ChatGPT bir GPT'dir (Gcanlandırıcı Pyeniden eğitilmiş Transformer) dünyayı şaşırtan makine öğrenimi (ML) aracı. Nefes kesen yetenekleri sıradan kullanıcıları, profesyonelleri, araştırmacıları ve hatta kendi yaratıcıları. Ayrıca, genel görevler için eğitilmiş ve alana özgü durumlarda çok iyi performans gösteren bir makine öğrenimi modeli olma kapasitesi etkileyicidir. Ben bir araştırmacıyım ve duygu analizi (SA) yapma yeteneği beni ilgilendiriyor.
ChatGPT'ye bu makalenin başlığı olan bu araştırma sorusunu sorarsanız, size mütevazı bir yanıt verecektir (devam edin, deneyin). Ama, sevgili okuyucum, normalde bunu senin için bozmazdım, ama bu ChatGPT yanıtının ne kadar şaşırtıcı derecede mütevazı olduğu hakkında hiçbir fikrin yok...
Yine de, bir AI araştırmacısı, endüstri uzmanı ve hobi uzmanı olarak, alana özgü görevlerde kullanım için genel alan NLP makine öğrenimi araçlarına (örn. GloVe) ince ayar yapmaya alışkınım. Çoğu alan adının ince ayar yapmadan yeterince iyi sonuç verebilecek, kullanıma hazır bir çözüm bulması alışılmadık bir durum olduğu için durum böyledir. Size bunun nasıl artık böyle olamayacağını göstereceğim.
Bu metinde, aşağıdaki konuları ele alarak ChatGPT'yi alana özgü bir makine öğrenimi modeliyle karşılaştırıyorum:
SemEval 2017 Görev 5 — Alana özgü bir meydan okuma
Bir veri kümesini kod örnekleriyle etiketlemek için ChatGPT API'yi kullanma
Tekrar üretilebilirlik ayrıntılarıyla karşılaştırmanın sonucu ve sonuçları
Sonuç ve Sonuç Tartışması
BONUS: Uygulamalı bir senaryoda bu karşılaştırma nasıl yapılabilir?
Notlar 1: Bu sadece konuya biraz ışık tutan basit bir uygulamalı deney, DEĞİL kapsamlı bir bilimsel araştırma.
Notlar 2: Aksi belirtilmedikçe tüm görseller yazara aittir.
1. SemEval 2017 Görev 5 — Alana özgü bir meydan okuma
SemEval (Olmadanmaskara Değerlendirkullanım) araştırma ekiplerinin duygu analizi, metin benzerliği ve soru cevaplama görevlerinde bilimsel olarak rekabet ettiği ünlü bir NLP atölyesidir. Düzenleyiciler, her görev için son teknoloji çözümleri değerlendirmek üzere açıklamacılar (etki alanı uzmanları) ve dilbilimciler tarafından oluşturulan metin verileri ve altın standart veri kümeleri sağlar.
Özellikle SemEval'in 5 baskısının 2017. Görevi araştırmacılardan finansal mikroblogları ve haber başlıklarını duyarlılık analizi için -1 (en olumsuz) ile 1 (en olumlu) arasında puanlamalarını istedi. ChatGPT'nin etki alanına özgü bir görevdeki performansını test etmek için o yılki SemEval'deki altın standart veri kümesini kullanacağız. Alt görev 2 veri setinde (haber başlıkları) iki set cümle vardı (her biri maksimum 30 kelime): eğitim (1,142 cümle) ve test (491 cümle) seti.
Bu kümeler dikkate alındığında duygu puanlarının ve metin cümlelerinin veri dağılımı aşağıda gösterilmektedir. Aşağıdaki çizim, hem eğitim hem de test kümelerindeki çift modlu dağılımları göstermektedir. Ayrıca, grafik, veri setinde olumsuzdan çok olumlu cümleleri göstermektedir. Bu, değerlendirme bölümünde kullanışlı bir bilgi olacaktır.
SemEval 2017 Görev 5 Alt Görev 2 (haber başlıkları) eğitim (solda — 1,142 cümle) ve test (sağda — 491 cümle) kümelerini dikkate alan veri dağıtım duyarlılık puanı.
