Giriş
Tek Sınıf Destek Vektör Makinesi (SVM), geleneksel SVM'nin bir çeşididir. Anormallikleri tespit etmek için özel olarak tasarlanmıştır. Temel amacı standarttan belirgin biçimde sapan örnekleri tespit etmektir. Gelenekselden farklı olarak Makine öğrenme İkili veya çok sınıflı sınıflandırmaya odaklanan modeller için tek sınıflı SVM, veri kümeleri içindeki aykırı değer veya yenilik tespitinde uzmanlaşmıştır. Bu makalede Tek Sınıf Destek Vektör Makinesinin (SVM) geleneksel SVM'den nasıl farklı olduğunu öğreneceksiniz. Ayrıca OC-SVM'nin nasıl çalıştığını ve nasıl uygulanacağını da öğreneceksiniz. Ayrıca hiperparametrelerini de öğreneceksiniz.
Öğrenme hedefleri
- Anomalileri Anlamak
- Tek sınıf SVM hakkında bilgi edinin
- Geleneksel Destek Vektör Makinesinden (SVM) nasıl farklı olduğunu anlayın
- Sklearn'de OC-SVM'nin hiperparametreleri
- OC-SVM kullanılarak Anomaliler nasıl tespit edilir
- Tek Sınıf SVM'nin kullanım örnekleri
İçindekiler
Anomalileri Anlamak
Anormallikler, bir veri kümesinin normal davranışından önemli ölçüde sapan gözlemler veya örneklerdir. Bu sapmalar aykırı değerler, gürültü, hatalar veya beklenmedik modeller gibi çeşitli biçimlerde ortaya çıkabilir. Anomaliler genellikle büyüleyicidir çünkü değerli içgörüleri temsil edebilirler. Sahte işlemlerin belirlenmesi, ekipman arızalarının tespit edilmesi veya yeni olayların ortaya çıkarılması gibi bilgiler sağlayabilirler. Aykırı değer ve yenilik tespiti, anormallikleri ve anormal veya olağandışı gözlemleri tanımlar.
Ayrıca Oku: Anormallik Tespiti Konusunda Uçtan Uca Kılavuz
Tek Sınıf SVM
Destek Vektör Makinelerine (SVM'ler) Giriş
Destek Vektör Makineleri (SVM'ler) popüler denetimli öğrenme algoritması sınıflandırma ve regresyon görevleri için. SVM'ler, özellik uzayında farklı sınıfları ayıran ve aralarındaki marjı maksimuma çıkaran en uygun hiperdüzlemi bularak çalışır. Bu hiperdüzlem, destek vektörleri adı verilen eğitim veri noktalarının bir alt kümesine dayanmaktadır.
Tek Sınıf SVM ve Geleneksel SVM
- Tek sınıflı SVM'ler, öncelikle aykırı değer ve yenilik tespit görevleri için kullanılan geleneksel SVM algoritmasının bir varyantını temsil eder. İkili sınıflandırma görevlerini yerine getiren geleneksel SVM'lerin aksine, Tek Sınıf SVM yalnızca hedef sınıf olarak bilinen tek bir sınıftan gelen veri noktaları üzerinde eğitim verir. Tek sınıflı SVM, hedef sınıfı özellik uzayında kapsülleyen ve verilerin normal davranışını etkili bir şekilde modelleyen bir sınır veya karar fonksiyonunu öğrenmeyi amaçlar.
- Geleneksel SVM'ler, farklı sınıflar arasındaki marjı maksimuma çıkaran ve yeni veri noktalarının en iyi şekilde sınıflandırılmasına olanak tanıyan bir karar sınırı bulmayı amaçlar. Öte yandan, Tek Sınıf SVM, bu sınırın dışındaki aykırı değerleri veya yeni örnekleri dahil etme riskini en aza indirirken hedef sınıfı kapsayan bir sınır bulmaya çalışır.
- Geleneksel SVM'ler, birden fazla sınıftan örnekler içeren etiketlenmiş verilere ihtiyaç duyar ve bu da onları denetimli sınıflandırma görevlerine uygun hale getirir. Buna karşılık, Tek Sınıf SVM, yalnızca hedef sınıftan gelen verilerin mevcut olduğu senaryolarda uygulamaya izin verir ve bu da onu denetimsiz anormallik tespiti ve yenilik tespiti görevleri için çok uygun hale getirir.
