Giriş
Büyük Dil Modellerinin ortaya çıkışıyla (LLM'lergibi daha küçük transformatör modellerinin yerini alarak çok sayıda uygulamaya nüfuz ettiler. Bert veya birçok durumda Kural Tabanlı Modeller Doğal Dil İşleme (NLP) görevler. Yüksek Lisans'lar çok yönlüdür ve kapsamlı ön eğitimleri sayesinde Metin Sınıflandırma, Özetleme, Duygu Analizi ve Konu Modelleme gibi görevleri yerine getirebilmektedir. Bununla birlikte, geniş yeteneklerine rağmen, LLM'ler genellikle daha küçük muadilleriyle karşılaştırıldığında doğruluk açısından geride kalmaktadır.
Bu sınırlamayı ele almak için etkili bir strateji, önceden eğitilmiş LLM'leri belirli görevlerde başarılı olacak şekilde ayarlamaktır. Büyük modellerde ince ayar yapılması sıklıkla en iyi sonuçları verir. Diğer büyük modellerin yanı sıra Google Gemini'nin artık kullanıcılara bu modellere kendi eğitim verileriyle ince ayar yapma yeteneği sunması dikkat çekicidir. Bu kılavuzda, Gemini modellerine belirli sorunlar için ince ayar yapma sürecinin yanı sıra HuggingFace'in kaynaklarını kullanarak bir veri kümesinin nasıl iyileştirileceğini anlatacağız.
Öğrenme hedefleri
- Google'ın Gemini modellerinin performansını anlayın.
- Gemini modelinin ince ayarını yapmak için Veri Kümesi Hazırlamayı öğrenin.
- Gemini modelinin ince ayarı için parametreleri yapılandırın.
- İnce ayar ilerlemesini ve ölçümlerini izleyin.
- Gemini modelinin performansını yeni veriler üzerinde test edin.
- PII maskelemeye yönelik Gemini modeli uygulamalarını keşfedin.

Bu makale, Veri Bilimi Blogatonu.
İçindekiler
Google Gemini'yi Ayarlayacağını Duyurdu
Gemini'nin iki versiyonu vardır: Pro ve Ultra. Pro sürümünde Gemini 1.0 Pro ve yeni Gemini 1.5 Pro bulunmaktadır. Google'ın bu modelleri ChatGPT ve Claude gibi diğer gelişmiş modellerle rekabet ediyor. Gemini modellerine AI Studio kullanıcı arayüzü ve ücretsiz bir API aracılığıyla herkes kolayca erişebilir.
Geçtiğimiz günlerde Google, Gemini modelleri için yeni bir özelliği duyurdu: ince ayar. Bu, herkesin Gemini modelini kendi ihtiyaçlarına göre ayarlayabileceği anlamına gelir. Gemini'de AI Studio kullanıcı arayüzünü veya API'sini kullanarak ince ayar yapabilirsiniz. İnce ayar, Gemini'nin istediğimiz gibi davranabilmesi için kendi verilerimizi ona vermemizdir. Google, Gemini modelinin birkaç önemli parçasını hızlı bir şekilde ayarlamak için Parametre Verimli Ayarlama'yı (PET) kullanıyor ve bu da onu farklı görevler için kullanışlı hale getiriyor.
Veri Kümesini Hazırlama
Modelin ince ayarını yapmaya başlamadan önce gerekli kütüphaneleri kurmaya başlayacağız. Bu arada bu rehber için Colab ile çalışacağız.
Gerekli Kütüphanelerin Kurulumu
Başlamak için gerekli Python modülleri şunlardır:
!pip install -q google-generativeai datasets- google-üretkenlik: Google Gemini Modeline erişmemizi sağlayan, Google ekibinin hazırladığı bir kütüphanedir. Gemini Modeline ince ayar yapmak için aynı kütüphaneyle çalışılabilir.
- veri kümeleri: Bu, HuggingFace merkezinden çeşitli veri kümelerini indirmek için birlikte çalışabileceğimiz bir HuggingFace kütüphanesidir. PII (Kişisel Tanımlanabilir Bilgiler) veri setini indirmek ve İnce Ayar için Gemini Modeline vermek için bu veri seti kütüphanesiyle çalışacağız.
