
Yazara göre resim
Bugünün makalesinde, veri bilimi için Python becerilerine odaklanacağım. Python'u olmayan bir veri bilimcisi, kalemi olmayan bir yazar gibidir. Veya bir daktilo. Veya bir dizüstü bilgisayar. Tamam, buna ne dersiniz: Python'u olmayan bir veri bilimcisi, mizah girişimi olmayan benim gibidir.
Python'u bilip veri bilimcisi olamazsınız. Ama tersi? Python olmadan veri biliminde başarılı olan birini tanıyorsanız bana bildirin. Son 20 yılda, yani.
Python ve mülakat becerilerini uygulamanıza yardımcı olmak için üç Python kodlama mülakat sorusu seçtim. iki kişi StrataScratchve belirli bir iş sorununu çözmek için Python kullanılmasını gerektiren soru türleridir. Üçüncü soru şurdan LeetKodu, ve Python algoritmalarında ne kadar iyi olduğunuzu test eder.

Yazara göre resim
Google'ın bu sorusuna bir göz atın.

Soruya bağlantı: https://platform.stratascratch.com/coding/10067-google-fit-user-tracking
Göreviniz, iki yaklaşımı kullanarak GPS verilerine dayalı olarak ortalama mesafeyi hesaplamaktır. Biri Dünya'nın eğriliğini dikkate alıyor, diğeri dikkate almıyor.
Soru size her iki yaklaşım için de formüller verir. Gördüğünüz gibi, bu python kodlama mülakat sorusu matematik ağırlıklı. Sadece bu düzeydeki matematiği anlamanız değil, aynı zamanda onu bir Python koduna nasıl çevireceğinizi de bilmeniz gerekir.
O kadar kolay değil, değil mi?
Yapmanız gereken ilk şey, matematiksel işlevlere erişmenizi sağlayan bir matematik Python modülü olduğunu fark etmektir. Bu modülü bu soruda çok kullanacaksınız.
Gerekli kitaplıkları ve sinüs, kosinüs, arkkosin ve radyan fonksiyonlarını içe aktararak başlayalım. Bir sonraki adım, mevcut DataFrame'i kullanıcı kimliği, oturum kimliği ve oturum günü ile birleştirmektir. Ayrıca, ayırt edebilmek için kimliklere son ekleri ekleyin.
import numpy as np
import pandas as pd
from math import cos, sin, acos, radians df = pd.merge( google_fit_location, google_fit_location, how="left", on=["user_id", "session_id", "day"], suffixes=["_1", "_2"],
)
Ardından, iki adım kimliği arasındaki farkı bulun.
df['step_var'] = df['step_id_2'] - df['step_id_1']
Bir sonraki adımda yalnızca bir adım kimliğine sahip olan tüm oturumları hariç tutabilmemiz için önceki adım gerekliydi. Soruların bize yapmamızı söylediği şey bu. İşte nasıl yapılacağı.
df = df.loc[ df[df["step_var"] > 0] .groupby(["user_id", "session_id", "day"])["step_var"] .idxmax()
]
Adımlar arasında en büyük farkın olduğu oturumlara erişmek için pandas idxmax() işlevini kullanın.
Veri setini hazırladıktan sonra sıra matematik kısmına geliyor. Bir pandas Serisi ve ardından for döngüsü oluşturun. Her sıra, yani oturum için mesafeyi hesaplamak için iterrows() yöntemini kullanın. Bu, Dünya'nın eğriliğini hesaba katan bir mesafedir ve kod, soruda verilen formülü yansıtmaktadır.
df["distance_curvature"] = pd.Series()
for i, r in df.iterrows(): df.loc[i, "distance_curvature"] = ( acos( sin(radians(r["latitude_1"])) * sin(radians(r["latitude_2"])) + cos(radians(r["latitude_1"])) * cos(radians(r["latitude_2"])) * cos(radians(r["longitude_1"] - r["longitude_2"])) ) * 6371 )
Şimdi aynı şeyi yapın ama Dünya'nın düz olduğunu göz önünde bulundurarak. Düz Dünyalı olmanın faydalı olduğu tek durum budur.
df["distance_flat"] = pd.Series()
for i, r in df.iterrows(): df.loc[i, "distance_flat"] = ( np.sqrt( (r["latitude_2"] - r["latitude_1"]) ** 2 + (r["longitude_2"] - r["longitude_1"]) ** 2 ) * 111 )
Sonucu bir DataFrame'e dönüştürün ve çıktı metriklerini hesaplamaya başlayın. İlki, Dünya'nın eğriliği ile ortalama mesafedir. Sonra eğrilik olmadan aynı hesaplama. Son ölçü, ikisi arasındaki farktır.
