Dan Yu, Harry Foster ve Tom Fitzpatrick tarafından
Yapay zekanın gücüyle elektronik tasarım otomasyonunda devrim niteliğinde bir dönüşüme tanık olduğumuz EDA 4.0 çağına hoş geldiniz. EDA'nın tarihi, daha hızlı tasarım yinelemelerini, geliştirilmiş üretkenliği ve karmaşık elektronik sistemlerin gelişimini ilerleten önemli teknolojik gelişmelerle işaretlenmiş farklı dönemlere ayrılabilir.
Özellikle, EDA 1.0'ın ortaya çıkışı, 1970'lerin başında Berkeley'deki California Üniversitesi'nde devre tasarımında devrim yaratan SPICE'ın (entegre devre ağırlıklı simülasyon programı) tanıtılmasıyla başlatıldı.
1980'lerde ve 1990'ların başında EDA 2.0, verimli yer ve rota algoritmalarının geliştirilmesinin bir sonucu olarak ortaya çıktı. RTL dönemi olarak da bilinen bu dönem, RTL tasarımının yazmaç-aktarım düzeyinde devre açıklamalarına olanak vermesi ve böylece simülasyon performansının artmasıyla kapı düzeyinde tasarımdan daha yüksek düzey soyutlamalara geçişe tanık oldu. Bu dönem, mantık sentezinin tanıtılmasıyla önemli bir dönüm noktasına tanık oldu.
1990'ların sonlarında ve 2000'lerin başlarında çip üzerinde sistem (SoC) tasarımlarının yükselişi, EDA 3.0'a yol açan çok önemli bir anı işaret ediyordu. Bu çağ, tasarımın yeniden kullanım metodolojileriyle birlikte bir IP geliştirme ekonomisinin ortaya çıkışına tanık oldu. EDA araçları ve standartları, SoC'lerin tasarımını, doğrulanmasını ve doğrulanmasını desteklemek için geliştirildi ve mühendislerin SoC sınıfı tasarımların artan karmaşıklığını yönetmesine olanak sağladı.
EDA 4.0, birçok yönden, kısmen imalat sektörünün dijitalleşmesinin önderliğinde şirketlerin ürünlerini üretme, geliştirme ve dağıtma şeklini hızla değiştiren Sanayi Devrimi 4.0'ın daha geniş eğilimleriyle uyumludur. EDA 4.0, bulut bilgi işlem ve yapay zeka (AI) ve makine öğrenimi (ML) yeteneklerinin potansiyelinden yararlanarak akıllı ve bağlantılı cihazların tasarımını kolaylaştırmak için geliştirildi.


EDA araçları artık EDA ürünlerine hızlandırılmış doğrulama, otomatik doğrulama iş akışları ve artırılmış doğrulama doğruluğu getirmek için makine öğrenimi, sanal prototip oluşturma, dijital ikiz ve sistem düzeyinde tasarım metodolojilerini birleştiriyor. EDA 4.0 dönemi, optimize edilmiş ürün performansı, azaltılmış pazara sürüm süresi ve kolaylaştırılmış geliştirme ve üretim süreçleri vaat ediyor.
Bu makalede, işlevsel doğrulama için özel olarak tasarlanmış makine öğrenimi çözümlerinin en son teknoloji uygulamasını inceliyoruz. Makine öğrenimi tarafından ele alınabilecek zorlukları keşfediyor ve bu alanda geçerli olan yeni teknikler ve algoritmalar sunuyoruz.
İşlevsel doğrulamada makine öğrenimi konuları
Tablo 1, programlama kodu doğrulamasının genel perspektifinde tüm fonksiyonel doğrulama konularını dahil ederken fonksiyonel doğrulamaya uygulanabilir konuları ve alt konuları özetlemektedir. İtalik metin, diğer genel araştırma yayınlarında keşfedilmemiş alt konuları gösterir.
Tablo 1: İşlevsel doğrulamada makine öğrenimi uygulamalarının konuları.

