
Image Freepik
Doğal Dil İşleme veya NLP, makinelerin metin verilerini anlama yeteneğine sahip olmasını sağlayan yapay zeka kapsamındaki bir alandır. NLP araştırması uzun süredir varlığını sürdürüyor ancak son zamanlarda büyük verilerin ve daha yüksek hesaplamalı işlem gücünün kullanıma sunulmasıyla daha da öne çıktı.
NLP alanının büyümesiyle birlikte birçok araştırmacı, makinenin metinsel verileri daha iyi anlama yeteneğini geliştirmeye çalışacak. Pek çok ilerleme sayesinde, NLP alanında birçok teknik önerilmiş ve uygulanmıştır.
Bu makale, NLP alanındaki metin verilerinin işlenmesine yönelik çeşitli teknikleri karşılaştıracaktır. Bu makale RNN, Transformers ve BERT'i tartışmaya odaklanacaktır çünkü araştırmalarda sıklıkla kullanılan RNN'dir. Hadi konuya girelim.
Tekrarlayan Sinir Ağı veya RNN 1980'de geliştirildi ancak NLP alanında ancak yakın zamanda ilgi görmeye başladı. RNN, sıralı veriler veya birbirinden bağımsız olamayan veriler için kullanılan sinir ağı ailesi içindeki özel bir türdür. Sıralı veri örnekleri, zaman serileri, ses veya metin cümlesi verileridir; temel olarak anlamlı sıraya sahip her türlü veridir.
RNN'ler, bilgiyi farklı şekilde işledikleri için normal ileri beslemeli sinir ağlarından farklıdır. Normal ileri beslemede bilgi katmanlar takip edilerek işlenir. Ancak RNN, bilgi girişinde dikkate alınarak bir döngü döngüsü kullanıyor. Farklılıkları anlamak için aşağıdaki resme bakalım.
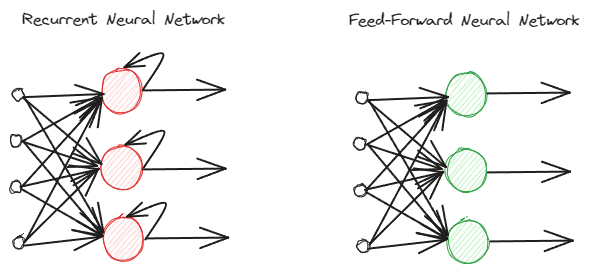
Yazara göre resim
Gördüğünüz gibi RNN modeli, bilgi işleme sırasında bir döngü döngüsü uygular. RNN'ler bu bilgiyi işlerken mevcut ve önceki veri girişini dikkate alacaktır. Bu nedenle model her türlü sıralı veri için uygundur.
Metin verilerinde örnek alırsak, “sabah 7’de uyanıyorum” cümlesinin olduğunu ve giriş olarak da kelimemizin olduğunu düşünün. İleri beslemeli sinir ağında "yukarı" kelimesine ulaştığımızda model zaten "ben", "uyan" ve "yukarı" kelimelerini unutacaktır. Ancak, RNN'ler her kelime için her çıktıyı kullanacak ve modelin unutmaması için bunları geri döngüye alacaktı.
NLP alanında, RNN'ler genellikle metin sınıflandırma ve oluşturma gibi birçok metinsel uygulamada kullanılır. Genellikle Konuşmanın Kısmı etiketleme, yeni kelime oluşturma vb. gibi kelime düzeyindeki uygulamalarda kullanılır.
RNN'lere metinsel veriler üzerinde daha derinlemesine bakıldığında, birçok RNN türü vardır. Örneğin, aşağıdaki görüntü çoktan çoğa türleridir.