result = pd.DataFrame()
result["avg_distance_curvature"] = pd.Series(df["distance_curvature"].mean())
result["avg_distance_flat"] = pd.Series(df["distance_flat"].mean())
result["distance_diff"] = result["avg_distance_curvature"] - result["avg_distance_flat"]
result
Kodun tamamı ve sonucu aşağıda verilmiştir.
import numpy as np
import pandas as pd
from math import cos, sin, acos, radians df = pd.merge( google_fit_location, google_fit_location, how="left", on=["user_id", "session_id", "day"], suffixes=["_1", "_2"],
)
df["step_var"] = df["step_id_2"] - df["step_id_1"]
df = df.loc[ df[df["step_var"] > 0] .groupby(["user_id", "session_id", "day"])["step_var"] .idxmax()
] df["distance_curvature"] = pd.Series()
for i, r in df.iterrows(): df.loc[i, "distance_curvature"] = ( acos( sin(radians(r["latitude_1"])) * sin(radians(r["latitude_2"])) + cos(radians(r["latitude_1"])) * cos(radians(r["latitude_2"])) * cos(radians(r["longitude_1"] - r["longitude_2"])) ) * 6371 )
df["distance_flat"] = pd.Series()
for i, r in df.iterrows(): df.loc[i, "distance_flat"] = ( np.sqrt( (r["latitude_2"] - r["latitude_1"]) ** 2 + (r["longitude_2"] - r["longitude_1"]) ** 2 ) * 111 )
result = pd.DataFrame()
result["avg_distance_curvature"] = pd.Series(df["distance_curvature"].mean())
result["avg_distance_flat"] = pd.Series(df["distance_flat"].mean())
result["distance_diff"] = result["avg_distance_curvature"] - result["avg_distance_flat"]
result
| avg_distance_curvature | avg_distance_flat | mesafe_diff |
| 0.077 | 0.088 | -0.01 |
Yazara göre resim
Bu, StrataScratch'ten gelen çok ilginç Python kodlama mülakat sorularından biridir. Sizi gerçek hayattaki bir veri bilimcinin çok yaygın ama karmaşık bir durumuna sokar.
Delta Havayolları tarafından bir soru. Bir göz atalım.
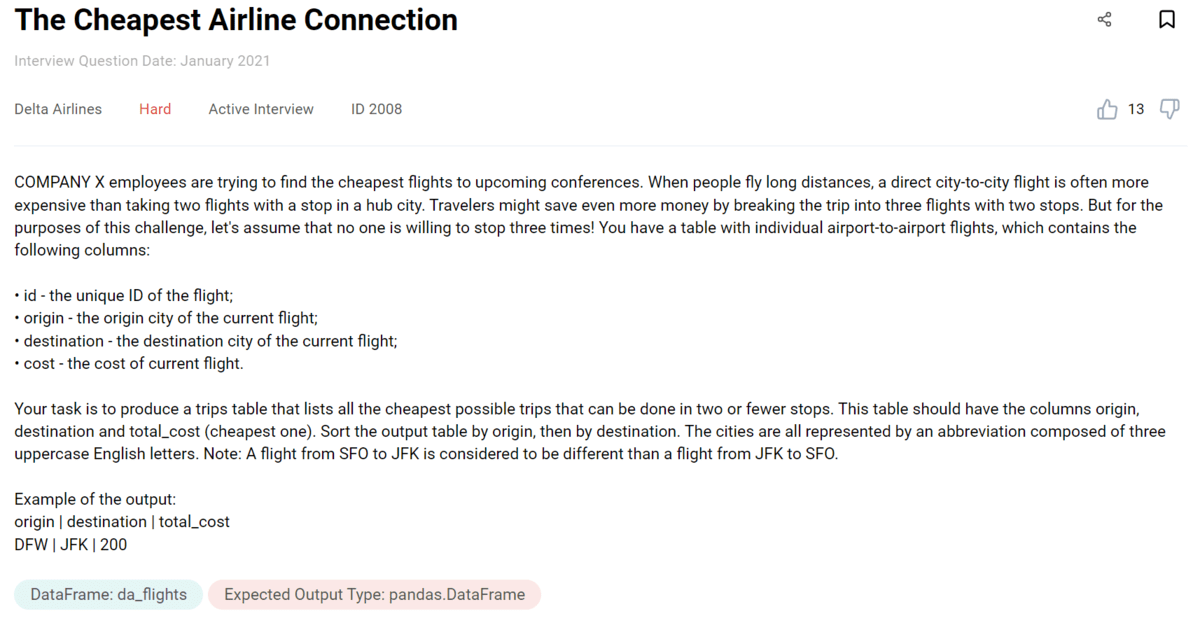
Soruya bağlantı: https://platform.stratascratch.com/coding/2008-the-cheapest-airline-connection
Bu soru, maksimum iki duraklı en ucuz havayolu bağlantısını bulmanızı ister. Bu çok tanıdık geliyor, değil mi? evet biraz değiştirilmiş en kısa yol problemi: yol yerine maliyet vardır.
