Güvenli, sağlam ve eşitlikçi yapay zeka modellerini eğitmenin gerekliliği hakkında çok konuşulsa da veri bilimcilerin bu hedeflere ulaşması için çok az araç kullanıma sunuldu. Sonuç olarak, üretim sistemlerindeki Doğal Dil İşleme (NLP) modellerinin cephe hattı, içler acısı bir durumu yansıtıyor.
Mevcut NLP sistemleri sıklıkla ve sefil bir şekilde başarısız oluyor. [Ribiero 2020], en iyi üç bulut sağlayıcısının duyarlılık analizi hizmetlerinin, nötr sözcükleri değiştirirken %9-16 oranında, tarafsız adlandırılmış varlıkları değiştirirken %7-20 oranında, zamansal testlerde %36-42 oranında başarısız olduğunu gösterdi ve bazı olumsuzlama testlerinde zamanın neredeyse %100'ü. [Şarkı ve Raghunathan 2020], kişisel bilgilerin %50-70'inin popüler kelime ve cümle yerleştirmelerine veri sızdırdığını gösterdi. [Parrish et. al. 2021] ırk, cinsiyet, fiziksel görünüm, engellilik ve din hakkındaki önyargıların son teknoloji soru yanıtlama modellerine nasıl yerleştiğini - bazen olası yanıtı zamanın %80'inden fazla değiştirdiğini gösterdi. [Van Aken et. al. 2022], bir hasta notuna herhangi bir etnik köken ifadesinin eklenmesinin tahmin edilen ölüm riskini nasıl azalttığını gösterdi - en doğru model en büyük hatayı üretiyor.
Kısacası bu sistemler çalışmıyor. Sadece bazı sayıları doğru toplayan bir hesap makinesini veya koyduğunuz yiyeceğin türüne veya günün saatine göre gücünü rastgele değiştiren bir mikrodalgayı asla kabul etmeyiz. İyi tasarlanmış bir üretim sistemi, ortak girdiler üzerinde güvenilir bir şekilde çalışmalıdır. Sıra dışı olanları tutarken de güvenli ve sağlam olmalıdır. Yazılım mühendisliği, oraya ulaşmamıza yardımcı olacak üç temel ilke içerir.
İlk olarak, yazılımınızı test edin. Bugün NLP modellerinin neden başarısız olduğuna dair tek şaşırtıcı şey, cevabın bayağılığı: çünkü kimse onları test etmedi. Yukarıda belirtilen makaleler, ilkler arasında oldukları için yeniydi. Çalışan yazılım sistemleri sunmak istiyorsanız, bunun ne anlama geldiğini tanımlamanız ve üretime dağıtmadan önce işe yarayıp yaramadığını test etmeniz gerekir. NLP modelleri de gerilediğinden, yazılımı her değiştirdiğinizde bunu da yapmalısınız [Xie et. al. 2021].
İkinci olarak, akademik modelleri üretime hazır modeller olarak yeniden kullanmayın. NLP'deki bilimsel ilerlemenin harika bir yönü, çoğu akademisyenin modellerini herkese açık ve kolayca yeniden kullanılabilir hale getirmesidir. Bu, araştırmayı daha hızlı hale getirir ve aşağıdakiler gibi karşılaştırmalı değerlendirmeler sağlar: Süper yapıştırıcı, LM-Demeti, ve BÜYÜK tezgah. Ancak, araştırma sonuçlarını çoğaltmak için tasarlanan araçlar, üretimde kullanım için uygun değildir. Tekrar üretilebilirlik, modellerin güncel kalmasını veya zaman içinde daha sağlam kalmasını sağlamak yerine aynı kalmasını gerektirir. Yaygın bir örnek BioBERT, 2019'un başlarında yayınlanan ve bu nedenle COVID-19'u kelime dağarcığı dışı bir kelime olarak gören, belki de en yaygın kullanılan biyomedikal yerleştirme modeli.
