Derin pekiştirmeli öğrenmeye (DRL) dayalı yeni oluşturulan bir yapay zeka (AI) sistemi, simüle edilmiş bir ortamda saldırganlara tepki verebilir ve siber saldırıların %95'ini tırmanmadan önce engelleyebilir.
Bu, bir ağdaki saldırganlar ve savunucular arasındaki dijital çatışmanın soyut bir simülasyonunu oluşturan ve uzlaşmaları önleme ve ağ kesintisini en aza indirme temelinde ödülleri en üst düzeye çıkarmak için dört farklı DRL sinir ağını eğiten Energy'nin Pasifik Kuzeybatı Ulusal Laboratuvarı'ndan araştırmacılara göre.
Simüle saldırganlar, aşağıdakilere dayalı bir dizi taktik kullandı: GÖNYE ATT & CK Çerçevenin sınıflandırması, ilk erişim ve keşif aşamasından diğer saldırı aşamalarına, hedeflerine ulaşana kadar geçmek için: darbe ve sızma aşaması.
Derneğin yıllık toplantısında ekibin çalışmalarını sunan veri bilimcisi Samrat Chatterjee, yapay zeka sisteminin basitleştirilmiş saldırı ortamında başarılı bir şekilde eğitilmesinin, saldırılara gerçek zamanlı olarak verilen savunma yanıtlarının bir yapay zeka modeli tarafından ele alınabileceğini gösterdiğini söylüyor. Advance of Yapay Zeka 14 Şubat'ta Washington, DC'de.
"Bu tekniklerin vaatlerini bile gösteremiyorsanız, daha karmaşık mimarilere geçmek istemezsiniz" diyor. "Bir DRL'yi gerçekten başarılı bir şekilde eğitebileceğimizi ve ilerlemeden önce bazı iyi test sonuçları gösterebileceğimizi göstermek istedik."
Makine öğreniminin ve yapay zeka tekniklerinin siber güvenlik içindeki farklı alanlara uygulanması, makine öğreniminin e-posta güvenlik ağ geçitlerine erken entegrasyonundan bu yana son on yılda sıcak bir trend haline geldi. 2010’lerin başlarında için daha yeni çabalara kodu analiz etmek için ChatGPT'yi kullanın veya adli tıp analizi yapın. Şimdi, çoğu güvenlik ürününün sahip olduğu — veya sahip olduğunu iddia — büyük veri kümeleri üzerinde eğitilmiş makine öğrenimi algoritmaları tarafından desteklenen birkaç özellik.
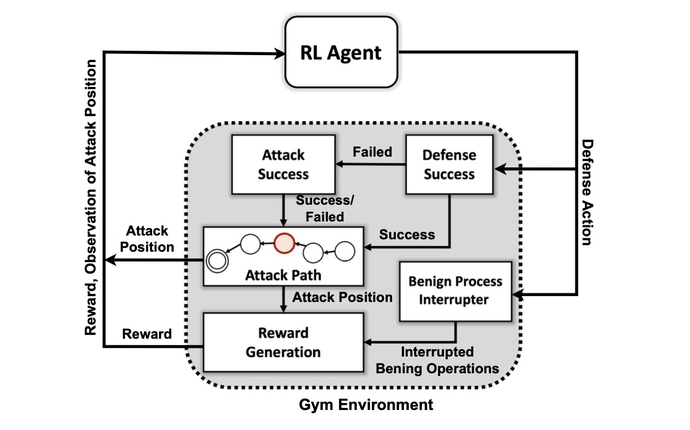
Yine de, proaktif savunma yeteneğine sahip bir AI sistemi oluşturmak, pratik olmaktan çok istek uyandırmaya devam ediyor. Araştırmacılar için çeşitli engeller devam etse de, PNNL araştırması gelecekte bir AI savunucusunun mümkün olabileceğini gösteriyor.
PNNL araştırma ekibi, "Farklı rakip ortamlar altında eğitilmiş birden fazla DRL algoritmasını değerlendirmek, pratik otonom siber savunma çözümlerine yönelik önemli bir adımdır" dedi. kağıtlarında belirtilen. "Deneylerimiz, modelden bağımsız DRL algoritmalarının, farklı beceri ve kalıcılık seviyelerine sahip çok aşamalı saldırı profilleri altında etkili bir şekilde eğitilebileceğini ve tartışmalı ortamlarda olumlu savunma sonuçları sağlayabileceğini gösteriyor."
