
Giriş
ChatGPT, OpenAI tarafından geliştirilen ve insan girdilerini anlama ve konuşarak yanıt verme yeteneğiyle dünyayı kasıp kavuran güçlü bir dil modelidir. ChatGPT'nin en heyecan verici özelliklerinden biri, aşağıdakiler de dahil olmak üzere çeşitli programlama dillerinde kod parçacıkları oluşturma yeteneğidir: Python, Java, JavaScript ve C++. Bu özellik yaptı ChatGPT kod tabanının tamamını kendileri yazmak zorunda kalmadan hızlı bir şekilde prototip oluşturmak veya bir sorunu çözmek isteyen geliştiriciler arasında popüler bir seçim. Bu makale, Veri Bilimcileri için Gelişmiş Veri Analizi için ChatGPT'nin Kod Yorumlayıcısının nasıl olduğunu keşfedecektir. Ayrıca, nasıl çalıştığına ve makine öğrenimi kodu oluşturmak için kullanılabileceğine bakacağız. Ayrıca ChatGPT kullanmanın bazı faydalarını ve sınırlamalarını da tartışacağız.
Öğrenme hedefleri
- ChatGPT'nin Gelişmiş Veri Analizinin nasıl çalıştığını ve makine öğrenimi kodu oluşturmak için nasıl kullanılabileceğini anlayın.
- Python kullanan veri bilimcileri için kod parçacıkları oluşturmak amacıyla ChatGPT'nin Gelişmiş Veri Analizini nasıl kullanacağınızı öğrenin.
- Makine öğrenimi kodu oluşturmaya yönelik ChatGPT'nin Gelişmiş Veri Analizinin avantajlarını ve sınırlamalarını anlayın.
- ChatGPT'nin Gelişmiş Veri Analizini kullanarak makine öğrenimi modellerinin nasıl tasarlanacağını ve uygulanacağını öğrenin.
- Eksik değerlerin işlenmesi, 'kategorik değişkenlerin kodlanması, verilerin normalleştirilmesi ve sayısal özelliklerin ölçeklendirilmesi' dahil olmak üzere, makine öğrenimi için verilerin nasıl önceden işleneceğini anlayın. Kategorik değişkenleri kodlama, verileri normalleştirme ve sayısal özellikleri ölçeklendirme.
- Verileri eğitim ve test kümelerine nasıl böleceğinizi ve doğruluk, hassasiyet, geri çağırma, F1 puanı, ortalama kare hata, ortalama mutlak hata, R-kare değeri vb. gibi ölçümleri kullanarak makine öğrenimi modellerinin performansını nasıl değerlendireceğinizi öğrenin.
Bu öğrenme hedeflerine hakim olarak, makine öğrenimi kodu oluşturmak ve çeşitli makine öğrenimi algoritmalarını uygulamak için ChatGPT'nin Gelişmiş Veri Analizinin nasıl kullanılacağı anlaşılmalıdır. Ayrıca bu becerileri gerçek dünya sorunlarına ve veri kümelerine uygulayabilmeli ve makine öğrenimi görevleri için ChatGPT'nin Gelişmiş Veri Analizini kullanma konusundaki yeterliliklerini gösterebilmelidirler.
Bu makale, Veri Bilimi Blogathon.
İçindekiler
ChatGPT'nin Gelişmiş Veri Analizi Nasıl Çalışır?
ChatGPT'nin Gelişmiş Veri Analizi, derin öğrenme Transformatör olarak adlandırılan model, geniş bir metin verisi külliyatı üzerinde eğitilmiştir. Dönüştürücü, giriş metninin farklı bölümleri arasındaki bağlamı ve ilişkiyi anlamak için kişisel dikkat mekanizmalarını kullanır. Bir kullanıcı bir bilgi istemi veya kod parçacığı girdiğinde ChatGPT'nin modeli, eğitim verilerinden öğrendiği kalıplara ve yapılara dayalı bir yanıt oluşturur.
ChatGPT'deki Gelişmiş Veri Analizi, büyük miktarda çevrimiçi koddan yararlanarak kod parçacıkları oluşturabilir. ChatGPT'nin modeli, açık kaynak kod depolarını ve diğer kod kaynaklarını analiz ederek çeşitli programlama dillerinin sözdizimini, anlambilimini ve deyimlerini öğrenebilir. ChatGPT'nin modeli, bir kullanıcı ilgili ve çalışan bir kod parçacığı oluşturmak için bir kod parçası istediğinde bu bilgiden yararlanabilir.