Üçüncü olarak, doğruluğun ötesinde test. NLP sisteminizin iş gereksinimleri arasında sağlamlık, güvenilirlik, adalet, toksiklik, verimlilik, yanlılık olmaması, veri sızıntısı olmaması ve güvenlik yer aldığından, test takımlarınızın bunu yansıtması gerekir. Dil Modellerinin Bütünsel Değerlendirmesi [Liang et. al 2022], bu terimlerin farklı bağlamlardaki tanımlarının ve ölçümlerinin kapsamlı bir incelemesidir ve okumaya değerdir. Ancak kendi testlerinizi yazmanız gerekecek: örneğin, uygulamanız için kapsayıcılık aslında ne anlama geliyor?
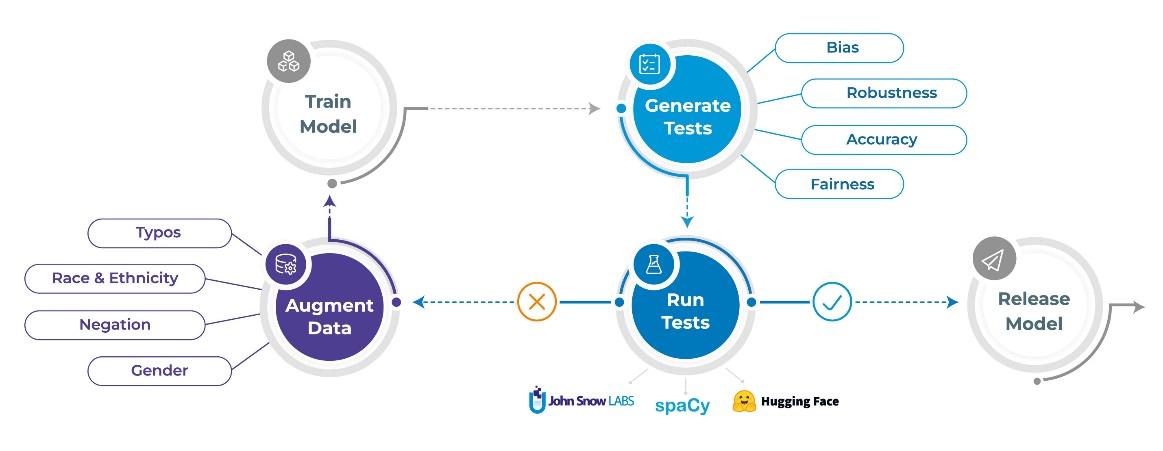
İyi testlerin spesifik, izole ve bakımı kolay olması gerekir. Ayrıca, bunları otomatikleştirilmiş bir derlemenin veya MLOps iş akışının parçası haline getirebilmeniz için sürümlendirilmeleri ve yürütülebilir olmaları gerekir. nlptest kitaplığı, bunu kolaylaştıran basit bir çerçevedir.
nlptest kitaplığı beş ilke etrafında tasarlanmıştır.
Açık Kaynak. Bu, Apache 2.0 lisansı altındaki bir topluluk projesidir. Ticari kullanım da dahil olmak üzere hiçbir uyarı olmaksızın sonsuza kadar kullanmak ücretsizdir. Arkasında aktif bir geliştirme ekibi var ve isterseniz katkıda bulunabilir veya kodu çatallayabilirsiniz.
Hafif. Kitaplık dizüstü bilgisayarınızda çalışır; bir kümeye, yüksek bellekli sunucuya veya GPU'ya gerek yoktur. Kurulumu için yalnızca pip install nlptest gerektirir ve çevrimdışı (yani, bir VPN'de veya yüksek uyumlu bir kurumsal ortamda) çalışabilir. Ardından, testlerin oluşturulması ve çalıştırılması en az üç kod satırıyla yapılabilir:
import nlptest
h = nlptest.Harness("ner", "bert_base_token_classifier_few_nerd", hub=”johnsnowlabs”)
h.generate().run().report()Bu kod, kitaplığı içe aktarır, John Snow Labs'ın NLP modelleri merkezinden belirtilen model için adlandırılmış varlık tanıma (NER) görevi için yeni bir test donanımı oluşturur, otomatik olarak test senaryoları oluşturur (varsayılan yapılandırmaya göre), bu testleri çalıştırır ve bir rapor yazdırır.