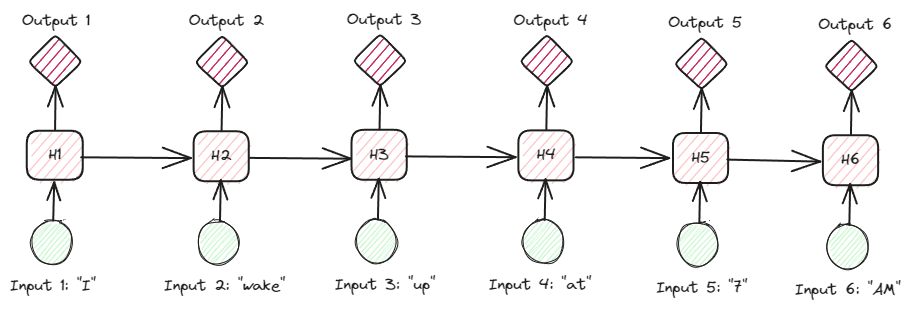
Yazara göre resim
Yukarıdaki görüntüye baktığımızda, her adıma (RNN'deki zaman adımı) ilişkin çıktının her seferinde bir adım işlendiğini ve her yinelemenin her zaman önceki bilgileri dikkate aldığını görebiliriz.
Birçok NLP uygulamasında kullanılan bir diğer RNN türü, kodlayıcı-kod çözücü türüdür (Sıradan Sıraya). Yapı aşağıdaki resimde gösterilmektedir.
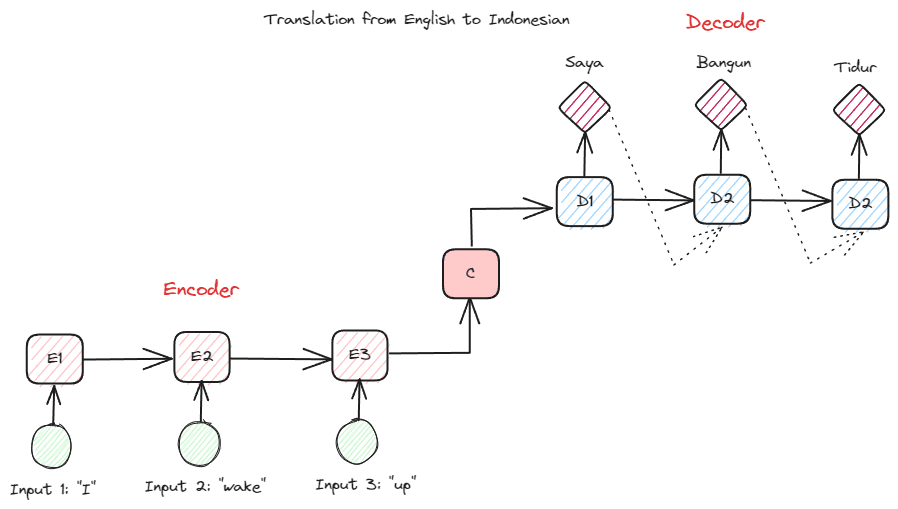
Yazara göre resim
Bu yapı modelde kullanılan iki parçayı tanıtmaktadır. İlk bölüme, veri dizisini alan ve buna dayalı olarak yeni bir gösterim oluşturan bölüm olan Encoder adı verilir. Gösterim, modelin ikinci kısmı olan kod çözücüde kullanılacaktır. Bu yapıyla giriş ve çıkış uzunluklarının mutlaka eşit olması gerekmez. Örnek kullanım durumu, genellikle giriş ve çıkış arasında aynı uzunluğa sahip olmayan bir dil çevirisidir.
Doğal dil verilerini işlemek için RNN'leri kullanmanın aşağıdakiler dahil çeşitli faydaları vardır:
- RNN, uzunluk sınırlaması olmaksızın metin girişini işlemek için kullanılabilir.
- Model tüm zaman adımlarında aynı ağırlıkları paylaşıyor ve bu da sinir ağının her adımda aynı parametreyi kullanmasına olanak tanıyor.
- Geçmiş girişlerin hafızasına sahip olmak, RNN'yi herhangi bir sıralı veri için uygun kılar.
Ancak birkaç dezavantajı da var:
- RNN hem kaybolan hem de patlayan gradyanlara karşı hassastır. Bu, gradyan sonucunun sıfıra yakın bir değer olduğu (kaybolduğu), ağ ağırlığının yalnızca küçük bir miktar için güncellenmesine neden olduğu veya gradyan sonucunun o kadar önemli olduğu (patlayan) ve ağa gerçekçi olmayan çok büyük bir önem verdiği yerdir.
- Modelin sıralı yapısından dolayı uzun eğitim süresi.