ChatGPT ile Makine Öğrenimi Kodu Oluşturma
Makine öğrenme ChatGPT'nin Gelişmiş Veri Analizinin en umut verici uygulamalarından biridir. Derin öğrenme ve makine öğrenimi uygulamalarının yükselişiyle birlikte, giderek daha önemli araştırma ve geliştirme alanları haline geldiler. Ancak bu modellerin tasarlanması ve uygulanması karmaşık ve zaman alıcı olabilir; doğrusal cebir, matematik, olasılık teorisi ve bilgisayar bilimlerinde uzmanlık gerektirir.
ChatGPT'nin Gelişmiş Veri Analizi, kullanıcıların projelerine entegre edebileceği makine öğrenimi kod parçacıkları oluşturarak bu süreci basitleştirmeye yardımcı olabilir. Örneğin, bir kullanıcı ChatGPT'den, .csv formatında girdi olarak sağlanan bir eğitim veri kümesine dayanarak Kaliforniya'daki ev fiyatlarını tahmin etmek için doğrusal bir regresyon tekniği kullanarak bir kod pasajı oluşturmasını isteyebilir. ChatGPT'nin modeli, kullanıcının girdisine dayalı olarak gerekli içe aktarmaları, veri ön işleme adımlarını, model mimarisini ve eğitim prosedürlerini içeren bir kod parçacığı oluşturabilir.
Veri kümesini ChatGPT'deki kod yorumlayıcıya yükleyin ve aşağıdaki istemi girin.
istemi:
Yapmak doğrusal regresyon yukarıdaki veri kümesinde sklearn'i kullanarak Python koduyla tüm adımları gösterin. Verilerden elde edilen tahmin değişkeni medyan_ev_değeridir.

Cevabı:
Aşağıdakileri kullanarak doğrusal regresyon adımları skleöğrenmek “housing.csv” veri setinde, hedef değişken olarak “median_house_value” kullanılarak yapılanlar aşağıdaki gibidir:
- Veri Keşfi: Veri kümesini yükleyin ve yapısını hızla inceleyin.
- Veri Ön İşleme: Eksik değerleri işleyin, kategorik değişkenleri (varsa) kodlayın ve sayısal özellikleri ölçeklendirin.
- Verileri bölme: Verileri eğitim ve test kümelerine bölün.
- Model Eğitimi: Eğitim setinde bir regresyon modeli eğitin.
- Değerlendirme: Eğitilen modeli test setinde değerlendirin.
- Modelin Yorumlanması: Tahmindeki her özelliğin önemini analiz edin.
Veri kümesini yükleme ve yapısını keşfetme:
# Load the dataset
data = pd.read_csv('/mnt/data/housing.csv')
# Display the first few rows of the dataset to understand its structure
data.head()
#import csv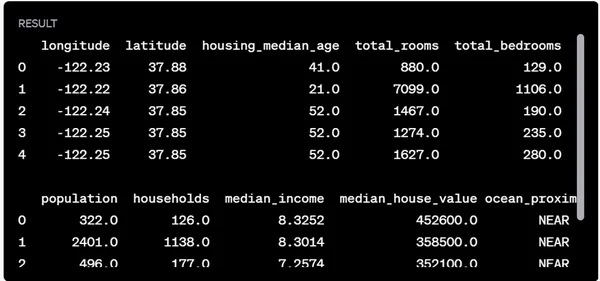
Veri kümesi aşağıdaki sütunları içerir:
- boylam: Konumun boylamı
- enlem: Konumun enlemi
- housing_median_age: Bölgedeki konutların ortalama yaşı
- toplam_oda sayısı: Bölgedeki toplam oda sayısı
- toplam_yatak odaları: Bölgedeki toplam yatak odası sayısı
- nüfus: Bölgenin nüfusu
- hane halkı: Bölgedeki hane sayısı
- ortalama_gelir: Bölgedeki insanların ortalama geliri
- medyan_ev_değeri: Bölgedeki medyan ev değeri (hedef değişkenimiz)
- okyanus_yakınlığı: Okyanusa yakınlık (kategorik değişken)
Şimdi veri ön işlemeye devam edelim:
Veri Ön İşleme:
- Eksik değerleri kontrol edin ve bunları halledin.
