Bu yazıda öğreneceğiz GPT4All modelini yalnızca CPU bilgisayarınızda nasıl dağıtacağınız ve kullanacağınız (ben kullanıyorum Macbook Pro GPU'suz!)

GPT4All'ı Bilgisayarınızda Kullanın — Yazarın resmi
Bu yazıda yerel bilgisayarımıza GPT4All (güçlü bir LLM) kuracağız ve python ile belgelerimizle nasıl etkileşim kuracağımızı keşfedeceğiz. PDF'lerden veya çevrimiçi makalelerden oluşan bir koleksiyon, soru/yanıtlarımız için bilgi tabanı olacaktır.
itibaren resmi web sitesi GPT4All olarak tarif edilir kullanımı ücretsiz, yerel olarak çalışan, gizliliğe duyarlı bir sohbet robotu. GPU veya internet gerekmez.
GTP4All, eğitmek ve dağıtmak için bir ekosistemdir güçlü ve özelleştirilmiş çalışan büyük dil modelleri lokal olarak tüketici sınıfı CPU'larda.
GPT4All modelimiz, indirip GPT4All açık kaynaklı ekosistem yazılımına ekleyebileceğiniz 4 GB'lık bir dosyadır. Nomik AI yüksek kaliteli ve güvenli yazılım ekosistemlerini kolaylaştırarak, bireylerin ve kuruluşların kendi büyük dil modellerini yerel olarak zahmetsizce eğitmelerini ve uygulamalarını sağlama çabasını artırır.
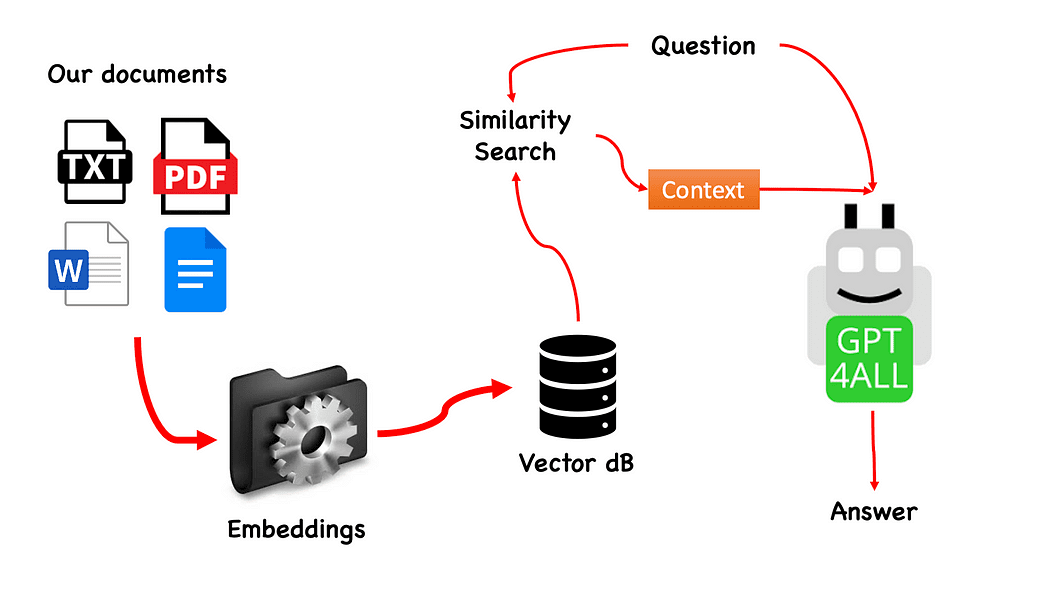
Yazar tarafından oluşturulan GPT4All ile QnA iş akışı
İşlem gerçekten basittir (bildiğiniz zaman) ve diğer modellerle de tekrarlanabilir. Adımlar aşağıdaki gibidir:
- GPT4All modelini yükleyin
- kullanım Uzun zincir belgelerimizi almak ve yüklemek için
- belgeleri Embeddings tarafından sindirilebilen küçük parçalara ayırın
- Gömülü vektör veritabanımızı oluşturmak için FAISS'ı kullanın
- GPT4All'a iletmek istediğimiz soruya göre vektör veri tabanımızda bir benzerlik araması (anlamsal arama) gerçekleştirin: bu, bağlam sorumuz için
- Soruyu ve bağlamı şununla GPT4All'a besleyin: Uzun zincir ve cevabı bekleyin.
Yani ihtiyacımız olan şey Gömmeler. Gömme, metin, belgeler, resimler, ses vb. gibi bir bilgi parçasının sayısal bir temsilidir. Temsil, gömülmekte olan şeyin anlamsal anlamını yakalar ve tam olarak ihtiyacımız olan şey budur. Bu proje için ağır GPU modellerine güvenemeyiz: bu nedenle Alpaca yerel modelini indirip şu adresten kullanacağız: Uzun zincir the LlamaCppGömmeler. Merak etme! Her şey adım adım anlatılıyor
Sanal Ortam Oluşturun
Yeni Python projeniz için yeni bir klasör oluşturun, örneğin GPT4ALL_Fabio (adınızı girin…):
mkdir GPT4ALL_Fabio
cd GPT4ALL_FabioArdından, yeni bir Python sanal ortamı oluşturun. Yüklü birden fazla python sürümünüz varsa, istediğiniz sürümü belirtin: bu durumda, python 3.10 ile ilişkili ana kurulumumu kullanacağım.
python3 -m venv .venvKomuta python3 -m venv .venv adlı yeni bir sanal ortam oluşturur. .venv (nokta, venv adlı gizli bir dizin oluşturacaktır).
