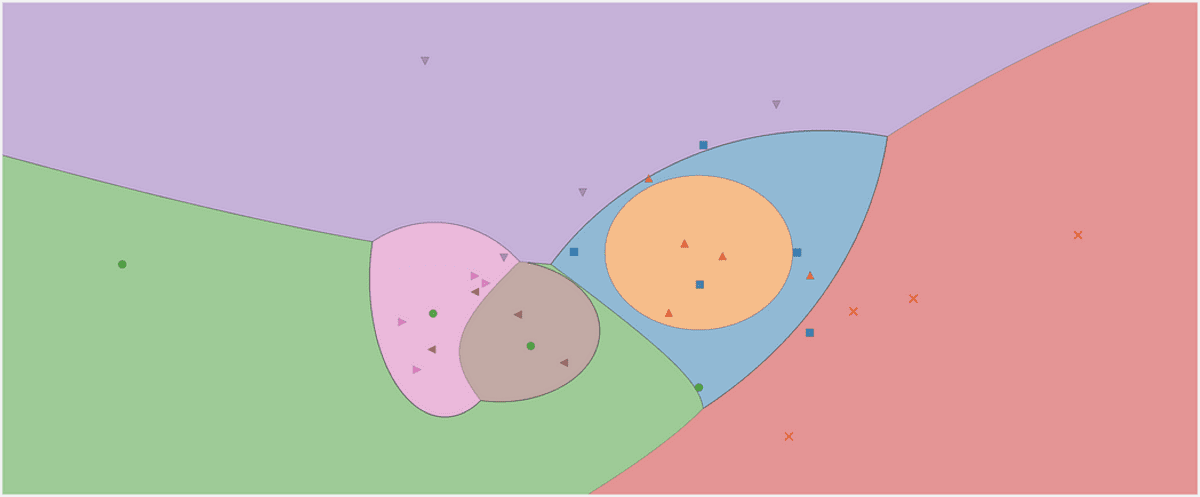
Gauss saf Bayes sınıflandırıcısının karar bölgesi. Yazarın resmi.
Bunun her veri bilimi kariyerinin başında bir klasik olduğunu düşünüyorum: Naive Bayes Sınıflandırıcı. Ya da söylemeyi tercih ederim aile Pek çok çeşide sahip olduklarından, saf Bayes sınıflandırıcılarından. Örneğin, göreceğimiz gibi, her biri yalnızca küçük bir ayrıntıda farklı olan, çok terimli bir naive Bayes, bir Bernoulli naive Bayes ve ayrıca bir Gaussian naive Bayes sınıflandırıcısı vardır. Naif Bayes algoritmaları, tasarım açısından oldukça basittir, ancak birçok karmaşık gerçek dünya durumunda yararlı olduğu kanıtlanmıştır.
Bu makalede, öğrenebilirsiniz
- saf Bayes sınıflandırıcıları nasıl çalışır,
- onları oldukları gibi tanımlamanın neden mantıklı olduğunu ve
- NumPy kullanarak Python'da nasıl uygulanacağı.
Kodu adresinde bulabilirsiniz. benim Github'ım.
Bayes istatistikleriyle ilgili kitabımı kontrol etmek biraz yardımcı olabilir Bayes Çıkarımına Nazik Bir Giriş Bayes formülüne alışmak için. Sınıflandırıcıyı scikit öğren-uygun bir şekilde uygulayacağımız için, makaleme de göz atmakta fayda var. Kendi özel scikit-learn Regresyonunuzu oluşturun. Ancak, scikit-learn ek yükü oldukça küçüktür ve yine de takip edebilmeniz gerekir.
Naif Bayes sınıflandırmasının şaşırtıcı derecede basit teorisini keşfetmeye başlayacağız ve ardından uygulamaya geçeceğiz.
