
Yazara göre resim
Veri biliminin temelini oluşturan alanlardan biri makine öğrenimidir. Dolayısıyla veri bilimine girmek istiyorsanız makine öğrenimini anlamak, atmanız gereken ilk adımlardan biridir.
Peki nereden başlayacaksınız? İki ana makine öğrenimi algoritması türü arasındaki farkı anlayarak başlarsınız. Ancak bundan sonra, yeni başlayan biri olarak öğrenmek için öncelik listenizde olması gereken bireysel algoritmalardan bahsedebiliriz.
Algoritmalar arasındaki temel ayrım, nasıl öğrendiklerine dayanmaktadır.

Yazara göre resim
Denetimli öğrenme algoritmaları bir konuda eğitilirler etiketli veri kümesi. Bu veri seti, öğrenme için bir denetim (dolayısıyla adı) görevi görür çünkü içerdiği bazı veriler zaten doğru cevap olarak etiketlenmiştir. Algoritma, bu girdiye dayanarak öğrenebilir ve bu öğrenmeyi verilerin geri kalanına uygulayabilir.
Öte yandan, denetimsiz öğrenme algoritmaları bir şekilde öğren etiketlenmemiş veri kümesiyani insanlar talimat vermeden verilerdeki kalıpları bulmaya çalışıyorlar.
Hakkında daha detaylı bilgi edinebilirsiniz makine öğrenme algoritmaları ve öğrenme türleri.
Makine öğreniminin başka türleri de vardır ancak yeni başlayanlar için uygun değildir.
Algoritmalar, her makine öğrenimi türünde iki ana farklı sorunu çözmek için kullanılır.
Tekrar ediyorum, birkaç görev daha var ama bunlar yeni başlayanlar için değil.

Yazara göre resim
Denetimli Öğrenme Görevleri
Gerileme bir şeyi tahmin etme görevidir Sayısal değerDenilen sürekli sonuç değişkeni veya bağımlı değişken. Tahmin, yordayıcı değişken(ler)e veya bağımsız değişken(ler)e dayanmaktadır.
Petrol fiyatlarını veya hava sıcaklığını tahmin etmeyi düşünün.
Sınıflandırma tahmin etmek için kullanılır kategori (sınıf) giriş verileri. sonuç değişkeni burada kategorik veya ayrık.
Postanın spam olup olmadığını veya hastanın belirli bir hastalığa yakalanıp yakalanmayacağını tahmin etmeyi düşünün.
Denetimsiz Öğrenme Görevleri
kümeleme anlamına geliyor verileri alt kümelere veya kümelere bölme. Amaç, verileri mümkün olduğunca doğal bir şekilde gruplandırmaktır. Bu, aynı küme içindeki veri noktalarının, diğer kümelerdeki veri noktalarına göre birbirine daha benzer olduğu anlamına gelir.
Boyutsal küçülme Bir veri kümesindeki girdi değişkenlerinin sayısının azaltılması anlamına gelir. Temel olarak şu anlama gelir Veri kümesini çok az değişkene indirirken aynı zamanda özünü de yakalayın.
İşte ele alacağım algoritmalara genel bir bakış.
