Giriş
Birkaç ay önce, Office People'da ilk çalışmaya başladığımda Dil Modellerine, özellikle Word2Vec'e ilgi duymaya başladım. Yerel bir Python kullanıcısı olarak, doğal olarak Gensim'in Word2Vec uygulamasına odaklandım ve çevrimiçi makaleler ve öğreticiler aradım. Herhangi bir iyi veri bilimcinin yapacağı gibi, birden çok kaynaktan kod parçacıklarını doğrudan uyguladım ve çoğalttım. Stackoverflow görüşmelerini, Gensim'in Google Gruplarını ve kitaplığın belgelerini okuyarak yöntemimde neyin yanlış gittiğini anlamaya çalışmak için daha fazla ve daha derine indim.

Ancak, her zaman bir yaratmanın en önemli yönlerinden birinin olduğunu düşünmüşümdür. Word2Vec modeli eksikti. Deneylerim sırasında, cümleleri lemmatize etmenin veya onlarda tamlama/bigram aramanın modellerimin sonuçları ve performansı üzerinde önemli bir etkisi olduğunu keşfettim. Ön işlemenin etkisi veri kümesine ve uygulamaya bağlı olarak değişse de, bu makaleye veri hazırlama adımlarını dahil etmeye ve harika olanı kullanmaya karar verdim. spaCy kütüphanesi yanında.
Bu konulardan bazıları beni rahatsız ediyor, bu yüzden kendi makalemi yazmaya karar verdim. Word2Vec'i uygulamanın mükemmel veya en iyi yolu olduğuna söz vermiyorum, sadece orada olanların çoğundan daha iyi.
Öğrenme hedefleri
- Kelime yerleştirmelerini ve anlamsal ilişkileri yakalamadaki rollerini anlayın.
- Gensim veya TensorFlow gibi popüler kitaplıkları kullanarak Word2Vec modellerini uygulayın.
- Word2Vec yerleştirmelerini kullanarak kelime benzerliğini ölçün ve mesafeleri hesaplayın.
- Word2Vec tarafından yakalanan sözcük analojilerini ve anlamsal ilişkileri keşfedin.
- Duygu analizi ve makine çevirisi gibi çeşitli NLP görevlerinde Word2Vec'i uygulayın.
- Belirli görevler veya etki alanları için Word2Vec modellerinde ince ayar yapma tekniklerini öğrenin.
- Alt kelime bilgilerini veya önceden eğitilmiş yerleştirmeleri kullanarak kelime dağarcığı dışındaki kelimeleri ele alın.
- Word2Vec'in kelime anlamı belirsizliğini giderme ve cümle düzeyinde semantik gibi sınırlamalarını ve değiş tokuşlarını anlayın.
- Word2Vec ile alt kelime yerleştirme ve model optimizasyonu gibi ileri düzey konulara dalın.
Bu makale, Veri Bilimi Blogatonu.
İçindekiler
Word2Vec Hakkında Kısa Bilgi
Bir Google araştırma ekibi, Word2Vec'i Eylül ve Ekim 2013 arasında iki makale halinde tanıttı. Araştırmacılar ayrıca makalelerin yanı sıra kendi C uygulamalarını da yayınladılar. Gensim, ilk makaleden kısa bir süre sonra Python uygulamasını tamamladı.
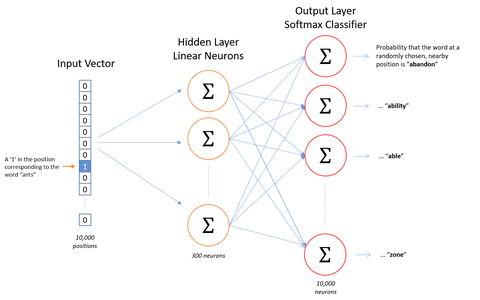
Word2Vec'in altında yatan varsayım, benzer bağlamlara sahip iki kelimenin benzer anlamlara sahip olduğu ve sonuç olarak modelden benzer bir vektör temsilinin olduğudur. Örneğin, "köpek", "köpek yavrusu" ve "köpek yavrusu", "iyi", "kabarık" veya "sevimli" gibi benzer çevreleyen kelimelerle benzer bağlamlarda sıklıkla kullanılır ve bu nedenle Word2Vec'e göre benzer bir vektör temsiline sahiptir.