Daha Fazla Bilgi: Destek Vektör Makinelerini Kullanarak Tek Sınıf Sınıflandırma
Her ikisi de yumuşak marj formülasyonları ve bunları kullanma şekilleri bakımından farklılık gösterir:
(SVM'deki yumuşak kenar boşluğu, bir dereceye kadar yanlış sınıflandırmaya izin vermek için kullanılır)
Tek sınıflı SVM, eşlenen verileri orijinden ayırarak özellik alanı içinde maksimum kenar boşluğuna sahip bir hiperdüzlem keşfetmeyi amaçlamaktadır. Bir veri kümesinde Dn = {x1, . . . xi ∈ X (xi bir özelliktir) ve n boyutlu , xn}:
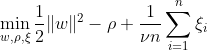
Bu denklem OC-SVM için temel problem formülasyonunu temsil eder; burada w, ayırıcı hiperdüzlemdir, ρ, orijinden uzaklıktır ve ξi, gevşek değişkenlerdir. Yumuşak bir marja izin verirler ancak ξi ihlallerini cezalandırırlar. Bir hiperparametre ν ∈ (0, 1], gevşek değişkenin etkisini kontrol eder ve ihtiyaca göre ayarlanmalıdır. Amaç, marjdan sapmaları cezalandırırken w normunu en aza indirmektir. Ayrıca, bu, verilerin bir kısmının kenar boşluğuna veya hiperdüzlemin yanlış tarafına düşer.
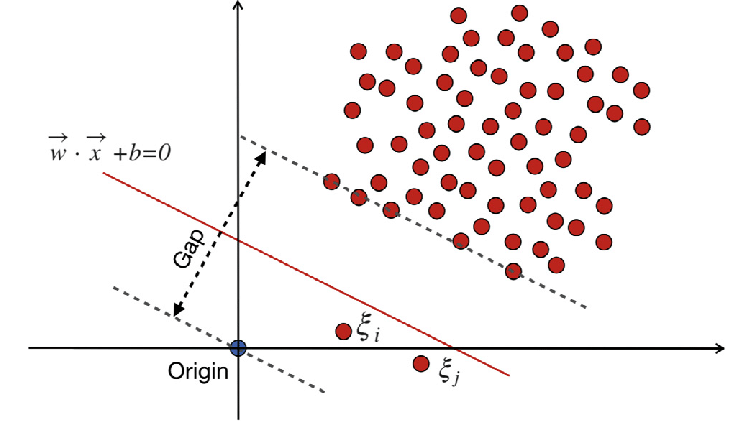
WX + b =0 karar sınırıdır ve gevşek değişkenler sapmaları cezalandırır.
Geleneksel Destekli Vektör Makineleri (SVM)
Geleneksel Destek Vektör Makineleri (SVM), yanlış sınıflandırma hataları için yumuşak kenar boşluğu formülasyonunu kullanır. Veya kenar boşluğuna giren veya karar sınırının yanlış tarafında bulunan veri noktalarını kullanırlar.
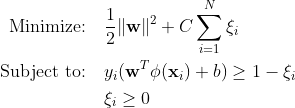
Nerede:
w ağırlık vektörüdür.
b önyargı terimidir.
ξi yumuşak marj optimizasyonuna izin veren gevşek değişkenlerdir.
C, marjı maksimuma çıkarmak ve sınıflandırma hatasını minimuma indirmek arasındaki dengeyi kontrol eden düzenleme parametresidir.
ϕ(xi) özellik eşleme fonksiyonunu temsil eder.
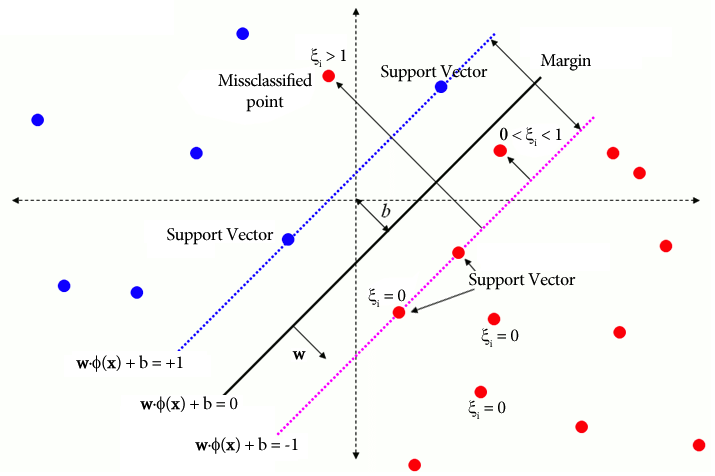
Geleneksel SVM'de, ayırma için sınıf etiketlerine dayanan denetimli bir öğrenme yöntemi, belirli bir düzeyde yanlış sınıflandırmaya izin vermek için gevşek değişkenleri içerir. SVM'nin birincil amacı, WX + b = 0 karar sınırını kullanarak farklı sınıfların veri noktalarını ayırmaktır. Gevşek değişkenlerin değeri, veri noktalarının konumuna bağlı olarak değişir: veri noktaları kenarların ötesinde bulunuyorsa 0'a ayarlanırlar. Veri noktası marjın içinde bulunuyorsa gevşek değişkenler 0 ile 1 arasında değişir ve 1'den büyükse karşı marjın ötesine uzanır.