Sınıflandırırken gerçekten neyle ilgileniyoruz? Aslında ne yapıyoruz, girdisi ve çıktısı nedir? Cevap basit:
Bir x veri noktası verildiğinde, x'in herhangi bir c sınıfına ait olma olasılığı nedir?
Cevaplamak istediğimiz tek şey bu herhangi sınıflandırma. Bu ifadeyi doğrudan bir koşullu olasılık olarak modelleyebilirsiniz: p(c|x).
Örneğin, varsa
- 3 sınıfları c₁, c₂, c₃, ve
- x 2 özellikten oluşur x₁, x₂,
bir sınıflandırıcının sonucu şöyle bir şey olabilir p(c₁|x₁, x₂)=0.3, p(c₂|x₁, x₂)=0.5 ve p(c₃|x₁, x₂)=0.2. Çıktı olarak tek bir etiketi önemsiyorsak, en yüksek olasılığa sahip olanı seçerdik, yani c₂ Burada %50 olasılıkla.
Saf Bayes sınıflandırıcısı bu olasılıkları doğrudan hesaplamaya çalışır.
Naif bayanlar
Tamam, bu yüzden bir veri noktası verildi x, hesaplamak istiyoruz p(c|x) tüm sınıflar için c ve ardından çıktısını alın c en yüksek olasılıkla. Formüllerde bunu genellikle şu şekilde görürsünüz:

Yazarın resmi.
Not: maksimum p(c|x) maksimum olasılığı döndürürken argmax p(c|x) döndürür c bu en yüksek olasılıkla.
Ancak optimize etmeden önce p(c|x), hesaplayabilmeliyiz. Bunun için kullandığımız Bayes teoremi:
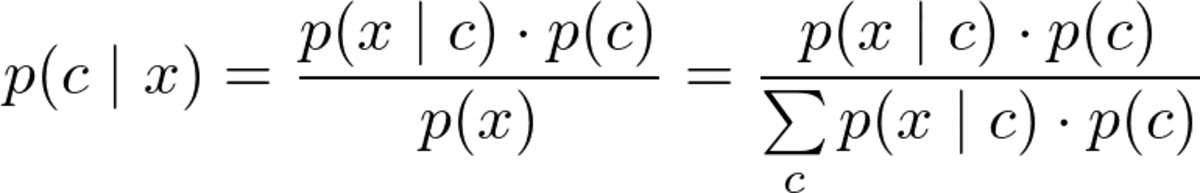
Bayes teoremi. Yazarın resmi.
Bu saf Bayes'in Bayes kısmı. Ama şimdi, şu sorunla karşı karşıyayız: Nedir? p(x|c) Ve p(c)?
Naif bir Bayes sınıflandırıcısının eğitiminin amacı budur.
Eğitim
Her şeyi göstermek için, bir oyuncak veri seti kullanalım. iki gerçek özellik x₁, x₂, ve üç sınıf c₁, c₂, c₃ aşağıdaki.
