Giriş
Sahte banknotlar hem küçük hem de büyük işletmeler için kolaylıkla sorun haline gelebilir. Bu banknotların gerçek olmadıklarını tespit edebilmek çok önemlidir. Bu süreç, günlük iş profesyonelleri ve nakit ile uğraşan bireyler için zaman alıcı olabilir. Bu, otomasyon yoluyla bu hedefe ulaşma ihtiyacını gerektirir. AI, Makine Öğrenimi ve derin öğrenme sayesinde.
Sonuç olarak, bir geliştirme ihtiyacı görüyoruz. Otomatik Makine Öğrenimi Profesyonel olmayan kişiler tarafından bile bu banknotların gerçekliğini tespit etmek için kullanılabilecek sahte banknot algılama modeli.
Bu makale, bankacılık sektöründe derin öğrenme ve görüntü sınıflandırmasının nasıl kullanılabileceğine dair gerçek dünyadan bir prototip geliştirdiğimiz pratik bir projeyi kapsamaktadır. Amaç, gerçek hayattaki bir problem senaryosunu kullanarak bir makine öğrenimi demosunu tamamlamaktır. Veri toplama ve derinlemesine temizleme/ön işlemeden basitçe eğitilmiş modeli devreye almaya geçeceğiz.
Modelin performansını ve ne kadar uygun bir şekilde öğrenildiğinden emin olmak için bazı uygun değerlendirme ölçütleri kullanacağız. Bu bir bankacılık sistemi olduğu için tahminlerin doğru olduğundan emin olmak istiyoruz.
Bu makale, Veri Bilimi Blogatonu.
İçindekiler
Sorun bildirimi
Giriş bölümünde tartışıldığı gibi, sahte banknot ile gerçek banknot arasında ayrım yapmak çoğu kişi için zor bir iştir. Çoğu insanın bu alanda herhangi bir becerisi yoktur ve dolandırıcılar tarafından iyi para birimlerini sahte paralarla değiştirmek için kolayca kandırılabilirler. Araştırma için profesyonel olarak sunulan orijinal ve sahte Kolombiya banknotlarını kullanarak bu sorunu çözme mücadelesine girişeceğiz.

Bu projeyi tamamlamanın ön koşulları, makine öğrenimi modeli ardışık düzenleri bilgisi, jupyter not defterleriyle ilgili temel deneyim ve bunu derin öğrenme ile daha ileriye götürme ilgisidir. Bu, görüntü işlemeyle ilgili ilk deneyiminiz olsa bile endişelenmenize gerek yok çünkü her set kolayca kavranabilir hale getirildi.
Veri Kümesi Açıklaması
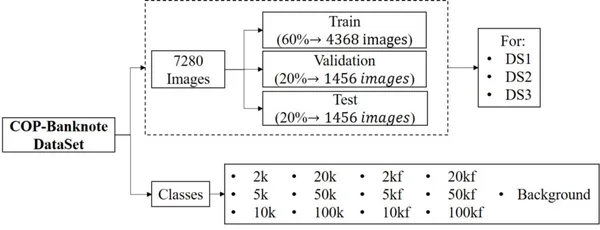
Veri seti, 2020 yılında Universidad Militar Nueva Granada tarafından CC BY 4.0 lisansı altında kullanıma sunuldu. Veri seti, banknotlardaki kupürleri ve sahteleri tespit etmek için sistemleri gerçek zamanlı olarak kontrol etmek için kullanılabilir. Veri kümesi, boyut ve görüntü sayısı açısından büyüktür ve hem sahte hem de gerçek sınıfların profesyonelce çekilmiş görüntülerinden oluşur. Aşağıdaki vurguyu görelim:
- Veri seti, 20800'sı orijinal banknotlara, 13'sı sahte banknotlara ve arka plan için 6 ek kategoriye karşılık gelen 6 sınıf içeren 1 görüntüden oluşmaktadır.
- Banknotların aydınlatma varyasyonlarını, döndürme ve kısmi görünümlerini içerir. ds3, ds20800 ve ds1'e karşılık gelen, her biri 2 görüntüden oluşan 3 klasör içerir.
- Her klasör, görüntüleri içeren bir eğitim, doğrulama ve test alt klasörü içerir.
- Tüm sınıflar, görüntü sayısı bakımından dengelidir.
