Giriş
Görüntüyü etiketlemek veya fotoğrafa açıklama eklemek, bilgisayarla görmenin büyük resminde zorlayıcıydı. Araştırmamız, hassas açıklama eklemeyi etkili model oluşturmayla birleştiren güçlü bir ikili olan LabelImg ve Detectron'un ekip çalışmasını derinlemesine inceliyor. Kullanımı kolay ve doğru olan LabelImg, net nesne algılama için sağlam bir temel oluşturarak dikkatli açıklama eklemeye öncülük ediyor.
LabelImg'ı keşfettikçe ve sınırlayıcı kutular çizmede daha iyi hale geldikçe sorunsuz bir şekilde Detectron'a geçiyoruz. Bu sağlam çerçeve, işaretlenmiş verilerimizi düzenleyerek gelişmiş modellerin eğitiminde yardımcı olur. LabelImg ve Detectron birlikte, ister yeni başlayan ister uzman olun, nesne algılamayı herkes için kolaylaştırır. İşaretli her görselin görsel bilginin tüm gücünü ortaya çıkarmamıza yardımcı olduğu yere gelin.
Öğrenme hedefleri
- LabelImg'a Başlarken.
- Ortam Kurulumu ve LabelImg Kurulumu.
- LabelImg'ı ve İşlevselliğini Anlamak.
- Nesne Tespiti için VOC veya Pascal Verilerini COCO Formatına Dönüştürme.
Bu makale, Veri Bilimi Blogathon.
İçindekiler
Akış Şeması

Ortamınızı Ayarlama
1. Sanal Ortam Oluşturun:
conda create -p ./venv python=3.8 -yBu komut, Python sürüm 3.8'i kullanarak "venv" adında bir sanal ortam oluşturur.
2. Sanal Ortamı Etkinleştirin:
conda activate venvLabelImg kurulumunu izole etmek için sanal ortamı etkinleştirin.
LabelImg'ı Yükleme ve Kullanma
1. LabelImg'ı yükleyin:
pip install labelImgEtkinleştirilen sanal ortama LabelImg'yi yükleyin.
2. LabelImg'ı başlatın:
labelImg
Sorun Giderme: Komut Dosyasını Çalıştırırken Hatalarla Karşılaşırsanız
Betiği çalıştırırken hatalarla karşılaşırsanız size kolaylık sağlamak için sanal ortamı (venv) içeren bir zip arşivi hazırladım.
1. Zip Arşivini İndirin:
- venv.zip arşivini şuradan indirin: Link
2. Bir LabelImg Klasörü oluşturun:
- Yerel makinenizde LabelImg adında yeni bir klasör oluşturun.
3. venv Klasörünü çıkarın:
- venv.zip arşivinin içeriğini LabelImg klasörüne çıkarın.
4. Sanal Ortamı Etkinleştirin:
- Komut isteminizi veya terminalinizi açın.
- LabelImg klasörüne gidin.
- Sanal ortamı etkinleştirmek için aşağıdaki komutu çalıştırın:
conda activate ./venvBu süreç, LabelImg ile kullanıma hazır, önceden yapılandırılmış bir sanal ortama sahip olmanızı sağlar. Sağlanan zip arşivi, gerekli bağımlılıkları kapsayarak olası kurulum konusunda endişelenmeden daha sorunsuz bir deneyim sağlar.
Şimdi, bu etkinleştirilmiş sanal ortamda LabelImg'ı yüklemek ve kullanmak için önceki adımlara geçin.
LabelImg ile Ek Açıklama İş Akışı
1. Görüntülere PascalVOC Formatında Açıklama Ekleyin:
- LabelImg'yi oluşturun ve başlatın.
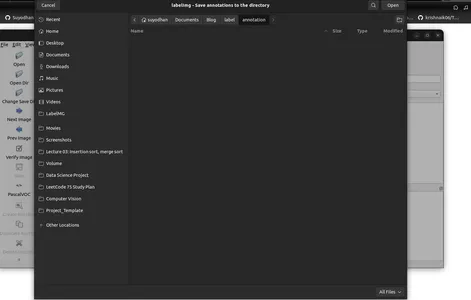
- Menü/Dosya'da 'Varsayılan kayıtlı ek açıklama klasörünü değiştir' seçeneğini tıklayın.