Aşağıdaki kodu çalıştırdığınızda Google Generative AI ve Veri Kümeleri kitaplığı Python Ortamımıza indirilip yüklenecektir.
OAuth'u ayarlama
Bir sonraki adımda bu eğitim için bir OAuth ayarlamamız gerekiyor. Gemini'de İnce Ayar yapmak için Google'a gönderdiğimiz verilerin güvende olması için OAuth gereklidir. OAuth'u almak için şunu izleyin Link. Daha sonra OAuth'u oluşturduktan sonra client_secret.json dosyasını indirin. Client_secrent.json içeriğini CLIENT_SECRET adı altında Colab Secrets'a kaydedin ve aşağıdaki kodu çalıştırın:
import os
if 'COLAB_RELEASE_TAG' in os.environ:
from google.colab import userdata
import pathlib
pathlib.Path('client_secret.json').write_text(userdata.get('CLIENT_SECRET'))
# Use `--no-browser` in colab
!gcloud auth application-default login --no-browser
--client-id-file client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'
else:
!gcloud auth application-default login --client-id-file
client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'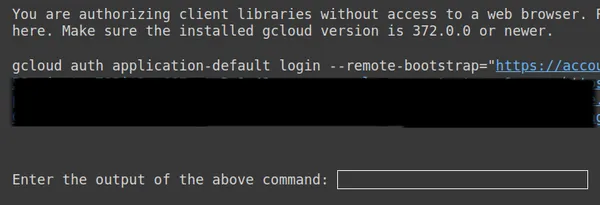
Yukarıdaki ikinci bağlantıyı kopyalayıp CMD yerel sisteminize yapıştırın ve çalıştırın.
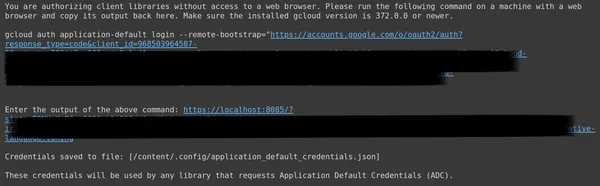
Ardından, OAuth'u kurduğunuz e-posta adresiyle oturum açmak için Web Tarayıcısına yönlendirileceksiniz. CMD’ye giriş yaptıktan sonra bir URL alıyoruz, şimdi bu URL’yi 3. satıra yapıştırıp enter tuşuna basıyoruz. Artık Google ile OAuth işlemini tamamladık.
Veri Kümesini İndirmek ve Hazırlamak
Öncelikle Gemini Modeline ince ayar yapmak için çalışacağımız veri setini indirerek başlayacağız. Bunun için veri seti kütüphanesi ile çalışıyoruz. Bunun kodu şöyle olacaktır:
from datasets import load_dataset
dataset = load_dataset("ai4privacy/pii-masking-200k")
print(dataset)- Burada veri kümeleri kitaplığından load_dataset işlevini içe aktararak başlıyoruz.
- Bu load_dataset() fonksiyonuna indirmek istediğimiz veri setini aktarıyoruz. Örneğimizde, 4 bin satırlık maskelenmiş ve maskesiz PII verilerini içeren "ai200privacy/pii-masking-200k"dir.
- Daha sonra veri setini yazdırıyoruz.