- Ocean_proximity kategorik değişkenini kodlayın.
- Sayısal özellikleri standartlaştıracak şekilde ölçeklendirin.
Veri kümesindeki eksik değerlerin kontrol edilmesi:
# Check for missing values in each column
missing_values = data.isnull().sum()
missing_values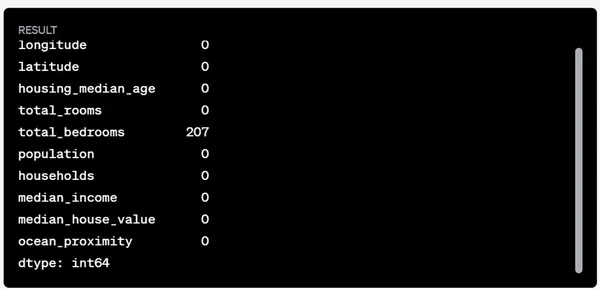
Bu gibi görünüyor total_bedrooms sütununda 207 eksik değer var. Sayısal sütunlar için eksik değerleri ele almanın yaygın bir stratejisi, bunları o sütunun medyan değeriyle değiştirmektir. Eksik değerleri dolduralım total_bedrooms medyan değeriyle.
Bundan sonra kodlayacağız okyanus yakınlığı One-hot kodlamayı kullanarak kategorik değişkeni kullanın ve sayısal özellikleri ölçeklendirin.
Ön işleme adımları:
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# Fill missing values in total_bedrooms with its median value
data['total_bedrooms'].fillna(data['total_bedrooms'].median(), inplace=True)
# Define columns for preprocessing
numerical_features = ['longitude', 'latitude', 'housing_median_age', 'total_rooms',
'total_bedrooms', 'population', 'households', 'median_income']
categorical_feature = ['ocean_proximity']
# Create a column transformer for preprocessing
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), numerical_features),
('cat', OneHotEncoder(), categorical_feature)
])
# Apply the transformations to the data (excluding the target variable)
X = data.drop('median_house_value', axis=1)
y = data['median_house_value']
X_transformed = preprocessor.fit_transform(X)
# Checking the transformed data's shape and first few rows to ensure preprocessing was successful
X_transformed.shape, X_transformed[:5]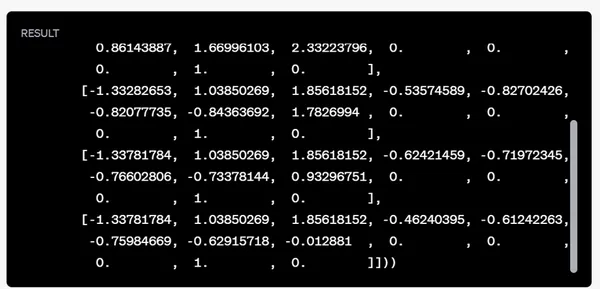
Ön işleme adımları başarılı oldu:
- Eksik değerleri kontrol edin ve bunları halledin.
- Ocean_proximity kategorik değişkenini kodlayın.
- Sayısal özellikleri standartlaştıracak şekilde ölçeklendirin.
Dönüştürülen veri kümesinde 20,640 örnek ve 13 özellik bulunmaktadır.
Verileri bölme:
Daha sonra verileri eğitim ve test setlerine ayıracağız. Bu, modelimizi bir alt küme üzerinde eğitmemize olanak tanır ve
Performansını görünmeyen başka bir alt kümede test edin. Tipik olarak, eğitim ve test için ortak bir bölünme oranı 80:20 veya 70:30'dur. Bu alıştırmada 80:20'lik bir bölünme kullanacağız.