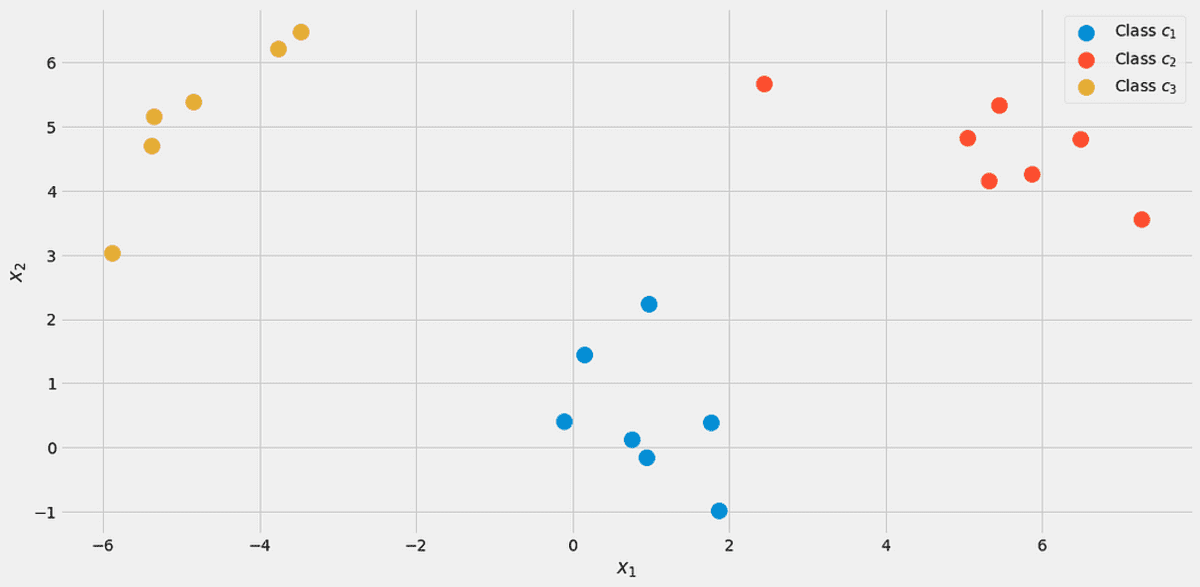
Veriler görselleştirildi. Yazarın resmi.
Bu kesin veri kümesini şu yolla oluşturabilirsiniz:
from sklearn.datasets import make_blobs X, y = make_blobs(n_samples=20, centers=[(0,0), (5,5), (-5, 5)], random_state=0)İle başlayalım sınıf olasılığı p(c), bazı sınıfların olma olasılığı c etiketli veri kümesinde gözlenir. Bunu tahmin etmenin en basit yolu, sınıfların göreceli frekanslarını hesaplamak ve bunları olasılıklar olarak kullanmaktır. Bunun tam olarak ne anlama geldiğini görmek için veri kümemizi kullanabiliriz.
Sınıf etiketli 7 puandan 20'si var c₁ (mavi) veri kümesinde, bu nedenle diyoruz ki p(c₁)=7/20. Sınıf için 7 puanımız var c₂ (kırmızı) da, bu nedenle ayarladık p(c₂)=7/20. son sınıf c₃ (sarı) yalnızca 6 puana sahiptir, dolayısıyla p(c₃)=6/20.
Sınıf olasılıklarının bu basit hesaplaması, maksimum olasılık yaklaşımına benzer. Bununla birlikte, başka bir önceki isterseniz dağıtın. Örneğin, sınıf nedeniyle bu veri kümesinin gerçek popülasyonu temsil etmediğini biliyorsanız, c₃ vakaların %50'sinde görünmelidir, ardından siz ayarlarsınız p(c₁)=0.25, p(c₂)=0.25 ve p(c₃)=0.5. Test setindeki performansı artırmanıza yardımcı olan her şey.
Şimdi olasılık p(x|c)=p(x₁, x₂|c). Bu olasılığı hesaplamak için bir yaklaşım, veri kümesini etiketli örnekler için filtrelemektir. c ve sonra özellikleri yakalayan bir dağılım (örneğin 2 boyutlu bir Gauss) bulmaya çalışın. x₁, x₂.
Ne yazık ki, genellikle, olasılığın uygun bir tahminini yapmak için sınıf başına yeterli örneğe sahip değiliz.
Daha sağlam bir model oluşturabilmek için, saf varsayım o özellikler x₁, x₂ vardır stokastik olarak bağımsız, verilen c. Bu, matematiği kolaylaştırmanın süslü bir yoludur.

Yazarın Resmi
her sınıf için c. İşte burada saf Saf Bayes'in bir kısmı bu denklemden geliyor çünkü genel olarak bu denklem geçerli değil. Yine de, saf Bayes bile pratikte iyi, bazen olağanüstü sonuçlar veriyor. Özellikle kelime torbası özelliklerine sahip NLP problemleri için, çok terimli saf Bayes parlar.
