Bu blog yazısı Federico Piccinini ile birlikte yazılmıştır.
Veri ortamı son yıllarda değişiyor: Şirketler içinde büyük miktarlarda veri üreten ve tüketen kuruluşların sayısında bir artış var ve bunların çoğu için uygun bir veri stratejisinin tanımlanması temel bir öneme sahip hale geldi. Modern bir veri stratejisi, verileri yönetmek, erişmek, analiz etmek ve veriler üzerinde hareket etmek için kapsamlı bir plan sunar.
Sonuç olarak, daha fazla şirket, verilerin etki alanına göre düzenlendiği, verilerin net sahipliğinin ve teknoloji yığınının geliştirildiği ve daha çevik bir kurulumun sağlandığı yakın zamanda tanıtılan bir paradigma olan bir veri ağı mimarisini benimsemeyi düşünüyor. Bu nedenle, bir veri ağı mimarisinden yararlanmak için bazı uygulamalarınızın veri etki alanı ayrımı için tasarlanması gerekebilir.
Bu gönderide, gerçek zamanlı öneriler gerektiren bir senaryo için veri ağı mimarisinin nasıl tasarlanacağını gösteriyoruz. Öneri sistemi şu şekilde uygulanmaktadır: Amazon Kişiselleştir, tam olarak yönetilen bir makine öğrenimi (ML) hizmetidir ve etki alanına göre veri tüketerek çalışır. Öneri kullanım durumları için, genellikle bir şirket içindeki farklı veri kaynaklarıyla ilişkili kullanıcılar, öğeler ve etkileşimler hakkındaki bilgilere erişim sahibi olmak önemlidir.
ML uygulamalarının birden fazla girdi verisi türü olabileceğinden, hem durağan veriler hem de gerçek zamanlı akış için çalışan bir çözüm öneriyoruz. Gerçek zamanlı öneriler, kullanıcının mevcut amacına uyum sağlamak için akış verileri gerektirir.
Gönderi boyunca, veri ağı paradigmasını tanıtıyoruz ve ardından olay akışı yetenekleri ekleyerek bunu gerçek zamanlı bir kullanım senaryosuna genişletiyoruz. Müşterilerine isteğe bağlı şarkıları dinleme fırsatı sunan bir müzik akışı şirketinin kullanım örneğini kullanıyoruz. Şirket ayrıca aynı platform üzerinden isteğe bağlı podcast'ler sunmaya başladı ve hızlı ML deneyi ve çıkarımı için veri erişimini desteklemek için modern bir veri mimarisinden yararlanmak istiyor.
Veri ağı: Bir paradigma kayması
Etki alanı odaklı tasarım (DDD), karmaşık çözümlerin temel iş mantığına göre etki alanlarına bölündüğü bir yazılım tasarım yaklaşımını temsil eder. DDD bağlamında sıklıkla bahsedilen bir mimari tarz, mikro hizmet mimarisi, yazılım sistemlerinin, her biri küçük bir ekibe ait olan ve iş gereksinimleri etrafında yapılandırılan, gevşek bağlı varlıklar, yani mikro hizmetler şeklinde yapılandırıldığı bir kavram. Bulut teknolojilerinin gelişmesiyle birlikte bu paradigmalar, şirketlerin yazılım güncellemelerini daha hızlı yayınlamalarına ve teknoloji yığınlarını sürekli olarak gelişen iş gereksinimlerine uyarlamalarına olanak tanıdı.
Ancak, yazılım mimarilerinden farklı olarak, çoğu veri mimarisi hala iş alanlarından ziyade teknolojiler etrafında tasarlandı. Bu, Zhamak Dehghani'nin 2019'da veri ağı. Veri ağı, bir ürün olarak ele alınan ve bir etki alanının parçası olarak işlenen verilere yönelik bir paradigma kaymasıdır. Veri ağı, DDD ilkelerini veri mimarilerine uygular: veriler, veri alanları halinde düzenlenir ve veriler, ekibin sahip olduğu ve tüketim için sunduğu ürün olarak kabul edilir. Bu, merkezi bir sahiplik modelinden, şirketlerin verilere geniş ölçekte erişmesine olanak tanıyan merkezi olmayan bir modele geçiştir. Bu değişim aynı zamanda bir veri alanına atanan her ekibin, bir mikro hizmet üzerinde çalışan yazılım mühendislerine benzer şekilde, işleri için doğru teknolojiyi seçerek veri ürünlerini oluşturmasına olanak tanır.