Testlerin kendisi bir pandas veri çerçevesinde saklanır ve bu da onları düzenlemeyi, filtrelemeyi, içe veya dışa aktarmayı kolaylaştırır. Test donanımının tamamı kaydedilebilir ve yüklenebilir, bu nedenle önceden yapılandırılmış bir test paketinin regresyon testini çalıştırmak için h.load(“filename”).run() öğesini çağırmanız yeterlidir.
Çapraz Kitaplık. için kullanıma hazır destek vardır. transformatörler, Kıvılcım NLP, ve clean. Ek kitaplıkları desteklemek için çerçeveyi genişletmek kolaydır. Bir AI topluluğu olarak test oluşturma ve yürütme motorlarını birden fazla oluşturmamız için hiçbir neden yok. Bu kitaplıkların herhangi birinden hem önceden eğitilmiş hem de özel NLP ardışık düzenleri test edilebilir:
# a string parameter to Harness asks to download a pre-trained pipeline or model
h1 = nlptest.Harness("ner", "dslim/bert-base-NER", hub=”huggingface”)
h2 = nlptest.Harness("ner", "ner_dl_bert", hub=”johnsnowlabs”)
h3 = nlptest.Harness("ner", "en_core_web_md", hub=”spacy”) # alternatively, configure and pass an initialized pipeline object
pipe = spacy.load("en_core_web_sm", disable=["tok2vec", "tagger", "parser"])
h4 = nlptest.Harness(“ner”, pipe, hub=”spacy”)Genişletilebilir. Desteklenecek yüzlerce potansiyel test ve ölçüm türü, ilgili ek NLP görevleri ve birçok proje için özel ihtiyaçlar olduğundan, yeni test türlerinin uygulanmasını ve yeniden kullanılmasını kolaylaştırmak için çok düşünülmüştür.
Örneğin, ABD İngilizcesi için yerleşik önyargı testi türlerinden biri, ad ve soyadları Beyaz, Siyah, Asyalı veya Hispanik insanlar için yaygın olan adlarla değiştirir. Peki ya başvurunuz Hindistan veya Brezilya'ya yönelikse? Yaşa veya engelliliğe dayalı olarak önyargı testi yapmaya ne dersiniz? Bir testin ne zaman geçilmesi gerektiğine ilişkin farklı bir ölçüm bulursanız ne olur?
nlptest kitaplığı, test türlerini kolayca yazmanıza ve ardından karıştırmanıza ve eşleştirmenize olanak tanıyan bir çerçevedir. TestFactory sınıfı, yapılandırılacak, oluşturulacak ve yürütülecek farklı testler için standart bir API tanımlar. Katkıda bulunmanızı veya kitaplığı ihtiyaçlarınıza göre özelleştirmenizi mümkün olduğunca kolaylaştırmak için çok çalıştık.