Bu alt görev için, kazanan araştırma ekibi (yani test setinde en iyi sırada yer alan) makine öğrenimi mimarisini adlandırdı Fortia-FBK. Bu yarışmanın keşiflerinden esinlenerek, bazı meslektaşlarım ve ben bir araştırma makalesi yaptık (Finansal Metinlerde Regresyon Temelli Duygu Analizi Tekniklerinin Değerlendirilmesi) Fortia-FBK sürümümüzü uyguladığımız ve bu mimariyi iyileştirmenin yollarını değerlendirdiğimiz yer.
Ayrıca, bu mimariyi kazanan yapan faktörleri araştırdık. Böylece uygulamamız (kod burada) bu kazanan mimarinin (ör. Fortia-FBK) ChatGPT ile karşılaştırması için kullanılacaktır. Kullanılan mimari (CNN+GloVe+Vader) aşağıda gösterilen mimaridir.
Bu kapsamlı eğitim içeriği sizin için yararlıysa, AI posta listemize abone olun yeni materyal çıkardığımızda uyarılmak.
2. Bir veri kümesini etiketlemek için ChatGPT API'yi kullanma
ChatGPT API'nin kullanımı burada, Medium'da zaten tartışılmıştır verileri sentezlemek için. Ayrıca duygu etiketleme örneklerini şu adreste bulabilirsiniz: ChatGPT API kod örnekleri bölümü (API kullanımının ücretsiz olmadığına dikkat edin). Bu kod örneği için, SemEval'in yapabileceğiniz 2017 Task altın standart veri kümesini göz önünde bulundurun. buraya gel.
Ardından, birkaç cümleyi aynı anda etiketlemek üzere API'yi kullanmak için, böyle bir kod kullanın; burada, etiketlenecek cümle ve duygunun gönderileceği hedef şirket ile Gold-Standard veri kümesine sahip bir veri çerçevesinden cümleler içeren tam bir bilgi istemi hazırlıyorum. atıfta.
def prepare_long_prompt(df): initial_txt = "Classify the sentiment in these sentences between brackets regarding only the company specified in double-quotes. The response should be in one line with format company name in normal case followed by upper cased sentiment category in sequence separated by a semicolon:nn" prompt = """ + df['company'] + """ + " [" + df['title'] + ")]" return initial_txt + 'n'.join(prompt.tolist())
Ardından, API için çağrı yapın. metin-davinci-003motor (GPT-3 versiyonu). Burada, istemdeki maksimum toplam karakter sayısını ve en fazla 4097 karakter olması gereken yanıtı hesaba katmak için kodda bazı ayarlamalar yaptım.
def call_chatgpt_api(prompt): # getting the maxium amount of tokens allowed to the response, based on the # api Max of 4097, and considering the length of the prompt text prompt_length = len(prompt) max_tokens = 4097 - prompt_length # this rule of dividing by 10 is just a empirical estimation and is not a precise rule if max_tokens < (prompt_length / 10): raise ValueError(f'Max allowed token for response is dangerously low {max_tokens} and might not be enough, try reducing the prompt size') response = openai.Completion.create( model="text-davinci-003", prompt=prompt, temperature=0, max_tokens=max_tokens, top_p=1, frequency_penalty=0, presence_penalty=0 ) return response.choices[0]['text'] long_prompt = prepare_long_prompt(df)
call_chatgpt_api(long_prompt)
Sonuç olarak, bunu altın standart veri setinde toplam 1633 (eğitim + test seti) cümle için yaptığınızda ChatGPT API etiketleri ile aşağıdaki sonuçları elde edersiniz.
SemEval 2017 Görev 5 Alt Görev 2 Örneği (haber başlıkları) ChatGPT API kullanılarak etiketlenmiş duyarlılık içeren Altın Standart veri kümesi.
2.1. Geniş ölçekte ChatGPT ve API'si ile ilgili sorunlar
Diğer tüm API'lerde olduğu gibi, bazı tipik gereksinimler vardır.