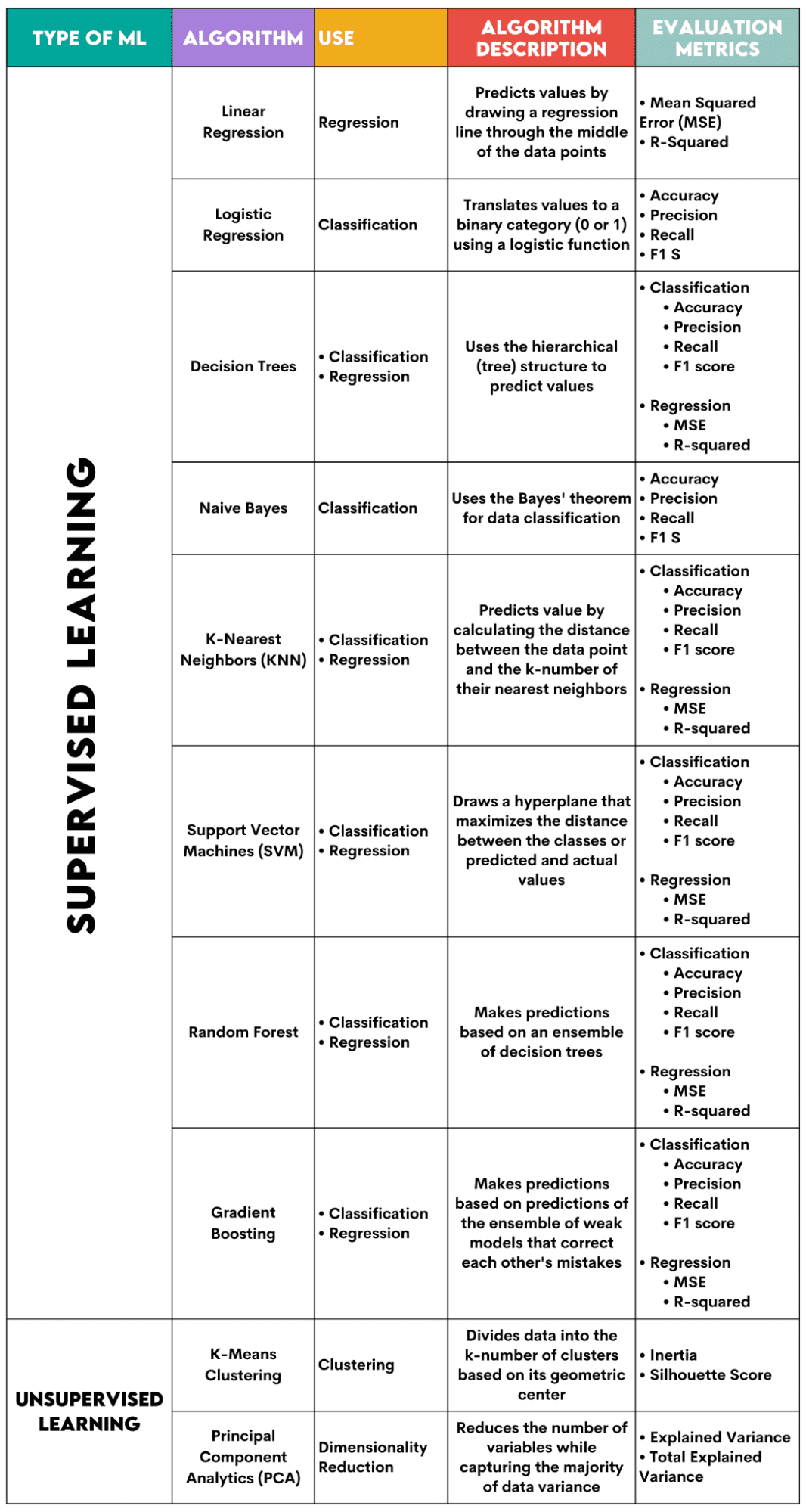
Yazara göre resim
Denetimli Öğrenme Algoritmaları
Probleminiz için algoritma seçerken algoritmanın hangi görev için kullanıldığını bilmek önemlidir.
Bir veri bilimci olarak muhtemelen bu algoritmaları Python'da aşağıdakileri kullanarak uygulayacaksınız: scikit-learn kitaplığı. Sizin için (neredeyse) her şeyi yapsa da, en azından her algoritmanın iç işleyişinin genel ilkelerini bilmeniz tavsiye edilir.
Son olarak algoritma eğitildikten sonra ne kadar iyi performans gösterdiğini değerlendirmelisiniz. Bunun için her algoritmanın bazı standart metrikleri vardır.
1. Doğrusal Regresyon
İçin kullanılır: Gerileme
Açıklama: Doğrusal regresyon düz bir çizgi çizer değişkenler arasındaki regresyon çizgisi denir. Bu çizgi yaklaşık olarak veri noktalarının ortasından geçerek tahmin hatasını en aza indirir. Bağımsız değişkenlerin değerine bağlı olarak bağımlı değişkenin tahmin edilen değerini gösterir.
Değerlendirme Metrikleri:
- Ortalama Kare Hatası (MSE): Hatanın karesinin ortalamasını temsil eder; hata, gerçek ve tahmin edilen değerler arasındaki farktır. Değer ne kadar düşük olursa algoritma performansı o kadar iyi olur.
- R-kare: Bağımlı değişkenin bağımsız değişken tarafından tahmin edilebilecek varyans yüzdesini temsil eder. Bu ölçü için 1'e olabildiğince yaklaşmaya çalışmalısınız.