Veri setinin 209261 satır eğitim verisi içerdiğini ve test verisi içermediğini görüyoruz. Ve her satırda masked_text, unmasked_text, gizlilik_mask, span_labels, bio_labels ve tokenised_text gibi farklı sütunlar bulunur. Örnek veriler aşağıda belirtilmiştir:
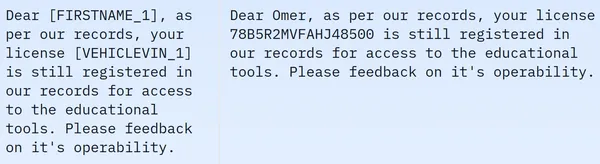
Görüntülenen görselde hem maskeli hem de maskesiz cümleleri görüyoruz. Özellikle maskelenmiş cümlede kişinin adı ve araç numarası gibi belirli unsurlar belirli etiketlerle gizlenmiştir. Verileri daha sonraki işlemlere hazırlamak için şimdi bazı veri ön işlemeleri yapmamız gerekiyor. Bu ön işleme adımının kodu aşağıdadır:
df = dataset['train'].to_pandas()
df = df[['unmasked_text','masked_text']][:2000]
df.columns = ['input','output']
- Öncelikle veri setinden verinin eğitim kısmını alıyoruz (indirdiğimiz veri seti sadece eğitim kısmını içeriyor). Daha sonra bunu Pandas Dataframe'e dönüştürüyoruz.
- Burada Gemini'ye ince ayar yapmak için yalnızca unmasked_text ve masked_text sütunlarına ihtiyacımız var, dolayısıyla yalnızca bu ikisini alıyoruz.
- Daha sonra verinin ilk 2000 satırını alıyoruz. Gemini'ye ince ayar yapmak için ilk 2000 satırla çalışacağız.
- Daha sonra unmasked_text ve masked_text'ten giriş ve çıkış sütunlarına kadar olan sütun adlarını düzenleriz, çünkü PII'yi (Kişisel Tanımlanabilir Bilgiler) içeren giriş metni verilerini Gemini Modeline verdiğimizde, PII'nin bulunduğu çıkış metni verilerini oluşturmasını bekleriz. maskelenmiştir.
Gemini'nin İnce Ayarı için Verileri Biçimlendirme
Bir sonraki adım verilerimizi formatlamaktır. Bunu yapmak için bir biçimlendirici işlevi oluşturacağız:
def formatter(x):
text = f"""
Given the information below, mask the personal identifiable information.
Input:
{x['input']}
Output:
"""
return text
df['text_input'] = df.apply(formatter,axis=1)
print(df['text_input'][0])- Burada verilerimizin bir satırı olan x'i alan bir işlev biçimlendiriciyi tanımlıyoruz.
- Daha sonra, bağlamı sağladığımız f-dizeleri ve ardından veri çerçevesinden gelen giriş verileri ile değişken bir metin tanımlar.
- Son olarak biçimlendirilmiş metni döndürüyoruz.
- Son satır, formatlayıcı fonksiyonunu, application() fonksiyonu aracılığıyla oluşturduğumuz veri çerçevesinin her satırına uygular.
- Eksen=1, fonksiyonun veri çerçevesinin her satırına uygulanacağını söyler.
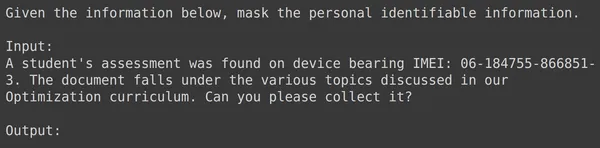
Kodun çalıştırılması, giriş alanı da dahil olmak üzere her satır için biçimlendirilmiş metni içeren "eğitim" adı verilen yeni bir sütunun oluşturulmasıyla sonuçlanacaktır. Veri çerçevesinin öğelerinden birini gözlemlemeyi deneyelim:
Verileri Tren ve Test Setlerine Bölme
Text_input'un, her satırın PII'yi maskelemeyi söyleyen verilerin başlangıcındaki bağlamı içerdiği ve ardından giriş verilerinin ve ardından modelin çıktıyı oluşturması gereken kelime çıkışının geldiği verileri içerdiğini görebiliriz. Şimdi veri çerçevesini eğitim ve test olarak bölmemiz gerekiyor:
df = df[['text_input','output']]
df_train = df.iloc[:1900,:]
df_test = df.iloc[1900:,:]- Verileri text_input ve çıktı sütunlarını içerecek şekilde filtreleyerek başlıyoruz. Bunlar Google Fine-Tune kütüphanesinin Gemini'yi eğitmek için beklediği sütunlardır
- Gemini text_input'u alacak ve çıktıyı yazmayı öğrenecek
- Verileri orijinal verilerimizin 1900 satırını içeren df_train'e bölüyoruz
- Ve orijinal verilerin yaklaşık 100 satırını içeren bir df_test
- Gemini'yi df_train üzerinde eğitiyoruz ve ardından ürettiği çıktıyı görmek için df_test'ten 3-4 örnek alarak test ediyoruz.
