Giriş
Veriler BT endüstrisi için yakıttır ve Veri Bilimi Projesi günümüzün çevrimiçi dünyasında. BT endüstrileri büyük ölçüde gerçek zamanlı bilgilerden elde edilen bilgilere güveniyor. veri akışı kaynaklar. Akış verilerinin işlenmesi ve işlenmesi en zor iştir Veri Analizi. Akış verilerinin, sürekli bir işlem sırasında yüksek hacimde yayılan veriler olduğunu biliyoruz; bu, verilerin her saniye değiştiği anlamına gelir. Bu verileri işlemek için kullanıyoruz Birleşik Platform – Kendi kendini yöneten, kurumsal düzeyde bir dağıtım Apache Kafka.
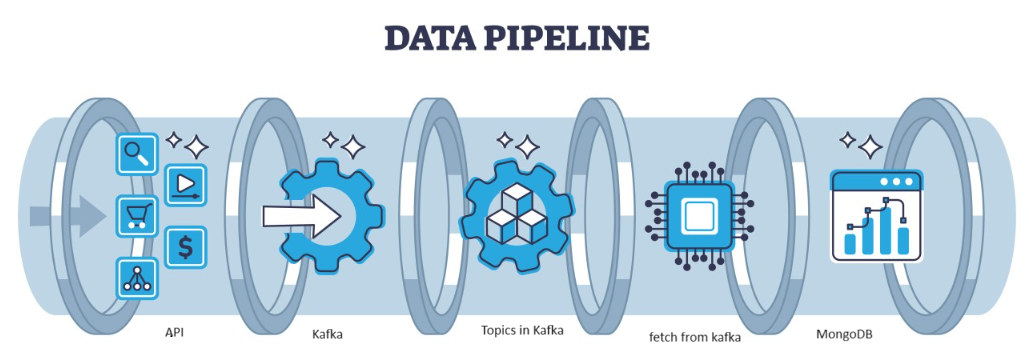
Kafka, yüksek verimli veri akışlarını yönetmek için popüler bir seçim olarak hizmet veren, mimari tarafından yönetilebilen dağıtılmış bir hatadır. Daha sonra Kafka'dan gelen veriler şu şekilde toplanır: MongoDB koleksiyonlar şeklinde. Bu yazımızda Pipeline'da API yardımıyla verilerin getirilip Kafka'da konu şeklinde toplandığı ve daha sonra MongoDB'de saklandığı uçtan uca boru hattını oluşturacağız ve oradan kullanabiliriz. projede veya özellik mühendisliğini yapın.
Öğrenme hedefleri
- Akış verilerinin ne olduğunu ve akış verilerinin nasıl işleneceğini Kafka'nın yardımıyla öğrenin.
- Confluent Platformunu Anlayın – Apache Kafka'nın kendi kendini yöneten, kurumsal düzeyde bir dağıtımı.
- Kafka tarafından toplanan verileri, yapılandırılmamış verileri saklayan bir NoSQL veritabanı olan MongoDB'de saklayın.
- Verileri Veritabanına getirmek ve depolamak için tamamen uçtan uca bir işlem hattı oluşturun.
Bu makale, Veri Bilimi Blogatonu.
İçindekiler
Sorunu Tanımla
Sensörden gelen akış verilerini işlemek için, sensör verilerini içeren araçlar saniyede üretilir ve verinin işlenip ön işleme tabi tutulması zordur. Veri Bilimi projesi. Bu sorunu çözmek için verileri işleyen ve depolayan uçtan uca bir işlem hattı oluşturuyoruz.
Veri Akışı Nedir?
Veri akışı Farklı kaynaklardan sürekli olarak üretilen, yapılandırılmamış verilerdir. Farklı kaynaklardan gerçek zamanlı veya neredeyse gerçek zamanlı olarak üretilen verilerin sürekli akışını ifade eder. Verilerin toplandığı ve bu akış verilerinin oluşturulduğu anda işlendiği geleneksel toplu işlemede. Akış verileri, sıcaklık sensörleri ve GPS izleyicileri gibi IOT verileri veya araçlardan ve üretim makinelerinden alınan telemetri verileri gibi makineler ve endüstriyel ekipmanlar tarafından oluşturulan Makine Verileri benzeri veriler olabilir. Apache-Kafka gibi akışlı veri işleme platformları vardır.
Kafka nedir?