Sanal ortam, sistem genelindeki Python kurulumunu veya diğer projeleri etkilemeden yalnızca belirli bir proje için paketleri ve bağımlılıkları kurmanıza izin veren yalıtılmış bir Python kurulumu sağlar. Bu yalıtım, tutarlılığın korunmasına ve farklı proje gereksinimleri arasındaki potansiyel çatışmaların önlenmesine yardımcı olur.
Sanal ortam oluşturulduktan sonra, aşağıdaki komutu kullanarak etkinleştirebilirsiniz:
source .venv/bin/activate 
Aktif sanal ortam
Kurulacak kütüphaneler
Kurduğumuz proje için çok fazla pakete ihtiyacımız yok. Sadece ihtiyacımız var:
- GPT4All için piton bağlamaları
- Belgelerimizle etkileşime geçmek için Langchain
LangChain, dil modelleri tarafından desteklenen uygulamalar geliştirmek için bir çerçevedir. Yalnızca bir API aracılığıyla bir dil modelini çağırmanıza değil, aynı zamanda bir dil modelini diğer veri kaynaklarına bağlamanıza ve bir dil modelinin çevresiyle etkileşime girmesine olanak tanır.
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4LangChain için versiyonu da belirttiğimizi görüyorsunuz. Bu kitaplık son zamanlarda çok sayıda güncelleme alıyor, bu nedenle kurulumumuzun yarın da çalışacağından emin olmak için düzgün çalıştığını bildiğimiz bir sürümü belirtmek daha iyidir. Yapılandırılmamış, pdf yükleyici için gerekli bir bağımlılıktır ve Pytesseract ve pdf2görüntü gibi.
NOT: GitHub deposunda bir gereklilikler.txt dosyası vardır (tarafından önerilen jl adcr) bu projeyle ilişkili tüm sürümlerle birlikte. Aşağıdaki komut ile ana proje dosya dizinine indirdikten sonra tek seferde kurulumu yapabilirsiniz:
pip install -r requirements.txtMakalenin sonunda bir oluşturdum sorun giderme bölümü. GitHub deposunda ayrıca tüm bu bilgileri içeren güncellenmiş bir READ.ME vardır.
unutmayın ki bazı kitaplıkların, python sürümüne bağlı olarak kullanılabilen sürümleri vardır sanal ortamınız üzerinde çalışıyorsunuz.
Modelleri PC'nize indirin
Bu gerçekten önemli bir adım.
Proje için kesinlikle GPT4All'a ihtiyacımız var. Nomic AI'da açıklanan süreç gerçekten karmaşık ve hepimizde olmayan (benim gibi) donanımlar gerektiriyor. Bu yüzden işte modelin linki zaten dönüştürülmüş ve kullanıma hazır. İndirmeye tıklamanız yeterli.

GPT4All modelini indirin
Giriş bölümünde kısaca açıklandığı gibi, gömmeler için de bir modele ihtiyacımız var, CPU'muzda ezmeden çalıştırabileceğimiz bir model. Tıkla alpaca-native-7B-ggml dosyasını indirmek için buraya bağlantı zaten 4-bit'e dönüştürüldü ve gömme için modelimiz olarak hareket etmeye hazır.
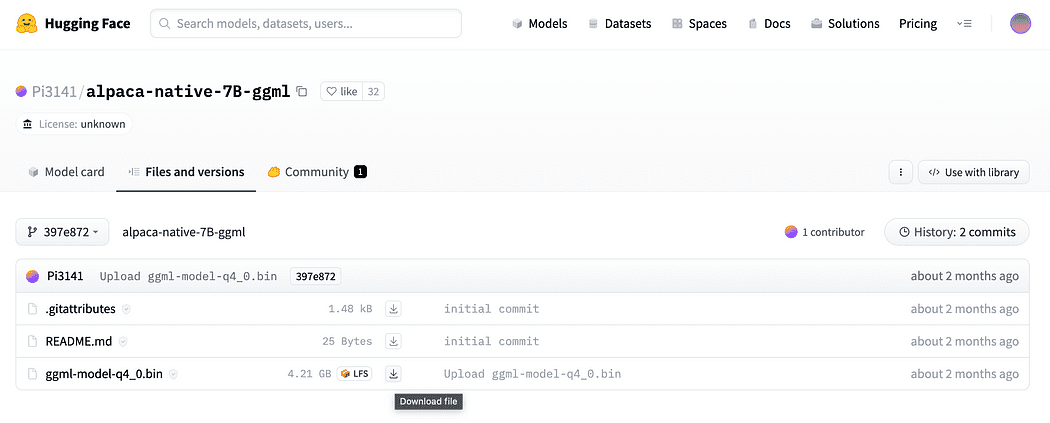
yanındaki indir okunu tıklayın. ggml-model-q4_0.bin
Neden gömmelere ihtiyacımız var? Akış şemasından hatırlarsanız, bilgi tabanımız için belgeleri topladıktan sonra gerekli olan ilk adım, gömmek onlara. Bu Alpaca modelindeki LLamaCPP yerleştirmeleri işe mükemmel bir şekilde uyuyor ve bu model de oldukça küçük (4 Gb). Bu arada soru-cevaplarınız için Alpaka modelini de kullanabilirsiniz!