Bu varsayıma dayanarak, Word2Vec, bir metindeki sözcükler arasındaki ilişkileri keşfetmek için kullanılabilir. veri kümesi, benzerliklerini hesaplayın veya bu kelimelerin vektör temsilini metin sınıflandırması veya kümeleme gibi diğer uygulamalar için girdi olarak kullanın.
Word2vec'in uygulanması
Word2Vec'in arkasındaki fikir oldukça basit. Bir kelimenin anlamının, tuttuğu şirket tarafından çıkarılabileceği varsayımında bulunuyoruz. Bu, “Bana arkadaşlarını göster, sana kim olduğunu söyleyeyim” sözüne benzer. İşte bir word2vec uygulaması.
Ortamın Ayarlanması
piton==3.6.3
Kullanılan kütüphaneler:
- xlrd==1.1.0:
- spaCy==2.0.12:
- gensim==3.4.0:
- scikit-learn==0.19.1:
- denizde doğan==0.8:
import re # For preprocessing
import pandas as pd # For data handling
from time import time # To time our operations
from collections import defaultdict # For word frequency import spacy # For preprocessing import logging # Setting up the loggings to monitor gensim
logging.basicConfig(format="%(levelname)s - %(asctime)s: %(message)s", datefmt= '%H:%M:%S', level=logging.INFO)Veri kümesi
Bu veri kümesi, 600'a kadar uzanan 1989'den fazla Simpsons bölümü için karakterler, konumlar, bölüm ayrıntıları ve senaryo satırları hakkında bilgiler içerir. Kaggle. (~25MB)
Ön İşleme
Ön işleme yapılırken, bir veri kümesinden yalnızca iki sütun tutulacaktır, bunlar ham_karakter_metni ve sözlü_kelimelerdir.
- raw_character_text: konuşan karakter (ön işleme adımlarını izlemek için kullanışlıdır).
- konuşulan_kelimeler: diyalog satırındaki ham metin
Kendi ön işlememizi yapmak istediğimiz için normalleştirilmiş_metni tutmuyoruz.
df = pd.read_csv('../input/simpsons_dataset.csv')
df.shape
df.head()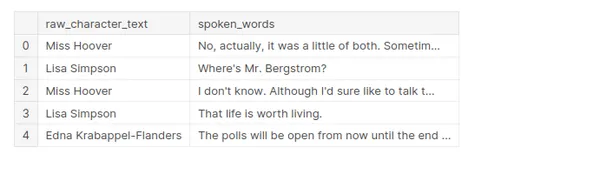
Eksik değerler, betiğin bir şeyin olduğu ancak diyalogun olmadığı bir bölümündendir. “(Springfield İlköğretim Okulu: HARİCİ İLKOKUL – OKUL OYUN GRUBU – ÖĞLEDEN SONRA)” bir örnektir.
df.isnull().sum()
Temizlik
Her diyalog satırı için, yasak sözcükleri ve alfabetik olmayan karakterleri lemmatize ediyor ve kaldırıyoruz.
nlp = spacy.load('en', disable=['ner', 'parser']) def cleaning(doc): # Lemmatizes and removes stopwords # doc needs to be a spacy Doc object txt = [token.lemma_ for token in doc if not token.is_stop] if len(txt) > 2: return ' '.join(txt)Alfabetik olmayan karakterleri kaldırır:
brief_cleaning = (re.sub("[^A-Za-z']+", ' ', str(row)).lower() for row in df['spoken_words'])Temizleme işlemini hızlandırmak için spaCy.pipe() niteliğini kullanma:
t = time() txt = [cleaning(doc) for doc in nlp.pipe(brief_cleaning, batch_size=5000, n_threads=-1)] print('Time to clean up everything: {} mins'.format(round((time() - t) / 60, 2)))

Eksik değerleri ve kopyaları kaldırmak için sonuçları bir DataFrame'e yerleştirin:
df_clean = pd.DataFrame({'clean': txt})
df_clean = df_clean.dropna().drop_duplicates()
df_clean.shape

Bigramlar
Bigramlar, doğal dil işleme ve metin çözümlemede kullanılan bir kavramdır. Bir metin dizisinde görünen ardışık kelime veya karakter çiftlerine atıfta bulunurlar. Bigramları analiz ederek, belirli bir metindeki kelimeler veya karakterler arasındaki ilişkiler hakkında fikir edinebiliriz.
