Bu makale, Veri Bilimi Blogathon.
İşte bir sır: sentetik kontrol yöntemleri bu sorunu son derece kolay bir şekilde ve gelir veya müşteri kaybı olmadan çözebilir. Eğer bu bir deney olsaydı hipotez şu olurdu: Ödeme yöntemi olarak kartların kaldırılması geliri ve satışları etkilemeyecektir. Test tabanı, ödeme seçeneği olarak kartlara sahip olmayan müşterilerden oluşacak ve kontrol tabanı, ödeme seçeneği olarak kartlara sahip olacaktır.
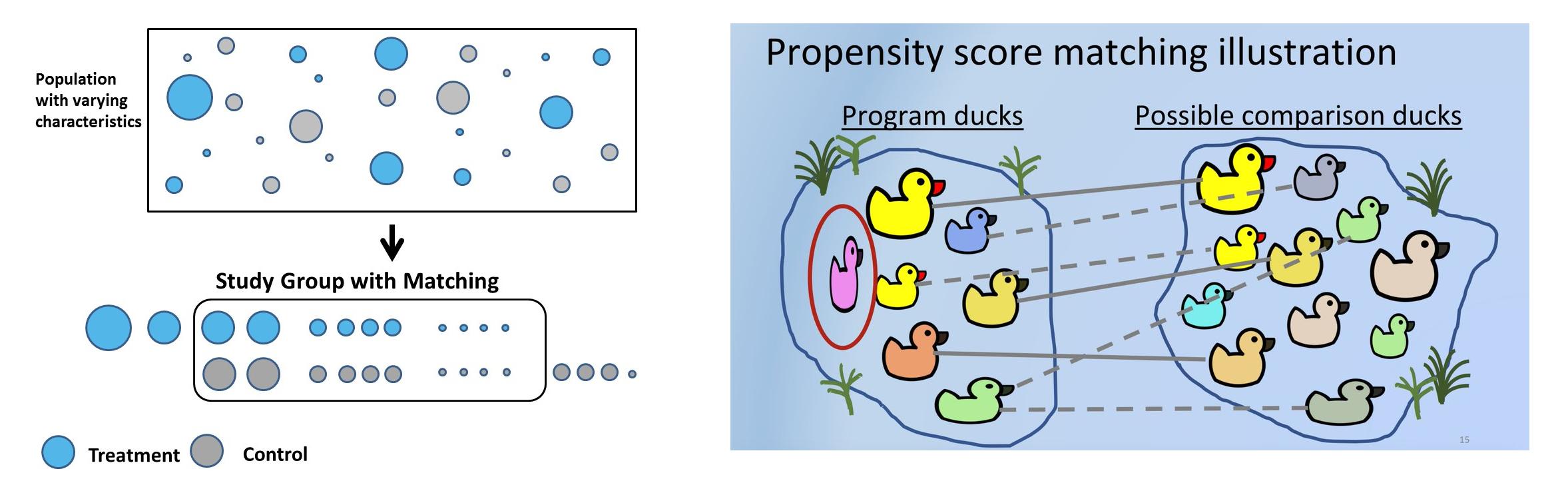
Sentetik Kontrol Yöntemi: Örnek Olay İncelemesi
Sentetik kontrol yöntemleri (SCM), basit bir ifadeyle, her test müşterisi için, ön işlem özellikleri benzer ancak işlem görmemiş, önceden tanımlanmış bir dizi özellik veya ortak değişkenler kullanan benzer bir kontrol müşterisini seçecektir. SCM'de müşterilere birimler, müdahalelere tedaviler ve özelliklere ortak değişkenler adı verilir. Şirketler SCM'yi birçok pratik kullanım durumu için kullanıyor. Örneğin Uber, yolculuk öncesinde sürücüye iletişim bilgileri sağlamanın müşteri memnuniyetini artırıp artırmadığını test etmek için SCM'yi kullandı.