Yani kodu çalıştırmak verilerimizi filtreleyecek ve onu eğitim ve test olarak bölecektir. Son olarak veri ön işleme kısmını bitiriyoruz.
İnce Ayar İkizler Modeli
Gemini Modelinize ince ayar yapmak için aşağıda belirtilen adımları izleyin:
Ayarlama Parametrelerini Ayarlama
Bu bölümde Gemini Modeline Ayarlama işlemini gerçekleştireceğiz. Bunun için aşağıdaki kodla çalışacağız:
import google.generativeai as genai
bm_name = "models/gemini-1.0-pro-001"
name = 'pii-model'
operation = genai.create_tuned_model(
source_model=bm_name,
training_data=df_train,
id = name,
epoch_count = 2,
batch_size=4,
learning_rate=0.001,
)
- Google.generativeai kitaplığını içe aktarın: Bu kitaplık, Google'ın Üretken Yapay Zeka hizmetleriyle etkileşime geçmek için API'ler sağlar.
- Temel Model Adını Sağlayın: Bu, ince ayarlı modelimizin başlangıç noktası olarak çalışmak istediğimiz önceden eğitilmiş modelin adıdır. Şu anda ayarlanabilir tek model models/gemini-1.0-pro-001'dir, bunu bm_name değişkeninde saklıyoruz.
- İnce ayarlı modelin adını belirtin: Bu, ince ayarlı modelimize vermek istediğimiz addır. Burada buna “pii-model” ismini veriyoruz.
- Ayarlanmış Model İşlemi nesnesi oluşturun: Bu nesne, ince ayarlı bir model oluşturma işlemini temsil eder. Aşağıdaki argümanları alır:
- source_model: Temel Modelin adı
- training_data: Az önce oluşturduğumuz ince ayarlı model için eğitim verileri, yani df_train
- id: İnce ayar yapılan modelin kimliği/adı
- epoch_count: Eğitim dönemi sayısı. Bu örnek için, 2 dönem ile yapacağız
- Batch_size: Eğitim için parti boyutu. Bu örnek için 4 değerini kullanacağız
- Learning_rate: Eğitim için Öğrenme Oranı. Burada 0.001 değerini sağlıyoruz.
- Parametreleri sağlamayı bitirdik. Bu kodu çalıştırmak, ince ayarlı bir model nesnesi oluşturacaktır. Şimdi Gemini LLM'nin eğitim sürecine başlamamız gerekiyor. Bunun için aşağıdaki kodla çalışıyoruz.
Parametreleri ayarlamayı bitirdik. Bu kodu çalıştırmak, ayarlanmış bir model nesnesi yaratacaktır. Şimdi Gemini LLM'nin eğitim sürecine başlamamız gerekiyor. Bunun için aşağıdaki kodla çalışıyoruz:
model = genai.get_tuned_model(f'tunedModels/{name}')
print(model)Ayarlanmış Bir Model Oluşturma
Burada genai kütüphanesinden .get_tuned_model() fonksiyonunu kullanarak tanımladığımız modelimizin adını geçiyoruz ve eğitim sürecini başlatıyoruz. Daha sonra aşağıdaki resimde gösterildiği gibi modeli yazdırıyoruz:
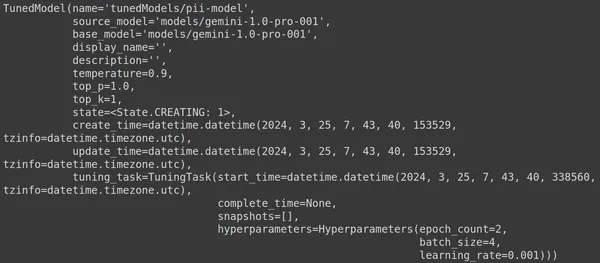
Model TunedModel türündedir. Burada tanımladığımız modele ait farklı parametreleri gözlemleyebiliyoruz. Bunlar:
- name: Bu değişken, ayarlanan modelimiz için sağladığımız adı içerir.
