
Editöre göre resim
Veri bilimi, bilgisayar bilimi alanında kaydedilen ilerlemeler nedeniyle son yüz yılda muazzam bir şekilde büyüyen bir alandır. Bilgisayar ve bulut depolama maliyetlerinin ucuzlaması sayesinde, artık birkaç yıl öncesine kıyasla çok daha düşük bir maliyetle çok miktarda veriyi depolayabiliyoruz. Hesaplama gücünün artmasıyla birlikte, makine öğrenimi algoritmalarını büyük veri kümeleri üzerinde çalıştırabilir ve bunları içgörü üretmek için dağıtabiliriz. Ağ teknolojisindeki gelişmeler sayesinde, internet üzerinden ışık hızında veri üretip iletebiliyoruz. Tüm bunların sonucunda her saniye bol miktarda verinin üretildiği bir çağda yaşıyoruz. Elimizde e-posta, finansal işlemler, sosyal medya içerikleri, internetteki web sayfaları, işletmelere ait müşteri verileri, hastaların tıbbi kayıtları, akıllı saatlerden alınan fitness verileri, Youtube'daki video içerikleri, akıllı cihazlardan telemetri ve liste şeklinde veriler bulunmaktadır. devam eder. Hem yapılandırılmış hem de yapılandırılmamış formattaki bu veri bolluğu, Veri Madenciliği adı verilen bir alana yönelmemizi sağlamıştır.
Veri Madenciliği bir sonucu tahmin etmek için büyük veri kümelerinden kalıpları, anormallikleri ve korelasyonları keşfetme sürecidir. Veri madenciliği teknikleri her türlü veriye uygulanabilse de Veri Madenciliği'nin böyle bir dalı vardır. Metin madenciliği yapılandırılmamış metinsel verilerden anlamlı bilgiler bulmayı ifade eder. Bu yazıda, Metin Madenciliğinde Belge Benzerliğini bulmak için ortak bir göreve odaklanacağım.
Belge Benzerliği verimli bilgi alımına yardımcı olur. Belge benzerliği uygulamaları şunları içerir: intihal tespit etmek, web arama sorgularını etkili bir şekilde yanıtlamak, araştırma makalelerini konuya göre kümelemek, benzer haber makalelerini bulmak, benzer soruları Quora, StackOverflow, Reddit gibi bir Soru-Cevap sitesinde kümelemek ve ürünü açıklamaya göre Amazon'da gruplamak , vb. Doküman benzerliği, DropBox ve Google Drive gibi şirketler tarafından aynı dokümanın mükerrer kopyalarının saklanmasını önlemek ve böylece işlem süresinden ve depolama maliyetinden tasarruf etmek için de kullanılır.
Belge benzerliğini hesaplamanın birkaç adımı vardır. İlk adım, belgeyi vektör formatında temsil etmektir. Daha sonra bu vektörler üzerinde ikili benzerlik fonksiyonlarını kullanabiliriz. Benzerlik fonksiyonu, bir vektör çifti arasındaki benzerlik derecesini hesaplayan bir fonksiyondur. Öklid Uzaklığı, Kosinüs Benzerliği, Jaccard Benzerliği, Pearson korelasyonu, Spearman korelasyonu, Kendall Tau ve benzeri gibi birkaç ikili benzerlik fonksiyonu vardır [2]. İkili benzerlik işlevi iki belgeye, iki arama sorgusuna veya bir belge ile bir arama sorgusu arasına uygulanabilir. İkili benzerlik işlevleri daha az sayıda belgeyi karşılaştırmak için uygun olsa da, Doc2Vec, BERT gibi derin öğrenme tekniklerine dayanan ve Google gibi arama motorları tarafından arama sorgusuna dayalı olarak verimli bilgi erişimi için kullanılan daha gelişmiş teknikler de vardır. Bu yazıda Jaccard Benzerliği, Öklid Uzaklığı, Kosinüs Benzerliği, TF-IDF, Doc2Vec ve BERT ile Kosinüs Benzerliği konularına odaklanacağım.