Yukarıda verilen argümanlar, bulabileceğiniz herhangi bir saf Bayes sınıflandırıcısı için aynıdır. Şimdi sadece nasıl modellediğinize bağlı p(x₁|c₁), p(x₂|c₁), p(x₁|c₂), p(x₂|c₂), p(x₁|c₃) ve p(x₂|c₃).
Özellikleriniz yalnızca 0 ve 1 ise, bir Bernoulli dağılımı. Tamsayı iseler, bir Çok terimli dağıtım. Ancak, gerçek özellik değerlerimiz var ve bir Gauss dağıtım, dolayısıyla adı Gauss saf Bayes. Aşağıdaki formu varsayıyoruz

Yazarın resmi.
nerede μᵢ,ⱼ ortalama ve σᵢ,ⱼ verilerden tahmin etmemiz gereken standart sapmadır. Bu, her özellik için bir ortalama elde ettiğimiz anlamına gelir. i bir sınıfla birleştiğinde cⱼ, bizim durumumuzda 2*3=6 demektir. Aynı şey standart sapmalar için de geçerli. Bu bir örnek gerektirir.
tahmin etmeye çalışalım μ₂,₁ ve σ₂,₁. çünkü j=1, biz sadece sınıfla ilgileniyoruz c₁, sadece bu etikete sahip numuneleri tutalım. Aşağıdaki örnekler kalır:
# samples with label = c_1 array([[ 0.14404357, 1.45427351], [ 0.97873798, 2.2408932 ], [ 1.86755799, -0.97727788], [ 1.76405235, 0.40015721], [ 0.76103773, 0.12167502], [-0.10321885, 0.4105985 ], [ 0.95008842, -0.15135721]])şimdi, yüzünden i=2 sadece ikinci sütunu dikkate almalıyız. mikro₂,₁ ortalamadır ve σ₂,₁ bu sütun için standart sapma, yani mikro₂,₁ = 0.49985176 ve σ₂,₁ = 0.9789976.
Dağılım grafiğine tekrar yukarıdan bakarsanız, bu sayılar anlamlıdır. Özellikler x₂ sınıftaki örneklerin c₁ Resimden de görebileceğiniz gibi 0.5 civarındadır.
Bunu şimdi diğer beş kombinasyon için hesaplıyoruz ve işimiz bitti!
Python'da bunu şu şekilde yapabilirsiniz:
from sklearn.datasets import make_blobs
import numpy as np # Create the data. The classes are c_1=0, c_2=1 and c_3=2.
X, y = make_blobs( n_samples=20, centers=[(0, 0), (5, 5), (-5, 5)], random_state=0
) # The class probabilities.
# np.bincounts counts the occurence of each label.
prior = np.bincount(y) / len(y) # np.where(y==i) returns all indices where the y==i.
# This is the filtering step.
means = np.array([X[np.where(y == i)].mean(axis=0) for i in range(3)])
stds = np.array([X[np.where(y == i)].std(axis=0) for i in range(3)])
Aldığımız
# priors
array([0.35, 0.35, 0.3 ])
# means array([[ 0.90889988, 0.49985176], [ 5.4111385 , 4.6491892 ], [-4.7841679 , 5.15385848]])
# stds
array([[0.6853714 , 0.9789976 ], [1.40218915, 0.67078568], [0.88192625, 1.12879666]])Bu, Gauss saf Bayes sınıflandırıcısının eğitiminin sonucudur.