Apache Kafka, gerçek zamanlı veri hatları ve akış uygulamaları oluşturmak için kullanılan bir platformdur. Kafka Streams API, anında işlemeye olanak tanıyan, pencereleme parametrelerini toplamanıza ve oluşturmanıza, bir akış içinde veri birleştirmeleri gerçekleştirmenize ve daha fazlasına olanak tanıyan güçlü bir kitaplıktır. Apache Kafka, verimli, gerçek zamanlı veri alımını, akışlı veri ardışık düzenlerini ve sistemler arasında depolamayı birleştiren bir depolama katmanı ve bir bilgi işlem katmanından oluşur.
Yaklaşım Ne Olacak?
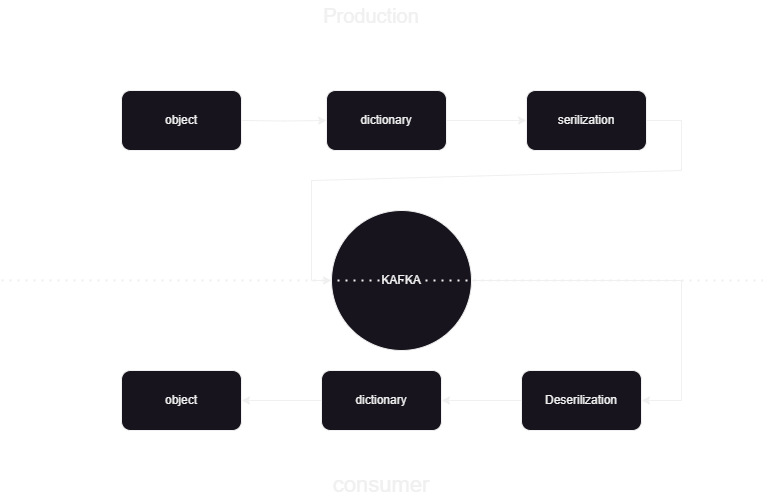
Bu, Kafka'ya giden ve Kafka'dan gelen verileri JSON formatında nasıl yayınlayacağımızı ve işleyeceğimizi bilmemize yardımcı olan bir makine öğrenimi hattıdır. Kafka veri işlemenin tüketici ve üretici olmak üzere iki kısmı vardır. Farklı üreticilerden gelen akış verilerini depolamak ve bir arada depolamak için veriler üzerinde seri durumdan çıkarma işlemi yapılır ve bu veriler Veritabanında saklanır.
Sistem Mimarisine Genel Bakış
Akış verilerini birleşik kafka yardımıyla işliyoruz ve Kafka iki iki bölüme ayrılıyor:
- Kafka Yapımcısı: Kafka Yapımcısı, Kafka konularına veri üretmek ve göndermekle sorumludur.
- Kafka Tüketicisi: Kafka Tüketicisi, Kafka konularındaki verileri okuyup işleyecektir.
Start
│
├─ Kafka Consumer (Read from Kafka Topic)
│ ├─ Process Message
│ └─ Store Data in MongoDB
│
├─ Kafka Producer (Generate Sensor Data)
│ ├─ Send Data to Kafka Topic
│ └─ Repeat
│
End
Bileşenler Nelerdir?
- Başlıklar: Konular yapımcılar tarafından yayınlanan mantıksal kanallar veya kategorilerdir. Her konu bir veya daha fazla bölüme ayrılır ve her konu, hata toleransı için birden fazla aracıda çoğaltılır. Üreticiler belirli konulardaki verileri yayınlar ve tüketiciler verileri kullanmak için konulara abone olurlar.