Size göstereceğim çözüm kapsamlı bir şekilde birleştirme() pandalar işlevini kullanıyor. Ayrıca döngü için itertools kullanacağım. Gerekli tüm kitaplıkları ve modülleri içe aktardıktan sonra ilk adım, kaynak ve hedefin olası tüm kombinasyonlarını oluşturmaktır.
import pandas as pd
import itertools df = pd.DataFrame( list( itertools.product( da_flights["origin"].unique(), da_flights["destination"].unique() ) ), columns=["origin", "destination"],
)
Şimdi, yalnızca çıkış noktasının varış noktasından farklı olduğu kombinasyonları gösterin.
df = df[df['origin'] != df['destination']]
Şimdi da_flights'ı kendisi ile birleştirelim. Ben birleştirme() işlevini kullanacağım ve tablolar hedefte ve kaynakta soldan birleştirilecek. Bu şekilde, ilk varış noktasına giden tüm doğrudan uçuşları ve ardından ilk uçuşun varış noktasıyla aynı orijine sahip bağlantılı uçuşu alırsınız.
connections_1 = pd.merge( da_flights, da_flights, how="left", left_on="destination", right_on="origin", suffixes=["_0", "_1"],
)
Daha sonra bu sonucu da_flights ile birleştiriyoruz. Bu şekilde, üçüncü uçağa bineceğiz. Bu, sorunun izin verdiği maksimum değer olan iki durağa eşittir.
connections_2 = pd.merge( connections_1, da_flights[["origin", "destination", "cost"]], how="left", left_on="destination_1", right_on="origin", suffixes=["", "_2"],
).fillna(0)
Şimdi mantıksal sütun adlarını atayarak birleştirme sonucunu düzenleyelim ve bir ve iki duraklı uçuşların maliyetini hesaplayalım. (Direkt uçuşların maliyeti bizde zaten var!). Bu kolay! Tek aktarmalı uçuşun toplam maliyeti, ilk uçuş artı ikinci uçuştur. İki aktarmalı uçuş için, üç uçuşun tümünün maliyetlerinin toplamıdır.
connections_2.columns = [ "id_0", "origin_0", "destination_0", "cost_0", "id_1", "origin_1", "destination_1", "cost_1", "origin_2", "destination_2", "cost_2",
]
connections_2["cost_v1"] = connections_2["cost_0"] + connections_2["cost_1"]
connections_2["cost_v2"] = ( connections_2["cost_0"] + connections_2["cost_1"] + connections_2["cost_2"]
)
Şimdi oluşturduğum DataFrame'i verilen DataFrame ile birleştireceğim. Bu şekilde, her direkt uçuşun masraflarını belirlemiş olacağım.
result = pd.merge( df, da_flights[["origin", "destination", "cost"]], how="left", on=["origin", "destination"],
)
Ardından, tek durak gerektiren varış noktalarına yapılan uçuşların maliyetlerini almak için yukarıdaki sonucu links_2 ile birleştirin.
result = pd.merge( result, connections_2[["origin_0", "destination_1", "cost_v1"]], how="left", left_on=["origin", "destination"], right_on=["origin_0", "destination_1"],
)
İki duraklı uçuşlar için de aynısını yapın.
result = pd.merge( result, connections_2[["origin_0", "destination_2", "cost_v2"]], how="left", left_on=["origin", "destination"], right_on=["origin_0", "destination_2"],
)
Bunun sonucu, doğrudan, tek duraklı ve iki duraklı uçuşlarla bir kalkış noktasından bir varış noktasına kadar olan maliyetleri veren bir tablodur. Artık min() yöntemini kullanarak en düşük maliyeti bulmanız, NA değerlerini kaldırmanız ve çıktıyı göstermeniz yeterlidir.