Bazen hipotezler yasal, ticari veya platform nedenlerinden dolayı deneysel bir düzenekte test edilemeyebilir. Örneğin: Bangalore'da Meghana'nın biryanisi en iyilerden biridir ve çevrimiçi teslimat platformları (Swiggy veya Zomato), yüksek harcama yapan müşterilerin de Meghana'dan sipariş verme olasılığının yüksek olduğunu fark etti. Hipotez, Meghana müşterilerinin ortalama olarak diğerlerinden daha fazla harcama yaptığı yönünde. Ancak Swiggy veya Zomato, sırf deney olsun diye müşterilerin %50'sinin Meghana'larını platformdan kaldıramaz. Müşterinin yanı sıra restoranın tepkisi de olacaktır. SCM kullanılarak, test ve kontrol müşterilerinin benzer ön işlem ortak değişkenlerine sahip olduğu sentetik bir kontrol oluşturulabilir ve hipotez doğrulanabilir.
Seçim yanlılığını çözmek ve doğru kontrolü seçerken doğru iş buluşsal yöntemlerini kullanmak çok önemli hale gelir ve hatta deneylerin sonuçlarını tersine çevirebilir. Örneğin test, Meghana sipariş eden bir grup müşteriyi kapsayacak. Kontrol için vejetaryen müşteriler seçilebilir. Ancak doğası gereği test ve kontrol farklıdır, çünkü kontrol asla sebze olmayan mutfağı denememiştir. Kontrol etmenin bir başka yolu da hiç biryani sipariş etmeyen müşterilerdir, ancak Meghana's ağırlıklı olarak biryani servisi yapan bir restoran olduğundan bu uygun bir kontrol olmayacaktır. Kontrol etmenin başka bir yolu da coğrafyaları kullanmaktır. Meghana's Delhi'de bulunmadığından Delhi müşterileri kontrol olarak kullanılabilir. Ancak Delhi kullanıcılarının yemek alışkanlıkları güney Hintli kullanıcılardan farklıdır ve eğer deney yaş grubu, cinsiyet ve mutfak gibi çeşitli boyutlara bölünürse bu durum önyargıya neden olacaktır. Dolayısıyla doğru iş buluşsal yöntemi, sentetik kontrol için çözüm sunarken çok önemli bir parça haline gelir.
İçerik Tablosu
Eşleştirme kullanılarak sentetik kontroller oluşturulabilir. Eğilim puanı eşleştirme, SC oluşturmak için kullanılan en yaygın yöntemdir çünkü kolaydır, daha az zaman alır, çok fazla para tasarrufu sağlar ve geniş bir kullanıcı tabanına ölçeklenebilir, süreç en benzer teste kadar N kez tekrarlanabilir ve kontrol edilebilir. kohortlar eşleştirilir.
Eğilim puanı eşleştirmesinde yer alan adımlar:
- Büyük bir müşteri grubu seçin (yaş, cinsiyet, satışlar, birimler vb.). Bunlar önyargıya neden olabilecek ortak değişkenlerdir.
- Ana amaç, müdahaleden önce ortak değişkenleri eşleştirmektir. Kontrolde kredi kartı kullanarak ödeme yapan her müşteri için (test müşterisi), ön işlem ortak değişkenleri testtekine benzer olan ancak kart kullanarak ödeme yapmayan ancak bunun yerine UPI veya internet bankacılığı kullanan bir müşterinin olması gerekir.
- Eğilim puanlarını elde etmek için sınıflandırma modelini uygun hale getirin. Tahmin edilen olasılıklar farklı kullanıcıları eşleştirmek için kullanıldığından doğruluk önemli değildir. Ağaç tabanlı veya lojistik regresyon kullanılabilir. Ağaç tabanlı yöntemin avantajı, lojistik regresyonun varsayımlarının göz ardı edilebilmesidir.
- Olasılık puanı kullanılarak, diyelim ki 0.6 ve 0.61, k en yakın komşu kullanılarak eşleştirilebilir. Eşleştirme, kopyaların kullanıldığı 1:1 veya 1:çok olabilir.
- Şimdi tedavinin sonucu nasıl etkilediğini araştırın. Tedavi ikili, 1 veya 0'dır. Sipariş edilen Meghana olsun veya olmasın, kart kullanılmış olsun veya olmasın. Ancak sonuç ya sürekli olabilir - gelecekteki gelir ya da ikili - kesintiye uğramış ya da değişmemiş vb.
Sorun bildirimi
Burada kullanılan veri kümesi aşağıdakilere dayanmaktadır: müşteri ödeme geçmişi. Banka kartı sorun bildiriminden bir ipucu alarak konuyu detaylandıralım.