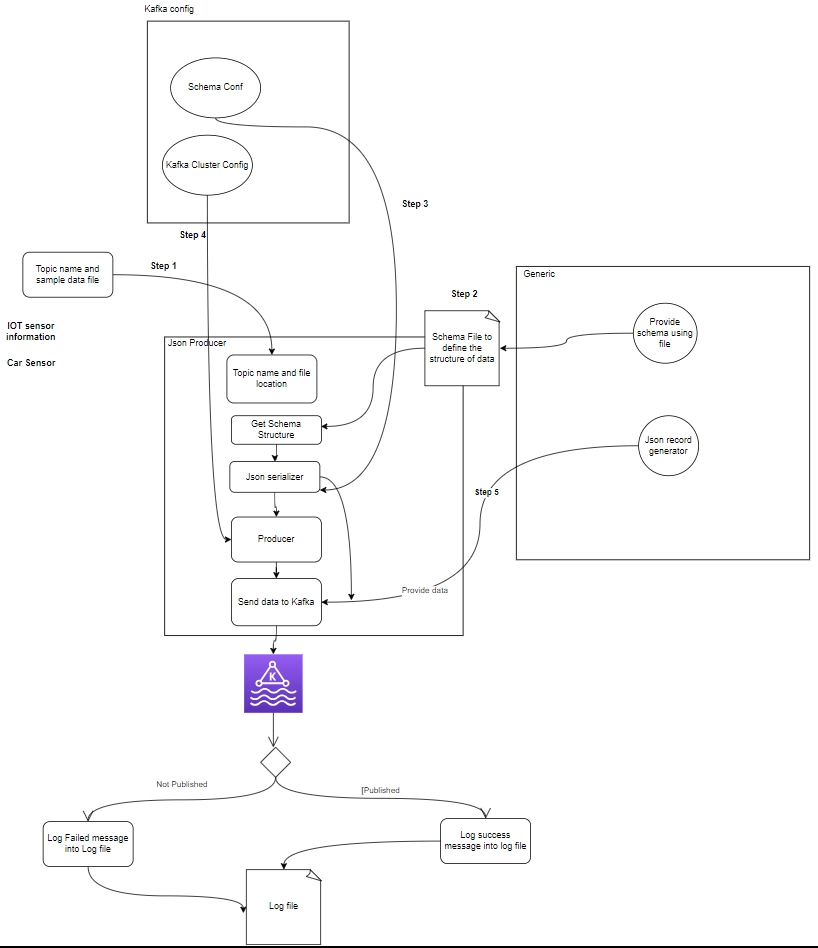
- yapımcılar: Apache Kafka Yapımcısı, olayları bir Kafka kümesine yayınlayan (yazar) bir istemci uygulamasıdır. Konulara veri gönderen uygulamalar Kafka üreticileri olarak bilinir. Bu bölümde Kafka yapımcısına genel bir bakış sunulmaktadır.
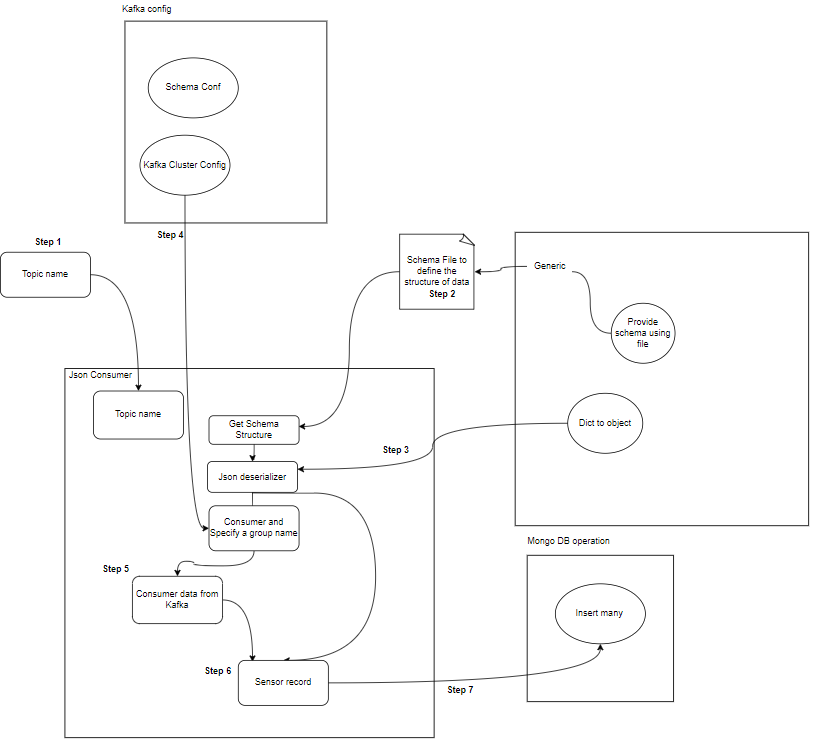
- Tüketici: Kafka tüketicileri, Kafka konularına ait veri ve işlemelerin okunması ve işlenmesinden sorumludur. Tüketiciler, Kafka'daki verileri kullanması ve bunlara tepki vermesi gereken herhangi bir uygulamanın parçası olabilir. Kafka komisyoncularının bir veya daha fazla konusuna ve verilerine abone olurlar. Tüketiciler, her tüketici grubunun bir veya daha fazla tüketiciye sahip olduğu ve bir konunun her konusunun grup içindeki yalnızca bir tüketici tarafından tüketildiği tüketici grupları halinde organize edilebilir. Bu, veri tüketiminin paralel işlenmesine ve yük dengelemesine olanak tanır.