- Kısa süreli hafıza, model ne kadar uzun süre eğitilirse modelin unutmaya başlaması anlamına gelir. RNN'nin bir uzantısı var LSTM Bu sorunu hafifletmek için.
Transformers, daha önce RNN'lerde karşılaşılan diziden diziye görevleri çözmeye çalışan bir NLP model mimarisidir. Yukarıda belirtildiği gibi RNN'lerin kısa süreli hafızayla ilgili sorunları vardır. Giriş ne kadar uzun olursa, modelin bilgiyi unutması da o kadar belirgin oluyor. Dikkat mekanizmasının sorunun çözümüne yardımcı olabileceği yer burasıdır.
Makalede dikkat mekanizması şu şekilde tanıtılmaktadır: Bahdanau ve diğerleri. (2014) Özellikle kodlayıcı-kod çözücü tipi RNN'lerde uzun giriş problemini çözmek için. Dikkat mekanizmasını ayrıntılı olarak açıklamayacağım. Temel olarak, modelin çıktı tahminini yaparken model girdisinin kritik kısmına odaklanmasını sağlayan bir katmandır. Örneğin, eğer görev çeviri içinse, "Saat" sözcüğü girişi Endonezcedeki "Jam" ile yüksek düzeyde ilişkili olacaktır.
Transformatörler modeli tarafından tanıtıldı Vasvani ve ark. (2017). Mimari, kodlayıcı-kod çözücü RNN'den ilham alınarak dikkat mekanizması göz önünde bulundurularak oluşturulmuştur ve verileri sıralı bir şekilde işlemez. Genel transformatör modeli aşağıdaki resimdeki gibi yapılandırılmıştır.
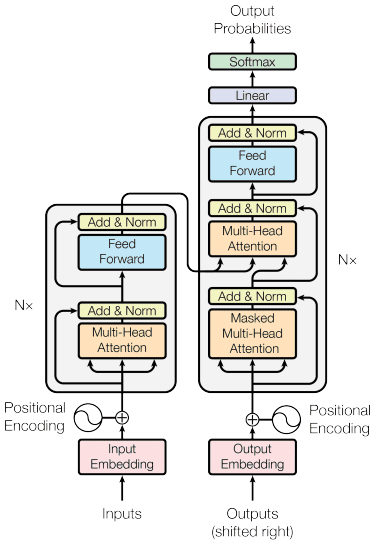
Transformatör Mimarisi (Vasvani ve diğerleri. 2017)
Yukarıdaki yapıda transformatörler, verileri orijinal forma dönüştürmek için kod çözmeyi kullanırken, konumsal kodlama yerinde olacak şekilde veri vektör dizisini kelime yerleştirmeye kodlar. Dikkat mekanizmasının devreye girmesiyle girdiye göre kodlamaya önem verilebilir.
Transformatörler diğer modele kıyasla birkaç avantaj sağlar:
- Paralelleştirme işlemi eğitim ve çıkarım hızını artırır.
- Bağlamın daha iyi anlaşılmasını sağlayan daha uzun girdileri işleyebilme
Transformatör modelinin hala bazı dezavantajları vardır:
- Yüksek hesaplamalı işleme ve talep.
- Dikkat mekanizması, kaldırabileceği uzunluk sınırı nedeniyle metnin bölünmesini gerektirebilir.
- Bölme yanlış yapılırsa bağlam kaybolabilir.
Bert
BERT veya Transformatörlerden Çift Yönlü Kodlayıcı Gösterimleri, tarafından geliştirilen bir modeldir. Devlin ve ark. (2019) modeli oluşturmak için iki adım (ön eğitim ve ince ayar) içerir. Karşılaştırma yaparsak, BERT bir transformatör kodlayıcı yığınıdır (BERT Base'de 12 Katman bulunurken BERT Large'da 24 katman bulunur).
BERT'in genel model gelişimi aşağıdaki resimde gösterilebilir.