Sistem MITRE ATT&CK'yi Nasıl Kullanır?
Araştırma ekibinin ilk hedefi, olarak bilinen açık kaynaklı bir araç setine dayalı özel bir simülasyon ortamı yaratmaktı. AI Gym'i açın. Araştırmacılar bu ortamı kullanarak, MITRE ATT&CK çerçevesinden 7 taktik ve 15 teknikten oluşan bir alt küme kullanma becerisine sahip, farklı beceri ve kalıcılık düzeylerine sahip saldırgan varlıklar oluşturdu.
Saldırgan aracıların hedefleri, ilk erişimden yürütmeye, ısrardan komuta ve kontrole ve toplamadan etkiye kadar saldırı zincirinin yedi adımında ilerlemektir.
PNNL'den Chatterjee, saldırgan için taktiklerini ortamın durumuna ve savunanın mevcut eylemlerine uyarlamanın karmaşık olabileceğini söylüyor.
"Düşman, başlangıçtaki bir keşif durumundan bir tür sızma veya darbe durumuna kadar yolunu bulmak zorunda," diyor. "Bir düşmanı çevreye girmeden önce durdurmak için bir tür model oluşturmaya çalışmıyoruz - sistemin zaten tehlikede olduğunu varsayıyoruz."
Araştırmacılar, takviyeli öğrenmeye dayalı sinir ağlarına dört yaklaşım kullandılar. Takviyeli öğrenme (RL), insan beyninin ödül sistemini taklit eden bir makine öğrenimi yaklaşımıdır. Bir sinir ağı, sistemin ne kadar iyi performans gösterdiğini gösteren bir puanla ölçüldüğü gibi, daha iyi çözümleri ödüllendirmek için bireysel nöronlar için belirli parametreleri güçlendirerek veya zayıflatarak öğrenir.
Bir PNNL araştırmacısı ve makalenin yazarı Mahantesh Halappanavar, pekiştirmeli öğrenmenin esas olarak bilgisayarın eldeki soruna iyi, ancak mükemmel olmayan bir yaklaşım oluşturmasına izin verdiğini söylüyor.
"Herhangi bir takviyeli öğrenme kullanmadan, bunu yine de yapabiliriz, ancak gerçekten iyi bir mekanizma bulmak için yeterli zamana sahip olamayacak kadar büyük bir sorun olur" diyor. "Araştırmamız... bize, derin pekiştirmeli öğrenmenin insan davranışının bir kısmını bir dereceye kadar taklit ettiği bu mekanizmayı veriyor ve bu çok geniş alanı çok verimli bir şekilde keşfedebiliyor."
Prime Time için Hazır Değil
Deneyler, Derin Q Ağı olarak bilinen belirli bir pekiştirmeli öğrenme yönteminin savunma sorununa güçlü bir çözüm yarattığını buldu. Saldırganların %97'sini yakalamak test veri setinde. Yine de araştırma sadece başlangıç. Güvenlik uzmanları, yakın zamanda olay müdahalesi ve adli tıp yapmalarına yardımcı olacak bir yapay zeka yardımcısı aramamalıdır.
Çözülmesi gereken pek çok sorun arasında, kararlarını etkileyen faktörleri açıklamak için takviyeli öğrenme ve derin sinir ağları, açıklanabilir takviyeli öğrenme (XRL) adı verilen bir araştırma alanı var.
Ek olarak, PNNL'den Chatterjee, AI algoritmalarının sağlamlığının ve sinir ağlarını eğitmenin verimli yollarını bulmanın çözülmesi gereken sorunlar olduğunu söylüyor.
"Bir ürün yaratmak - bu araştırma için ana motivasyon bu değildi" diyor. "Bu daha çok bilimsel deneyler ve algoritmik keşiflerle ilgiliydi."
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.darkreading.com/emerging-tech/researchers-create-ai-cyber-defender-that-reacts-to-attackers