Kısıtlama ayarlamaları gerektiren istek oranı sınırı
25000 jetonluk talep limiti (yani, alt kelime birimi veya bir bayt çifti kodlaması)
İstek başına maksimum 4096 belirteç uzunluğu (soru + yanıt dahil)
0.0200$ / 1K jeton maliyeti (Not: Yaptığım onca şeyden sonra hiçbir zaman 2 U$'dan fazlasını harcamadım)
Ancak bunlar, çoğu API ile uğraşırken yalnızca tipik gereksinimlerdir. Ayrıca, bu alana özgü problemde, duygu için her cümle için bir hedef varlık (yani şirket) olduğunu unutmayın. Bu yüzden, birkaç cümlenin duygularını aynı anda etiketlemeyi mümkün kılan ve daha sonra sonuçları işlemeyi kolaylaştıran bir komut istemi kalıbı tasarlayana kadar oynamak zorunda kaldım. Ayrıca bunlar, daha önce gösterdiğim bilgi istemini ve kodu etkileyen diğer sınırlamalardır. Özellikle, birkaç cümle (>1000) için bu metin API'sini kullanırken sorunlar buldum.
Yeniden üretilebilirlik: ChatGPT'nin duyarlılıkla ilgili duyarlılık değerlendirmeleri, istemde yapılacak çok az değişiklikle (örneğin, cümleye virgül veya nokta ekleme veya çıkarma) önemli ölçüde değişebilir.
Tutarlılık: Model yanıtını açıkça belirtmezseniz, ChatGPT yaratıcı olacaktır (çok düşük bir rastgelelik parametresi seçseniz bile), sonuçların işlenmesini zorlaştıracaktır. Ayrıca, kalıbı belirttiğinizde bile tutarsız çıktı formatları verebilir.
uyumsuzluklar: Duygunun bir cümlede değerlendirilmesini istediğiniz hedef varlığı (örneğin şirket) çok kesin bir şekilde tanımlayabilse de, bunu geniş ölçekte yaparken sonuçları karıştırabilir. Örneğin, her biri bir hedef şirketle 10'ar cümle ilettiğinizi varsayalım. Yine de bazı şirketler başka cümlelerde geçiyor ya da tekrarlanıyor. Bu durumda, ChatGPT hedefleri ve cümle ifadelerini yanlış eşleştirebilir, duygu etiketlerinin sırasını değiştirebilir veya 10'dan az etiket sağlayabilir.
Tüm bu sorunlar, (önyargılı) API'yi doğru şekilde kullanmak için bir öğrenme eğrisi anlamına gelir. İhtiyacım olanı elde etmek için biraz ince ayar gerekiyordu. Bazen minimum tutarlılıkla istenen sonuca ulaşana kadar birçok deneme yapmak zorunda kaldım.
İki nedenden dolayı ideal bir durumda mümkün olduğu kadar çok cümleyi aynı anda göndermelisiniz. İlk olarak, etiketlerinizi olabildiğince hızlı almak istiyorsunuz. İkincisi, bilgi istemi maliyette belirteç olarak sayılır, bu nedenle daha az istek daha az maliyet anlamına gelir. Yine de istek başına 4096 belirteç sınırımız var. Ayrıca, bahsettiğim sorunlar göz önüne alındığında, dikkate değer başka bir API sınırlaması var. Aynı anda çok fazla cümle geçmek, uyumsuzluk ve tutarsızlık olasılığını artırır. Bu nedenle, tutarlılık ve maliyet için tatlı noktanızı bulana kadar cümle sayısını artırmaya ve azaltmaya devam etmek size kalmıştır. Bunu doğru bir şekilde yapmazsanız, işlem sonrası sonuçlar aşamasında sıkıntı yaşarsınız.
Özetle, işlenecek binlerce cümleniz varsa, yanıtların güvenilirliğini kontrol etmek için birkaç yarım düzine cümleden oluşan bir grupla başlayın ve 10'dan fazla bilgi istemi yapmayın. Ardından, görevinize en uygun istemi ve hızı bulana kadar kapasiteyi ve kaliteyi doğrulamak için sayıyı yavaşça artırın.
3. Karşılaştırmanın hükmü ve sonuçları
3.1. Karşılaştırmanın ayrıntıları
ChatGPT, GPT-3 sürümünde, sayısal değerler kullanarak metin cümlelerine duygu atfedemez (ne kadar denersem deneyeyim). Ancak uzmanlar, bu belirli Gold-Standard veri kümesindeki sayısal puanları cümle duygularına bağladılar.
Dolayısıyla, geçerli bir karşılaştırma yapmak için şunları yapmam gerekiyordu:
Veri kümesi puanlarını şu şekilde kategorilere ayırın: Olumlu, Nötrya da Negatif etiketler.