Tahminler Yapmak
Tam tahmin formülü
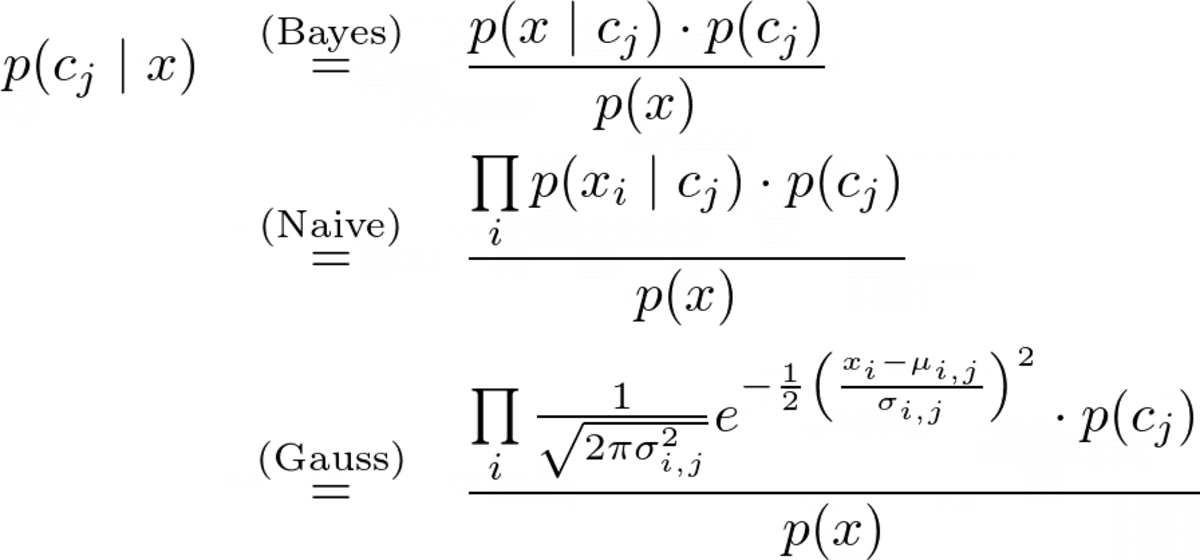
Yazarın resmi.
Yeni bir veri noktası varsayalım x*=(-2, 5) gelir.
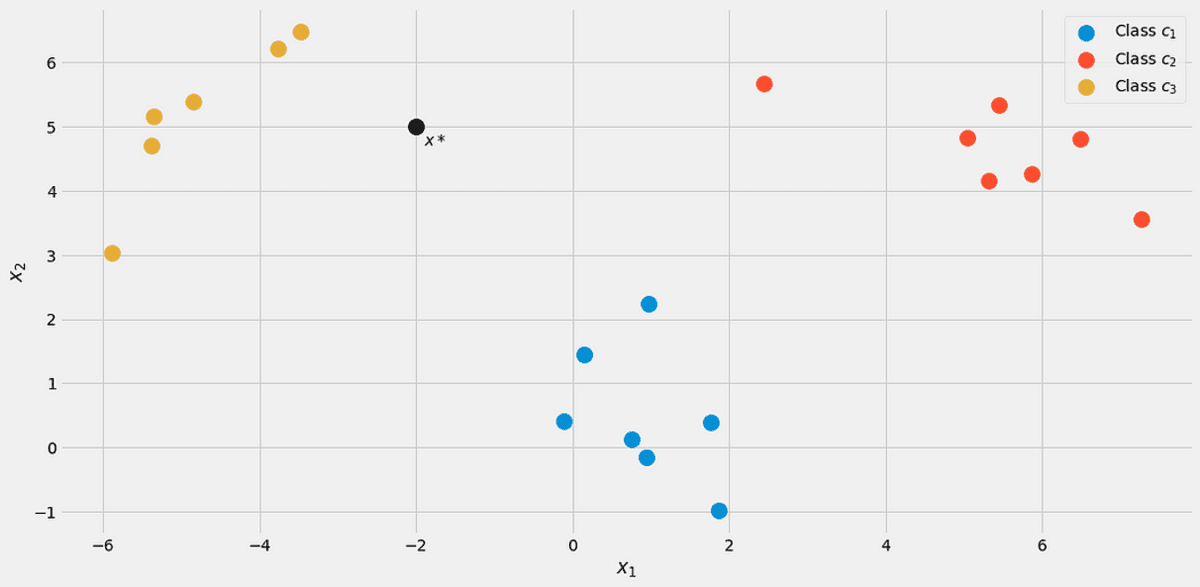
Yazarın resmi.