Proje Yapısı Nedir?
Bu, projenin akış şemasını, klasör ve dosyaların projede nasıl bölündüğünü gösterir:
flowchart/
│
├── consumer.drawio.svg
├── flow of kafka.drawio
└── producer.drawio.svg
sample_data/
│
└── aps_failure_training_set1.csv
env/
sensor_data-pipeline_kafka
/
│
├── src/
│ ├── database/
│ │ ├── mongodb.py
│ │
│ ├── kafka_config/
│ │ └──__init__.py/
│ │
│ │
│ ├── constant/
│ │ ├── __init__.py
│ │
│ │
│ ├── data_access/
│ │ ├── user_data.py
│ │ └── user_embedding_data.py
│ │
│ ├── entity/
│ │ ├── __init__.py
│ │ └── generic.py
│ │
│ ├── exception/
│ │ └── (exception handling)
│ │
│ ├── kafka_logger/
│ │ └── (logging configuration)
│ │
│ ├── kafka_consumer/
│ │ └── util.py
│ │
│ └── __init__.py
│
└── logs/
└── (log files)
.dockerignore
.gitignore
Dockerfile
schema.json
consumer_main.py
producer_main.py
requirments.txt
setup.py- Kafka Yapımcısı: Üretici, sensör verilerini (örn. sample_data/ içindeki CSV dosyalarından) üreten ve bunu bir Kafka konusuna yayınlayan ana kısımdır. Veri üretimi veya yayınlanması sırasında oluşabilecek hata durumları.
- Kafka Broker(lar)ı: Kafka aracıları, Kafka kümesi genelinde verileri depolar ve çoğaltır, veri bölümlemeyi yönetir ve hata toleransı ve yüksek kullanılabilirlik sağlar.
- Kafka Tüketici(ler): Tüketiciler Kafka konularındaki verileri okur, işler (örn. dönüşümler, toplamalar) ve MongoDB'de saklar. Ayrıca veri işleme sırasında oluşabilecek hata durumlarını da izlerler.
- MongoDB: MongoDB, Kafka tüketicilerinden alınan sensör verilerini saklar. Veri alımı için bir sorgu sağlar ve çoğaltma ve hata toleransı mekanizmaları aracılığıyla veri dayanıklılığını sağlar.
Start
│
├── Kafka Producer ──────────────────┐
│ ├── Generate Sensor Data │
│ └── Publish Data to Kafka Topic │
│ │
│ └── Error Handling
│ │
├── Kafka Broker(s) ─────────────────┤
│ ├── Store and Replicate Data │
│ └── Handle Data Partitioning │
│ │
├── Kafka Consumer(s) ───────────────┤
│ ├── Read Data from Kafka Topic │
│ ├── Process Data │
│ └── Store Data in MongoDB │
│ │
│ └── Error Handling
│ │
├── MongoDB ────────────────────────┤
│ ├── Store Sensor Data │
│ ├── Provide Query Interface │
│ └── Ensure Data Durability │
│ │
└── End │
Veri Depolamanın Önkoşulları
Konfluent Kafka
- Hesap Oluşturun: Kafka'yı anlamak için Confluent'e ihtiyacınız var Apache Kafka®'yı seviyorsunuz ama yönetmiyorsunuz. Bulutta yerel, eksiksiz ve tam olarak yönetilen hizmet, Kafka'nın ötesine geçer ve böylece en iyi çalışanlarınız işinize değer sağlamaya odaklanabilir.
- Konu Oluşturun:
- Ana sayfaya ve kenar çubuğuna gidin
- Ortam'a gidin ve ardından Varsayılan'a tıklayın
- Konulara git

- Yeni konuyu seçin konunun adını verin

MongoDB
Kayıt oluşturun ve ardından MongoDB Atlas'ta oturum açın ve daha sonra kullanmak üzere Mongodb Atlas'ın bağlantı bağlantısını kaydedin.
Proje Kurulumu için Adım Adım Kılavuz
- Python Kurulumu: Makinenizde Python'un kurulu olduğundan emin olun. İndirip kurabilirsiniz Python resmi web sitesinden.
- Conda sürümü: Terminaldeki conda sürümünü kontrol edin.