result["min_price"] = result[["cost", "cost_v1", "cost_v2"]].min(axis=1)
result[~result["min_price"].isna()][["origin", "destination", "min_price"]]
Bu son kod satırları ile tam çözüm şudur.
import pandas as pd
import itertools df = pd.DataFrame( list( itertools.product( da_flights["origin"].unique(), da_flights["destination"].unique() ) ), columns=["origin", "destination"],
)
df = df[df["origin"] != df["destination"]] connections_1 = pd.merge( da_flights, da_flights, how="left", left_on="destination", right_on="origin", suffixes=["_0", "_1"],
)
connections_2 = pd.merge( connections_1, da_flights[["origin", "destination", "cost"]], how="left", left_on="destination_1", right_on="origin", suffixes=["", "_2"],
).fillna(0)
connections_2.columns = [ "id_0", "origin_0", "destination_0", "cost_0", "id_1", "origin_1", "destination_1", "cost_1", "origin_2", "destination_2", "cost_2",
]
connections_2["cost_v1"] = connections_2["cost_0"] + connections_2["cost_1"]
connections_2["cost_v2"] = ( connections_2["cost_0"] + connections_2["cost_1"] + connections_2["cost_2"]
) result = pd.merge( df, da_flights[["origin", "destination", "cost"]], how="left", on=["origin", "destination"],
) result = pd.merge( result, connections_2[["origin_0", "destination_1", "cost_v1"]], how="left", left_on=["origin", "destination"], right_on=["origin_0", "destination_1"],
) result = pd.merge( result, connections_2[["origin_0", "destination_2", "cost_v2"]], how="left", left_on=["origin", "destination"], right_on=["origin_0", "destination_2"],
)
result["min_price"] = result[["cost", "cost_v1", "cost_v2"]].min(axis=1)
result[~result["min_price"].isna()][["origin", "destination", "min_price"]]
İşte kod çıktısı.
| köken | hedef | min_fiyat |
| SFO | JFK | 400 |
| SFO | DFW | 200 |
| SFO | MCO | 300 |
| SFO | LHR | 1400 |
| DFW | JFK | 200 |
| DFW | MCO | 100 |
| DFW | LHR | 1200 |
| JFK | LHR | 1000 |
Yazara göre resim
Grafiklerin yanı sıra, bir veri bilimcisi olarak ikili ağaçlarla da çalışacaksınız. Bu yüzden DoorDash, Facebook, Microsoft, Amazon, Bloomberg, Apple ve TikTok gibilerinin sorduğu bu Python kodlama mülakat sorusunu nasıl çözeceğinizi bilmeniz faydalı olacaktır.

Soruya bağlantı: https://leetcode.com/problems/binary-tree-maximum-path-sum/description/
Kısıtlamalar şunlardır:

class Solution: def maxPathSum(self, root: Optional[TreeNode]) -> int: max_path = -float("inf") def gain_from_subtree(node: Optional[TreeNode]) -> int: nonlocal max_path if not node: return 0 gain_from_left = max(gain_from_subtree(node.left), 0) gain_from_right = max(gain_from_subtree(node.right), 0) max_path = max(max_path, gain_from_left + gain_from_right + node.val) return max(gain_from_left + node.val, gain_from_right + node.val) gain_from_subtree(root) return max_path
Çözüme yönelik ilk adım, bir maxPathSum işlevi tanımlamaktır. Kökten sol veya sağ düğüme doğru bir yol olup olmadığını belirlemek için, tekrarlamalı gain_from_subtree işlevini yazın.
İlk örnek, bir alt ağacın köküdür. Yol bir köke eşitse (alt düğüm yoksa), o zaman bir alt ağaçtan elde edilen kazanç 0'dır. Ardından, sol ve sağ düğümde özyinelemeyi yapın. Yol toplamı negatifse, soru onu dikkate almamanızı ister; bunu 0 olarak ayarlayarak yapıyoruz.
Ardından, bir alt ağaçtan elde edilen kazançların toplamını mevcut maksimum yolla karşılaştırın ve gerekirse güncelleyin.
Son olarak, maksimum kök artı sol düğüm ve kök artı sağ düğüm olan bir alt ağacın yol toplamını döndürün.