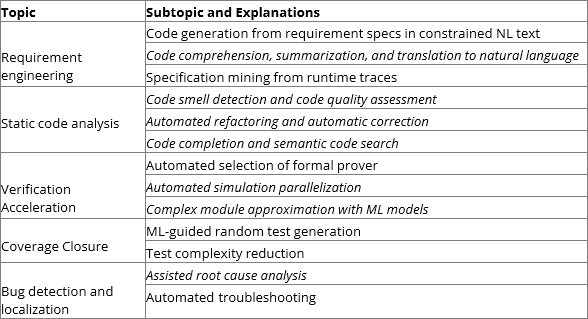
Gereksinim mühendisliği
İşlevsel doğrulamada gereksinim mühendisliği, temel IC tasarımının mükemmel kalitesini sağlamak için kritik olan doğrulama gereksinimlerinin tanımlanması, belgelenmesi ve sürdürülmesi sürecidir.
Gereksinim tanımı, belirsiz doğal dil (NL) doğrulama hedeflerinin formalite ve kesinlik ile doğrulama özelliklerine dönüştürülmesini içerir. Çevirinin kalitesi, doğrulamanın doğruluğunu doğrudan belirler. Geleneksel olarak bu süreç zahmetlidir ve kaliteyi sağlamak için birkaç manuel prova yinelemesiyle önemli tasarım döngüleri tüketir.
Çeviriyi otomatikleştirmek için iki grup klasik yaklaşım önerilmiştir. Bir yaklaşım grubu, şartname taslağını resmileştirmek için kısıtlı doğal dili (CNL) ve ardından şablon tabanlı bir çeviri motorunu tanıtmaktır. Bu yaklaşım, işlevsel doğrulamada karşılaşılan gereksinimlerin çoğunu karşılayacak kadar güçlü olmasını sağlamak için güçlü bir CNL sözdizimi ve kapsamlı bir derleyici/şablon sistemi geliştirmeye yönelik önemli bir ön yatırım gerektirir. Ayrıca, geliştiricilere ek bir dil öğrenme yükü yükler ve bu da fikrin geniş çapta kabul görmesini engeller.
Diğer grup, NL belirtimlerini ayrıştırmak ve resmi belirtimleri formüle etmek için ilgili anahtar öğeleri çıkarmak için klasik doğal dil sürecinden (NLP) yararlanır.
Makine öğrenimi çevirisinin NL alanındaki ilerlemesi, tam otomatik makine çevirisini ticari olarak mümkün kılmıştır ve bazen ortalama insan çevirmenlerin performansını aşmaktadır. NL belirtimlerini SystemVerilog Assertions (SVA), Özellik Belirtim Dili (PSL) veya diğer dillerdeki doğrulama belirtimlerine doğrudan çevirmek için milyarlarca parametreye sahip büyük ölçekli eğitimli NL modellerinden yararlanma umudunu ateşledi. Başarılı bir uçtan uca çeviri yapmak için birkaç girişim gözlemlendi, ancak hiçbiri üretime hazır hale getirilmedi. Bu yaklaşımın önündeki en büyük engel, NL spesifikasyonlarını resmi çevirileriyle eşleştiren mevcut eğitim veri setlerinin azlığıdır. En kapsamlı veri kümeleri yalnızca yaklaşık 100 cümle çiftidir.. Sayı, rutin olarak milyonlarca hatta milyarlarca cümle çifti halinde gelen NL akranlarına kıyasla sönük kalıyor.
Gereksinim tanımının tersine özetleme, koda bakar ve onu insan tarafından anlaşılabilir bir NL özetine dönüştürür. Geliştiricilerin daha az ideal şekilde korunan kodu okumalarına veya karmaşık mantığı anlamalarına yardımcı olur. İdeal olarak uygulanan bir kod özetleme, satır içi belgeleri kod bloklarına ekleyebilir veya ayrı belgeler oluşturabilir. Yardımı ile kodun bakımı ve dokümantasyonu önemli ölçüde iyileştirilebilir.
Kod özetlemede makine öğreniminin uygulanması, Python ve JavaScript gibi daha popüler bilgisayar dillerinde denenmiştir. Birkaç yaklaşım grubu, çeşitli derecelerde başarı ile deneyler yaptı. Bilgi alma (IR) tabanlı yaklaşımlar, NLP'yi kaynak koduna uygulamaya ve mevcut özetleme ile benzer kodu aramaya odaklanır. Bu yaklaşım grubu, büyük ölçüde özetlerle birlikte mevcut kodun kalitesine dayanır. Kullanımı, yalnızca birçok mevcut kod deposunun hazır olduğu yakın bir kuruluş içinde mümkündür. Sezgisel tabanlı yaklaşımlar bunun yerine, bir modülün tanımında tanımlanan buluşsal yöntemlere dayalı belirli kuralları tanımlamaya çalışır; örneğin, birçok temel okuma/yazma komut satırı alt modülüne sahip bir modül, bir bellek modülü olarak kabul edilebilir. Bu nedenle, bellek modülü için önceden tanımlanmış bir modelden bir özet oluşturulabilir.
