I
Bu teknik çağda, Büyük Veri beklenmedik bir şekilde büyüdüğü için devrimci olduğu kanıtlanmıştır. Anket raporlarına göre, mevcut verilerin yaklaşık %90'ı yalnızca son iki yılda üretildi. Büyük veri, veri kümelerinin geniş hacminden başka bir şey değildir.
Büyük veri, birden çok şirketin ürünlerini ve hizmetlerini daha iyi tanımasına ve bunlar hakkında değerli bilgiler üretmesine yardımcı olur. Big Daechnology her alanda genişliyor ve endüstrinin pazarlama kampanyalarını ve tekniklerini iyileştirmenin yanı sıra Yapay Zeka (AI) segmentlerinin ve otomasyonun genişlemesine yardımcı oluyor.
Günümüzde, dünya çapındaki her işletme, iş hizmetlerini düzene sokmak ve yönetmek için Büyük Veri profesyonellerine yönelik gereksinimler aradığından, istihdam fırsatları çok büyüktür. İşverenler, güçlü bilgilerini ve verilere ve piyasaya olan ilgilerini göstererek işi kolayca bulabilirler. Büyük Veri, Veri Analisti, Veri Bilimcisi, Veritabanı yöneticisi (DBA), Büyük Veri Mühendisi (BDA), Hadoop Mühendisi vb. gibi çeşitli pozisyonlar sunar.
Öğrenme hedefleri
- Bir Büyük Veri analisti olarak güçlü bir kariyere adım atmak için Büyük Veriyi anlayın.
- Büyük veri ve türleri hakkında derin bir bilgiye sahip olun.
- Büyük verideki temel V'leri ve bunların önemini bilin.
- Büyük veri ve Hadoop'un kullanım durumları ve uygulamaları hakkında bilgi edinin.
- Hadoop'un büyük verilerde nasıl kullanıldığını anlayın.
Bu makale, Veri Bilimi Blogathon.
- Büyük Veri terimini anlama
- Farklı Büyük Veri Türleri
- Büyük Veride 5 V
- Büyük Veri ve Hadoop'un İlk 3 Kullanım Durumu
4.1Netflix
4.2 Über
4.3 Walmart'ı - Büyük Veride Hadoop Kullanımı
- Sonuç
Terimi Anlamak: Büyük Veri
büyük Veri geleneksel ilişkisel veritabanlarının kaldıramayacağı kadar geniş kapsamlı ve genellikle karmaşık veri kümeleriyle ilişkilidir. Devasa bir veri koleksiyonu üzerinde işlem yapmak için özel araçlara ve metodolojilere ihtiyaç duyarlar. büyük Veri ses, video, fotoğraf, web sitesi vb. yapılandırılmış, yarı yapılandırılmış ve yapılandırılmamış veri setlerinden oluşur. Bu verileri aldığımız n sayıda kaynak vardır. Veri kaynaklarından bazıları şunlardır: -
-
E-posta takibi
-
Sunucu günlükleri
-
Akıllı Telefonlar ve Akıllı Saatler
-
İnternet çerezleri
-
sosyal medya
-
Tıbbi kayıtlar
-
Makine sensörleri ve IoT Cihazları
-
Çevrimiçi satın alma işlem formları
İşletmeler bu yapılandırılmamış ve ham veri kümelerini günlük olarak topluyor ve bu verileri yönetmek ve işlerini daha iyi anlamak için Büyük veri teknolojisine ihtiyaçları var. Büyük veriler, endüstrilerin verilerle desteklenen daha iyi iş kararları almasına yardımcı olan anlamlı bilgileri çıkararak veri kümelerini yönetir.
Büyük Verinin işleyişini üç aşamalı bir süreç olarak anlayalım!
-
Entegrasyon: çeşitli heterojen kaynaklardan veri toplamayı içeren çalışmanın ilk adımıdır. Toplanan verileri birleştirir ve iş içgörüleri sağlayacak şekilde analiz edilebilecek bir formata dönüştürür.
-
Yönetim: Toplandıktan sonra, değerli bilgiler için madencilik yapmak ve uygulanabilir içgörülere dönüştürmek için veriler dikkatli bir şekilde yönetilmelidir. Büyük miktarda Büyük Veri yapılandırılmamıştır, bu nedenle verileri tablo biçiminde depolayan geleneksel ilişkisel veritabanlarında depolayamayız.