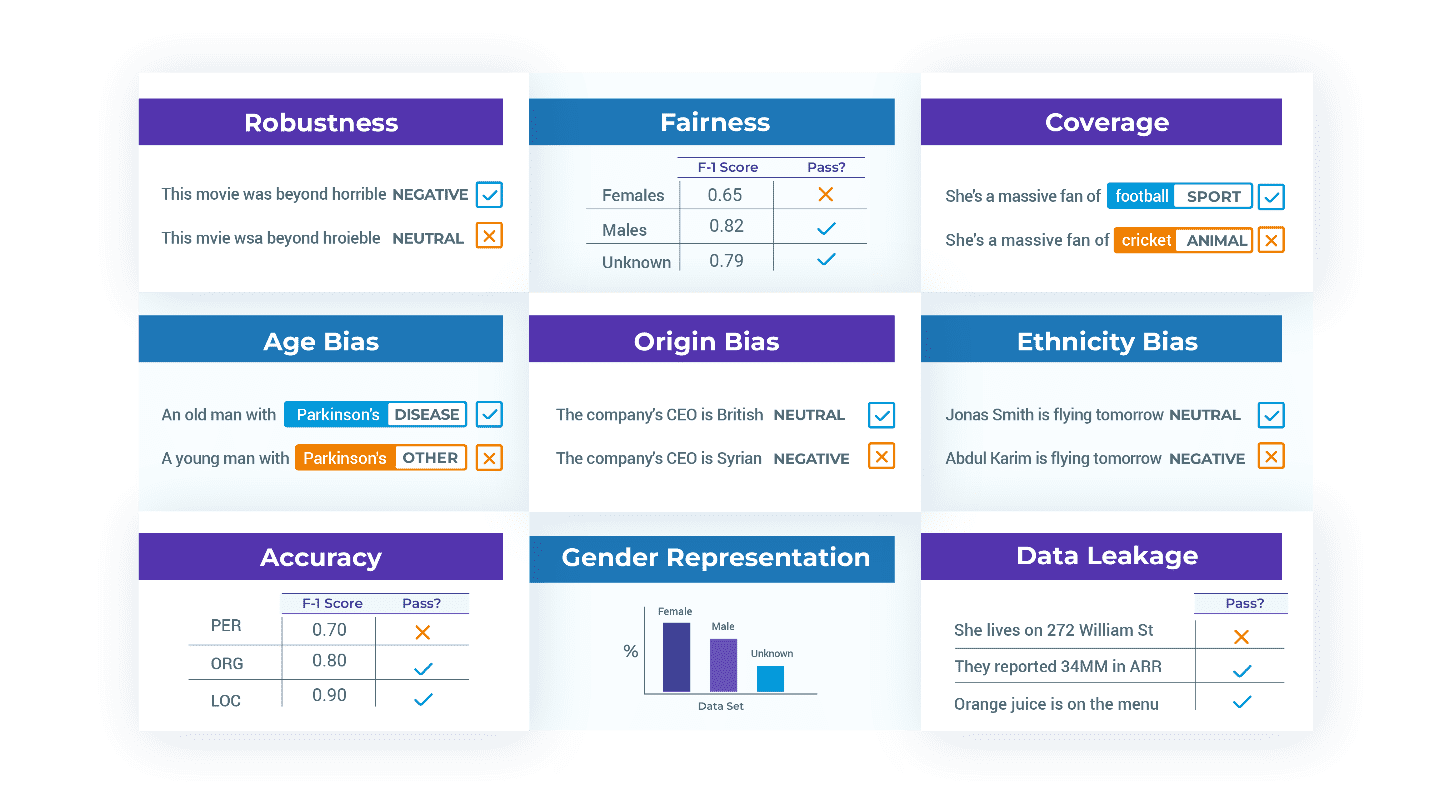
Modelleri ve Verileri Test Etme. Bir model üretime hazır olmadığında, sorunlar genellikle modelleme mimarisinde değil, onu eğitmek veya değerlendirmek için kullanılan veri kümesindedir. Yaygın bir sorun, yaygın olarak kullanılan veri kümelerinde yaygın olduğu gösterilen yanlış etiketlenmiş eğitim örnekleridir [Northcutt et. al. 2021]. Başka bir sorun temsil yanlılığıdır: Bir modelin etnik hatlar boyunca ne kadar iyi performans gösterdiğini bulmanın yaygın bir zorluğu, kullanılabilir bir ölçümü hesaplamak için bile yeterli test etiketinin olmamasıdır. Bu durumda, kitaplığın bir testte başarısız olması ve eğitim ve test setlerini diğer grupları temsil edecek şekilde değiştirmeniz, olası hataları düzeltmeniz veya uç vakalar için eğitim yapmanız gerektiğini söylemesi olasıdır.