Bu yazının yazıldığı sırada, IC tasarım doğrulamasında kod özetleme henüz herhangi bir literatürde bildirilmemiştir. Diğer dillerin başarısının, araştırma topluluğu tarafından henüz onaylanmayan IC tasarımı ve doğrulamasında gerçekleştirilebileceği konusunda iyimser olmak mantıklıdır. Özellikle, diller arası modellerdeki son gelişmeler, öğrenilen bilgilerin diğer programlama dillerinden IC tasarımına aktarılmasına yardımcı olabilir. Bununla birlikte, kod özetleme konusunda makine öğrenimi için genel zorluklara ek olarak, IC tasarımı ve doğrulama kodundaki içsel zamansal paralellik, diğer programlama dillerinde yaygın olmayan zorluklar sunabilir.
Spesifikasyon madenciliği, uzun vadeli bir yazılım mühendisliği konusu olmuştur. Spesifikasyonları manuel olarak tasarlamaya bir alternatif olarak, spesifikasyonları test altındaki tasarım (DUT) uygulamasından dolaylı olarak çıkarır. Makine öğrenimi, simülasyon izlerinden yinelenen kalıpları çıkarmak için uygulanabilir. Simülasyon tabanlı kapsama kapanışını veya resmi doğrulamayı otomatikleştirmeye yardımcı olabilir. Yaygın olarak tekrar eden kalıpların, DUT'un beklenen davranışı olabileceği varsayılmaktadır. Alternatif olarak, izlerde nadiren meydana gelen bir olay örüntüsü bir anormallik olarak kabul edilebilir; bu nedenle, teşhis ve hata ayıklama amaçları için kullanılabilir.
Makine öğrenimi, karmaşık bir sistemin zamansal verilerinin mevcut olduğu birçok alanda örüntü keşfi ve anormallik tespitinde uygulanmıştır. Azeem ve ark. ML'nin protokol izlerini gözlemleyerek ve protokolün olası sorunlu uygulamasını bularak resmi özellikleri keşfetmek için kullanıldığı genel bir yazılım mühendisliği yaklaşımı önermek. Başarılı deneyler, ML ile spesifikasyon madenciliğinde ilginç takip araştırma projelerine ilham verdi.
Statik kod analizi
IC geliştirme aşamaları boyunca bir hatayı düzeltmenin maliyeti katlanarak arttığından, statik kod analizi, tasarım geliştirmenin daha erken bir aşamasında kod kalitesini ve sürdürülebilirliği iyileştirmek için çekici bir seçenek sunar.
Kod kokusu, kaynak koddaki sözdizimsel ve anlamsal olarak doğru olabilen ancak en iyi uygulamaları ihlal eden ve zayıf kod bakımına yol açabilen yetersiz tasarım modellerini ifade eder. Belirli bir örnek, aynı işlevin bir projede veya tüm kod tabanında birden çok kez uygulandığı kod çoğaltmadır. Bazı kopyalarda nispeten kısa bir süre içinde belirli bir hata giderilebilirken, diğer kopyalarda aynı hata fark edilmeyebilir.
Klasik kod kokusu algılama, kaynak koddaki kalıpları tanımlamak için tanımlanmış sezgisel kurallara dayanır. Statik kod analiz araçlarında bu kuralları ve ölçümleri manuel olarak geliştirmek yerine, kod kokularını tanımlamak için büyük miktarda mevcut kaynak kodu üzerinde ML tabanlı bir yaklaşım eğitilebilir. Araştırmalar, makine öğrenimi ile koku algılamanın evrensel kod kokusu algılamaya ve önemli ölçüde daha az model uygulama çabasına yol açabileceğini kanıtlamıştır. Ortaya çıkan koku puanı daha sonra kod kalitesi değerlendirmesi için kullanılabilir ve geliştiricilerin ürün kalitesini tutarlı bir şekilde iyileştirmesine yardımcı olur. Ayrıca, makine öğrenimi tabanlı kod yeniden düzenleme, kod kokusunu iyileştirme veya hatta bazı aday değişiklikleri geliştirme konusunda yararlı ipuçları sağlayabilir.