Proje Hattı
Diğer yandan, ele alacağımız her şeyi kavrayabilmek için, geliştirilen modelin çeşitli adımlarını aşağıda ayrıntılı olarak özetledim:
- Ortamı kurma
- Bağımlılıkları içe aktarma
- Veri Kümesini Okuyun ve Yükleyin
- Veri dönüşümü
- Veri Goruntuleme
- Tensorboarding
- Model Binası
- Tahminleri Görselleştirme
- Evrişimli Ağı İnce Ayarlama
- Eğitim ve Değerlendirme
- Öğrenilen matrisler için TensorBoard ile raporlama
- Model Testi
- Eğitilmiş model yapısını kaydetme
- Yerel olarak dağıtma
- Buluta Dağıtım (Streamlit Cloud)
Not: Uygulamayı takip etmek için, özellikle bilgisayarınızda yerel bir GPU veya grafik kartınız yoksa, bu çalışmayı Google Colab kullanarak çoğaltmanızı tavsiye ederim. Derin öğrenmenin zorluklarından biri bilgi işlem ortamıdır, ancak ücretsiz GPU sağlayan Google Colab sayesinde size bunu nasıl devreye alacağınızı göstereceğim.
Adım-1: Ortamı Kurma
Daha fazla uzatmadan birkaç kod yazmaya başlayalım. Google'ı kullanıyor olacağız CoLab geliştirme ortamı olarak. Artık Google Colaboratory için çevrimiçi olarak kolayca Google'da arama yapabilir veya şu adresi ziyaret edebilirsiniz: https://colab.research.google.com/. Jüpyter ile aynı arayüze sahiptir, bu yüzden sadece bir google hesabına ihtiyacınız olduğunu anlamak için fazla zaman almaz. Ana sayfa aşağıdaki gibi görünür:

Şimdi çalışma zamanına ekleyerek kullanıma sunulan ücretsiz GPU'yu kullanalım. "Çalışma Zamanı" sekmesine tıklayın ve aşağıda gösterildiği gibi "Çalışma zamanı türünü değiştir"i seçin.

"Donanım hızlandırıcı" altında, açılır menüyü tıklayın ve aşağıda gösterildiği gibi "GPU" öğesini seçin!
Artık GPU'nuz bağlı. Artık kodlarla devam edebiliriz.
Bağımlılıklarımızı import etmeye başlamadan hemen önce son bir şey yapmamız gerekiyor; aşağıdaki satırı kullanarak matplotlib ile arsalarımız için hazırlanıyoruz. bu, çıktıların veya grafiklerin düzenlenmesine yardımcı olacaktır.
#magic function for matplotlib graphs. Graphs will be included in notebook next to the code. %matplotlib inlineAdım-2: Bağımlılıkları İçe Aktarma
#importing dependencies
from __future__ import print_function, division from datetime import datetime
from PIL import Image
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
from torchvision.datasets import ImageFolder
import torchvision.transforms as T
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
import time
import os
import copy plt.ion() # interactive mode3. Adım: Veri Kümesinin Yüklenmesi
Veri kümesinin bağlantısını bu makalenin sonunda veya bu makaleye eşlik eden genel GitHub deposunda bulabilirsiniz. Veri setini indirdikten sonra kolay kullanım için google drive'ınıza yükleyebilirsiniz. Zaten orada var ve sürücüyü sağ sütundan yükleyip hücreyi çalıştıracaktım.
from google.colab import drive
drive.mount('/content/drive')#Dataset from drive DATA_FILE = "/content/drive/MyDrive/MLProjects/dataset/COP"
train_dataset_location = "/content/drive/MyDrive/Datasets/dataset/COP/Train/"
val_dataset_location = "/content/drive/MyDrive/Datasets/dataset/COP/Validation/"Not: Yukarıdaki snippet için, yolu kendi google drive dosya yolunuzla değiştirmelisiniz.