- source_model: Bu, ince ayarını yaptığımız kaynak modeldir; örneğimizde models/gemini-1.0-pro
- base_model: Bu yine ince ayarını yaptığımız temel modeldir; örneğimizde models/Gemini-1.0-pro. Temel model daha önceden ince ayar yapılmış bir model bile olabilir. İşte biz ikimiz için de aynıyız
- display_name: Ayarlanan modelin görünen adı
- açıklama: Modelimizin herhangi bir açıklamasını ve modelin neyle ilgili olduğunu içerir
- sıcaklık: Değer ne kadar yüksek olursa, Büyük Dil Modelinden oluşturulan yanıtlar da o kadar yaratıcı olur. Burada varsayılan olarak 0.9'a ayarlanmıştır
- top_p: Metin oluştururken belirteç seçimi için en yüksek olasılığı tanımlar. Top_p sayısı arttıkça daha fazla token seçilir, yani tokenlar daha büyük bir veri örneğinden seçilir
- top_k: Her adımda büyük olasılıkla sonraki k jetondan örnek alınmasını söyler. Burada top_k 1'dir; bu, en olası sonraki jetonun seçilecek olan olduğu anlamına gelir; yani en yüksek olasılığa sahip jeton her zaman seçilecektir.
- durum: Durum yaratılıyor, modelin şu anda ince ayarlandığını ima ediyor
- create_time: Modelin oluşturulduğu zaman
- update_time: Modelin en son ayarlandığı zamandır
- tuning_task: Ayarlama için tanımladığımız sıcaklık, dönemler ve parti boyutunu içeren parametreleri içerir
Eğitim Sürecinin Başlatılması
Ayarlanan modelin durumunu ve meta verilerini bile aşağıdaki kod aracılığıyla alabiliriz:
print(operation.metadata)
Burada tahmin edilebilir olan toplam adımları, yani 950'yi görüntüler. Çünkü örneğimizde 1900 satırlık eğitim verimiz var. Her adımda 4'lü, yani 4 satırlık bir grup alıyoruz, yani tam bir dönem için 1900/4 yani 475 adımımız var. Eğitim için 2 dönem belirledik, bu da 2*475 = 950 adım anlamına gelir.
Eğitim İlerlemesini İzleme
Aşağıdaki kod, eğitimin yüzde kaçının bittiğini ve tüm eğitim sürecinin tamamlanmasının ne kadar süreceğini belirten bir durum çubuğu oluşturur:
import time
for status in operation.wait_bar():
time.sleep(30)
Yukarıdaki kod bir ilerleme çubuğu oluşturur, tamamlandığında ayarlama işlemimizin sona erdiğini gösterir.
Eğitim Performansını Görselleştirme
Operasyon nesnesi eğitimin anlık görüntülerini bile içerir. Dönem başına ortalama kayıp gibi değerlendirme ölçümlerini içerecektir. Bunu aşağıdaki kodla görselleştirebiliriz:
import pandas as pd
import seaborn as sns
model = operation.result()
snapshots = pd.DataFrame(model.tuning_task.snapshots)
sns.lineplot(data=snapshots, x = 'epoch', y='mean_loss')- Burada, Operation.result()'tan ayarlanan son modeli alıyoruz.
- Modeli eğittiğimizde model sık aralıklarla anlık görüntüler alır. Bu anlık görüntüler, ortalama_kayıp gibi verileri içerir. Bu nedenle, ayarlanan modelin anlık görüntülerini model.tuning_task.snapshots'ı çağırarak çıkarıyoruz.
- Snapshot'ları pd.DataFrame'e geçirip snapshots değişkeninde saklayarak bu snapshot'lardan bir dataframe oluşturuyoruz.