İşlevsel doğrulamada makine öğrenimi uygulaması henüz görünür değil ve büyük eğitim veri kümelerinin bulunmaması, mevcut araştırmaların bu çözümün potansiyelinden tam olarak yararlanmasını engelledi.
IC tasarımı üzerinde çalışan geliştiriciler, uygun araçlar sağlandığında en üretken olabilir. Basit kod tamamlama, modern Entegre Geliştirme Ortamında (IDE) standart bir özelliktir. Bununla birlikte, derin öğrenmeyi içeren daha gelişmiş teknikler önerildi ve hızla olgunlaşıyor. YSA'ları, geliştiricilerin uygulama amacından veya içeriğinden makul kod parçacıkları önerileri vermek için birçok büyük ölçekli açık kaynak kod deposundan milyarlarca parametre ile eğitmek artık mümkün.
Makine öğrenimi, IC geliştiricilerinin, NL sorgularıyla ilgili kodun alınmasına izin veren semantik kod aramayla üretken kalmasına da yardımcı olabilir. Kod genellikle çeşitli kısaltmalar ve teknik jargonla dolu olduğundan, anlamsal aramalar, anahtar değişken, işlev veya modül adlarını doğru şekilde yazmadan ilgili kod parçacıklarını bulmada daha etkili olabilir. Birçok mevcut arama motorundaki semantik aramaya benzer olsa da, anlamsal kod araması kısaltılmış ve muğlak kavramlarla son derece teknik kodun bulunmasına yardımcı olabilir. En iyi modelin ortalama karşılıklı sıralaması, halihazırda %70'lik kullanılabilir puanlara ulaşabilir.
Teorik olarak diğer programlama dillerine uygulanan aynı makine öğrenimi teknikleri IC tasarımına uygulanabilse de, kodlama yardımı konusunda henüz bir araştırma yayınlanmadı.
Doğrulama hızlandırma
Son anketler, işlevsel doğrulamanın IC tasarımında hala en çok zaman alan adım olduğunu ve işlevsel ve mantık hatalarının hala bir yanıtın en önemli nedeni olduğunu gösteriyor. İşlevsel doğrulama hızındaki herhangi bir gelişme, IC tasarımının kalitesini ve üretkenliğini önemli ölçüde etkileyecektir. Makine öğrenimi, hızlanmaları için hem resmi hem de simülasyon tabanlı doğrulamada kullanılmıştır.
Resmi doğrulama, bir tasarımın doğruluğunu kanıtlamak için resmi matematik algoritmaları kullanır. Modern resmi doğrulama düzenlemesi, farklı boyut, tür ve karmaşıklıktaki tasarımları hedeflemek için resmi algoritmalar kullanır. Deneyim ve buluşsal yöntemler, geliştiricilerin belirli bir sorun için kitaplıktan en uygun algoritmaları seçmesine yardımcı olabilir.
İstatistiksel bir yöntem olarak makine öğrenimi, resmi doğrulama sorunlarını doğrudan ele alamaz. Ancak, resmi orkestrasyonda çok yardımcı olduğu kanıtlanmıştır. Bilgi işlem kaynaklarının tahmini ve bir sorunu çözme olasılığı ile, ilk olarak daha düşük bilgi işlem kaynağı tüketimi ile en umut verici çözücüleri planlayarak doğrulama süresini kısaltmak için resmi çözücüleri bu kaynakları en iyi şekilde kullanacak şekilde programlamak mümkündür. Ada-boost karar ağacı tabanlı sınıflandırıcı, ortalama 95'lik bir hız artışıyla temel orkestrasyondan çözülmüş örneklerin oranını %97'ten %1.85'ye çıkarabilir. Başka bir deney, resmi doğrulamanın kaynak gereksinimlerini ortalama %32 hatayla tahmin edebildi. Daha sonra kaynak gereksinimleri tahmini için çoklu doğrusal regresyon modelini eğitmek için kullanılan DUT, özellikler ve biçimsel kısıtlamalardan özellikleri dikkatlice seçmek için özellik mühendisliğini yinelemeli olarak uygular.