Adım-4: Veri Dönüşümü
#changing the format and structure of the data.
data_transforms = { 'Train': transforms.Compose([ transforms.Resize((224, 224)),# resizing the image dimention transforms.RandomHorizontalFlip(),# generating different possible image position transforms.ToTensor(), # tensors are like the data type for deep learning images transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # normalizes the tensor image for each channel regards mean and SD ]), 'Validation': transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), 'Test': transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]),
} data_dir = DATA_FILE
data_types = ['Train', 'Validation', 'Test'] # grouping into the various sets
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in data_types}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4, shuffle=True, num_workers=4) for x in data_types}
dataset_sizes = {x: len(image_datasets[x]) for x in data_types}
class_names = image_datasets['Train'].classes #checking for available processor device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")Adım-5: Veri Görselleştirme
Veri görselleştirme yardımı ile görselden verinin nasıl göründüğünü ve neyle uğraştığımızı görebiliriz.
# Reasigning images for visualization
image_size = 300
batch_size = 128
# converting to Tensors for visualization purpose
train_dataset = ImageFolder(data_dir+'/Train', transform=ToTensor())
val_dataset = ImageFolder(data_dir+'/Validation', transform=ToTensor())img, label = val_dataset[13]
print(img.shape, label)
imgYukarıdaki kod bize dizin 13'teki val_dataset'lerden birinin tensör versiyonunu gösterir.
def imshow(inp, title=None): """Imshow for Tensor.""" inp = inp.numpy().transpose((1, 2, 0)) mean = np.array([0.485, 0.456, 0.406]) std = np.array([0.229, 0.224, 0.225]) inp = std * inp + mean inp = np.clip(inp, 0, 1) plt.imshow(inp) if title is not None: plt.title(title) plt.pause(0.001) # pause a bit so that plots are updated # Get a batch of training data
inputs, classes = next(iter(dataloaders['Train'])) # Make a grid from batch
out = torchvision.utils.make_grid(inputs) imshow(out, title=[class_names[x] for x in classes])
# attempting to show the image classes and directories
print("List of Directories:", os.listdir(data_dir))
classes = os.listdir(data_dir + "/Train")
print("List of classes:", classes)Dizin Listesi: ['Doğrulama', 'Test', 'Eğitim'] Sınıfların listesi: ['2k', '20k', '50kf', '20kf', '5kf', 'Arka Plan', '5k', '50k', '10k', '10kf', '100k', '2kf', '100kf']
# carrying out more visualization
import matplotlib.pyplot as plt def show_example(img, label): print('Label: ', train_dataset.classes[label], "("+str(label)+")") plt.imshow(img.permute(1, 2, 0)) import random
random_value = random.randint(1, 2000)# getting random images
show_example(*train_dataset[2000])
random_value = random.randint(1, 2000)
show_example(*train_dataset[random_value])
random_value = random.randint(1, 2000)
show_example(*train_dataset[random_value])
Adım-6: Tensorboarding
TensorBoard, çeşitli parametrelerin nasıl değiştiğini daha sonra görselleştirebilmeniz için makine öğrenimi eğitimi yürütmenin iyi bir yoludur. Makine öğrenimi iş akışı sırasında ölçümlerdeki değişimi görselleştirme olarak sağlamaya yarayan bir araçtır. Bir tür parametre günlüğü olarak görülebilir. Son çalıştırma için Kayıp, Doğruluk ve hatta aykırı değerleri izlemek için burada kullanacağız.
KOD GİRİŞİ:
#tensorboard logging
#to track various metrics such as accuracy and log loss on training or validation set
from torch.utils.tensorboard import SummaryWriter TB_DIR = f'runs/exp_{datetime.now().strftime("%Y%m%d-%H%M%S")}' tb_train_writer = SummaryWriter(f'{TB_DIR}/Train')
tb_val_writer = SummaryWriter(f'{TB_DIR}/Validation') %load_ext tensorboardAdım-7: Model Oluşturma
Etin peynirle buluştuğu yer burasıdır. Ya da henüz değil. Daha sonra çağırabileceğimiz, istediğimiz tüm parametreler ve ayarlarla bir yardımcı fonksiyon oluşturalım.