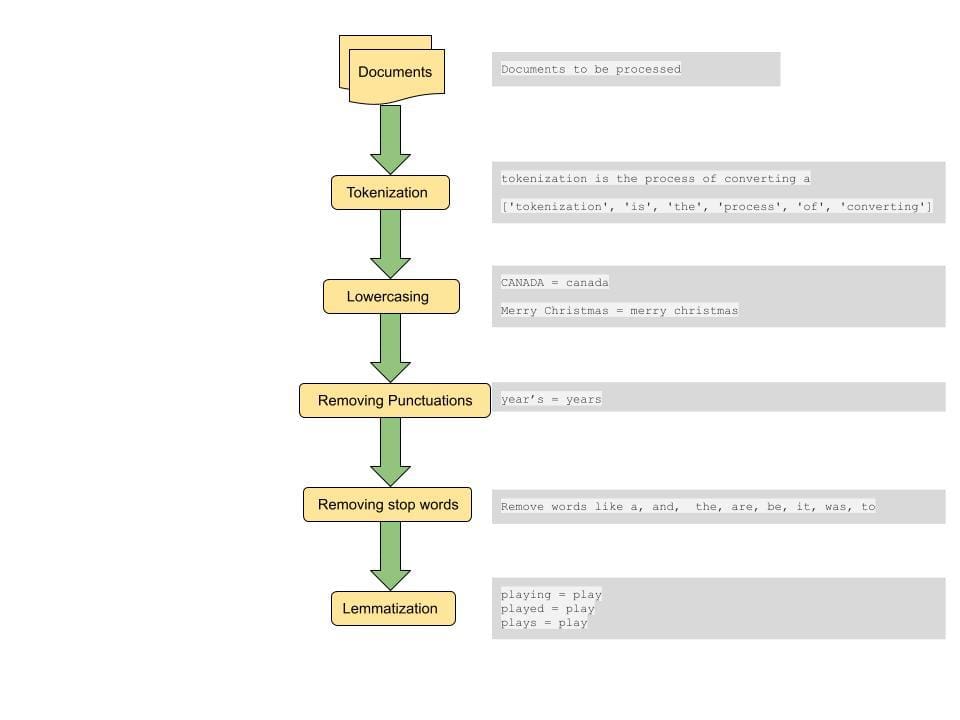
Ön İşleme
Belgeler arasındaki mesafeyi veya belgeler arasındaki benzerlikleri hesaplamanın yaygın adımlarından biri, belge üzerinde bazı ön işlemler yapmaktır. Ön işleme adımı, tüm metnin küçük harfe dönüştürülmesini, metnin simgeleştirilmesini, durdurulan sözcüklerin kaldırılmasını, noktalama işaretlerinin kaldırılmasını ve sözcüklerin lemmatize edilmesini içerir[4].
dizgeciklere: Bu adım, cümleleri işlenmek üzere daha küçük birimlere ayırmayı içerir. Belirteç, bir cümlenin bölünebileceği en küçük sözcüksel atomdur. Bir cümle, ayırıcı olarak boşluk kullanılarak belirteçlere bölünebilir. Bu tokenleştirmenin bir yoludur. Örneğin, "tokenizasyon gerçekten harika bir adımdır" biçimindeki bir cümle, ['tokenizasyon', 'dir', a, 'gerçekten', 'harika', 'adım'] biçimindeki belirteçlere bölünür. Bu belirteçler Metin Madenciliğinin yapı taşlarını oluşturur ve metinsel verilerin modellenmesinde ilk adımlardan biridir.
Küçük harf: Bazı özel durumlarda harflerin korunması gerekebilir, ancak çoğu durumda farklı büyük/küçük harfe sahip kelimeleri tek bir kelime gibi ele almak isteriz. Büyük bir veri setinden tutarlı sonuçlar elde etmek için bu adım önemlidir. Örneğin, bir kullanıcı 'hindistan' kelimesini arıyorsa, arama sorgusuyla alakalıysa "Hindistan", "HİNDİSTAN" ve "hindistan" gibi farklı büyük/küçük harflerle kelimeler içeren ilgili belgeleri almak isteriz.
Noktalama İşaretlerinin Kaldırılması: Noktalama işaretlerinin ve boşlukların kaldırılması, aramanın önemli kelimelere ve belirteçlere odaklanmasına yardımcı olur.