Resmi doğrulamanın aksine, simülasyona dayalı doğrulama genellikle tasarımda tam doğruluğu garanti edemez. Bunun yerine, tasarım, belirli rastgele veya sabit örüntü girdi uyarıcılarının uygulandığı bir test tezgahına konur ve bu arada, tasarım davranışının beklenip beklenmediğini doğrulamak için çıktılar referans çıktılarla karşılaştırılır. Simülasyon, işlevsel doğrulamanın ekmeği ve yağı olsa da, simülasyona dayalı doğrulama da uzun doğrulama sürelerinden zarar görebilir. Karmaşık bir tasarımın doğrulanmasının tamamlanmasının haftalar alması alışılmadık bir durum değildir.
Tartışılan ve denenen ümit verici bir fikir, karmaşık bir sistemin davranışını modellemek ve tahmin etmek için makine öğreniminin kullanılmasıdır. Evrensel Yaklaşım Teoremi, en az bir gizli katmana sahip ileri beslemeli bir YSA olan çok katmanlı bir algılayıcının (MLP), herhangi bir sürekli fonksiyona rastgele doğrulukla yaklaşabileceğini kanıtlar. YSA'nın özel bir biçimi olan normalleştirilmiş tekrarlayan sinir ağlarının (RNN'ler), hafızalı herhangi bir dinamik sisteme yaklaştığı kanıtlanmıştır. Gelişmiş makine öğrenimi hızlandırıcı donanımı, YSA'ların simülasyonlarını hızlandırmak için bazı IC tasarım modüllerinin davranışlarını modelleyebilmesini mümkün kılmıştır. AI hızlandırıcıların kapasitesine ve ML modellerinin karmaşıklığına bağlı olarak önemli hızlanma elde edilebilir.
Test oluşturma ve kapsam kapatma
Manuel olarak tanımlanan test modellerinin yanı sıra, simülasyon tabanlı doğrulamada kullanılan standart teknikler, rastgele test oluşturma ve grafik tabanlı akıllı test tezgahı otomasyonunu içerir. Kapsam kapatmanın "uzun kuyruklu" doğası nedeniyle, küçük bir verimlilik artışı bile kolayca simülasyon süresinin önemli ölçüde azalmasıyla sonuçlanabilir. Makine öğreniminin işlevsel doğrulamaya uygulanmasına ilişkin çoğu araştırma bu alana odaklanmıştır.
Kapsamlı makine öğrenimi çalışmaları, rastgele test oluşturmadan daha iyisini yapabileceklerini göstermiştir. Çoğu araştırma, bir DUT'nin girdileri kontrol edilebilen ve çıktıları izlenebilen bir kara kutu olduğunu varsayarak bir "kara kutu modeli" kullanır. Opsiyonel olarak bazı test noktaları gözlenebilir. Araştırma, DUT'un davranışını anlamaya çalışmaz. Bunun yerine, gereksiz testleri azaltmaya odaklanılır. Rastgele test oluşturucuları ayarlamak veya yararlı olma olasılığı düşük testleri ortadan kaldırmak için geçmiş girdi/çıktı/gözlem verilerinden öğrenmek için çeşitli makine öğrenimi teknikleri kullanırlar. Yakın tarihli bir geliştirmede, bir DUT'un çıktısından öğrenmek ve bir önbellek denetleyicisi için en olası testleri tahmin etmek için pekiştirmeli öğrenme (RL) tabanlı bir model kullanıldı. Makine öğrenimi modeline verilen ödül FIFO derinlikleri olduğunda, deneyler tarihsel sonuçlardan öğrenebilir ve birkaç yinelemede tam hedef FIFO derinliklerine ulaşabilirken, rastgele test oluşturma tabanlı yaklaşım hala 1'den fazlasına ulaşmak için mücadele ediyor. Çok daha ince ayrıntı düzeyine sahip bir makine öğrenimi mimarisi, her kapsam noktası için bir makine öğrenimi modelinin eğitilmesini gerektirir. Bir testin simüle edilip edilmeyeceğine, iptal edilip edilmeyeceğine veya bir modeli daha fazla yeniden eğitmek için kullanılıp kullanılmayacağına karar vermeye yardımcı olmak için üçlü bir sınıflandırıcı da kullanılır. Destek vektör makinesi (SVM), rastgele orman ve derin sinir ağının tümü bir CPU tasarımı üzerinde denenmiştir. 100 ila 3 kat daha az testle %5 kapsamı kapatabilir. FSM ve FSM olmayan tasarımlar üzerinde yapılan diğer deneyler, yönlendirilmiş dizi üretimine kıyasla %69 ve %72 azalma göstermiştir. Ancak, bu sonuçların çoğu hala ML'nin istatistiksel doğasının sınırlandırılmasından muzdariptir. Makine öğrenimi tabanlı kapsama yönelik test oluşturmanın (CDG) daha kapsamlı bir incelemesi, çeşitli makine öğrenimi modellerine ve bunların deney sonuçlarına genel bir bakış sunar. Bayes Ağı genetik algoritmaları ve genetik programlama yaklaşımları, Markov modeli, veri madenciliği ve tümevarımsal mantık programlaması, çeşitli başarı derecelerine sahip deneylerdir.