Aynı şeyi, alana özgü makine öğrenimi modelinden elde edilen puanlar için de yapın.
Bir kategorinin nerede başlayıp nerede bittiğini belirlemek için bir dizi olası eşik (0.001'lik adımlarla) tanımlayın. Ardından, verilen eşik TH,yukarıdaki puanlar +TH dikkate alındı Olumlu duygu, aşağıda -TH is Olumsuzive ve arasında Nötr.
Eşik aralığını yineleyin ve her noktada her iki modelin doğruluğunu değerlendirin.
Alana özgü modelin eğitim setinde haksız bir avantaja sahip olacağı göz önüne alındığında, performanslarını setlerle (ör. eğitim veya test) araştırın.
3. adımın kodu aşağıdadır. Ve tüm karşılaştırmayı kopyalamak için eksiksiz kod işte.
3.2. Karar: Evet, ChatGPT sadece kazanmakla kalmaz, aynı zamanda rekabeti alt üst eder
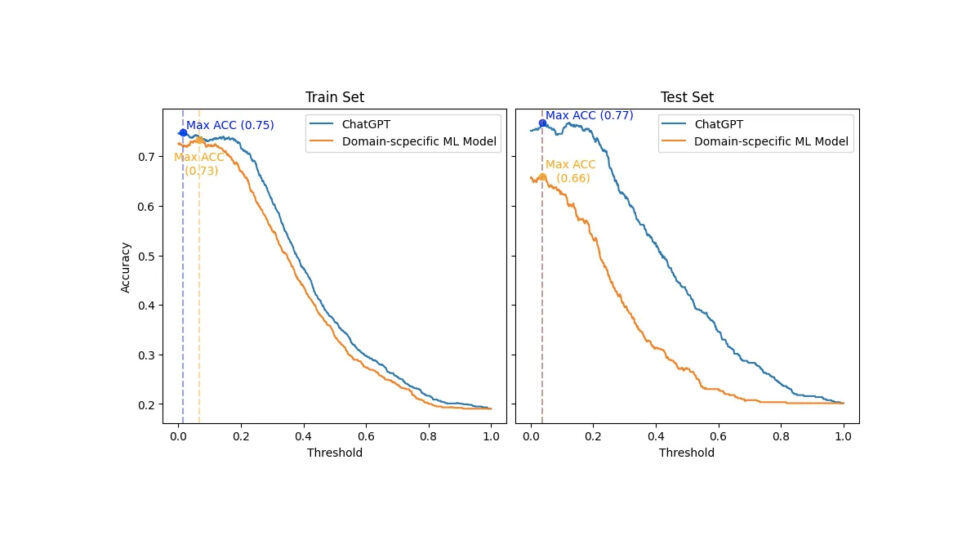
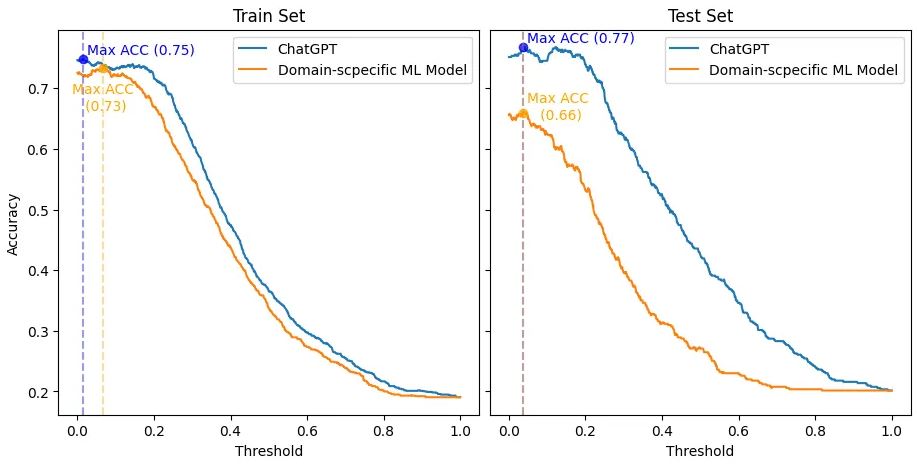
Nihai sonuç, eşik (x ekseni) ayarlandığında sayısal Altın Standart veri kümesini kategorilere ayırırken her iki model için doğruluğun (y ekseni) nasıl değiştiğini gösteren aşağıdaki çizimde görüntülenir. Ayrıca, eğitim ve test setleri sırasıyla sol ve sağ taraftadır.
