Yazara göre resim
Keşif Amaçlı Veri Analizi (veya EDA), Veri Analizi Sürecinde temel bir aşama olarak durur ve bir veri kümesinin iç ayrıntılarına ve özelliklerine ilişkin kapsamlı bir araştırmayı vurgular.
Temel amacı, altta yatan kalıpları ortaya çıkarmak, veri kümesinin yapısını kavramak ve olası anormallikleri veya değişkenler arasındaki ilişkileri belirlemektir.
Veri profesyonelleri EDA gerçekleştirerek verinin kalitesini kontrol eder. Bu nedenle daha fazla analizin doğru ve anlaşılır bilgilere dayanmasını sağlayarak sonraki aşamalarda hata olasılığını azaltır.
Öyleyse bir sonraki Veri Bilimi projemiz için iyi bir EDA gerçekleştirmek için temel adımların neler olduğunu birlikte anlamaya çalışalım.
Şu cümleyi daha önce duymuş olduğunuza eminim:
Çöp içeri çöp dışarı
Giriş verilerinin kalitesi her başarılı veri projesi için her zaman en önemli faktördür.
Ne yazık ki çoğu veri ilk başta kirdir. Keşifsel Veri Analizi süreci sayesinde, neredeyse kullanılabilir olan bir veri kümesi, tamamen kullanılabilir bir veri kümesine dönüştürülebilir.
Bunun herhangi bir veri kümesini arındırmak için sihirli bir çözüm olmadığını açıklığa kavuşturmak önemlidir. Bununla birlikte, çok sayıda EDA stratejisi, veri kümelerinde karşılaşılan çeşitli tipik sorunların çözümünde etkilidir.
Öyleyse… Ayodele Oluleye'nin Python Yemek Kitabı ile Keşifsel Veri Analizi adlı kitabındaki en temel adımları öğrenelim.
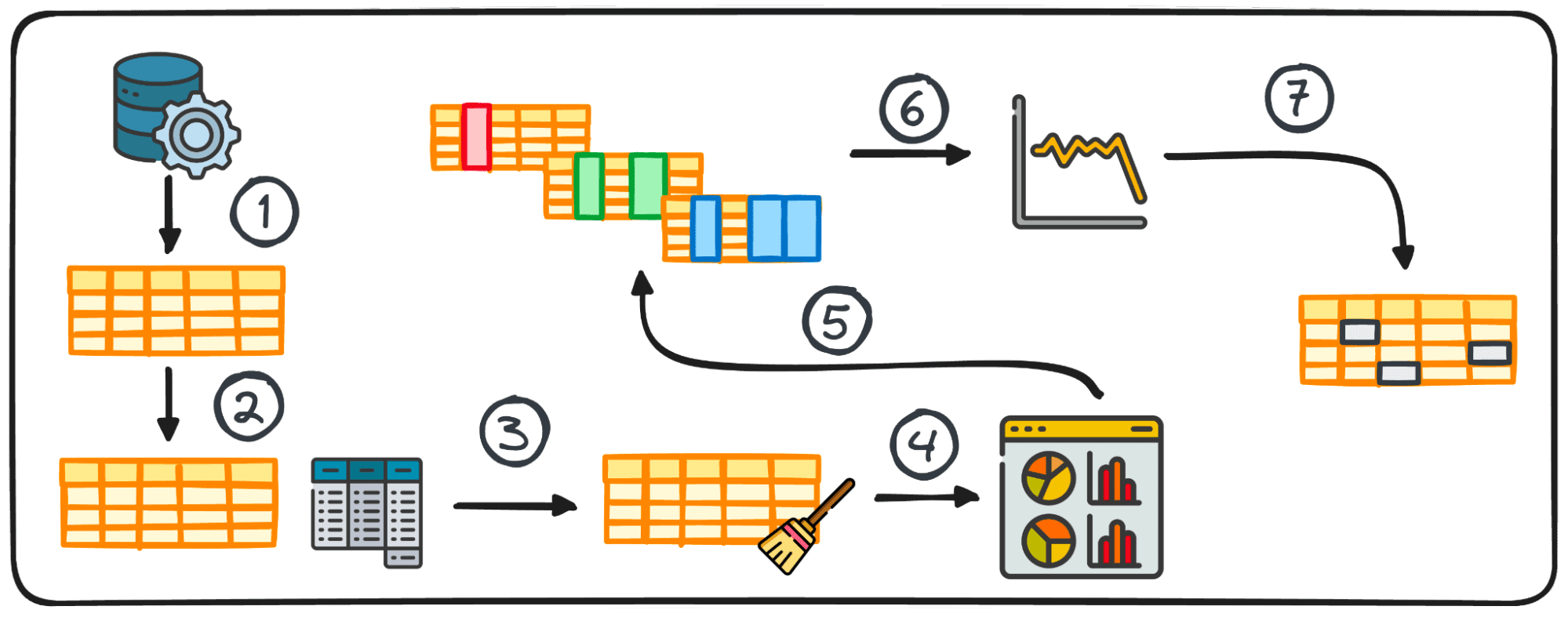
1. Adım: Veri Toplama
Herhangi bir veri projesindeki ilk adım, verinin kendisine sahip olmaktır. Bu ilk adım, sonraki analiz için çeşitli kaynaklardan verilerin toplandığı yerdir.