-
Analiz: Bu analiz aşamasında veriler çıkarılır ve veri bilimcileri, büyük veri kümelerini incelemek ve verileri daha derinden anlamak için genellikle makine öğrenimi, derin öğrenme ve tahmine dayalı modelleme gibi gelişmiş teknolojileri kullanır.
Farklı Büyük Veri Türleri
Yapılandırılmış, yarı yapılandırılmış ve yapılandırılmamış olmak üzere üç Büyük Veri türü vardır. Her birini anlayalım!

Kaynak: devopedia.org
Yapılandırılmış Veriler: Adından da anlaşılacağı gibi, veriler, verileri depolamak ve işlemek için belirli bir formatı izleyen oldukça organize verilerdir. Nitelikler düzenlendikçe, örneğin cep telefonu numaraları, sosyal güvenlik numaraları, PIN kodları, çalışan ayrıntıları, atama ayrıntıları ve maaşlar gibi verileri kolayca alabiliriz. RDBMS'de (İlişkisel veritabanı yönetimi) depolanan veriler, yapılandırılmış verilere bir örnektir ve kullanabiliriz SQL (Yapılandırılmış Sorgu Dili) bu tür verileri işlemek ve yönetmek için.
Yapılandırılmamış Veri: Adından da anlaşılacağı gibi, yapılandırılmamış veri verileri depolamak ve işlemek için herhangi bir belirli yapı veya formatı takip etmeyen, oldukça düzensiz verilerdir. RDBMS'de depolanamaz ve yapılandırılmış bir biçime dönüştürülene kadar analiz bile edemeyiz. Yapılandırılmamış veriler, günlük olarak en çok üretilen verilerdir ve görüntü, ses, video, sosyal medya gönderileri, gözetim verileri, çevrimiçi alışveriş verileri vb. yapılandırılmamış.
Yarı yapılandırılmış Veri: Yarı yapılandırılmış veri, belirli bir formatı olmayan ancak kendisiyle ilişkili sınıflandırma özelliklerine sahip yapılandırılmış ve yapılandırılmamış verilerin bir kombinasyonudur. Örneğin, videolar ve resimler çekildikleri yer, tarih veya kim tarafından çekildikleri ile ilgili dahili semantik etiketler veya meta veriler veya işaretler içerebilir, ancak içindeki bilgilerin herhangi bir yapısı yoktur. XML veya JSON dosyaları, yarı yapılandırılmış verilerin yaygın örnekleridir.
Büyük Veride 5 V
Büyük verilerdeki 5 V terimi şunları temsil eder:
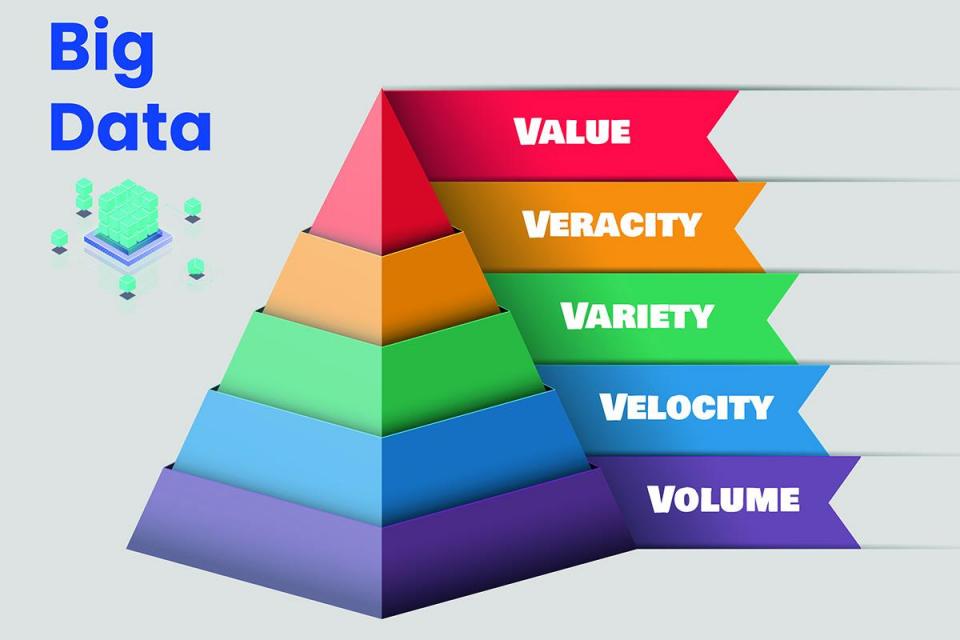
Kaynak: timesofmalta.com
-
Cilt: Hacim, yüksek oranda büyüyen devasa veri miktarından başka bir şey değildir. Günümüzde veri hacmi terabayt, petabayt ve hatta daha fazladır. Bu devasa veri hacmi ambarlarda saklanır ve incelenmesi ve işlenmesi gerekir. Veriler o kadar geniş ki, onu ilişkisel veritabanlarında saklayamıyoruz. Hadoop gibi dağıtılmış sistemlere ihtiyacımız var ve MongoDB veri parçalarını birden çok yerde depolamak ve yazılım tarafından bir araya getirmek.