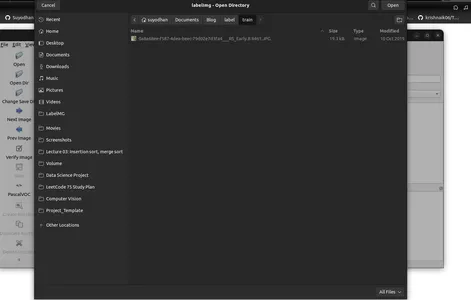
- Görüntü dizinini seçmek için 'Dizini Aç'ı tıklayın.
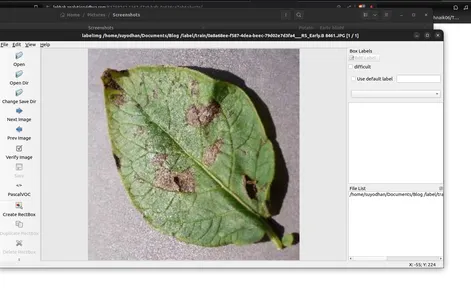
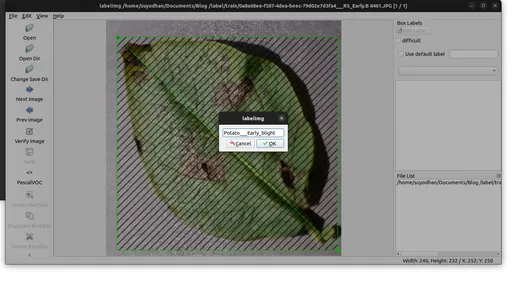
- Görüntüdeki nesnelere açıklama eklemek için 'Create RectBox'ı kullanın.
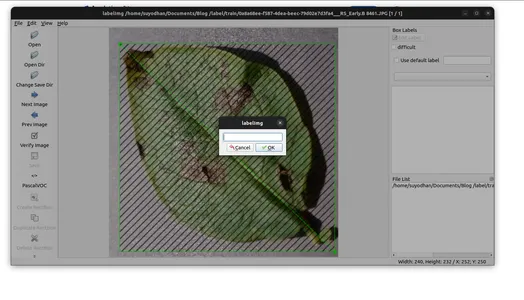
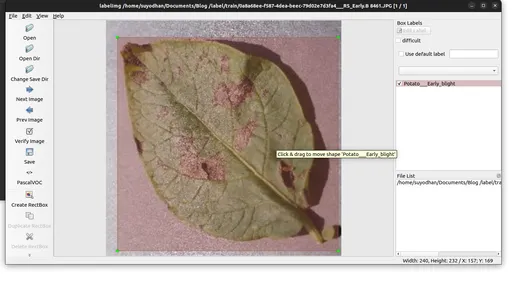
- Ek açıklamaları belirtilen klasöre kaydedin.
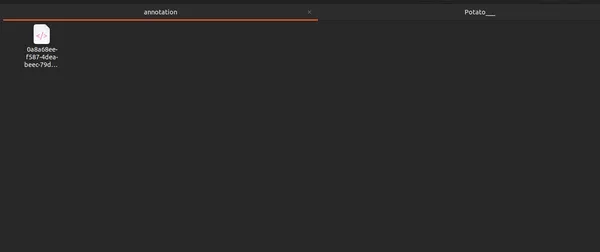
.xml'in içinde
<annotation>
<folder>train</folder>
<filename>0a8a68ee-f587-4dea-beec-79d02e7d3fa4___RS_Early.B 8461.JPG</filename>
<path>/home/suyodhan/Documents/Blog /label
/train/0a8a68ee-f587-4dea-beec-79d02e7d3fa4___RS_Early.B 8461.JPG</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>256</width>
<height>256</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>Potato___Early_blight</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>12</xmin>
<ymin>18</ymin>
<xmax>252</xmax>
<ymax>250</ymax>
</bndbox>
</object>
</annotation>Bu XML yapısı, nesne algılama veri kümeleri için yaygın olarak kullanılan Pascal VOC açıklama biçimini izler. Bu format, bilgisayarlı görme modellerinin eğitimi için açıklamalı verilerin standartlaştırılmış bir temsilini sağlar. Ek açıklamalara sahip ek resimleriniz varsa, ilgili resimlerdeki açıklamalı her nesne için benzer XML dosyaları oluşturmaya devam edebilirsiniz.