Örnek bir cümle ele alalım: “Dondurmayı severim”. Bu cümledeki bigramları belirlemek için ardışık kelime çiftlerine bakarız:
"Seviyorum"
“Buzu seviyorum”
"dondurma"
Bu çiftlerin her biri bir bigramı temsil eder. Bigramlar, çeşitli dil işleme görevlerinde faydalı olabilir. Örneğin, dil modellemede, bir cümledeki bir sonraki kelimeyi önceki kelimeye göre tahmin etmek için bigramları kullanabiliriz.
Bigramlar, trigramlar (ardışık üçlüler) veya n-gramlar (n kelime veya karakterin ardışık dizileri) adı verilen daha büyük dizilere genişletilebilir. n'nin seçimi, belirli analize veya eldeki göreve bağlıdır.
Gensim Phrases paketi, ortak cümleleri (bigramları) bir cümle listesinden otomatik olarak tespit etmek için kullanılıyor. https://radimrehurek.com/gensim/models/phrases.html
Bunu öncelikle "mr_burns" ve "bart_simpson" gibi kelimeleri yakalamak için yapıyoruz!
from gensim.models.phrases import Phrases, Phraser
sent = [row.split() for row in df_clean['clean']]Aşağıdaki ifadeler, cümle listesinden oluşturulur:
phrases = Phrases(sent, min_count=30, progress_per=10000)
Phraser()'ın amacı, bigram algılama görevi için kesinlikle gerekli olmayan model durumunu atarak Phrases() bellek tüketimini azaltmaktır:
bigram = Phraser(phrases)
Tespit edilen bigramlara dayalı olarak külliyatı dönüştürün:
sentences = bigram[sent]En Sık Kullanılan Kelimeler
Çoğunlukla lemmatizasyonun, yasak kelime kaldırmanın ve bigram eklemenin etkinliğine ilişkin bir akıl sağlığı kontrolü.
word_freq = defaultdict(int)
for sent in sentences: for i in sent: word_freq[i] += 1
len(word_freq)

sorted(word_freq, key=word_freq.get, reverse=True)[:10]
Modelin Eğitimini 3 Adıma Ayırın
Netlik ve izleme için eğitimi üç farklı adıma bölmeyi tercih ediyorum.
- Word2Vec():
- Bu ilk adımda, modelin parametrelerini tek tek ayarlıyorum.
- Parametre cümlelerini sağlamayarak modeli kasıtlı olarak başlatılmamış halde bırakıyorum.
- build_vocab():
- Bir dizi cümleden sözcük dağarcığı oluşturarak modeli başlatır.
- Günlükleri kullanarak ilerlemeyi ve daha da önemlisi, min_count ve sample'ın word corpus üzerindeki etkisini takip edebilirim. Bu iki parametrenin, özellikle numunenin, model performansı üzerinde önemli bir etkisi olduğunu keşfettim. Her ikisinin de gösterilmesi, etkilerinin daha doğru ve basit bir şekilde yönetilmesini sağlar.
- .tren():
- Son olarak model eğitilir.
- Bu sayfadaki günlükler çoğunlukla yararlıdır.