Hipotez: H0: Kartla ödeme yapan müşterilerin posta gelirleri daha yüksektir. Alternatif hipotez: H1: Kartlarla ödeme yapan müşterilerin posta gelirleri daha yüksek değildir (dolayısıyla, kart ödemelerini platformdan tamamen kaldırmaya yönelik deney). P<0.05 ise sıfır hipotezini reddedebiliriz ve sonuç olarak kartlarla ödeme yapan müşterilerin posta gelirinin daha yüksek olmadığını söyleyebiliriz.
Burada üç zaman dilimi vardır: Özelliklerin/ortak değişkenlerin dayandığı ön dönem. Müşterilerin kart kullanarak ödeme yaptığı tedavi dönemi. Sonucun (bu durumda gelir sonrası) ölçüldüğü post dönemi. Bu dönemlerin dikkatli bir şekilde seçilmesi, etkinlik yanlılığından kaçınmak ve bu süre zarfında herhangi bir tanıtım etkinliğinin planlanmadığından ve yürütülmediğinden emin olmak açısından önemlidir. Örneğin Ekim-Kasım aylarında bayram ve banka ortaklarından gelen para iadesi nedeniyle kullanıcılar 500'den 5000'e kadar indirim sunan kredi kartlarını tercih ediyor. Analiz için bu sürenin dikkate alınması, sonuçları açıkça saptıracaktır.
Bu analizin amacına uygun olarak, ön dönemin Ocak'21 ila Haziran'21 olduğunu ve modeli eğitmek için kullanılan ortak değişkenlerin bu dönemden türetildiğini varsayalım. Tedavi, tedavi süresi boyunca banka/kredi kartlarını kullanır ve bu, modelin bağımlı değişkenidir. Tedavi periyodunun temmuz ayının ilk haftası olduğunu, periyot sonrası sonucun ise sonraki 30 gün olduğunu düşünelim.
Bu veri kümesinin Keşif Amaçlı Veri Analizi güncellendi okuyun.
Veri Ön İşleme
- Veri kümesini okuyun ve alakasız özellikleri bırakın. kart_ödeme bağımlı değişken:
df_fintec = pd.read_csv("https://raw.githubusercontent.com/chrisdmell/Project_DataScience/working_branch/07_cred/Analytics%20Assignment/data_for_churn_analiz.csv") cols_basic_model = ['kart_sayısı', 'ödeme_başlatıldı', 'ödeme_başarısız oldu', ' Payments_completed', 'payments_completed_amount_first_7days', 'reward_purchase_count_first_7days', 'coins_redeemed_first_7days', 'is_referral', 'visits_feature_1', 'visits_feature_2', 'given_permission_1', 'given_permission_2'] df_fintec_LR = df_fintec[cols_ basic_model] df_fintec_LR["is_referral"] = df_fintec_LR[ "is_referral"].astype(int) df_fintec_LR.fillna(0, inplace = Doğru) oh_cols = ["is_referral", "given_permission_1", "given_permission_2"] df_fintec_LR.drop(columns = oh_cols, inplace = Doğru)
Çıktıyı görmek için Çalıştır'a basın
- Tren testi bölme ve ölçeklendirme özelliklerini hazırlayın (catboost, özellik standardizasyonu olmadan da çalışır):
df_fintec = df_fintec.rename(columns={'is_churned': 'card_payment'}) X_train, X_test, y_train, y_test = train_test_split(df_fintec_LR, df_fintec[["card_payment"]],random_state = 70, test_size=0.30) ölçekleyici = StandardScaler () Scaler.fit(X_train) X_train_Scaled = Scaler.transform(X_train) X_test_Scaled = Scaler.transform(X_test) X, y =X_train_Scaled ,y_train