Durdurma sözcüklerinin kaldırılması: Durdurma sözcükleri, İngilizce dilinde yaygın olarak kullanılan bir dizi sözcüktür ve bu tür sözcüklerin kaldırılması, sorgunun bağlamını aktaran daha önemli sözcüklerle eşleşen belgelerin alınmasına yardımcı olabilir. Bu aynı zamanda özellik vektörünün boyutunun azaltılmasına ve böylece işlem süresinin kısaltılmasına yardımcı olur.
Lemmatizasyon: Lemmatizasyon, kelimeleri kök kelimelerle eşleştirerek seyrekliğin azaltılmasına yardımcı olur. Örneğin, 'Oyunlar', 'Oynadı' ve 'Oynama'nın tümü oyunla eşlenir. Bunu yaparak aynı zamanda özellik kümesinin boyutunu küçültüyoruz ve en alakalı belgeyi ortaya çıkarmak için bir kelimenin farklı belgelerdeki tüm varyasyonlarını eşleştiriyoruz.
Bu yöntem en kolay yöntemlerden biridir. Kelimeleri simgeleştirir ve paylaşılan terim sayısının toplamını, her iki belgedeki toplam terim sayısının toplamına göre hesaplar. İki belge benzerse puan bir, iki belge farklıysa puan sıfırdır [3].
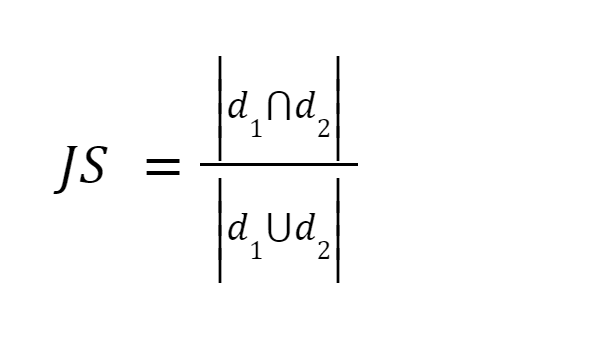
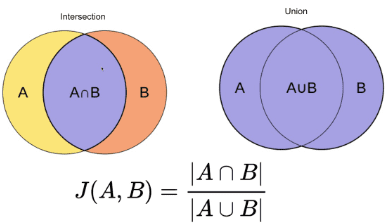
Resim kaynağı: O'Reilly
Özet: Bu yöntemin bazı dezavantajları vardır. Belgenin boyutu arttıkça, iki belge anlamsal olarak farklı olsa da ortak sözcük sayısı da artacaktır.
Belgeyi ön işleme tabi tuttuktan sonra belgeyi bir vektöre dönüştürüyoruz. Vektörün ağırlığı, terimin belgede kaç kez geçtiğini saydığımız terim frekansı olabilir veya terim sayısının toplam terim sayısına oranını hesapladığımız göreceli terim frekansı olabilir. belgede [3].
d1 ve d2, n terimin vektörleri olarak temsil edilen (n boyutu temsil eden) iki belge olsun; daha sonra iki vektör arasındaki düz bir çizgiyi bulmak için pisagor teoremini kullanarak iki belge arasındaki en kısa mesafeyi hesaplayabiliriz. Mesafe ne kadar büyük olursa benzerlik o kadar düşük olur; mesafe ne kadar az olursa iki belge arasındaki benzerlik o kadar yüksek olur.