Veri ağı, dağıtılmış yönetişim ve self servis araçlara olan ihtiyacı vurgularken, veri yönetim sistemlerinin merkezi olmayan mülkiyetini ve dağıtımını savunur. Veri ağı yaklaşımı, veri alanı sahiplerinin daha iyi özerkliğini sağlar ve veri güvenliğinden ödün vermeden iş birimleri arasında veri paylaşımını ve federasyonu sağlamak için alanları bir araya getirir. Bu tür bir mimari, tüm verilere erişim yetkisine sahip kişiler tarafından erişilebildiği dağıtılmış veri fikrini destekler. Veri gölü ile veri ağı arasındaki temel farklardan biri, veri ağlarında verilerin tek bir veri gölünde birleştirilmesi gerekmemesi ve farklı veritabanlarında kalabilmesidir.
Veri ağını etki alanına dayalı bir veri mimarisi olarak benimsemenin ayrıntıları ve avantajları hakkında daha fazla bilgi için bkz. AWS Lake Formation ve AWS Glue kullanarak bir veri ağı mimarisi tasarlayın.
Bir veri ağının bileşenleri
Artık veri ağı paradigmasını iyi anladığımıza göre, uygulamaya ve bileşenlerine bakalım.
İlk olarak, ile başlıyoruz veri üreticileri. Bunlar, etki alanlarının belirli verilerini korumaktan, sahiplenmekten ve ifşa etmekten sorumlu olan varlıklardır. Alan ayrımı nedeniyle, her üretici kendi teknoloji yığınını bağımsız olarak seçebilir.
Aynı şekilde bizde de var veri tüketicileri. Bu bileşenler, adlarından da anlaşılacağı gibi, üreticiler tarafından sunulan bir veya daha fazla veri kaynağını kullanır. Daha önce olduğu gibi, bir veri ağı mimarisini benimsemek, her tüketicinin birbirinden bağımsız olduğu anlamına gelir; bu, farklı kullanım durumlarını çözmenin yanı sıra farklı teknoloji yığınlarını uygulayabilecekleri anlamına gelir.
The hareketsiz veri düzlemi daha sonra tarafından tamamlanır Merkezi Veri Kataloğu, üreticiler ve tüketiciler arasında bağlantı görevi gören bir bileşen. Bu orta katman, mevcut veri üreticilerini merkezi bir veri kataloğunda indekslemekten ve farklı veri kaynaklarına erişimi kontrol etmekten sorumludur.
Veri kataloğu, üreticiler tarafından veri ürünlerini (adım 1a ve 1b) kuruluşun veri bilimcilerine ve tüketici alanlarında çalışan veri mühendislerine göstermek için kullanılır. Aşağıdaki şekil, veri ürünlerinin nasıl kolayca keşfedilebileceğini göstermektedir: merkezi veri kataloğu, ilgili üretici etki alanı tarafından merkezi kataloğa kaydolduktan sonra veri tüketicilerinin ilgilendikleri veri kaynağını bulmalarına olanak tanır (2a ve 2b adımları) (adım 1a ve 1b).
Gerçek zamanlı olaylarla çalışma
Bu mimarinin yalnızca durağan verileri olduğu gibi destekleyebileceği iddia edilebilir; aslında, verileri gerçek zamanlı olarak bir üretici alanından bir tüketiciye taşımak için basit bir çözüm yoktur. Şimdiye kadar sunulan paradigma, üreticilerin veri değiştiğinde bilgilendirilmek yerine talep üzerine veri çektiği, atıl durumdaki veri senaryosunu ele alıyor.
Birçok uygulamanın ortamda meydana gelen değişikliklere hızla yanıt vermesi gerektiğinden, gerçek zamanlı veriler veri mimarilerinde önemli bir husustur. Örneğin, bir e-ticaret platformu veya bir video akış hizmeti, içerikle gerçek zamanlı kullanıcı etkileşimlerinden değer çıkarabilir. Bu durumlarda, olayları olduğu gibi izlemek, onları ML modelinde beslemek ve tahminleri buna göre uyarlamak çok önemlidir.
Bu bölümde, bu kalıbı uygulamak için çalışabilecek bazı akış platformlarını tanıtmak istiyoruz. Apache Kafka çünkü sık kullanılıyor ve birçok şirket Kafka iş yüklerini buluta taşıyor.