Hangi sınıfa ait olduğunu görmek için hesaplayalım. p(c|x*) tüm sınıflar için. Resimden, sınıfa ait olmalıdır c₃ = 2, ama bakalım. paydayı yok sayalım p(x) bir saniye. Aşağıdaki döngüyü kullanarak adayları hesapladı: j = 1, 2, 3.
x_new = np.array([-2, 5]) for j in range(3): print( f"Probability for class {j}: {(1/np.sqrt(2*np.pi*stds[j]**2)*np.exp(-0.5*((x_new-means[j])/stds[j])**2)).prod()*p[j]:.12f}" )
Aldığımız
Probability for class 0: 0.000000000263
Probability for class 1: 0.000000044359
Probability for class 2: 0.000325643718Tabii ki bunlar olasılıkları (onlara bu şekilde dememeliyiz) paydayı göz ardı ettiğimiz için toplamı bir yapmayın. Ancak, bu normalleştirilmemiş olasılıkları alıp toplamlarına bölebildiğimiz için bu sorun değil, sonra toplamları bir olacak. Böylece, bu üç değeri toplamları yaklaşık 0.00032569'a bölerek şunu elde ederiz:
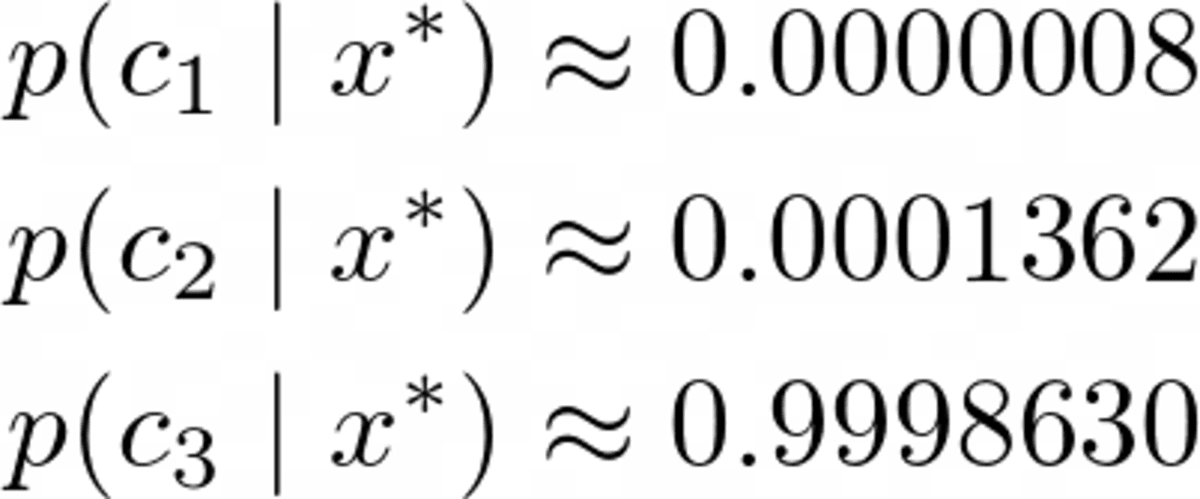
Yazarın resmi.
Beklediğimiz gibi net bir kazanan. Şimdi uygulayalım!
Bu uygulama açık ara verimli değil, sayısal olarak kararlı değil, sadece eğitimsel bir amaca hizmet ediyor. Çoğu şeyi tartıştık, bu yüzden şimdi takip etmek kolay olmalı. hepsini görmezden gelebilirsin check işlevler veya makalemi okuyun Kendi özel scikit-learn'ınızı oluşturun tam olarak ne yaptıklarıyla ilgileniyorsanız.