Hem geleneksel SVM'ler hem de yumuşak marj formülasyonlu Tek Sınıf SVM'ler, ağırlık vektörünün normunu en aza indirmeyi amaçlamaktadır. Yine de hedefleri ve yanlış sınıflandırma hatalarını veya karar sınırından sapmaları nasıl ele aldıkları bakımından farklılık gösterirler. Geleneksel SVM'ler aşırı uyumu önlemek için sınıflandırma doğruluğunu optimize ederken Tek Sınıf SVM'ler hedef sınıfı modellemeye ve aykırı değerlerin veya yeni örneklerin oranını kontrol etmeye odaklanır.
Ayrıca Oku: A'dan Z'ye Vektör Makinesini Destekleme Kılavuzu
Tek Sınıf SVM'de Önemli Hiperparametreler
- hayır: Bu, Tek Sınıf SVM'de izin verilen aykırı değerlerin oranını kontrol eden çok önemli bir hiperparametredir. Eğitim hatalarının oranı için bir üst sınır ve destek vektörlerinin oranı için bir alt sınır belirler. Tipik olarak 0 ile 1 arasında değişir; burada daha düşük değerler daha sıkı bir marj anlamına gelir ve daha az aykırı değer yakalayabilir, daha yüksek değerler ise daha hoşgörülüdür. Varsayılan değer 0.5'tir.
- çekirdek: Çekirdek işlevi, SVM'nin kullandığı karar sınırının türünü belirler. Yaygın seçenekler arasında 'doğrusal', 'rbf' (Gauss radyal tabanlı fonksiyon), 'poli' (polinom) ve 'sigmoid' yer alır. 'Rbf' çekirdeği, karmaşık doğrusal olmayan ilişkileri etkili bir şekilde yakalayabildiği için sıklıkla kullanılır.
- gama: Bu, doğrusal olmayan hiperdüzlemler için bir parametredir. Tek bir eğitim örneğinin ne kadar etkiye sahip olduğunu tanımlar. Gama değeri ne kadar büyük olursa, diğer örneklerin de o kadar yakın etkilenmesi gerekir. Bu parametre RBF çekirdeğine özeldir ve genellikle varsayılan olarak 1 / n_features olan 'auto'ya ayarlanır.
- çekirdek parametreleri (derece, katsayı0): Bu parametreler polinom ve sigmoid çekirdekler içindir. 'derece' polinom çekirdek fonksiyonunun derecesidir ve 'kats0' çekirdek fonksiyonundaki bağımsız terimdir. En iyi performansı elde etmek için bu parametrelerin ayarlanması gerekli olabilir.
- Tol: Bu durdurma kriteridir. Algoritma, dualite boşluğu toleranstan küçük olduğunda durur. Durdurma kriterinin toleransını kontrol eden bir parametredir.
Tek Sınıf SVM'nin Çalışma Prensibi
Tek Sınıf SVM'de Çekirdek İşlevleri
Çekirdek işlevleri, algoritmanın dönüşümleri açıkça hesaplamadan daha yüksek boyutlu özellik alanlarında çalışmasına izin vererek Tek Sınıf SVM'de çok önemli bir rol oynar. Tek Sınıf SVM'de, geleneksel SVM'lerde olduğu gibi, giriş alanındaki veri noktası çiftleri arasındaki benzerliği ölçmek için çekirdek işlevleri kullanılır. Tek Sınıf SVM'de kullanılan yaygın çekirdek işlevleri arasında Gaussian (RBF), polinom ve sigmoid çekirdekler bulunur. Bu çekirdekler, orijinal girdi uzayını, veri noktalarının doğrusal olarak ayrılabilir hale geldiği veya daha farklı modeller sergileyerek öğrenmeyi kolaylaştırdığı daha yüksek boyutlu bir uzaya eşler. Tek Sınıf SVM, uygun bir çekirdek işlevi seçip parametrelerini ayarlayarak verilerdeki karmaşık ilişkileri ve doğrusal olmayan yapıları etkili bir şekilde yakalayabilir, anormallikleri veya aykırı değerleri tespit etme yeteneğini geliştirebilir.