2023.05.25 Güncellemesi: Mani Windows kullanıcıları, llamaCPP yerleştirmelerini kullanmakta sorunlar yaşıyor. Bunun başlıca nedeni, llama-cpp-python piton paketinin kurulumu sırasında:
pip install llama-cpp-pythonpip paketi, kütüphane kaynağından derlenecek. Windows genellikle makinede varsayılan olarak CMake veya C derleyicisine sahip değildir. Ama endişelenme, bir çözüm var
LangChain tarafından gerekli olan llamaEmbeddings ile llama-cpp-python kurulumunu Windows'ta çalıştırmak CMake C derleyicisi varsayılan olarak kurulu değildir, bu nedenle kaynaktan derleyemezsiniz.
Xtools ve Linux'a sahip Mac Kullanıcılarında, genellikle C derleyici işletim sisteminde zaten mevcuttur.
Sorundan kaçınmak için önceden uyumlu çarkı KULLANMALISINIZ.
Buraya git https://github.com/abetlen/llama-cpp-python/releases
ve mimariniz ve python sürümünüz için uyumlu çarkı arayın — Weels Sürüm 0.1.49'u almanız GEREKİR çünkü daha yüksek sürümler uyumlu değildir.
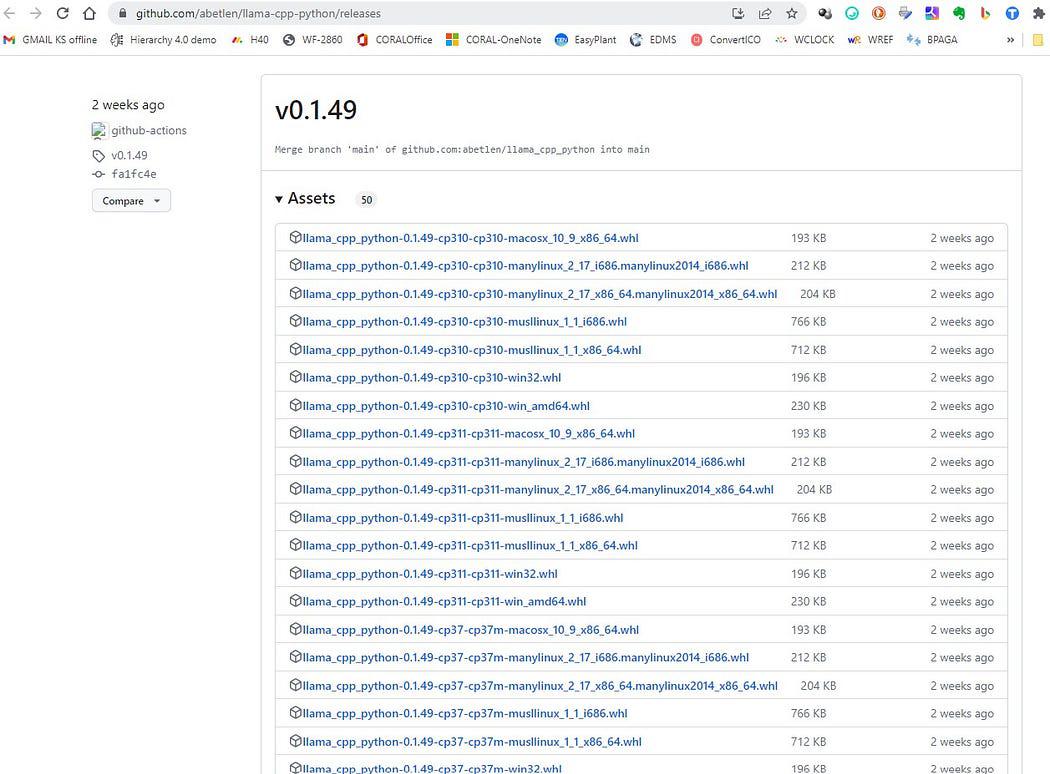
Ekran görüntüsü https://github.com/abetlen/llama-cpp-python/releases
Benim durumumda Windows 10, 64 bit, python 3.10 var
bu yüzden dosyam llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl
Bu sorun GitHub deposunda izleniyor
İndirdikten sonra, iki modeli aşağıda gösterildiği gibi modeller dizinine koymanız gerekir.