Sadece bir uyguladığıma dikkat edin predict_proba olasılıkları hesaplamak için ilk yöntem. yöntem predict sadece bu yöntemi çağırır ve bir argmax işlevi kullanarak en yüksek olasılıkla dizini (=sınıf) döndürür (yine öyle!). Sınıf, 0'dan sınıfları bekliyor k-1, nerede k sınıf sayısıdır.
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.utils.validation import check_X_y, check_array, check_is_fitted class GaussianNaiveBayesClassifier(BaseEstimator, ClassifierMixin): def fit(self, X, y): X, y = check_X_y(X, y) self.priors_ = np.bincount(y) / len(y) self.n_classes_ = np.max(y) + 1 self.means_ = np.array( [X[np.where(y == i)].mean(axis=0) for i in range(self.n_classes_)] ) self.stds_ = np.array( [X[np.where(y == i)].std(axis=0) for i in range(self.n_classes_)] ) return self def predict_proba(self, X): check_is_fitted(self) X = check_array(X) res = [] for i in range(len(X)): probas = [] for j in range(self.n_classes_): probas.append( ( 1 / np.sqrt(2 * np.pi * self.stds_[j] ** 2) * np.exp(-0.5 * ((X[i] - self.means_[j]) / self.stds_[j]) ** 2) ).prod() * self.priors_[j] ) probas = np.array(probas) res.append(probas / probas.sum()) return np.array(res) def predict(self, X): check_is_fitted(self) X = check_array(X) res = self.predict_proba(X) return res.argmax(axis=1)Uygulamanın Test Edilmesi
Kod oldukça kısa olsa da, herhangi bir hata yapmadığımızdan tamamen emin olmak için hala çok uzun. Öyleyse, karşı nasıl ilerlediğini kontrol edelim. scikit-learn GaussianNB sınıflandırıcısı.
my_gauss = GaussianNaiveBayesClassifier()
my_gauss.fit(X, y)
my_gauss.predict_proba([[-2, 5], [0,0], [6, -0.3]])çıkışlar
array([[8.06313823e-07, 1.36201957e-04, 9.99862992e-01], [1.00000000e+00, 4.23258691e-14, 1.92051255e-11], [4.30879705e-01, 5.69120295e-01, 9.66618838e-27]])kullanılarak yapılan tahminler predict yöntem
# my_gauss.predict([[-2, 5], [0,0], [6, -0.3]])
array([2, 0, 1])Şimdi scikit-learn'ü kullanalım. Bazı kodlar atmak
from sklearn.naive_bayes import GaussianNB gnb = GaussianNB()
gnb.fit(X, y)
gnb.predict_proba([[-2, 5], [0,0], [6, -0.3]])verim
array([[8.06314158e-07, 1.36201959e-04, 9.99862992e-01], [1.00000000e+00, 4.23259111e-14, 1.92051343e-11], [4.30879698e-01, 5.69120302e-01, 9.66619630e-27]])Sayılar bizim sınıflandırıcımızınkine benziyor, ancak görüntülenen son birkaç basamakta biraz farklılar. Yanlış bir şey mi yaptık? Hayır. Scikit-learn sürümü yalnızca başka bir hiperparametre kullanır var_smoothing=1e-09 . Bunu ayarlarsak sıfır, tam olarak numaralarımızı alıyoruz. Mükemmel!
Sınıflandırıcımızın karar bölgelerine bir göz atın. Test için kullandığımız üç noktayı da işaretledim. Sınıra yakın bir noktanın, kırmızı sınıfa ait olma şansı yalnızca %56.9'dur. predict_proba çıktılar. Diğer iki nokta çok daha yüksek bir güvenle sınıflandırılır.