Verileri bölelim.
from sklearn.model_selection
import train_test_split
# Splitting the data into training and test sets (80% training, 20% testing)
X_train, X_test, y_train, y_test = train_test_split(X_transformed, y, test_size=0.2,
random_state=42)
X_train.shape, X_test.shape
Veriler başarıyla eğitim ve test setlerine bölündü:
- Eğitim Seti: 16,512 örnekleri
- Deneme seti: 4,128 örnekleri
Model Eğitimi:
Daha sonra eğitim verilerini kullanarak bir regresyon modeli eğiteceğiz. Bu gösteri için basit bir yöntem kullanacağız.
doğrusal regresyon modeli. Gerekirse daha sonra daha karmaşık modeller veya topluluk yöntemleri araştırılabilir.
Doğrusal regresyon modelini eğitin:
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Initialize the Linear Regression model
model = LinearRegression()
# Train the model on the training data
model.fit(X_train, y_train)
# Predict on the training data to check in-sample performance
train_predictions = model.predict(X_train)
train_mse = mean_squared_error(y_train, train_predictions)
train_rmse = train_mse**0.5
train_rmse
Eğitim verilerine ilişkin tahminlerin ortalama kare hatasının (RMSE) kökü yaklaşık 68,433.94 ABD dolarıdır.
RMSE bize tahmin hatalarının ortalama büyüklüğü hakkında bir fikir verir. Bu bağlamda modelimizin tahminleri, eğitim setindeki gerçek ev değerlerinden ortalama olarak yaklaşık 68,433.94 $ uzaktadır.
Değerlendirme:
Modelin genelleme yeteneğini değerlendirmek için test verilerini tahmin edeceğiz ve bu tahminlere ilişkin RMSE'yi hesaplayacağız.
Modeli test seti üzerinde değerlendirelim.
# Predict on the test data
test_predictions = model.predict(X_test)
# Compute the RMSE for the test predictions
test_mse = mean_squared_error(y_test, test_predictions)
test_rmse = test_mse**0.5
test_rmse
Test verilerine ilişkin tahminlerin ortalama kare hatasının (RMSE) kökü yaklaşık 70,060.52 ABD dolarıdır.
Test RMSE'si, model test verileri üzerinde eğitilmediği için beklenen eğitim RMSE'sinden biraz daha yüksektir. Ancak değerlerin nispeten yakın olması, modelin eğitim verilerine çok fazla uymadığını gösteriyor.
Modelin Yorumlanması:
Modeli daha iyi anlamak için her özelliğin katsayılarına bakabiliriz. Bu katsayılar her bir özelliğin hedef değişken üzerindeki önemini ve etkisini gösterir. medyan_ev_değeri.
Özellik katsayılarına bir göz atalım.
# Extract feature names after one-hot encoding
feature_names = numerical_features + list(preprocessor.named_transformers_['cat'].categories_[0])
# Retrieve the coefficients from the model
coefficients = model.coef_
# Create a DataFrame to display the feature coefficients
feature_importance = pd.DataFrame({
'Feature': feature_names,
'Coefficient': coefficients
}).sort_values(by='Coefficient', ascending=False)
feature_importance
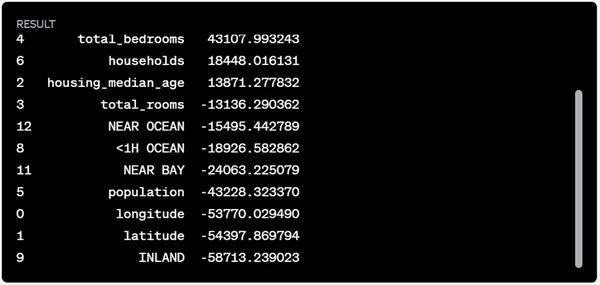
Özellik katsayılarının yorumları şunlardır:
- Pozitif katsayılar, özellik değeri arttıkça tahmin edilen medyan_ev_değerinin de arttığını göstermektedir.
- Negatif katsayılar, özellik değeri arttıkça tahmin edilen medyan_ev_değerinin azaldığını göstermektedir.
Örneğin:
- ISLAND en yüksek pozitif katsayıya sahiptir; bu da adalardaki evlerin diğer konumlara göre daha yüksek bir tahmin değerine sahip olduğunu göstermektedir.
- medyan_gelir aynı zamanda tahmin edilen ev değeri üzerinde de önemli bir pozitif etkiye sahiptir.
- Öte yandan, INLAND en olumsuz etkiye sahip olup, iç kesimlerde bulunan evlerin daha düşük bir tahmin değerine sahip olma eğiliminde olduğunu göstermektedir.