Apache Kafka, mikro hizmetler veya veritabanları gibi kaynaklardan gerçek zamanlı olarak veri yakalayan, olayları konulara göre düzenlenmiş akışlarda depolayan ve bu olaylara hem gerçek zamanlı hem de geriye dönük olarak tepki veren, açık kaynaklı bir dağıtılmış olay akışı platformudur. Apache Kafka üzerine kurulu olay akışı mimarileri, yayınla/abone ol paradigmasını takip eder: üreticiler, olayları bir yazma işlemi aracılığıyla konulara yayınlar ve bu tür konulara abone olan tüketiciler, olayları olduğu gibi alır. Bu senaryoda Apache Kafka'ya bir alternatif olabilir Amazon Kinesis Veri Akışları, geliştiricilerin bulutta gerçek zamanlı verileri toplamasına, depolamasına ve işlemesine olanak tanıyan bir akış hizmeti.
Örneğin bir e-ticaret platformunu düşünürsek, Ödeme için sistem yayınlama olaylarının ödeme işlevlerini çalıştıran mikro hizmet Alınan Tedaviler konu, platformda gerçekleşen her işlemin izlenmesi. Ardından, abone olan başka bir bileşenimiz olabilir. Alınan Tedaviler Örneğin, iş zekası için bir gösterge panosunu güncelleyerek olayları almak ve buna göre eylemde bulunmak için konu başlığı. Apache Kafka hakkında daha fazla bilgi için okumanızı öneririz. Apache Kafka'ya Giriş.
Olay akışı mimarisi
The hareket halindeki veri düzlemi yayınla/abone ol modelini bir veri ağı bağlamında uygulamak için tanıtıldı. Böyle bir düzlem, gerçek zamanlı olayları erişilebilir kılan merkezi bir olay akışı bileşeni aracılığıyla birbirine bağlanan üretici ve tüketici etki alanlarından oluşur. Etki alanına göre veri mimarisinden yararlanmak için, aşağıdaki şekilde gösterildiği gibi her üreticinin kendi ilgili merkezi akışına sahip olduğunu düşünüyoruz.
Olay akışını tüketicilere gerçek zamanlı olaylar gönderme kanalı olarak da düşünebilirsiniz, bu nedenle her üreticinin güncellemeleri göndermek için özel kanalı vardır.
Her tüketici, belirli veri ihtiyaçlarına göre birden fazla konuya abone olabilir. Yeni olaylar mevcut olduğunda, ilgili üretici bunları ilişkili akışta yayınlar (adım 1a ve 1b) ve aboneler olayları okuyabilir (adım 2a ve 2b), işleyebilir ve buna göre harekete geçebilir.
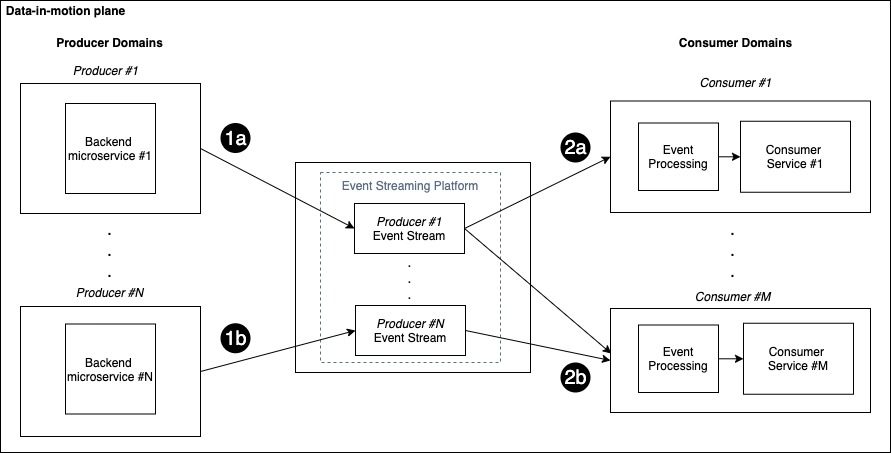
Önceki şekil, N üretici etki alanı ve M tüketici etki alanı içeren bir senaryoyu göstermektedir: her tüketici yalnızca o etki alanı için ilgi akışlarına abone olur. Bu örnekte, Tüketici #1 gelen olaylara abone olunur Yapımcı #1, süre Tüketici #M her ikisinden de gelen olaylara abone olunur Yapımcı #1 ve Yapımcı #N.