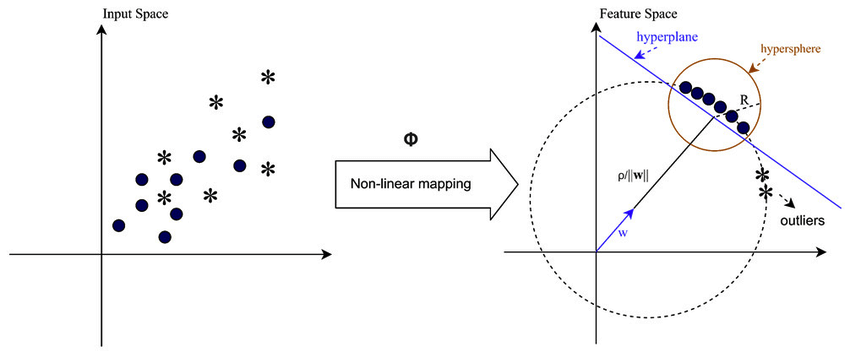
Verilerin doğrusal olarak ayrılamadığı durumlarda, örneğin karmaşık veya örtüşen modellerle uğraşırken, Destek Vektör Makineleri (SVM'ler), aykırı değerleri verilerin geri kalanından etkili bir şekilde ayırmak için bir Radyal Temel Fonksiyon (RBF) çekirdeği kullanabilir. RBF çekirdeği, giriş verilerini daha iyi ayrılabilen daha yüksek boyutlu bir özellik alanına dönüştürür.
Marj ve Destek Vektörleri
Tek Sınıf SVM'deki marj ve destek vektörleri kavramı, geleneksel SVM'lerdekine benzer. Kenar boşluğu, karar sınırı (hiperdüzlem) ile her sınıftan en yakın veri noktaları arasındaki bölgeyi ifade eder. Tek Sınıf SVM'de kenar boşluğu, hedef sınıfa ait veri noktalarının çoğunun bulunduğu bölgeyi temsil eder. Marjın maksimuma çıkarılması, Yeni veri noktalarının iyi bir şekilde genelleştirilmesine yardımcı olduğundan ve modelin sağlamlığını arttırdığından Tek Sınıf SVM için çok önemlidir. Destek vektörleri, marjın üzerinde veya içinde yer alan ve karar sınırının tanımlanmasına katkıda bulunan veri noktalarıdır.
Tek Sınıf SVM'de destek vektörleri, karar sınırına en yakın hedef sınıftan gelen veri noktalarıdır. Bu destek vektörleri, karar sınırının şeklinin ve yönünün belirlenmesinde ve dolayısıyla Tek Sınıf SVM modelinin genel performansında önemli bir rol oynar. Tek Sınıf SVM, destek vektörlerini tanımlayarak hedef sınıfın özellik alanındaki temsilini etkili bir şekilde öğrenir ve aykırı değerlerin veya yeni örneklerin dahil edilmesi riskini en aza indirirken veri noktalarının çoğunu kapsayan bir karar sınırı oluşturur.
Tek Sınıf SVM Kullanılarak Anormallikler Nasıl Tespit Edilebilir?
Hem yenilik tespiti hem de aykırı değer tespit teknikleri yoluyla Tek Sınıf SVM (Destek Vektör Makinesi) kullanılarak anormalliklerin tespiti:
Aykırı Değer Algılama
Eğitim verilerinde diğerlerinden önemli ölçüde sapan, genellikle aykırı değerler olarak adlandırılan gözlemlerin tanımlanmasını içerir. Tahminciler aykırı değer tespiti Bu sapkın gözlemleri göz ardı ederek, eğitim verilerinin en yoğun olduğu alanlara uymayı hedefleyin.