import multiprocessing from gensim.models import Word2Vec cores = multiprocessing.cpu_count() # Count the number of cores in a computer w2v_model = Word2Vec(min_count=20, window=2, size=300, sample=6e-5, alpha=0.03, min_alpha=0.0007, negative=20, workers=cores-1)word2vec'in gensim uygulaması: https://radimrehurek.com/gensim/models/word2vec.html
Kelime Tablosunu Oluşturma
Word2Vec, kelime tablosu oluşturmamızı gerektirir (tüm kelimeleri sindirerek, benzersiz kelimeleri filtreleyerek ve bunlar üzerinde bazı temel hesaplamalar yaparak):
t = time() w2v_model.build_vocab(sentences, progress_per=10000) print('Time to build vocab: {} mins'.format(round((time() - t) / 60, 2))) 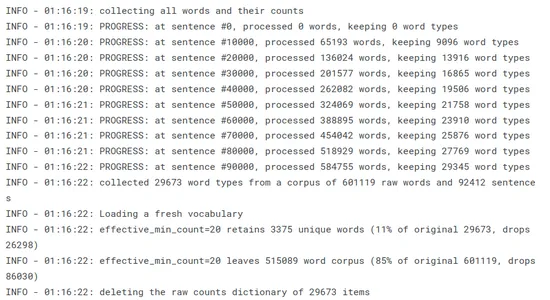
Kelime tablosu, kelimeleri indeksler olarak kodlamak ve eğitim veya çıkarım sırasında karşılık gelen kelime yerleştirmelerine bakmak için çok önemlidir. Word2Vec modellerini eğitmek için temel oluşturur ve sürekli vektör uzayında verimli kelime gösterimi sağlar.
Modelin Eğitimi
Bir Word2Vec modelini eğitmek, algoritmaya bir metin verisi külliyatı beslemeyi ve kelime gömmelerini öğrenmek için modelin parametrelerini optimize etmeyi içerir. Word2Vec için eğitim parametreleri, eğitim sürecini ve sonuçta ortaya çıkan kelime gömmelerinin kalitesini etkileyen çeşitli hiperparametreleri ve ayarları içerir. Word2Vec için yaygın olarak kullanılan bazı eğitim parametreleri şunlardır:
- total_examples = int – Cümle sayısı;
- dönemler = int – Derlem üzerindeki yinelemelerin (dönemlerin) sayısı – [10, 20, 30]
t = time() w2v_model.train(sentences, total_examples=w2v_model.corpus_count, epochs=30, report_delay=1) print('Time to train the model: {} mins'.format(round((time() - t) / 60, 2)))
Modeli daha fazla eğitme niyetinde olmadığımız için, modeli bellek açısından çok daha verimli hale getirmek için init_sims()'i çağırıyoruz:
w2v_model.init_sims(replace=True)
Bu parametreler, bağlam penceresi boyutu, sık ve nadir sözcükler arasındaki değiş tokuş, öğrenme oranı, eğitim algoritması ve negatif örnekleme için negatif örneklerin sayısı gibi hususları kontrol eder. Bu parametreleri ayarlamak, Word2Vec eğitim sürecinin kalitesini, verimliliğini ve bellek gereksinimlerini etkileyebilir.
Modeli Keşfetmek
Bir Word2Vec modeli eğitildikten sonra, öğrenilen kelime yerleştirmeleri hakkında fikir edinmek ve yararlı bilgiler elde etmek için onu keşfedebilirsiniz. Word2Vec modelini keşfetmenin bazı yolları şunlardır:
En çok benzeyen
Word2Vec'te, öğrenilen kelime yerleştirmelerine dayalı olarak belirli bir kelimeye en çok benzeyen kelimeleri bulabilirsiniz. Benzerlik tipik olarak kosinüs benzerliği kullanılarak hesaplanır. Word2Vec kullanarak bir hedef kelimeye en çok benzeyen kelimeleri bulmanın bir örneğini burada bulabilirsiniz:
Bakalım dizinin ana karakteri için ne elde edeceğiz:
similar_words = w2v_model.wv.most_similar(positive=["homer"])
for word, similarity in similar_words: print(f"{word}: {similarity}")
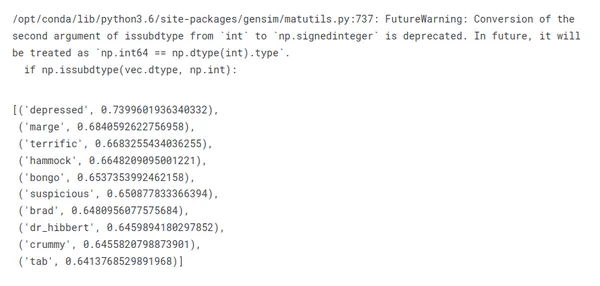
Açık olmak gerekirse, "homer" kelimesine en çok benzeyen kelimelere baktığımızda, onun aile üyelerini, kişilik özelliklerini ve hatta en akılda kalan sözlerini anlamamız gerekmez.