Dizin yapısı ve model dosyalarının nereye yerleştirileceği
GPT modeliyle olan etkileşimimizi kontrol etmek istediğimiz için, bir python dosyası oluşturmalıyız (buna bir python dosyası diyelim) pygpt4all_test.py), bağımlılıkları içe aktarın ve modele talimat verin. Bunun oldukça kolay olduğunu göreceksiniz.
from pygpt4all.models.gpt4all import GPT4AllBu, modelimiz için python bağlamasıdır. Şimdi onu arayabilir ve sormaya başlayabiliriz. Yaratıcı bir tane deneyelim.
Modelden geri aramayı okuyan bir fonksiyon oluşturuyoruz ve GPT4All'dan cümlemizi tamamlamasını istiyoruz.
def new_text_callback(text): print(text, end="") model = GPT4All('./models/gpt4all-converted.bin')
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)İlk ifade programımıza modeli nerede bulacağımızı söylüyor (yukarıdaki bölümde ne yaptığımızı hatırlayın)
İkinci ifade, modelden bir yanıt oluşturmasını ve "Bir zamanlar" istemimizi tamamlamasını istemektir.
Çalıştırmak için sanal ortamın hala etkin olduğundan emin olun ve şunu çalıştırın:
python3 pygpt4all_test.pyModelin yükleme metnini ve cümlenin tamamlanmasını görmelisiniz. Donanım kaynaklarınıza bağlı olarak biraz zaman alabilir.
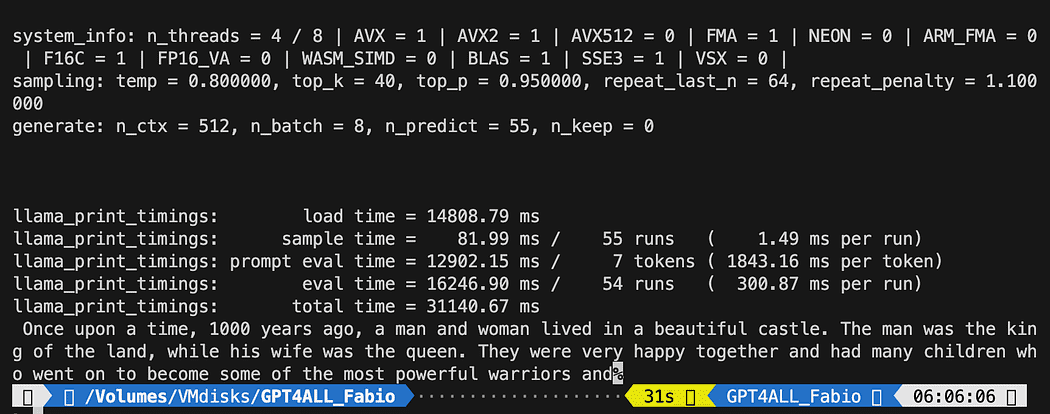
Sonuç sizinkinden farklı olabilir… Ama bizim için önemli olan çalışıyor olması ve LangChain ile bazı gelişmiş şeyler yaratmaya devam edebilmemiz.
NOT (güncellendi 2023.05.23): pygpt4all ile ilgili bir hatayla karşılaşırsanız, bu konudaki sorun giderme bölümünü, tarafından verilen çözümle kontrol edin. Rajneesh Aggarwal or Oscar Jeong tarafından.
LangChain çerçevesi gerçekten harika bir kütüphanedir. sağlar Bileşenler kullanımı kolay bir şekilde dil modelleriyle çalışmak ve aynı zamanda Zincirler. Zincirler, belirli bir kullanım durumunu en iyi şekilde gerçekleştirmek için bu bileşenleri belirli şekillerde bir araya getirmek olarak düşünülebilir. Bunların, insanların belirli bir kullanım durumuyla kolayca başlayabilecekleri daha üst düzey bir arayüz olması amaçlanmıştır. Bu zincirler ayrıca özelleştirilebilir olacak şekilde tasarlanmıştır.
Bir sonraki python testimizde bir Bilgi İstemi Şablonu. Dil modelleri metni girdi olarak alır - bu metne genellikle bilgi istemi denir. Tipik olarak bu, yalnızca sabit kodlanmış bir dize değil, bir şablonun, bazı örneklerin ve kullanıcı girişinin bir birleşimidir. LangChain, oluşturmayı ve istemlerle çalışmayı kolaylaştırmak için çeşitli sınıflar ve işlevler sağlar. Biz de nasıl yapabileceğimize bakalım.
Yeni bir python dosyası oluşturun ve onu arayın my_langchain.py
# Import of langchain Prompt Template and Chain
from langchain import PromptTemplate, LLMChain # Import llm to be able to interact with GPT4All directly from langchain
from langchain.llms import GPT4All # Callbacks manager is required for the response handling from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler local_path = './models/gpt4all-converted.bin' callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])GPT modelimiz ile doğrudan etkileşim kurabilmek için LangChain'den Prompt Template ve Chain ile GPT4All llm sınıfını içe aktardık.