Pascal VOC Ek Açıklamalarını COCO Formatına Dönüştürme: Bir Python Komut Dosyası
Nesne algılama modelleri, etkili bir şekilde eğitmek ve değerlendirmek için genellikle belirli formatlarda ek açıklamalara ihtiyaç duyar. Pascal VOC yaygın olarak kullanılan bir format olsa da Detectron gibi belirli çerçeveler COCO ek açıklamalarını tercih eder. Bu boşluğu kapatmak için çok yönlü bir ürün sunuyoruz. Python voc2coco.py betiği, Pascal VOC ek açıklamalarını sorunsuz bir şekilde COCO formatına dönüştürmek için tasarlanmıştır.
#!/usr/bin/python
# pip install lxml
import sys
import os
import json
import xml.etree.ElementTree as ET
import glob
START_BOUNDING_BOX_ID = 1
PRE_DEFINE_CATEGORIES = None
# If necessary, pre-define category and its id
# PRE_DEFINE_CATEGORIES = {"aeroplane": 1, "bicycle": 2, "bird": 3, "boat": 4,
# "bottle":5, "bus": 6, "car": 7, "cat": 8, "chair": 9,
# "cow": 10, "diningtable": 11, "dog": 12, "horse": 13,
# "motorbike": 14, "person": 15, "pottedplant": 16,
# "sheep": 17, "sofa": 18, "train": 19, "tvmonitor": 20}
def get(root, name):
vars = root.findall(name)
return vars
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise ValueError("Can not find %s in %s." % (name, root.tag))
if length > 0 and len(vars) != length:
raise ValueError(
"The size of %s is supposed to be %d, but is %d."
% (name, length, len(vars))
)
if length == 1:
vars = vars[0]
return vars
def get_filename_as_int(filename):
try:
filename = filename.replace("", "/")
filename = os.path.splitext(os.path.basename(filename))[0]
return str(filename)
except:
raise ValueError("Filename %s is supposed to be an integer." % (filename))
def get_categories(xml_files):
"""Generate category name to id mapping from a list of xml files.
Arguments:
xml_files {list} -- A list of xml file paths.
Returns:
dict -- category name to id mapping.
"""
classes_names = []
for xml_file in xml_files:
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall("object"):
classes_names.append(member[0].text)
classes_names = list(set(classes_names))
classes_names.sort()
return {name: i for i, name in enumerate(classes_names)}
def convert(xml_files, json_file):
json_dict = {"images": [], "type": "instances", "annotations": [], "categories": []}
if PRE_DEFINE_CATEGORIES is not None:
categories = PRE_DEFINE_CATEGORIES
else:
categories = get_categories(xml_files)
bnd_id = START_BOUNDING_BOX_ID
for xml_file in xml_files:
tree = ET.parse(xml_file)
root = tree.getroot()
path = get(root, "path")
if len(path) == 1:
filename = os.path.basename(path[0].text)
elif len(path) == 0:
filename = get_and_check(root, "filename", 1).text
else:
raise ValueError("%d paths found in %s" % (len(path), xml_file))
## The filename must be a number
image_id = get_filename_as_int(filename)
size = get_and_check(root, "size", 1)
width = int(get_and_check(size, "width", 1).text)
height = int(get_and_check(size, "height", 1).text)
image = {
"file_name": filename,
"height": height,
"width": width,
"id": image_id,
}
json_dict["images"].append(image)
## Currently we do not support segmentation.
# segmented = get_and_check(root, 'segmented', 1).text
# assert segmented == '0'
for obj in get(root, "object"):
category = get_and_check(obj, "name", 1).text
if category not in categories:
new_id = len(categories)
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, "bndbox", 1)
xmin = int(get_and_check(bndbox, "xmin", 1).text) - 1
ymin = int(get_and_check(bndbox, "ymin", 1).text) - 1
xmax = int(get_and_check(bndbox, "xmax", 1).text)
ymax = int(get_and_check(bndbox, "ymax", 1).text)
assert xmax > xmin
assert ymax > ymin
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {
"area": o_width * o_height,
"iscrowd": 0,
"image_id": image_id,
"bbox": [xmin, ymin, o_width, o_height],
"category_id": category_id,
"id": bnd_id,
"ignore": 0,
"segmentation": [],
}
json_dict["annotations"].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {"supercategory": "none", "id": cid, "name": cate}
json_dict["categories"].append(cat)
#os.makedirs(os.path.dirname(json_file), exist_ok=True)
json_fp = open(json_file, "w")
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(
description="Convert Pascal VOC annotation to COCO format."