Modelleme
- Eğilim puanıyla daha çok ilgilendiğimiz için basit bir model kullanın:
clf = CatBoostClassifier( yinelemeler=5, öğrenme_oranı=0.1, #loss_function='CrossEntropy' ) clf.fit(X_train, y_train, ayrıntılı=False) y_pred = clf.predict(X_test, tahmin_tipi='Olasılık') y_pred y_pred_df = pd. DataFrame(y_pred,columns = ["sıfır", "bir"]) y_pred_df.head() df_test = pd.concat([X_test.reset_index(drop=True), y_test.reset_index(drop=True)], axis=1 ) df_test = pd.concat([df_test.reset_index(drop=True), y_pred_df[["one"]].reset_index(drop=True)], axis=1) df_test['gelir'] = np.random.randint (0,50000, size=len(df_test)) display(df_test.head()) sns.histplot(data=df_test, x='one', hue='card_payment') # multiple="dodge" for
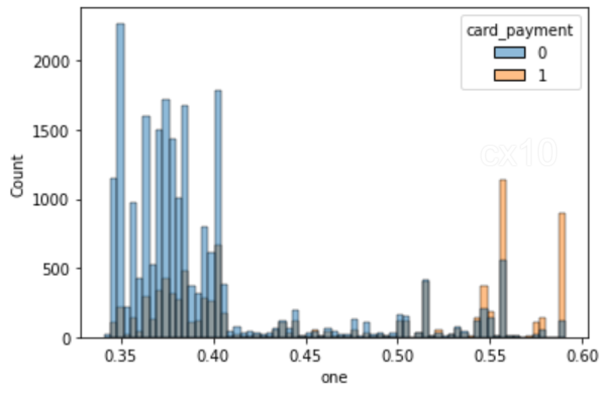
Histogramda görüldüğü gibi net örtüşme alanları vardır, dolayısıyla PSM kullanılarak benzer birimler elde edilebilir. Aralarında genel bir uyum yoksa eşleşme bulmak mümkün değildir.
NearestNeighbors kullanarak eşleştirme
- NearestNeighbors kullanarak eşleştirme.
sklearn.neighbors'tan import NearestNeighbors pergel = np.std(df_test.one) * 0.25 print(f'kumpas (yarıçap) is: {kumpas:.4f}') n_neighbors = 10 # setup knn knn = NearestNeighbors(n_neighbors=n_neighbors, radius=caliper) ps = df_test[['one']] # veri çerçevesi olarak çift parantez knn.fit(ps)
# mesafeler ve indeksler mesafeler, komşu_indexes = knn.kneighbors(ps) print(komşu_indexes.shape) # ilk noktaya en yakın 10 nokta print(mesafeler[0]) print(komşu_indexes[0])
# tedavideki her nokta için, değiştirmeden kontrolde eşleşen bir nokta buluyoruz # 10 komşunun hem tedavi hem de kontrol noktalarını içerebileceğine dikkat edin matched_control = [] # current_index için kontroldeki eşleşen gözlemleri takip edin, df_test.iterows satırında (): # veri çerçevesi üzerinde yineleme if row.card_payment == 0: # geçerli satır kontrol grubundadır df_test.loc[current_index, 'matched'] = np.nan # nan ile eşleştirilmiş set else: komşu_indexes'teki idx için [current_index, :]: # tedavideki her satır için k komşuyu bulun # mevcut satırın idx olmadığından emin olun - kendisiyle eşleşmeyin # ve komşu kontrolde ise if (current_index != idx) ve (df_test.loc[idx].card_payment == 0): eğer idx matched_control'de değilse: # bu kontrol henüz eşleştirilmedi df_test.loc[current_index, 'matched'] = idx # eşleşen matched_control.append(idx)'i kaydedin # eşleşenleri liste sonuna ekle
# daha fazla eşleşme elde etmek için komşuların ve/veya pergel sayısını artırmaya çalışın print('tedavideki toplam gözlemler:', len(df_test[df_test.card_payment==1])) print('kontroldeki toplam eşleşen gözlemler:', len(matched_control))
Tedavide toplam gözlemler: 8988
kontroldeki toplam eşleşen gözlemler: 1296