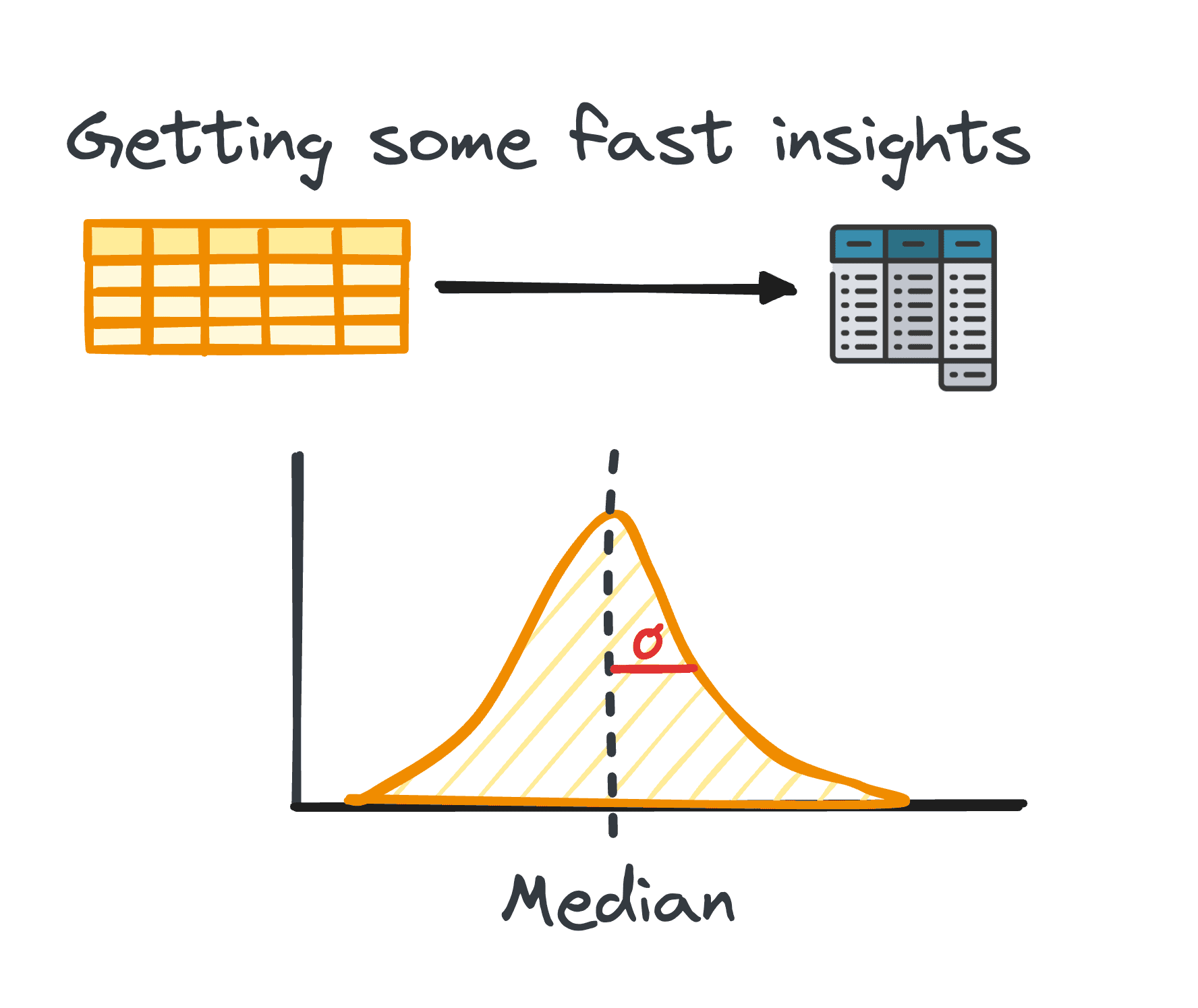
2. Özet İstatistikler
Veri analizinde tablo halindeki verilerin işlenmesi oldukça yaygındır. Bu tür verilerin analizi sırasında, genellikle verilerin kalıplarına ve dağılımına ilişkin hızlı içgörüler elde etmek gerekir.