Birkaç kullanım senaryosunu ve veri alanını çözmek için bu kalıbı benimseyebilirsiniz. Örneğin, bir müzik akışı platformunda şarkı çalan bir kullanıcı, müzik akışı platformundan gönderilen yeni bir olay oluşturabilir. Etkileşimler hizmet üreticisine Kişiselleştirme tavsiye sisteminin kişiselleştirilmiş tavsiyeler ürettiği tüketici. Benzer şekilde, bir Ödeme üretici bir işlem talebi gönderebilir ve Dolandırıcılık Dedektörü Tüketici, işlemin hileli olup olmadığına karar verir.
Üreticilerin ve tüketicilerin doğru iletişim kurabilmesi için olay yük şemasının tutarlı olması gerekir. Uygulamalar şemalara bağlıdır, bu nedenle olaylarda yapılan hiçbir değişiklik, üreticiler ve tüketiciler arasındaki örtülü sözleşmeyi bozmaz. Karmaşık kullanım durumlarında, olay akışında uyumluluğu zorlamak için bir şema kayıt defteri kullanabilirsiniz. ile çalışma seçenekleri hakkında daha fazla bilgi için AWS Tutkal Şema Kayıt Defteri, bkz. Hesaplar arası AWS Glue Schema Registry'deki şemaları kullanarak Amazon MSK üzerinden akış verilerini doğrulayın.
Öneri kullanım örneği
Daha önce, belirli bir kullanım durumuna odaklanmadan veri ağı mimarisinin arkasındaki genel fikri tanıtmıştık. Bu bölümde, ağ paradigmasının AWS kullanılarak uygulandığı bir gerçek dünya senaryosu sunuyoruz.
Müşterilerine isteğe bağlı şarkı dinleme fırsatı sunan müzik yayın şirketi XYZ'yi ele alalım. XYZ, son zamanlarda aynı platform üzerinden isteğe bağlı podcast'ler de sunmaya başladı.
ML ekibi, kullanıcılara sunulan kişiselleştirilmiş öneriler kataloğuna podcast'ler eklemekle ilgileniyor. Bunu yapmak için, veri ağı paradigmasında bir tüketici olarak görülebilen öneri sistemi üzerinde çalışan makine öğrenimi ekibinin birden çok veri alanına (üreticilere) erişmesi gerekir: Kullanıcılar, şarkılar, Podcast, ve Etkileşimler.
Bu gönderide, kişiselleştirilmiş öneriler için tam olarak yönetilen bir makine öğrenimi hizmeti olarak Amazon Kişiselleştirmeyi kullanıyoruz. Geliştiricilerin yüksek düzeyde özelleştirilmiş deneyimler sunmak için özel makine öğrenimi modellerini eğitmesine, ayarlamasına ve dağıtmasına olanak tanır. Amazon Personalize, altyapıyı sağlar ve verilerin işlenmesi de dahil olmak üzere tüm ML ardışık düzenini yönetir; tanımlayıcı özellikler; ve modelleri eğitmek, optimize etmek ve barındırmak. Amazon Kişiselleştirme hakkında daha fazla bilgiyi şurada bulabilirsiniz: Geliştirici Kılavuzu.
Şimdi hem durağan veriler hem de hareket halindeki veriler senaryosu için çözümün uygulanmasına daha derinden dalıyoruz. Makine öğrenimi, bir veri kümesi oluşturmak ve modelleri eğitmek için bekleyen büyük miktarda veriye ihtiyaç duyar. Ek olarak, kişiselleştirme senaryosu, kullanıcıların mevcut amacına uyum sağlamak için gerçek zamanlı verilere erişim gerektirir, bu nedenle gerçek zamanlı olaylara ve etkileşimlere erişmemiz gerekir. Bu senaryo için bir veri ağı çözümü her ikisini de gerektirir:
- Beklemedeki veriler – Kullanıcıdan, öğelerden ve etkileşimlerden geçmiş veriler. Bunların bir kısmı ayrı sistemlerde ve veri kaynaklarında saklanabilir.
- Hareket halindeki veriler – Bu veriler, örneğin dinlenen şarkılar veya katalogda kullanıma sunulan yeni öğeler gibi gerçek zamanlı etkinlikler içindir.