-
Hız: Hız, büyük miktarda verinin üretilme, depolanma ve analiz edilme hızıdır. Hız, verilerin gerçek zamanlı olarak üretilme hızını gösterir. Her saniye ses, video, gönderi vb. üreten sosyal medya örneğini alabiliriz. Bu nedenle, yapılandırılmamış veriler dünya çapında yıldırım hızında artmaktadır.
-
Çeşit: Çeşitlilik, günlük olarak kullandığımız farklı veri türleri anlamına gelir. Geçmişte veriler çok basitti ve yapılandırılmış bir formatta (isim, cep telefonu numarası, adres, e-posta kimliği vb.) saklanabilirdi, ancak şimdi veriler çok farklı. Artık, çeşitli kaynaklardan toplanan, yapılandırılmış, yapılandırılmamış ve yarı yapılandırılmış çeşitli verilerimiz var. Metin, ses, video vb. çeşitli formatlardaki verileri işlemek için yenilikçi ve uygun algoritmalara sahip özel analiz ve işleme teknolojilerine ihtiyacımız var.
-
veracity: Doğruluk, mevcut verilerin kalitesinden veya güvenilirliğinden başka bir şey değildir. Veri doğruluğu, analiz edilen verilerin doğruluğu ve kesinliği ile ilgilidir. Örneğin, Twitter hashtag'ler, imlalar, kısaltmalar, yazım hataları vb. ile saniyede gönderiler oluşturuyor ve verilerin doğruluğuna ve kalitesine güvenemiyorsak bu tonlarca veri işe yaramaz.
-
Değer: Ham veriler günlük olarak üretilir, ancak işe yaramaz. Yararlı bilgiler elde etmek için onu değerli bir şeye dönüştürmeliyiz. Anlamlı bir yatırım getirisi üretirsek verileri değerli görebiliriz.
Büyük Veri ile Başa Çıkmak İçin Farklı Yaklaşımlar
büyük Veri bir işletmenin rakipleri üzerinde olağanüstü bir rekabet gücü olduğu kanıtlanmıştır; bir işletme, büyük verinin yeteneklerini nasıl kullanmak istediğine karar verebilir. Kuruluşlar, amaçlarına göre çeşitli iş faaliyetlerini kolaylaştırabilir ve gereksinimlerine göre Büyük Verinin potansiyelini kullanabilir.
Büyük Veri ile başa çıkmak için temel yaklaşım, işletmenin ihtiyaçlarına/taleplerine ve mevcut bütçe hükümlerine dayanmaktadır. Öncelikle hangi sorunu çözdüğümüze, ne tür verilere ihtiyacımız olduğuna, verilerimizden neyi cevaplamak istediğimize ve bundan ne elde etmek istediğimize karar vermeliyiz. Bundan sonra, Büyük Veri işleme için aşağıdaki yaklaşımlarla gidebiliriz.
-
Toplu işleme: Toplu işlemede, benzer verileri toplarız, gruplandırırız (toplu olarak adlandırılır) ve işlenmek üzere bir analiz sistemine besleriz. Toplu işlemeyi, yüksek hacimli verileri işlememiz gerektiğinde ve veri boyutu bilindiğinde ve sınırlı olduğunda kullanabiliriz.