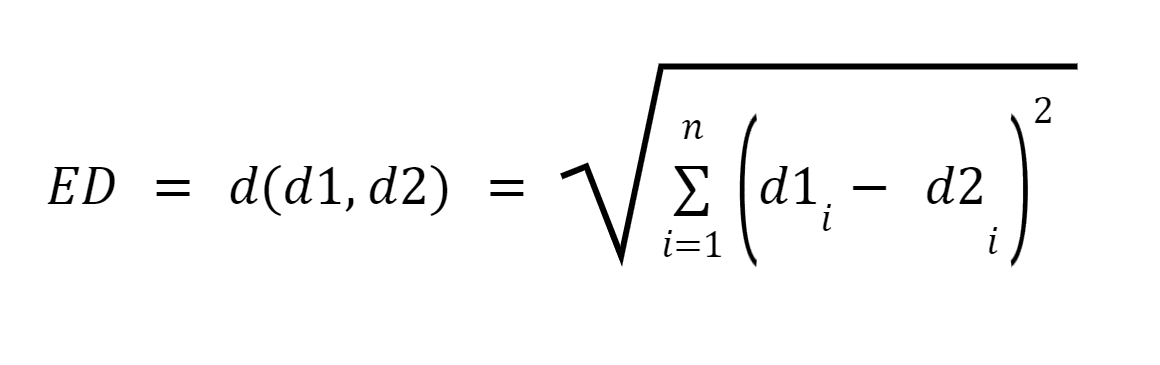
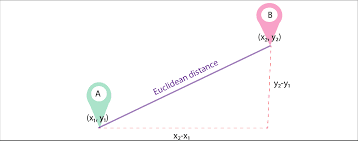
Resim Kaynağı: Medium.com
Özet: Bu yaklaşımın en büyük dezavantajı, belgelerin boyutu farklı olduğunda, iki belgenin doğası benzer olmasına rağmen Öklid Uzaklığı'nın daha düşük bir puan vermesidir. Vektörün büyüklüğü belgedeki sözcük sayısıyla doğru orantılı olduğundan, daha küçük belgeler daha küçük büyüklükte vektörlerle, daha büyük belgeler ise daha büyük büyüklükte vektörlerle sonuçlanır, böylece toplam mesafe daha büyük olur.
Kosinüs benzerliği, iki vektör arasındaki açının kosinüsünü ölçerek belgeler arasındaki benzerliği ölçer. Kosinüs benzerliği sonuçları 0 ile 1 arasında değer alabilir. Vektörler aynı yönü gösteriyorsa benzerlik 1, vektörler zıt yönleri gösteriyorsa benzerlik 0'dır.[6]
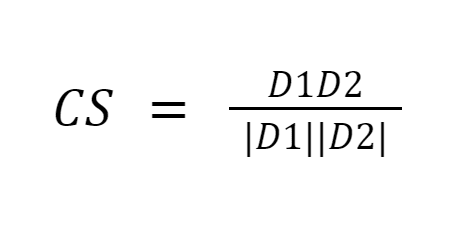
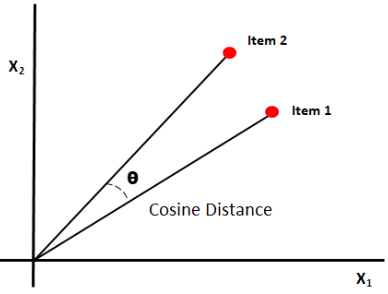
Resim Kaynağı: Medium.com
Özet: Kosinüs benzerliğinin iyi yanı, büyüklüğü değil vektörler arasındaki yönelimi hesaplamasıdır. Böylece boyutları farklı olmasına rağmen benzer olan iki belge arasındaki benzerlik yakalanacaktır.
Yukarıdaki üç yaklaşımın temel dezavantajı, ölçümün anlambilim yoluyla benzer belgeleri bulmayı gözden kaçırmasıdır. Ayrıca bu tekniklerin tümü yalnızca ikili olarak yapılabileceğinden daha fazla karşılaştırma yapılması gerekir.
Belge benzerliğini bulmaya yönelik bu yöntem, ElasticSearch'ün varsayılan arama uygulamalarında kullanılmaktadır ve 1972'den beri kullanılmaktadır [4]. tf-idf, frekans-ters belge frekansı terimini ifade eder. İlk önce bu formülü kullanarak terimin sıklığını hesaplıyoruz
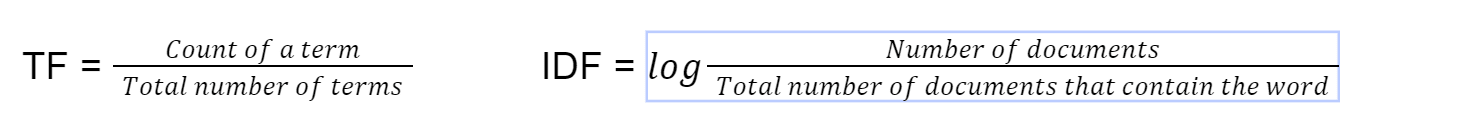
Son olarak TF*IDF'yi çarparak tf-idf'yi hesaplıyoruz. Daha sonra vektör üzerindeki kosinüs benzerliğini, vektörün ağırlığı olarak tf-idf ile kullanırız.