)
parser.add_argument("xml_dir", help="Directory path to xml files.", type=str)
parser.add_argument("json_file", help="Output COCO format json file.", type=str)
args = parser.parse_args()
xml_files = glob.glob(os.path.join(args.xml_dir, "*.xml"))
# If you want to do train/test split, you can pass a subset of xml files to convert function.
print("Number of xml files: {}".format(len(xml_files)))
convert(xml_files, args.json_file)
print("Success: {}".format(args.json_file))Komut Dosyasına Genel Bakış
voc2coco.py betiği, lxml kitaplığından yararlanarak dönüştürme işlemini basitleştirir. Kullanıma geçmeden önce temel bileşenlerini inceleyelim:
1. Bağımlılıklar:
- Lxml kitaplığının pip install lxml kullanılarak kurulduğundan emin olun.
2. Yapılandırma:
- İsteğe bağlı olarak PRE_DEFINE_CATEGORIES değişkenini kullanarak kategorileri önceden tanımlayın. Bu bölümün yorumunu kaldırın ve veri kümenize göre değiştirin.
3. İşlevGet
- get, get_and_check, get_filename_as_int: XML ayrıştırma için yardımcı işlevler.
- get_categories: XML dosyaları listesinden kimlik eşlemesi için bir kategori adı oluşturur.
- Convert: Ana dönüştürme işlevi XML dosyalarını işler ve COCO formatı JSON'u oluşturur.
Nasıl Kullanılır?
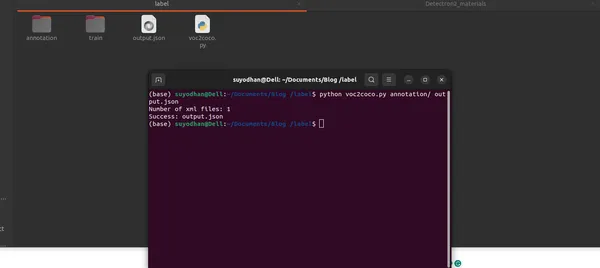
Betiği çalıştırmak, Pascal VOC XML dosyalarınızın yolunu sağlayarak ve COCO formatındaki JSON dosyası için istenen çıktı yolunu belirterek komut satırından çalıştırmak kolaydır. İşte bir örnek:
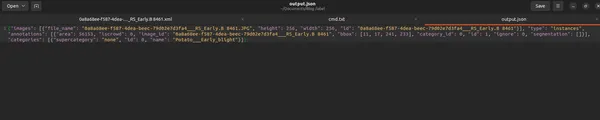
python voc2coco.py /path/to/xml/files /path/to/output/output.jsonÇıktı:
Komut dosyası, görüntüler, açıklamalar ve kategoriler hakkında temel bilgileri içeren, iyi yapılandırılmış bir COCO formatı JSON dosyası üretir.
Sonuç
Sonuç olarak, LabelImg ve Detectron ile nesne algılama yolculuğumuzu tamamlarken, meraklılara ve profesyonellere yönelik çeşitli açıklama araçlarının tanınması çok önemlidir. Açık kaynaklı bir mücevher olan LabelImg, çok yönlülük ve erişilebilirlik sunarak onu en iyi seçim haline getiriyor.
Ücretsiz araçların ötesinde, karmaşık görevler ve büyük projeler için VGG Image Annotator (VIA), RectLabel ve Labelbox gibi ücretli çözümler devreye giriyor. Bu platformlar, finansal bir yatırımla da olsa gelişmiş özellikler ve ölçeklenebilirlik sunarak yüksek riskli çalışmalarda verimlilik sağlar.