- Enlem ve boylam gibi coğrafi özellikler de ev değerlerinin belirlenmesinde rol oynamakta olup her ikisi de bu modelde negatif katsayılara sahiptir.
Bu katsayılar, özellikler ile hedef değişken arasındaki ilişkilere dair fikir verirken, mutlaka nedensellik anlamına gelmez. Dış faktörler ve özellikler arasındaki etkileşimler de evin değerlerini etkileyebilir.
Makine Öğrenimi Kodu Oluşturma için ChatGPT Kullanmanın Yararları

Makine öğrenimi kodu oluşturmak için ChatGPT'nin Gelişmiş Veri Analizini kullanmanın çeşitli avantajları vardır:
- Zaman tasarrufu: Bir makine öğrenimi modeli tasarlamak ve uygulamak, özellikle yeni başlayanlar için oldukça zaman alabilir. ChatGPT'nin Gelişmiş veri analizi, projeleri için başlangıç noktası olarak kullanabilecekleri çalışan kod parçacıkları oluşturarak kullanıcılara çok zaman kazandırabilir.
- Geliştirilmiş üretkenlik: ChatGPT'nin Gelişmiş veri analizi sayesinde kullanıcılar, model mimarisini uygulamanın ayrıntılarında boğulmadan, veri ön işleme, özellik mühendisliği ve model değerlendirme gibi makine öğrenimi projelerinin üst düzey kavramlarına odaklanabilirler.
- Erişilebilirlik: ChatGPT'nin Gelişmiş veri analizi, makine öğrenimini, bilgisayar bilimi veya programlama konusunda güçlü bir geçmişi olmayan kişiler için daha erişilebilir hale getirir. Kullanıcılar isteklerini tanımlayabilir ve ChatGPT gerekli kodu oluşturacaktır.
- Özelleştirme: ChatGPT'nin Gelişmiş veri analizi, kullanıcıların oluşturulan kodu ihtiyaçlarına göre özelleştirmelerine olanak tanır. Kullanıcılar hiperparametreleri değiştirebilir, model mimarisini ayarlayabilir veya kod pasajına ek işlevsellik ekleyebilir.
Makine Öğrenimi Kodu Oluşturma için ChatGPT Kullanımının Sınırlamaları
ChatGPT'nin kod yorumlayıcısı makine öğrenimi kodu oluşturmak için güçlü bir araç olsa da dikkate alınması gereken bazı sınırlamalar vardır:
- Oluşturulan kodun kalitesi: ChatGPT'nin Gelişmiş veri analizi, çalışan kod parçacıkları oluşturabilse de kodun kalitesi, görevin karmaşıklığına ve eğitim verilerinin kalitesine bağlı olarak değişebilir. Kullanıcıların kodu üretimde kullanmadan önce temizlemesi, hataları düzeltmesi veya performansı optimize etmesi gerekebilir.
- Alan bilgisi eksikliği: ChatGPT'nin modeli her zaman belirli bir alanın veya uygulama alanının nüanslarını anlamayabilir. Kullanıcıların, ChatGPT'nin gereksinimlerini karşılayan kod oluşturmasına yardımcı olmak için ek bağlam veya rehberlik sağlaması gerekebilir.
- Eğitim verilerine bağımlılık: ChatGPT'nin Gelişmiş veri analizi büyük ölçüde maruz kaldığı eğitim verilerinin kalitesine ve çeşitliliğine dayanır. Eğitim verileri taraflı veya eksikse oluşturulan kod bu eksiklikleri yansıtabilir.
- Etik hususlar: Yapay zeka tarafından oluşturulan kodun sağlık veya finans gibi kritik uygulamalarda kullanılması konusunda etik kaygılar mevcuttur. Kullanıcılar oluşturulan kodu dikkatli bir şekilde değerlendirmeli ve gerekli standartları ve düzenlemeleri karşıladığından emin olmalıdır.