Tartışılan tüm yaklaşımlarda, bir makine öğrenimi modeli, topladığı tarihsel verilerden öğrenmeye dayalı olarak bir tahminde bulunabilir, ancak geleceği tahmin etme konusunda asgari yeteneğe sahiptir, yani, hangi testin açıklanmamış bir test hedefine ulaşmak için daha umut verici bir seçenek olabileceği. Bu tür bilgiler henüz mevcut olmadığından, yapabilecekleri en iyi şey, tarihsel testlerle en alakasız olan testleri seçmektir. Başka bir umut verici deney, DUT'nin bir beyaz kutu olarak kabul edildiği ve kodun analiz edilip bir Kontrol / Veri Akış Grafiğine (CDFG) dönüştürüldüğü farklı bir yaklaşımı araştırdı. Önceden tanımlanmış bir test hedefi için testler oluşturmak üzere eğitimli bir Grafik Sinir Ağı (GNN) üzerinde gradyan tabanlı bir arama kullanılır. IBEX v1, v2 ve TPU üzerindeki deneyler, %74 kapsama noktaları ile eğitildiğinde kapsama tahmininde %73, %90 ve %50 doğruluk elde etti. Birkaç ek deney de, kullanılan gradyan arama yönteminin GNN mimarisine duyarsız olduğunu doğrulamaktadır.
Eğitim verilerinin bulunmaması nedeniyle, bu makine öğrenimi yaklaşımlarının çoğunun, diğer benzer tasarımlardan herhangi bir ön bilgiden yararlanmadan yalnızca her tasarımdan öğrendiği belirtilmektedir.
Hata analizi
Hata analizi, potansiyel hataları belirlemeyi, bunları içeren kod bloklarını yerelleştirmeyi ve düzeltme önerileri vermeyi amaçlar. Son anketler, bir IC'nin doğrulanmasının tasarımda olduğu gibi kabaca aynı miktarda zaman harcadığını ve işlevsel hataların bir ASIC tasarımı için yanıtların yaklaşık %50'sine katkıda bulunduğunu buldu. Bu nedenle, erken fonksiyonel doğrulama aşamasında bu hataların tespit edilip düzeltilebilmesi kritik öneme sahiptir. Makine öğrenimi, geliştiricilerin tasarımlardaki hataları tespit etmesine ve hataları daha hızlı bulmasına yardımcı olmak için kullanılmıştır.
İşlevsel doğrulamada hata avını hızlandırmak için üç aşamalı problemin çözülmesi gerekir; yani, hataların kök nedenlerine göre kümelenmesi, temel nedenlerin sınıflandırılması ve düzeltme önerileri. Araştırmaların çoğu ilk ikisine odaklanırken, üçüncüsüne ilişkin henüz herhangi bir araştırma sonucu mevcut değil.
Hata analizi için yarı yapılandırılmış simülasyon günlük dosyaları kullanılabilir. Açıklanmayan tasarımların meta verilerinden ve günlük dosyalarından mesaj satırlarından 616 farklı özellik çıkarır. Kümeleme deneyi, özellik boyutluluk azaltma sonrasında bile, K-ortalamaları ve aglomeratif kümeleme ile 0.543'lük Düzeltilmiş Karşılıklı Bilgiye (AMI) ve DBSCAN ile 0.593'e ulaştı, AMI 1.0'a ulaştığında ideal kümelemeden çok uzak. 2. problemi çözmedeki doğruluklarını belirlemek için çeşitli sınıflandırma algoritmaları da test edildi. Rastgele orman, Destek Vektör Sınıflandırması (SVC), karar ağacı, lojistik regresyon, K-komşular ve naif Bayes dahil tüm algoritmalar, güçleri açısından karşılaştırılır. temel nedenleri tahmin edin. En iyi skor, %90.7 tahmin doğruluğu ve 0.913 F1 skoru ile rastgele orman tarafından elde edildi. Başka bir yaklaşım, algoritma için 100 seçilene kadar yazarlar, revizyonlar, kodlar ve projeler hakkında 36'den fazla özelliğin test edildiği bir gradyan artırma modelini eğitmek için kod taahhüdünden etiketlenmiş bir veri kümesi kullanmayı önerir. Deneyler, hangi taahhütlerin hatalı kod içerme olasılığının yüksek olduğunu tahmin etmenin ve potansiyel olarak manuel hata avlama süresini önemli ölçüde azaltmanın mümkün olduğunu gösteriyor.