Özet: Terim sıklığının ters belge sıklığıyla çarpılması, genel olarak belgelerde daha sık görülen bazı sözcüklerin dengelenmesine ve belgeler arasında farklı olan sözcüklere odaklanılmasına yardımcı olur. Bu teknik, aramayı önemli anahtar kelimelere odaklayarak bir arama sorgusuyla eşleşen belgeleri bulmaya yardımcı olur.
Her ne kadar belgelerdeki tek tek kelimeleri (BOW – Kelime Çantası) vektörlere dönüştürmek için kullanmanın uygulanması daha kolay olsa da, bir cümledeki kelimelerin sırasına herhangi bir önem vermez. Doc2Vec, Word2Vec'in üzerine inşa edilmiştir. Word2Vec bir kelimenin anlamını temsil ederken, Doc2Vec bir belgenin veya paragrafın anlamını temsil etmektedir [5].
Bu yöntem, belgenin anlamsal anlamını koruyarak bir belgeyi vektör temsiline dönüştürmek için kullanılır. Bu yaklaşım, cümle veya paragraf veya belge gibi değişken uzunluktaki metinleri vektörlere dönüştürür [5]. Daha sonra doc2vec modu eğitilir. Modellerin eğitimi, daha iyi sonuçlar elde etmek için eğitim setlerini ve test seti belgelerini seçerek ve ayarlama parametrelerini ayarlayarak diğer makine öğrenimi modellerini eğitmeye benzer.
Özet: Belgenin bu şekilde vektörleştirilmiş biçimi, vektöre dönüştürülürken benzer bağlam veya anlama sahip paragraflar birbirine daha yakın olacağından belgenin anlamsal anlamını korur.
BERT, Google tarafından geliştirilen, NLP görevlerinde kullanılan transformatör tabanlı bir makine öğrenme modelidir.
BERT'in (Transformatörlerden Çift Yönlü Kodlayıcı Gösterimleri) ortaya çıkışıyla birlikte, NLP modelleri, bir metne hem sağdan sola hem de soldan sağa bakan devasa, etiketsiz metin bütünlükleriyle eğitilir. BERT, sonuçları iyileştirmek için "Dikkat" adı verilen bir teknik kullanır. Google'ın arama sıralaması BERT'i kullandıktan sonra büyük bir farkla iyileşti [4]. BERT'in benzersiz özelliklerinden bazıları şunlardır:
- 104 dildeki Wikipedia makaleleriyle önceden eğitilmiştir.
- Metne hem soldan sağa hem de sağdan sola bakar
- Bağlamın anlaşılmasına yardımcı olur
Özet: Sonuç olarak BERT, göreve özgü önemli mimari değişikliklere gerek kalmadan soru cevaplama, cümleyi başka kelimelerle ifade etme, Spam Sınıflandırıcı, Derleme dili algılayıcı gibi birçok uygulama için ince ayar yapılabilir.
Belge benzerliğini bulmada benzerlik fonksiyonlarının nasıl kullanıldığını öğrenmek harikaydı. Şu anda senaryoya en uygun benzerlik fonksiyonunu seçmek geliştiriciye kalmıştır. Örneğin, tf-idf şu anda belgeleri eşleştirmek için en son teknolojidir, BERT ise sorgu aramaları için en son teknolojidir. Senaryoya göre hangi benzerlik fonksiyonunun en uygun olduğunu otomatik olarak algılayan ve dolayısıyla bellek ve işlem süresi için optimize edilmiş bir benzerlik fonksiyonu seçen bir araç oluşturmak harika olurdu. Bu, özgeçmişlerin iş tanımlarıyla otomatik olarak eşleştirilmesi, belgelerin kategoriye göre kümelenmesi, hastaların tıbbi kayıtlarına göre hastaların farklı kategorilere göre sınıflandırılması gibi senaryolarda büyük ölçüde yardımcı olabilir.
Bu yazıda belge benzerliğini hesaplamak için bazı önemli algoritmaları ele aldım. Bu hiçbir şekilde kapsamlı bir liste değildir. Belge benzerliğini bulmak için başka yöntemler de vardır ve doğru olanı seçme kararı, belirli senaryoya ve kullanım durumuna bağlıdır. tf-idf, Jaccard, Euclidien, Kosinüs benzerliği gibi basit istatistiksel yöntemler daha basit kullanım durumları için çok uygundur. Python, R'de bulunan mevcut kütüphanelerle kolayca kurulum yapılabilir ve ağır makinelere veya işleme yeteneklerine ihtiyaç duymadan benzerlik puanı hesaplanabilir. BERT gibi daha gelişmiş algoritmalar, saatler sürebilen ancak belgenin içeriğinin anlaşılmasını gerektiren analiz için etkili sonuçlar üreten ön eğitim sinir ağlarına dayanır.