- Sanal Ortam Oluşturma: venv kullanarak sanal bir ortam oluşturun.
conda create -p venv python==3.10 -y- Sanal Ortam Aktivasyonu: Sanal ortamı etkinleştirin:
conda activate venv/- Gerekli Paketleri Kurun: Gereksinimler.txt dosyasında listelenen gerekli bağımlılıkları yüklemek için pip kullanın:
pip install -r requirements.txt- yerel sistemde bazı ortam değişkenlerini ayarlamamız gerekiyor. Bu, birleşik bulut Küme Ortamı Değişkenidir
API_KEY
API_SECRET_KEY
BOOTSTRAP_SERVER
SCHEMA_REGISTRY_API_KEY
SCHEMA_REGISTRY_API_SECRET
ENDPOINT_SCHEMA_URL
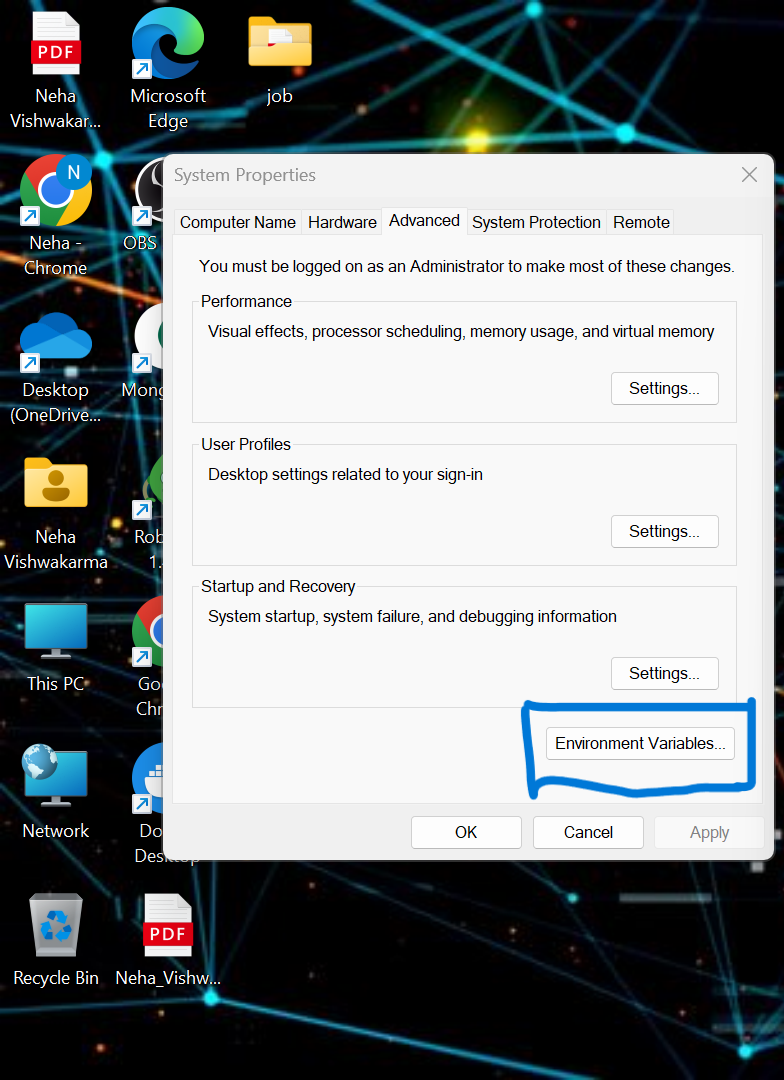
.env dosyasındaki kimlik bilgilerini güncelleyin ve uygulamanızı docker'da çalıştırmak için aşağıdaki komutu çalıştırın.
- Projenizin kök dizininde .env dosyası oluşturun, eğer mevcut değilse aşağıdaki içeriği yapıştırın ve kimlik bilgilerini güncelleyin
API_KEY=asgdakhlsa
API_SECRET_KEY=dsdfsdf
BOOTSTRAP_SERVER=sdfasd
SCHEMA_REGISTRY_API_KEY=sdfsaf
SCHEMA_REGISTRY_API_SECRET=sdfasdf
ENDPOINT_SCHEMA_URL=sdafasf
MONGO_DB_URL=sdfasdfas
- Üretici ve tüketici dosyasını çalıştırma:
python producer_main.py
python consumer_main.pyKod Nasıl Uygulanır?