2. Lojistik Regresyon
İçin kullanılır: Sınıflandırma
Açıklama: Kullanır lojistik fonksiyon veri değerlerini ikili bir kategoriye, yani 0 veya 1'e çevirmek için. Bu, genellikle 0.5 olarak ayarlanan eşik kullanılarak yapılır. İkili sonuç, bu algoritmayı EVET/HAYIR, DOĞRU/YANLIŞ veya 0/1 gibi ikili sonuçları tahmin etmek için mükemmel kılar.
Değerlendirme Metrikleri:
- Doğruluk: Doğru ve toplam tahminler arasındaki oran. 1'e ne kadar yakınsa o kadar iyidir.
- Hassasiyet: Pozitif tahminlerde model doğruluğunun ölçüsü; doğru pozitif tahminler ile toplam beklenen pozitif sonuçlar arasındaki oran olarak gösterilir. 1'e ne kadar yakınsa o kadar iyidir.
- Hatırlayın: Bu da modelin pozitif tahminlerdeki doğruluğunu ölçer. Doğru olumlu tahminlerin sınıfta yapılan toplam gözlemlere oranı olarak ifade edilir. Bu metrikler hakkında daha fazlasını okuyun okuyun.
- F1 Skoru: Modelin geri çağırma ve kesinliğinin harmonik ortalaması. 1'e ne kadar yakınsa o kadar iyidir.
3. Karar Ağaçları
İçin kullanılır: Regresyon ve Sınıflandırma
Açıklama: Karar ağaçları değeri veya sınıfı tahmin etmek için hiyerarşik veya ağaç yapısını kullanan algoritmalardır. Kök düğüm tüm veri kümesini temsil eder ve bu daha sonra değişken değerlere göre karar düğümlerine, dallara ve yapraklara ayrılır.
Değerlendirme Metrikleri:
- Doğruluk, kesinlik, hatırlama ve F1 puanı -> sınıflandırma için
- MSE, R-kare -> regresyon için
4. Naif Bayes
İçin kullanılır: Sınıflandırma
Açıklama: Bu, sınıflandırma algoritmalarının bir ailesidir. Bayes teoremi, yani bir sınıf içindeki özellikler arasında bağımsızlığı üstlenirler.
Değerlendirme Metrikleri:
- doğruluk
- Hassas
- Geri çağırmak
- F1 skoru
5. K-En Yakın Komşular (KNN)
İçin kullanılır: Regresyon ve Sınıflandırma
Açıklama: Test verileri ile cihaz arasındaki mesafeyi hesaplar. k-en yakın veri noktalarının sayısı eğitim verilerinden. Test verileri daha yüksek sayıda 'komşu' içeren bir sınıfa aittir. Regresyona ilişkin olarak tahmin edilen değer, seçilen k eğitim noktasının ortalamasıdır.
Değerlendirme Metrikleri:
- Doğruluk, kesinlik, hatırlama ve F1 puanı -> sınıflandırma için
- MSE, R-kare -> regresyon için
6. Destek Vektör Makineleri (SVM)
İçin kullanılır: Regresyon ve Sınıflandırma
Açıklama: Bu algoritma bir çizim yapar hiperdüzlem Farklı veri sınıflarını ayırmak için. Her sınıfın en yakın noktalarına en geniş mesafede konumlandırılır. Veri noktasının hiperdüzlemden uzaklığı ne kadar yüksek olursa, sınıfına o kadar ait olur. Regresyon için prensip benzerdir: hiperdüzlem, tahmin edilen ve gerçek değerler arasındaki mesafeyi maksimuma çıkarır.
Değerlendirme Metrikleri:
- Doğruluk, kesinlik, hatırlama ve F1 puanı -> sınıflandırma için
- MSE, R-kare -> regresyon için
7. Rastgele Orman
İçin kullanılır: Regresyon ve Sınıflandırma
Açıklama: Rastgele orman algoritması Daha sonra bir karar ormanı oluşturan bir karar ağaçları topluluğu kullanır. Algoritmanın tahmini birçok karar ağacının tahminine dayanmaktadır. Veriler en çok oyu alan sınıfa atanacaktır. Regresyon için tahmin edilen değer, tüm ağaçların tahmin edilen değerlerinin ortalamasıdır.