Bu ilk bilgiler, daha fazla araştırma ve derinlemesine analiz için bir temel görevi görür ve özet istatistikler olarak bilinir.
Ortalama, medyan, mod, varyans, standart sapma, aralık, yüzdelikler ve çeyrekler gibi ölçümlerle özetlenen veri kümesinin dağılımına ve modellerine ilişkin kısa bir genel bakış sunarlar.
Yazara göre resim
3. EDA için Verilerin Hazırlanması
Araştırmamıza başlamadan önce verilerin genellikle daha ileri analizler için hazırlanması gerekir. Veri hazırlama, analizinizin ihtiyaçlarına uyacak şekilde Python'un pandas kütüphanesini kullanarak verileri dönüştürmeyi, toplamayı veya temizlemeyi içerir.
Bu adım, verinin yapısına göre uyarlanmıştır ve gruplandırmayı, eklemeyi, birleştirmeyi, sıralamayı, kategorize etmeyi ve kopyalarla uğraşmayı içerebilir.
Python'da bu görevin yerine getirilmesi, çeşitli modüller aracılığıyla pandas kütüphanesi tarafından kolaylaştırılır.
Tablosal verilerin hazırlanma süreci evrensel bir yönteme bağlı kalmamaktadır; bunun yerine verilerimizin satırları, sütunları, veri türleri ve içerdiği değerler dahil olmak üzere belirli özelliklerine göre şekillenir.
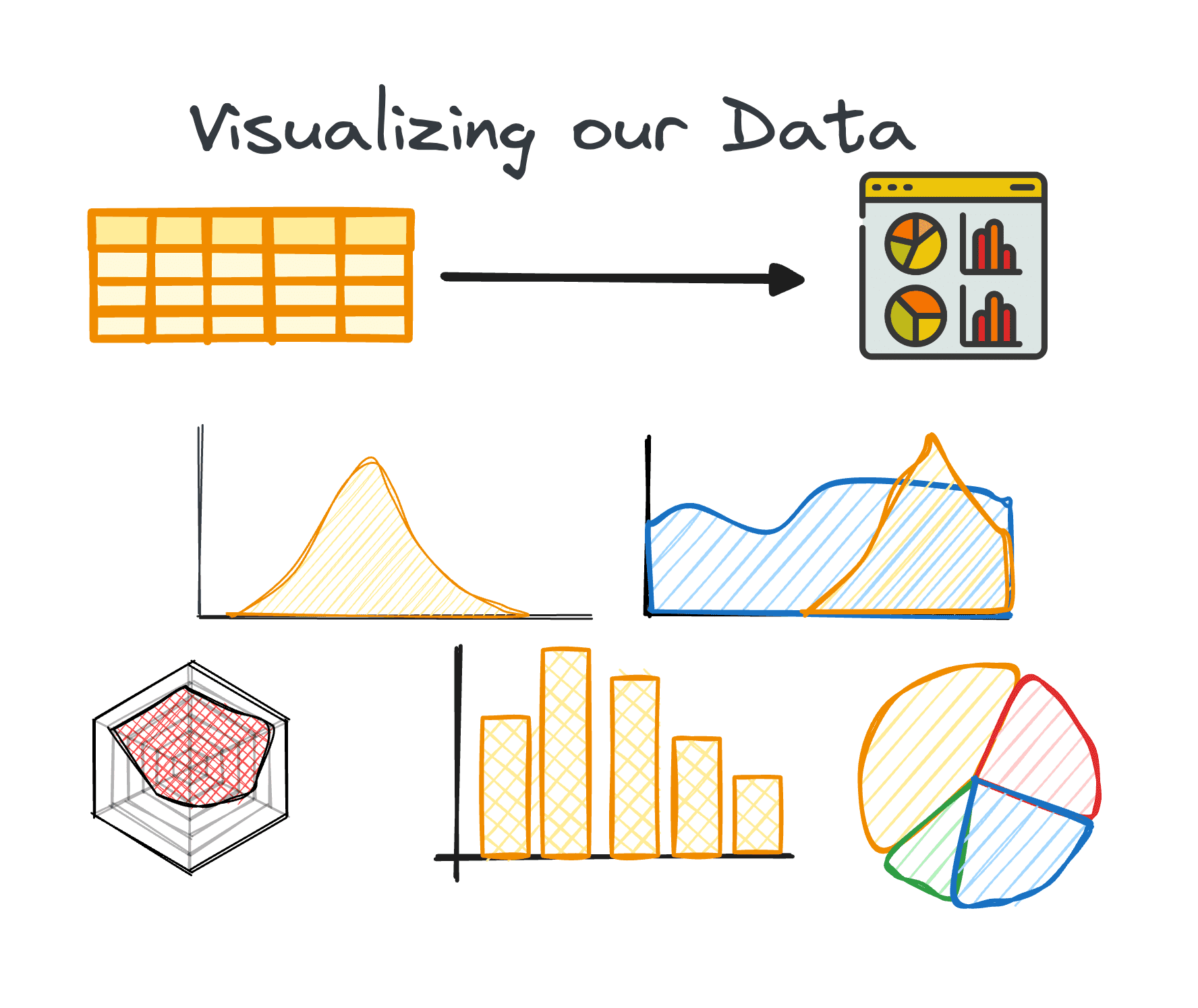
4. Verileri Görselleştirme
Görselleştirme, EDA'nın temel bir bileşenidir ve veri kümesi içindeki karmaşık ilişkileri ve eğilimleri kolayca anlaşılır hale getirir.