Duran veriler için mimari
Bu bölümde, çözümün geri kalan kısmındaki verilere odaklanıyoruz.
Aşağıdaki şema, kişiselleştirilmiş öneriler bağlamında veri ağı mimarisini nasıl uygulayabileceğimizi ve podcast'leri Amazon Personalize ile dağıtılan öneri sistemine nasıl ekleyebileceğimizi gösterir. Her üretici etki alanı verilere sahiptir ve bunları veri katalogları aracılığıyla sunar. Tüketiciler, uygulamaları için ihtiyaç duydukları verileri bulmak için veri kataloglarını kullanır.

İlk olarak, daha önce tanıtılan ağ mimarisinin üç ana bileşenini tanımlayabiliriz: veri üreticileri, merkezi veri kataloğu ve veri tüketicileri.
Bu özel örnekte, farklı üretici etki alanlarının farklı depolama çözümlerini nasıl uyguladığını görebiliriz:
- The Kullanıcılar alan kullanımları Amazon Aurora'sı kendi iş kolu (LOB) veritabanı olarak, ilişkisel bir veritabanı (adım 1a)
- şarkılar ve Podcast kullanım Amazon DinamoDB, bir NoSQL veritabanı (adım 1b ve 1c)
- Etkileşimler olayları doğrudan Amazon S3'e alır (adım 1d)
Üretici etki alanları, LOB veritabanlarını kullanarak veri kataloglarından ayrıştırıyor. Amazon Basit Depolama Hizmeti (Amazon S3). Veri ağı paradigması ile her üretici, verileri bir ürün olarak kabul eder, bu nedenle verileri açığa çıkarmadan önce ön işleyebilir ve sonuçları tüketicilere uygun bir formatta saklayabilir. Bu ayrıştırma kullanılarak uygulanır AWS Tutkal sonuçları sonunda S3 kovalarında depolanan bir ayıklama, dönüştürme ve yükleme (ETL) işlem hattı tanımlamak için (2a, 2b, 2c adımları).
Son olarak, her üretici kendi AWS Glue Veri Kataloğunu Merkezi Veri Kataloğu (adım 3a, 3b, 3c, 3d).
Veri tüketicileri artık merkezi katalog aracılığıyla farklı veri alanlarına erişebilir. Önceki şekilde gösterildiği gibi, iki tüketicimiz var: analitik belirli kataloglara erişen ve bir Amazon QuickSight kontrol paneli (4. adım) ve Kişiselleştirilmiş Öneriler etki alanı (adım 5).
Bu gönderi için ilgi çekici olan ikincisi, merkezi katalog aracılığıyla farklı üreticilerin verilerine erişen bir AWS Glue ETL işinden oluşur. ETL işi, örneğin şarkı ve podcast verilerini birleştirme gibi geleneksel veri mühendisliği görevlerini gerçekleştirir. Artık ürün veri setimizin hem şarkılar hem de podcast'ler hakkında bilgiler içerdiği ve ilk öneri kataloğunu genişleten Amazon Kişiselleştirme çözümümüzü oluşturabiliriz.
Öneri motorumuz, daha sonra, aşağıdakiler kullanılarak dağıtılan bir API aracılığıyla çıkarım istekleri için kullanılabilir hale getirilir: Amazon API Ağ Geçidi (adım 6).
Mimari, birden çok hesapta çalışmak üzere tasarlanmıştır: bir AWS hesabı, kendisine dağıtılan kaynaklar ve tek bir faturalandırma birimi için doğal bir sınırdır. Bu yaklaşım, farklı alanların sahip olduğu kaynakları ayırmamıza ve operasyonel çevikliği korumamıza olanak tanır: her ekip kendi hesabına sahiptir ve kontrol eder. Bir veri ağıyla çalışırken veri kataloglarını farklı hesaplar arasında paylaşma yaklaşımları hakkında daha fazla bilgi edinmek için AWS Lake Formation ve AWS Glue kullanarak bir veri ağı mimarisi tasarlayın.
Artık kullanıcılara iki kategorideki kapsamlı dinleme tercihlerine göre şarkı veya podcast önerileri sunabiliyoruz. Bir sonraki bölümde, kataloğa eklenen yeni şarkılar veya kullanıma sunulan yeni etkileşimler gibi sürekli gelişen verilere tepki verecek şekilde mimarinin nasıl geliştirileceğini keşfedeceğiz.