Referans
[1] Heidarian, A. ve Dinneen, M. J. (2016). Belgeler Arasındaki Benzerlik Düzeyinin Ölçülmesine ve Belge Kümelenmesine Yönelik Hibrit Geometrik Yaklaşım. 2016 IEEE İkinci Uluslararası Büyük Veri Bilgi İşlem Hizmeti ve Uygulamaları Konferansı (BigDataService), 1-5. https://doi.org/10.1109/bigdataservice.2016.14
[2] Kavitha Karun A, Philip, M. ve Lubna, K. (2013). Belge kümelemede benzerlik ölçümlerinin karşılaştırmalı analizi. 2013 Uluslararası Yeşil Bilgi İşlem, İletişim ve Enerjinin Korunması Konferansı (ICGCE), 1-4. https://doi.org/10.1109/icgce.2013.6823554
[3] Lin, Y.-S., Jiang, J.-Y. ve Lee, S.-J. (2014). Metin Sınıflandırma ve Kümeleme için Benzerlik Ölçümü. Bilgi ve Veri Mühendisliğinde IEEE İşlemleri, 26(7), 1575-1590. https://doi.org/10.1109/tkde.2013.19
[4] Nishimura, M. (2020, 9 Eylül). 2020'nin En İyi Belge Benzerliği Algoritması: Yeni Başlayanlar İçin Kılavuz - Veri Bilimine Doğru. Orta. https://towardsdatascience.com/the-best-document-similarity-algorithm-in-2020-a-beginners-guide-a01b9ef8cf05
[5] Sharaki, O. (2020, 10 Temmuz). Doc2vec ile Belge Benzerliğinin Tespiti – Veri Bilimine Doğru. Orta. https://towardsdatascience.com/detecting-document-similarity-with-doc2vec-f8289a9a7db7
[6] Lüthe, M. (2019, 18 Kasım). Benzerliği Hesaplayın - Özetle En İlgili Metrikler - Veri Bilimine Yönelik. Orta. https://towardsdatascience.com/calculate-similarity-the-most-relevant-metrics-in-a-nutshell-9a43564f533e
[7] S. (2019, 27 Ekim). Benzerlik Ölçümleri - Metin Makalelerinin Puanlanması - Veri Bilimine Yönelik. Orta. https://towardsdatascience.com/similarity-measures-e3dbd4e58660
Poornima Muthukumar Microsoft'ta Kıdemli Teknik Ürün Yöneticisidir ve bulut bilişim, yapay zeka, dağıtılmış ve büyük veri sistemleri gibi çeşitli alanlara yönelik yenilikçi çözümler geliştirme ve sunma konusunda 10 yılı aşkın deneyime sahiptir. Washington Üniversitesi'nden Veri Bilimi alanında yüksek lisans derecem var. Microsoft'ta AI/ML ve Büyük Veri Sistemleri konusunda uzmanlaşmış dört Patentim var ve 2016 yılında Yapay Zeka Kategorisinde Global Hackathon'un kazananı oldum. Bu yıl 2023 Yazılım Mühendisliği kategorisi için Grace Hopper Konferansı inceleme panelinde yer almaktan onur duydum. Bu alanlarda yetenekli kadınların başvurularını okuyup değerlendirmek ve kadınların teknolojide ilerlemesine katkıda bulunmak da değerli bir deneyimdi. onların araştırmalarından ve içgörülerinden öğrenmek için. Ayrıca Microsoft Machine Learning AI ve Veri Bilimi (MLADS) Haziran 2023 konferansında komite üyesiydim. Aynı zamanda Dünya Veri Biliminde Kadınlar Topluluğu ve Veri Bilimini Kodlayan Kadınlar Topluluğu'nun da Elçisiyim.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/evaluating-methods-for-calculating-document-similarity?utm_source=rss&utm_medium=rss&utm_campaign=evaluating-methods-for-calculating-document-similarity