Bunu "homer_simpson" bigramının döndürdüğü şeyle karşılaştırın:
w2v_model.wv.most_similar(positive=["homer_simpson"])
Peki ya şimdi Marge?
w2v_model.wv.most_similar(positive=["marge"])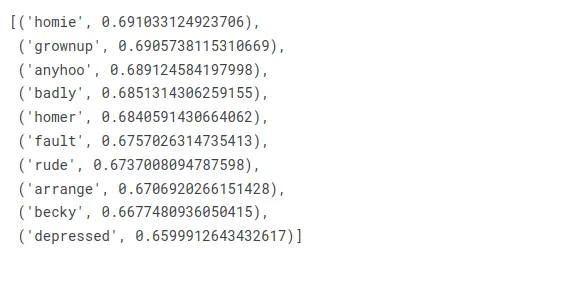
Şimdi Bart'ı kontrol edelim:
w2v_model.wv.most_similar(positive=["bart"])
Mantıklı görünüyor!
Benzerlikler
Word2Vec kullanarak iki kelime arasındaki kosinüs benzerliğini bulmanın bir örneğini burada bulabilirsiniz:
Örnek: İki kelime arasındaki kosinüs benzerliğinin hesaplanması.
w2v_model.wv.similarity("moe_'s", 'tavern')
Moe'nun meyhanesini kim unutabilir ki? Barney değil.
w2v_model.wv.similarity('maggie', 'baby')
Maggie gerçekten de Simpsonlar'daki en ünlü bebek!
w2v_model.wv.similarity('bart', 'nelson')
Bart ve Nelson arkadaş olsalar da o kadar yakın değiller, mantıklı!
Tek-Bir-Çıkış
Burada modelimizden listede olmayan kelimeyi bize vermesini istiyoruz!
Jimbo, Milhouse ve Kearney arasında zorba olmayan kim var?
w2v_model.wv.doesnt_match(['jimbo', 'milhouse', 'kearney'])
Nelson, Bart ve Milhouse arasındaki dostluğu karşılaştırsak ne olur?
w2v_model.wv.doesnt_match(["nelson", "bart", "milhouse"])
Görünüşe göre buradaki tuhaf kişi Nelson!
Son olarak, Homer ve iki baldızı arasındaki ilişki nasıl?
w2v_model.wv.doesnt_match(['homer', 'patty', 'selma'])
Kahretsin, senden gerçekten hoşlanmıyorlar Homer!
Analoji Farkı
Hangi kelime kadın için, homer marge için ne ifade ediyor?
w2v_model.wv.most_similar(positive=["woman", "homer"], negative=["marge"], topn=3)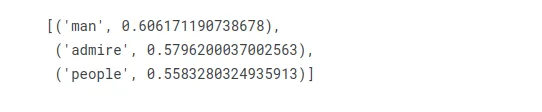
İlk pozisyonda “adam” geliyor, bu doğru gibi görünüyor!
Bart erkeğe ne ifade ediyorsa, kadın için de o sözcük hangisidir?
w2v_model.wv.most_similar(positive=["woman", "bart"], negative=["man"], topn=3)
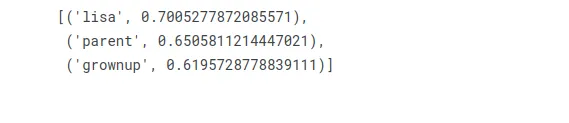
Lisa, Bart'ın kız kardeşi, onun erkek muadili!
Sonuç
Sonuç olarak, Word2Vec, kelimeleri sürekli bir vektör uzayında yoğun vektörler olarak temsil ederek kelime yerleştirmelerini öğrenen doğal dil işleme (NLP) alanında yaygın olarak kullanılan bir algoritmadır. Geniş bir metin külliyatında birlikte bulunma modellerine dayalı olarak sözcükler arasındaki anlamsal ve sözdizimsel ilişkileri yakalar.