Doğru grafikleri kullanmak, büyük bir veri kümesindeki eğilimleri tanımlamamıza ve gizli kalıpları veya aykırı değerleri bulmamıza yardımcı olabilir. Python, diğerlerinin yanı sıra Matplotlib veya Seaborn da dahil olmak üzere veri görselleştirme için farklı kütüphaneler sunar.
Yazara göre resim
5. Değişken Analizinin Yapılması:
Değişken analizi tek değişkenli, iki değişkenli veya çok değişkenli olabilir. Bunların her biri, veri kümesinin değişkenleri arasındaki dağılım ve korelasyonlara ilişkin bilgiler sağlar. Teknikler analiz edilen değişken sayısına bağlı olarak değişir:
Tek değişkenli
Tek değişkenli analizde asıl odak noktası, veri setimizdeki her değişkenin kendi başına incelenmesidir. Bu analiz sırasında medyan, mod, maksimum, aralık ve aykırı değerler gibi bilgileri ortaya çıkarabiliriz.
Bu analiz türü hem kategorik hem de sayısal değişkenlere uygulanabilir.
İki değişkenli
İki değişkenli analiz, seçilen iki değişken arasındaki içgörüyü ortaya çıkarmayı amaçlar ve bu iki değişken arasındaki dağılım ve ilişkiyi anlamaya odaklanır.
İki değişkeni aynı anda analiz ettiğimiz için bu tür bir analiz daha yanıltıcı olabilir. Üç farklı değişken çiftini kapsayabilir: sayısal-sayısal, sayısal-kategorik ve kategorik-kategorik.