- Son olarak, çıkarılan anlık görüntü verilerinden bir çizgi grafiği oluşturuyoruz
Kodun çalıştırılması aşağıdaki grafikle sonuçlanacaktır:
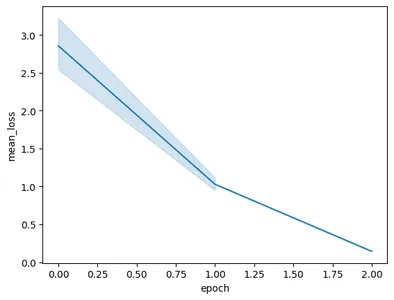
Bu görüntüde, sadece 3 eğitim döneminde kaybı 0.5'ten 2'in altına düşürdüğümüzü görebiliyoruz. Sonunda Gemini Modelinin eğitimini tamamladık
İnce Ayarlı İkizler Modelinin Test Edilmesi
Bu bölümde modelimizi test verileri üzerinde test edeceğiz. Şimdi ayarlanan modelle çalışmak için aşağıdaki kodla çalışıyoruz:
model = genai.GenerativeModel(model_name=f'tunedModels/{name}')Yukarıdaki kod, Kişisel Tanımlanabilir Bilgi verileriyle yeni eğittiğimiz ayarlanmış modeli yükleyecektir. Şimdi bu modeli bir kenara koyduğumuz test verilerinden bazı örneklerle test edeceğiz. Bunun için test setinden rastgele text_input'u ve buna karşılık gelen çıktıyı yazdıralım:
print(df_test['text_input'][1900])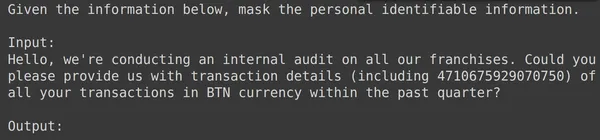
df_test['output'][1900]
Yukarıda rastgele bir text_input'u ve test setinden alınan çıktıyı görebiliriz. Şimdi bu text_input'u modele aktaracağız ve oluşturulan çıktıyı gözlemleyeceğiz:
text = df_test['text_input'][1900]
res = model.generate_content(text)
print(res.text)
Modelin, verilen text_input için Kişisel Tanımlayıcı Bilgiyi maskelemede başarılı olduğunu ve model tarafından oluşturulan çıktının, test setindeki çıktıyla tam olarak eşleştiğini görüyoruz. Şimdi bunu birkaç örnekle daha deneyelim:
print(df_test['text_input'][1969])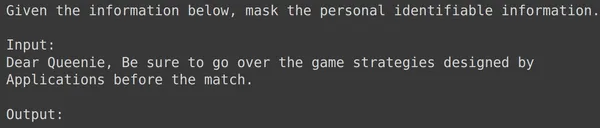
print(df_test['output'][1969])
text = df_test['text_input'][1969]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1987])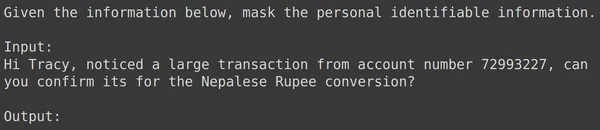
print(df_test['output'][1987])
text = df_test['text_input'][1987]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1933])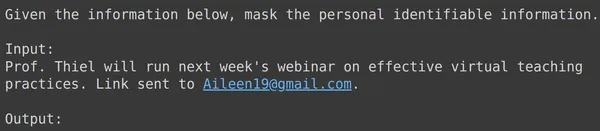
print(df_test['output'][1933])
text = df_test['text_input'][1933]
res = model.generate_content(text)
print(res.text)
Yukarıdaki tüm örneklerde ince ayarlı model performansımızın iyi olduğunu görüyoruz. Model, verilen eğitim verilerinden öğrenmeyi başardı ve hassas kişisel bilgileri gizlemek için maskelemeyi doğru şekilde uyguladı. Böylece ince ayar için bir veri kümesinin nasıl oluşturulacağını ve bir veri kümesi üzerinde Gemini Modeline nasıl ince ayar yapılacağını baştan sona gördük ve gördüğümüz sonuçlar, ince ayar yapılmış bir model için çok ümit verici görünüyor
Sonuç
Sonuç olarak bu kılavuz, Google'ın amiral gemisi Gemini modellerinde kişisel tanımlayıcı bilgilerin (PII) maskelenmesine yönelik ince ayarlar yapılmasına ilişkin kapsamlı bir kılavuz sunmaktadır. Google'ın Gemini modellerine yönelik ince ayar özelliğine ilişkin blog gönderisini inceleyerek başladık ve göreve özel doğruluk elde etmek için bu modellerde ince ayar yapılması gerektiğini vurguladık. Veri Kümesi Hazırlama, Gemini modeline ince ayar yapma ve performansını test etme gibi kılavuzda özetlenen pratik adımlar sayesinde kullanıcılar, PII maskeleme görevleri için büyük dil modellerinin gücünden yararlanabilirler.