from sklearn.svm import OneClassSVM
from sklearn.datasets import load_wine
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
from sklearn.inspection import DecisionBoundaryDisplay
# Load data
X = load_wine()["data"][:, [6, 9]] # "banana"-shaped
# Define estimators (One-Class SVM)
estimators_hard_margin = {
"Hard Margin OCSVM": OneClassSVM(nu=0.01, gamma=0.35), # Very small nu for hard margin
}
estimators_soft_margin = {
"Soft Margin OCSVM": OneClassSVM(nu=0.25, gamma=0.35), # Nu between 0 and 1 for soft margin
}
# Plotting setup
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
colors = ["tab:blue", "tab:orange", "tab:red"]
legend_lines = []
# Hard Margin OCSVM
ax = axs[0]
for color, (name, estimator) in zip(colors, estimators_hard_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Hard Margin Outlier detection (wine recognition)",
)
# Soft Margin OCSVM
ax = axs[1]
legend_lines = []
for color, (name, estimator) in zip(colors, estimators_soft_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Soft Margin Outlier detection (wine recognition)",
)
plt.tight_layout()
plt.show()
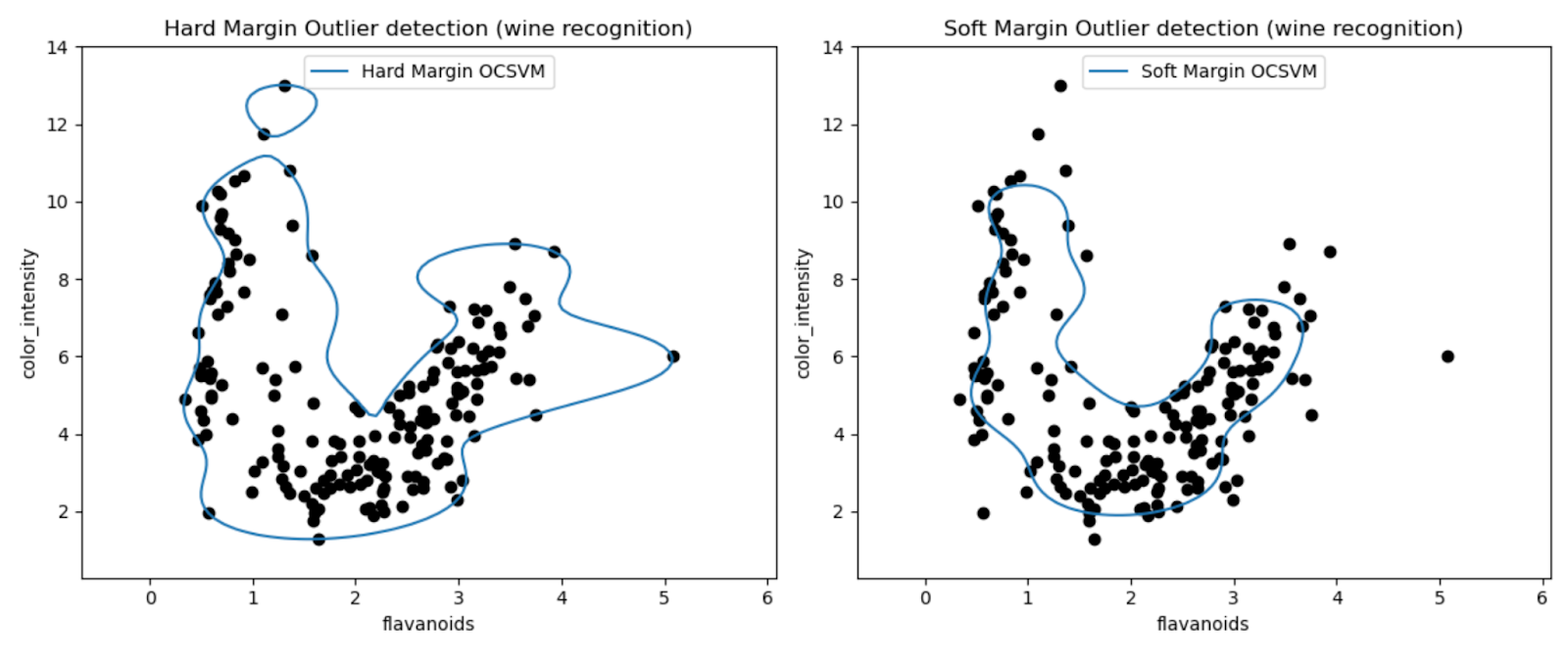
Grafikler, One-Class SVM modellerinin Wine veri kümesindeki aykırı değerleri tespit etme performansını görsel olarak incelememize olanak tanır.
Sert marjlı ve yumuşak marjlı Tek Sınıf SVM modellerinin sonuçlarını karşılaştırarak, marj ayarı seçiminin (nu parametresi) aykırı değer tespitini nasıl etkilediğini gözlemleyebiliriz.
Çok küçük bir nu değerine (0.01) sahip kesin marj modeli muhtemelen daha ihtiyatlı bir karar sınırıyla sonuçlanır. Veri noktalarının çoğunu sıkı bir şekilde sarar ve potansiyel olarak daha az sayıda noktayı aykırı değer olarak sınıflandırır.
Tersine, daha büyük bir nu değerine (0.35) sahip yumuşak marj modeli muhtemelen daha esnek bir karar sınırıyla sonuçlanır. Böylece daha geniş bir marja izin verilir ve potansiyel olarak daha fazla aykırı değer yakalanır.