KOD GİRİŞİ:
# helper function
def train_model(model, criterion, optimizer, scheduler, num_epochs=4): since = time.time() best_model_wts = copy.deepcopy(model.state_dict()) best_acc = 0.0 for epoch in range(num_epochs): print('Epoch {}/{}'.format(epoch, num_epochs - 1)) print('-' * 10) # Each epoch has a training and validation phase for phase in ['Train', 'Validation']: if phase == 'Train': model.train() # Set model to training mode else: model.eval() # Set model to evaluate mode running_loss = 0.0 running_corrects = 0 # Iterate over data. for inputs, labels in dataloaders[phase]: inputs = inputs.to(device) labels = labels.to(device) # zero the parameter gradients optimizer.zero_grad() # forward # track history if only in train with torch.set_grad_enabled(phase == 'Train'): outputs = model(inputs) _, preds = torch.max(outputs, 1) loss = criterion(outputs, labels) # backward + optimize only if in training phase if phase == 'Train': loss.backward() optimizer.step() # statistics running_loss += loss.item() * inputs.size(0) running_corrects += torch.sum(preds == labels.data) if phase == 'Train': scheduler.step() epoch_loss = running_loss / dataset_sizes[phase] epoch_acc = running_corrects.double() / dataset_sizes[phase] if phase == 'Train': tb_writer = tb_train_writer else: tb_writer = tb_val_writer tb_writer.add_scalar(f'Loss', epoch_loss, epoch) tb_writer.add_scalar(f'Accuracy', epoch_acc, epoch) print('{} Loss: {:.4f} Acc: {:.4f}'.format( phase, epoch_loss, epoch_acc)) # deep copy the model if phase == 'Validation' and epoch_acc > best_acc: best_acc = epoch_acc best_model_wts = copy.deepcopy(model.state_dict()) print() time_elapsed = time.time() - since print('Training complete in {:.0f}m {:.0f}s'.format( time_elapsed // 60, time_elapsed % 60)) print('Best val Acc: {:4f}'.format(best_acc)) tb_train_writer.close() tb_val_writer.close() # load best model weights model.load_state_dict(best_model_wts) return modelAdım-8: Tahminleri Görselleştirme
Yine de tahmin yapmak için başka bir yardımcı fonksiyon yazıyoruz. Kodun daha basit bir sürümü bu aşamayı atlayabilir ve yalnızca elde edilen doğruluğu kullanabilir.
KOD GİRİŞİ:
def visualize_model(model, dataset, num_images=6): was_training = model.training model.eval() images_so_far = 0 fig = plt.figure() with torch.no_grad(): for i, (inputs, labels) in enumerate(dataloaders[dataset]): inputs = inputs.to(device) labels = labels.to(device) outputs = model(inputs) _, preds = torch.max(outputs, 1) for j in range(inputs.size()[0]): images_so_far += 1 ax = plt.subplot(num_images//2, 2, images_so_far) ax.axis('off') ax.set_title('predicted: {}'.format(class_names[preds[j]])) imshow(inputs.cpu().data[j]) if images_so_far == num_images: model.train(mode=was_training) return model.train(mode=was_training)Adım-9: Convnet'te İnce Ayar Yapma
Önceden eğitilmiş bir model yükleyeceğiz ve tamamen bağlı son katmanı sıfırlayacağız. bu uygulama Transfer Öğrenimi olarak bilinir. Parametrelerle ilgili yaptığımız ayarlara güvenmek yerine, önceden eğitilmiş modelden bazı bilgileri ödünç almaya karar verdik. Bu, ResNet18 olarak bilinen artık bir ağdır.
Artık Ağlar: Derin öğrenme, birçok Yapay Sinir Ağı türünden oluşur ve Artık Sinir Ağı bunlardan biridir.
KOD GİRİŞİ:
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to number of classes.
# Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)).
model_ft.fc = nn.Linear(num_ftrs, len(class_names)) model_ft = model_ft.to(device) criterion = nn.CrossEntropyLoss() # Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9) # Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)Adım-10: Eğitim ve Değerlendirme
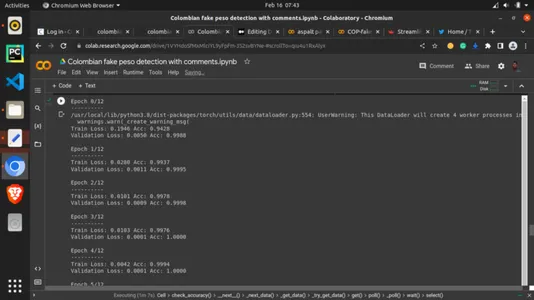
Sonunda peynir etle buluşuyor. Şimdi önceki yardımcı fonksiyonumuzu çağırıyoruz ve en iyi deneyi yaptığımız gibi eğitim parametrelerini atayacağız. Dönemleri 13 olarak ayarladık. Dönemler, tüm eğitim verilerinin yineleme sayısı olarak eğitim verilerine bir kerede bakılan turlardır. Eğitim setinin bir algoritma etrafında aldığı görüntüleme sayısı olarak görülebilir. Bu kesinlikle önemlidir. Ne kadar çok görünürse o kadar iyi ama modelin çok göründüğü bir durumdan da kaçınmak istiyoruz. 13 dönem, burada 13 kez olacağı anlamına gelir, ancak daha yüksek ve daha düşük değerlerle deneyler yapabilirsiniz.