-
Akış işleme: Akış işlemede, sürekli bir veri akışını üretildiği anda işleriz ve işleme genellikle gerçek zamanlı olarak yapılır. Veri akışı sürekli olduğunda ve anında yanıt gerektirdiğinde ve veri boyutu bilinmediğinde ve sonsuz olduğunda akış işlemeyi kullanabiliriz.
Büyük Veri ve Hadoop'un İlk 3 Kullanım Durumu
Netflix
Netflix, kullanıcıları için yüksek kaliteli isteğe bağlı video akışı sunan dünyaca ünlü bir eğlence şirketidir.
Netflix, kullanıcılarına tam olarak keyif aldıkları içeriği sağlayarak pazardaki hızı belirliyor. Peki Netflix'in nelerden hoşlandığınızı nasıl bildiğini biliyor musunuz? Cevap, Büyük Veri Analitiği kullanılarak açıktır.
Netflix son derece doğru öneri sistemini oluşturmak ve kullanıcının talebini karşılamak için Büyük veri analitiğini kullanıyor.
Düşünmek, nasıl?
Netflix, izlediğimiz veya aradığımızla ilgili verilerimizi analiz eder, müşterilerin hangi başlıkları izlediği, hangi türü sevdikleri, oynatmanın ne sıklıkta durdurulduğu, derecelendirmelerin verildiği vb. tavsiye sistemi. Bu, müşterilerin ihtiyaçlarını varsaymak yerine (çoğu şirketin yaptığı gibi) bilmek açısından kararları sorunsuz ve kesin hale getirecektir.
Bu süreçte kullanılan başlıca veri yapıları arasında Hadoop, Hive, Pig ve diğer geleneksel iş zekası yer alır.
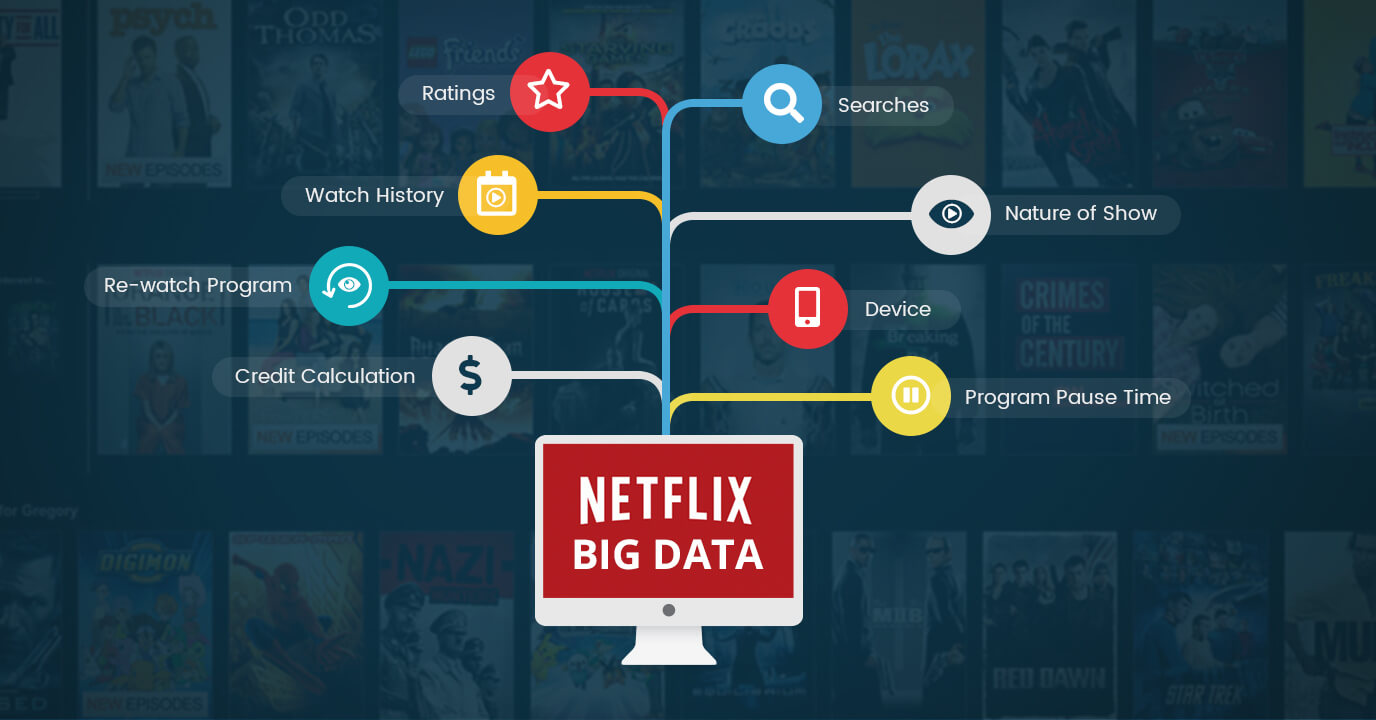
Kaynak: www.muvi.com/
Uber
Günümüzde Uber'siz hayatımızı hayal edemiyoruz; Nereye gitmek istersek, Uber sadece bir tık ötemizde ve teslimatları göndermek için de kullanabiliriz.