Ardından, llm yolumuzu belirledikten sonra (daha önce yaptığımız gibi), sorgumuzun yanıtlarını yakalayabilmemiz için geri arama yöneticilerini başlatıyoruz.
Bir şablon oluşturmak gerçekten çok kolay: dokümantasyon eğitimi böyle bir şey kullanabiliriz…
template = """Question: {question} Answer: Let's think step by step on it. """
prompt = PromptTemplate(template=template, input_variables=["question"])The şablon değişken, modelle etkileşim yapımızı içeren çok satırlı bir dizedir: kaşlı ayraçlar içinde, harici değişkenleri şablona ekleriz, senaryomuzda bizim soru.
Bir değişken olduğundan, bunun sabit kodlanmış bir soru mu yoksa kullanıcı girişi sorusu mu olduğuna karar verebilirsiniz: işte iki örnek.
# Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User input question...
question = input("Enter your question: ")Test çalıştırmamız için, kullanıcı girişini yorumlayacağız. Şimdi sadece şablonumuzu, soruyu ve dil modelini birbirine bağlamamız gerekiyor.
template = """Question: {question}
Answer: Let's think step by step on it. """ prompt = PromptTemplate(template=template, input_variables=["question"]) # initialize the GPT4All instance
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True) # link the language model with our prompt template
llm_chain = LLMChain(prompt=prompt, llm=llm) # Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User imput question...
# question = input("Enter your question: ") #Run the query and get the results
llm_chain.run(question)Sanal ortamınızın hala etkin olduğunu doğrulamayı unutmayın ve şu komutu çalıştırın:
python3 my_langchain.pyBenimkinden farklı sonuçlar alabilirsiniz. Şaşırtıcı olan şey, GPT4All'ın sizin için bir yanıt bulmaya çalışırken izlediği tüm mantığı görebilmenizdir. Soruyu ayarlamak da size daha iyi sonuçlar verebilir.

GPT4All'da Bilgi İstemi Şablonlu Langchain
İşte harika kısma başlıyoruz, çünkü sorularımıza cevap veren bir chatbot olarak GPT4All'ı kullanarak belgelerimizle konuşacağız.
Adımların sırası, referans GPT4All ile Soru-Cevap İş Akışı, pdf dosyalarımızı yüklemek, onları parçalar haline getirmektir. Bundan sonra yerleştirmelerimiz için bir Vector Store'a ihtiyacımız olacak. Bilgi alımı için parçalanmış belgelerimizi bir vektör deposunda beslememiz gerekiyor ve ardından onları LLM sorgumuz için bir bağlam olarak bu veritabanındaki benzerlik aramasıyla birlikte gömeceğiz.
Bu amaçlar için FAISS'i doğrudan Uzun zincir kütüphane. FAISS, büyük yüksek boyutlu veri koleksiyonlarında benzer öğeleri hızlı bir şekilde bulmak için tasarlanmış, Facebook AI Research'ün açık kaynaklı bir kitaplığıdır. Bir veri kümesindeki en benzer öğeleri bulmayı daha kolay ve daha hızlı hale getirmek için dizin oluşturma ve arama yöntemleri sunar. basitleştirdiği için bizim için özellikle uygundur. bilgi alma ve oluşturulan veritabanını yerel olarak kaydetmemize izin verin: bu, ilk oluşturmadan sonra daha fazla kullanım için çok hızlı yükleneceği anlamına gelir.
vektör indeksi db'nin oluşturulması
Yeni bir dosya oluşturun ve arayın my_knowledge_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # function for loading only TXT files
from langchain.document_loaders import TextLoader # text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter # to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader # Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator # LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings # FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS import os #for interaaction with the files
import datetimeİlk kütüphaneler daha önce kullandığımızla aynı: ek olarak kullanıyoruz Uzun zincir vektör deposu dizini oluşturma için, LlamaCppGömmeler Alpaca modelimiz (4-bit olarak nicelenmiş ve cpp kitaplığı ile derlenmiş) ve PDF yükleyici ile etkileşim için.
LLM'lerimizi de kendi yollarıyla yükleyelim: biri yerleştirmeler için, diğeri metin oluşturma için.
# assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)Test için tüm pfd dosyalarını okuyup okumadığımıza bakalım: ilk adım, her bir belgede kullanılacak 3 işlevi bildirmektir. Birincisi, çıkarılan metni parçalara bölmek, ikincisi metadata ile vektör dizini oluşturmak (sayfa numaraları vb… gibi) ve sonuncusu benzerlik aramasını test etmek içindir (daha sonra daha iyi açıklayacağım).
# Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sourcesArtık belgeler için dizin oluşturmayı test edebiliriz. docs dizin: tüm pdf'lerimizi oraya koymamız gerekiyor. Uzun zincir dosya türünden bağımsız olarak tüm klasörü yüklemek için bir yöntemi de vardır: son işlem karmaşık olduğundan, LaMini modelleri hakkındaki bir sonraki makalede ele alacağım.

belgelerim dizini 4 pdf dosyası içeriyor
Fonksiyonlarımızı listedeki ilk belgeye uygulayacağız.