KOD GİRİŞİ:
# setting the number of epochs and other key parametersp model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=13)ÇIKIŞ:
Adım-11: Öğrenilen metrikler için TensorBoard gösteriliyor
KOD GİRİŞİ:
# calling the tensorboard %tensorboard --logdir='./runs'Adım-12: Eğitimli Modeli Kaydetme
Son olarak bu article.save yöntemi ve PyTorch .pt uzantılı modeli torch ile kaydedeceğiz. Bir dakika bekleyin, ardından sol sütunda kayıtlı mod olup olmadığını kontrol edin, üzerine sağ tıklayın ve indir'i seçin. Mod bilgisayarınıza indirilecektir. Buna artefakt denir. Bu yapıtı bir sonraki bölümde kullanacağız.
KOD GİRİŞİ:
torch.save(model_ft, 'model100.pt')
Adım-13: Kayıtlı Modeli Yerel Olarak Dağıtma
Bu eğlenceli yol. Bir GUI ile tahminler yaparak modelimizi gerçek zamanlı olarak görmeye çalışacağız. Burada Streamlit çerçevesi için bir python betiği oluşturacağız. Kodun ayrıntıları, bu makaleye eşlik eden GitHub deposundadır. Streamlit, makine öğrenimi çerçevelerini yerel olarak veya bulutta dağıtmak için tasarlanmış hafif bir çerçevedir. Önce yerel, sonra bulut sürümünü göreceğiz. Bir dosya oluşturun ve onu python .py uzantılı olarak dilediğiniz bir kod düzenleyicide kaydedin ve aşağıdaki kodu yazın.
KOD GİRİŞİ:
# importing dependencies
import io
from PIL import Image
import streamlit as st
import torch
from torchvision import transforms
import base64 # setting background
def add_bg_from_local(image_file): with open(image_file, "rb") as image_file: encoded_string = base64.b64encode(image_file.read()) st.markdown( f""" <style> .stApp {{ background-image: url(data:images/{"jpg"};base64,{encoded_string.decode()}); background-size: cover }} </style> """, unsafe_allow_html=True )
add_bg_from_local('images/bg2.jpg') # importing model
MODEL_PATH = 'model/model100.pt'
# importing class names
LABELS_PATH = 'model/model_classes.txt' # image picker
def load_image(): uploaded_file = st.file_uploader(label='Pick a banknote to test') if uploaded_file is not None: image_data = uploaded_file.getvalue() st.image(image_data) return Image.open(io.BytesIO(image_data)) else: return None def load_model(model_path): model = torch.load(model_path, map_location='cpu') model.eval() return model def load_labels(labels_file): with open(labels_file, "r") as f: categories = [s.strip() for s in f.readlines()] return categories def predict(model, categories, image): preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(image) input_batch = input_tensor.unsqueeze(0) with torch.no_grad(): output = model(input_batch) probabilities = torch.nn.functional.softmax(output[0], dim=0) all_prob, all_catid = torch.topk(probabilities, len(categories)) for i in range(all_prob.size(0)): st.write(categories[all_catid[i]], all_prob[i].item()) def main(): st.title('Colombian Pesu banknote Detection') model = load_model(MODEL_PATH) categories = load_labels(LABELS_PATH) image = load_image() result = st.button('Predict image') if result: st.write('Checking...') predict(model, categories, image) if __name__ == '__main__': main()Not: modelle birlikte içe aktarılan sınıflar dosyası da oluşturulmalıdır. Bunu yapmak için "model_classes.txt" adlı bir metin dosyası oluşturun. Bunu kaydedin ve ardından modeli, python betiğiyle aynı dizinde "model" adlı bir klasöre indirin. Ayrıca, sınıf adlarının nasıl eğitildiklerine göre olması gerektiğine dikkat etmelisiniz. Bunu, yukarıdaki sınıfları ve dizinleri yazdırdığımız yerden bulabilirsiniz. Model, aşağıda gösterildiği gibi metin dosyasını satır satır okuyacağından, her sınıfın tek bir satır almasına izin verin.