Şimdi Uber'in verilerimizi nasıl kullandığını veya Uber'de büyük verinin rolünü düşünüyor olabilirsiniz.
Yani önce bir düşünelim, sık sık aynı yerlere gittiniz ama her seferinde aynı meblağı ödediniz mi? Cevap apaçık hayır.
Uber, verilerimizi bu şekilde kullanıyor. Uber, sunulan hizmetlerin fiyatlarını yönetmek için hizmetlere olan talebe ve arza odaklanır.
Dalgalanma Fiyatlandırması, Uber tarafından alınan büyük verilerin en büyük avantajıdır. Örneğin, bir tren istasyonuna veya havaalanına taksi arıyorsanız, sizden ne istenirse ödemeye hazırsınız ve Uber zamanın bu kritikliğini anlıyor ve fiyatları artırıyor. Ya da bayram günlerinde bile fiyatlarda artış göreceksiniz.
Walmart
Walmart, 2 milyonu aşkın çalışanı ve 20,000 ülkede 28 mağazasıyla dünyanın en büyük perakendecisi ve gelir devidir.
Walmart, "büyük veri" terimini bilmediğimiz zamanlarda bile, yıllardır Büyük veri analitiğini kullanıyor. Veri modellerini keşfetmek, ürün tavsiyeleri sağlamak ve müşteri taleplerini kullanarak analiz etmektir. Veri Madenciliği.
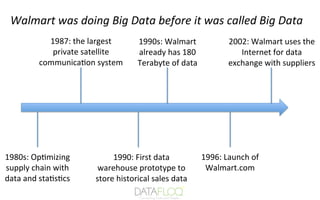
Kaynak: www.slideshare.net
Bu analiz kullanımı, Walmart'ın müşteri dönüşüm oranını artırmasına, alışveriş deneyimini optimize etmesine ve üstün bir müşteri deneyimi sunmak için sınıfının en iyisi e-ticaret teknolojilerini sağlamasına yardımcı olur.
Walmart gibi teknolojileri kullanır NoSQL ve etkili kullanım için çeşitli kaynaklardan toplanan ve merkezileştirilmiş gerçek zamanlı verilere dahili kullanıcılara erişim sağlamak için Hadoop.
Büyük Veride Hadoop Kullanımı
Büyük veri, yüksek hızda üretilen yapılandırılmamış ve yapılandırılmış verilerde olabilen çeşitli türlerdeki veri hacimlerinden oluşur. Büyük Veri bir varlık olarak kabul edilebilir ve bu varlıkla başa çıkmak için bir araca ihtiyacımız var. Hadoop, büyük verileri depolama, işleme ve analiz etme sorunuyla başa çıkmak için kullanılan bir araçtır. Hadoop, karmaşık yapılandırılmamış veri kümelerini işlemek, depolamak ve analiz etmek ve ticari donanım kümelerinde uygulamaları çalıştırmak için kullanılan açık kaynaklı bir yazılım programıdır. Herhangi bir veri için büyük depolama sağlar ve birden fazla makineye dağıtıldığı ve paralel olarak işlendiği için kolaylaştırır.
Hadoop'un büyük verileri nasıl daha iyi bir şekilde ele aldığını anlamak için yaygın olarak kullanılan bazı Hadoop komutlarını tartışalım!