# kontrolün eşleşmesi yoktreatment_matched = df_test.dropna(subset=['matched']) # drop eşleşmedi # eşleşen kontrol gözlem indeksleri control_matched_idx =treatment_matched.matched control_matched_idx = control_matched_idx.astype(int) # int olarak değiştirin control_matched = df_test.loc [control_matched_idx, :] # eşleşen kontrol gözlemlerini seçin # eşleşen tedaviyi ve kontrolü birleştirin df_matched = pd.concat([treatment_matched, control_matched]) df_matched.card_payment.value_counts()
1 1296
0 1296
Ad: kart_ödeme, dtype: int64
sns.histplot(data=df_matched, x='number_of_cards', hue='card_payment') sns.histplot(data=df_matched, x='payments_completed_amount_first_7days', hue='card_payment')
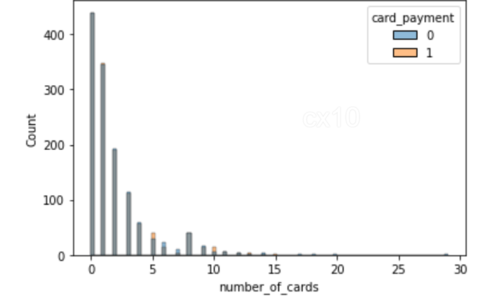
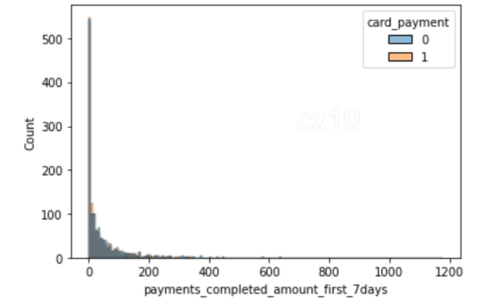
2 histogramdan, eğilim sonrası eşleşmede, ortak değişkenlerin dağılımının 2 özellik için neredeyse aynı olduğu açıktır - kart sayısı ve tamamlanan ödemelerin sayısı ilk yedi günde. Aynı şey diğer özellikler için de çizilebilir.
Öncesi ve Sonrası
Ortak değişkenlerin önceki ve sonraki dağılımı SD'de önemli farklılıklar göstermelidir; ancak o zaman eşleştirmenin etkili olduğu sonucuna varılabilir.
numpy'den içe aktarma, numpy'den içe aktarmanın ortalaması matematik içe aktarmadan var sqrt # bağımsız örnekler için Cohen'in d'sini hesaplayan işlev def cohen_d(d1, d2): # örneklerin boyutunu hesapla n1, n2 = len(d1), len(d2) # hesapla örneklerin varyansı s1, s2 = var(d1, ddof=1), var(d2, ddof=1) # birleştirilmiş standart sapmayı hesapla s = sqrt(((n1 - 1) * s1 + (n2 - 1) * s2) / (n1 + n2 - 2)) # örneklerin ortalamasını hesapla u1, u2 = ortalama(d1), ortalama(d2) # etki büyüklüğü getirisini hesapla (u1 - u2) / s
effect_sizes = [] cols = list(X_train.columns) # t-testi için ayrı kontrol ve işlem df_control = df_fintec[df_fintec.card_payment==0] df_treatment = df_fintec[df_fintec.card_payment==1] sütunlarda cl için: _, p_before = ttest_ind(df_control[cl], df_treatment[cl]) _, p_after = ttest_ind(df_matched_control[cl], df_matched_treatment[cl]) cohen_d_before = cohen_d(df_treatment[cl], df_control[cl]) cohen_d_after = cohen_d(df_matched_treatment[ cl], df_matched_control[cl]) effect_sizes.append([cl,'before', cohen_d_before, p_before]) effect_sizes.append([cl,'after', cohen_d_after, p_after])
df_fect_sizes = pd.DataFrame(efekt_sizes, sütunlar=['özellik', 'eşleştirme', 'etki_boyutu', 'p-değeri']) fig, ax = plt.subplots(figsize=(15, 5)) sns.barplot( data=df_fect_sizes, x=' effect_size', y='feature', hue='matching', orient='h')
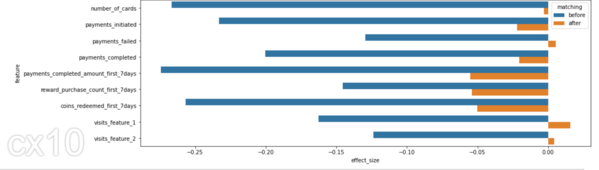
Cohen'in D'si veya standartlaştırılmış ortalama farkı, etki büyüklüğünü ölçmenin en yaygın yollarından biridir. Eşleştirmeden önce test ve kontrol arasındaki SD farkı daha yüksektir (mavi çubuklar). Eşleştirme sonrasında SD farkının daha düşük olması, tedavi süresi öncesinde test ve kontrolün benzer dağılımlara sahip olduğunu göstermektedir.