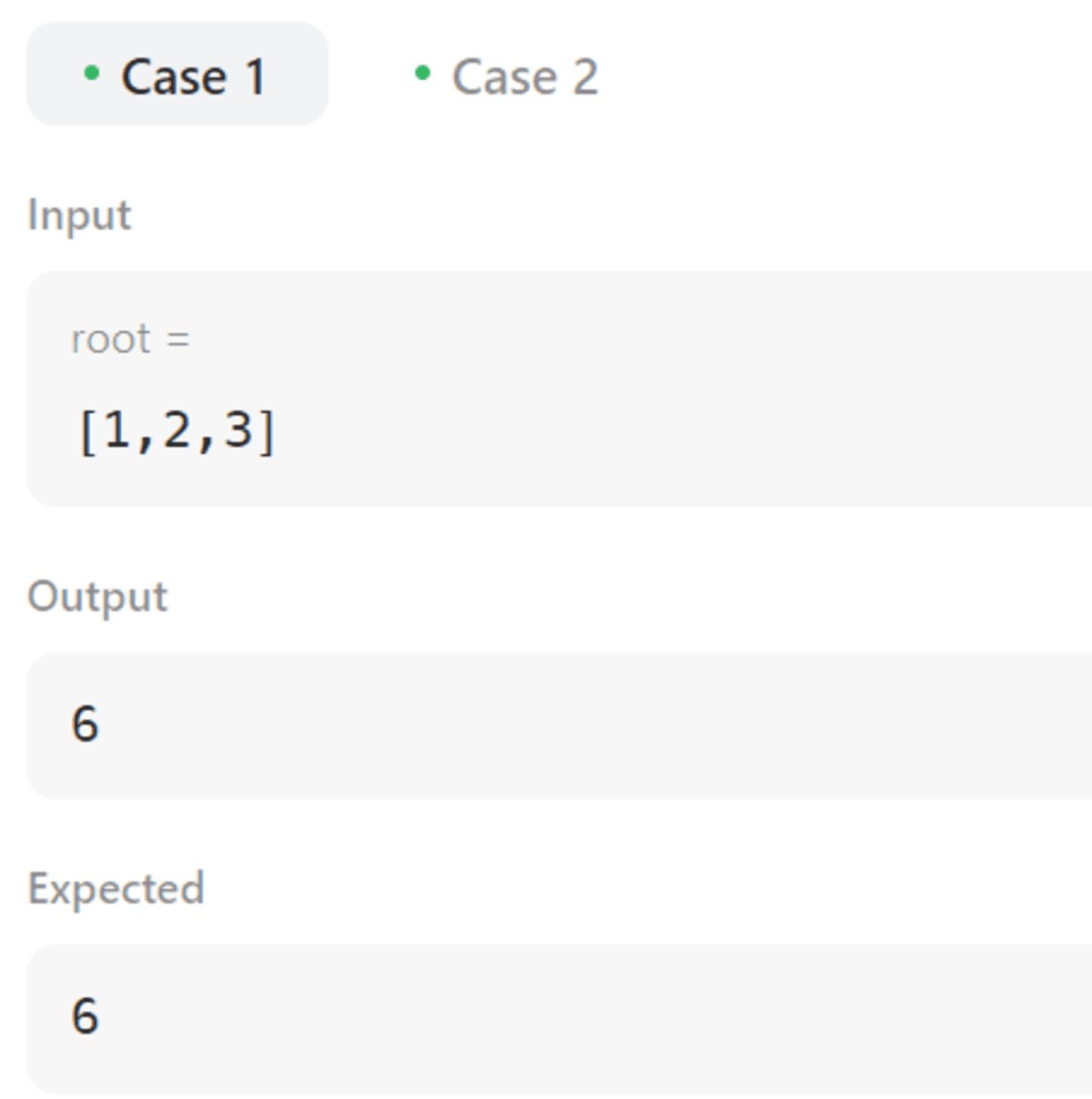
Bunlar Durum 1 ve 2'nin çıktılarıdır.