1. Hadoop'ta Mkdir Komutu
mkdir, “make directory” anlamına gelir; komut, Hadoop kümesinin belirtilen yolunda belirli bir ada sahip yeni bir dizin oluşturur; tek kısıtlama, dizinin zaten mevcut olmaması gerektiğidir. Kümede aynı ada sahip dizin varsa, dizinin varlığını gösteren bir hata oluşturur.
Sözdizimi:-
Hadoop fs -Mkdir /yol_adı/dizin_adı
2. Hadoop'ta "Touchz" Komutu
Hadoop'taki "Touchz" komutu, Hadoop kümesinin belirtilen yolunda belirli bir ada sahip yeni bir boş dosya oluşturmak için kullanılır. Bu komut yalnızca verilen dizin varsa çalışır, herhangi bir dosya oluşturmaz ve bunun yerine dizinin kümede bulunmadığını belirten bir hata gösterir.
Sözdizimi:-
Hadoop fs -touchz/dizin_adı/dosya_adı
3. Hadoop'ta LS Komutu
LS, Hadoop'ta liste anlamına gelir; komut, belirtilen dizinde veya yolda bulunan dosyaların/içeriklerin listesini görüntüler. Dosyalar hakkında daha fazla bilgi almak veya filtrelenmiş bir biçimde bilgi almak için ls komutu ile çeşitli seçenekler ekleyebiliriz, örneğin:
-
-c: Dosya veya dizinlerin tam adresini almak için “ls” komutu ile “-c” seçeneğini kullanabiliriz.
-
-R: Bu seçenek, dizinlerin içeriğini yinelemeli bir sırada istediğimizde kullanılır.
-
-S: Bu seçenek, dizindeki dosyaları boyutlarına göre sıralar. Yani, ne zaman en yüksek veya en küçük dosya boyutuna sahip istersek, bu fonksiyonla gidebiliriz.
-
-t: Bu aynı zamanda “ls” komutuyla en sık kullanılan seçenektir çünkü dosyayı değiştirme zamanına göre sıralar, yani en son kullanılan dosyayı listenin ilk konumuna getirir.
Sözdizimi:-
Hadoop fs -ls/yol_adı
4. Hadoop'ta Test Komutu
Adından da anlaşılacağı gibi, bu komut Hadoop kümesindeki bir dosyanın varlığını test etmek için kullanılır ve yalnızca kümede yol varsa “1” döndürür. Bu komut “[defsz]” gibi birden çok seçenek kullanır, hadi bunları anlayalım!
Sözdizimi:-
Hadoop fs -testi -[defsz]
Seçenekler:-
-
-d: Bu seçenek, kullanıcı tarafından sağlanan yolun bir dizin olup olmadığını test eder ve yol bir dizin ise “0” döndürür.
-
-e: Bu seçenek, kullanıcı tarafından sağlanan yolun var olup olmadığını test eder ve yol kümede varsa "0" döndürür.
-
-f: Bu seçenek, kullanıcı tarafından sağlanan yolun bir dosya olup olmadığını test eder ve verilen yol bir dosya ise “0” döndürür.
-
-s: Bu seçenek, kullanıcı tarafından sağlanan yolun boş olup olmadığını test eder ve yol boş değilse "0" döndürür.
-
-r: Bu seçenek, kullanıcı tarafından sağlanan yolun var olup olmadığını ve okuma izni verilip verilmediğini test eder. Yalnızca yol mevcutsa ve okuma izni de verilmişse "0" döndürür.
-
-w: Bu seçenek, kullanıcının sağladığı yolun var olup olmadığını ve yazılı izin verilip verilmediğini test eder. Yalnızca yol mevcutsa ve ayrıca yazma izni verilirse "0" döndürür.
-
-z: Bu seçenek, verilen dosyanın boyutunun sıfır bayt olup olmadığını test eder ve dosya boyutu sıfır bayt ise "0" döndürür.
5. Hadoop'ta Komut Bulun
Adından da anlaşılacağı gibi, bu komut Hadoop kümesinde bulunan dosyaları aramak için kullanılır. Komutta belirtilen ifadeyi kümedeki tüm dosyalarla tarar ve tanımlanan ifadeyle eşleşen dosyaları döndürür. Yolu açıkça belirtmediysek, varsayılan olarak mevcut çalışma dizinini aldı.
