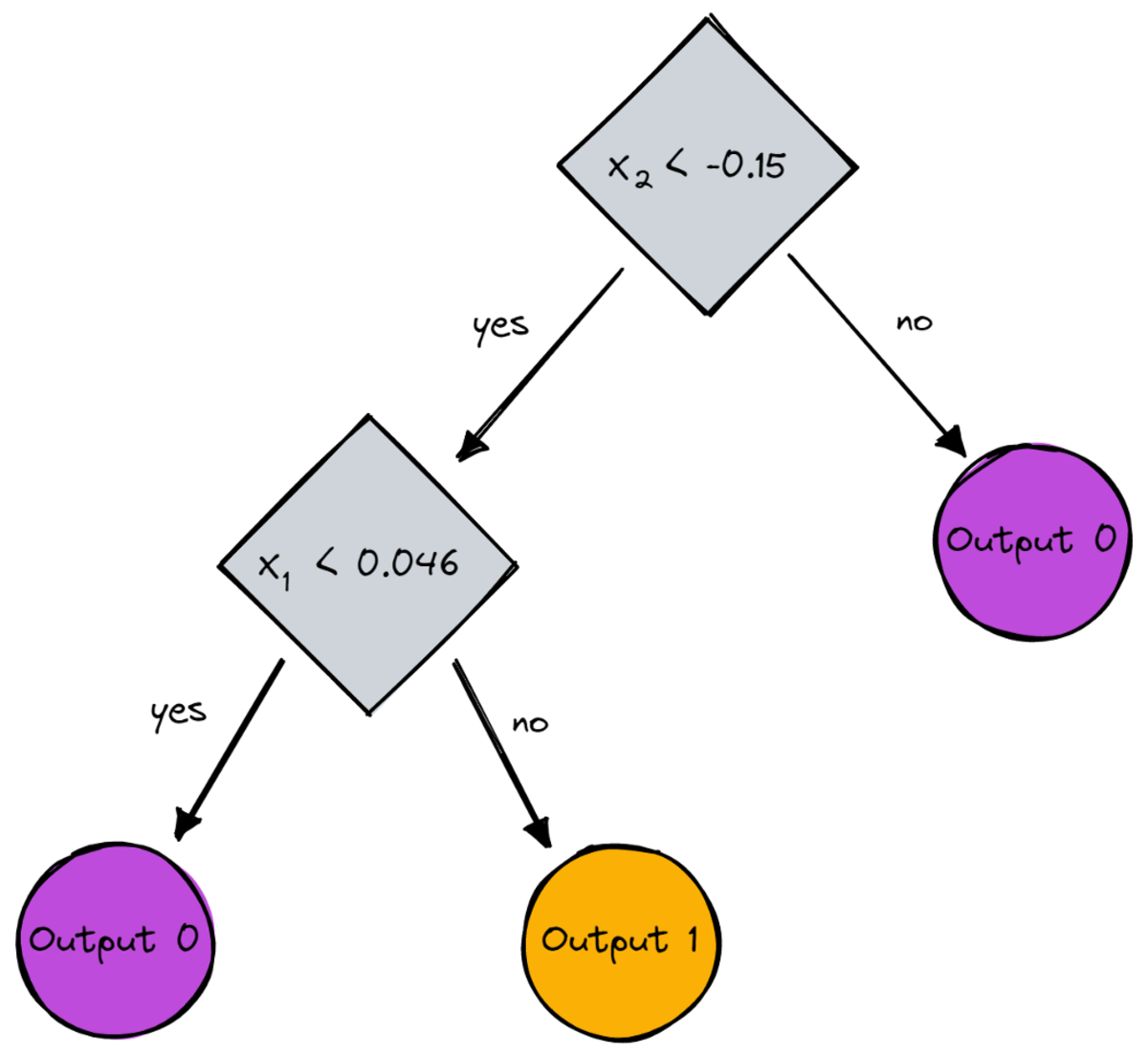
Yazara göre resim
Bu yazımızda karar ağaçlarının nasıl çalıştığını detaylı bir şekilde gördük. Bazı belirsiz ama sezgisel fikirlerle başladık ve bunları formüllere ve algoritmalara dönüştürdük. Sonunda, sıfırdan bir karar ağacı uygulayabildik.
Yine de bir uyarı: Karar ağacımız henüz düzenli hale getirilemiyor. Genellikle, gibi parametreleri belirtmek isteriz.
- Maksimum derinlik
- yaprak boyutu
- ve minimum bilgi kazancı
diğerleri arasında. Şans eseri, bunları uygulamak o kadar da zor değil, bu da sizin için mükemmel bir ev ödevi olmasını sağlıyor. Örneğin, belirtirseniz leaf_size=10 bir parametre olarak, o zaman 10'dan fazla örnek içeren düğümler artık bölünmemelidir. Ayrıca bu uygulama, verimli değil. Genellikle veri kümelerinin parçalarını düğümlerde depolamak istemezsiniz, bunun yerine yalnızca dizinleri depolamak istersiniz. Yani (potansiyel olarak büyük) veri kümeniz yalnızca bir kez bellekte kalır.
İşin güzel yanı, bu karar ağacı şablonuyla artık çıldırabilirsiniz. Yapabilirsiniz:
- diyagonal bölmeler uygulayın, yani xᵢ + 2xⱼ = 3 sadece xᵢ = 3,
- yaprakların içinde gerçekleşen mantığı değiştirin, yani sadece çoğunluk oyu yapmak yerine her yaprakta bir lojistik regresyon çalıştırabilirsiniz, bu da size doğrusal ağaç
- bölme prosedürünü değiştirin, yani kaba kuvvet uygulamak yerine, bazı rastgele kombinasyonları deneyin ve en iyisini seçin; ağaç dışı sınıflandırıcı
- ve daha fazlası.
Robert Kübler Publicis Media'da Veri Bilimcisi ve Towards Data Science'da Yazar.
orijinal. İzinle yeniden yayınlandı.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/2023/02/understanding-implementing-decision-tree.html?utm_source=rss&utm_medium=rss&utm_campaign=understanding-by-implementing-decision-tree