Yenilik Tespiti
Öte yandan, eğitim verileri aykırı değerlerden arınmış olduğunda bunu uygularız ve amaç, yeni bir gözlemin nadir olup olmadığını, yani bilinen gözlemlerden çok farklı olup olmadığını belirlemektir. Buradaki son gözleme yenilik denir.
import numpy as np
from sklearn import svm
# Generate train data
np.random.seed(30)
X = 0.3 * np.random.randn(100, 2)
X_train = np.r_[X + 2, X - 2]
# Generate some regular novel observations
X = 0.3 * np.random.randn(20, 2)
X_test = np.r_[X + 2, X - 2]
# Generate some abnormal novel observations
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
# fit the model
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
n_error_outliers = y_pred_outliers[y_pred_outliers == 1].size
import matplotlib.font_manager
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
_, ax = plt.subplots()
# generate grid for the boundary display
xx, yy = np.meshgrid(np.linspace(-5, 5, 10), np.linspace(-5, 5, 10))
X = np.concatenate([xx.reshape(-1, 1), yy.reshape(-1, 1)], axis=1)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
cmap="PuBu",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
levels=[0, 10000],
colors="palevioletred",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contour",
ax=ax,
levels=[0],
colors="darkred",
linewidths=2,
)
s = 40
b1 = ax.scatter(X_train[:, 0], X_train[:, 1], c="white", s=s, edgecolors="k")
b2 = ax.scatter(X_test[:, 0], X_test[:, 1], c="blueviolet", s=s, edgecolors="k")
c = ax.scatter(X_outliers[:, 0], X_outliers[:, 1], c="gold", s=s, edgecolors="k")
plt.legend(
[mlines.Line2D([], [], color="darkred"), b1, b2, c],
[
"learned frontier",
"training observations",
"new regular observations",
"new abnormal observations",
],
loc="upper left",
prop=matplotlib.font_manager.FontProperties(size=11),
)
ax.set(
xlabel=(
f"error train: {n_error_train}/200 ; errors novel regular: {n_error_test}/40 ;"
f" errors novel abnormal: {n_error_outliers}/40"
),
title="Novelty Detection",
xlim=(-5, 5),
ylim=(-5, 5),
)
plt.show()

- İki veri noktası kümesiyle sentetik bir veri kümesi oluşturun. Bunu, bunları iki farklı merkez etrafında normal bir dağılımla oluşturarak yapın: eğitim ve test verileri için (2, 2) ve (-2, -2). Her iki boyut boyunca -4'ten 4'e kadar değişen bir kare bölge içinde eşit şekilde yirmi veri noktasını rastgele oluşturun. Bu veri noktaları, eğitim ve test verilerinde gözlemlenen normal davranıştan önemli ölçüde sapan anormal gözlemleri veya aykırı değerleri temsil eder.
- Öğrenilen sınır, Tek sınıf SVM modeli tarafından öğrenilen karar sınırını ifade eder. Bu sınır, modelin veri noktalarını normal olarak kabul ettiği özellik alanı bölgelerini aykırı değerlerden ayırır.
- Konturlardaki Maviden beyaza renk gradyanı, Tek Sınıf SVM modelinin özellik alanındaki farklı bölgelere atadığı değişen güven veya kesinlik derecelerini temsil eder; daha koyu gölgeler, veri noktalarının 'normal' olarak sınıflandırılmasında daha yüksek güveni belirtir. Koyu Mavi, modelin karar fonksiyonuna göre güçlü bir 'normal' göstergeye sahip bölgeleri belirtir. Konturdaki renk açıldıkça model, veri noktalarını 'normal' olarak sınıflandırma konusunda daha az emin olur.
- Grafik, Tek Sınıf SVM modelinin düzenli ve anormal gözlemler arasında nasıl ayrım yapabileceğini görsel olarak temsil eder. Öğrenilen karar sınırı normal ve anormal gözlem bölgelerini ayırır. Yenilik tespiti için tek sınıf SVM, belirli bir veri kümesindeki anormal gözlemleri tanımlamadaki etkinliğini kanıtlar.