Sözdizimi:-
Hadoop fs-bul ..
6. Hadoop'ta Metin Komutu
Hadoop'taki metin komutu, esas olarak zip dosyasının kodunu çözmek ve kaynak dosyanın içeriğini metin biçiminde görüntülemek için kullanılır. Kaynak dosyayı kodlar, işler ve son olarak içeriğini düz metin biçiminde çözer.
Sözdizimi:-
Hadoop fs -metin
7. Hadoop'ta Sayım Komutu
Adından da anlaşılacağı gibi, bu komut belirtilen yol altındaki dosya, dizin ve bayt sayısını sayar. Çıktıyı gereksinimlerimize göre değiştirmek için çeşitli seçeneklerle birlikte count komutunu kullanabiliriz, örneğin:
-
-q – Bu seçenek, kotayı göstermek için kullanılır; bu, toplam ad sayısı sınırı ve bireysel dizinler için kullanılan alan kullanımı anlamına gelir.
-
-u – Bu seçenek yalnızca kotaları ve kullanımı görüntüler.
-
-h – Bu seçenek, dosya boyutlarını insan tarafından okunabilir bir biçimde görüntüler.
-
-v – Bu seçenek, başlık satırını görüntülemek için kullanılır.
Sözdizimi:-
Hadoop fs -count [seçenek]
8. Hadoop'ta GetMerge Komutu
Getmerge komutu, adından da anlaşılacağı gibi, Hadoop kümesindeki belirli bir dizindeki bir veya daha fazla dosyayı yerel dosya sistemindeki tek bir yerel dosyada birleştirir. Söz dizimindeki “src_dest” ve “local_dest” sözcükleri kaynak ve yerel hedefleri temsil eder.
Sözdizimi:-
Hadoop fs -Birleştirme
9. Hadoop'ta AppendToFile Komutu
Bu kabuk komutu, tek veya birden çok yerel dosyanın içeriğini Hadoop kümesinde sağlanan hedef dosyaya tek bir dosyaya eklemek için kullanılır. Bu komut yürütülürken, verilen yerel kaynak dosyaları, komutta verilen dosya adına göre hedef kaynağa eklenir. Ayrıca, hedef dosya dizinde yoksa, o adla yeni bir dosya oluşturur.
Sözdizimi:-
Hadoop fs -Dosyaya Ekle
Sonuç
Bu blog, kariyerinize büyük veri analizinde başlamanıza yardımcı olacak bazı önemli Büyük Veri konularını içermektedir. Bu başlangıç konularını referans olarak kullanarak, mülakatlara hazırlanmanıza ve veri analisti, Hadoop geliştiricisi, veri bilimcisi vb. olma yolunda ilerlemenize yardımcı olacak büyük veri ve Hadoop kavramını daha iyi anlayabilirsiniz. veri blogları şunlardır:
-
Büyük Veri, esas olarak işletmeler ve kuruluşlar tarafından ürünlerini veya hizmetlerini anlamak ve bundan değerli bilgiler elde etmek için kullanılan geleneksel olmayan bir stratejidir.
-
Sosyal medya gönderileri, e-postalar, cep telefonları, kredi kartları vb. birçok kaynaktan üretilen çeşitli veri türlerini tartıştık.
-
Aşağıdakileri içeren Büyük verinin 5 V'sini tartıştık:
-
Hacim: - Sahip olduğumuz veri miktarı.
-
Hız: - Verilerin oluşturulduğu, taşındığı veya erişildiği hız.
-
Çeşitlilik: - Sahip olduğumuz farklı veri kaynakları türleri.
-
Doğruluk: - Verilerimiz ne kadar güvenilir?
-
Değer: - Verilerimizin yatırım karşılığında sağladığı anlamlı getiri.
-
Büyük veride akış ve toplu işlemeyi de tartıştık.
-
Büyük miktarda veriyi en iyi şekilde işlemek için kullanılan Java ile yazılmış bir çerçeve olan Hadoop hakkında biraz tartıştık.
-
Son olarak, yaygın olarak kullanılan bazı Hadoop komutlarını söz dizimleriyle birlikte ele aldık.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/02/a-beginners-guide-to-the-basics-of-big-data-and-hadoop/

