Yazara göre resim
Veri bilimi ve makine öğrenimi dünyasına daldığınızda karşılaşacağınız temel becerilerden biri veri okuma sanatıdır. Zaten bu konuda biraz deneyiminiz varsa, muhtemelen hem veri depolamak hem de veri alışverişi yapmak için kullanılan popüler bir format olan JSON'a (JavaScript Nesne Gösterimi) aşinasınızdır.
MongoDB gibi NoSQL veritabanlarının JSON'da veri depolamayı ne kadar sevdiğini veya REST API'lerinin sıklıkla aynı formatta yanıt verdiğini düşünün.
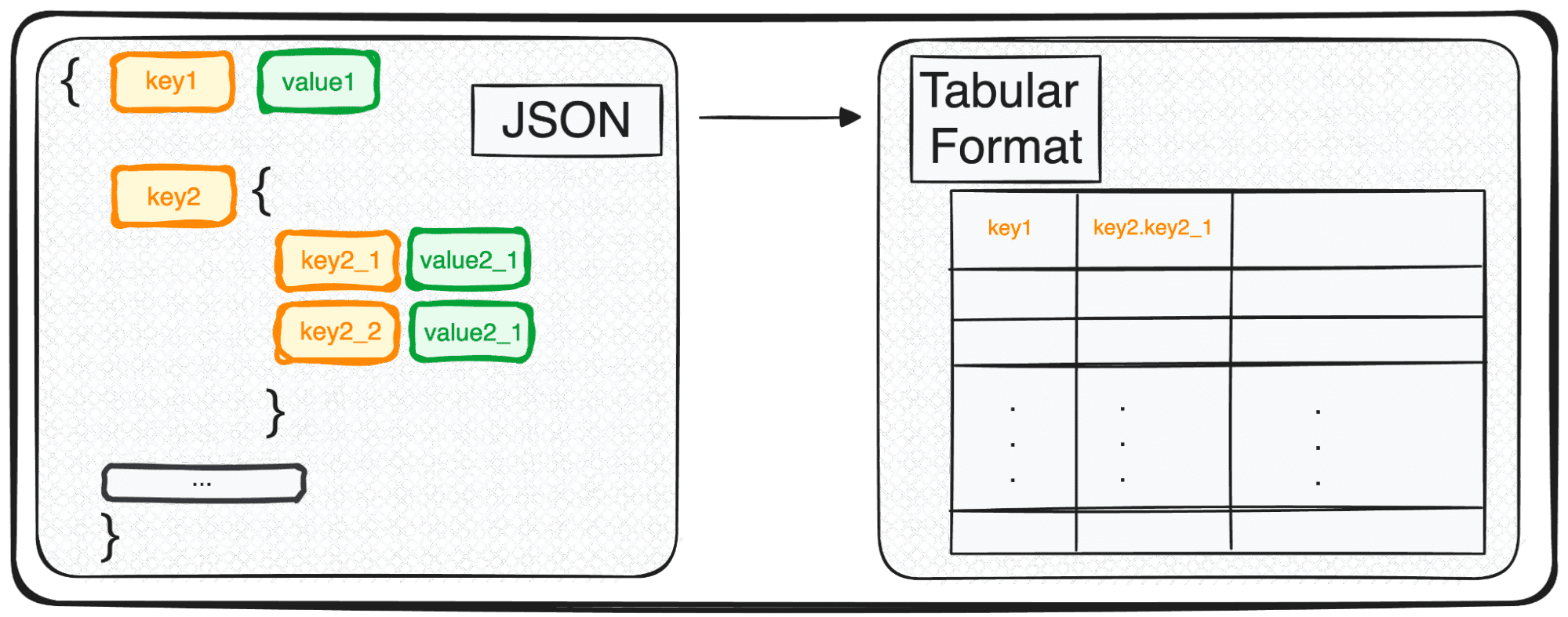
Ancak JSON, depolama ve değişim için mükemmel olsa da, ham haliyle derinlemesine analize tam olarak hazır değildir. Burası onu analitik açıdan daha kolay bir şeye, tablo formatına dönüştürdüğümüz yerdir.
Yani, ister tek bir JSON nesnesiyle, ister bunların hoş bir dizisiyle uğraşıyor olun, Python'un terimleriyle, aslında bir dikte veya bir dikim listesiyle uğraşıyorsunuz demektir.
Verilerimizi analize hazır hale getiren bu dönüşümün nasıl gerçekleştiğini birlikte keşfedelim ????
Bugün herhangi bir JSON'u saniyeler içinde tablo formatına kolayca ayrıştırmamızı sağlayan sihirli bir komutu açıklayacağım.
Ve bu… pd.json_normalize()
Şimdi bunun farklı JSON türleriyle nasıl çalıştığını görelim.
Çalışabileceğimiz ilk JSON türü, birkaç anahtar ve değere sahip tek düzeyli JSON'lardır. İlk basit JSON’larımızı şu şekilde tanımlıyoruz:
Yazara göre Kod
Öyleyse bu JSON'larla çalışma ihtiyacını simüle edelim. JSON formatlarında yapılacak pek bir şey olmadığını hepimiz biliyoruz. Bu JSON'ları okunabilir ve değiştirilebilir bir formata dönüştürmemiz gerekiyor… bu da Pandas DataFrames anlamına geliyor!
1.1 Basit JSON yapılarıyla ilgilenmek
Öncelikle pandas kütüphanesini içe aktarmamız gerekiyor ve ardından pd.json_normalize() komutunu aşağıdaki gibi kullanabiliriz:
import pandas as pd
pd.json_normalize(json_string)
Bu komutu tek kayıtlı bir JSON’a uygulayarak en temel tabloyu elde etmiş oluyoruz. Ancak verilerimiz biraz daha karmaşık olduğunda ve bir JSON listesi sunduğunda, yine de aynı komutu daha fazla komplikasyon olmadan kullanabiliriz ve çıktı, birden fazla kayıt içeren bir tabloya karşılık gelir.