Ancak, benimsenen makine öğrenimi tekniklerinin göreli basitliği nedeniyle, koddaki zengin semantiği dikkate alabilen veya tarihsel hata düzeltmelerinden öğrenebilen makine öğrenimi modellerini eğitemezler. Bu nedenle, hataların neden ve nasıl oluştuğunu açıklayamazlar ve hataları otomatik veya yarı otomatik olarak ortadan kaldırmak için kodun revize edilmesini öneremezler.
İşlevsel doğrulamaya uygulanabilir gelişen makine öğrenimi teknikleri ve modelleri
Son yıllarda makine öğrenimi teknikleri, modelleri ve algoritmalarında önemli atılımlara tanık olunmaktadır. Araştırmamız, ortaya çıkan bu tekniklerin çok azının işlevsel doğrulama araştırması tarafından benimsendiğini buldu ve iyimser bir şekilde, işlevsel doğrulamadaki zorlu sorunların üstesinden gelmek için kullanıldıklarında büyük başarının mümkün olacağına inanıyoruz.
Muazzam miktarda metin külliyatı üzerinde eğitilmiş milyarlarca parametreye sahip transformatör tabanlı büyük ölçekli NL modelleri, çeşitli NL görevlerinde, örneğin soru yanıtlama, makine çevirisi, metin sınıflandırma, soyutlamalı özetleme ve insan ötesi düzeyde performans elde etti. diğerleri. Bu araştırma sonuçlarının kod analizinde uygulanması, bu modellerin büyük potansiyelini ve çok yönlülüğünü de göstermiştir. Bu modellerin gerçekten büyük bir eğitim verisi topluluğunu alabildiği, öğrenilen bilgileri yapılandırabildiği ve kolay erişilebilirlik sağlayabildiği kanıtlanmıştır. Bu yetenek, birçok popüler programlama dili için statik kod analizi, gereksinim mühendisliği ve kodlama yardımında etkilidir. Yeterli eğitim verisi verildiğinde, bu tekniklerin makine öğrenimi modellerini çeşitli işlevsel doğrulama görevleri için eğitebileceğine inanmak mantıklıdır.
Yakın zamana kadar, yapılarının karmaşıklığı nedeniyle makine öğrenimini grafik verilerine uygulamak zordu. Grafik sinir ağı (GNN) ilerlemeleri, işlevsel doğrulama için yeni bir fırsat vaat etti. Böyle bir yaklaşım, tasarımı bir kod/veri akış grafiğine dönüştürür ve bu daha sonra bir testin kapsama kapanışını tahmin etmeye yardımcı olmak için bir GNN'yi eğitmek için kullanılır. Bu tür bir beyaz kutu yaklaşımı, potansiyel kapsama boşluklarını doldurmak için yönlendirilmiş testler oluşturabilen bir tasarımdaki kontrol ve veri akışına ilişkin daha önce mevcut olmayan içgörü vaat ediyor. Grafikler, doğrulamada karşılaşılan zengin ilişkisel, yapısal ve anlamsal bilgileri temsil edebilir. Grafikler üzerinde bir makine öğrenimi modelinin eğitiminden elde edilen zengin bilgiler, hata arama ve kapsam kapatma gibi birçok yeni olası işlevsel doğrulama görevini karşılayabilir.
Sonuç
EDA 4.0, elektronik tasarım otomasyonunu yapay zekanın gücüyle dönüştürüyor ve mühendislerin Endüstri 4.0'ın devrim niteliğindeki değişikliklerini fark etmelerine yardımcı olacak birkaç önemli teknoloji sunuyor. Bu makalede, işlevsel doğrulamanın çeşitli yönlerini ele almada makine öğreniminin potansiyel katkılarına ilişkin kapsamlı bir araştırma sunuyoruz. Makale, işlevsel doğrulamada makine öğreniminin tipik uygulamalarını vurgular ve bu alandaki en son başarıları özetler.