Hareket halindeki veriler için mimari
Daha önce, hareket halindeki veri düzlemi olarak tanımlanan veri ağı bağlamında olay akışı için teorik çerçeveyi tanıtmıştık. Artık özel kullanım durumumuz için mimariyi derinlemesine inceleyebiliriz.
Dört yapımcı ile bir senaryo kullanıyoruz (Kullanıcılar, şarkılar, Podcast, ve Etkileşimler), merkezi akış bileşeni ve iki tüketici alanı (Kişiselleştirilmiş Öneriler ve analitik). Hareket halindeki veri düzlemi, olay akışı için bir platform, yani Apache Kafka kullanılarak uygulanır ve her üreticinin olaylarını yayınlamak için özel bir akışı vardır.
Müzik için gerçek zamanlı öneriler senaryosunda, Kişiselleştirilmiş Öneriler değişiklikler hakkında tüketiciye bilgi verilir. Kullanıcılar, şarkılar, Podcast, ve Etkileşimler. Durağan örneğe benzer şekilde, adı verilen ikinci bir tüketici alanını da düşünüyoruz. analitik, etkileşimlerdeki trendler hakkında gerçek zamanlı panolar oluşturmak için kullanılır. Burada, analitik tüketicisi yalnızca etkileşim olaylarına ihtiyaç duyar, bu nedenle yalnızca aşağıdakilere abone olur: Etkileşims akışı.
Bu mimari, üreticiler ve tüketiciler için gevşek bağlantılı bir etkileşim mekanizması sunmak üzere tasarlanmıştır: üreticilerin sistemin parçası olan tüketiciler hakkında bilgi sahibi olmalarına gerek yoktur. Yapımcılar olayları yayınlamaya odaklanır, olaylar hareket halindeki veri düzlemine gönderilir ve teslimat akış platformu tarafından garanti edilir.
Bu mimariyi bulutta oluşturma stratejisini ayrıntılı olarak inceleyelim. Okunabilirlik amacıyla, çözümün bu bölümünü, hareketsiz veri senaryosunun diyagramına eklemeden ayrı olarak inceliyoruz.
Teknolojik açıdan, kullandığımız AWS Lambda uygulamanın arka uç iş mantığını çalıştırmak için: mikro hizmet, mantığı bir Lambda işlevinde çalıştırır ve olayları olay akışlarına yayınlar. Lambda'yı kullanıyoruz çünkü hem ölçeklenebilirlik hem de operasyonel verimlilik açısından kullanım durumumuza çok iyi uyuyor, çünkü minimum operasyonel ek yük sunuyor. Bununla birlikte, mimari desen, örneğin, üzerinde çalışan kapsayıcılar gibi diğer arka uç dağıtım türleri için de geçerlidir. Amazon Elastik Kubernetes Hizmeti (Amazon EKS) veya Amazon Elastik Konteyner Hizmeti (Amazon ECS).
Hareket halindeki veri düzlemi kullanılarak uygulanır Apache Kafka için Amazon Tarafından Yönetilen Akış (Amazon MSK), Apache Kafka'yı bulutta çalıştırmak için tam olarak yönetilen bir çözüm. Sunucuları sağlar, Apache Kafka kümelerini yapılandırır, başarısız olduklarında sunucuları değiştirir, sunucu yamalarını ve yükseltmelerini düzenler ve yüksek kullanılabilirlik için kümeleri çalıştırır. Kafka, olayları konulara göre düzenler ve saklar. Konular her zaman çok üretici ve çok tüketicidir: bu, bir veya daha fazla üreticinin aynı konuya yayın yapabileceği ve bir veya daha fazla tüketicinin konudan okumak için abone olabileceği anlamına gelir. Bu mimari paradigmayı modellemek için konu kavramını kullanıyoruz ve her üretici alanı için bir konu atadık.