- kaynak/: Bu dizin tüm kaynak kod dosyalarının ana klasörüdür. Bu dizinde aşağıdaki alt dizinlerimiz var:
tüketici/: Bu dizin, Kafka konularındaki verileri okumaktan ve işlemekten sorumlu olan Kafka_tüketici kodunu içerir.
yapımcı/: Bu dizin, Kafka konularına sensör verilerinin oluşturulmasından ve gönderilmesinden sorumlu olan Kafka_producer kodunu içerir. - README.md: Bu Markdown dosyası, amacına genel bakış, talimatlar, kullanım yönergeleri ve her türlü bilgi de dahil olmak üzere projeye ilişkin belgeleri ve talimatları içerir.
- gereksinimler.txt: Bu dosya proje için gerekli Python kütüphanesini listeler. Her bağımlılık sürüm numarasıyla birlikte listelenir. Pip gibi araçlar, gerekli bağımlılıkları otomatik olarak kurmak için bu dosyayı kullanabilir.
sensor_data-pipeline_kafka/
│
├── src/
│ ├── consumer/
│ │ ├── __init__.py
│ │ └── kafka_consumer.py
│ │
│ ├── producer/
│ │ ├── __init__.py
│ │ └── kafka_producer.py
│ │
│ └── __init__.py
│
├── README.md
└── requirements.txt
mongodb.py: MongoDB Altas'ı link üzerinden bağlamak için python betiğini yazıyoruz
import pymongo
import os
import certifi
ca = certifi.where()
db_link ="mongodb+srv://Neha:<password>@cluster0.jsogkox.mongodb.net/"
class MongodbOperation:
def __init__(self) -> None:
#self.client = pymongo.MongoClient(os.getenv('MONGO_DB_URL'),tlsCAFile=ca)
self.client = pymongo.MongoClient(db_link,tlsCAFile=ca)
self.db_name="NehaDB"
def insert_many(self,collection_name,records:list):
self.client[self.db_name][collection_name].insert_many(records)
def insert(self,collection_name,record):
self.client[self.db_name][collection_name].insert_one(record)
MongoDb Altas'tan kopyalanan URL'nizi girin
Çıktı:
from src.kafka_producer.json_producer import product_data_using_file
from src.constant import SAMPLE_DIR
import os
if __name__ == '__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
product_data_using_file(topic=topic,file_path=sample_file_path)
Bu dosya çalışır ve ardından onu çağırırız. piton yapımcı_main.py ve bu aşağıdaki dosyayı arayacak:
import argparse
from uuid import uuid4
from src.kafka_config import sasl_conf, schema_config
from six.moves import input
from src.kafka_logger import logging
from confluent_kafka import Producer
from confluent_kafka.serialization import StringSerializer, SerializationContext, MessageField
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.json_schema import JSONSerializer
import pandas as pd
from typing import List
from src.entity.generic import Generic, instance_to_dict
FILE_PATH = "C:/Users/RAJIV/Downloads/ml-data-pipeline-main/sample_data/kafka-sensor-topic.csv"
def delivery_report(err, msg):
"""
Reports the success or failure of a message delivery.
Args:
err (KafkaError): The error that occurred on None on success.
msg (Message): The message that was produced or failed.
"""
if err is not None:
logging.info("Delivery failed for User record {}: {}".format(msg.key(), err))
return
logging.info('User record {} successfully produced to {} [{}] at offset {}'
.format(
msg.key(), msg.topic(), msg.partition(), msg.offset()))
def product_data_using_file(topic,file_path):
logging.info(f"Topic: {topic} file_path:{file_path}")
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
schema_registry_conf = schema_config()
schema_registry_client = SchemaRegistryClient(schema_registry_conf)
string_serializer = StringSerializer('utf_8')
json_serializer = JSONSerializer(schema_str, schema_registry_client,
instance_to_dict)
producer = Producer(sasl_conf())
print("Producing user records to topic {}. ^C to exit.".format(topic))
# while True:
# Serve on_delivery callbacks from previous calls to produce()
producer.poll(0.0)
try:
for instance in Generic.get_object(file_path=file_path):
print(instance)
logging.info(f"Topic: {topic} file_path:{instance.to_dict()}")
producer.produce(topic=topic,
key=string_serializer(str(uuid4()), instance.to_dict()),
value=json_serializer(instance,
SerializationContext(topic, MessageField.VALUE)),
on_delivery=delivery_report)
print("nFlushing records...")
producer.flush()
except KeyboardInterrupt:
pass
except ValueError:
print("Invalid input, discarding record...")