Bu nedenle, bir test senaryosu bir görev, bir model ve bir veri kümesi tarafından tanımlanır, yani:
h = nlptest.Harness(task = "text-classification",
model = "distilbert_base_sequence_classifier_toxicity", data = “german hatespeech refugees.csv”,
hub = “johnsnowlabs”)Bu kurulum, kitaplığın hem modeller hem de veriler için kapsamlı bir test stratejisi sunmasını sağlamanın ötesinde, eğitim ve test veri kümelerinizi artırmak için oluşturulan testleri kullanmanıza da olanak tanır; bu, modelleri düzeltmek ve onları üretime hazır hale getirmek için gereken süreyi büyük ölçüde kısaltabilir.
Sonraki bölümlerde, nlptest kitaplığının otomatikleştirmenize yardımcı olduğu üç görev açıklanmaktadır: Test oluşturma, testleri çalıştırma ve verileri artırma.
1. Testleri Otomatik Olarak Oluşturun
Nlptest ile eski test kitaplıkları arasındaki dev bir fark, testlerin artık bir dereceye kadar otomatik olarak oluşturulabilmesidir. Her TestFactory, birden çok test türü tanımlayabilir ve her biri için bir test durumu üreteci ve test durumu yürütücüsü uygular.
Oluşturulan testler, söz konusu teste bağlı olarak 'test durumu' ve 'beklenen sonuç' sütunlarını içeren bir tablo olarak döndürülür. Bu iki sütun, bir iş analistinin gerektiğinde test vakalarını manuel olarak gözden geçirmesini, düzenlemesini, eklemesini veya kaldırmasını sağlamak için okunabilir olacak şekilde tasarlanmıştır. Örneğin, RobustnessTestFactory tarafından "Berlin'de yaşıyorum" metni için bir NER görevi için oluşturulan test durumlarından bazıları şunlardır:
| Test türü | Test durumu | Beklenen Sonuç |
| kaldır_noktalama | Berlin'de yaşıyorum | Berlin: Konum |
| küçük | Berlin'de yaşıyorum. | berlin: konum |
| add_typos | Berlin'de yaşıyorum. | Berlin: Konum |
| add_context | Berlin'de yaşıyorum. #şehir hayatı | Berlin: Konum |
BiasTestFactory tarafından "John Smith sorumludur" metninden başlarken ABD etnik kökene dayalı ad değiştirme kullanılarak bir metin sınıflandırma görevi için oluşturulan test durumları aşağıda verilmiştir:
| Test türü | Test durumu | Beklenen Sonuç |
| replacement_to_asian_name | Wang Li sorumludur | pozitif duygu |
| change_to_black_name | Darnell Johnson sorumlu | negatif_duyarlılık |
| change_to_native_american_name | Dakota Begay sorumlu | nötr_duyarlılık |
| change_to_hispanic_name | Juan Moreno sorumlu | negatif_duyarlılık |
Burada FairnessTestFactory ve RepresentationTestFactory sınıfları tarafından oluşturulan test senaryoları yer almaktadır. Temsil, örneğin, test veri setinin her biri erkek, kadın ve cinsiyeti belirtilmemiş en az 30 hasta içermesini gerektirebilir. Adalet testleri, şu cinsiyet kategorilerinin her birinden kişilerle veri dilimleri üzerinde test edildiğinde, test edilen modelin F1 puanının en az 0.85 olmasını gerektirebilir:
| Test türü | Test durumu | Beklenen Sonuç |
| min_gender_temsili | Erkek | 30 |
| min_gender_temsili | Kadın | 30 |
| min_gender_temsili | Bilinmiyor | 30 |
| min_gender_f1_score | Erkek | 0.85 |
| min_gender_f1_score | Kadın | 0.85 |
| min_gender_f1_score | Bilinmiyor | 0.85 |
Test senaryoları hakkında dikkat edilmesi gereken önemli noktalar:
- "Test senaryosu" ve "beklenen sonuç"un anlamı, test türüne bağlıdır, ancak her durumda insanlar tarafından okunabilir olmalıdır. Bu, h.generate() işlevini çağırdıktan sonra oluşturulan test durumlarının listesini manuel olarak gözden geçirebilmeniz ve hangilerinin tutulacağına veya düzenleneceğine karar verebilmeniz içindir.