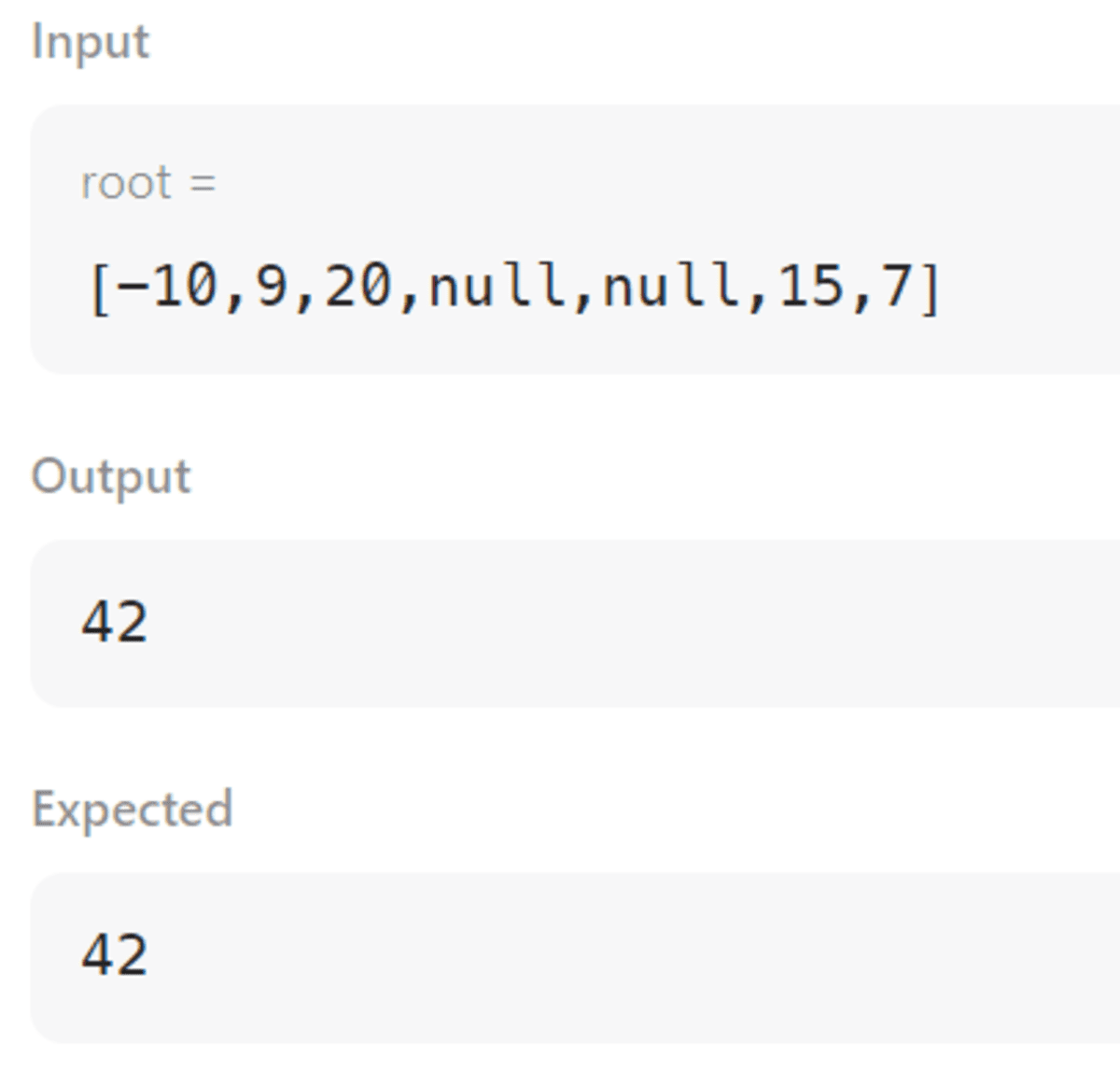
Özet
Bu sefer size farklı bir şey vermek istedim. Bir veri bilimcisi olarak bilmeniz gereken pek çok Python kavramı vardır. Bu sefer çok sık görmediğim üç konuyu ele almaya karar verdim: matematik, grafik veri yapıları ve ikili ağaçlar.
Size gösterdiğim üç soru, bu kavramları Python koduna nasıl çevireceğinizi göstermek için ideal görünüyordu. Çıkış yapmak "Python kodlama mülakat soruları” gibi daha fazla Python konseptini uygulamak için.
Nate Rosidi bir veri bilimcisi ve ürün stratejisidir. Aynı zamanda analitik öğreten bir yardımcı profesördür ve kurucusudur. StrataScratch, veri bilimcilerinin en iyi şirketlerden gelen gerçek röportaj sorularıyla röportajlarına hazırlanmalarına yardımcı olan bir platform. onunla bağlantı kurun Twitter: StrataScratch or LinkedIn.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/2023/03/3-hard-python-coding-interview-questions-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=3-hard-python-coding-interview-questions-for-data-science