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# load the documents with Langchain
docs = loader.load()
# Split in chunks
chunks = split_chunks(docs)
# create the db vector index
db0 = create_index(chunks)İlk satırlarda os kütüphanesini kullanıyoruz. pdf dosyalarının listesi dokümanlar dizini içinde. Daha sonra ilk belgeyi yüklüyoruz (doc_list[0]) ile dokümanlar klasöründen Uzun zincir, parçalara ayırıyoruz ve ardından vektör veritabanını şu şekilde oluşturuyoruz: Lama yerleştirmeler.
Gördüğünüz gibi kullanıyoruz pyPDF yöntemi. Dosyaları birer birer yüklemeniz gerektiğinden, ancak PDF'yi kullanarak yüklemeniz gerektiğinden, bunun kullanımı biraz daha uzundur. pypdf Belge dizisine, her belgenin sayfa içeriğini ve meta verileri içerdiği bir diziye sahip olmanızı sağlar. page sayı. Bu, sorgumuzla GPT4All'a vereceğimiz bağlamın kaynaklarını bilmek istediğinizde gerçekten kullanışlıdır. İşte readthedocs'tan örnek:
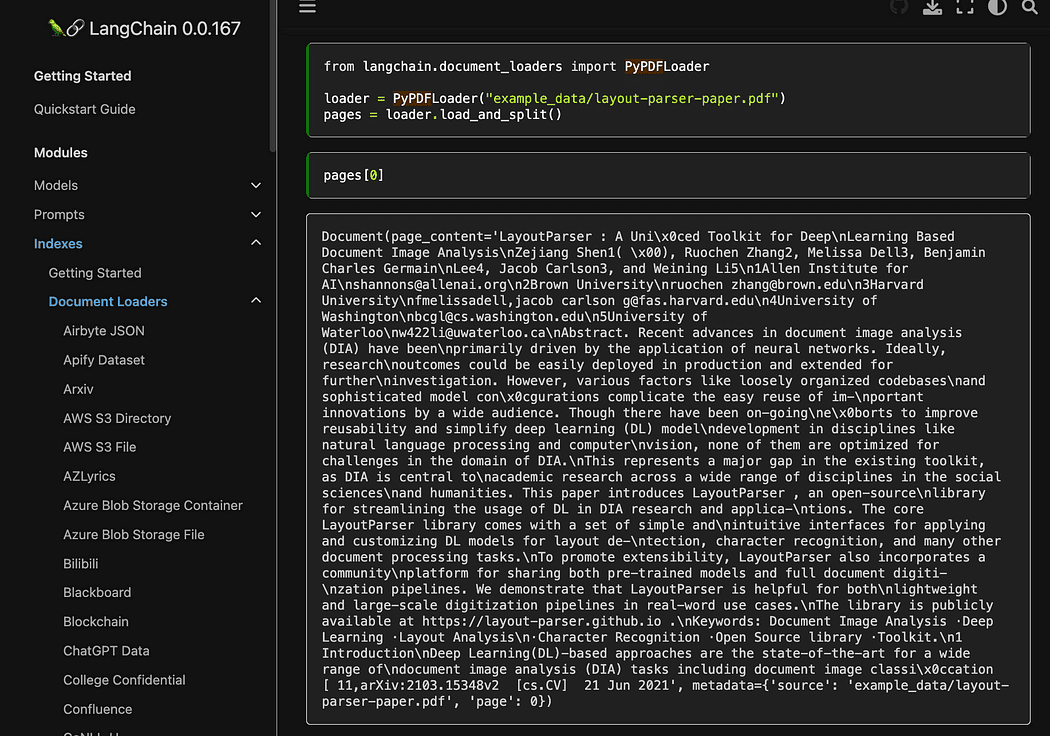
Ekran görüntüsü Langchain belgeleri
Python dosyasını terminalden şu komutla çalıştırabiliriz:
python3 my_knowledge_qna.pyGömmeler için modelin yüklenmesinden sonra belirteçlerin indeksleme için iş başında olduğunu göreceksiniz: özellikle benim gibi sadece CPU ile çalışıyorsanız (8 dakika sürdü) zaman alacağından korkmayın.