ChatGPT ile eğitim (sol taraf) ve test (sağ taraf) setini ayrı ayrı dikkate alan Alana özel makine öğrenimi modeli arasındaki karşılaştırma. Bu değerlendirme, her iki model için sayısal Altın Standart veri kümesini kategorize etmek için eşik değerine (x ekseni) ilişkin doğruluğun (y ekseni) nasıl değiştiğini değerlendirir.
Öncelikle dürüst olmalıyım. Bu müthiş sonucu beklemiyordum. Sonuç olarak, ChatGPT'ye haksızlık etmemek için, eğitim seti ile Etki Alanına Özel ML modelinin oluşturulacağı orijinal SemEval 2017 yarışma kurulumunu kopyaladım. O zaman gerçek sıralama ve karşılaştırma sadece test seti üzerinden gerçekleşir.
Ancak, en uygun senaryo olan eğitim setinde bile - ChatGPT için eşik değeri 0.066'ya karşı 0.014'tür - Etki Alanına Özel Makine Öğrenimi modeli, ChatGPT'nin en iyi doğruluğundan (2'e karşı 0.73) en fazla 0.75 puan daha kötü bir doğruluk elde etti. Ayrıca ChatGPT, hem eğitim hem de test setlerinde Etki Alanına Özgü modelden tüm eşiklerde üstün bir doğruluk gösterdi.
İlginç bir şekilde, her iki model için de en iyi eşik (0.038 ve 0.037) test setinde birbirine yakındı. Ve bu eşikte ChatGPT, Etki Alanına Özgü modelden (11'ya karşı 0.66) 077 puan daha iyi doğruluk elde etti. Ayrıca ChatGPT, eşik değişikliklerinde Etki Alanına Özgü Modelden çok daha iyi bir tutarlılık gösterdi. Böylece, ChatGPT'nin doğruluğunun çok daha az keskin bir şekilde düştüğü görülmektedir.
Özgeçmişte ChatGPT, Etki Alanına Özgü ML modelinden doğruluk açısından büyük ölçüde daha iyi performans gösterdi. Ayrıca, ChatGPT'nin belirli görevlere göre ince ayar yapılabileceği fikri de var. Bu nedenle, ChatGPT'nin ne kadar iyi hale gelebileceğini hayal edin.
3.3. ChatGPT yaklaşım etiketlemesini inceleme
Her zaman ChatGPT'nin hatalı olduğu örnekleri alarak ve Etki Alanına Özgü Model ile karşılaştırarak daha mikro bir araştırma yapmayı amaçladım. Ancak, ChatGPT beklenenden çok daha iyi gittiği için, yalnızca doğru duyguyu kaçırdığı durumları araştırmaya geçtim.
Başlangıçta, öncekine benzer bir değerlendirme yaptım, ancak şimdi bir kerede tüm Gold-Standard veri setini kullanıyorum. Ardından, Altın Standart sayısal değerleri ChatGPT'nin en iyi doğruluğunu (0.016) sağlayan Pozitif, Nötr ve Negatif etiketlere dönüştürmek için eşiği (0.75) seçtim. Sonra bir karışıklık matrisi yaptım. Parseller aşağıdadır.
Sol tarafta, ChatGPT'nin doğruluğunun (y ekseni) sayısal Gold-Standard tam veri kümesini kategorize etmek için eşiğe (x ekseni) göre nasıl değiştiğini değerlendirmek için bir çizgi çizimi. Maksimum ChatGPT performansına götüren eşiğin 0.016 olduğu göz önüne alındığında, pozitif, nötr ve negatif etiketler için karışıklık matrisi sağ taraftadır. Ayrıca, karışıklık matrisi, dönüştürülen etiketlere göre ChatGPT'nin isabet ve ıskalama yüzdesini içerir.
Bir önceki bölümde olumsuz cümlelerden daha fazla olumlu puana sahip veri cümlelerinin bir dağılımını gösterdiğimi hatırlayın. Burada karışıklık matrisinde 0.016 eşiği dikkate alındığında 922 (%56.39) olumlu, 649 (%39.69) olumsuz ve 64 (%3.91) nötr cümle olduğu görülmektedir.