Değerlendirme Metrikleri:
- Doğruluk, kesinlik, hatırlama ve F1 puanı -> sınıflandırma için
- MSE, R-kare -> regresyon için
8. Gradyan Artırma
İçin kullanılır: Regresyon ve Sınıflandırma
Açıklama: Bu algoritmalar Her bir sonraki modelin önceki modelin hatalarını tanıyıp düzelttiği bir zayıf modeller topluluğu kullanın. Bu işlem hata (kayıp fonksiyonu) en aza indirilene kadar tekrarlanır.
Değerlendirme Metrikleri:
- Doğruluk, kesinlik, hatırlama ve F1 puanı -> sınıflandırma için
- MSE, R-kare -> regresyon için
Denetimsiz Öğrenme Algoritmaları
9. K-Means Kümeleme
İçin kullanılır: kümeleme
Açıklama: Algoritma veri kümesini her biri kendi değeriyle temsil edilen k-sayılı kümelere böler ağırlık merkezi veya geometrik merkez. Verileri k sayıda kümeye bölmenin yinelemeli süreci aracılığıyla amaç, veri noktaları ile kümenin ağırlık merkezi arasındaki mesafeyi en aza indirmektir. Öte yandan, bu veri noktalarının diğer kümelerin ağırlık merkezlerine olan uzaklığını da maksimuma çıkarmaya çalışır. Basitçe söylemek gerekirse, aynı kümeye ait veriler mümkün olduğu kadar benzer ve diğer kümelerden gelen verilerden farklı olmalıdır.
Değerlendirme Metrikleri:
- Atalet: Her veri noktasının en yakın küme merkezine olan uzaklığının karesi toplamı. Atalet değeri ne kadar düşük olursa küme o kadar kompakt olur.
- Siluet Skoru: Kümelerin uyumunu (verinin kendi kümesi içindeki benzerliğini) ve ayrılığını (verinin diğer kümelerden farklılığını) ölçer. Bu puanın değeri -1 ile +1 arasında değişmektedir. Değer ne kadar yüksek olursa, veri kendi kümesiyle o kadar iyi eşleşir, diğer kümelerle ise o kadar kötü eşleşir.
10. Temel Bileşen Analizi (PCA)
İçin kullanılır: Boyutsal küçülme
Açıklama: Algoritma Verinin yakalanan varyansını en üst düzeye çıkarmaya çalışırken, yeni değişkenler (temel bileşenler) oluşturarak kullanılan değişkenlerin sayısını azaltır. Başka bir deyişle, verinin özünü kaybetmeden veriyi en yaygın bileşenleriyle sınırlandırır.
Değerlendirme Metrikleri:
- Açıklanan Varyans: Her bir temel bileşenin kapsadığı varyansın yüzdesi.
- Toplam Açıklanan Varyans: Tüm temel bileşenler tarafından kapsanan varyansın yüzdesi.
Makine öğrenimi veri biliminin önemli bir parçasıdır. Bu on algoritmayla makine öğrenimindeki en yaygın görevleri ele alacaksınız. Elbette bu genel bakış size her algoritmanın nasıl çalıştığına dair yalnızca genel bir fikir verir. Yani bu sadece bir başlangıç.
Artık bu algoritmaları Python'da nasıl uygulayacağınızı ve gerçek sorunları nasıl çözeceğinizi öğrenmeniz gerekiyor. Bunun için scikit-learn'i kullanmanızı öneririm. Yalnızca kullanımı nispeten kolay bir ML kütüphanesi olduğu için değil, aynı zamanda kapsamlı malzemeler ML algoritmaları hakkında.
Nate Rosidi bir veri bilimcidir ve ürün stratejisindedir. Aynı zamanda analitik öğreten yardımcı profesördür ve veri bilimcilerinin röportajlarına en iyi şirketlerden gelen gerçek röportaj sorularıyla hazırlanmalarına yardımcı olan bir platform olan StrataScratch'in kurucusudur. Nate, kariyer pazarındaki en son trendler hakkında yazıyor, röportaj tavsiyeleri veriyor, veri bilimi projelerini paylaşıyor ve SQL ile ilgili her şeyi ele alıyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/a-beginner-guide-to-the-top-10-machine-learning-algorithms?utm_source=rss&utm_medium=rss&utm_campaign=a-beginners-guide-to-the-top-10-machine-learning-algorithms