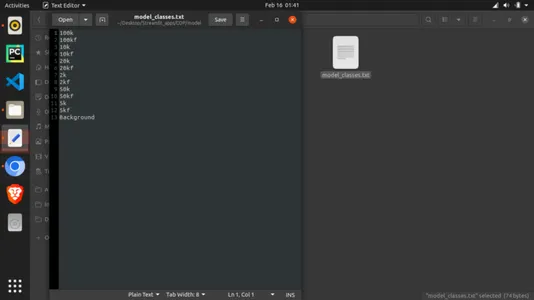
Python betiğini çalıştırmak için, halihazırda sahip değilseniz bazı paketleri kurmalısınız. Depoda bulabileceğiniz bağımlılıklar şunlardır:
- akıcı
- meşale
- meşale
Bağımlılıkları kurduktan sonra, betiğinizin bulunduğu dizindeki bir terminalde çalıştırın:
streamlit run filename.pyUmarım, bu, uygulamanızı aşağıdaki gibi göstermelidir:

Adım-14: Buluta Dağıtma
Belki de makine öğrenimi uygulamanızı size yakın olmayan biriyle paylaşmak istiyorsunuz. Bu, Bulut altyapısı aracılığıyla yapılabilir. Depoyu Streamlit Cloud'a bağlamak için çalışma dizininizi GitHub gibi bir çevrimiçi kod yönetim platformuna taşımanız gerekir. Git'i kullanarak dizininizi zorlayın ve şu adrese gidin: https://streamlit.io/cloud aşağıdaki gibi ana ekran ile:
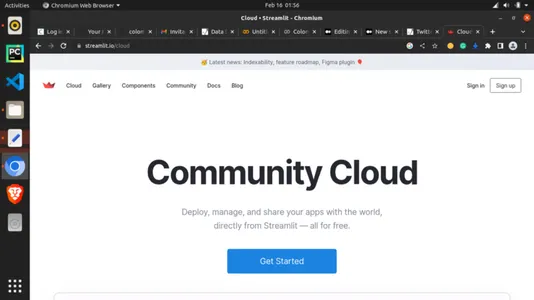
Kaydolun ve "Başlayın"ı tıklayın. Kaydolmanız istenecektir. Tamamen ücretsiz! Kaydolduktan sonra, uygulamanın bulunduğu GitHub deponuzu seçin ve seçin. Uygulamanız çalışırken dağıtmayı ve beklemeyi seçin! Artık bağlantıyı paylaşmak için kopyalayabilirsiniz.
Sonuç
Aerodinamik topluluk bulutunu kullanarak güzel ve güçlü bir makine öğrenimi ürününü eğitmeyi, kaydetmeyi ve buluta dağıtmayı başardık. 100. dönemde de %3 doğruluk elde ettik.
Anahtar teslim paketler
- Sahte banknotlar, bankacılık sektörü için kolayca sorun haline gelebilir. Bu banknotları tanımlayabilmek, derin öğrenmeyi kullanarak başarabildiğimiz bir görevdi.
- Profesyonel olmayan kişiler tarafından bile bu banknotların gerçekliğini tespit etmek için kullanılabilecek bir Otomatik Makine Öğrenimi Sahte banknot tespit Modeli geliştirdik.
- %100 doğrulukla Kayıp ve Doğruluk da dahil olmak üzere bazı uygun değerlendirme ölçütleri kullandık.
- Derin öğrenmeyi kullanarak modeli hem yerel olarak hem de bulutta devreye aldık.
Referanslar
Pachon Suescun, Cesar; Ballesteros, Dora Maria; Renza, Diego (2020), “Orijinal ve sahte Kolombiya pesosu banknotları”, Mendeley Data, V1, doi: 10.17632/tj8kvrbfz6.1
Hızlı Linkler
Genel GitHub deposu: https://github.com/inuwamobarak/Deep-learning-in-Banking
Veri kümesi: https://data.mendeley.com/datasets/tj8kvrbfz6/1
Akış ışığı: https://streamlit.io/
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/02/deep-learning-in-banking-colombian-peso-banknote-detection/