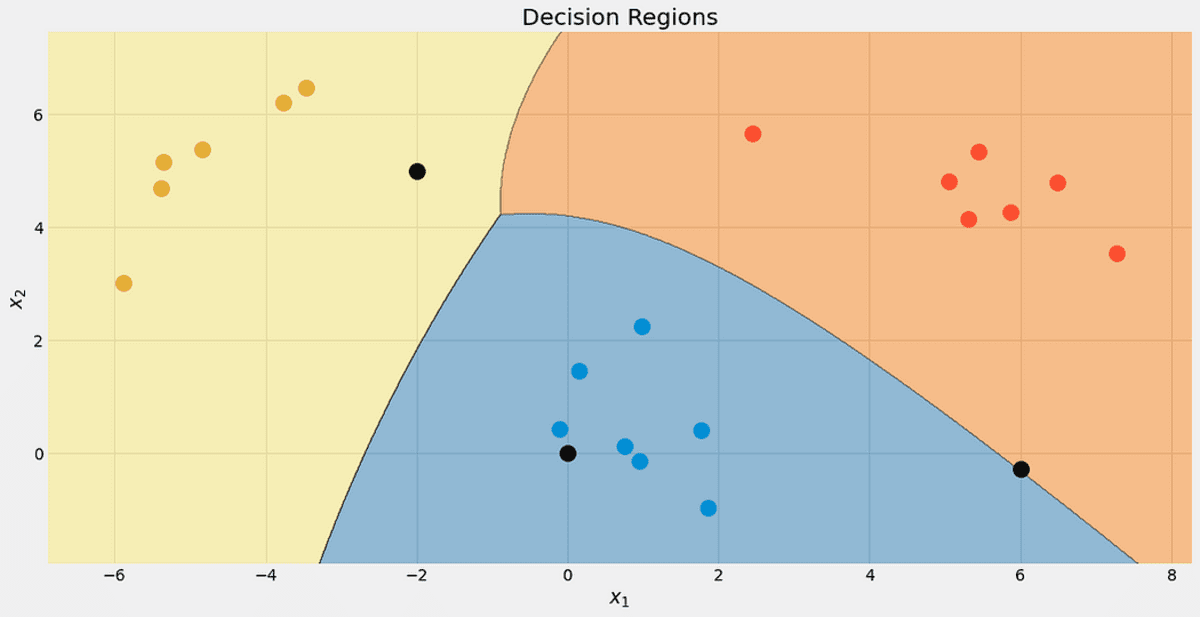
3 yeni nokta ile karar bölgeleri. Yazarın resmi.
Bu makalede, Gauss naif Bayes sınıflandırıcısının nasıl çalıştığını öğrendik ve neden bu şekilde tasarlandığına dair bir fikir verdik - ilgili olasılığı modellemek için doğrudan bir yaklaşımdır. Bunu Lojistik regresyon ile karşılaştırın: burada olasılık, üzerine bir sigmoid işlevi uygulanmış doğrusal bir işlev kullanılarak modellenir. Hâlâ kolay bir model ama saf bir Bayes sınıflandırıcısı kadar doğal gelmiyor.
Yolda birkaç örnek hesaplayarak ve bazı yararlı kod parçaları toplayarak devam ettik. Son olarak, scikit-learn ile iyi çalışacak şekilde eksiksiz bir Gauss saf Bayes sınıflandırıcısı uyguladık. Bu, örneğin boru hatlarında veya kılavuz aramada kullanabileceğiniz anlamına gelir.
Sonunda, scikit-learns'ün kendi Gauss saf Bayes sınıflandırıcısını içe aktararak ve hem bizim hem de scikit-learn'ün sınıflandırıcısının aynı sonucu verip vermediğini test ederek küçük bir akıl sağlığı kontrolü yaptık. Bu test başarılı oldu.
Robert Kübler Publicis Media'da Veri Bilimcisi ve Towards Data Science'da Yazar.
orijinal. İzinle yeniden yayınlandı.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/2023/03/gaussian-naive-bayes-explained.html?utm_source=rss&utm_medium=rss&utm_campaign=gaussian-naive-bayes-explained