Araştırmamız, proje özelliklerine, bütçeye ve karmaşıklık düzeyine göre doğru açıklama aracını seçmeyi vurguluyor. İster LabelImg'in açıklığına sadık kalın, ister ücretli araçlara yatırım yapın, önemli olan projenizin ölçeği ve hedefleriyle uyumdur. Gelişen bilgisayarlı görüntü alanında, açıklama araçları çeşitlenmeye devam ederek her boyut ve karmaşıklıktaki projeler için seçenekler sunuyor.
Önemli Noktalar
- LabelImg'ın sezgisel arayüzü ve gelişmiş özellikleri, onu hassas görüntü açıklamaları için çok yönlü, açık kaynaklı bir araç haline getiriyor ve nesne algılamaya başlayanlar için ideal.
- VIA, RectLabel ve Labelbox gibi ücretli araçlar, karmaşık açıklama görevlerine ve büyük ölçekli projelere hitap ederek gelişmiş özellikler ve ölçeklenebilirlik sunar.
- Önemli olan, proje ihtiyaçlarına, bütçeye ve istenen karmaşıklığa göre doğru açıklama aracını seçmek ve nesne algılama çabalarında verimlilik ve başarı sağlamaktır.
İleri Öğrenme Kaynakları:
1. LabelImg Belgeleri:
- Özellikleri ve işlevleri hakkında derinlemesine bilgi edinmek için LabelImg'in resmi belgelerini inceleyin.
- LabelImg Belgeleri
2. Detectron Çerçeve Belgeleri:
- Yeteneklerini ve kullanımını anlamak için güçlü nesne algılama çerçevesi olan Detectron'un belgelerini inceleyin.
- Detectron Belgeleri
3. VGG Görüntü Açıklayıcı (VIA) Kılavuzu:
- VGG Görüntü Annotator'ı VIA'yı keşfetmek istiyorsanız ayrıntılı talimatlar için kapsamlı kılavuza bakın.
- VIA Kullanım Kılavuzu
4.RectLabel Dokümantasyonu:
- Kullanım ve özelliklerle ilgili rehberlik için resmi belgelerine bakarak ücretli bir açıklama aracı olan RectLabel hakkında daha fazla bilgi edinin.
- RectLabel Dokümantasyonu
5.Labelbox Öğrenim Merkezi:
- Bu açıklama platformu hakkındaki anlayışınızı geliştirmek için Labelbox Öğrenim Merkezi'ndeki eğitim kaynaklarını ve öğreticileri keşfedin.
- Labelbox Öğrenim Merkezi
Sık Sorulan Sorular
C: LabelImg, nesne algılama görevleri için açık kaynaklı bir görüntü açıklama aracıdır. Kullanıcı dostu arayüzü ve çok yönlülüğü onu diğerlerinden ayırıyor. Bazı araçların aksine, LabelImg hassas sınırlayıcı kutu açıklamasına izin verir ve bu da onu nesne algılamada yeni olanlar için tercih edilen bir seçenek haline getirir.
C: Evet, VGG Image Annotator (VIA), RectLabel ve Labelbox gibi çeşitli ücretli açıklama araçları gelişmiş özellikler ve ölçeklenebilirlik sunar. LabelImg gibi ücretsiz araçlar temel görevler için mükemmel olsa da, ücretli çözümler daha karmaşık projeler için özel olarak tasarlanmış olup, işbirliği özellikleri ve gelişmiş verimlilik sağlar.
C: Ek açıklamaları Pascal VOC formatına dönüştürmek, Detectron gibi çerçevelerle uyumluluk açısından çok önemlidir. Tutarlı sınıf etiketlemesi ve eğitim hattına kusursuz entegrasyon sağlayarak doğru nesne algılama modellerinin oluşturulmasını kolaylaştırır.
C: Detectron, model eğitim sürecini kolaylaştıran güçlü bir nesne algılama çerçevesidir. Açıklamalı verilerin işlenmesinde, eğitime hazırlanmasında ve nesne algılama modellerinin genel verimliliğinin optimize edilmesinde çok önemli bir rol oynar.
C: Ücretli açıklama araçları genellikle kurumsal düzeydeki görevlerle ilişkilendirilse de küçük ölçekli projelere de fayda sağlayabilir. Karar, özel gereksinimlere, bütçe kısıtlamalarına ve açıklama görevleri için istenen karmaşıklık düzeyine bağlıdır.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/11/detectron-integration-with-labelimg/