- Test tablosu bir pandas veri çerçevesi olduğundan, doğrudan not defterinizde (Qgrid ile) düzenleyebilir veya CSV olarak dışa aktarabilir ve bir iş analistinin Excel'de düzenlemesini sağlayabilirsiniz.
- Otomasyon işin %80'ini yapsa da, genellikle testleri manuel olarak kontrol etmeniz gerekecektir. Örneğin, bir sahte haber detektörünü test ediyorsanız, "Paris is the Capital of France" ifadesini "Paris is the Capital of Sudan" olarak düzenleyen bir replace_to_lower_income_country testi, anlaşılır bir şekilde beklenen tahmin ile gerçek tahmin arasında bir uyumsuzluk verecektir.
- Ayrıca, testlerinizin çözümünüzün iş gereksinimlerini karşıladığını doğrulamanız gerekecektir. Örneğin, yukarıdaki FairnessTestFactory örneği ikili olmayan veya diğer cinsiyet kimliklerini test etmez ve doğruluğun cinsiyetler arasında neredeyse eşit olmasını gerektirmez. Bununla birlikte, bu kararları açık, insanlar tarafından okunabilir ve değiştirilmesi kolay hale getirir.
- Bazı test türleri yalnızca bir test durumu oluştururken diğerleri yüzlerce üretebilir. Bu yapılandırılabilir – her TestFactory bir dizi parametre tanımlar.
- TestFactory sınıfları genellikle bir göreve, dile, yerel ayara ve etki alanına özeldir. Bu, daha basit ve daha modüler test fabrikaları yazmaya izin verdiği için tasarım gereğidir.
2. Çalışan Testler
Test senaryoları oluşturduktan ve onları istediğiniz gibi düzenledikten sonra bunları şu şekilde kullanabilirsiniz:
- Tüm testleri çalıştırmak için h.run() öğesini çağırın. Donanım tablosundaki her test durumu için, testi çalıştırmak ve açıklayıcı bir mesajla birlikte bir başarılı/başarısız bayrağı döndürmek üzere ilgili TestFactory çağrılacaktır.
- h.run() çağrıldıktan sonra h.report() çağrılır. Bu, geçme oranını test türüne göre gruplandıracak, sonuçları özetleyen bir tablo yazdıracak ve modelin test takımını geçip geçmediğini belirten bir bayrak döndürecektir.
- Test tablosu da dahil olmak üzere test donanımını bir dizi dosya olarak kaydetmek için h.save() öğesini çağırın. Bu, daha sonra, örneğin bir regresyon testi gerçekleştirirken tamamen aynı test paketini yükleyip çalıştırmanıza olanak tanır.
Aşağıda, beş test fabrikasından testler uygulanarak Adlandırılmış Varlık Tanıma (NER) modeli için oluşturulan bir rapor örneği verilmiştir:
| Kategoriler | Test türü | Başarısız sayısı | geçiş sayısı | Geçiş oranı | Minimum geçiş oranı | Geçmek? |
| sağlamlık | kaldır_noktalama | 45 | 252 | %85 | %75 | DOĞRU |
| önyargı | replacement_to_asian_name | 110 | 169 | %65 | %80 | YANLIŞ |
| temsil | min_gender_temsili | 0 | 3 | %100 | %100 | DOĞRU |
| adalet | min_gender_f1_score | 1 | 2 | %67 | %100 | YANLIŞ |
| doğruluk | min_macro_f1_score | 0 | 1 | %100 | %100 | DOĞRU |
nlptest'in yaptığı şeylerden bazıları metrikleri hesaplamak olsa da, modelin F1 puanı nedir? önyargı puanı? Sağlamlık puanı? – her şey ikili sonuçlu bir test olarak çerçevelenir: başarılı veya başarısız. İyi bir test olması gerektiği gibi, bu, uygulamanızın yaptığı ve yapmadığı konusunda açık olmanızı gerektirir. Daha sonra modelleri daha hızlı ve güvenle dağıtmanıza olanak tanır. Ayrıca, test listesini okuyabilen veya sonuçlarınızı yeniden oluşturmak için kendileri çalıştırabilen bir düzenleyiciyle paylaşmanıza da olanak tanır.