Son olarak, daha önce tanıttığımız tüketici alanımızı uyarlıyoruz, Kişiselleştirilmiş Öneriler, gerçek zamanlı olayları hesaba katmak için. Bu sefer, konulardan olayları okumak için Lambda kullanıyoruz ve Amazon Personalize API'yi çağırmak için komutları çağırıyoruz. Amazon Kişiselleştirme SDK'sı. Aynı tüketici alanı içinde, izlenen konuda yeni bir olay yayınlanır yayınlanmaz tetiklenen konu başına bir Lambda işlevi kullanıyoruz. Bu olaya dayalı model, yalnızca yeni bir etkinlik yayınlandığında ve Amazon Personalize'daki bilgileri güncellememiz gerektiğinde kod çalıştırmamıza olanak tanır. içindeki her Lambda işlevi Kişiselleştirilmiş Öneriler etki alanı, Amazon Personalize'da karşılık gelen eylemleri başlatmak için Amazon Personalize SDK'yı kullanır ve veri kümeleri.
Aşağıdaki şekli kullanarak sistemde gerçekleşen yeni bir etkileşimi düşünelim. Olay akışı modelinin bu sunucusuz uygulaması, veri ağını gerçek zamanlı olaylara yanıt verecek şekilde genişletir.

The Etkileşimler Uygulamanın arka uç mantığını çalıştıran mikroservis, uygulamada kalıcı olan yeni bir olay (1. adım) yayınlar. Etkileşimler konu (2. adım). Yeni bir olayın yayınlanması, konuya abone olan Lambda işlevlerini tetikler, bu durumda benetkileşimlerGüncelleme ve EtkileşimlerIngestor (Aşama 3). bu EtkileşimlerGüncelleme işlevi, gerçek zamanlı olayı öneri sistemine eklemek için Amazon Kişiselleştirme SDK'sı aracılığıyla Amazon Kişiselleştirme API'sindeki PutEvents işlemini çağırır (4. adım). EtkileşimlerIngestor tarafından benimsenen stratejiye göre panoları yenileme işlemlerini tetikler. analitik alan adı. Son olarak, diğer hizmetler ve bileşenler, önerilen API aracılığıyla önerileri tüketebilir. Kişiselleştirilmiş Öneri tahminleri tüketilebilir hale getirmek için etki alanı (5. adım).
Için analitik Bu mimarinin ölçeklenebilirliğini göstermek için eklediğimiz etki alanında, gerçek zamanlı olayları içine almak için bir Lambda işlevi kullanıyoruz. Amazon Kinesis Veri İtfaiyesi. Daha sonra etkileşimleri kullanarak görselleştirebiliriz. Amazon Açık Arama Hizmeti ile birlikte Amazon QuickSight. Daha fazla ayrıntı için bkz. Amazon OpenSearch Service'e bağlı Amazon QuickSight'tan canlı analizleri görselleştirin.
Veri üreticileri, Kafka kaynakları ve veri tüketicilerinin tümü farklı hesaplarda olduğundan, hem güvenlik nedenleriyle hem de maliyet optimizasyonu nedeniyle trafiği AWS altyapısı içinde tutmak ve genel internetten kaçınmak için hesaplar arası bağlantı kurmamız gerekiyor. Bu gönderinin amacı, mimariyi ve bu kalıbı uygulama yaklaşımını göstermektir. Üreticiler ve tüketiciler ile Amazon MSK arasında hesaplar arası bağlantının nasıl kurulacağı konusunda daha derine inmek istiyorsanız, bkz. Amazon MSK'ya erişmek için güvenli bağlantı modelleri ve Goldman Sachs, AWS Private Link ile Amazon MSK kümelerine hesaplar arası bağlantıyı nasıl kurar?.
Olay akışıyla veri ağı: Hepsini bir araya getirme
Daha önce, veri ağı paradigmasını hatırladık ve bir veriyi bir ürün stratejisi olarak benimsemenin önemini vurgulamak için bir çözüm tasarladık. Her üretici etki alanı, verileri katalog aracılığıyla sunar ve bunlar, veri aracılığıyla merkezi olarak keşfedilebilir hale getirilir. Merkezi Veri Kataloğu. Her tüketici etki alanı, merkezi kataloğa bağlanmak ve etki alanının odaklandığı çözümü oluşturmak için gereken verileri bulmak için bir katalog arabirimine sahiptir.
Ardından, hareket halindeki veriler için senaryoyu inceledik, olay akış platformunu uygulamak için Apache Kafka ve Amazon MSK'yı tanıttık ve üreticiler ile tüketicileri Lambda aracılığıyla akış hizmetine bağladık. Bu olaya dayalı uygulama, üreticileri tüketicilerden ayırmamıza ve mimaride önemli değişiklikler gerektirmeden etki alanları zaman içinde değişip gelişebileceğinden çözümü ölçeklenebilir hale getirmemize olanak tanır.