Ayrıca, nötr etiketlerle ChatGPT'nin daha az doğru olduğuna dikkat edin. Bunlar, eşiğin sınırlarından etkilenmeye daha yatkın olan etiketler olduğundan, bu beklenen bir durumdur. İlginç bir şekilde, ChatGPT bu tarafsız cümlelerin çoğunu olumlu olarak kategorize etme eğilimindeydi. Bununla birlikte, daha az cümle tarafsız kabul edildiğinden, bu olgu, veri kümesindeki daha yüksek pozitif duyarlılık puanları ile ilişkili olabilir.
Öte yandan, diğer etiketler göz önüne alındığında, ChatGPT, negatif kategorilerden 6 puan daha fazla pozitif kategori tanımlama kapasitesi gösterdi (%78.52'ye karşı %72.11). Bu durumda, bunun her nota spektrumunun cümle sayısıyla ilgili olduğundan emin değilim. Birincisi, çünkü her kategori türünden çok daha fazla cümle var. İkinci olarak, ChatGPT'nin etiketlere ters yönde (pozitiften negatife veya tam tersi) giden ıskalama sayısını gözlemleyin. Yine ChatGPT, sayıca çok daha az olan negatif kategoride bu tür hataları daha çok yapıyor. Bu nedenle ChatGPT, olumsuz cümlelerde olumlu olanlardan daha sorunlu görünüyor.
3.4. Bazı özel durumlar ve İnsan Uzmanları ile karşılaştırma
Altın Standart (insan puanları) ve ChatGPT arasında en göze çarpan özelliklere sahip birkaç cümle seçtim. Ardından, sayısal puanları duyarlılık etiketlerine (0.016) dönüştürmek için daha önce belirlenen aynı eşiği kullandım. Dahası, ChatGPT'nin insanlardan daha iyi performans gösterdiği zaten bildirildi. Böylece, tutarsızlıkları araştırdım ve ya İnsanların ya da bulduğum Chatgpt'nin daha kesin olduğu kararımı verdim.
Tablo, Altın Standart etiketleri (0.016 eşiği kullanılarak insan uzmanların puanlarından dönüştürülmüştür) ve ChatGPT arasındaki uyumsuzluklara sahip cümle örneklerini gösterir. Ayrıca hangisinde daha iyi anlaşırsam hükmümü verdim.
İnsan uzmanları lehine karar verdiğim davalardan başlayarak. 3. ve 4. cümlelerde ChatGPT, ödemeleri geri almanın ve şirket ittifaklarının genellikle finans alanında faydalı kabul edildiğini fark etmiş olmalıdır. Ancak, 7. cümle söz konusu olduğunda, ondan kararını açıklamasını istedim ve ChatGPT'nin yanıtı şöyle:
Barclays'e yönelik olumlu duygu, şirketin yasal sorunları düzenleyici kurumlarla başarılı bir şekilde çözmede önemli bir başarı anlamına gelen "kayıt" kelimesiyle aktarılır.
Bu cümle söz konusu olduğunda, ChatGPT, rekor bir anlaşma yapmak genellikle iyi olsa da, SEC'in düzenleyici bir kurum olduğunu anlamadı. Bu nedenle, SEC ile rekor bir anlaşma yapmak, Barclays ve Credit Suisse'in rekor miktarda para cezası ödemek zorunda kalması anlamına geliyor.
5. ve 8. cümlelere geçersek, bunlar çok zor çağrılardı. Açık konuşayım, insanlar değerlendirmelerinde haklıydı. Ancak, ChatGPT'nin bunları tahmin edemediği bir durumdur. 5. cümlede, cümlenin iyi bir sonucu temsil ettiğini anlamak için o andaki durumun bilinmesi gerekiyordu. Ve 8. cümle için, petrol fiyatındaki düşüşün söz konusu belirli hedef şirket için hisse senedi fiyatındaki düşüşle ilişkili olduğu bilgisi gereklidir.
Ardından, bir cümlenin sıfır duyarlılık puanıyla alabileceği en nötr olan 6. cümle için ChatGPT kararını şu şekilde açıkladı:
Yatırım Bankası'nın yeni bir COO'sunun atandığını açıkladığı için cümle olumlu, bu şirket için iyi bir haber.