pass
Çıktı:

from src.kafka_consumer.json_consumer import consumer_using_sample_file
from src.constant import SAMPLE_DIR
import os
if __name__=='__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
consumer_using_sample_file(topic="kafka-sensor-topic",file_path = sample_file_path)
Bu dosya çalışır ve ardından onu çağırırız. python tüketici_main.py ve bu aşağıdaki dosyayı arayacak:
import argparse
from confluent_kafka import Consumer
from confluent_kafka.serialization import SerializationContext, MessageField
from confluent_kafka.schema_registry.json_schema import JSONDeserializer
from src.entity.generic import Generic
from src.kafka_config import sasl_conf
from src.database.mongodb import MongodbOperation
def consumer_using_sample_file(topic,file_path):
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
json_deserializer = JSONDeserializer(schema_str,
from_dict=Generic.dict_to_object)
consumer_conf = sasl_conf()
consumer_conf.update({
'group.id': 'group7',
'auto.offset.reset': "earliest"})
consumer = Consumer(consumer_conf)
consumer.subscribe([topic])
mongodb = MongodbOperation()
records = []
x = 0
while True:
try:
# SIGINT can't be handled when polling, limit timeout to 1 second.
msg = consumer.poll(1.0)
if msg is None:
continue
record: Generic = json_deserializer(msg.value(),
SerializationContext(msg.topic(), MessageField.VALUE))
# mongodb.insert(collection_name="car",record=car.record)
if record is not None:
records.append(record.to_dict())
if x % 5000 == 0:
mongodb.insert_many(collection_name="sensor", records=records)
records = []
x = x + 1
except KeyboardInterrupt:
break
consumer.close()Çıktı:

Hem tüketiciyi hem de üreticiyi çalıştırdığımızda sistem kafka üzerinde çalışıyor ve bilgi/veri daha hızlı toplanıyor

Çıktı:
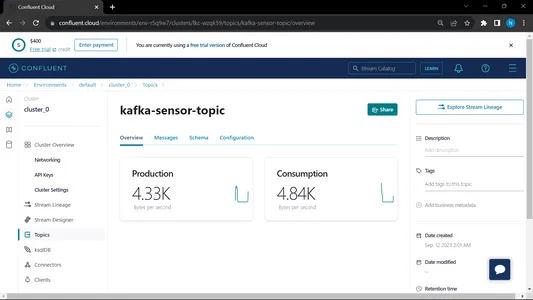
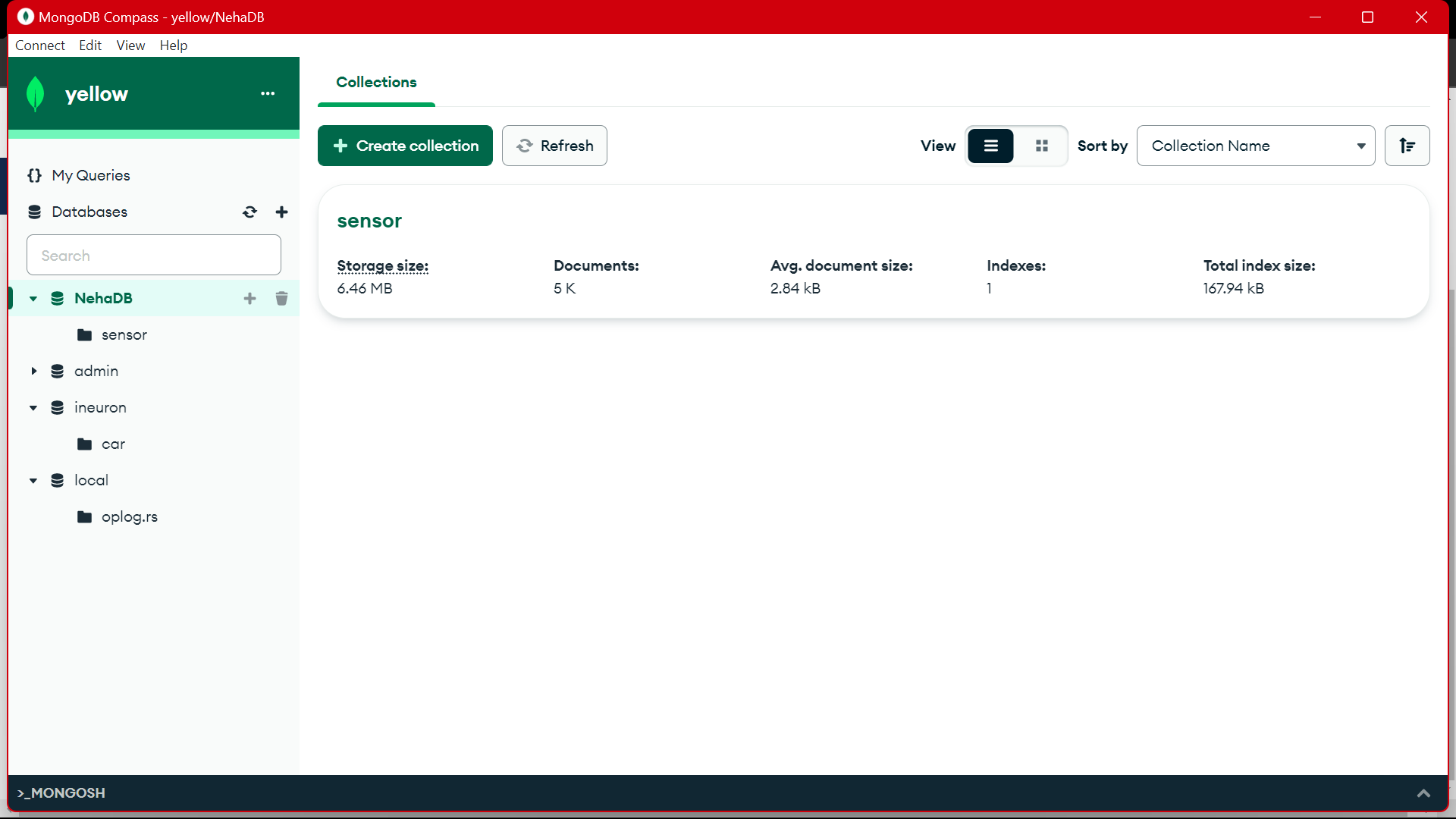
MongoDB'den bu verileri EDA'da ön işlemek için kullanıyoruz, bu veriler üzerinde özellik mühendisliği ve veri analitiği çalışmaları yapılıyor.