İşte bu kılavuzdan önemli çıkarımlar:
- Gemini modelleri, ince ayar için güçlü bir kitaplık sağlayarak kullanıcıların Parametre Verimli Ayarlama (PET) yoluyla PII maskeleme dahil belirli görevlere göre bunları uyarlamasına olanak tanır.
- Veri kümesi hazırlığı, gerekli modüllerin kurulumunu, veri güvenliği için OAuth'un başlatılmasını ve verilerin eğitim için biçimlendirilmesini içeren çok önemli bir adımdır.
- İnce ayar süreci, Gemini modelini Hazırlanan Veri Kümesi üzerinde eğitmek için Temel Model, dönem sayısı, toplu iş boyutu ve Öğrenme Oranı gibi parametrelerin sağlanmasını içerir
- Eğitim ilerlemesinin izlenmesi, durum güncellemeleri ve dönem başına ortalama kayıp gibi ölçümlerin görselleştirilmesi yoluyla kolaylaştırılmıştır.
- İnce ayarı yapılmış modelin ayrı bir test veri kümesinde test edilmesi, verilerin bütünlüğünü korurken PII'yi doğru bir şekilde maskeleme performansını doğrular.
- Sunulan örnekler, ince ayarlı Gemini modelinin hassas kişisel bilgileri başarılı bir şekilde maskelemedeki etkinliğini ortaya koyuyor ve gerçek dünya uygulamaları için umut verici sonuçlara işaret ediyor
Sık Sorulan Sorular
A. Parametre Verimli Ayarlama (PET), modelin yalnızca küçük bir parametre grubuna ince ayar yapan ince ayar tekniklerinden biridir. Bu, Google tarafından Gemini modelindeki önemli katmanlara hızla ince ayar yapmak için kullanılır. Modeli kullanıcının verilerine verimli bir şekilde uyarlayarak belirli görevler için performansını artırır
A. Gemini modelinin ayarlanması Temel Model adı, Dönem Sayısı, Grup Boyutu ve Öğrenme Oranı gibi parametrelerin sağlanmasını içerir. Bu parametreler eğitim sürecini etkiler ve sonuçta modelin performansını etkiler.
C. Kullanıcılar, ince ayarlı Gemini modelinin eğitim ilerlemesini durum güncellemeleri, dönem başına ortalama kayıp gibi ölçümlerin görselleştirilmesi ve eğitim sürecinin anlık görüntülerini gözlemleyerek izleyebilir.
C. Gemini modeline ince ayar yapmadan önce kullanıcıların google-generativeai ve datasets gibi gerekli kitaplıkları yüklemeleri gerekir. Ayrıca veri güvenliği için OAuth'un başlatılması ve eğitim için veri kümesinin biçimlendirilmesi de önemli adımlardır.
C. Veri anonimleştirme, NLP uygulamalarında gizliliğin korunması ve GDPR gibi veri koruma düzenlemelerine uyumluluk gibi PII maskelemenin gerekli olduğu farklı alanlarda ince ayarlı bir Gemini modeli uygulanabilir.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2024/03/guide-to-fine-tuning-gemini-for-masking-pii-data/