Bununla birlikte, çeşitli makine öğrenimi tekniklerinin uygulanmasına rağmen, mevcut araştırmalar öncelikle temel makine öğrenimi yöntemlerine dayanmaktadır ve eğitim verilerinin mevcudiyeti ile sınırlıdır. Bu durum, diğer gelişmiş alanlardaki makine öğrenimi uygulamalarının ilk aşamalarını anımsatıyor ve bu da, işlevsel doğrulamadaki makine öğrenimi uygulamalarının henüz gelişme aşamasında olduğunu gösteriyor. Makine öğreniminin yeteneklerinden tam olarak yararlanmak için gelişmiş teknikler ve modellerden yararlanmaya yönelik kullanılmayan önemli bir potansiyel var. Ayrıca, günümüz makine öğrenimi uygulamalarında anlamsal, ilişkisel ve yapısal bilgilerin kullanımı hala tam olarak gerçekleştirilememiştir.
Bu konunun daha ayrıntılı bir incelemesi için sizi başlıklı teknik incelememize başvurmaya davet ediyoruz. İşlevsel Doğrulamada Makine Öğrenimi Uygulamalarına İlişkin Bir Araştırma. Bu teknik incelemede, konuyu daha derinlemesine inceliyor, endüstriyel bir bakış açısıyla içgörüler sunuyor ve sınırlı veri kullanılabilirliğinin ortaya çıkardığı acil zorluğu tartışıyoruz. Makalenin tamamı ayrıca, bu makalenin çoğunu bilgilendiren büyüleyici araştırmalara ve yazılara kapsamlı referanslar içerir.
Harry Foster, Siemens Digital Industries Software için Doğrulama Baş Bilim İnsanıdır; Verification Academy'nin Kurucu Ortağı ve Yönetici Editörüdür. Foster, 2021 Tasarım Otomasyonu Konferansı Genel Başkanı olarak görev yaptı ve şu anda Eski Başkan olarak görev yapıyor. Doğrulama konusunda birden fazla patente sahiptir ve doğrulama üzerine altı kitabın yazarlarından biridir. Foster, endüstri standartlarının geliştirilmesine yaptığı katkılardan dolayı Accellera Teknik Mükemmellik Ödülü'nün sahibidir ve Accellera Açık Doğrulama Kitaplığı (OVL) standardının orijinal yaratıcısıdır. Ayrıca Foster, 2022 ACM Seçkin Hizmet Ödülü'nün ve 2022 IEEE CEDA Üstün Hizmet Ödülü'nün sahibidir.
Tom Fitzpatrick, gelişmiş doğrulama metodolojileri, dilleri ve standartları geliştirmek için çalıştığı Siemens Digital Industries Software'de (Siemens EDA) Stratejik Doğrulama Mimarıdır. Son 25 yılda Verilog 1364, SystemVerilog 1800 ve UVM 1800.2 dahil olmak üzere işlevsel doğrulama ortamını önemli ölçüde iyileştiren çeşitli endüstri standartlarına önemli katkılarda bulunmuştur. Accellera Portable Stimulus Working Group'un kurucu üyesi ve şu anki Başkan Yardımcısıdır ve şu anda IEEE 1800 ve Accellera UVM-AMS Çalışma Gruplarının Başkanı olarak görev yapmaktadır. Fitzpatrick, DVCon US Yürütme Komitesinin uzun süredir üyesidir ve DVConUS 2024'ün Genel Başkanıdır. Aynı zamanda Tasarım Otomasyonu Konferansı Yürütme Komitesinin de bir üyesidir. Fitzpatrick, MIT'den Elektrik Mühendisliği ve Bilgisayar Bilimleri alanlarında yüksek lisans ve lisans derecelerine sahiptir.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoAiStream. Web3 Veri Zekası. Bilgi Genişletildi. Buradan Erişin.
- Adryenn Ashley ile Geleceği Basmak. Buradan Erişin.
- PREIPO® ile PRE-IPO Şirketlerinde Hisse Al ve Sat. Buradan Erişin.
- Kaynak: https://semiengineering.com/welcome-to-eda-4-0-and-the-ai-driven-revolution/