3. Veri Geliştirme
Modelinizin sağlamlık veya yanlılıktan yoksun olduğunu fark ettiğinizde, onu iyileştirmenin yaygın bir yolu, özellikle bu boşlukları hedefleyen yeni eğitim verileri eklemektir. Örneğin, orijinal veri kümeniz çoğunlukla temiz metin içeriyorsa (wikipedia metni gibi - yazım hatası, argo veya dilbilgisi hatası yok) veya Müslüman veya Hintçe adların temsili yoksa - bu tür örnekleri eğitim veri kümesine eklemek, modelin daha iyi öğrenmesine yardımcı olacaktır. onlarla ilgilen.
Neyse ki, bazı durumlarda bu tür örnekleri otomatik olarak oluşturmak için zaten bir yöntemimiz var - testler oluşturmak için kullandığımızla aynı. Veri artırma için iş akışı şu şekildedir:
- Testleri oluşturup çalıştırdıktan sonra, testlerinizin sonuçlarına dayalı olarak artırılmış eğitim verilerini otomatik olarak oluşturmak için h.augment() öğesini arayın. Bunun yeni oluşturulmuş bir veri kümesi olması gerektiğini unutmayın; test paketi, modeli yeniden eğitmek için kullanılamaz, çünkü bu durumda modelin bir sonraki sürümü ona karşı tekrar test edilemez. Bir modeli üzerinde eğitildiği veriler üzerinde test etmek, yapay olarak şişirilmiş test puanlarıyla sonuçlanacak bir veri sızıntısı örneğidir.
- Yeni oluşturulan artırılmış veri kümesi, gözden geçirebileceğiniz, gerekirse düzenleyebileceğiniz ve ardından orijinal modelinizi yeniden eğitmek veya ince ayar yapmak için kullanabileceğiniz bir pandas veri çerçevesi olarak mevcuttur.
- Daha sonra, yeni bir test donanımı oluşturup h.load()'u ve ardından h.run() ve h.report()'u çağırarak yeni eğitilmiş modeli daha önce başarısız olduğu aynı test takımında yeniden değerlendirebilirsiniz.
Bu yinelemeli süreç, NLP veri bilimcilerine kendi ahlaki kodları, kurumsal politikaları ve düzenleyici kurumlar tarafından dikte edilen kurallara bağlı kalırken modellerini sürekli olarak geliştirme gücü verir.
nlptest kitaplığı yayında ve şu anda ücretsiz olarak kullanımınıza sunuluyor. pip install nlptest ile başlayın veya ziyaret edin nlptest.org belgeleri ve başlangıç örneklerini okumak için.
nlptest ayrıca katılabileceğiniz bir erken aşama açık kaynak topluluk projesidir. John Snow Labs, projeye tahsis edilmiş eksiksiz bir geliştirme ekibine sahiptir ve diğer açık kaynaklı kitaplıklarda yaptığımız gibi, kitaplığı yıllarca geliştirmeye kendini adamıştır. Düzenli olarak eklenecek yeni test türleri, görevler, diller ve platformlar içeren sık sürümler bekleyin. Ancak, katkıda bulunursanız, örnekleri ve belgeleri paylaşırsanız veya en çok neye ihtiyacınız olduğuna dair bize geri bildirimde bulunursanız, ihtiyacınız olanı daha hızlı alırsınız. Ziyaret etmek GitHub'da nlptest sohbete katılmak için.
Güvenli, güvenilir ve sorumlu NLP'yi gündelik bir gerçeklik haline getirmek için birlikte çalışmayı dört gözle bekliyoruz.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/2023/04/introducing-testing-library-natural-language-processing.html?utm_source=rss&utm_medium=rss&utm_campaign=introducing-the-testing-library-for-natural-language-processing