Sonuç
ChatGPT'nin Gelişmiş veri analizi, kod parçacıkları oluşturmak için güçlü bir araçtır. Doğal dil komutlarını anlama ve çalışma kodu oluşturma yeteneği sayesinde ChatGPT, makine öğrenimi teknolojisine erişimi demokratikleştirme ve bu alandaki inovasyonu hızlandırma potansiyeline sahiptir. Ancak kullanıcıların teknolojinin sınırlamalarının farkında olması ve oluşturulan kodu üretimde kullanmadan önce dikkatlice değerlendirmesi gerekir. ChatGPT'nin yetenekleri gelişmeye devam ettikçe, bu teknolojinin daha da heyecan verici uygulamalarını görmeyi bekleyebiliriz.
Önemli Noktalar
- ChatGPT'nin Gelişmiş veri analizi, transformatör adı verilen ve geniş bir metin verisi topluluğu üzerinde eğitilmiş bir derin öğrenme modeline dayanmaktadır.
- Gelişmiş veri analizi, büyük miktarda çevrimiçi koddan yararlanarak Python, Java, JavaScript ve C++ dahil olmak üzere çeşitli programlama dillerinde kod parçacıkları oluşturabilir.
- ChatGPT'nin Gelişmiş veri analizi, doğrusal regresyon, lojistik regresyon, karar ağaçları, rastgele orman, destek vektör makineleri, sinir ağları ve derin öğrenme için makine öğrenimi kod parçacıkları oluşturabilir.
- ChatGPT'nin makine öğrenimi için Gelişmiş veri analizini kullanmak için kullanıcılar bir bilgi istemi veya kod pasajı sağlayabilir ve belirli bir veri kümesini kullanarak doğrusal bir regresyon modeli için bir kod pasajı oluşturmak gibi belirli bir görevi talep edebilir.
- ChatGPT'nin modeli, gerekli içe aktarmaları, veri ön işleme adımlarını, model mimarisini ve eğitim prosedürlerini içeren kod parçacıkları oluşturabilir.
- ChatGPT'nin Gelişmiş veri analizi, makine öğrenimi modellerinin tasarlanmasını ve uygulanmasını basitleştirmeye yardımcı olarak geliştiricilerin ve veri bilimcilerinin bir sorunu hızlı bir şekilde prototiplemesini veya çözmesini kolaylaştırabilir.
- Bununla birlikte, ChatGPT'nin Gelişmiş veri analizini kullanmanın, oluşturulan kodun hatalar içerme potansiyeli veya özelleştirme seçeneklerinin eksikliği gibi sınırlamaları da vardır.
- Genel olarak ChatGPT'nin Gelişmiş veri analizi, özellikle makine öğrenimi kod parçacıkları oluştururken geliştiriciler ve veri bilimcileri için geliştirme sürecini kolaylaştırmaya yardımcı olabilecek güçlü bir araçtır.
Sık Sorulan Sorular
C: ChatGPT web sitesine gidin ve kodlama sorularınızı veya istemlerinizi yazmaya başlayın. Sistem daha sonra sorgunuzu anlamasına göre yanıt verecektir. Başlamanıza yardımcı olması için çevrimiçi eğitimlere ve belgelere de başvurabilirsiniz.
C: ChatGPT'nin kod yorumlayıcısı Python, Java, JavaScript ve C++ dahil olmak üzere birçok popüler programlama dilini destekler. Çıktının kalitesi, kodun karmaşıklığına ve eğitim verilerindeki örneklerin kullanılabilirliğine bağlı olarak değişebilmesine rağmen, diğer dillerde de kod parçacıkları oluşturabilir.
C: Evet, ChatGPT'nin kod yorumlayıcısı, makine öğrenimi algoritmaları, veri analizi ve web geliştirme dahil olmak üzere karmaşık kodlama görevlerini gerçekleştirebilir. Ancak oluşturulan kodun kalitesi, görevin karmaşıklığına ve model için mevcut olan eğitim veri kümesinin boyutuna bağlı olabilir.
C: Evet, ChatGPT'nin kod yorumlayıcısı tarafından oluşturulan kodun kullanımı, MIT Lisansı koşulları kapsamında ücretsizdir. Bu, telif ücreti ödemeden veya yazarın iznini almadan kodu ticari amaçlarla değiştirebileceğiniz, dağıtabileceğiniz ve kullanabileceğiniz anlamına gelir.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/11/chatgpts-code-interpreter-gpt-4-advanced-data-analysis-for-data-scientists/