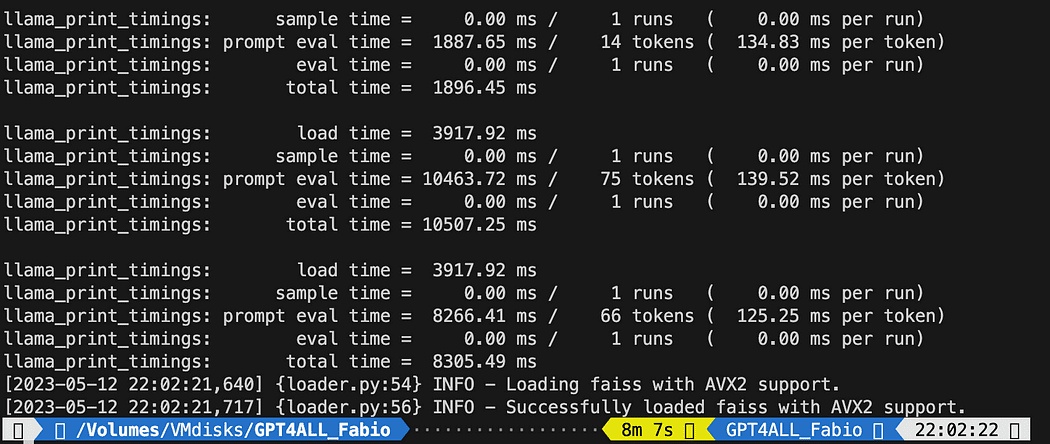
İlk vektör db'nin tamamlanması
Açıkladığım gibi, pyPDF yöntemi daha yavaştır ancak benzerlik araştırması için bize ek veriler sağlar. Tüm dosyalarımızı tekrarlamak için FAISS'tan farklı veritabanlarını BİRLEŞTİRMEmize izin veren uygun bir yöntem kullanacağız. Şimdi yaptığımız şey, ilk db'yi oluşturmak için yukarıdaki kodu kullanmak. db0) ve bir for döngüsü ile listedeki bir sonraki dosyanın dizinini oluşturur ve hemen birleştiririz db0.
İşte kod: kullanarak ilerlemenin durumunu size vermek için bazı günlükler eklediğimi unutmayın. tarihsaat.tarihsaat.şimdi() ve işlemin ne kadar sürdüğünü hesaplamak için bitiş zamanı ve başlangıç zamanı deltasını yazdırmak (beğenmediyseniz kaldırabilirsiniz).
Birleştirme talimatları böyle
# merge dbi with the existing db0
db0.merge_from(dbi)Son talimatlardan biri, veritabanımızı yerel olarak kaydetmek içindir: tüm nesil bile saatler alabilir (ne kadar belgeniz olduğuna bağlı olarak), bu yüzden bunu yalnızca bir kez yapmamız gerçekten iyi!
# Save the databasae locally
db0.save_local("my_faiss_index")İşte tüm kod. Dizini doğrudan klasörümüzden yükleyen GPT4All ile etkileşimde bulunduğumuzda birçok bölümünü yorumlayacağız.
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
general_start = datetime.datetime.now() #not used now but useful
print("starting the loop...")
loop_start = datetime.datetime.now() #not used now but useful
print("generating fist vector database and then iterate with .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Main Vector database created. Start iteration and merging...")
for i in range(1,num_of_docs): print(doc_list[i]) print(f"loop position {i}") loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i])) start = datetime.datetime.now() #not used now but useful docs = loader.load() chunks = split_chunks(docs) dbi = create_index(chunks) print("start merging with db0...") db0.merge_from(dbi) end = datetime.datetime.now() #not used now but useful elapsed = end - start #not used now but useful #total time print(f"completed in {elapsed}") print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now but useful
loop_elapsed = loop_end - loop_start #not used now but useful
print(f"All documents processed in {loop_elapsed}")
print(f"the daatabase is done with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging completed")
print("-----------------------------------")
print("Saving Merged Database Locally")
# Save the databasae locally
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now but useful
general_elapsed = general_end - general_start #not used now but useful
print(f"All indexing completed in {general_elapsed}")
print("-----------------------------------")  Python dosyasını çalıştırmak 22 dakika sürdü
Python dosyasını çalıştırmak 22 dakika sürdü
GPT4All'a belgeleriniz hakkında sorular sorun
Şimdi buradayız. Dizinimiz var, onu yükleyebiliriz ve bir Bilgi İstemi Şablonu ile GPT4All'dan sorularımızı yanıtlamasını isteyebiliriz. Sabit kodlanmış bir soruyla başlıyoruz ve ardından girdi sorularımız arasında dolaşacağız.
Aşağıdaki kodu bir python dosyasının içine koyun db_loading.py ve terminalden gelen komutla çalıştırın python3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime # TEST FOR SIMILARITY SEARCH # assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True) # Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources # Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded question
query = "What is a PLC and what is the difference with a PC"
docs = index.similarity_search(query)
# Get the matches best 3 results - defined in the function k=3
print(f"The question is: {query}")
print("Here the result of the semantic search on the index, without GPT4All..")
print(docs[0])Basılı metin, bize belge adını ve sayfa numarasını da veren, sorguyla en iyi eşleşen 3 kaynağın listesidir.