Tedavinin Etkisini Ölçmek İçin İstatistiksel Test
İki grubun ortalamalarını karşılaştırmak için öğrenciler T-testi yapar. Dönem sonrası elde tutma veya kayıp olması durumunda Ki-Kare Testi kullanılabilir.
# öğrencinin gelir için t testi (bağımlı değişken) eşleştirmeden sonra # p değeri artık anlamlı değil scipy.stats'tan import ttest_ind print(df_matched_control.revenue.mean(), df_matched_treatment.revenue.mean()) # örnekleri karşılaştır _, p = ttest_ind(df_matched_control.revenue, df_matched_treatment.revenue) print(f'p={p:.3f}') # yorum alfa = 0.05 # anlamlılık düzeyi if p > alpha: print('aynı dağılımlar/aynı grup ortalaması (başarısız) H0'ı reddet - H0'ı reddetmek için yeterli kanıtımız yok)') else: print('farklı dağılımlar/farklı grup ortalaması (H0'ı reddet)')
25105.91898148148 24040.162037037036
p = 0.062
aynı dağılımlar/aynı grup ortalaması (H0'ı reddetmede başarısız – H0'ı reddetmek için yeterli kanıtımız yok)
P değeri > 0.05 olduğundan sıfır hipotezini reddedemiyoruz, dolayısıyla kartlarla ödeme yapan müşterilerin posta gelirleri daha yüksek oluyor. Böylece bu yeni özelliğin oluşturulması için harcanacak zamandan ve kaynaklardan tasarruf sağlandı.
En Yakın Komşuları Kullanarak Eşleşmenin Başka Bir Yolu
PSM dışında başka eşleştirme yöntemleri de vardır. Aynı şey için bir kod pasajı.
sklearn.preprocessing'den StandardScaler'ı sklearn.neighbors'tan içe aktarın NearestNeighbors def get_matching_pairs(tedavi edilen_df, non_treated_df, Scaler=True): Treat_x = Treated_df.values non_treated_x = non_treated_df.values if Scaler == True: Scaler = StandardScaler() if Scaler: Scaler. fit(tedavi edilen_x) tedavi edilen_x = Scaler.transform(muamele edilen_x) non_treated_x = Scaler.transform(non_treated_x) nbrs = En Yakın Komşular(n_neighbors=1, algoritma='ball_tree').fit(non_treated_x) mesafeler, indices = nbrs.kneighbors(tedavi edilen_x) endeksleri = indices.reshape(indices.shape[0]) eşleşti = non_treated_df.iloc[indices] dönüş eşleşti
pandaları pd olarak içe aktar numpy'yi np olarak içe aktar matplotlib.pyplot'u plt olarak içe aktar Treat_df = pd.DataFrame() np.random.seed(1) size_1 = 200 size_2 = 1000 Treat_df['x'] = np.random.normal(0,1, 1,size=size_50,20) işlenmiş_df['y'] = np.random.normal(1,size=size_0,100) işlenmiş_df['z'] = np.random.normal(1,size=size_0,3) non_treated_df = pd. DataFrame() # iki farklı popülasyon non_treated_df['x'] = list(np.random.normal(2,size=size_1,2)) + list(np.random.normal(-2,size=2*size_50,30) )) non_treated_df['y'] = list(np.random.normal(2,size=size_100,2)) + list(np.random.normal(-2,size=2*size_0,200)) non_treated_df[' z'] = list(np.random.normal(2,size=size_13,200)) + list(np.random.normal(2,size=2*size_6,6)) matched_df = get_matching_pairs(tedavi edilen_df, non_treated_df) fig, ax = plt .subplots(figsize=(0.3)) plt.scatter(non_treated_df['x'], non_treated_df['y'], alpha=1,2, label='Tümü tedavi edilmeyen') plt.scatter(treated_df['x) '], tedavi edilen_df['y'], label='İşlem gören') plt.scatter(eşleşen_df['x'], eşleşen_df['y'], marker='x', etiket='eşleşen') plt.legend( ) plt.xlim(-XNUMX)
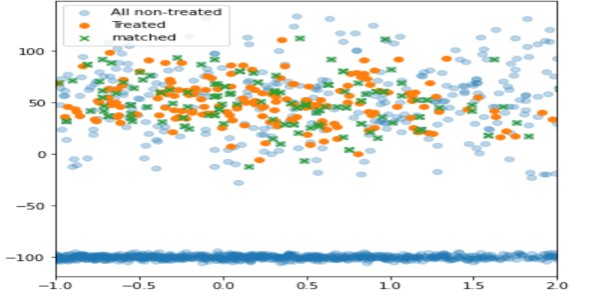
Bu tekniği kullanarak, yalnızca tedavi edilene yakın olan, tedavi edilmeyen birimler eşleştirilir (yeşil), geri kalanı dışarıda bırakılır (açık mavi).