[Gömülü içerik]
Sonuç
Bu yazımızda sensörden gelen akış verilerini JSON formatında Kafka'ya nasıl saklayıp işleyeceğimizi ve ardından verileri MongoDB'ye nasıl depoladığımızı anlıyoruz. Akış verilerinin, sürekli bir işlem sırasında yüksek hacimde yayılan veriler olduğunu biliyoruz; bu, verilerin her saniye değiştiği anlamına gelir. Pipeline'da API yardımıyla verilerin getirilip Kafka'da konu şeklinde toplandığı ve ardından MongoDB'de saklandığı uçtan uca boru hattını oluşturduk, oradan projede kullanabiliriz veya bunu yapabiliriz. özellik mühendisliği.
Önemli Noktalar
- Akış verilerinin ne olduğunu ve akış verilerinin nasıl işleneceğini Kafka'nın yardımıyla öğrenin.
- Confluent Platformunu anlayın – Apache Kafka'nın kendi kendini yöneten, kurumsal düzeyde bir dağıtımı.
- Kafka tarafından toplanan verileri, yapılandırılmamış verileri saklayan bir NoSQL veritabanı olan MongoDB'de saklayın.
- Verileri Veritabanına getirmek ve depolamak için tamamen uçtan uca bir işlem hattı oluşturun.
- Projenin her bir bileşeninin işlevselliğini anlayın, bunu docker'da uygulayın ve istediğiniz zaman kullanmak üzere bir bulutta uygulayın.
Kaynaklar
Sık Sorulan Sorular
A. MongoDB, verileri yapılandırılmamış verilerde saklar. akış verileri, bellek kullanımı için yapılandırılmamış veri biçimleridir ve veritabanı olarak MongoDB'yi kullanıyoruz.
C. Amaç, Kafka konularına alınan verilerin daha fazla analiz, raporlama veya uygulama kullanımı için MongoDB'de tüketilebileceği, işlenebileceği ve depolanabileceği gerçek zamanlı bir veri işleme hattı oluşturmaktır.
C. Kullanım örnekleri arasında akış verilerinin daha fazla analiz veya uygulama kullanımı için işlenmesi ve saklanması gereken gerçek zamanlı analizler, IoT veri işleme, günlük toplama, sosyal medya izleme ve öneri sistemleri yer alır.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2024/02/kafka-to-mongodb-building-a-streamlined-data-pipeline/