Word2Vec, sinir ağı mimarileri olan Sürekli Kelime Çantası (CBOW) veya Skip-gram modelini kullanarak çalışır. Word2Vec tarafından oluşturulan sözcük yerleştirmeleri, anlamsal ve sözdizimsel bilgileri kodlayan sözcüklerin yoğun vektör temsilleridir. Kelime benzerliği hesaplaması gibi matematiksel işlemlere izin verirler ve çeşitli NLP görevlerinde özellik olarak kullanılabilirler.
Önemli Noktalar
- Word2Vec, kelime yerleştirmelerini, kelimelerin yoğun vektör temsillerini öğrenir.
- Anlamsal ilişkileri yakalamak için bir metin külliyatındaki birlikte oluşum modellerini analiz eder.
- Algoritma, CBOW veya Skip-gram modeline sahip bir sinir ağı kullanır.
- Sözcük gömmeleri, sözcük benzerliği hesaplamalarını mümkün kılar.
- Çeşitli NLP görevlerinde özellik olarak kullanılabilirler.
- Word2Vec, doğru yerleştirmeler için geniş bir eğitim topluluğu gerektirir.
- Sözcük anlamında anlam ayrımını yakalamaz.
- Word2Vec'te kelime sırası dikkate alınmaz.
- Kelime dağarcığı dışındaki kelimeler zorluklar yaratabilir.
- Sınırlamalara rağmen Word2Vec, NLP'de önemli uygulamalara sahiptir.
Word2Vec güçlü bir algoritma olsa da bazı sınırlamaları vardır. Doğru kelime yerleştirmelerini öğrenmek için büyük miktarda eğitim verisi gerektirir. Her kelimeyi atomik bir varlık olarak ele alır ve kelime anlamında anlam ayrımını yakalamaz. Kelime dağarcığı dışındaki kelimeler, önceden mevcut bir yerleşime sahip olmadıkları için zorluk teşkil edebilir.
Word2Vec, NLP'deki gelişmelere önemli ölçüde katkıda bulunmuştur ve bilgi alma, duyarlılık analizi, makine çevirisi ve daha fazlası gibi görevler için değerli bir araç olmaya devam etmektedir.
Sıkça Cevap ve Sorular
C: Word2Vec, doğal dil işleme (NLP) görevleri için popüler bir algoritmadır. Sığ, iki katmanlı bir sinir ağı, kelimeleri sürekli bir vektör uzayında yoğun vektörler olarak temsil ederek kelime yerleştirmelerini öğrenir. Word2Vec, büyük bir metin külliyatındaki birlikte oluşum modellerine dayalı olarak sözcükler arasındaki anlamsal ve sözdizimsel ilişkileri yakalar.
C: Word2Vec, kelime gömmelerini öğrenmek için "dağıtılmış gösterim" adı verilen bir teknik kullanır. Sürekli Kelime Torbası (CBOW) veya Skip-gram modeli gibi bir sinir ağı mimarisi kullanır. CBOW modeli, hedef kelimeyi bağlam kelimelerine göre tahmin ederken, Skip-gram modeli bir hedef kelime verilen bağlam kelimelerini tahmin eder. Eğitim sırasında model, hedef veya bağlam sözcüklerini doğru tahmin etme olasılığını en üst düzeye çıkarmak için sözcük vektörlerini ayarlar.
C: Sözcük yerleştirmeleri, sürekli bir vektör uzayında sözcüklerin yoğun vektör gösterimleridir. Eğitim korpusundaki dağıtımsal özelliklerine dayalı olarak ilişkilerini yakalayarak, kelimelerle ilgili anlamsal ve sözdizimsel bilgileri kodlarlar. Kelime benzerliği hesaplaması gibi matematiksel işlemleri mümkün kılar ve bunları duygu analizi, makine çevirisi vb. gibi çeşitli NLP görevlerinde özellik olarak kullanırlar.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. Otomotiv / EV'ler, karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- Blok Ofsetleri. Çevre Dengeleme Sahipliğini Modernleştirme. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/07/step-by-step-guide-to-word2vec-with-gensim/