Yazara göre resim
Kolay değil mi?
Bir sonraki doğal soru, bazı değerler eksik olduğunda ne olacağıdır.
1.2 Boş değerlerle uğraşmak
David'in Gelir kaydının eksik olması gibi bazı değerlerin bildirilmediğini düşünün. JSON'umuzu basit bir pandas veri çerçevesine dönüştürürken karşılık gelen değer NaN olarak görünecektir.

Yazara göre resim
Peki ya sadece bazı tarlaları almak istersem?
1.3 Yalnızca ilgilenilen sütunların seçilmesi
Sadece bazı belirli alanları tablolu panda DataFrame'e dönüştürmek istediğimizde, json_normalize() komutu hangi alanların dönüştürüleceğini seçmemize izin vermez.
Bu nedenle, yalnızca ilgilenilen sütunları filtrelediğimiz JSON'da küçük bir ön işleme gerçekleştirilmelidir.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
O halde daha gelişmiş bir JSON yapısına geçelim.
Çok seviyeli JSON'larla uğraşırken kendimizi farklı seviyelerde iç içe geçmiş JSON'larla buluyoruz. Prosedür öncekiyle aynı ancak bu durumda kaç seviyeyi dönüştürmek istediğimizi seçebiliyoruz. Varsayılan olarak komut her zaman tüm düzeyleri genişletecek ve iç içe geçmiş tüm düzeylerin birleştirilmiş adını içeren yeni sütunlar oluşturacaktır.
Yani aşağıdaki JSON'ları normalleştirirsek.
Yazara göre Kod
Alan becerileri altında 3 sütunlu aşağıdaki tabloyu elde ederiz:
- beceriler.python
- beceriler.SQL
- beceriler.GCP
ve alan rolleri altında 4 sütun
- roller.proje yöneticisi
- roller.veri mühendisi
- roller.veri bilimcisi
- roller.veri analisti

Yazara göre resim
Ancak, sadece en üst seviyemizi dönüştürmek istediğimizi hayal edin. Bunu, max_level parametresini özel olarak 0 (genişletmek istediğimiz max_level) olarak tanımlayarak yapabiliriz.
pd.json_normalize(mutliple_level_json_list, max_level = 0)
Bekleyen değerler, pandalarımız DataFrame içindeki JSON'lar içinde tutulacaktır.

Yazara göre resim
Bulabileceğimiz son durum, bir JSON alanı içinde iç içe geçmiş bir Listeye sahip olmaktır. Bu yüzden öncelikle kullanacağımız JSON'larımızı tanımlıyoruz.
Yazara göre Kod
Python'daki Pandaları kullanarak bu verileri etkili bir şekilde yönetebiliriz. pd.json_normalize() işlevi bu bağlamda özellikle faydalıdır. İç içe geçmiş liste de dahil olmak üzere JSON verilerini analize uygun yapılandırılmış bir formatta düzleştirebilir. Bu fonksiyon JSON verilerimize uygulandığında, alanlarının bir parçası olarak iç içe geçmiş listeyi içeren normalleştirilmiş bir tablo üretir.
Üstelik Pandalar bu süreci daha da iyileştirme olanağı sunuyor. pd.json_normalize() dosyasındaki Record_path parametresini kullanarak, işlevi özellikle iç içe geçmiş listeyi normalleştirmeye yönlendirebiliriz.
Bu eylem, listenin içeriğine özel olarak ayrılmış bir tabloyla sonuçlanır. Varsayılan olarak bu işlem yalnızca listedeki öğeleri açar. Ancak bu tabloyu, her kayıt için ilişkili bir kimliğin korunması gibi ek bağlamla zenginleştirmek için meta parametresini kullanabiliriz.

Yazara göre resim
Özetle JSON verilerinin Python'un Pandas kütüphanesini kullanarak CSV dosyalarına dönüştürülmesi kolay ve etkilidir.
JSON, modern veri depolama ve alışverişinde, özellikle de NoSQL veritabanlarında ve REST API'lerinde hâlâ en yaygın formattır. Ancak veriler ham formatta ele alınırken bazı önemli analitik zorluklar ortaya çıkar.
Pandas'ın pd.json_normalize() işlevinin önemli rolü, bu tür formatları işlemenin ve verilerimizi pandas DataFrame'e dönüştürmenin harika bir yolu olarak ortaya çıkıyor.
Umarım bu kılavuz faydalı olmuştur ve bir dahaki sefere JSON ile uğraştığınızda bunu daha etkili bir şekilde yapabilirsiniz.
İlgili Jupyter Notebook'u kontrol edebilirsiniz. GitHub deposunu takip ediyorum.
Josep Ferrer Barselona'dan bir analitik mühendisidir. Fizik mühendisliğinden mezun oldu ve şu anda insan hareketliliğine uygulanan Veri Bilimi alanında çalışıyor. Veri bilimi ve teknolojisine odaklanan yarı zamanlı bir içerik oluşturucudur. onunla iletişime geçebilirsin LinkedIn, Twitter or Orta.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way