psmpy – Python Eğilim Puanı Eşleştirme Kütüphanesi
PSMPY, PSM'yi basitleştirerek etkili bir şekilde yalnızca 10 kod satırına indirir. Model oluşturma, eşleştirme ve ölçeklendirme çerçeve tarafından gerçekleştirilir. Bir dezavantajı, 50'den fazla birim için zayıf ölçeklendirilmesidir.
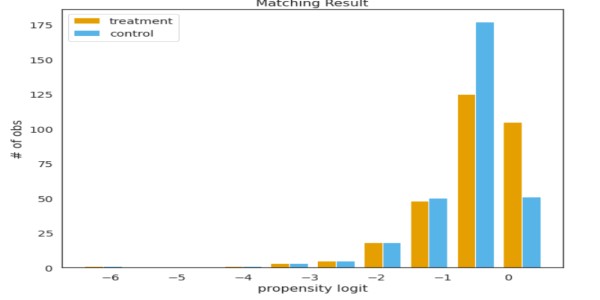
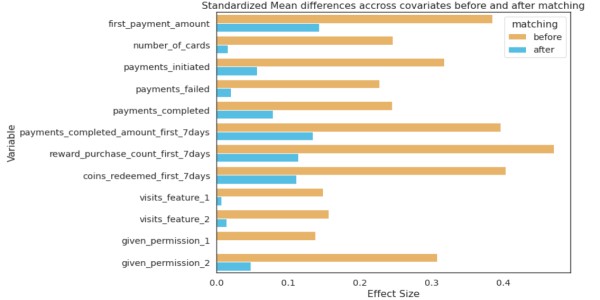
psmpy'den import PsmPy psmpy.plotting'den import * df_fintec.fillna(0, inplace = True) psm = PsmPy(df_fintec,treatment='card_payment', indx='user_id', exclusion = ['is_referral', 'age', ' city', 'device']) # Balance=False psm.logistic_ps(balance=False) psm.predicted_data psm.knn_matched(matcher='propensity_logit', replacement=False, caliper=None) psm.plot_match( kullanan kodumla aynı Title='Eşleşen Sonuç', Ylabel='obs sayısı', Xlabel= 'eğilim logit', nameler = ['tedavi', 'kontrol']) display(psm.fect_size) psm.fect_size_plot()
Dezavantajları
Bunların ortak değişken değerleri, aynı eğilim puanlarına sahip iki kişi için aynı olmayacaktır. PSM, kohortlar arasındaki ortak değişkenlerin ortalama değerlerini etkili bir şekilde dengeler. Temel olarak, test ve kontroldeki kart sayısının ortalaması aynıysa ancak aynı eğilim değerlerine sahip iki kullanıcı seçilirse bunların ortak değişkenleri farklı olacaktır.
Ortak değişkenlerin sayısı arttıkça boyutluluğun laneti eşleşmeyi etkileyerek şansı neredeyse sıfıra indirir.
Sonuç
- Doğal önyargıyı kontrol etmek iyi sonuçlara yol açabilir.
- Eldeki soruna göre uygun dönem öncesi ortak değişkenleri seçin.
- Hipotezin iş zekası ve verilerle desteklenmesi gerekiyor.
Aşağıdaki yorumlar bölümünde PSM'nin diğer kullanım durumlarını bana bildirin.
İyi şanlar! işte benim Linkedin Benimle bağlantı kurmak istiyorsanız veya makaleyi geliştirmeye yardımcı olmak istiyorsanız profilime bakın. Veri bilimi ve analitik hakkındaki diğer makalelerime göz atın okuyun.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2022/12/introduction-to-synthetic-control-using-propensity-score-matching/