Şimdi aşağıdaki şekilde gösterildiği gibi hepsini bir araya getirebiliriz. Olay akışı mimarisine sahip eksiksiz veri ağı, iki farklı veri düzlemi kullanır: biri hareketsiz (mavi) verileri paylaşmak için ayrılmıştır; diğeri ise hareket halindeki veriler içindir (kırmızı).

Her etki alanı, her iki düzlemle iletişim kurmak için gereken iki arabirime sahiptir: veri katalogları ve Lambda işlevleri. Duran veriler, veri kataloglarından yararlanılarak paylaşılır ve keşfedilirken, hareket halindeki veriler, üretici etki alanlarında arka uç mantığını çalıştıran servis tarafından yayılır. Tüketici etki alanlarında dağıtılan konulara abone olan Lambda işlevleri kullanılarak tüketilirler.
Sonuç
Bu gönderide, veri ağı kavramını gerçek zamanlı olaylara genişletmenize izin veren üst düzey mimari paradigmasını tanıttık.
Önce bu mimari tarzla ilişkili temel kavramları ele aldık ve ardından bu çözümün, gerçek zamanlı kişiselleştirilmiş öneriler ve analitikler gibi gerçek dünyadaki iş zorluklarını çözmek için AWS'de çok hesaplı bir ortamda nasıl uygulanacağını gösterdik.
Ayrıca, bu gönderide sunulan çerçeve, örneğin aşağıdakiler gibi diğer AWS AI hizmetleri gibi farklı alanlara genelleştirilebilir: Amazon Tahmini or Amazon Kavramakveya özel senaryonuz için oluşturulmuş ve aracılığıyla dağıtılan özel makine öğrenimi çözümleriniz Amazon Adaçayı Yapıcı. En fazla deneyime, en güvenilir, ölçeklenebilir ve güvenli buluta ve en kapsamlı hizmet ve çözümlere sahip olan AWS, verilerinizden değer elde etmek için en iyi yerdir.
Daha fazla kaynak:
yazarlar hakkında
 Vittorio Denti Londra merkezli AWS'de Çözüm Mimarıdır. Yüksek Lisansını tamamladıktan sonra Politecnico di Milano (Milan) ve KTH Royal Institute of Technology'de (Stockholm) Bilgisayar Bilimi ve Mühendisliği bölümünde AWS'ye katıldı. Vittorio, Dağıtılmış Sistemler ve Makine Öğrenimi konusunda bir geçmişe ve bulut teknolojilerine büyük ilgi duyuyor. Özellikle yazılım mühendisliği, makine öğrenimi modelleri oluşturma ve makine öğrenimini üretime geçirme konusunda tutkulu.
Vittorio Denti Londra merkezli AWS'de Çözüm Mimarıdır. Yüksek Lisansını tamamladıktan sonra Politecnico di Milano (Milan) ve KTH Royal Institute of Technology'de (Stockholm) Bilgisayar Bilimi ve Mühendisliği bölümünde AWS'ye katıldı. Vittorio, Dağıtılmış Sistemler ve Makine Öğrenimi konusunda bir geçmişe ve bulut teknolojilerine büyük ilgi duyuyor. Özellikle yazılım mühendisliği, makine öğrenimi modelleri oluşturma ve makine öğrenimini üretime geçirme konusunda tutkulu.
 Anna Grüebler AWS'de Yapay Zeka üzerine odaklanan Uzman Çözüm Mimarıdır. Müşterilerin makine öğrenimi uygulamaları geliştirmesine ve dağıtmasına yardımcı olan 10 yılı aşkın bir deneyime sahiptir. Tutkusu, yeni teknolojileri alıp herkesin kullanımına sunmak ve bulutta yapay zeka kullanmanın avantajlarından yararlanarak zor sorunları çözmektir.
Anna Grüebler AWS'de Yapay Zeka üzerine odaklanan Uzman Çözüm Mimarıdır. Müşterilerin makine öğrenimi uygulamaları geliştirmesine ve dağıtmasına yardımcı olan 10 yılı aşkın bir deneyime sahiptir. Tutkusu, yeni teknolojileri alıp herkesin kullanımına sunmak ve bulutta yapay zeka kullanmanın avantajlarından yararlanarak zor sorunları çözmektir.