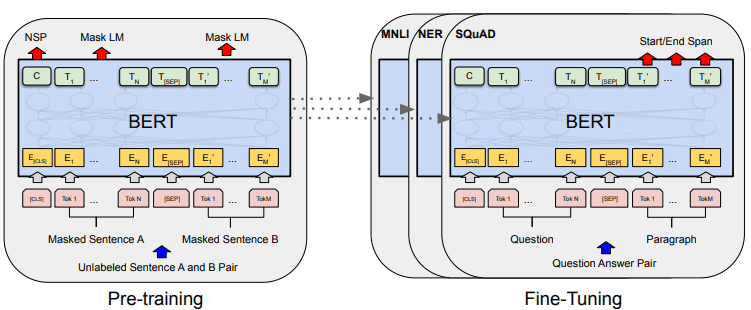
BERT genel prosedürleri (Devlin ve ark. (2019)
Eğitim öncesi görevler, aynı anda modelin eğitimini başlatır ve tamamlandığında model, çeşitli alt görevler (soru cevaplama, sınıflandırma vb.) için ince ayar yapılabilir.
BERT'i özel kılan şey, metin verileri üzerinde önceden eğitilmiş ilk denetimsiz çift yönlü dil modeli olmasıdır. BERT daha önce Vikipedi'nin tamamı ve 3000 milyondan fazla kelimeden oluşan kitap külliyatı hakkında önceden eğitim almıştı.
BERT çift yönlü olarak kabul edilir çünkü veri girişini sırayla (soldan sağa veya tam tersi) okumaz, ancak transformatör kodlayıcı tüm diziyi aynı anda okur.
Metin girişini sırayla okuyan (soldan sağa veya sağdan sola) yönlü modellerin aksine, Transformer kodlayıcı tüm kelime dizisini aynı anda okur. Bu nedenle model çift yönlü olarak kabul edilir ve modelin girdi verilerinin tüm bağlamını anlamasına olanak tanır.
Çift yönlü olmak için BERT iki teknik kullanır:
- Maske Dili Modeli (MLM) — Kelime maskeleme tekniği. Teknik, giriş kelimelerinin %15'ini maskeleyecek ve bu maskelenmiş kelimeyi, maskelenmemiş kelimeye dayalı olarak tahmin etmeye çalışacaktır.
- Sonraki Cümle Tahmini (NSP) — BERT cümleler arasındaki ilişkiyi öğrenmeye çalışır. Model, veri girişi olarak cümle çiftlerine sahiptir ve sonraki cümlenin orijinal belgede bulunup bulunmadığını tahmin etmeye çalışır.
BERT'i NLP alanında kullanmanın birkaç avantajı vardır:
- BERT'in önceden eğitilmiş çeşitli NLP aşağı yönlü görevleri için kullanımı kolaydır.
- Çift yönlü, BERT'in metin içeriğini daha iyi anlamasını sağlar.
- Topluluktan çok fazla destek alan popüler bir model
Bununla birlikte, aşağıdakiler de dahil olmak üzere hala birkaç dezavantaj vardır:
- Bazı alt görev ince ayarları için yüksek hesaplama gücü ve uzun eğitim süresi gerektirir.
- BERT modeli, çok daha büyük depolama gerektiren büyük bir modelle sonuçlanabilir.
- Basit görevlerin performansı, daha basit modellerin kullanılmasından çok farklı olmadığından, karmaşık görevler için kullanılması daha iyidir.
NLP son zamanlarda daha da ön plana çıktı ve birçok araştırma uygulamaların iyileştirilmesine odaklandı. Bu yazıda sıklıkla kullanılan üç NLP tekniğini tartışıyoruz:
- RNN
- Transformers
- Bert
Tekniklerin her birinin avantajları ve dezavantajları vardır, ancak genel olarak modelin daha iyi bir şekilde geliştiğini görebiliriz.
Cornellius Yudha Wijaya bir veri bilimi müdür yardımcısı ve veri yazarıdır. Allianz Endonezya'da tam zamanlı çalışırken, sosyal medya ve yazılı medya aracılığıyla Python ve Veri ipuçlarını paylaşmayı seviyor.
Cornellius Yudha Wijaya bir veri bilimi müdür yardımcısı ve veri yazarıdır. Allianz Endonezya'da tam zamanlı çalışırken, sosyal medya ve yazılı medya aracılığıyla Python ve Veri ipuçlarını paylaşmayı seviyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/comparing-natural-language-processing-techniques-rnns-transformers-bert?utm_source=rss&utm_medium=rss&utm_campaign=comparing-natural-language-processing-techniques-rnns-transformers-bert