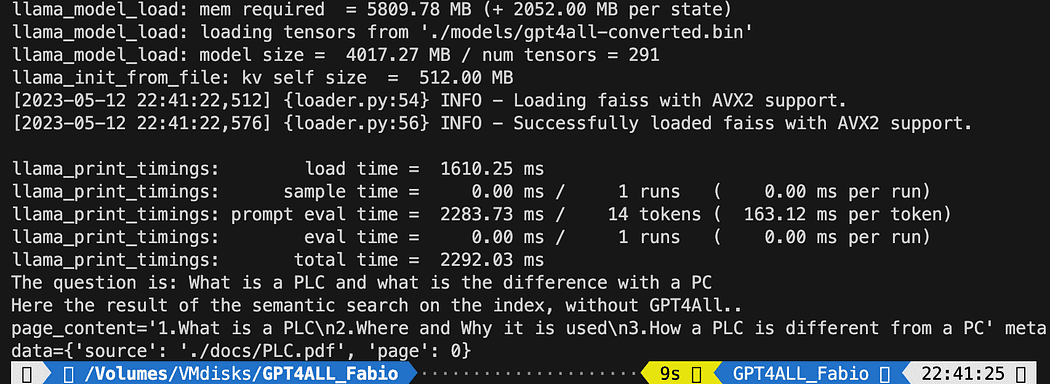
Dosyayı çalıştıran semantik aramanın sonuçları db_loading.py
Artık bilgi istemi şablonunu kullanarak benzerlik aramasını sorgumuzun bağlamı olarak kullanabiliriz. 3 işlevden sonra tüm kodu aşağıdakiyle değiştirin:
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings) # create the prompt template
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step.""" # Hardcoded question
question = "What is a PLC and what is the difference with a PC"
matched_docs, sources = similarity_search(question, index)
# Creating the context
context = "n".join([doc.page_content for doc in matched_docs])
# instantiating the prompt template and the GPT4All chain
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Print the result
print(llm_chain.run(question))Çalıştırdıktan sonra böyle bir sonuç alacaksınız (ama değişebilir). İnanılmaz hayır!?!?
Please use the following context to answer questions.
Context: 1.What is a PLC
2.Where and Why it is used
3.How a PLC is different from a PC
PLC is especially important in industries where safety and reliability are
critical, such as manufacturing plants, chemical plants, and power plants.
How a PLC is different from a PC
Because a PLC is a specialized computer used in industrial and
manufacturing applications to control machinery and processes.,the
hardware components of a typical PLC must be able to interact with
industrial device. So a typical PLC hardware include:
---
Question: What is a PLC and what is the difference with a PC
Answer: Let's think step by step. 1) A Programmable Logic Controller (PLC), also called Industrial Control System or ICS, refers to an industrial computer that controls various automated processes such as manufacturing machines/assembly lines etcetera through sensors and actuators connected with it via inputs & outputs. It is a form of digital computers which has the ability for multiple instruction execution (MIE), built-in memory registers used by software routines, Input Output interface cards(IOC) to communicate with other devices electronically/digitally over networks or buses etcetera
2). A Programmable Logic Controller is widely utilized in industrial automation as it has the ability for more than one instruction execution. It can perform tasks automatically and programmed instructions, which allows it to carry out complex operations that are beyond a Personal Computer (PC) capacity. So an ICS/PLC contains built-in memory registers used by software routines or firmware codes etcetera but PC doesn't contain them so they need external interfaces such as hard disks drives(HDD), USB ports, serial and parallel communication protocols to store data for further analysis or report generation.Satırı değiştirmek için bir kullanıcı girişi sorusu istiyorsanız
question = "What is a PLC and what is the difference with a PC"bunun gibi bir şeyle:
question = input("Your question: ")Deney yapmanın zamanı geldi. Belgelerinizle ilgili tüm konularda farklı sorular sorun ve sonuçları görün. Kesinlikle bilgi istemi ve şablonda iyileştirme için büyük bir alan var: bir göz atabilirsiniz bazı ilhamlar için burada. Ancak Uzun zincir belgeler gerçekten harika (onu takip edebilirim!!).
Kodu makaleden takip edebilir veya üzerinde kontrol edebilirsiniz. benim github depom.
Fabio Matricardi bir eğitimci, öğretmen, mühendis ve öğrenme meraklısı. 15 yıldır genç öğrencilere ders veriyor ve şimdi Key Solution Srl'de yeni çalışanları eğitiyor. Kariyerime 2010 yılında Endüstriyel Otomasyon Mühendisi olarak başladı. Gençliğinden beri programlama konusunda tutkuluydu, bir şeyleri hayata geçirmek için yazılım ve İnsan Makine Arayüzleri geliştirmenin güzelliğini keşfetti. Öğretmek ve koçluk yapmak, güncel yönetim becerileriyle nasıl tutkulu bir lider olunacağını öğrenmek ve çalışmak kadar günlük rutinimin bir parçasıdır. Tüm mühendislik yaşam döngüsü boyunca Makine Öğrenimi ve Yapay Zeka kullanarak daha iyi bir tasarıma, tahmine dayalı bir sistem entegrasyonuna giden yolculukta bana katılın.
orijinal. İzinle yeniden yayınlandı.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- EVM Finans. Merkezi Olmayan Finans için Birleşik Arayüz. Buradan Erişin.
- Kuantum Medya Grubu. IR/PR Güçlendirilmiş. Buradan Erişin.
- PlatoAiStream. Web3 Veri Zekası. Bilgi Genişletildi. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/2023/06/gpt4all-local-chatgpt-documents-free.html?utm_source=rss&utm_medium=rss&utm_campaign=gpt4all-is-the-local-chatgpt-for-your-documents-and-it-is-free