nu=0.5 için:
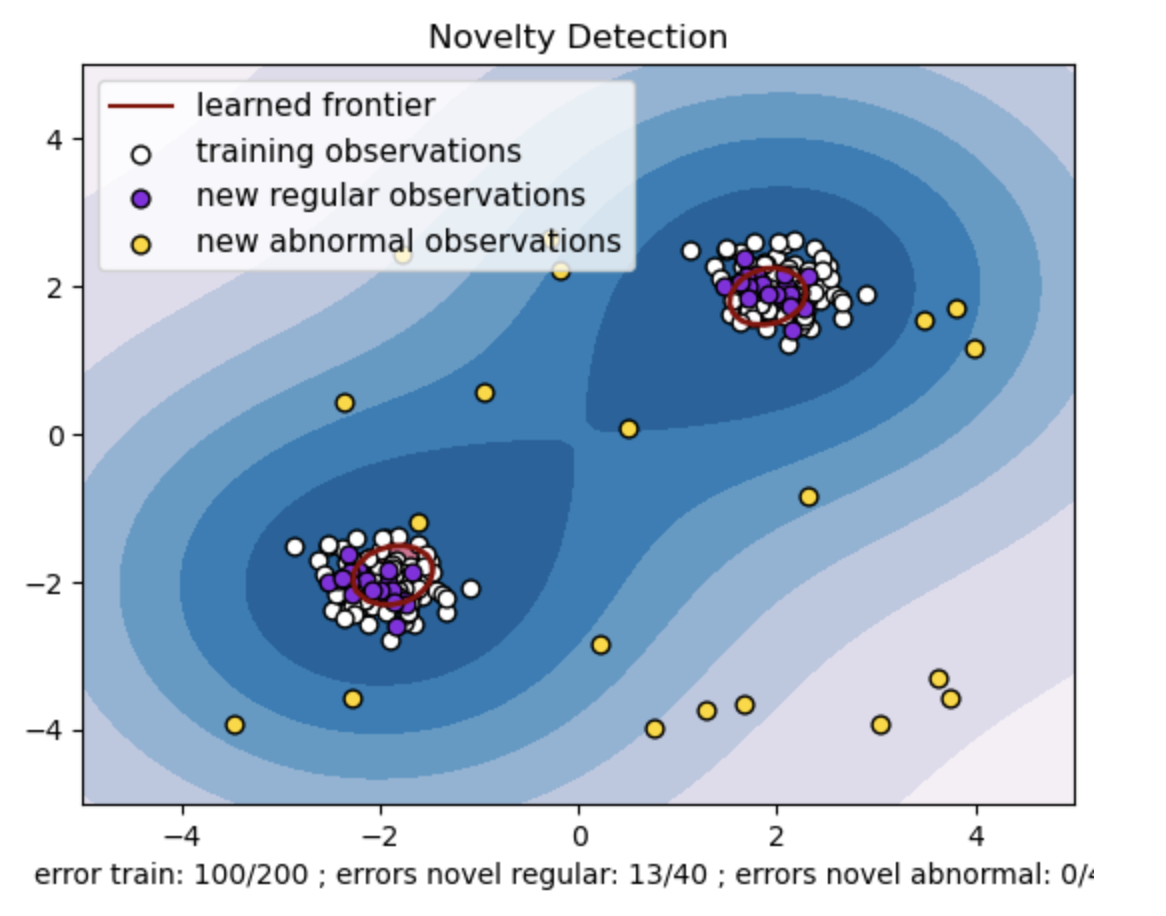
Tek sınıf SVM'deki "nu" değeri, modelin tolere ettiği aykırı değerlerin oranını kontrol etmede çok önemli bir rol oynar. Modelin anormallikleri belirleme yeteneğini doğrudan etkiler ve dolayısıyla tahmini etkiler. Modelin 100 eğitim noktasının yanlış sınıflandırılmasına izin verdiğini görüyoruz. Daha düşük bir nu değeri, aykırı değerlerin izin verilen kısmı üzerinde daha katı bir kısıtlama anlamına gelir. Nu seçimi, modelin anormallikleri tespit etme performansını etkiler. Ayrıca uygulamanın özel gereksinimlerine ve veri kümesinin özelliklerine göre dikkatli ayarlama yapılması gerekir.