Ancak bu, genel ve pek bilgilendirici olmayan bir yanıttı ve ChatGPT'nin bu özel yöneticinin atanmasının neden iyi olduğunu düşündüğünü haklı çıkarmadı. Böylece, bu durumda insan uzmanlarıyla anlaştım.
İlginç bir şekilde, ChatGPT için 1, 2, 9 ve 10. cümlelerde olumlu karar verdim. Ayrıca, dikkatli bakıldığında, insan uzmanların hedef şirkete veya genel mesaja daha fazla dikkat etmesi gerekirdi. Bu özellikle 1. cümlede semboliktir; burada uzmanlar, duygu Glencore için olumlu olsa da, hedef şirketin raporu az önce yazan Barclays olduğunu fark etmiş olmalıdır. Bu anlamda ChatGPT, bu cümlelerdeki duygu hedefini ve anlamı daha iyi ayırt etti.
4. Sonuç ve Sonuç Tartışması
Aşağıdaki tabloda görüldüğü gibi, böyle bir performansa ulaşmak çok fazla mali ve insan kaynağı gerektiriyordu.
Parametre sayısı, kullanılan kelime gömme boyutu, maliyet, onu oluşturacak araştırmacı sayısı, test setindeki en iyi doğruluk ve kararının açıklanabilir olup olmadığı gibi modellerin özelliklerinin karşılaştırılması.
Bu anlamda, ChatGPT, alana özgü modelden daha iyi performans gösterse de nihai karşılaştırma, etki alanına özgü bir görev için ChatGPT'de ince ayar yapılmasını gerektirecektir. Bunu yapmak, ince ayar performansındaki kazanımların çaba maliyetlerinden daha ağır basıp basmadığını ele almaya yardımcı olacaktır.
Başka bir kayda göre, üretken metin modellerinin ve LLM'lerin popülaritesiyle, bazıları açık kaynak sürümleri ilginç bir gelecek karşılaştırması oluşturmaya yardımcı olabilir. Ayrıca, ChatGPT gibi LLM'lerin kararlarını açıklama kapasitesi, bu alanda devrim yaratabilecek olağanüstü, muhtemelen beklenmedik bir başarıdır.
5. BONUS: Uygulamalı bir senaryoda bu karşılaştırma nasıl yapılabilir?
Farklı alanlardaki duygu analizi, kendi başına bağımsız bir bilimsel çabadır. Yine de duygu analizi sonuçlarını uygun bir senaryoda uygulamak başka bir bilimsel problem olabilir. Ayrıca, mali alandaki cümleleri düşündüğümüz için, uygulamalı bir akıllı sisteme duygu özellikleri eklemeyi denemek uygun olacaktır. Bu tam olarak bazı araştırmacıların yaptığı şey ve ben de bunu deniyorum.
Uygulamalı durumlar için piyasa duyarlılığının pekiştirici öğrenme mimarisine nasıl dahil edileceğine dair bir mimari örneğinin bir parçası. Kaynak:Akıllı Ticaret Sistemleri: Duyarlılığa Duyarlı Takviye Öğrenme Yaklaşımı. İkinci ACM Uluslararası Finansta Yapay Zeka Konferansı Bildirileri (ICAIF '21). Lima Paiva, FC; Felizardo, LK; Bianchi, RA d. CB; Kosta, AHR
Bu mimari, Gold-Standard veri kümesindekiler gibi sayısal duyarlılık puanlarıyla çalışacak şekilde tasarlanmıştır. Yine de, teknikler var (örn. Bullishnex endeksi) ChatGPT tarafından uygun sayısal değerlerde oluşturulan kategorik duyarlılığı dönüştürmek için. Böyle bir dönüştürmenin uygulanması, böyle bir mimaride ChatGPT etiketli duyarlılığın kullanılmasını mümkün kılar. Üstelik bu, böyle bir durumda neler yapabileceğinize dair bir örnek ve benim gelecekteki bir analizde yapmayı düşündüğüm şey bu.
5.1. Araştırma alanımdaki diğer makaleler (NLP, RL)
Davis, B., Cortis, K., Vasiliu, L., Koumpis, A., Mcdermott, R. ve Handschuh, S. X-Scores tarafından desteklenen Sosyal Duyarlılık Endeksleri. ALLDATA, İkinci Uluslararası Büyük Veri, Küçük Veri, Bağlantılı Veri ve Açık Veri Konferansı (2016).