Çok değişkenli
Büyük veri kümelerinde sık karşılaşılan bir zorluk, birden fazla değişkenin eş zamanlı analizidir. Tek değişkenli ve iki değişkenli analiz yöntemleri değerli bilgiler sunsa da, bu genellikle birden fazla değişken (genellikle beşten fazla) içeren veri kümelerini analiz etmek için yeterli değildir.
Genellikle boyutluluğun laneti olarak adlandırılan yüksek boyutlu verileri yönetme sorunu, iyi belgelenmiştir. Çok sayıda değişkene sahip olmak, daha fazla içgörü elde edilmesini sağladığından avantajlı olabilir. Aynı zamanda birden fazla değişkenin aynı anda analiz edilmesi veya görselleştirilmesi için mevcut tekniklerin sınırlı olması nedeniyle bu avantaj aleyhimize olabilir.
6. Zaman Serisi Verilerini Analiz Etme
Bu adım, düzenli zaman aralıklarında toplanan veri noktalarının incelenmesine odaklanır. Zaman serisi verileri, zamanla değişen veriler için geçerlidir. Bu temel olarak veri setimizin düzenli zaman aralıklarında kaydedilen bir grup veri noktasından oluştuğu anlamına gelir.
Zaman serisi verilerini analiz ettiğimizde, genellikle zaman içinde tekrarlanan ve geçici bir mevsimsellik sunan modelleri veya eğilimleri ortaya çıkarabiliriz. Zaman serisi verilerinin temel bileşenleri trendleri, mevsimsel değişimleri, döngüsel değişimleri ve düzensiz değişimleri veya gürültüyü içerir.
7. Aykırı Değerler ve Eksik Değerlerle Başa Çıkmak
Aykırı değerler ve eksik değerler, uygun şekilde ele alınmadığı takdirde analiz sonuçlarını çarpıtabilir. Bu nedenle bunlarla başa çıkmak için her zaman tek bir aşamayı düşünmeliyiz.
Bu veri noktalarının belirlenmesi, kaldırılması veya değiştirilmesi, veri kümesi analizinin bütünlüğünü korumak açısından çok önemlidir. Bu nedenle verilerimizi analiz etmeye başlamadan önce bunları ele almak son derece önemlidir.
- Aykırı değerler, diğerlerinden önemli bir sapma gösteren veri noktalarıdır. Genellikle alışılmadık derecede yüksek veya düşük değerler sunarlar.
- Eksik değerler, belirli bir değişkene veya gözleme karşılık gelen veri noktalarının bulunmamasıdır.
Eksik değerler ve aykırı değerlerle başa çıkmanın kritik ilk adımı, bunların veri kümesinde neden mevcut olduğunu anlamaktır. Bu anlayış çoğu zaman bu sorunlara çözüm bulmak için en uygun yöntemin seçimine rehberlik eder. Göz önünde bulundurulması gereken diğer faktörler, verilerin özellikleri ve gerçekleştirilecek spesifik analizlerdir.
EDA yalnızca veri kümesinin netliğini arttırmakla kalmaz, aynı zamanda çok sayıda değişkene sahip veri kümelerini yönetmeye yönelik stratejiler sağlayarak veri profesyonellerinin boyutluluğun lanetini aşmasına da olanak tanır.
Bu titiz adımlarla EDA Python, analistleri verilerden anlamlı içgörüler elde etmek için gerekli araçlarla donatarak sonraki tüm veri analizi çabaları için sağlam bir temel oluşturur.
Josep Ferrer Barselona'dan bir analitik mühendisidir. Fizik mühendisliğinden mezun oldu ve şu anda insan hareketliliğine uygulanan Veri Bilimi alanında çalışıyor. Veri bilimi ve teknolojisine odaklanan yarı zamanlı bir içerik oluşturucudur. onunla iletişime geçebilirsin LinkedIn, Twitter or Orta.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/7-steps-to-mastering-exploratory-data-analysis?utm_source=rss&utm_medium=rss&utm_campaign=7-steps-to-mastering-exploratory-data-analysis