Gama=0.5 ve nu=0.5 için
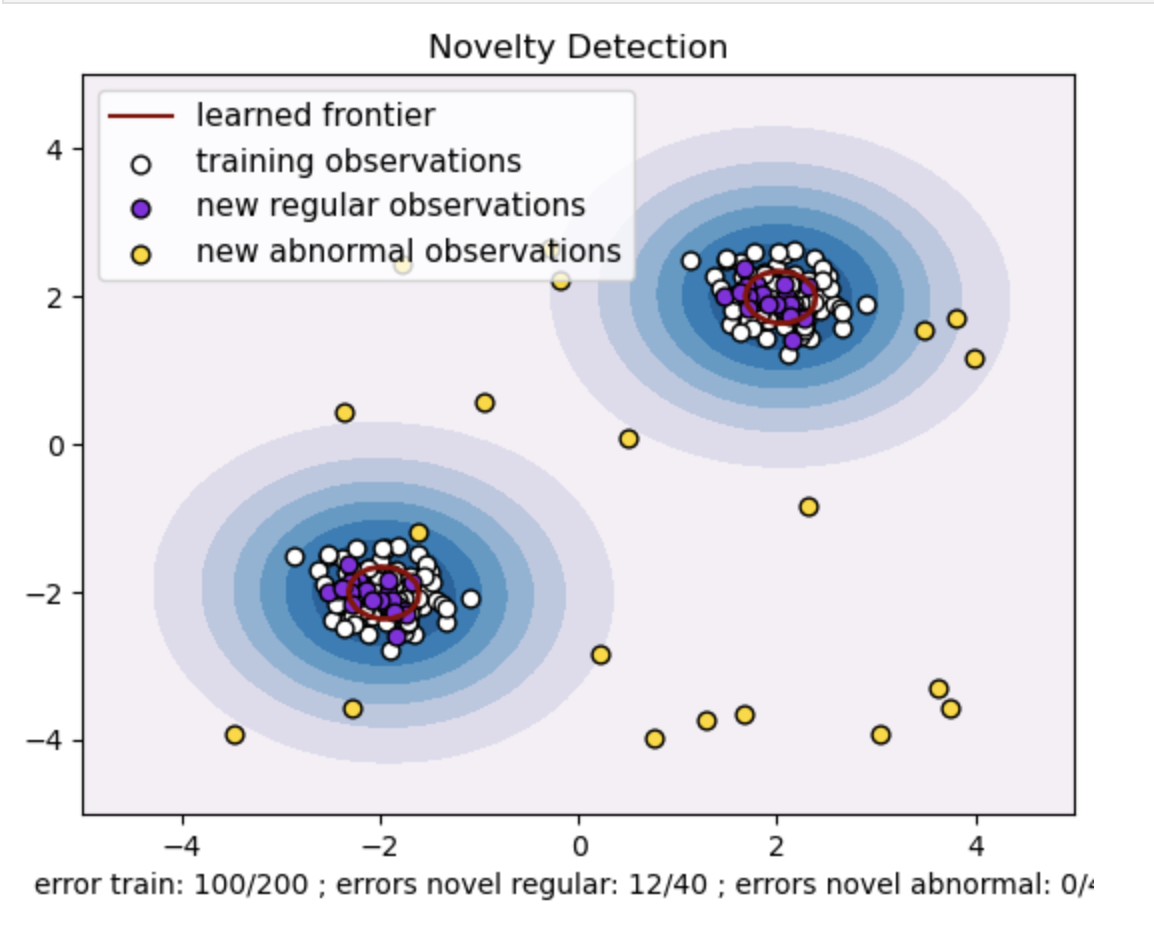
Tek sınıf SVM'de gama hiperparametresi 'rbf' çekirdeğinin çekirdek katsayısını temsil eder. Bu hiperparametre karar sınırının şeklini etkiler ve sonuç olarak modelin tahmin performansını etkiler.
Gama yüksek olduğunda, tek bir eğitim örneği etkisini yakın çevresiyle sınırlar. Bu daha yerelleştirilmiş bir karar sınırı yaratır. Bu nedenle veri noktalarının aynı sınıfa ait olabilmesi için destek vektörlerine daha yakın olması gerekir.
Sonuç
Anormallik tespiti için Tek Sınıf SVM'nin kullanılması, aykırı değer ve yenilik tespitinin kullanılması, çeşitli alanlarda sağlam bir çözüm sunar. Bu, etiketli anormallik verilerinin az olduğu veya kullanılamadığı senaryolarda yardımcı olur. Bu nedenle, anormalliklerin nadir olduğu ve açıkça tanımlanmasının zor olduğu gerçek dünya uygulamalarında onu özellikle değerli kılmaktadır. Kullanım durumları, anormalliklerin sonuçlarının olduğu siber güvenlik ve hata teşhisi gibi çeşitli alanlara uzanır. Bununla birlikte, Tek Sınıf SVM çok sayıda avantaj sunsa da, daha iyi sonuçlar elde etmek için hiperparametrelerin verilere göre ayarlanması gerekir ki bu bazen sıkıcı olabilir.
Sık Sorulan Sorular
A. Tek Sınıf SVM, normal veri noktalarını kapsayan bir hiperdüzlem (veya daha yüksek boyutlarda bir hiperküre) oluşturur. Bu hiperdüzlem, normal veriler ile karar sınırı arasındaki marjı maksimuma çıkaracak şekilde konumlandırılmıştır. Veri noktaları, test veya çıkarım sırasında normal (sınır içi) veya anormallik (sınır dışı) olarak sınıflandırılır.
C. Tek sınıf SVM avantajlıdır çünkü eğitim sırasındaki anormallikler için etiketlenmiş verilere ihtiyaç duymaz. Yalnızca normal örnekleri içeren bir veri kümesinden öğrenebilir, bu da onu anormalliklerin nadir olduğu ve eğitim için etiketli örneklerin elde edilmesinin zor olduğu senaryolar için uygun hale getirir.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2024/03/one-class-svm-for-anomaly-detection/

